Blog
Schnelles Prototyping von Online-Maschinenlernen mit Divolte Collector

Es heißt, dass bei den meisten Data Science-Lösungen 80 Prozent der Arbeit auf die technische Datenaufbereitung und nur 20 Prozent auf die eigentliche Modellierung und Algorithmen entfallen. Ihre Erfahrungen können variieren. Eine weitere Beobachtung ist, dass die Entwicklung noch schwieriger wird (und die Modelle für maschinelles Lernen oft einfacher), wenn die Verarbeitung nahezu in Echtzeit erfolgen muss. Lassen Sie mich dies mit einem architektonischen Überblick über eine typische Web-Optimierungseinrichtung veranschaulichen:
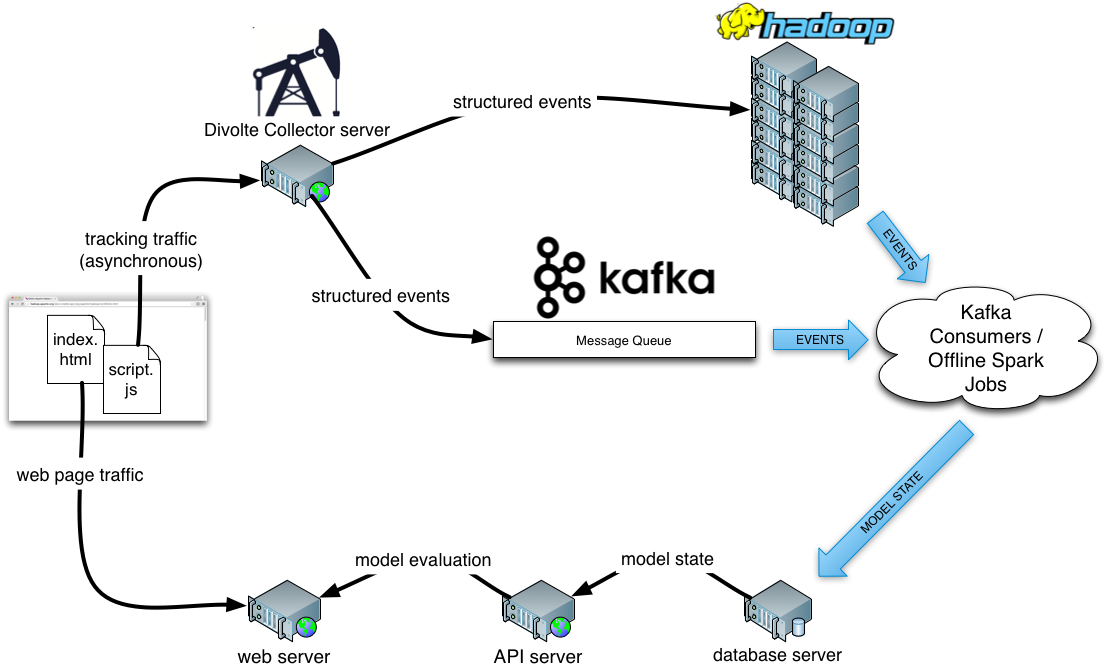
Lassen Sie uns das ein wenig aufschlüsseln:
- Divolte Collector ist eine Open-Source-Lösung, die bei GoDataDriven entwickelt wurde. Kurz gesagt, sorgt sie dafür, dass Clickstream-Ereignisse im Browser erfasst und in Avro-Datensätze übersetzt werden, die zur Offline- und Online-Verarbeitung an HDFS und Kafka gesendet werden. Es wird von einem begleitenden Stück Javascript aufgerufen, das auf der Webseite läuft, um Ereignisse auszulösen. Divolte Collector ermöglicht ein dynamisches Mapping zwischen Clickstream-Ereignissen und einem beliebigen Avro-Schema.
- Hadoop ist heutzutage mehr oder weniger de facto für die Verarbeitung großer Datenmengen geeignet. Wenn wir hier von Hadoop sprechen, meinen wir einen Cluster, auf dem HDFS und verschiedene Hadoop-Ökosystemprojekte für die Datenverarbeitung laufen, wie Hive, Impala, Spark und möglicherweise andere.
- Kafka ist ein verteiltes Nachrichtensystem mit hohem Durchsatz. Kafka hat Produzenten, die Nachrichten erstellen, und Konsumenten, die Nachrichten als Input für die Online-Datenverarbeitung verwenden. Divolte Collector ist ein Kafka-Produzent und die Konsumenten führen unsere Modelle für maschinelles Lernen auf Streaming-Daten aus.
- Die Verarbeitung von Clickstream-Ereignissen erfolgt in der Regel sowohl offline in der Stapelverarbeitung als auch online in nahezu Echtzeit. Die Batch-Verarbeitung kann zum Beispiel mit Spark-Jobs erfolgen, während der Online-Teil typischerweise Kafka-Konsumenten sind.
- Modelle für maschinelles Lernen haben in der Regel einen gewissen Modellstatus, der persistiert werden muss und für die Modellauswertung mit sehr geringer Latenz zur Verfügung stehen muss. Normalerweise verwenden wir hier eine Art In-Memory-Datenbank, wie z.B. Redis. Es können auch andere Datenbanken verwendet werden, da die meisten Datenbanken Zwischenspeicher verwenden und die Daten oft effektiv im Speicher liegen.
- Der API-Server kümmert sich um die eigentliche Auswertung des trainierten Modells anhand des gespeicherten Modellstatus und der vorliegenden Beispieleingabe.
- Der Webserver fordert eine Modellbewertung vom API-Server an und verwendet diese, um die Antwort an den Client zu rendern.
Das sind eine Menge beweglicher Teile! Wenn wir all dies aufbauen müssen, um etwas scheinbar Einfaches zu tun, wie z.B. eine Zufallsstichprobe aus einer Reihe von parametrisierten Verteilungen zu ziehen (d.h. eine mehrarmige Bandit-Optimierung) oder eine Klassifizierung mit einem vorab trainierten Klassifikator durchzuführen, werden wir kaum je etwas zustande bringen. Aus diesem Grund konzentrieren wir uns bei GoDataDriven darauf, diese Art von Infrastruktur einmal einzurichten und versuchen, sie generisch genug zu machen, um verschiedene Arten von Anwendungen darauf zu implementieren. Das ist auch der Grund, warum wir in den Aufbau von Divolte Collector investieren. Er löst ein sehr wichtiges technisches Problem für Unternehmen, die eine große Anzahl von Websites betreiben.
In diesem Beitrag werden wir einen Blick auf die Implementierung eines Prototyps für eine mehrarmige Bandit-Optimierung werfen, die diesen Stack mit minimalem Python-Code und einer Redis-Datenbank für den Modellstatus verwendet. Wir werden Divolte Collector verwenden, um uns nahezu in Echtzeit mit Clickstream-Daten zu versorgen.
Das Problem
Bei GoDataDriven verwenden wir intern eine kleine gefälschte Webshop-Anwendung für Demozwecke. Wir nennen sie den Shop für Menschen. Im Shop für Menschen können Sie Fotos "kaufen", für die Sie "bezahlen", indem Sie eine Reihe von CAPTCHAs lösen; daher der Shop für Menschen, nicht für Bots. Der Shop liefert Ihnen die Fotos, indem er Ihnen einfach die direkten Links zu den Quellen zur Verfügung stellt, nachdem Sie die Kaufabwicklung abgeschlossen haben (was ziemlich mühsam sein kann, da CAPTCHAs involviert sind). Die Fotos im Shop stammen von Flickr. Nur um das klarzustellen: Nein, wir verkaufen nicht die Fotos anderer Leute im Internet; wir verwenden nur einige Fotos für eine interne Demo-Anwendung. Alle Fotos werden so gefiltert, dass sie über eine kommerziell freundliche Creative Commons-Lizenz verfügen und eine korrekte Namensnennung erfolgt.
Für Menschen. Keine Bots erlaubt.
Auf der Startseite des Webshops möchten wir ein bestimmtes Bild anzeigen. Anstatt einfach ein zufälliges Bild aus dem Katalog auszuwählen oder dieses Bild von Hand auszuwählen, möchten wir das Bild mit Hilfe eines beliebten Bayes'schen Ansatzes zur mehrarmigen Banditen-Optimierung auswählen, der auch Bayes'sche Banditen genannt wird.
Das Modell: Bayes'sche Banditen für die Fotoauswahl
Wir können den Bayes'schen Bandit-Ansatz verwenden, um ein Foto aus einer Reihe von Fotos für die Anzeige auf der Homepage auszuwählen. Der Bayes'sche Bandit-Algorithmus funktioniert, indem er die Prioritäten über die Klickrate für jeden Artikel kontinuierlich aktualisiert und dann eine Stichprobe aus diesem Satz von Prioritätsverteilungen zieht und das Foto anzeigt, für das der Stichprobenwert am größten ist. Konkret bedeutet dies, dass wir jedes Mal, wenn wir die Homepage mit einem der Bilder aufrufen, einen Impressionszähler für dieses Bild inkrementieren. Dann prüfen wir, ob dieses Bild angeklickt wurde. Wenn ja, erhöhen wir den Klickzähler für dieses Bild. Wenn wir ein Bild für die Startseite auswählen möchten, ziehen wir für jedes Bild eine Stichprobe aus einer Beta-Verteilung mit den Parametern alpha gleich der Anzahl der Click-Throughs für dieses Bild und beta gleich der Anzahl, wie oft wir dieses Bild bisher gezeigt haben. Das Bild mit dem größten Stichprobenwert gewinnt. Anschauliche Erklärungen zu diesem Konzept finden Sie hier und hier.
Da wir viele Bilder in unserem Katalog haben und möglicherweise nicht genug Besucher bekommen, um herauszufinden, welches der Bilder das beste ist, möchten wir eine begrenzte Anzahl von Bildern für die Optimierung verwenden. Außerdem möchten wir diese Bilder von Zeit zu Zeit austauschen, um den gesamten Katalog weiter zu erforschen. Zu diesem Zweck verwenden wir die folgende Methode:
- Wählen Sie eine zufällige Menge von n Bildern.
- Lernen Sie die Verteilungen für diese Bilder mit Hilfe der Bayes'schen Banditenmethode.
- Nach X Experimenten:
- Wählen Sie die obere Hälfte der aktuellen Bildermenge durch Stichproben aus den gelernten Verteilungen aus.
- Wählen Sie n / 2 neue Bilder aus dem Katalog nach dem Zufallsprinzip aus.
- Erstellen Sie einen neuen Satz von Bildern, indem Sie die obere Hälfte aus der Stichprobe und die neu ausgewählten Zufallsbilder verwenden.
- Setzen Sie alle Verteilungen auf alpha=1, beta=1 zurück.
- Gehen Sie zu 2.
Die Idee dahinter ist, dass wir die Bilder mit der besten Leistung behalten und die Bilder mit der schlechtesten Leistung verwerfen, um den Katalog weiter zu durchsuchen. Nach der Auffrischung der Bildermenge weisen wir allen Bildern wieder gleiche Prioritäten zu. Dieses Modell sollte einfach genug sein, um es in Python zu implementieren. Idealerweise sollte es etwa einen Tag Arbeit in Anspruch nehmen, um es zu erstellen, zu testen und in Produktion zu bringen.
Schritt 1: Prototyp der Benutzeroberfläche
Wir müssen also ein Bild auf der Homepage platzieren, das anklickbar ist. Außerdem müssen wir sicherstellen, dass wir den Klick auf dieses Bild verfolgen können. Um einen Prototyp der Benutzeroberfläche zu erstellen und die richtigen Ereignisse zu erfassen, fangen wir damit an, ein festes Bild auf die Homepage zu stellen.
Unser Shop ist in Python geschrieben und verwendet Tornado. Die Metadaten der Bilder werden in ElasticSearch gespeichert, das wir mit einem kleinen, in Java geschriebenen Dienst abstrahieren. Das Backend des Shops ist für unseren Prototyp nicht wirklich wichtig. Es sollte im Allgemeinen einfach genug sein, ein beliebiges Produkt aus dem Katalog in eine Homepage einzubinden. In unserem Shop sieht der Handler-Code dafür so aus:
Klasse HomepageHandler(ShopHandler): @coroutine def erhalten.(selbst): # Hardcodierte ID für eine hübsche Blume. # Später wird diese ID durch die Banditen-Optmierung bestimmt. Gewinner = '15442023790' # Übernehmen Sie die Artikeldetails aus unserem Katalogdienst. top_item = Ertrag selbst._get_json('Katalog/Einzelteil/%s' % Gewinner) # Rendering der Homepage selbst.rendern( 'index.html', top_item=top_item)
Die zugehörige Vorlage zum Rendern der Homepage enthält dies:
div Klasse="col-md-6">
h4>Beste Wahl:h4>
p>
a href="/product/{{ top_item['id'] }}/#/?source=top_pick">
img Klasse="img-responsive img-rounded" src="{{ top_item['variants']['Medium']['img_source'] }}">
Skript>divolte.Signal('Eindruck', { Quelle: 'top_pick', productId: '{{ top_item['id'] }}'})Skript>
a>
p>
p>
Foto von {{ top_item['owner']['real_name'] oder top_item['owner']['user_name']}}
p>
div>
Hier ist die neue Homepage:
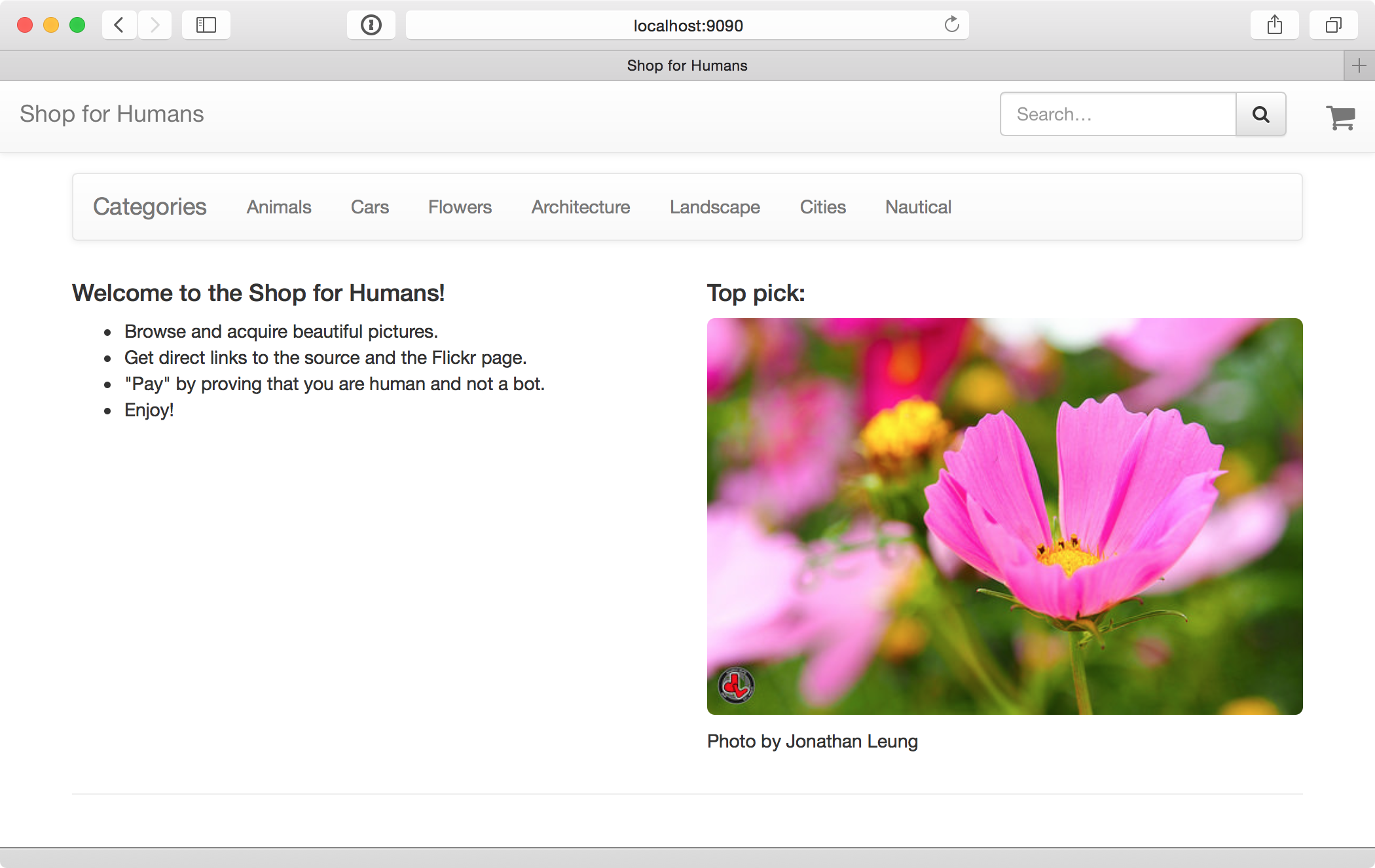
Shop for Humans, für Sie von Banditen gebracht. Foto von Flickr-Benutzer Jonathan Leung.
Beachten Sie, dass wir die href URL mit diesem kleinen Suffix abschließen: #/?source=top_pick. Außerdem senden wir ein benutzerdefiniertes Divolte Collector-Ereignis, um zu signalisieren, dass eine Impression des Bildes serviert wurde. Damit erfassen wir die Ereignisse Impression und Click-Through. Wir verwenden ein URL-Fragment (den Teil nach dem #), so dass wir den serverseitigen Code nicht mit diesem Tracking belästigen. Stattdessen erfassen wir das URL-Fragment in der Divolte Collector-Zuordnung und füllen ein spezielles Feld in unseren Ereignisdatensätzen, wenn es vorhanden ist. Dasselbe gilt für das benutzerdefinierte Impressionsereignis. In Divolte Collector sind Ereignisdatensätze Avro-Datensätze, die aus den eingehenden Anfragen entsprechend einem bestimmten Mapping, das Sie in einer Groovy-basierten DSL angeben, ausgefüllt werden. Weitere Einzelheiten hierzu finden Sie in der Mapping-Dokumentation (oder in unserem Leitfaden Erste Schritte).
In unserem Ereignis-Datensatzschema fügen wir das folgende Feld hinzu, um die Quelle eines Klicks zu erfassen:
{ "Name": "Quelle", "Typ": ["null", "string"], "Standard": null }
Anschließend müssen wir Divolte Collector über dieses Feld informieren und wie es ausgefüllt werden soll. In der Zuordnung werden wir das URL-Fragment verwenden, um den Quellparameter zu analysieren. Beachten Sie, dass das Fragment, das wir hinzufügen, die URL-Syntax für die Angabe dieses Feldes verwendet; die Quelle ist lediglich ein Abfrageparameter. Hier ist das Mapping, das erforderlich ist, um diese Daten in unsere Datensätze zu bekommen:
def StandortUri = parsen Standort() zu uri wenn eventType().equalTo('pageView') anwenden. { def fragmentUri = parsen StandortUri.rawFragment() zu uri Karte fragmentUri.Abfrage().Wert('Quelle') auf 'Quelle' } wenn eventType().equalTo('Abdruck') anwenden. { Karte eventParameter().Wert('productId') auf 'productId' Karte eventParameter().Wert('Quelle') auf 'Quelle' }
Das war's. Die Datenerfassung ist eingerichtet. Wir können jetzt mit dem Lernen beginnenâ¦
Schritt 2: Erstellen Sie den Kafka-Konsumenten zur Aktualisierung des Modellstatus
Wir werden einen Kafka-Konsumenten in Python erstellen, der die Ereignisse konsumiert und unseren Modellstatus aktualisiert. Der Modellstatus besteht aus einer Reihe von Zählern für Klicks und Impressionen der einzelnen Artikel. Außerdem aktualisieren wir einen globalen Zähler für die Anzahl der bisher durchgeführten Experimente, damit wir wissen, wann wir die Artikelmenge aktualisieren müssen.
Modellzustand in Redis
Redis ist mehr als nur ein Key-Value-Speicher. Es ermöglicht das Speichern und Ändern verschiedener Datenstrukturen, die oft nützlich sind, um verschiedene Arten von Interaktionen zu verfolgen. In unserem Fall werden wir eine einzelne Hash-Datenstruktur verwenden, die im Grunde eine in Redis gespeicherte Hash-Map ist. Unser Hash wird wie folgt aussehen:
{ 'c|14502147379': '2', 'c|15106342717': '2', 'c|15624953471': '1', 'c|9609633287': '1', 'i|14502147379': '2', 'i|15106342717': '3', 'i|15624953471': '2', 'i|9609633287': '3' }
Hier sind die Schlüssel im Hash ein spezielles Präfix, gefolgt von einer Artikel-ID. Das Präfix dient dazu, zwischen Klicks und Impressionen zu unterscheiden; die Artikel-ID identifiziert das Bild in der Menge. Immer wenn wir ein Bild auf der Homepage anbieten, möchten wir den Impressionszähler für dieses Bild erhöhen und wenn ein Bild auf der Homepage angeklickt wird, möchten wir den Klickzähler für dieses Bild erhöhen. In Redis verwenden wir den Befehl HINCRBY, um dies zu erreichen. Wenn wir eines der Bilder auswählen müssen, können wir mit dem Befehl HGETALL den gesamten Satz an Zählern aus Redis abrufen. Ein Vorteil dieses Layouts in Redis ist, dass wir den gesamten erforderlichen Modellstatus für die Auswertung in einem einzigen Round-Trip abrufen können.
Den Verbraucher schaffen
Die Erstellung eines Kafka-Konsumenten in Python ist ziemlich einfach und erfordert erfreulich wenig Boilerplate-Code. Wir verwenden dafür das Paket kafka-python. Es ist möglich, mehrere Kafka-Konsumenten laufen zu lassen und mehrere Prozesse zu starten, um mehrere Kerne auf einem oder mehreren Rechnern zu nutzen. Der Code hierfür unterscheidet sich nur unwesentlich von der Single-Thread-Version unten.
Für den Zugriff auf Redis verwenden wir den empfohlenen Redis-Client für Python. Da die von Divolte Collector erstellten Nachrichten mit Avro serialisiert werden, verwenden wir auch das Python-Paket von Avro zur Deserialisierung der Datensätze.
Hier ist der Kern unseres Verbrauchercodes:
def start_verbraucher(args): # Laden Sie das für die Serialisierung verwendete Avro-Schema. Schema = avro.Schema.Parsen(öffnen Sie(args.Schema).lesen()) # Erstellen Sie einen Kafka-Konsumenten und einen Avro-Leser. Beachten Sie, dass # es ist trivialerweise möglich, einen Multiprozess zu erstellen # Verbraucher. Verbraucher = KafkaConsumer(args.Thema, client_id=args.Kunde, gruppe_id=args.Gruppe, metadaten_makler_liste=args.Makler) Leser = avro.io.DatumReader(Schema) # Nachrichten verbrauchen. für Nachricht in Verbraucher: handle_event(Nachricht, Leser) def ascii_bytes(id): return Bytes(id, 'us-ascii') def handle_event(Nachricht, Leser): # Dekodieren Sie Avro-Bytes in ein Python-Wörterbuch. nachricht_bytes = io.BytesIO(Nachricht.Wert) Decoder = avro.io.BinaryDecoder(nachricht_bytes) Veranstaltung = Leser.lesen(Decoder) # Ereignislogik. wenn 'top_pick' == Veranstaltung['Quelle'] und 'pageView' == Veranstaltung['eventType']: # Registrieren Sie einen Klick. redis_client.Hincrby( ITEM_HASH_KEY, CLICK_KEY_PREFIX + ascii_bytes(Veranstaltung['productId']), 1) elif 'top_pick' == Veranstaltung['Quelle'] und 'Abdruck' == Veranstaltung['eventType']: # Registrieren Sie einen Eindruck und erhöhen Sie die Anzahl der Experimente. p = redis_client.Pipeline() p.incr(EXPERIMENT_COUNT_KEY) p.Hincrby( ITEM_HASH_KEY, IMPRESSUM_SCHLÜSSEL_PRÄFIX + ascii_bytes(Veranstaltung['productId']), 1) experiment_count, ingnoriert = p.ausführen.() wenn experiment_count == REFRESH_INTERVAL: refresh_items()
Der nächste interessante Schritt ist das Aktualisieren des Objektsatzes. Hier müssen wir etwas vorsichtig sein, da wir den gesamten Status in Redis zurücksetzen und einen neuen Satz von Objekten erstellen werden. Da möglicherweise mehrere Clients gleichzeitig auf Redis zugreifen, müssen wir sicherstellen, dass wir die Schreiboperationen in einer Transaktion durchführen. Glücklicherweise unterstützt Redis dies als Teil seiner Anfrage-Pipelining-Unterstützung. Um Stichproben aus Zufallsverteilungen zu ziehen, verwenden wir Numpy.
def refresh_items(): # Holen Sie den aktuellen Modellstatus. Wir konvertieren alles in str. current_item_dict = redis_client.hgetall(ITEM_HASH_KEY) aktuelle_Artikel = numpy.einzigartig([k[2:] für k in current_item_dict.Tasten()]) # Holen Sie zufällige Elemente aus ElasticSearch. Beachten Sie, dass wir mehr abrufen, als wir benötigen, # aber wir filtern die Objekte heraus, die bereits in der aktuellen Menge vorhanden sind und kürzen sie ab. # die Liste anschließend auf die gewünschte Größe. zufällige_Einträge = [ ascii_bytes(Artikel) für Artikel in zufälliges_Element_setzen(NUM_ITEMS + NUM_ITEMS - len(aktuelle_Artikel) // 2) wenn nicht Artikel in aktuelle_Artikel][:NUM_ITEMS - len(aktuelle_Artikel) // 2] # Ziehen Sie Zufallsstichproben. Proben = [ numpy.zufällig.beta( int(current_item_dict[CLICK_KEY_PREFIX + Artikel]), int(current_item_dict[IMPRESSUM_SCHLÜSSEL_PRÄFIX + Artikel])) für Artikel in aktuelle_Artikel] # Wählen Sie die obere Hälfte nach Probenwerten aus. current_items ist praktisch # ein Numpy-Array hier. Überlebende = aktuelle_Artikel[numpy.argsort(Proben)[len(aktuelle_Artikel) // 2:]] # Der neue Gegenstandssatz besteht aus den Überlebenden und den zufälligen Gegenständen. neue_Artikel = numpy.konkatenieren([Überlebende, zufällige_Einträge]) # Aktualisieren Sie den Status des Modells, um das neue Artikelset zu berücksichtigen. Dieser Vorgang ist atomar # in Redis. p = redis_client.Pipeline(Transaktion=True) p.einstellen.(EXPERIMENT_COUNT_KEY, 1) p.löschen(ITEM_HASH_KEY) für Artikel in neue_Artikel: p.Hincrby(ITEM_HASH_KEY, CLICK_KEY_PREFIX + Artikel, 1) p.Hincrby(ITEM_HASH_KEY, IMPRESSUM_SCHLÜSSEL_PRÄFIX + Artikel, 1) p.ausführen.()
Und falls Sie sich fragen, wie Sie einen zufälligen Satz von Dokumenten aus ElasticSearch abrufen können, hier ist die Anleitung. Wir haben uns dafür entschieden, nicht den offiziellen ElasticSearch-Client zu verwenden, sondern nutzen einfach das Python-Paket requests, um den HTTP-Aufruf selbst durchzuführen. Der offizielle Client kann jedoch einige Vorteile für komplexere Anwendungsfälle bieten.
def zufälliges_Element_setzen(zählen): Abfrage = { "Abfrage": { "funktions_score" : { "Abfrage" : { "match_all": {} }, "random_score" : {} } }, "Größe": zählen } Ergebnis = Anfragen.erhalten.('http://%s:%s/catalog/_search' % (es_host, es_port), Daten=json.dumps(Abfrage)) return [schlagen Sie['_Quelle'] für schlagen Sie in Ergebnis.json()['Treffer']['Treffer']]
Das ist alles, was wir auf der Kafka-Konsumentenseite brauchen. Dieser Code konsumiert Klick-Ereignisse und aktualisiert unseren erforderlichen Modellstatus in Redis. Es gibt einige minimale Boilerplates für Dinge wie das Parsen von Argumenten. Das vollständige Listing für den Kafka-Konsumenten finden Sie hier: consumer.py.
Schritt 3: Erstellen Sie die API zur Auswertung des Modells
Um die API für unser Modell zu erstellen, müssen wir den derzeit aktiven Artikelsatz aus Redis und alle zugehörigen Klickzahlen abrufen. Dann ziehen wir eine Stichprobe aus den Verteilungen und geben das Element zurück, das den größten Wert aufweist.
Ein wichtiger Aspekt dieser gesamten Einrichtung ist, dass der API-Code vollständig vom Lerncode entkoppelt ist; Modelltraining und Modellauswertung sind getrennt. Durch diese Trennung können wir sie unabhängig voneinander skalieren. Außerdem können wir das Modelltraining optimieren und aktualisieren, ohne das System aus der Sicht des Benutzers vom Netz zu nehmen.
Für die Erstellung dieser API verwenden wir erneut Tornado. Hier ist der Handler-Code für unsere Bandit-API:
Klasse BanditHandler(Web.RequestHandler): redis_client = Keine def initialisieren(selbst, redis_client): selbst.redis_client = redis_client @gen.coroutine def erhalten.(selbst): # Holen Sie den Modellstatus. item_dict = Ertrag gen.Aufgabe(selbst.redis_client.hgetall, ITEM_HASH_KEY) Artikel = numpy.einzigartig([k[2:] für k in item_dict.Tasten()]) # Ziehen Sie Zufallsstichproben. Proben = [ numpy.zufällig.beta( int(item_dict[CLICK_KEY_PREFIX + Artikel]), int(item_dict[IMPRESSUM_SCHLÜSSEL_PRÄFIX + Artikel])) für Artikel in Artikel] # Wählen Sie den Artikel mit dem größten Probenwert. Gewinner = Artikel[numpy.argmax(Proben)] selbst.Schreiben Sie(Gewinner)
Die Anfrage an http://localhost:8989/item liefert uns dies:
HTTP/1.1 200 OK Inhalt-Länge: 11 Inhalt-Typ: text/html; charset=UTF-8 Datum: Tue, 07 Apr 2015 11:37:50 GMT Server: TornadoServer/4.1 14502147379
Eine weitere gute Eigenschaft der Entkopplung der Modellaktualisierungen von der Serving-API ist, dass der Aufruf der API die Eindruckzähler nicht erhöht. Wir können den Endpunkt zu Testzwecken so oft aufrufen, wie wir wollen, ohne den Feedback-Zyklus zu beeinflussen.
Schritt 4: Integrieren
Als Nächstes verwenden wir im Code des Webshops den asynchronen HTTP-Client von Tornado, um jedes Mal, wenn wir die Homepage aufrufen, einen Artikel abzurufen.
Klasse HomepageHandler(ShopHandler): @coroutine def erhalten.(selbst): http = AsyncHTTPClient() anfordern. = HTTPRequest(url='http://localhost:8989/item', Methode='GET') Antwort = Ertrag http.abrufen.(anfordern.) Gewinner = json_decode(Antwort.Körper) top_item = Ertrag selbst._get_json('Katalog/Einzelteil/%s' % Gewinner) selbst.rendern( 'index.html', top_item=top_item)
Fazit
Diese Lösung besteht aus etwa 200 Zeilen Python-Code, einschließlich Boilerplate für das Parsen von Argumenten, das Einrichten des Tornado-Servers und der IO-Schleife sowie das Einrichten des Kafka-Verbrauchers. Die gesamte technische Arbeit, die dahinter steckt, ist jedoch um Größenordnungen größer. Dazu gehören die Einrichtung von Kafka-Clustern, die Verwaltung von Webservern, Load Balancern, Divolte Collector Servern, Hadoop-Clustern, ElasticSearch und vieles mehr. Wenn jedoch all diese beweglichen Teile vorhanden sind, ist es relativ einfach, schnell einen Prototyp einer Online-Lösung für maschinelles Lernen mit einer API zu erstellen. So können wir uns auf den Modellcode und die Benutzererfahrung konzentrieren, anstatt alle Grundlagen für jede einzelne Lösung neu zu erfinden. Wenn Sie sich im Vorfeld Gedanken über die Datenerfassung und die Verfügbarkeit von Daten machen, gewinnen Sie viel technische Flexibilität und damit eine bessere Position, um Technologielösungen dorthin zu bringen, wo das Geschäft ist. Wenn Sie Websysteme entwickeln, sollten Sie die Datenerfassung nicht auf die lange Bank schieben.
Divolte Collector ist in diesem Szenario sehr hilfreich, da es uns in vielen Fällen ermöglicht, zusätzliche Daten zu sammeln und Feedback zu geben, ohne in den serverseitigen Code einzugreifen oder komplexe Protokolldateien zu analysieren.
Verbesserungen
Das Modell, das wir in diesem Beispiel verwenden, ist absichtlich einfach. Hier sind einige Überlegungen, wie Sie es weiter verbessern können:
- Anstatt alle Prioritäten zurückzusetzen, wenn wir die Menge der Elemente ändern, könnten wir die gewonnenen Erkenntnisse nutzen, um unsere Prioritäten anzupassen. Außerdem könnten wir für die zufälligen Bilder, die wir dem Satz hinzufügen, die Prioritäten auf die historischen Benutzerinteraktionen mit diesen Elementen auf anderen Seiten stützen. Dazu müssten wir wahrscheinlich einen Offline-Job erstellen, der historische Clickstream-Daten verarbeitet, um die Prioritäten zu ermitteln. Dazu könnten wir z.B. Apache Spark-Jobs für die von Divolte Collector erzeugten Daten verwenden (da es sich um Avro handelt, funktioniert dies direkt nach dem Auspacken). Da unser Modelltraining und die Modellauswertung vollständig voneinander getrennt sind, wäre dies nicht einmal eine sehr komplexe Änderung.
- Für Artikel, die neu im Katalog sind oder nicht sehr beliebt sind, gibt es keine oder nur wenige Daten über historische Benutzerinteraktionen. Dennoch können wir bei diesen Artikeln versuchen, die Ähnlichkeit des Artikels mit anderen Artikeln, für die wir Daten haben, als Grundlage für die Prioritäten zu verwenden. Wir können Bild-Metadaten verwenden oder versuchen, visuelle Merkmale für die Bildähnlichkeit zu extrahieren oder wir können versuchen, latente Merkmale für Bilder auf der Grundlage des historischen Clickstreams zu lernen.
- Unsere Banditen betrachten alle Besucher als gleich. Es gibt einige Untersuchungen zur Kontextualisierung von Banditen, um die Entscheidungen besser auf bestimmte Zielgruppen zuzuschneiden.
Natürlich überlasse ich das dem Leser als Übungâ¦
F.A.Q.
F: Das ist ein schöner Prototyp, aber würden Sie ihn tatsächlich in der Produktion einsetzen?
Mit einigen kleinen Ergänzungen, ja. Der Code führt keine Fehlerbehandlung durch. Normalerweise würden wir diese Dinge in eine Art Prozessüberwachungsprogramm (z.B. supervisord oder monit) verpacken, um uns zu warnen und den Prozess neu zu starten, wenn er abbricht.
Außerdem müssen wir dafür sorgen, dass das Frontend damit zurechtkommt, wenn die Bandit-API aus irgendeinem Grund nicht verfügbar ist, und vorzugsweise eine andere Seite ohne die Top-Auswahl anzeigen.
Allerdings haben wir sehr oft kurze Einsätze von Python-Code wie diesem in der Produktion, um zu sehen, ob etwas funktioniert. Sie wollen so schnell wie möglich zum Prototyp kommen, damit Sie die Dinge an tatsächlichen Benutzern testen können. Wir haben viel Aufwand in den Aufbau einer Infrastruktur und von Datenpipelines gesteckt, die es uns ermöglichen, diese Prototypen sehr schnell und zuverlässig zu erstellen. Es wäre also eine Verschwendung, diese Gelegenheit nicht zu nutzen.
F: Redis-Anfragen, Python, HTTP. Wie langsam ist das Ding?
Nicht wirklich. Computer sind schnell und billig. Bei vielen Problemen kommt es nicht darauf an, wie effizient Sie sie einsetzen, sondern wie effektiv Sie sie nutzen.
Um eine Art Benchmark zu erhalten, lassen wir den gesamten Shop-Stack auf einer virtuellen Maschine auf meinem Laptop laufen. Dazu gehören: Java-basierter Dienst, ElasticSearch, Redis, Kafka, Zookeeper, Divolte Collector, Kafka-Consumer und der Bandit-Dienst. Dann lassen wir ApacheBench gegen ein paar Dinge laufen. Nachfolgend sehen Sie die Ausgabe für den Dienst. Beachten Sie, dass es sich hier um einen internen Dienst handelt, der mit aktiviertem Keep-alive und einer Gleichzeitigkeit von nur 8 Benutzern ausgeführt wird und somit recht repräsentativ ist. Beachten Sie auch, dass die von ApacheBench gemeldeten Fehler darauf zurückzuführen sind, dass der Dienst erwartet, dass alle Anfragen genau denselben Inhalt zurückgeben, was offensichtlich nicht der Fall ist; es gibt keine echten Fehler.
[root@localhost ~]# ab -k -c8 -n10000 http://127.0.0.1:8989/item Dies ist ApacheBench, Version 2.3 Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Lizenziert an The Apache Software Foundation, http://www.apache.org/ Benchmarking 127.0.0.1 (haben Sie Geduld) Erledigte 1000 Anfragen Erledigte 2000 Anfragen Erledigte 3000 Anfragen Erledigte 4000 Anfragen Erledigte 5000 Anfragen Erledigte 6000 Anfragen Erledigte 7000 Anfragen Erledigte 8000 Anfragen Erledigte 9000 Anfragen Erledigte 10000 Anfragen Erledigte 10000 Anfragen Server-Software: TornadoServer/4.1 Server-Hostname: 127.0.0.1 Server Anschluss: 8989 Dokument Pfad: /item Dokument Länge: 11 Bytes Gleichzeitigkeitsgrad: 8 Für die Tests benötigte Zeit: 6.306 Sekunden Vollständige Anfragen: 10000 Fehlgeschlagene Anfragen: 3544 (Verbinden: 0, Empfangen: 0, Länge: 3544, Ausnahmen: 0) Schreibfehler: 0 Keep-Alive-Anfragen: 10000 Insgesamt übertragen: 2276456 Bytes HTML übertragen: 106456 bytes Anfragen pro Sekunde: 1585.78 [#/sec] (Durchschnitt) Zeit pro Anfrage: 5.045 [ms] (Durchschnitt) Zeit pro Anfrage: 0.631 [ms] (Mittelwert, über alle gleichzeitigen Anfragen) Übertragungsrate: 352.54 [Kbytes/sec] empfangen Verbindungszeiten (ms) min Mittelwert[+/-sd] Median max Verbinden: 0 0 0.0 0 0 Verarbeitung: 2 5 0.3 5 8 Warten: 2 5 0.3 5 8 Insgesamt: 2 5 0.3 5 8 Prozentsatz der Anfragen, die innerhalb einer bestimmten Zeit (ms) bearbeitet werden 50% 5 66% 5 75% 5 80% 5 90% 5 95% 6 98% 6 99% 6 100% 8 (längste Anfrage)
Unsere Ideen
Weitere Blogs




Contact