Einführung
In der Welt der Datentechnik sind wir ständig auf der Suche nach Möglichkeiten, den Zugriff auf unsere Daten und die Arbeit mit ihnen zu vereinfachen. Drei spannende Technologien in diesem Bereich sind DuckDB, MotherDuck und Unity Catalog.
- DuckDB ist ein prozessintegriertes SQL-OLAP-Datenbankmanagementsystem. Es wurde entwickelt, um schnell, zuverlässig und einfach zu bedienen zu sein. Es wird oft als "SQLite für Analysen" bezeichnet.
- MotherDuck ist ein serverloses Data Warehouse auf der Grundlage von DuckDB. Es ermöglicht Ihnen, Daten in der Cloud und auf Ihrem lokalen Rechner abzufragen, als ob sie in einer einzigen Datenbank wären.
- Unity Catalog ist eine einheitliche Governance-Lösung für Daten und KI-Assets auf der Databricks Lakehouse-Plattform. Sie bietet eine zentrale Zugriffskontrolle, Audits, Abstammung und Datenermittlungsfunktionen für alle Databricks-Arbeitsbereiche.
In diesem Blog-Beitrag wird untersucht, wie diese Technologien miteinander verbunden werden können. Der Schwerpunkt liegt dabei auf dem Lesen von Daten aus einem DuckLake (einem von MotherDuck/DuckDB verwalteten Data Lake) mit Databricks Unity Catalog. Wir nutzen das BYO-Angebot (Bring your own) von Motherduck, mit dem Benutzer ihren eigenen Bucket für die Datenspeicherung bereitstellen können.
In diesem Blogbeitrag zeigen wir Ihnen, wie Sie mit Unity Catalog Daten aus DuckLake lesen können.
Voraussetzungen
Voraussetzungen: Ein S3-Bucket, der sowohl auf Databricks als auch auf MotherDuck gemountet ist:
- Wie Sie Ihren S3-Bucket auf Databricks mounten, erfahren Sie in dieser Databricks-Anleitung.
- Wie Sie Ihren S3-Bucket auf MotherDuck montieren, erfahren Sie in dieser MotherDuck-Anleitung.
Lesen aus DuckLake mit Unity Catalog
Zunächst erstellen wir eine neue Datenbank mit DuckLake als Datenkatalog.
-- Create a new database in ducklake
CREATE DATABASE ducklake_webinar_demo (
TYPE DUCKLAKE,
DATA_PATH 's3://motherduck-webinar-demo/ducklake_webinar_demo'
);
Als nächstes werden wir mit der TPC-H DuckDB-Erweiterung einige Daten für unsere neu erstellte Datenbank generieren:
USE memory;
CALL dbgen(sf = 0.1);
Als nächstes speichern wir die erzeugten lineitem Daten in der Datenbank:
USE ducklake_webinar_demo;
CREATE TABLE lineitem AS SELECT * FROM memory.lineitem
Da wir S3 für die Speicherung unserer Daten verwenden, können wir die im Bucket gespeicherten Parquet-Dateien sehen:
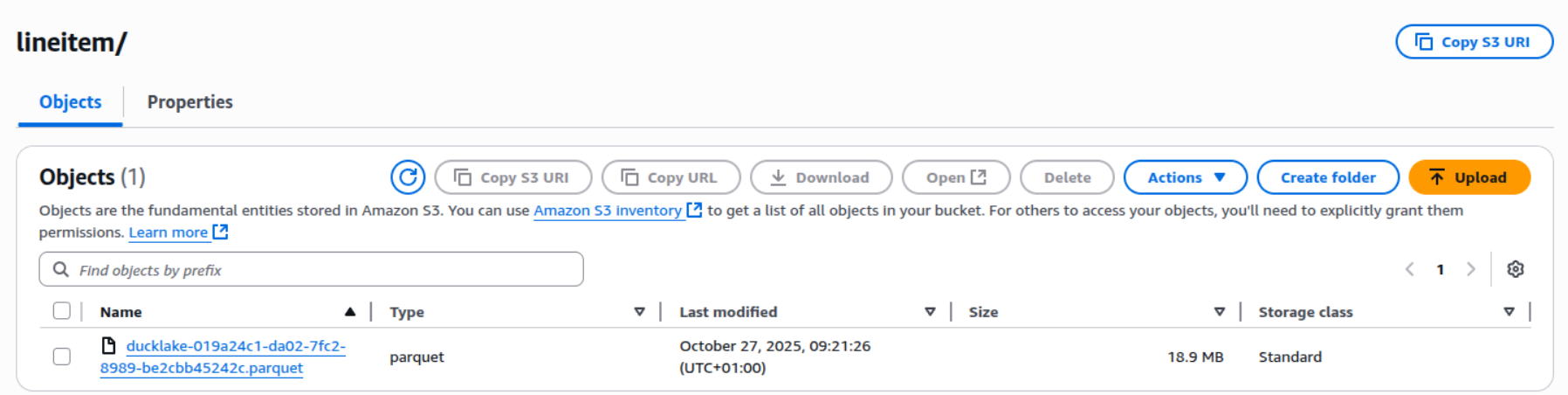
Da DuckLake nur einfaches Parquet schreibt, können wir diese Daten als externe Tabelle in Unity Catalog einhängen, indem wir den folgenden Befehl in unserer Databricks-Umgebung ausführen:
CREATE TABLE IF NOT EXISTS lineitem
USING PARQUET
LOCATION 's3://motherduck-webinar-demo/ducklake_webinar_demo/main/lineitem'
Wir sind jetzt in der Lage, die von MotherDuck in Databricks geschriebenen Daten mit Unity Catalog zu lesen:
Select count(*) from lineitem;
Allerdings gibt es bei dieser Methode ein Problem. DuckLake behandelt Löschvorgänge, indem es eine neue Parquet-"Löschdatei" mit den zu entfernenden Zeilenindizes erstellt und diese Datei dann in den Metadatentabellen registriert. Bei diesem Vorgang wird ein neuer Snapshot erstellt, und die ursprünglichen Datendateien werden nicht sofort geändert, so dass eine Zeitreise zu früheren Versionen der Tabelle möglich ist. Weitere Informationen über die Löschdatei finden Sie hier.
Wenn wir den folgenden Befehl ausführen:
-- Lets find some ids to delete
DELETE FROM ducklake_webinar_demo.main.lineitem where l_orderkey % 2 = 0;
Wir können sehen, dass die Datei im s3-Bucket gelöscht wurde:
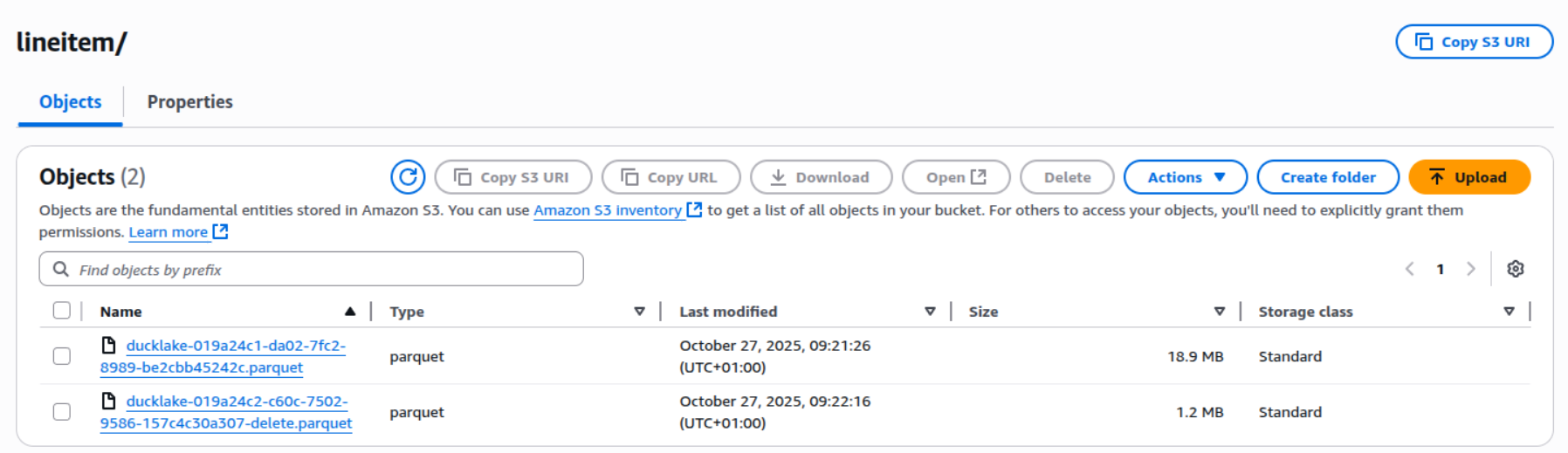
Dies stellt jedoch eine Herausforderung dar, da Unity Catalog die Löschdatei nicht berücksichtigt, wenn es die Parkettdatei liest, was dazu führt, dass die gelöschten Zeilen nicht registriert werden.
Eine schnelle Abhilfe besteht darin, die Daten in DuckLake neu zu schreiben, indem Sie die folgenden Befehle ausführen:
CALL ducklake_rewrite_data_files('ducklake_webinar_demo', delete_threshold=0.0);
CALL ducklake_expire_snapshots('ducklake_webinar_demo', older_than => now());
CALL ducklake_cleanup_old_files(
'ducklake_webinar_demo',
cleanup_all => true
);
Diese Befehle bewirken Folgendes:
- ducklake_rewrite_data_files - Damit werden Ihre Daten so umgeschrieben, dass DuckLake nicht alle Löschdateien verarbeiten muss, um eine Leseoperation über die Tabelle durchzuführen.
- ducklake_expire_snapshots - DuckLake ermöglicht Zeitreisen, indem es Snapshots aufzeichnet. Dieser Befehl lässt alle Snapshots ablaufen, so dass die zugrunde liegenden Parquet-Dateien gelöscht werden können.
- ducklake_cleanup_old_files - Bereinigt alle Dateien, die nicht Teil eines Snapshots sind oder verwaist sind.
Wenn wir nun die Daten laden, sehen wir, dass wir die richtige Menge haben. Außerdem wurden die Parquet-Dateien im S3-Bucket neu geschrieben:
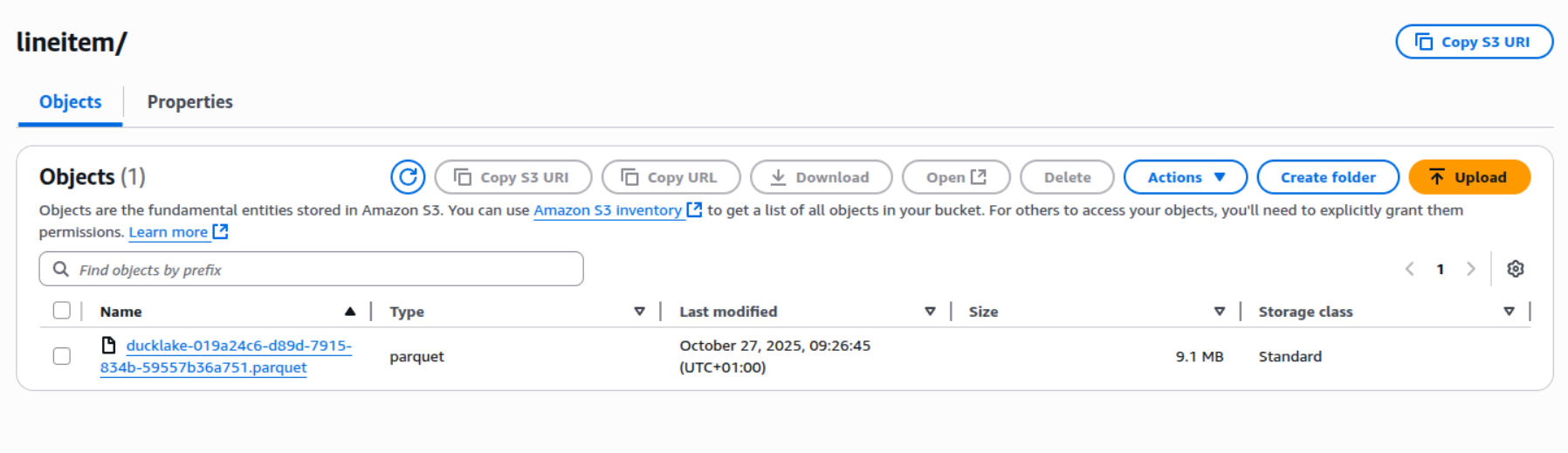
Diese Methoden könnten zu einem dbt-Post-Hook-Makro hinzugefügt werden, damit Unity Catalog die Tabellen lesen kann. Diese Methode hat jedoch auch Nachteile. Bei dieser Methode gehen alle Zeitreisefunktionen von DuckLake verloren und die Laufzeit pro dbt-Modell verlängert sich um ca. 15 Sekunden (abhängig von der Struktur und Größe Ihrer Daten).
Wenn Sie mit Spark lediglich Daten aus DuckLake lesen möchten, gibt es eine bessere Option, die auf dem DuckDB JDBC-Treiber basiert.
Verfasst von
Diederik Greveling




Contact