
Quartile Solver: Teil I
In dieser dreiteiligen Serie und dem dazugehörigen Projekt werden wir den Spaß an Apple News+ Quartiles erhöhen, indem wir einen effizienten Solver dafür entwickeln. Dazu verwenden wir die Programmiersprache Rust und die Terminal User Interface (TUI)-Bibliothek Ratatui. Ganz nebenbei lernen wir ein wenig über Rust, Spieltheorie, Kombinatorik, Benchmarking und TUIs. Um mit der fertigen App zu experimentieren, müssen Sie das Projekt lokal ziehen. Sie können den detaillierten Anweisungen im README.md um das Projekt unter Windows, macOS oder Linux zu erstellen, zu verwenden, zu testen, zu bewerten oder zu installieren.
In diesem ersten Beitrag stellen wir Quartiles vor, analysieren, warum es ein guter Kandidat für eine automatische Lösung ist, und erstellen schließlich das Wörterbuch, das der Solver im zweiten Beitrag nutzen wird.
Quartile: Ein vollständig rekonstruierbares Spiel mit perfekter Information
Grob gesagt besteht Quartiles aus drei Elementen:
- Ein Spielbrett, das aus 5 langen englischen Wörtern in kleinere Wortfragmente mit jeweils 2 bis 4 Buchstaben zerlegt wird, so dass es keine doppelten Wortfragmente gibt. Die aus den 5 Wörtern gewonnenen Wortfragmente werden alle zusammengewürfelt und dann so angeordnet, dass sie ein 4×5 Spielbrett mit 20 Feldern bilden. Zum Beispiel könnte das Wort
algorithmsinal,gor,itundhmszerlegt werden. - Ein Lösungsfinder, der gültige englische Wörter auflistet, die der Spieler entdeckt hat. Jedes Wort verwendet 1 bis 4 Felder des Spielbretts. Wörter, die 4 Zellen verwenden, werden Quartile genannt. Zellen können wiederverwendet werden, so dass mehrere Wörter dasselbe Wortfragment enthalten können, aber vollständige Wörter dürfen nicht wiederverwendet werden. Der Spielplan ist so aufgebaut, dass nur 5 Quartile vorhanden sind.
- Ein Wörterbuch mit englischen Wörtern, das einen angemessen großen Ausschnitt des englischen Lexikons umfasst. Das Spiel selbst stellt das Spielbrett zur Verfügung und aktualisiert den Lösungstracker, aber der Spieler bringt das Wörterbuch mit, typischerweise in Form von zuvor erlerntem Wissen über die englische Sprache.
Das Spiel ist gewonnen, wenn die Lösungsleiste 5 Quartile enthält. Aufgrund des Aufbaus des Spielbretts handelt es sich dabei garantiert um die 5 Original-Quartile; es gibt niemals "zusätzliche" Quartile. Um das Spiel unter Freunden wettbewerbsfähig zu machen, werden die Wörter nach der Anzahl der in ihnen enthaltenen Wortfragmente bewertet, wobei die Quartile die meisten Punkte einbringen. Die höchstmögliche Punktzahl erhalten Sie, wenn Sie nicht nur die 5 Quartile finden, sondern auch jedes Wort, das in Apples offiziellem Quartiles-Wörterbuch akzeptiert wird (das der Öffentlichkeit nicht zugänglich zu sein scheint). Aber wir werden uns hier nicht mit der Mechanik der Punktevergabe befassen, sondern nur mit dem vollständigen Auffüllen des Lösungsfinders in Bezug auf ein Wörterbuch.
Warum also einen Solver für das relativ neue Quartiles und nicht für das bekanntere und etabliertere Wordle entwickeln? Nun, das ist ganz einfach - weil es möglich ist, einen effektiven Solver für Quartiles zu entwickeln, während dies für Wordle nicht möglich ist!
Perfekte vs. unvollständige Informationen
Um sicherzustellen, dass wir einen effektiven Solver bauen können, d.h. einen, der garantiert zu einer korrekten Lösung kommt, indem er einen Algorithmus ausführt, muss das Zielspiel seinen Spielern perfekte Informationen bieten. Ein Spieler hat dann und nur dann perfekte Informationen über ein Spiel, wenn:
- Der vollständige Zustand des Spiels ist immer dann sichtbar, wenn der Spieler einen Zug machen darf. Ein Zug verändert den Zustand des Spiels in irgendeiner Weise, so dass eine Folge von Zügen dazu führt, dass sich das Spiel in seinem Zustandsraum weiterentwickelt.
- Wenn Sie einen Zug machen, gibt es keine Zufallsereignisse. Per Definition hat ein Zufallsereignis einen unbekannten Ausgang, selbst wenn der Spieler die momentanen Wahrscheinlichkeiten aller möglichen Ergebnisse kennt.
Zusammengenommen kommen wir zu einer natürlichen Schlussfolgerung: Ein Spieler kann nicht über perfekte Informationen verfügen, wenn es geheime Informationen gibt, unabhängig davon, ob diese Informationen durch das Spiel selbst, durch die Wahrscheinlichkeit oder durch einen anderen Spieler geheim gehalten werden. Wenn eine Information für einen Spieler geheim ist, dann hat dieser Spieler nur unvollkommene Informationen. Wenn irgendeine Information für einen Löser geheim ist, dann können wir im allgemeinen Fall nicht unbedingt einen effektiven Löser bauen. Praktisch alle Kartenspiele - Poker, Bridge, Rommé, Blackjack, Pik, Go Fish, ... - geben den Spielern nur unvollkommene Informationen, während berühmte Strategiespiele wie Schach und Go den Spielern perfekte Informationen geben.
Aber lassen Sie uns über Wortspiele sprechen. Nehmen wir Wordle als einfaches Beispiel. Der Sinn des Spiels besteht darin, ein geheimes Wort mit 5 Buchstaben in 6 oder weniger Zügen zu entschlüsseln, wobei jeder Zug der Vorschlag eines vollständigen englischen Wortes mit 5 Buchstaben ist. Daraus folgt direkt, dass der Spieler nur über unvollkommene Informationen verfügt - das Wissen um seine eigenen Vermutungen und die Rückmeldung von jeder Vermutung. Die Analyse der englischen Sprache, insbesondere der Buchstabenhäufigkeiten und der zulässigen Aneinanderreihungen, ermöglicht die Kodifizierung einer optimalen Strategie, und zufälligerweise kann diese Strategie das Spiel immer in 5 Zügen auf leicht und 6 Zügen auf schwer lösen. Aber natürlich muss dem Algorithmus die richtige Antwort eingetrichtert werden, oder es muss nach jedem Tippen die richtige Rückmeldung gegeben werden. Ohne diese Zugeständnisse gibt es keine Möglichkeit, das Geheimnis zu lüften, denn es gibt keine Möglichkeit festzustellen, ob sich ein Algorithmus auf die Antwort zubewegt oder von ihr weg.
Im Gegensatz dazu ist Quartiles eher wie Boggle. Vorausgesetzt, der Spieler ist mit dem englischen Lexikon vertraut, sind beide Spiele perfekte Informationsspiele. Der Spieler kann das gesamte Spielbrett sehen, der Spieler weiß, welche Wörter gespielt und akzeptiert wurden, der Spieler weiß (aufgrund der Konstruktion), ob ein Wort ein Quartil ist, und folglich weiß der Spieler, wann alle Quartile gefunden worden sind. Der Spieler "weiß" theoretisch, wann jedes Wort gefunden wurde, denn er kann theoretisch das Spielbrett erschöpfend durchsuchen, indem er jede erlaubte Kombination von Wortfragmenten mit seinem Wörterbuch vergleicht. (Außerdem ist das Online-Quartilspiel nett: Es zeigt Ihnen an, wenn keine Wörter mehr unentdeckt bleiben).
ℹ️ Lustige Fakten
Quartile ist nicht nur ein perfektes Informationsspiel, sondern auch ein vollständig rekonstruierbares Spiel. Das bedeutet, dass sein kompletter momentaner Zustand dem beobachtbaren Zustand entspricht und einfach durch die Betrachtung seiner sichtbaren Komponenten - dem Spielbrett, der Lösungsübersicht und dem Wörterbuch - korrekt ermittelt werden kann. Am wichtigsten für das Spiel ist, dass die nächsten legalen Züge vollständig durch den beobachtbaren Zustand des Spiels bestimmt sind.
Quartiles ist außerdem speicherlos, was bedeutet, dass die Züge des Spielers nicht in historischer Reihenfolge aufgezeichnet werden müssen, um die Einhaltung der Spielregeln zu gewährleisten. Tatsächlich sind die bisher gespielten
kZüge gegenseitig kommutativ, weshalb keine Spielhistorie geführt werden muss. Der Lösungstracker stellt eine Menge (und nicht eine Folge) von Zügen dar. Das Wichtigste für das Spiel ist, dass die nächsten legalen Züge vollständig bestimmt werden können, ohne dass auf den Spielverlauf zurückgegriffen werden muss.Interessanterweise sind Schach und Go weder vollständig rekonstruierbar noch gedächtnislos. Die Untersuchung eines beliebigen Schachbretts gibt keinen Aufschluss über das Recht auf Rochade, die Möglichkeit eines En-Passant-Schlags oder darüber, wann die 50-Züge-Regel oder die Regel der dreifachen Wiederholung verletzt werden würde. Die Untersuchung eines beliebigen Go-Bretts verrät nicht, welche Züge die
Ko-Regel verletzen würden. Beide Spiele erfordern also das Führen eines Spielberichts, d.h. eines Spielberichts, um die Rechtmäßigkeit der kommenden Züge zu bestimmen. Da die Aufzeichnung dieses (sichtbaren) Spielberichts von den offiziellen Regeln vorgeschrieben ist, werden beide Spiele zu vollständig rekonstruierbaren Spielen mit perfekter Information, obwohl keines der beiden Spiele gedächtnislos ist.
Nachvollziehbarkeit
Wir haben festgestellt, dass es theoretisch möglich ist, einen effektiven Solver für Quartile zu entwickeln. Bevor wir uns jedoch an die Programmierung machen, sollten wir zumindest eine ungefähre Vorstellung davon haben, ob die Ausführung unseres Algorithmus machbar ist. Mit anderen Worten: Wird das Programm in einer angemessenen Zeitspanne zu einer Lösung kommen?
Die Angemessenheit hängt natürlich von der Problembeschreibung ab. Wenn ein Algorithmus eine Woche braucht, um zu entscheiden, ob dog richtig geschrieben ist, dann ist er unlösbar (für praktisch jedes Problem). Wenn ein Algorithmus jedoch (nur) eine Woche braucht, um einen Brute-Force-Angriff gegen SHA-3 durchzuführen, dann wäre jemand absolut begeistert (und die meisten anderen sehr, sehr verärgert).
Tun Sie nicht das Unmögliche
Bevor ich zu Xebia kam, wurde ich von meinen Arbeitgebern mindestens zweimal aufgefordert, eine Aufgabe zu erfüllen, bei der ich praktisch zuerst einen Millenniumspreis gewinnen müsste. Beide Male wäre es der Preis für P gegen NP gewesen, das ist also wenigstens etwas. Die Moral von der Geschicht: Machen Sie immer einen Sanity Check, dass Ihr Problem sowohl entscheidbar als auch lösbar ist , bevor Sie mit der Arbeit an dem Problem beginnen!
Eine gute Faustregel für die Überschaubarkeit eines mechanischen Problems wie diesem ist die Frage, ob ein Mensch es gut lösen kann. Quartile ist ein Spiel für Menschen, also sollten Menschen es vermutlich auch gut spielen können. Während unsere allgemeine Intelligenz, unser abstrakter Verstand und unsere Weltkenntnis bei vielen wichtigen Aufgaben von Algorithmen des maschinellen Lernens und großen Sprachmodellen noch nicht erreicht werden, lässt unsere vertikale Skalierbarkeit zu wünschen übrig. Aber wir neigen dazu, sehr gut in Wortspielen zu sein, also erwarten wir, dass mechanische Löser das auch sein werden.
Aber warum sollten Sie sich auf mein Wort verlassen? Lassen Sie uns einen kurzen Abstecher nach Mathlandia machen.
Kombinatorik
Die Bestimmung der Nachvollziehbarkeit ist im Wesentlichen ein Zählproblem, also wenden wir uns der Kombinatorik zu, um den Umfang unseres Problems zu bestimmen. Da der Spieler von Quartiles ein Wort aus 1, 2, 3 oder 4 Spielsteinen bilden kann, müssen wir die Anzahl der Permutationen mit 1, 2, 3 und 4 Spielsteinen berechnen und dann diese Zahlen zusammenzählen, um die maximale Ausdehnung des Suchraums zu ermitteln. Ich sage "maximal", weil wir den Suchraum sehr effektiv beschneiden können, um den Umfang des Problems zu verringern, was ich weiter unten demonstrieren werde.
Um zu den Grundlagen zurückzukehren, lautet die Formel für k-Permutationen von n:
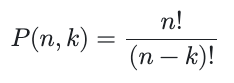
Dabei ist n die Gesamtzahl der Elemente in der Menge (der Spielsteine in Quartilen) und k ist die Anzahl dieser Elemente, die in einer Folge angeordnet werden müssen. n ist 20, die Anzahl der Spielsteine auf dem Spielbrett. Wir beschränken k auf [1,4] und berechnen die Summe der vier dazugehörigen Anwendungen. Die einzelnen Gleichungen liefern uns:
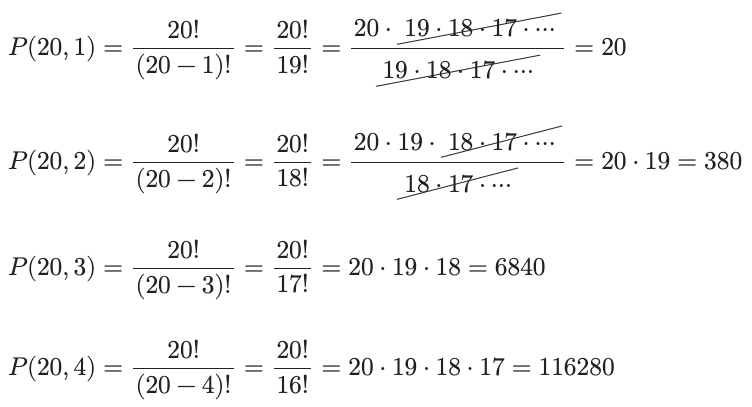
Und Trommelwirbel:
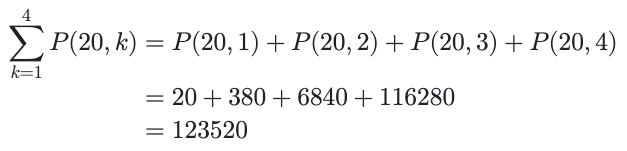
Es gibt "nur" 123520 Möglichkeiten, bis zu 4 Spielsteine unseres Spielbretts 20 anzuordnen. Wir würden diesen Raum nicht manuell durchsuchen wollen, aber Computer sind schnell, was diese Zahl klein und unser Problem sehr gut überschaubar macht - genau wie wir erwartet haben.
Darstellung im Wörterbuch
Wie ich oben angedeutet habe, können wir diese Komplexität weiter reduzieren. Die wichtigste Erkenntnis ist folgende: Die meisten Permutationen von Kacheln ergeben kein englisches Wort. Um zu entscheiden, ob wir ein gültiges englisches Wort gefunden haben, müssen wir ein englisches Wörterbuch konsultieren. Aber wenn wir das Wörterbuch für 123520 mögliche Permutationen konsultieren müssen, haben wir keine Mühe gespart. Wir wollen uns weniger Permutationen ansehen.
Dafür nutzen wir eine neue wichtige Erkenntnis: Die meisten Permutationen von Kacheln ergeben nicht einmal den Anfang eines englischen Wortes. Das klingt schon vielversprechender.
Lassen Sie uns permutation in 4 Fragmente zerlegen, also pe, rmut, at, ion. Wenn wir wissen, dass rmut kein englisches Wort einleitet - und das wissen wir - dann macht es keinen Sinn, das Wörterbuch nach rmutpeation, rmutatpeion, rmutationpe, und so weiter zu konsultieren. Wenn wir davon ausgehen, dass dies nur 4 von 20 Kacheln eines Quartiles-Bretts sind, können wir die Permutationen von P(20,3) = 6840 vollständig aus dem Suchraum eliminieren, wenn die erste Kachel keine brauchbare englische Vorsilbe ist. Dazu müssen wir nicht einmal das Wörterbuch konsultieren. Wir müssen sie während der Suche nicht einmal besuchen. Wenn es doch nur eine Datenstruktur gäbe, die diese Art der Suche unterstützt...
Präfix-Bäume
Präfixbäume sind die Rettung! Ein Präfixbaum (oder Trie) ist ein Suchbaum, der seine Schlüssel über die gesamte Datenstruktur verteilt. Die Adresse eines Knotens im Baum stellt seinen Schlüssel dar, d.h. der Pfad, der von der Wurzel zum Knoten führt, kodiert den Schlüssel. Nicht jeder Knoten muss einen gültigen Schlüssel repräsentieren. Daher unterscheidet ein Präfixbaum seine gültigen Schlüssel, indem er eine Nutzlast an den Endknoten des Schlüssels anhängt; für unsere Zwecke reicht ein einfaches Flag, das besagt "Ich bin ein Schlüssel!
Die Darstellung eines englischen Wörterbuchs als Präfixbaum ist einfach:
- Jeder Knoten besteht nur aus dem oben erwähnten Marker-Flag. Nehmen wir an, es handelt sich um einen booleschen Wert namens
endsWord, was bedeutet, dass der Knoten als Endpunkt für ein Wort im Wörterbuch dient.endsWordisttrue, wenn und nur wenn der Pfad, der durchlaufen wurde, um den Knoten zu erreichen, ein englisches Wort aus dem Wörterbuch enthält. - Jede Kante ist mit einem römischen Buchstaben beschriftet.
- Jeder Knoten hat bis zu 26 Ausgänge, einen für jeden möglichen römischen Buchstaben.
- Der Wurzelknoten ist ein Sentinel - ein leeres "Wort", das keine Buchstaben enthält.
Hier ist ein einfaches Beispiel, das das 6-Wörter-Wörterbuch ` veranschaulicht, wobei der ganz linke Knoten der Stammknoten ist:
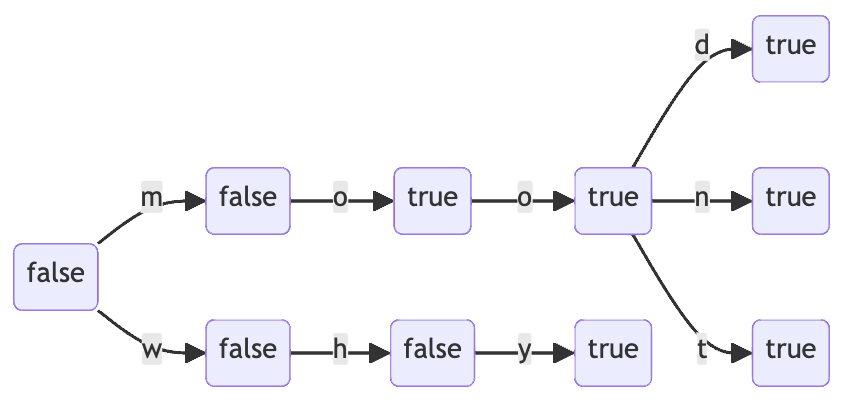
Die Beschriftung jedes Knotens ist der Wert von endsWord, den wir kurz als true oder false bezeichnen. Die Ausrichtung des Diagramms von links nach rechts, die gewählt wurde, um die Textrichtung des Englischen von links nach rechts widerzuspiegeln, veranschaulicht sehr schön, wie englische Wörter in den Kanten des Präfixbaums kodiert werden.
Anhand der Präfixbaum-Darstellung können Sie auf zwei Arten feststellen, dass ein Wort in diesem Wörterbuch nicht vorhanden ist:
- Die Durchquerung der einzelnen Buchstaben des Wortes von links nach rechts ist abgeschlossen, führt aber zu einem Knoten, dessen
endsWordMarkierungfalseist. In diesem Fall wird zum Beispielwheliminiert. - Das Durchlaufen der einzelnen Buchstaben des Wortes von links nach rechts muss wegen einer fehlenden Kante aufgegeben werden. In diesem Fall fällt zum Beispiel
mookweg (ein gültiger nordamerikanischer Slang, der aber in dem kleinen Beispielwörterbuch nicht vorkommt).
Der zweite Fall ist viel interessanter als der erste, denn er liefert die Grundlage für die Eliminierung unfruchtbarer Präfixe. Da der Knoten, der moo entspricht, keine Ausgangskante auf j hat, schließen wir daraus, dass keine dem Wörterbuch bekannten Wörter mit mooj beginnen. Jetzt haben wir eine gute Möglichkeit, den Suchraum zu beschneiden und statistisch sicherzustellen, dass wir nicht alle 123520 möglichen Kandidaten erschöpfend prüfen müssen.
Praxis
Genug der Theorie! Lassen Sie uns etwas Rust schreiben! Vergessen Sie nicht, einen Blick auf das fertige
Projekt einrichten
Einige der Projektkomponenten sollten wiederverwendbar sein, wie z.B. das englische Wörterbuch und sogar der Quartiles-Solver. Daher wollen wir diese von der textbasierten Benutzeroberfläche trennen, die wir in Teil drei dieser Blogserie schreiben werden.
Wir wollen am Ende zwei Kisten haben, eine Binärkiste und eine Bibliothekskiste, die jeweils den Namen quartiles-solver tragen. Richten wir also unser Projekt folgendermaßen ein:
quartiles-solver/
src/
lib.rs
main.rs
Cargo.tomlWir wollen nicht unsere eigene Implementierung des Präfixbaums schreiben, denn jemand hat bereits eine schöne Implementierung namens pfx geschrieben. Um zu vermeiden, dass wir das englische Wörterbuch in unser Programm einbetten oder den Präfixbaum bei jedem Start der Anwendung von Grund auf neu aufbauen müssen, beschließen wir, dass unsere Präfixbäume die Bincode-Serialisierung über Serde unterstützen sollten. Außerdem wollen wir die Ausführung über die Protokollierung nachvollziehbar machen, also wählen wir log als unsere Verblendung und env_logger als unseren spezifischen Anbieter. Wir verwenden dies Cargo.toml um loszulegen:
[package]
name = "quartiles-solver"
version = "0.1.0"
edition = "2021"
authors = ["Todd L Smith <todd.smith@xebia.com>"]
[dependencies]
bincode = "1.3"
env_logger = "0.11"
log = "0.4"
pfx = { version = "0.4", features = ["serde"] }
serde = { version = "1.0", features = ["derive"] }Wir werden dies schrittweise ausbauen, aber dies ist ein guter Anfang. Beachten Sie, dass wir unsere Cargo.lock weil eine unserer Kisten ausführbar ist.
Implementierung des Wörterbuchs
Lassen Sie uns eine neue Rust-Datei in das Projekt einfügen: src/dictionary.rs. Wie Sie vielleicht erwarten, werden wir das Wörterbuch hier implementieren.
Für unser Wörterbuch verwenden wir das newtype-Muster aus der funktionalen Programmierung. Wir verpacken pfx::PrefixTreeSet und leiten daraus einige relevante Eigenschaften ab, darunter serde::Deserialize und serde::Serialize.
#[derive(Clone, Debug, Default, Eq, PartialEq, Serialize, Deserialize)]
#[must_use]
pub struct Dictionary(PrefixTreeSet<String>);Wir gehen davon aus, dass Instanzen von Dictionary teuer sind, da jede von ihnen potenziell ein ganzes englisches Wörterbuch enthält (aus ≤70,000 Wörtern, wenn Sie die im Projekt enthaltene Wortliste verwenden). Zum Schutz vor dem versehentlichen Verwerfen eines Dictionary an der Stelle eines Funktionsaufrufs wenden wir die must_use Attribut. Jetzt erhebt der Compiler Einspruch, wenn eine von einer Funktion zurückgegebene Dictionary unbenutzt ist.
Jetzt erstellen wir einen schönen großen impl Dictionary Block, in dem wir unsere Logik unterbringen. Wir beginnen mit einem einfachen Konstruktor, der sich identisch zu Default::default verhält, aber inlined werden kann.
#[inline]
pub fn new() -> Self
{
Self(Default::default())
}Jetzt fügen wir einige einfache, aber wichtige Delegationsmethoden hinzu, um den Inhalt einer Dictionary abzufragen:
#[inline]
#[must_use]
pub fn is_empty(&self) -> bool
{
self.0.is_empty()
}
#[inline]
#[must_use]
pub fn contains(&self, word: &str) -> bool
{
self.0.contains(word)
}
#[inline]
#[must_use]
pub fn contains_prefix(&self, prefix: &str) -> bool
{
self.0.contains_prefix(prefix)
}Der letzte Punkt wird besonders wichtig sein, wenn wir den Solver schreiben, denn damit erreichen wir die oben beschriebene präfixbasierte Beschneidung.
Es wäre gut, wenn Sie die Möglichkeit hätten, einige Wörter in eine Dictionary einzufügen,
also fangen wir einfach an:
pub fn populate<T: AsRef<str>>(&mut self, words: &[T])
{
for word in words
{
self.0.insert(word.as_ref().to_string());
}
}Dies ist eine pauschale Lösung, die ein Dictionary aus jedem Slice füllen kann, dessen Elemente in &str konvertiert werden können. Wir müssen also nicht im Voraus genau wissen, welche Typen das sein werden. populate ist nützlich zum Testen, aber es ist nicht unbedingt praktisch, wenn wir ein Wörterbuch aus einer Textdatei lesen wollen. Gehen wir von der einfachsten möglichen Darstellung einer Textdatei aus, die eine englische Wortliste enthält: ASCII-Zeichensatz, ein Wort pro Zeile. Hier ist eine einfache Implementierung:
pub fn read_from_file<T: AsRef<Path>>(path: T) -> Result<Self, io::Error>
{
let file = File::open(path)?;
let reader = BufReader::new(file);
let words = reader.lines().map(|line| line.unwrap()).collect::<Vec<_>>();
let mut dictionary = Self::new();
dictionary.populate(&words);
Ok(dictionary)
}Im Grunde genommen schlürft read_from_file die gesamte Textdatei in den Speicher, teilt sie an den residenten Zeilentrennzeichen auf und verwendet dann populate, um die Dictionary zu erstellen. populate füllt die zugrunde liegende PrefixTreeSet schrittweise auf, ein Wort nach dem anderen, muss also den Baum wiederholt durchlaufen. Ehrlich gesagt, ist dies sogar für 70,000 Wörter schnell genug, aber wir können es besser machen. Nicht beim ersten Mal, nein, aber bei späteren Lesevorgängen in späteren Durchläufen der Anwendung. Und wie? Durch die Serialisierung und spätere Deserialisierung der PrefixTreeSet.
pub fn serialize_to_file<T: AsRef<Path>>(
&self,
path: T
) -> Result<(), io::Error>
{
let mut file = File::create(path)?;
let content = bincode::serialize(self)
.map_err(|_e| ErrorKind::InvalidData)?;
file.write_all(&content)?;
Ok(())
}
pub fn deserialize_from_file<T: AsRef<Path>>(
path: T
) -> Result<Self, io::Error>
{
let file = File::open(path)?;
let mut reader = BufReader::new(file);
let mut content = Vec::new();
reader.read_to_end(&mut content)?;
let dictionary = bincode::deserialize(&content)
.map_err(|_e| ErrorKind::InvalidData)?;
Ok(dictionary)
}Wir haben jetzt die ganze Bandbreite an Endpunkten für die Erstellung einer Dictionary. Wir können eine leere Dictionary erstellen, wir können sie aus einer bereits im Speicher befindlichen englischen Wortliste füllen, wir können sie aus einer Textdatei füllen, und wir können sie aus einer kompakten, übersichtlichen Binärdatei füllen. Aber wir haben durch die Bereitstellung all dieser Strategien eine gewisse Komplexität geschaffen. Also führen wir eine weitere Methode ein, um diese Komplexität zu zähmen und unsere API zu rationalisieren:
pub fn open<T: AsRef<Path>>(dir: T, name: &str) -> Result<Self, io::Error>
{
let dict_path = dir.as_ref().join(format!("{}.dict", name));
if dict_path.exists()
{
let dictionary = Self::deserialize_from_file(&dict_path);
trace!("Read binary dictionary: {}", dict_path.display());
dictionary
}
else
{
let txt_path = dir.as_ref().join(format!("{}.txt", name));
let dictionary = Self::read_from_file(&txt_path)?;
trace!("Read text dictionary: {}", txt_path.display());
match dictionary.serialize_to_file(&dict_path)
{
Ok(_) => trace!(
"Wrote binary dictionary: {}",
dict_path.display()
),
Err(e) => warn!(
"Failed to write binary dictionary: {}: {}",
dict_path.display(),
e
)
}
Ok(dictionary)
}
}Die Parameter auf open sind:
dir: DiePathzu dem Dateisystemverzeichnis, das das gewünschte englische Wörterbuch enthält, egal ob Text, Binärdatei oder beides.name: Der Name des Wörterbuchs auf der Festplatte, ohne jegliche Dateierweiterung.
Hier ist eine Illustration des Algorithmus, vereinfacht, um Fehlermodi außer Acht zu lassen:
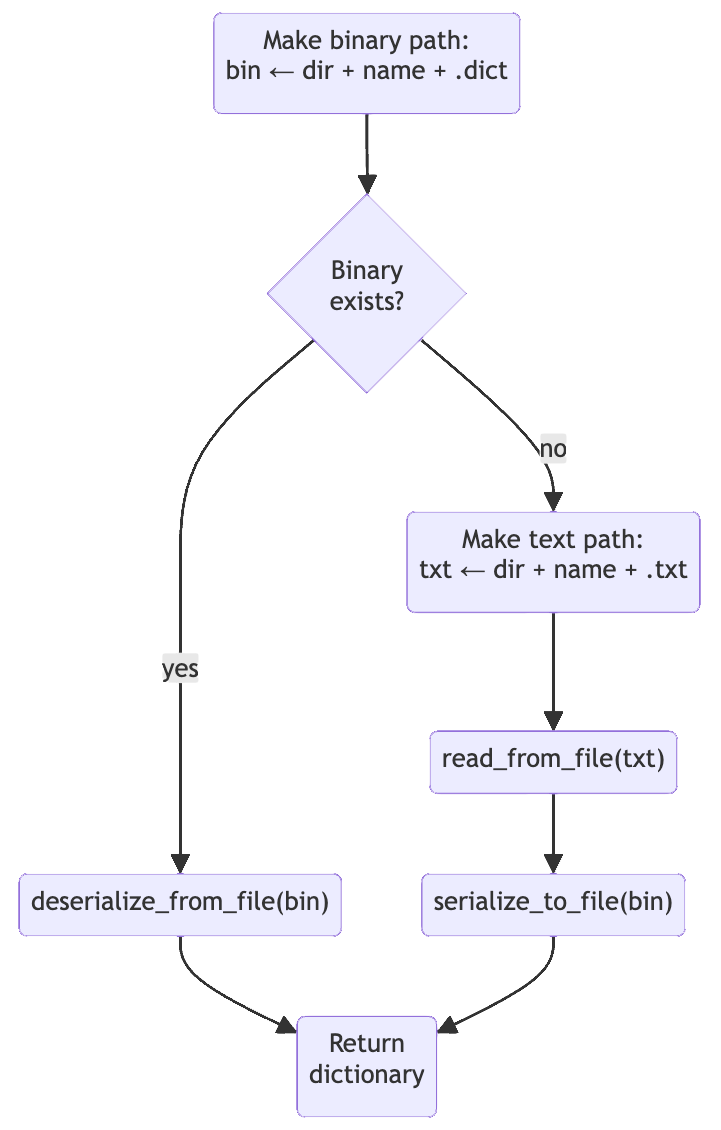
Das heißt, Sie suchen nach einer Datei mit dem Namen {dir}/{name}.dict und behandeln sie als serialisiertes Wörterbuch, falls sie existiert. Wenn ja, dann verwenden Sie sie. Ist dies nicht der Fall, suchen Sie nach einer Datei namens {dir}/{name}.txt und behandeln Sie diese als englische Wortliste im Klartext. Erstellen Sie das Wörterbuch aus der Textdatei und schreiben Sie dann die serialisierte Form auf {dir}/{name}.dict für einen späteren Durchlauf dieses Algorithmus. Die glücklichen Wege führen alle zu einem einsatzbereiten Dictionary.
Um sicherzustellen, dass alles funktioniert, fügen wir einige grundlegende Unit-Tests hinzu, die Sie am Ende der vollständigen
src/dictionary.rs
.
Benchmarking
Wenn Sie sich gefragt haben, ob die Deserialisierung einer echten Dictionary wirklich schneller ist als der Neuaufbau aus einer Textdatei, nun, das habe ich auch! Ich habe beschlossen, dies empirisch zu testen, indem ich einige Benchmarks erstellt habe.
Während Nightly Rust das Benchmarking direkt über das bench Attribut ist es schön, den stable Kanal zu verwenden, wo immer es möglich ist, denn das gibt uns das gute Gefühl, den sichersten Rust-Code zu schreiben. Glücklicherweise können wir unseren Code immer noch auf Cargo.tomlnatürlich. Wir fügen dies am Ende hinzu:
[dev-dependencies]
const_format = "0.2"
criterion = { version = "0.4", features = ["html_reports"] }
[[bench]]
name = "benchmarks"
harness = falseDer Bereich dev-dependencies zieht einfach einige Kisten heran, die wir für unsere Benchmarks verwenden möchten.
Der Abschnitt [[bench]] ist wichtiger, denn hier erfahren Sie mehr über cargo bench, dem Benchmark-Runner, wo unsere Benchmarks zu finden sind und wie sie ausgeführt werden können. Wir verwenden name, um sicherzustellen, dass der Runner nach unseren Benchmarks in benches/benchmarks.rs. Wir setzen harness auf false, um die libtest Kabelbaum, der es uns ermöglicht, unsere eigene main Funktion bereitzustellen und so eine feinkörnige Kontrolle darüber zu erhalten, wie unsere Benchmarks organisiert, konfiguriert und ausgeführt werden.
Jetzt ist alles richtig konfiguriert. Wenden wir uns also den Benchmarks zu.
Textdatei-Benchmark
Lassen Sie uns zunächst einen Benchmark für die Erstellung einer Dictionary aus einer Textdatei erstellen. Der Test selbst ist recht klein, aber wegen der Dependency Injection ziemlich komplex:
fn bench_read_from_file<M: Measurement>(g: &mut BenchmarkGroup<M>)
{
g.bench_function("read_from_file", |b| {
b.iter(|| Dictionary::read_from_file(path_txt()).unwrap());
});
}criterion::measurement::Measurement abstrahiert über die denkbaren Metriken für das Benchmarking - Wandzeit, Speichernutzung, Energieverbrauch usw. Stand zum Zeitpunkt der Erstellung dieses Artikels, criterion::measurement::WallTime ist jedoch der einzige unterstützte Benchmark; das ist in Ordnung, denn das ist es, was wir messen wollen. Verwandte Benchmarks sind in Instanzen von criterion::BenchmarkGroup, so dass die Konfiguration zusammengefasst werden kann. bench_function akzeptiert einen Identifikator ("read_from_file") und ein FnMut, wobei ein criterion::Bencher die den eigentlichen Benchmark wiederholt ausführen kann über iter. Wie erwartet, lautet die zu testende Funktion Dictionary::read_from_file.
path_dict ist nur eine triviale Hilfsfunktion, die den Dateisystempfad zu der englischen Wortliste liefert:
#[inline]
#[must_use]
const fn path_txt() -> &'static str
{
concatcp!(dir(), "/", name(), ".txt")
}
#[inline]
#[must_use]
const fn dir() -> &'static str
{
"dict"
}
/// The name of the dictionary file.
#[inline]
#[must_use]
const fn name() -> &'static str
{
"english"
}const_format::concatcp führt zur Kompilierzeit eine String-Konvertierung und Verkettung von primitiven Typen durch. Wir nutzen dies, um eine gewisse Abstraktion zu erreichen, ohne den Vorteil der harten Kodierung von String-Literalen zu verlieren.
Beachten Sie, dass bench_read_from_file den Benchmark nicht ausführt. Vielmehr definiert er ihn und installiert ihn in der angegebenen BenchmarkGroup. Wir müssen dem Benchmark-Manager mitteilen, dass er unsere Gruppen ausführen soll, was wir weiter unten in main tun werden.
Binärdatei-Benchmark
Da Sie bench_read_from_file bereits gesehen haben, können Sie den parallelen Benchmark wie ein Champion lesen:
fn bench_deserialize_from_file<M: Measurement>(g: &mut BenchmarkGroup<M>)
{
g.bench_function("deserialize_from_file", |b| {
b.iter(|| Dictionary::deserialize_from_file(path_dict()).unwrap());
});
}
#[inline]
#[must_use]
const fn path_dict() -> &'static str
{
concatcp!(dir(), "/", name(), ".dict")
}Die Boilerplate ist identisch, aber wir testen stattdessen Dictionary::deserialize_from_file.
Alles verdrahten
Da wir die Verantwortung für main übernommen haben, liegt die Definition von BenchmarkGroup in unserer Verantwortung. Unsere Funktion main verdrahtet alles miteinander und führt die Benchmarks aus:
fn main()
{
// Ensure that both the text and binary files exist.
let _ = Dictionary::open(dir(), name()).unwrap();
// Run the benchmarks.
let mut criterion = Criterion::default().configure_from_args();
let mut group = criterion.benchmark_group("benchmarks");
group.measurement_time(Duration::from_secs(30));
bench_read_from_file(&mut group);
bench_deserialize_from_file(&mut group);
bench_solver(&mut group);
group.finish();
// Generate the final summary.
criterion.final_summary();
}criterion::Criterion ist der Benchmark-Manager. Wir erstellen einen einfachen Manager und verwenden benchmark_group um die BenchmarkGroup zu erstellen, mit der sich bench_read_from_file und bench_deserialize_from_file registrieren. Wir verwenden measurement_time um jeden Test so oft wie möglich in 30 Sekunden durchzuführen. finish verbraucht die BenchmarkGroup, führt die einzelnen Benchmarks aus und fügt die zusammenfassenden Berichte dem Benchmark-Manager zu, der sie erstellt hat. Zum Schluss erstellt final_summary die endgültige Zusammenfassung und gibt sie aus.
Urteil
Hier ist die vereinfachte Ausgabe von cargo bench für meine Hardware:
Running benches/benchmarks.rs
benchmarks/read_from_file
time: [29.051 ms 29.092 ms 29.133 ms]
benchmarks/deserialize_from_file
time: [24.011 ms 24.058 ms 24.105 ms]Dictionary::deserialize_from_file ist durchgängig etwa 5 ms schneller als Dictionary::read_from_file, was in Computerzeit ausgedrückt sehr viel ist. In Wandzeit ausgedrückt, ist das nicht viel, aber es ist definitiv und zuverlässig schneller, eine Dictionary zu deserialisieren, als sie aus einer englischen Wortliste im Klartext zu erstellen. Das ist ein Gewinn, und ich nehme ihn an.
Das Englisch-Wörterbuch
Eine letzte Anmerkung zum Englisch-Wörterbuch selbst. Wenn Sie sich dafür interessieren, wie ich das englische Wörterbuch, das ich mit dem Projekt gebündelt habe, erstellt und kuratiert habe, lesen Sie dict/README.md. Die Methodik sowie die relevanten Copyrights und Namensnennungen sind darin enthalten.
Das war's für diese Ausgabe. Das nächste Mal werden wir den Solver selbst bauen. Bleiben Sie dran für den nächsten Blogbeitrag in dieser Serie!
Verfasst von
Todd Smith
Rust Solution Architect at Xebia Functional. Co-maintainer of the Avail programming language.
Unsere Ideen
Weitere Blogs

Wo die GitHub Copilot Erweiterungspunkte die Governance brechen
Viele der jüngsten Ergänzungen des GitHub Copilot-Ökosystems bieten einen echten Mehrwert für einzelne Entwickler, erweitern aber auch die...
Rob Bos


Contact