Amazon Web Services (AWS) bieten zahlreiche Lösungen an - das gibt uns als Entwicklern eine breite Palette optionaler Tools an die Hand, um die Geschäftsziele eines Kunden zu erreichen. Aber wie bestimmen wir die beste Lösung?
Das ist eine Situation, über die wir immer wieder nachdenken. Daher sind wir immer bestrebt, mögliche Lösungen zu testen, selbst in einem hypothetischen Stadium oder bei der Erstellung von Proof of Concepts (PoC), die weiterentwickelt werden können. In diesem Fall wollten wir die Skalierung von containerisierten Anwendungen untersuchen. Mit einem potenziellen realen Szenario vor Augen machte ich mich also an die Arbeit, um die beiden praktikabelsten Optionen zu testen, um herauszufinden, welche die erforderlichen Geschäftsziele erfüllt.
Die Herausforderung
Stellen wir uns vor, ein Fotounternehmen möchte sein Portfolio um Bildbearbeitungsdienste erweitern. Die Kunden des Unternehmens aus der ganzen Welt werden eine große Anzahl von Bildern hochladen, die bearbeitet werden müssen, und das Unternehmen geht aufgrund der bisherigen Daten davon aus, dass in einem Zeitraum von 30 Minuten nicht mehr als 10 Tausend Bilder zu bearbeiten sind. Dies sollte als der Grenzfall betrachtet werden, den das System erleben würde.
Das Fotounternehmen möchte eine Infrastruktur haben, die effektiv arbeitet, wenn eine große Menge an Uploads stattfindet, aber auch nachts, wenn nicht so viele Bilder umgewandelt werden, nicht zu viel Geld für die Infrastruktur ausgeben. Außerdem möchten sie diese neue Lösung schnell implementieren und die Zeit bis zur Markteinführung verkürzen. Das Unternehmen hat auch schon von Cloud-Lösungen gehört und würde diese Funktionen gerne nutzen. Nach der Bearbeitung der Bilder sollten sowohl das Original als auch die umgewandelte Version heruntergeladen werden können, solange die Benutzer sie nicht aus dem Dienst selbst löschen.
Die erste Lösung, die einem in den Sinn kommt, ist serverloses Computing mit AWS Lambda, aber das Unternehmen ist noch nicht bereit für eine solche Innovation. Zum Zwecke der Transformation haben sie bereits drei containerisierte Anwendungen entwickelt, um eine große Anzahl von Images zu verarbeiten:
- Eine App zum Konvertieren von Bildern in Graustufen,
- Eine App zum Erstellen einer Miniaturansicht.
 Abbildung 1 Ein Bild vor und nach der Konvertierung in Graustufen[/caption]
Abbildung 1 Ein Bild vor und nach der Konvertierung in Graustufen[/caption]
 Abbildung 2. Ein Originalbild und eine Miniaturansicht[/caption]
Abbildung 2. Ein Originalbild und eine Miniaturansicht[/caption]
Unser Hauptziel war es, eine Cloud-Infrastruktur aufzubauen, die die folgenden Geschäftsanforderungen erfüllt:
- Hochladen und Herunterladen einer großen Anzahl von Bildern auf eine dauerhafte Speicherlösung,
- Verarbeitung von 10 Tausend Bildern in weniger als 30 Minuten,
- Nutzung der vorhandenen containerisierten Anwendungen, je nach Verkehrsaufkommen, um die Kosten durch effektive Nutzung der Infrastruktur zu senken,
- Speichern von Bildern nach der Umwandlung, solange der Benutzer sie auf dem System behält.
Architektur
Mit diesen Geschäftszielen im Hinterkopf entschieden wir uns für die Implementierung einer Cloud-Architektur, die Amazon S3 als Objektspeicherdienst und Amazon SQS als Warteschlangendienst umfasst. Diese Dienste waren offensichtliche Kandidaten, wie wir weiter unten erläutern werden. Wir beschlossen jedoch, die Amazon Container Services zu testen, um diese Bildverarbeitungsanwendungen auszuführen und zu skalieren und ihre Funktionen zu vergleichen. Das folgende Diagramm der AWS-Architektur zeigt alle Ressourcen, die innerhalb einer Virtual Private Cloud (VPC) bereitgestellt werden, sowie ihre Beziehungen.
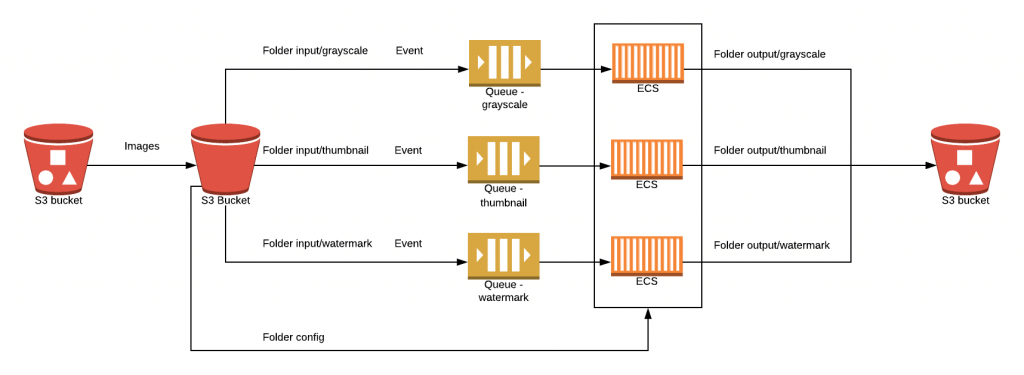
Wie im obigen Diagramm dargestellt, wird die S3-Ereignisbenachrichtigung an die entsprechende SQS-Warteschlange gesendet, wenn eine Bilddatei in den angegebenen Ordner im S3-Bucket hochgeladen wird. Sobald zum Beispiel das Ereignis s3:ObjectCreated im Ordner input/grayscale eintritt, wird der Link des kürzlich hochgeladenen Bildes an eine spezielle Warteschlange gesendet. Daraufhin ruft die Anwendung, die auf einem der besprochenen Amazon Container Management Services läuft, die Bildadresse aus der Warteschlange ab, lädt sie aus dem S3-Bucket herunter und wandelt sie in die Graustufenintensität um. Das verarbeitete Bild wird an den Ordner output/grayscale im ursprünglichen S3-Bucket gesendet.
Amazon Einfacher Speicherdienst
Die Annahme, dass die große Anzahl von Bildern alle verarbeitet werden muss, hat uns dazu veranlasst, Amazon S3 als Objektspeicherlösung zu wählen. Amazon Simple Storage Service bietet eine extrem langlebige (99,999999999% Haltbarkeit der Objekte) und hochverfügbare Datenspeicherinfrastruktur mit geringer Latenz und hoher Durchsatzleistung. Außerdem können als Reaktion auf Änderungen im S3-Bucket Ereignisbenachrichtigungen an Amazon Simple Notification Service (SNS), Amazon Simple Queue Service (SQS) oder AWS Lambda gesendet werden. Da die Images nach dem Hochladen in den S3-Bucket an containerisierte Anwendungen übertragen werden müssen, war die Amazon S3-Benachrichtigungsfunktion zusammen mit Amazon SQS eine gute Wahl.
Amazon Simple Queue Service
Amazon SQS ist ein kosteneffizienter Message Queuing Service, der die Entkopplung und Skalierung von verteilten Softwarekomponenten erleichtert. Kopien jeder Nachricht werden redundant über mehrere Verfügbarkeitszonen hinweg gespeichert. SQS kann jede beliebige Datenmenge übertragen, ohne dass andere Dienste ständig verfügbar sein müssen, was sehr kosteneffizient ist. Darüber hinaus bieten die Standard-SQS-Warteschlangen eine "at-least-once"-Zustellung, die der Anforderung gerecht wird, das Image nur einmal zu verarbeiten, und gleichzeitig dazu beiträgt, die Kosten zu senken.
Container Dienste
AWS bietet mehrere Container-Produkte für die Bereitstellung, Verwaltung und Skalierung von Containern in der Produktion. In der AWS Cloud können Container über Kubernetes mit Amazon EKS, Amazon Elastic Container Service (ECS) und AWS Fargate ausgeführt werden. Wir haben die Bildverarbeitungsanwendungen für diese Container-Orchestrierungsdienste bereitgestellt und eine automatische Skalierung implementiert, um die Leistung der Container, die betriebliche Effizienz und die Kosten zu vergleichen.
Amazon Elastic Container Service
Amazon ECS ermöglicht uns die einfache Ausführung, Verwaltung und Skalierung von Docker-Containern in einem Cluster innerhalb einer VPC, einem logisch isolierten Bereich der AWS Cloud mit Kontrolle des Netzwerkverkehrs. Der Amazon ECS-Cluster ist eine regionale Gruppierung von Services, Aufgaben und Container-Instanzen, wenn der EC2-Starttyp verwendet wird. Wenn ein Cluster eingerichtet ist und läuft, müssen Aufgabendefinitionen erstellt werden. Die Aufgabendefinition ist eine JSON-Datei, die einen oder mehrere Container mit Parametern wie auszuführende Docker-Images, für die Anwendung zu öffnende Ports oder mit den Containern zu verwendende Datenvolumen beschreibt.
Außerdem wurden die Container-Images für die Graustufen-, Thumbnail- und Wasserzeichen-Anwendungen in Amazon Elastic Container Registry (ECR) gespeichert und von dort abgerufen. Amazon ECR hilft dabei, Docker-Container-Images sicher zu speichern, abzurufen und bereitzustellen. In unserem Fall umfasste der Cluster drei ECS-Dienste, jeweils für eine der Anwendungen. Der Dienst war dafür verantwortlich, eine bestimmte Anzahl von Instanzen einer Aufgabendefinition, auch Aufgaben genannt, gleichzeitig in einem Cluster zu starten und zu verwalten. Immer wenn eine Aufgabe anhielt, startete der ECS-Dienstplaner eine neue Instanz der Aufgabendefinition.
Außerdem wurde der Dienst hinter einem Elastic Load Balancer (ELB) ausgeführt, um den Datenverkehr gleichmäßig auf die Aufgaben zu verteilen, was zu einer höheren Fehlertoleranz beiträgt.
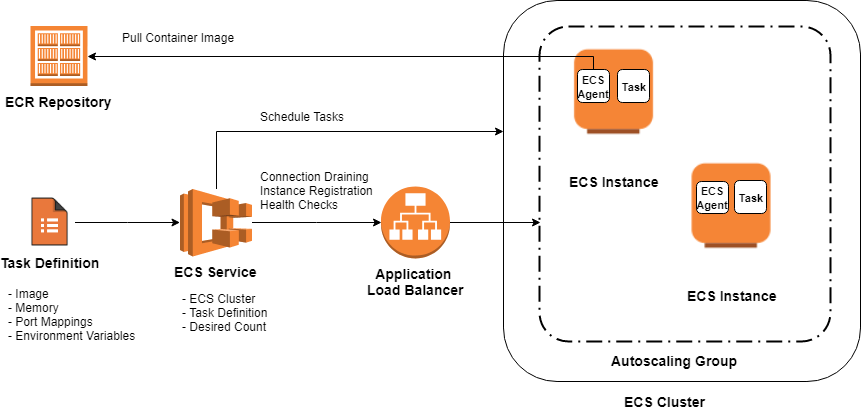
Für den Amazon ECS-Cluster wurde eine Auto-Scaling-Gruppe erstellt, die Container-Instanzen enthielt, die mithilfe von CloudWatch-Alarmen hoch- und herunterskaliert werden konnten. Die Auto Scaling-Gruppe verwendete zwei benutzerdefinierte Skalierungsrichtlinien:
- Fügen Sie eine EC2-Instanz hinzu, wenn der CloudWatch-Alarm ecs-asg-utilization-high den Schwellenwert überschreitet,
- Entfernen Sie eine Container-Instanz, wenn der Alarm ecs-asg-utilization-low den angegebenen Schwellenwert überschreitet.
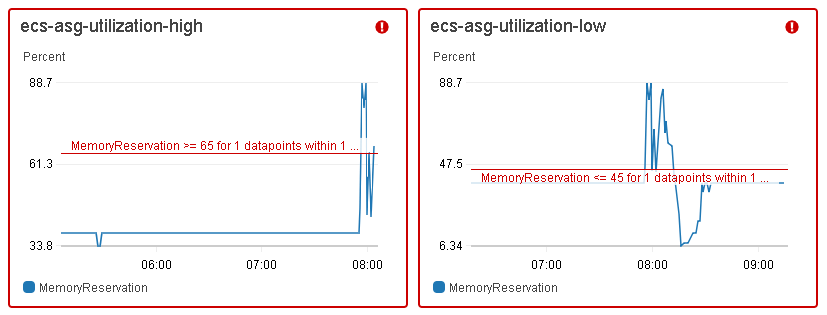
Wie in den vorangegangenen CloudWatch-Diagrammen zu sehen ist, löste der ecs-asg-utilization-high-Alarm die Skalierungsrichtlinie aus, wenn die Speicherreservierung des ECS-Clusters 60 Sekunden lang 65 % überschritt, während der ecs-asg-utilization-low-Alarm die Skalierungsrichtlinie auslöste, wenn die Speicherreservierung in einem gleitenden 1-Minuten-Fenster weniger als oder gleich 45 % betrug. Die Verwendung eines niedrigeren Schwellenwerts als der für die Skalierung nach oben ermöglicht uns eine Abkühlungsphase, so dass es beim Herunterfahren der Instanzen nicht zu einem Ressourcenkampf kommt.
CloudWatch-Alarme lösen nur dann Aktionen aus, wenn sich der Zustand ändert und dieser für einen bestimmten Zeitraum aufrechterhalten wird. Wenn zum Beispiel ein in einem Zeitfenster erfasster Datenpunkt den konfigurierten Schwellenwert nicht überschreitet, wird der CloudWatch-Alarm nicht ausgelöst. Ebenso wird der Alarm wieder auf normal gesetzt, wenn mindestens einer der Zeiträume den Schwellenwert nicht überschreitet.
Für jeden Amazon ECS-Service wurde die automatische Skalierung so konfiguriert, dass die Anzahl der gewünschten Aufgaben als Reaktion auf CloudWatch-Alarme nach oben oder unten angepasst wurde. Basierend auf der Anzahl der Nachrichten, die für den Abruf aus der SQS-Warteschlange zur Verfügung standen, wurden Aufgaben zum ECS-Service hinzugefügt oder aus ihm entfernt. Die folgenden Diagramme zeigen die Veränderung der Anzahl der verarbeitungsbereiten Nachrichten im Grayscale-Service. 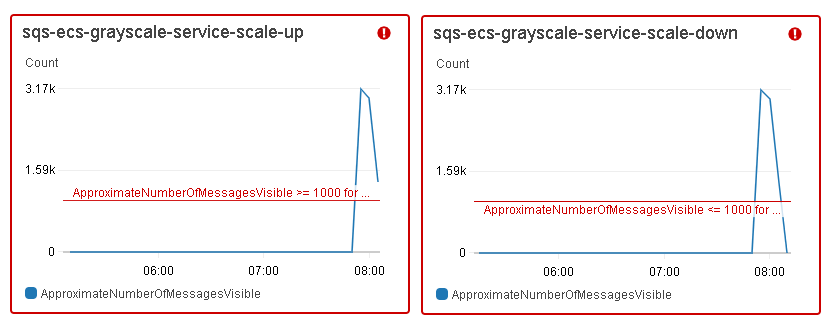
Der sqs-ecs-grayscale-service-scale-up-Alarm löste die Skalierungsrichtlinie aus, um 5 Tasks hinzuzufügen, wenn die ApproximateNumberOfMessagesVisible größer oder gleich 1.000 war, sowie 10 Tasks hinzuzufügen, wenn diese Zahl über 3.000 lag, während der sqs-ecs-grayscale-service-scale-down-Alarm die Skalierungsrichtlinie ausführte, um 5 Tasks zu entfernen, wenn die Anzahl der Nachrichten in der SQS-Warteschlange kleiner oder gleich 1.000 war.
Um die automatische Skalierung des ECS-Clusters zu testen, wurden, wie oben beschrieben, 10.000 Bilder in die Eingabeordner im leeren S3-Bucket hochgeladen: Graustufen, Vorschaubilder und Wasserzeichen, entsprechend. Dann wurden die folgenden Testfälle ausgeführt:
- 100% der Bilder wurden dem Wasserzeichenordner hinzugefügt, wobei der Schwellenwert auf 1.000 Nachrichten festgelegt wurde.
- Das Verhältnis der hochgeladenen Bilder war 40:40:20, wobei der Schwellenwert auf 1.000 Nachrichten festgelegt wurde.
- Das Verhältnis der hochgeladenen Bilder war 40:40:20, wobei der Schwellenwert auf 2.000 Nachrichten geändert wurde.
- Das Verhältnis der hochgeladenen Bilder war 40:40:20, wobei der Schwellenwert auf 500 Nachrichten geändert wurde.
Die nachstehende Tabelle enthält die Testergebnisse, einschließlich der Dauer der Bildverarbeitung, der Dauer der Hochskalierung von Aufgaben in jedem ECS-Dienst und der Dauer der Hochskalierung von ECS-Container-Instanzen.
| Test Fall | Dauer (Sekunden) | ||||
| Bild Verarbeitung | Graustufen-Aufgaben hochskalieren | Thumbnail-Aufgaben hochskalieren | Wasserzeichen-Aufgaben hochskalieren | ECS-Instanzen hochskalieren | |
| 1 | 861 | - | - | 720 | 840 |
| 2 | 940 | 800 | 840 | 642 | 782 |
| 3 | 978 | 500 | 260 | - | 820 |
| 4 | 1022 | 660 | 541 | 901 | 719 |
Wie aus der Tabelle hervorgeht, hatte eine Änderung des CloudWatch-Schwellenwerts einen spürbaren Einfluss auf die Testergebnisse. Wir hatten erwartet, dass nach einer Verringerung des Alarmschwellenwerts die Zeit für das Hochskalieren von Aufgaben und die Bildverarbeitung geringer sein würde als bei dem größeren Schwellenwert. Vergleicht man die Fälle 2 und 4, bei denen der Schwellenwert für den Testfall 2 um das Vierfache größer ist, so ist die Zeit für das Hochskalieren der Aufgaben sowohl für Graustufenbilder (von 800 Sekunden auf 660 Sekunden) als auch für Miniaturbilder (von 840 Sekunden auf 541 Sekunden) gesunken. Bei Wasserzeichen dauerte die Skalierung länger (die Zeit stieg von 640 Sekunden auf 901 Sekunden). Wahrscheinlich resultiert dieser Ausreißerwert aus der Tatsache, dass zu Beginn von Testfall 4 Aufgaben aus Graustufen- und Thumbnail-Ordnern vorlagen, das Wasserzeichen jedoch auf der zweiten EC2-Instanz erschien, so dass die Zeit für die Hochskalierung länger war. Es wäre eine gute Idee, eine einfache Skalierungsrichtlinie in eine Skalierungsrichtlinie mit Stufen zu ändern, bei der Sie je nach Speicherreservierung mehrere Skalierungsstufen festlegen können.
Sie sollten auch nicht vergessen, dass in einer solchen Situation die Durchführung von Tests sehr wichtig ist, um die optimale Skalierungslösung zu finden. Schließlich sind es diese Tests, die uns in die Lage versetzen, die Empfehlungen für die Zukunft zu bestimmen.
[caption id="attachment_21838" align="aligncenter" width="677"] Abbildung 4 Beispiel für die Stufenskalierung in der Auto-Skalierungsgruppe[/caption]
Abbildung 4 Beispiel für die Stufenskalierung in der Auto-Skalierungsgruppe[/caption]
Die nachstehenden Diagramme zeigen die Entwicklung der Anzahl der SQS-Nachrichten und der Anzahl der Aufgaben im Vergleich zur Zeit für Testfall 1 und 2.
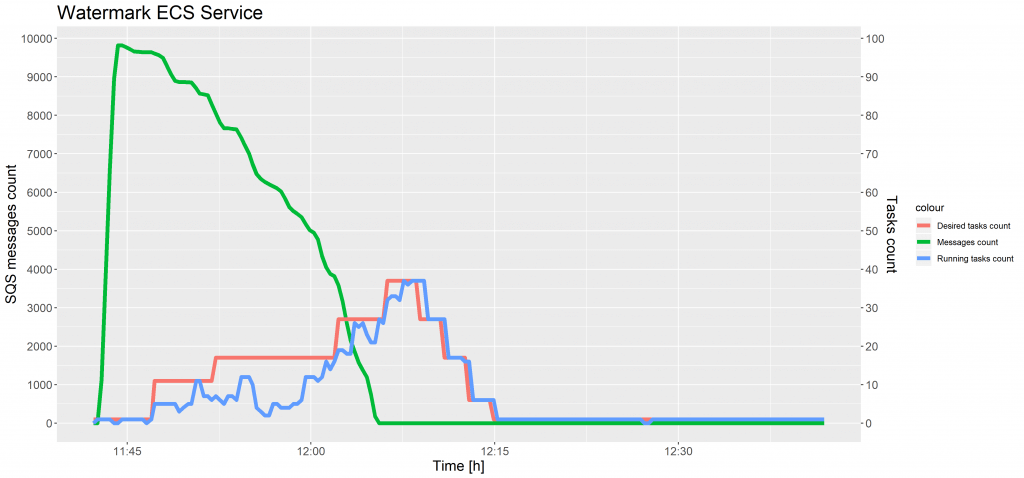
In der obigen Grafik ist die Anzahl der laufenden Aufgaben zwischen 11:40 und 11:55 Uhr mehrmals gesunken. Wenn der Speicher im Cluster nicht ausreichte, um neue Aufgaben zu reservieren, wurde eine weitere Container-Instanz hinzugefügt, während einige Aufgaben beendet und auf dem neuen Host platziert wurden, um die Ressourcen effektiver zu verteilen.
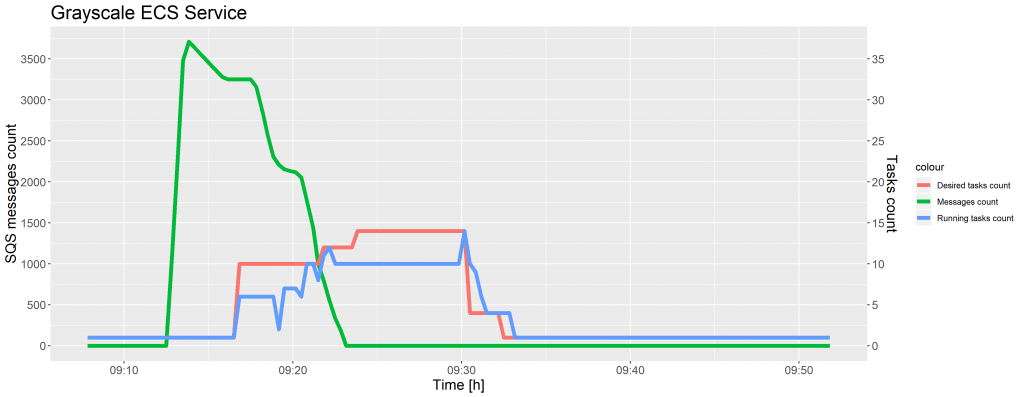
Wie in den vorangegangenen Diagrammen zu sehen ist, wurde die Anzahl der gewünschten Aufgaben nicht sofort erhöht, nachdem die Anzahl der SQS-Nachrichten dem Schwellenwert entsprach, sondern mit einer zeitlichen Verzögerung. Der Grund dafür ist, dass die Metriken für Amazon SQS-Warteschlangen alle fünf Minuten gesammelt und an CloudWatch übertragen werden. Eine mögliche Lösung für dieses Problem ist das Schreiben einer AWS Lambda-Funktion, um die SQS-Warteschlangen häufiger zu überwachen und die Skalierung der Aufgaben im ECS-Service zu steuern. Wir haben uns jedoch für eine Lösung von der Stange entschieden, wie sie von AWS bereitgestellt wird.
Wenn der Prozentsatz des von den laufenden Aufgaben im Cluster reservierten Speichers über 65 stieg, löste der CloudWatch-Alarm die Auto Scaling-Gruppe aus, um eine weitere Instanz hinzuzufügen. Wenn die Cluster-Speicherreservierung weniger als 45% betrug, führte der CloudWatch-Alarm die Gruppenrichtlinie Auto Scaling aus, um Container-Instanzen zu entfernen. Die folgende Abbildung zeigt die Veränderung der Cluster-Speicherreservierung und der Anzahl der ECS-Instanzen im Laufe der Zeit, als die Bilder in den Graustufen-, Thumbnail- und Wasserzeichenordner hochgeladen wurden, wiederum im Verhältnis 40:40:20.
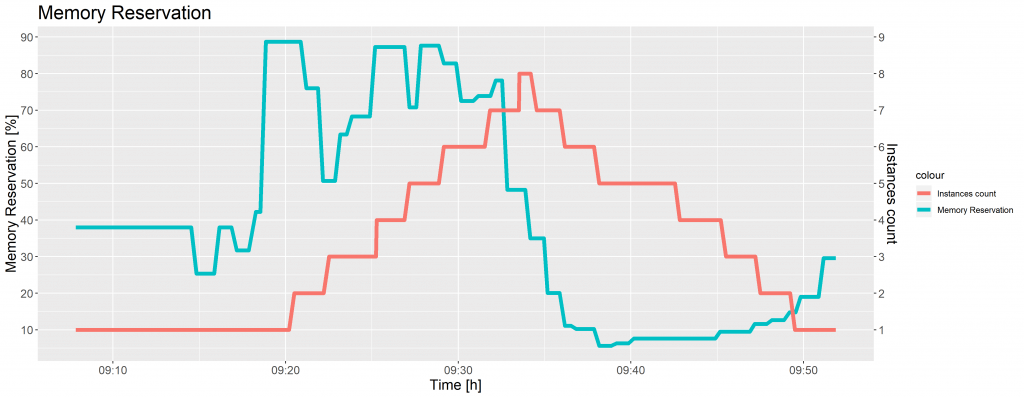
Abbildung 3 zeigt, dass die EC2-Instanzen unmittelbar nach Überschreiten der CloudWatch-Alarmschwelle hinzugefügt wurden. Die Auto Scaling-Gruppe beendete 7 Instanzen in 15 Minuten, was der Standardzeit für die Beendigung von EC2-Instanzen entspricht.
Wenn Sie Amazon Elastic Container Service mit dem EC2-Starttyp verwenden, zahlen Sie für AWS-Ressourcen, hauptsächlich für EC2-Instanzen, die für die Ausführung von containerisierten Anwendungen erstellt werden. Es gibt keine Mindestgebühren und keine Vorabverpflichtungen. In der AWS-Region EU (Irland), in der diese ECS-Tests durchgeführt wurden, beträgt der Preis pro On Demand Linux t2.medium-Instanz pro Stunde $0,05 und der Preis für den Application Load Balancer pro Stunde $0,0252. Im Falle von 8 Instanzen, die 10.000 Images verarbeiten sollten, beliefen sich die Gesamtkosten für die Berechnung also auf:
Gesamte Berechnungsgebühren = 8 × $0,05+ $0,0252 = $0,4252
AWS Fargate
AWS Fargate ist eine Rechen-Engine für Amazon ECS, die Container ausführt, ohne dass Sie Amazon EC2-Instance-Typen auswählen, Cluster bereitstellen und skalieren oder jeden Server patchen müssen. Bei der Ausführung von Aufgaben und Services mit dem Fargate-Starttyp wurden Anwendungen in Docker-Containern gestartet und die CPU- und Speicheranforderungen wurden in der Aufgabendefinition von Fargate angegeben. Auch wenn mit Fargate keine Instanzen zu verwalten sind, werden die Aufgaben in logischen Clustern gruppiert.
Ähnlich wie bei Amazon ECS wurde für jeden Fargate-Dienst eine automatische Skalierung konfiguriert, um die gewünschte Anzahl von Aufgaben zu erhalten. Die CloudWatch-Alarme wurden erstellt, um Aufgaben hinzuzufügen und zu entfernen, wenn sich die Anzahl der Nachrichten in der SQS-Warteschlange änderte. Da Fargate die zugrunde liegende Infrastruktur verwaltet, wurde keine Skalierung der Container-Instanzen vorgenommen. Analog zu ECS wurden 10.000 Bilder in die Eingabeordner im S3-Bucket hochgeladen: Graustufen, Thumbnail und Wasserzeichen, entsprechend. Die folgenden Testfälle wurden ausgeführt:
- 100% der Bilder wurden in den Ordner mit den Wasserzeichen hochgeladen und der Schwellenwert wurde auf 1.000 Nachrichten festgelegt.
- Das Verhältnis der hochgeladenen Bilder war 40:40:20, wobei der Schwellenwert auf 1.000 Nachrichten festgelegt wurde.
- Das Verhältnis der hochgeladenen Bilder war 40:40:20, wobei der Schwellenwert auf 2.000 Nachrichten geändert wurde.
- Das Verhältnis der hochgeladenen Bilder war 40:40:20, wobei der Schwellenwert auf 500 Nachrichten geändert wurde.
Die folgende Tabelle zeigt die Testergebnisse, einschließlich der Dauer der Bildverarbeitung und der Skalierung der Aufgaben in jedem Fargate-Dienst.
| Test Fall | Dauer (Sekunden) | |||
|---|---|---|---|---|
| Bild Verarbeitung | Graustufen-Aufgaben hochskalieren | Thumbnail-Aufgaben hochskalieren | Wasserzeichen-Aufgaben hochskalieren | |
| 1 | 739 | - | - | 560 |
| 2 | 800 | 500 | 500 | 220 |
| 3 | 800 | 439 | 360 | - |
| 4 | 601 | 518 | 536 | 575 |
Wie in der vorangegangenen Tabelle gezeigt, wurden die Images im Vergleich zu Amazon ECS schneller verarbeitet, da AWS Fargate die gesamte Skalierung und Infrastruktur verwaltete, die für die hochverfügbare Ausführung von Containern erforderlich ist.
Die folgenden Diagramme zeigen die Entwicklung der Anzahl der SQS-Nachrichten und der Anzahl der Aufgaben im Vergleich zur Zeit für Testfall 1 und 2.
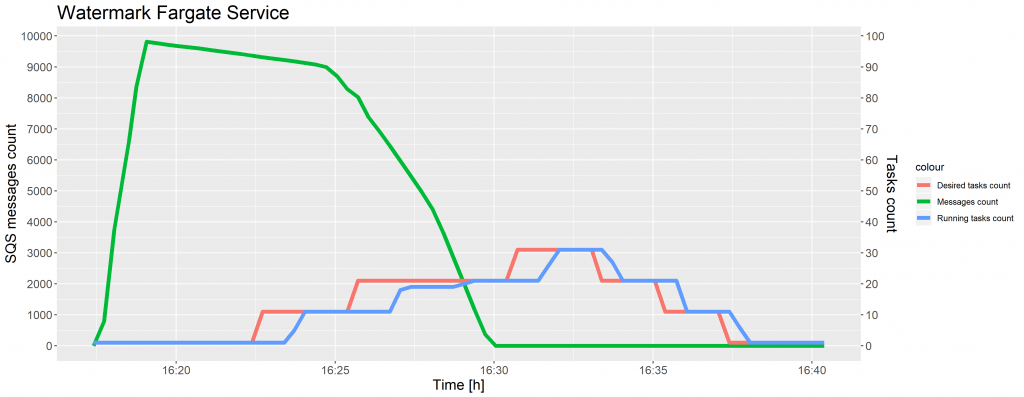
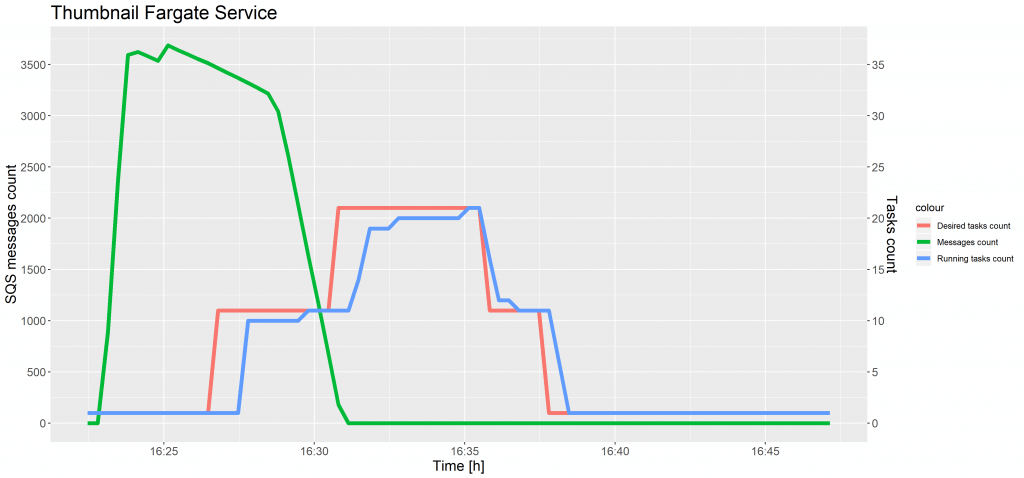
Wie in den vorangegangenen Diagrammen zu sehen ist, kam es zu einer zeitlichen Verzögerung bei der Erhöhung der Anzahl der gewünschten Aufgaben, nachdem der CloudWatch-Alarm den Schwellenwert erreicht hatte. Diese Situation trat auch bei der Skalierung von ECS-Aufgaben auf und wurde durch das 5-Minuten-Intervall bei den SQS-Metriken verursacht. Die Instanzen einer Aufgabendefinition wurden nahtlos skaliert, ohne dass sich die Anzahl der laufenden Aufgaben verringerte.
AWS Fargate hat eine ressourcenbasierte Preisgestaltung und eine sekundengenaue Abrechnung, d. h. Sie zahlen nur für die Zeit, in der die Ressourcen von der Aufgabe verbraucht werden. Der Preis für die Menge an vCPU- und Speicherressourcen wird auf Sekundenbasis berechnet. Die Dauer wird vom Beginn des Herunterladens der Container-Images bis zur Beendigung der Aufgabe berechnet. Unsere Fargate-Services liefen in der AWS-Region EU (Irland), wo der Preis pro vCPU pro Stunde $0,0506 und der Preis pro GB Speicher pro Stunde $0,0127 beträgt. Die gesamten vCPU-Kosten sollten nach der folgenden Formel berechnet werden:
vCPU-Gebühren = Anzahl der Tasks × Anzahl der vCPUs × Preis pro CPU pro Sekunde × CPU-Dauer pro Sekunden
Die Gesamtkosten für den Speicher sollten nach der folgenden Formel berechnet werden:
Speicherkosten = Anzahl der Aufgaben × Speicher in GB × Preis pro GB × Speicherdauer pro Sekunde
Wenn beispielsweise 90 Aufgaben 12 Minuten (720 Sekunden) lang laufen, um 10.000 Bilder zu verarbeiten, und jede Aufgabe 0,5 vCPU und 0,5 GB Arbeitsspeicher verwendet, sind die Kosten für vCPU und Arbeitsspeicher gleich:
vCPU-Gebühren = 90 × 0,5 × 0,00001406 × 720 = $0,455544 Speichergebühren = 90 × 0,5 × 0,00000353 × 720 = $0,114372
Die Gesamtkosten für die Fargate-Berechnungen beliefen sich in diesem Fall also auf $0,569916.
Zusammenfassung & Vergleich
AWS Fargate entlastet Sie von der Verantwortung für die zugrunde liegenden Amazon EC2-Instanzen. Andererseits bietet die Verwaltung von EC2-Instanzen mehr Kontrolle über Server-Cluster und eine breitere Palette von Anpassungsoptionen. Der Zugriff auf diese Container-Instanzen kann für bestimmte Zwecke nützlich sein, z.B. für die Installation fortgeschrittener Software oder für die Fehlersuche. Amazon ECS mit dem EC2-Starttyp erwies sich als ein günstigerer Container-Orchestrierungsdienst als AWS Fargate. Die Images wurden zwar langsamer verarbeitet, aber die Gesamtkosten für die Berechnung waren niedriger, so dass das Geschäftsziel, Container zu einem möglichst niedrigen Preis zu betreiben, erreicht wurde.
Diese Lösung würde jedoch einen noch größeren Verwaltungsaufwand erfordern, um die automatische Skalierung zu optimieren und bessere Ergebnisse zu erzielen - zum Beispiel durch die Verwendung einer Stufenskalierung mit geeigneten Schwellenwerten.
Mit AWS Fargate ist die Konfiguration der Infrastruktur und das Starten von Aufgaben einfach, und wir müssen uns nicht mehr um die Bereitstellung ausreichender Rechenressourcen für die Container-Anwendungen kümmern. Außerdem wurden die Bilder in den Aufgaben mit dem Fargate-Starttyp (10.000 Dateien in etwa 12 Minuten) schneller verarbeitet als mit dem ECS-Starttyp (10.000 Dateien in etwa 16 Minuten), da die Fargate-Aufgaben nicht beendet und auf die neue EC2-Instanz verlagert wurden. Dies entspricht dem Unternehmensziel, 10.000 Fotos in weniger als 30 Minuten zu verarbeiten.
Vorwärts bewegen
Für das hypothetische Fotografieunternehmen, das hinter diesem Szenario steht, ist der wichtigste Aspekt die Zeit bis zur Markteinführung und die Eliminierung des Verwaltungsaufwands, daher ist die beste Option die Verwendung von AWS Fargate. Wenn jedoch Änderungen an der Architektur der Anwendung ins Spiel kommen, würden wir die Verwendung von AWS Serverless mit AWS Lambda empfehlen.
Als PoC hat dieses Experiment die unterschiedlichen Vorzüge der verschiedenen AWS-Tools bewiesen, die je nach den wichtigsten Geschäftsanforderungen ausgewählt werden können. In Zukunft könnten beide Optionen weiterentwickelt und mit zusätzlichen Instanzen unterstützt werden. Die zugrundeliegende Technologie ist nicht nur auf die Bildverarbeitung beschränkt, sondern könnte auch für die Veröffentlichung digitaler Inhalte, die Bearbeitung von Geschäftsaufträgen (sowie deren anschließende Lieferung), Audiotranskriptionen, Plagiatsanalysen und mehr verwendet werden. Alle diese Beispiele können das hier aufgebaute Grundgerüst nutzen.
Geschäftsperspektive
Mit der Cloud und der AWS-Technologie gibt es mehr als einen Weg, ein Ziel zu erreichen. Jede Methode hat jedoch ihre eigenen Stärken, so dass die Entwicklung einer Lösung, die den wichtigsten Unternehmenszielen entspricht - sei es die Markteinführungszeit oder die langfristigen Gemeinkosten - die endgültige Entscheidung beeinflussen kann. Nichtsdestotrotz ermöglicht uns das effektive Testen dieser Lösungen, die besten Empfehlungen für jeden einzelnen Kunden auszusprechen.
Verfasst von
Xebia Author
Unsere Ideen
Weitere Blogs

Wo die GitHub Copilot Erweiterungspunkte die Governance brechen
Viele der jüngsten Ergänzungen des GitHub Copilot-Ökosystems bieten einen echten Mehrwert für einzelne Entwickler, erweitern aber auch die...
Rob Bos



Contact