
Quartile Solver: Teil II
Im ersten Teil dieser dreiteiligen Serie haben wir das englische Wörterbuch für einen Quartiles Solver entwickelt und einige Benchmarks für die Deserialisierungsleistung erstellt. In diesem Beitrag, dem zweiten Teil der dreiteiligen Serie, entwerfen und entwickeln wir den Solver selbst. Vielleicht möchten Sie sich das Projekt an verschiedenen Punkten unserer Reise ansehen.
Designüberlegungen für den Solver
Mit einem schnellen Wörterbuch, das sich für die Präfix-Suche eignet, können wir uns überlegen, was wir von der Anwendung als Ganzes erwarten:
- Die Anwendung wird eine textbasierte Benutzeroberfläche (TUI) sein , die auf einem einzigen Thread läuft.
- Ein gutes User Experience (UX)-Design erfordert, dass die Benutzeroberfläche (UI) jederzeit auf den Benutzer eingeht.
- Außerdem erfordert gutes UX-Design, dass die laufenden Berechnungen in irgendeiner Weise Fortschritte zeigen.
Eine kurze, angenehme Liste, finden Sie nicht auch? Da der Solver das Herz und die Seele dieser Anwendung ist, stellt sich die Frage, wie diese Ziele für das Anwendungsdesign uns bei der Festlegung der Ziele für den Solver leiten können.
- Erinnern wir uns an die obere Grenze, die wir in Teil I berechnet haben, so gibt es
123520mögliche Permutationen des Brettes, die wohlgeformten Quartilen entsprechen. Das ist möglicherweise zu viel Arbeit, um das Ziel Nr. 2 des Anwendungsdesigns zu erfüllen (die Benutzeroberfläche muss reaktionsfähig bleiben). Dies impliziert, dass der Solver unterbrechbar sein sollte. - Aber der Solver muss so lange laufen, bis er alle Wörter auf dem Brett gefunden hat, was bedeutet, dass der Solver wiederaufnehmbar sein muss. Unterbrechbar und fortsetzbar gehen Hand in Hand - es ist keine Unterbrechung, wenn Sie einen Algorithmus nicht fortsetzen, es ist nur eine Unterbrechung!
- Wie wir gerade erwähnt haben, sollte der Solver jedes Wort in der Schnittmenge zwischen dem Spielbrett und dem Wörterbuch finden, er sollte also erschöpfend sein.
- Vielleicht ist es offensichtlich, aber der Solver sollte für jede mögliche Eingabe beendet werden. Wir werden weiter unten sehen, dass es viele Gelegenheiten gibt, an dieser Aufgabe zu scheitern.
- Der Solver sollte keine totale Blackbox sein. Er sollte informativ sein und seine Entdeckungen an die Benutzeroberfläche weitergeben. Dies entspricht dem Ziel Nr. 3 des Anwendungsdesigns (der Fortschritt der Berechnungen sollte angezeigt werden).
- Wir wollen die gesamte Anwendung auf einem einzigen Thread laufen lassen und es wird ein Benutzer auf eine Lösung warten, also sollte der Solver schnell sein. Die Fertigstellung in Hunderten von Millisekunden sollte in der Fleischzeit schnell genug sein.
- Um schnell zu sein, sollte der Solver effizient sein und jede Permutation nur ein einziges Mal verarbeiten.
- Und schließlich möchten wir frei entscheiden können, wie wir Tests und Benchmarks für unseren Solver schreiben, also sollte der Solver deterministisch sein. Bei gleichem Board und gleichem Wörterbuch sollte der Solver jedes Mal, wenn er ausgeführt wird, die gleichen Schritte in der gleichen Reihenfolge ausführen, abgesehen von einer gewissen Varianz bei den Zeitangaben. Er sollte zumindest die gleichen Permutationen in der gleichen Reihenfolge untersuchen, auch wenn er nicht zu den gleichen Zeiten auf Unterbrechungen stößt.
Puh, das hört sich nach einer Menge von Designzielen an. Und das ist es auch, aber mit Sorgfalt und Gerissenheit sind sie gleichzeitig erreichbar.
Erkundung des Zustandsraums
Um einen Algorithmus fortzusetzen, benötigen wir eine Art Fortsetzung: einen Schnappschuss des kompletten Maschinenzustands, der erforderlich ist, um die Aktivität des Algorithmus an einem unterbrechbaren Kontrollpunkt darzustellen. Ohne einen Blick auf den Algorithmus zu werfen, lassen Sie uns überlegen, was wir in Bezug auf den Maschinenzustand für einen Quartiles Solver benötigen.
Der Quartiles-Löser ist im Wesentlichen ein State-Space-Explorer. Der Zustandsraum umfasst die Menge der 4-Permutationen des 20-Kachelbretts: in anderen Worten, jede mögliche Permutation von 1 bis 4 Kacheln, wobei jede Kachel ein Wortfragment ist. Wenn wir uns diesen Zustandsraum also wie eine Ergebnismenge aus einer hypothetischen Datenbanktabelle vorstellen, brauchen wir einen Cursor, der die gesamte Ergebnismenge durchlaufen kann. Aber wir können uns nicht darauf verlassen, dass wir vollständige Zeilen zur Verfügung haben, durch die wir linear iterieren können, denn wir haben diese Ergebnismenge ja selbst erstellt.
Aber die Idee des Cursors ist unglaublich nützlich. Wenn der Cursor nicht über einen Strom von Datensätzen verfügt, über die er sich hin und her bewegen kann, wie sieht dann die Bewegung des Cursors aus? Lassen Sie uns mit dem Zustandsraum spielen und uns vorstellen, wie wir ihn manuell durchlaufen könnten.
Wir abstrahieren für den Moment von den Wortfragmenten und nehmen an, dass wir 20 von etwas haben, von dem jedes eindeutig durch die Bezeichnungen 0 bis 19 ([0,19]) bezeichnet wird. Wir möchten die 1-, 2-, 3- und 4-Vermutungen dieser 20 Elemente erhalten. Lassen Sie uns unseren Cursor in der Tupel-Notation darstellen, z.B., (i0), (i0, i1), (i0, i1, i2), (i0, i1, i2, i3), usw., wobei jede Komponente in steht für eines der 20 -Elemente. Technisch gesehen können wir jeden beliebigen Punkt im Zustandsraum als Ursprung für den Cursor wählen, aber es ist sehr nützlich, das 1-Tupel zu wählen, das das erste Element enthält, so dass (0) die Anfangsposition des Cursors ist.
Wie bewegt sich der Cursor also? Nun, es gibt mehrere Achsen der Bewegung:
- Wenn es
<4Elemente gibt, können wir eine Komponente anhängen:(i0) ⟹ (i0, i1) - Wenn es
>1Elemente gibt, können wir eine Komponente öffnen:(i0, i1) ⟹ (i0) - Wir können jede Komponente an Ort und Stelle variieren, aber wir müssen nur inkrementieren, wenn wir die Komponente immer bei
0beginnen:(i0) ⟹ (i0+ 1)
Wir haben also effektiv fünf Dimensionen der Bewegung: append und pop wirken auf die Länge des Tupels (eine Dimension), während increment auf die einzelnen Komponenten wirkt (vier Dimensionen). Das klingt nach vielen Dimensionen, aber die einzelnen Bewegungen sind sehr einfach. Außerdem können wir einige vereinfachende Einschränkungen hinzufügen:
- Wir geben dem Anhängen Vorrang vor allen anderen Bewegungen.
- Wir geben dem Inkrement den Vorzug vor dem Pop.
- Wir stellen sicher, dass pop mit einem nachfolgenden Inkrement verschmolzen wird (um eine Wiederholung des Cursorstatus zu vermeiden).
- Wir erhöhen nur die Komponente ganz rechts.
- Wir stellen sicher, dass alle Komponenten disjunkt sind, d.h.,
(i0, i1)ist akzeptabel, aber(i0, i0)ist verboten.
Erinnern Sie sich daran, dass die Einzigartigkeitsbeschränkung sich direkt aus den Regeln von Quartiles ergibt: dieselbe Kachel kann nicht zweimal in demselben Wort verwendet werden.
Wenn wir alles zusammenfassen, sehen wir uns an, wie unser Cursor funktioniert. In der Tabelle unten sehen Sie die Schrittnummer (der vollständigen Erkundung), die auszuführende Bewegung und den Cursor nach der Bewegung. Der Einfachheit halber betrachten wir einen 6-Elementraum und nicht einen 20-Elementraum. Los geht's!
| Schritt# | Bewegung | Cursor |
|---|---|---|
| 0 | (Herkunft) |
(0)
|
| 1 | anhängen. |
(0, 1)
|
| 2 | anhängen. |
(0, 1, 2)
|
| 3 | anhängen. |
(0, 1, 2, 3)
|
| 4 | Inkrement |
(0, 1, 2, 4)
|
| 5 | Inkrement |
(0, 1, 2, 5)
|
| 6 | pop + inkrementieren |
(0, 1, 3)
|
| 7 | anhängen. |
(0, 1, 3, 2)
|
| 8 | Inkrement |
(0, 1, 3, 4)
|
| 9 | Inkrement |
(0, 1, 3, 5)
|
| 10 | pop + inkrementieren |
(0, 1, 4)
|
| 11 | anhängen. |
(0, 1, 4, 2)
|
| 12 | Inkrement |
(0, 1, 4, 3)
|
| 13 | Inkrement |
(0, 1, 4, 5)
|
| 14 | pop + inkrementieren |
(0, 1, 5)
|
| 15 | anhängen. |
(0, 1, 5, 2)
|
| 16 | Inkrement |
(0, 1, 5, 3)
|
| 17 | Inkrement |
(0, 1, 5, 4)
|
| 18 | pop + inkrementieren |
(0, 2)
|
Natürlich dauert dies noch viel länger, aber es sollte ausreichen, um zu sehen, wie der Cursor den Zustandsraum durchläuft. Sehen Sie sich an, was in Schritt #6 passiert, wenn wir einfach nur "pop" ohne das "fused increment" machen. Der Cursor wäre (0, 1, 2): eine Regression zu seinem Zustand in Schritt #2. Das wäre nicht nur überflüssig, sondern auch eine Endlosschleife! Pop ist also out, aber Pop + Inkrement ist in: Popcrement, wenn Sie so wollen!
Das sieht soweit gut aus, aber lassen Sie uns über das Endgame des Cursors nachdenken. Was passiert, wenn popcrement die Komponente ganz rechts außerhalb der Grenzen inkrementieren müsste? Das ist natürlich nicht erlaubt, also müssen wir popcrement erneut ausführen. Popcrement muss also eine Schleife machen, um die Korrektheit zu gewährleisten und sowohl redundante Zustände als auch Endlosschleifen zu vermeiden. Mit dieser Anpassung im Hinterkopf, lassen Sie uns die Auflösung sehen:
| Bewegung | Cursor |
|---|---|
| anhängen. | (5, 4, 3, 0) |
| Inkrement | (5, 4, 3, 1) |
| Inkrement | (5, 4, 3, 2) |
| Popcrement | () |
Bumm, popcrement hat das gesamte Tupel geräumt! Nach unseren obigen Definitionen ist dies ein illegaler Zustand für den Cursor - was großartig ist! Es bedeutet, dass wir einen natürlichen Sentinel haben, der einen Grabstein für den Algorithmus darstellt. Wenn wir das leere Tupel sehen, sind wir fertig!
Wir haben jetzt einen Cursor und Regeln, die eine vollständige Durchquerung unseres Zustandsraums gewährleisten. Das bedeutet, dass wir jetzt eine Fortsetzung für unseren Solver-Algorithmus haben: Der Cursor selbst ist unsere Fortsetzung. Der Solver kann immer den nächsten zu verarbeitenden Cursor zurückgeben, und wir können den Solver starten und stoppen, wo immer wir wollen. Abstrakt betrachtet haben wir sichergestellt, dass der Solver unterbrechbar, resumierbar, erschöpfend, effizient und deterministisch ist. Hot Dog, das ist bereits 5 unserer Designziele!
FragmentPath
Gutes Design ist immer der schwierige Teil, also lassen Sie uns jetzt etwas Code schreiben. Um den Cursor wieder mit seinem Zweck zu verbinden, nämlich zu verfolgen, welche Kacheln des Quartiles-Boards in welcher Reihenfolge ausgewählt wurden, haben wir uns auf den Namen FragmentPath geeinigt, um dieses Konzept zu bezeichnen. Alles, was mit FragmentPath zu tun hat, finden Sie in src/solver.rsWenn Sie also die Inline-Kommentare oder den gesamten Code auf einmal sehen möchten, sollten Sie sich das ansehen.
#[derive(Clone, Copy, Debug, Default, PartialEq, Eq)]
#[must_use]
pub struct FragmentPath([Option<usize>; 4]);Wir könnten ein Rust-Tupel für die Nutzlast des FragmentPath verwenden, aber das würde einige der Implementierungen ziemlich unbequem machen. Ein Array von 4 mit fester Größe passt besser zu uns, wobei jedes Element ein optionaler Index in der Quartiles-Tafel ist, die wir lösen wollen. None stellt eine freie Stelle im Cursor dar, und alle Nones müssen auf der rechten Seite zusammengefasst werden. Wir können also (0, 1) ganz einfach darstellen als:
FragmentPath([Some(0), Some(1), None, None])Beachten Sie das Attribut must_use. Fortsetzungen sind notorisch leicht zu ignorieren entlang einiger Kontrollpfade, so dass dieses Risiko reduziert wird. Jetzt stellt der Compiler sicher, dass wir tatsächlich etwas mit einer FragmentPath tun, anstatt sie einfach zu vergessen.
Iteration
Irgendwann müssen wir die von FragmentPath eingeschlossenen Board-Indizes durchlaufen, also machen wir sie iterierbar:
pub fn iter(&self) -> impl Iterator<Item = Option<usize>> + '_
{
self.0.iter().copied()
}Die Board-Indizes sind einfach usizes, so dass wir eine Iterator beantworten, die sie kopiert. Die anonyme Lebensdauer ('_) zeigt an, dass die zurückgegebene Iterator von self entlehnt ist. Ich freue mich, dass dieser spezielle Teil des Zeilenrauschens in der Edition 2024 verschwinden wird.
Belegung
Wir müssen auch wissen, ob die FragmentPath frei ist, d.h. ob sie leer ist (die oben beschriebene Sentinel-Bedingung) oder voll.
pub fn is_empty(&self) -> bool
{
self.0[0].is_none()
}
pub fn is_full(&self) -> bool
{
self.0[3].is_some()
}Da wir sorgfältig die Invariante beibehalten, dass alle Nones auf der rechten Seite geclustert werden müssen, sind diese Implementierungen ausreichend.
Zugriff auf
Die direkte Indizierung einer FragmentPath wird für die Definition der Bewegungsoperatoren nützlich sein, daher implementieren wir std::ops::Index und std::ops::IndexMut:
impl Index<usize> for FragmentPath
{
type Output = Option<usize>;
#[inline]
fn index(&self, index: usize) -> &Self::Output
{
&self.0[index]
}
}
impl IndexMut<usize> for FragmentPath
{
#[inline]
fn index_mut(&mut self, index: usize) -> &mut Self::Output
{
&mut self.0[index]
}
}Fehler
Bevor wir uns die Cursor-Bewegungen ansehen, sollten wir uns die möglichen Fehlerarten ansehen:
#[derive(Clone, Copy, Debug, PartialEq, Eq)]
enum FragmentPathError
{
Overflow,
Underflow,
IndexOverflow,
CannotIncrementEmpty
}Overflow: Zeigt an, dass eineFragmentPathvoll war, so dass das Anhängen fehlgeschlagen ist.Underflow: Zeigt an, dass eineFragmentPathleer war, so dass pop fehlgeschlagen ist.IndexOverflow: Zeigt an, dass die äußerste rechte Komponente vonFragmentPathbereits den maximalen eindeutigen Board-Index erreicht hat, so dass die Inkrementierung fehlgeschlagen ist.CannotIncrementEmpty: Zeigt an, dass eineFragmentPathleer war, so dass die Erhöhung fehlgeschlagen ist.
Das ist alles, was schief gehen kann, und wir werden diese Fehlerbedingungen im Solver-Algorithmus selbst verwenden, nicht nur an der Schnittstellengrenze. Und nun weiter zur Bewegung des Cursors!
Anhängen
Wir haben beschlossen, dass append die höchste Priorität hat, also fangen wir dort an:
fn append(&self) -> Result<Self, FragmentPathError>
{
if self.is_full()
{
Err(FragmentPathError::Overflow)
}
else
{
let rightmost = self.0.iter()
.rposition(|&index| index.is_some())
.map(|i| i as i32)
.unwrap_or(-1);
let used = HashSet::<usize>::from_iter(
self.0.iter().flatten().copied()
);
let mut start_index = 0;
while used.contains(&start_index)
{
start_index += 1;
}
// Append the next fragment index.
let mut fragment = *self;
fragment[(rightmost + 1) as usize] = Some(start_index);
Ok(fragment)
}
}Das ist eine ganze Menge. Hier ist ein Flussdiagramm, das uns hilft, es zu visualisieren:
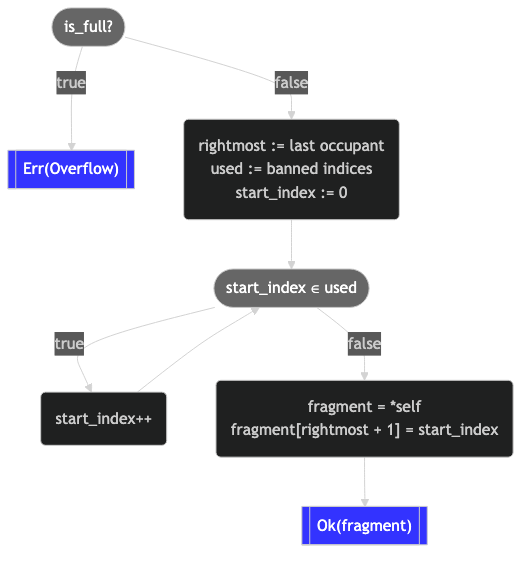
Jetzt ist es recht überschaubar:
- Signalisiert Überlauf, wenn voll.
- Suchen Sie den Index ganz rechts auf dem Brett.
- Berechnen Sie, welche Board-Indizes bereits vorhanden sind.
- Finden Sie den kleinsten verfügbaren Board-Index.
- Hängen Sie den kleinsten verfügbaren Board-Index an eine Kopie der
FragmentPathan. - Geben Sie die neue
FragmentPathzurück.
Inkrement
Inkrement ist die häufigste Bewegung für unseren Cursor und tragischerweise auch die komplexeste:
fn increment(&self) -> Result<Self, FragmentPathError>
{
let rightmost = self.0.iter()
.rposition(|&index| index.is_some())
.ok_or(FragmentPathError::CannotIncrementEmpty)?;
let used = HashSet::<usize>::from_iter(
self.0.iter().take(rightmost).flatten().copied()
);
let mut stop_index = 19;
while used.contains(&stop_index)
{
stop_index -= 1;
}
let mut fragment = *self;
loop
{
if fragment[rightmost] >= Some(stop_index)
{
return Err(FragmentPathError::IndexOverflow)
}
else
{
let next = fragment[rightmost].unwrap() + 1;
fragment[rightmost] = Some(next);
if !used.contains(&next)
{
return Ok(fragment)
}
}
}
}Zählen sah noch nie so schwer aus, nicht wahr? Nun, nichts macht das Zählen noch schwieriger als die Einführung eines Flussdiagramms, um es zu erklären, aber hier ist es trotzdem:
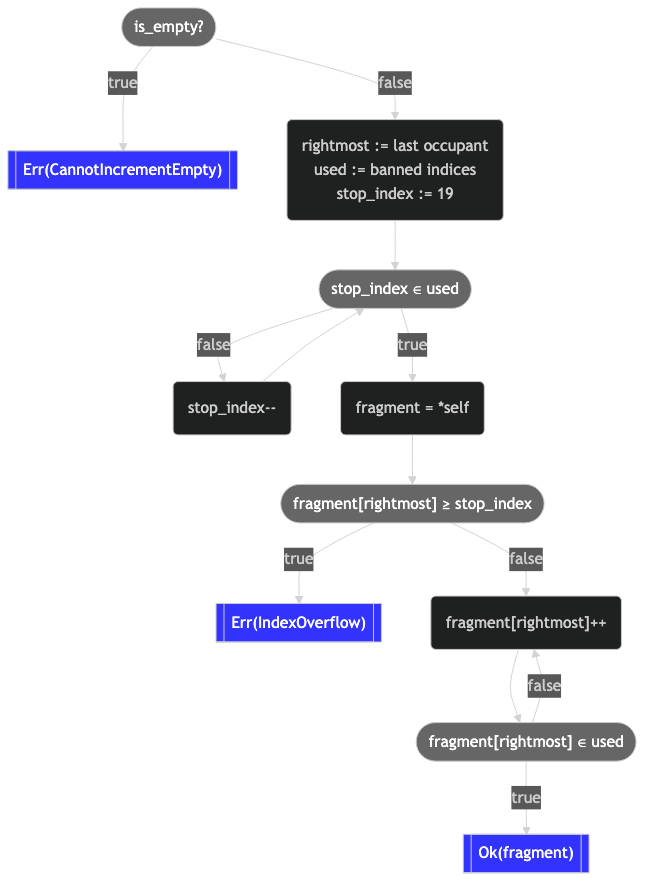
Oh, ich soll es einfacher machen, nicht schwieriger. Richtig, richtig. Nun, jetzt haben wir das Werkzeug, um es auseinander zu nehmen:
- Suchen Sie den Index ganz rechts auf dem Brett.
- Signal cannot-increment wenn leer.
- Berechnen Sie, welche Board-Indizes bereits vorhanden sind.
- Suchen Sie den Stopp-Index, indem Sie von
19aus rückwärts scannen (d.h. den höchsten gültigen Board-Index), bis wir einen unbenutzten Board-Index finden. Dies ist der höchste Board-Index, der nicht bereits inFragmentPathvorhanden ist. - Kopieren Sie die
FragmentPathzur Verwendung als Akkumulator. - Erhöhen Sie iterativ die Komponente ganz rechts, bis entweder:
- Der Stopp-Index ist erreicht. In diesem Fall müssen wir einen Indexüberlauf melden.
- Wenn ein unbenutzter Board-Index entdeckt wird, können wir den neuen
FragmentPathzurückgeben.
Dies ist deshalb so knifflig, weil wir sicherstellen müssen, dass alle von FragmentPath eingeschlossenen Board-Indizes disjunkt bleiben. Dies ist eine Invariante, die wir an den Grenzen der API sorgfältig aufrechterhalten und die für eine erschöpfende, effiziente Durchquerung des Zustandsraums von zentraler Bedeutung ist.
Pop...crement?
Pop stellt sich als einfach heraus. So einfach, dass ich denke, wir können auf das Flussdiagramm verzichten. Voilà:
fn pop(&self) -> Result<Self, FragmentPathError>
{
if self.is_empty()
{
Err(FragmentPathError::Underflow)
}
else
{
let mut indices = self.0;
let rightmost = indices.iter()
.rposition(|&index| index.is_some())
.unwrap();
indices[rightmost] = None;
Ok(Self(indices))
}
}Wir machen einen Unterlauf, wenn die FragmentPath leer ist, andernfalls werfen wir die Komponente ganz rechts weg. Aber sollten wir nicht Pop und Inkrement zusammen für, äh, Popcrement verschmelzen? Sicher, aber da wir Inkrement und Pop faktorisiert haben, ist es einfach, den fusionierten Operator zu definieren:
fn pop_and_increment(&self) -> Result<Self, FragmentPathError>
{
let mut fragment = *self;
loop
{
fragment = fragment.pop()?;
match fragment.increment()
{
Ok(fragment) => return Ok(fragment),
Err(FragmentPathError::IndexOverflow) => continue,
Err(FragmentPathError::CannotIncrementEmpty) =>
return Err(FragmentPathError::CannotIncrementEmpty),
Err(_) => unreachable!()
}
}
}Das Einzige, was hier erwähnenswert ist, ist, dass IndexOverflow eine weitere Komponente zum Platzen bringt. Ich hatte sogar den guten Geschmack, sie
Zuordnung von FragmentPaths zu englischen Wörtern
Ein FragmentPath enthält nur Board-Indizes, aber irgendwo da draußen gibt es ein Quartiles-Board. Wir möchten FragmentPath testen können, ohne einen Solver zu bauen, also fügen wir die Zuordnungslogik als eine Methode von FragmentPath hinzu:
fn word(&self, fragments: &[str8; 20]) -> str32
{
let mut word = str32::new();
for &index in self.0.iter().flatten()
{
word.push(&fragments[index]);
}
word
}str8 und str32 sind String-Typen aus dem beliebten fixedstr crate, die effiziente, kopierbare Strings mit fester Größe bereitstellt. Instanzen von str8 weisen genau 8 Bytes an Zeichendaten auf dem Stack zu, und es folgt direkt, was str32 tut. Bislang haben Quartiles Puzzles nur Fragmente mit einer Länge zwischen 2 und 4 Zeichen verwendet, aber wir können Apples Gedanken nicht lesen, also lassen wir uns etwas Spielraum. Da jedes unserer Fragmente höchstens 8 Bytes lang ist, reicht 32 Bytes aus, um 4 zu speichern.
Solver
Nun gut, wir wissen, wie wir uns im Zustandsraum orientieren können. FragmentPath in der Hand haben, können wir den Solver wieder aufnehmen. Aber zuerst brauchen wir einen Solver zum Fortsetzen. Siehe src/solver.rs um die Inline-Kommentare zu sehen. Wir beginnen mit der Datenstruktur selbst:
#[derive(Clone, Debug)]
#[must_use]
pub struct Solver
{
dictionary: Rc<Dictionary>,
fragments: [str8; 20],
path: FragmentPath,
solution: Vec<FragmentPath>,
is_finished: bool
}dictionary: Das englische Wörterbuch, das für die Lösung des Rätsels verwendet wird. Das Wörterbuch ist groß und die Anwendung wird es an mehreren Stellen speichern. Daher verwenden wirstd::rc::Rc, um sicherzustellen, dass wir es nicht wiederholt klonen müssen.fragments: Das Quartiles-Spielbrett, als Array von Fragmenten in zeilenweiser Reihenfolge. Beachten Sie, dassfragmentsmit dem gleichnamigen Parameter inFragmentPath::wordübereinstimmt.path: Die nächste zu untersuchende Position im Zustandsraum. Wenn der Solver weiterläuft, wird er hier fortgesetzt.solution: Der Akkumulator für die Lösung. Eine Lösung besteht aus den5Quartilen selbst und allen anderen Wörtern, die bei der Durchquerung des Zustandsraums entdeckt werden.is_finished: Das Flag, das anzeigt, ob der Solver abgeschlossen ist. Wenntrue,solutioneine vollständige Lösung für das Quartiles-Rätsel enthält. Wenn der Benutzer ein Brett eingegeben hat, das nicht kanonisch ist, d.h. nicht aus dem offiziellen Quartiles-Spiel stammt, dann könnte diestruesein undsolutionenthält möglicherweise nicht5Quartiles. Dies wäre z.B. der Fall, wenn der Benutzer dasselbe Fragment mehrfach eingegeben hat, was bei offiziellen Boards verboten zu sein scheint.
Bauwesen
Um ein Solver zu erstellen, brauchen wir nur das englische Wörterbuch und das Spielbrett:
pub fn new(dictionary: Rc<Dictionary>, fragments: [str8; 20]) -> Self
{
Self
{
dictionary,
fragments,
path: Default::default(),
solution: Vec::new(),
is_finished: false
}
}Fertigstellung
Wir stellen is_finished durch eine gleichnamige Methode dar:
pub fn is_finished(&self) -> bool
{
self.is_finished
}Wie bereits erwähnt, sagt uns dies nur, dass der Solver bis zum Ende gelaufen ist, nicht aber, ob er eine gültige Lösung gefunden hat. Wir würden dem Benutzer gerne mitteilen, wenn wir auf ein unlösbares Rätsel stoßen, da dies darauf hindeuten könnte, dass der Benutzer das Rätsel falsch eingegeben oder ein nicht ausreichend robustes Wörterbuch bereitgestellt hat. Lassen Sie uns also eine Methode schreiben, mit der wir feststellen können, ob eine Lösung gültig ist:
pub fn is_solved(&self) -> bool
{
if !self.is_finished
{
return false
}
let full_paths = self.solution.iter()
.filter(|p| p.is_full())
.collect::<Vec<_>>();
let unique = full_paths.iter()
.map(|p| p.word(&self.fragments).to_string())
.collect::<HashSet<_>>();
if unique.len() < 5
{
return false
}
let used_indices = full_paths.iter()
.flat_map(|p| p.0.iter().flatten())
.collect::<HashSet<_>>();
used_indices.len() == self.fragments.len()
}Aufgeschlüsselt:
- Wir können nicht wissen, ob das Rätsel gelöst ist, solange der Löser nicht fertig ist.
- Suchen Sie nach
≥5Wörtern, die aus4Fragmenten bestehen. Ein offizielles Rätsel versteckt genau5solche Wörter. - Um inoffizielle Rätsel zu unterstützen, stellen wir außerdem sicher, dass jedes Fragment tatsächlich eindeutig von einem der Quartile verwendet wird.
Abrufen des aktuellen Wortes
Der Einfachheit halber stellen wir eine Inline-Hilfe zur Verfügung, die der Solver verwenden kann, um das englische Wort zu erhalten, das dem aktuellen FragmentPath entspricht:
#[inline]
#[must_use]
fn current_word(&self) -> str32
{
self.path.word(&self.fragments)
}Zugriff auf die Lösung
Natürlich möchte Solver seinem Kunden Zugriff auf die Lösung gewähren. Wir bieten zwei Varianten an: eine für den Erhalt der FragmentPaths und eine für den Erhalt der englischen Wörter. Die Anwendung wird die erste Variante verwenden, während die Testsuite die zweite Variante nutzt.
#[inline]
#[must_use]
pub fn solution_paths(&self) -> Vec<FragmentPath>
{
self.solution.clone()
}
#[inline]
#[must_use]
pub fn solution(&self) -> Vec<str32>
{
self.solution.iter()
.map(|p| p.word(&self.fragments))
.collect()
}Lösen von Quartils-Rätseln
Genug des Hinhaltens! Wir haben die Designziele festgelegt und alle Bausteine kennengelernt. Endlich sind wir bereit, den mächtigen Algorithmus zur Lösung von Quartiles-Rätseln zu schreiben. Sehen Sie!
pub fn solve(mut self, duration: Duration) -> (Self, Option<FragmentPath>)
{
if self.is_finished
{
return (self, None)
}
let start_time = Instant::now();
let mut found_word = false;
loop
{
let start_path = self.path;
if self.dictionary.contains(self.current_word().as_str())
{
self.solution.push(self.path);
found_word = true;
}
if self.dictionary.contains_prefix(self.current_word().as_str())
{
match self.path.append()
{
Ok(path) =>
{
self.path = path;
}
Err(FragmentPathError::Overflow) => {}
Err(_) => unreachable!()
}
}
if self.path == start_path
{
match self.path.increment()
{
Ok(path) =>
{
self.path = path;
}
Err(FragmentPathError::IndexOverflow) =>
{
match self.path.pop_and_increment()
{
Ok(path) =>
{
self.path = path;
}
Err(FragmentPathError::CannotIncrementEmpty) =>
{
self.is_finished = true;
return (self, None)
}
Err(_) => unreachable!()
}
}
Err(_) => unreachable!()
}
}
if found_word
{
let word = *self.solution.last().unwrap();
return (self, Some(word))
}
let elapsed = Instant::now().duration_since(start_time);
if elapsed >= duration
{
return (self, None)
}
}
}Die Implementierung ist nicht riesig, aber knifflig, was bei einem State-Space-Explorer, der alle 8 der von uns gesetzten Designziele erfüllen muss, nicht überraschend ist.
Beginnen wir mit einer Untersuchung der Schnittstelle. Dies ist eine Methode von Solver, und da sie eine Instanz übernimmt, kann sie diese Instanz nach eigenem Ermessen verändern. Die Methode akzeptiert eine Instanz von std::time::Duration, die die weiche Grenze für die gewünschte Laufzeit darstellt. Wenn der Algorithmus feststellt, dass diese Grenze überschritten wurde, kehrt er zurück. Der Algorithmus besteht jedoch darauf, mindestens 1 fragment path zu verarbeiten, unabhängig davon, wie klein die gewünschte Laufzeit ist, um sicherzustellen, dass er unaufhaltsam auf den Abschluss zusteuert. Die Methode gibt ein 2-Tupel zurück, das die geänderte Solver und jedes Wort enthält, das während dieses Aufrufs gefunden wurde. Die Methode kehrt immer zurück, wenn entweder die angegebene Dauer überschritten wurde oder ein einziges gültiges Wort gefunden wurde. Der Aufrufer kann gefundene Wörter als Nachweis für den Fortschritt verwenden und die Benutzeroberfläche entsprechend aktualisieren.
Dies ist etwas komplexer als das Zählen, das, wie wir bereits gesehen haben, schon schwierig genug war, so dass es definitiv eine Visualisierung verdient:
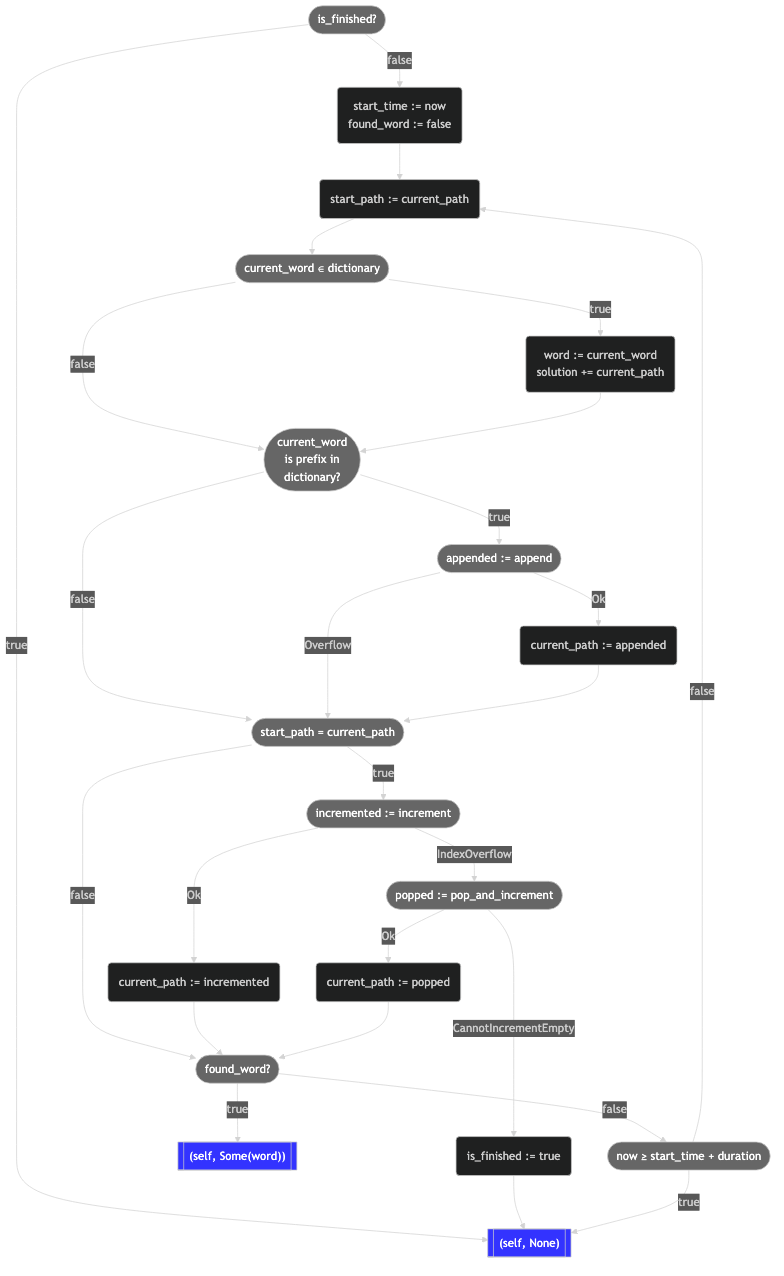
Immer noch gewaltig, aber das Flussdiagramm verdeutlicht die Gesamtstruktur. Nehmen Sie sich einen Moment Zeit, um das Diagramm zu studieren, dann werden wir die Logik aufschlüsseln.
Zunächst prüfen wir, ob der Solver bereits vollständig ausgeführt wurde. Wenn dies der Fall ist, beenden wir das Programm einfach. Die Ausführung von solve auf einer gelösten Solver sollte idempotent sein.
Wir erinnern uns daran, dass wir den Algorithmus mindestens einmal durchlaufen wollen, um einen inkrementellen Fortschritt in Richtung Fertigstellung zu gewährleisten. Dies ist erforderlich, um sicherzustellen, dass der Algorithmus für jede mögliche Eingabe beendet wird, was eines unserer Designziele war. Wir notieren die aktuelle Zeit (start), aber wir handeln noch nicht aufgrund dieser Information. Wir erstellen auch ein Flag (found_word), um zu verfolgen, ob wir während dieses Aufrufs ein Wort gefunden haben. Wir müssen die Lösungserweiterung getrennt von der Erkundung des Zustandsraums behandeln, und dieses Flag wird uns dabei helfen.
Am Anfang der Schleife erfassen wir den aktuellen FragmentPath (start_path). Wir verwenden den erfassten Wert, um zu bestimmen, welche der 5 Achsen der Erkundung wir durchlaufen werden.
Die nächsten beiden Blöcke fragen das Wörterbuch ab. Der erste dieser Blöcke sucht direkt nach dem aktuellen Wort. Wenn es vorhanden ist, dann erweitern wir die Lösung um das aktuelle Wort und setzen unser found_word Flag. Warum geben wir hier nicht einfach die Kontrolle an den Aufrufer zurück? Weil wir den Cursor noch nicht wirklich weiterbewegt haben. Wenn wir jetzt zurückkehren würden, würde der nächste Aufruf genau hier wieder ansetzen und das gleiche Wort erneut "entdecken": eine Endlosschleife.
Mit der zweiten Wörterbuchabfrage führen wir die in Teil I versprochene Bereinigung des Suchraums durch. Wir behandeln das aktuelle Wort als Präfix im Wörterbuch und fragen das Wörterbuch, ob es Wörter kennt, die auf diese Weise beginnen. Wenn dies nicht der Fall ist, dann streichen wir diesen Teil des Suchraums komplett. Ist dies jedoch der Fall, dann wenden wir den Algorithmus zum Anhängen auf die aktuelle FragmentPath an. Wenn append erfolgreich ist, bewegen wir den Cursor entsprechend weiter. Wenn append jedoch überläuft, übergehen wir einfach diesen Block und setzen den Algorithmus fort.
Wenn append erfolgreich war, stimmt start_path nicht mehr mit dem aktuellen Pfad überein, was bedeutet, dass wir den Cursor erfolgreich aktualisiert haben. Wir können also diesen riesigen Block überspringen, denn wir dürfen den Cursor nicht mehrmals vorwärts bewegen, ohne zwischendurch das Wörterbuch abzufragen. Der Algorithmus wäre nicht erschöpfend und würde möglicherweise gültige Wörter übersehen.
Wenn das Anhängen fehlgeschlagen ist, hat sich der Cursor noch nicht bewegt und wir müssen noch eine Art von Bewegung sicherstellen. Also versuchen wir den Inkrement-Algorithmus auf der aktuellen FragmentPath und bewegen den Cursor weiter, wenn das funktioniert. Wenn er jedoch einen Komponentenindex überläuft, greifen wir zurück, indem wir den Popcrement-Algorithmus ausführen.
Unter der Annahme, dass entweder increment oder popcrement erfolgreich waren, haben wir den Cursor weiterbewegt und das Ende der Schleife erreicht. Wenn das Flag found_word gesetzt ist, geben wir die Kontrolle an den Aufrufer zurück und überreichen ihm das neue Wort, das wir entdeckt haben. Wenn wir noch kein Wort gefunden haben, verwenden wir die erfasste Startzeit, um festzustellen, ob wir das vorgegebene Ausführungsquantum überschritten haben. Wenn die Zeit abgelaufen ist, geben wir die Kontrolle an den Aufrufer zurück, andernfalls durchlaufen wir die Schleife erneut.
Aber wenn weder increment noch popcrement erfolgreich waren, dann ist etwas Interessanteres passiert, als den Cursor zu bewegen: Wir haben den Algorithmus vollständig beendet! Wir setzen is_finished und geben die Kontrolle zurück, um den Algorithmus und die Lösung als "fertig" zu erklären. Wir haben alle 8 unserer Ziele für den Solver erreicht. Puh.
Testen Sie
Woher wissen wir, dass das alles funktioniert? Durch Testen, natürlich! Hier ist eine Kurzfassung des Haupttests:
#[test]
fn test_solver()
{
let dictionary = Rc::new(Dictionary::open("dict", "english").unwrap());
let (fragments, expected) = (
[
str8::from("azz"), str8::from("th"), str8::from("ss"),
str8::from("tru"), str8::from("ref"), str8::from("fu"),
str8::from("ra"), str8::from("nih"), str8::from("cro"),
str8::from("mat"), str8::from("wo"), str8::from("sh"),
str8::from("re"), str8::from("rds"), str8::from("tic"),
str8::from("il"), str8::from("lly"), str8::from("zz"),
str8::from("is"), str8::from("ment")
],
vec![
str32::from("cross"), str32::from("crosswords"),
str32::from("fully"), str32::from("fuss"), str32::from("fuzz"),
str32::from("is"), str32::from("mat"), str32::from("nihilistic"),
str32::from("rail"), str32::from("rally"), str32::from("rare"),
str32::from("rash"), str32::from("razz"), str32::from("razzmatazz"),
str32::from("recross"), str32::from("ref"), str32::from("refresh"),
str32::from("refreshment"), str32::from("rewords"),
str32::from("this"), str32::from("thrash"), str32::from("thresh"),
str32::from("tic"), str32::from("truss"), str32::from("truth"),
str32::from("truthfully"), str32::from("words"), str32::from("wore")
]
);
let solver = Solver::new(Rc::clone(&dictionary), fragments);
let solver = solver.solve_fully();
assert!(solver.is_finished());
assert!(solver.is_solved());
let mut solution = solver.solution();
solution.sort();
for word in solution.iter()
{
assert!(
dictionary.contains(word.as_str()),
"not in dictionary: {}",
word
);
}
let expected = HashSet::<str32>::from_iter(expected.iter().cloned());
let solution = HashSet::<str32>::from_iter(solution.iter().cloned());
assert!(expected.is_subset(&solution));
}fragments enthält ein offizielles Quartiles-Rätsel. Ich habe das Spiel gespielt, um 100 Punkte zu erreichen, wodurch die Option freigeschaltet wurde, alle im offiziellen Wörterbuch gefundenen Wörter anzuzeigen. expected ist diese Wortliste. Da sich das offizielle Wörterbuch höchstwahrscheinlich von dem unterscheidet, das ich mit der Anwendung gebündelt habe, testen wir nur, ob die erwartete Lösung eine Teilmenge der tatsächlichen Lösung ist, die der Solver gefunden hat.
Ich habe noch eine ganze Reihe anderer Tests geschrieben, in denen ich alle Modalitäten der verschiedenen Cursorbewegungen usw. getestet habe. Sehen Sie sich diese im Projekt an.
Leistung
Wenn Sie sich an das Designziel Nr. 6 für den Solver erinnern (der Solver sollte schnell sein), haben wir beschlossen, dass der Solver Hunderte von Millisekunden brauchen kann und trotzdem schnell genug ist. Hunderte von Millisekunden sind für den Benutzer spürbar, aber für das Lösen eines ganzen Rätsels ist das sehr flott.
Wie haben wir also abgeschnitten? Hier ist ein Auszug aus dem Bericht, den cargo bench für meine Hardware erstellt hat:
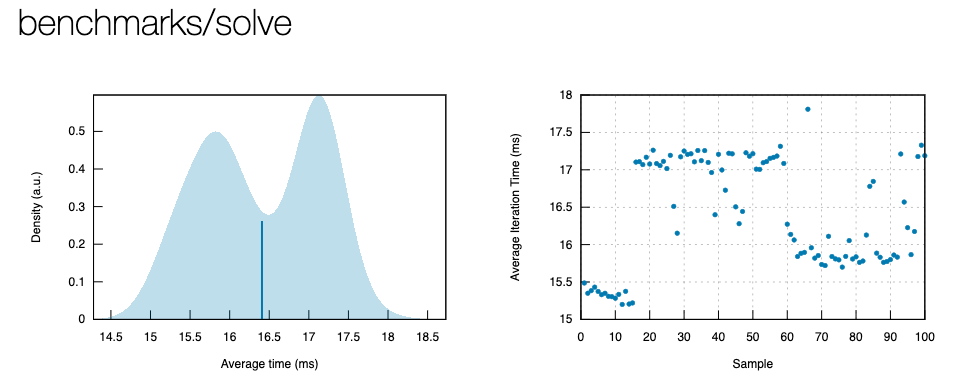
Die durchschnittliche Zeit für die Ausführung des Quartiles Solvers beträgt 16.408 Millisekunden. Wir haben unser unscharfes Ziel um eine ganze Größenordnung übertroffen. Gar nicht mal so schlecht; danke, Rust!
Beachten Sie, dass ich den sehr einfachen Benchmark der Kürze halber weggelassen habe, aber schauen Sie sich die Quelle an, wenn Sie neugierig sind. Ich möchte sichergehen, dass ich Sie nicht über die hervorragende Leistung, die wir erreicht haben, hinters Licht führe, nicht wahr?
Und das war's für diese Ausgabe. Beim nächsten Mal werden wir die textbasierte Benutzeroberfläche (TUI) erstellen und endlich die fertige Anwendung haben! Bleiben Sie dran, denn Teil III ist auf dem Weg! Nochmals vielen Dank für Ihre Zeit!
Verfasst von
Todd Smith
Rust Solution Architect at Xebia Functional. Co-maintainer of the Avail programming language.
Contact