Blog
Optimieren von Flink SQL: Joins, Zustandsverwaltung und effizientes Checkpointing

In der schnelllebigen Welt der Datenverarbeitung sind Effizienz und Zuverlässigkeit von größter Bedeutung. Apache Flink SQL bietet leistungsstarke Tools für die Bearbeitung von Batch- und Streaming-Aufträgen, aber die Optimierung von Joins, Statusverwaltung und Checkpointing kann die Stabilität und Leistung Ihrer Aufträge erheblich verbessern. Dieser Leitfaden führt Sie durch die besten Methoden, um mit Flink SQL eine optimale Leistung zu erzielen.
Flink SQL ist eine Abfrage- und Verarbeitungs-Engine, die die Entwicklung von Batch- und Streaming-Aufträgen beschleunigt. Es verarbeitet Aufgaben wie Joins, Aggregationen, Ranks, Mustervergleiche und mehr und bietet dank seiner zustandsabhängigen Verarbeitungsfunktionen Fehlertoleranz, Robustheit und Skalierbarkeit.
Der Status eines Flink-Auftrags entwickelt sich ständig weiter. Zu jedem Zeitpunkt wird der abgeschlossene Zustand des Auftrags als Kontrollpunkt oder Speicherpunkt bezeichnet. Mit dieser Funktion können Sie einen Auftrag von einem Kontrollpunkt aus wiederherstellen, wenn er fehlschlägt, ähnlich wie bei Videospielen.
Der Checkpoint-Mechanismus funktioniert, indem er in regelmäßigen Abständen Barrieren aussendet, die die Pipeline durchlaufen. Wenn eine Barriere eine Teilaufgabe erreicht, wird der Status des Operators serialisiert und extern gespeichert. Ein abgeschlossener Checkpoint enthält die von allen Operatoren gesammelten Zustandsdaten sowie die Daten während des Fluges und kann für eine Wiederherstellung, ein Upgrade oder die Wiederaufnahme eines Auftrags verwendet werden.
Effizientes und zuverlässiges Checkpointing ist entscheidend für die Stabilität und Leistung von Aufträgen. Wenn es falsch implementiert ist, kann es zu einem verringerten Pipeline-Durchsatz, erhöhter Latenz oder sogar zu Auftragsausfällen führen und den Fortschritt stoppen. In diesem Artikel gebe ich Ihnen einige Hinweise zur Optimierung des Checkpointing, wobei ich mich auf einen in Flink SQL geschriebenen Beispielauftrag konzentriere.
Kontrollpunkte und Erste Hilfe
Standardmäßig werden Checkpoint-Barrieren mit der Datenverarbeitung synchronisiert, d.h. ein Checkpoint wird erst dann als abgeschlossen betrachtet, wenn der Auftrag alle vor der Checkpoint-Barriere gepufferten Daten verarbeitet hat. Dieser Ansatz kann jedoch aufgrund von Faktoren wie einer komplexen Pipeline, die aus mehreren Tasks inline aufgebaut ist, IO-Operationen, großen Puffern oder Datenverzerrungen, die den Auftragsdurchsatz einschränken und die Verarbeitungszeit von der Quelle bis zur Senke beeinflussen können, langsam sein. In solchen Fällen kann die Aktivierung von nicht ausgerichteten Prüfpunkten von Vorteil sein. Ein nicht ausgerichteter Checkpoint ermöglicht es der Checkpoint-Barriere, die Daten in den Puffern zu überholen und sie als Teil des Checkpoints als In-Flight-Daten zu speichern.
Wenn das State Backend eines Auftrags von RocksDB verwaltet wird, kann die Aktivierung inkrementeller Checkpoints ebenfalls von Vorteil sein. Inkrementelle Checkpoints minimieren einen seriellen Zustand, indem sie nur Deltas zwischen aufeinanderfolgenden Checkpoints aufbewahren. Es ist jedoch anzumerken, dass die Aktivierung inkrementeller Checkpoints die Startzeit des Auftrags beeinträchtigen kann. Das liegt daran, dass ein Zustand aus fragmentierten Teilen wiederhergestellt werden muss, was die Initialisierungsphase des Auftrags verlangsamt.
Halten Sie den Staat klein
Scheitern Checkpoints an der Größe des Status? Sind Ihre Operationen langsam, weil der Zugriff auf den Status bzw. das Schreiben darauf zu lange dauert? Lassen Sie uns das optimieren!
Identifizieren Sie Schwerarbeiter
Flink bietet viele nützliche Metriken zur Überwachung des Checkpointing und zur Diagnose von Problemen. Beginnen wir mit der Identifizierung von schweren Aufgaben und Operatoren. Am einfachsten geht dies über die Flink-Benutzeroberfläche. Navigieren Sie zur Registerkarte Checkpoints, wo Sie detaillierte Informationen finden, wie z.B:
- Checkpoint-Typ (ausgerichtet/unausgerichtet): Flink startet den Checkpoint immer als ausgerichtet, aber er wird zu einem nicht ausgerichteten Checkpoint, wenn er die Zeitüberschreitung für den ausgerichteten Checkpoint überschreitet und das nicht ausgerichtete Checkpointing aktiviert ist.
- [Full] Größe der Checkpoint-Daten: Dies beinhaltet die Größe des Prüfpunkts. Bei inkrementellen Checkpoints (nur RocksDB) können Sie Delta- und vollständige Datengrößen vergleichen.
- Verarbeitete (persistierte) Daten während des Fluges: Nicht ausgerichtete Checkpoints können Daten, die im Checkpoint persistiert werden sollen, überholen, was einen Kompromiss zwischen Checkpoint-Zeit und IO-Operationen darstellt.
- Ende-zu-Ende-Dauer: Dies ist die Dauer zwischen der Freigabe der Schranke an der Quelle und der Speicherung des Status des Bedieners.
Im Falle von Datenschiefständen werden Sie feststellen, dass einige Teilaufgaben mehr Zeit für die Verarbeitung von Checkpoint-Barrieren benötigen, insbesondere bei der Verwendung von ausgerichteten Checkpoints. Außerdem kann der Status dieser Teilaufgaben erheblich größer sein. Dieser Artikel konzentriert sich zwar auf die Größe von Checkpoints, aber es ist wichtig zu wissen, dass auch Datenschiefstände Auswirkungen auf das Checkpointing haben können.
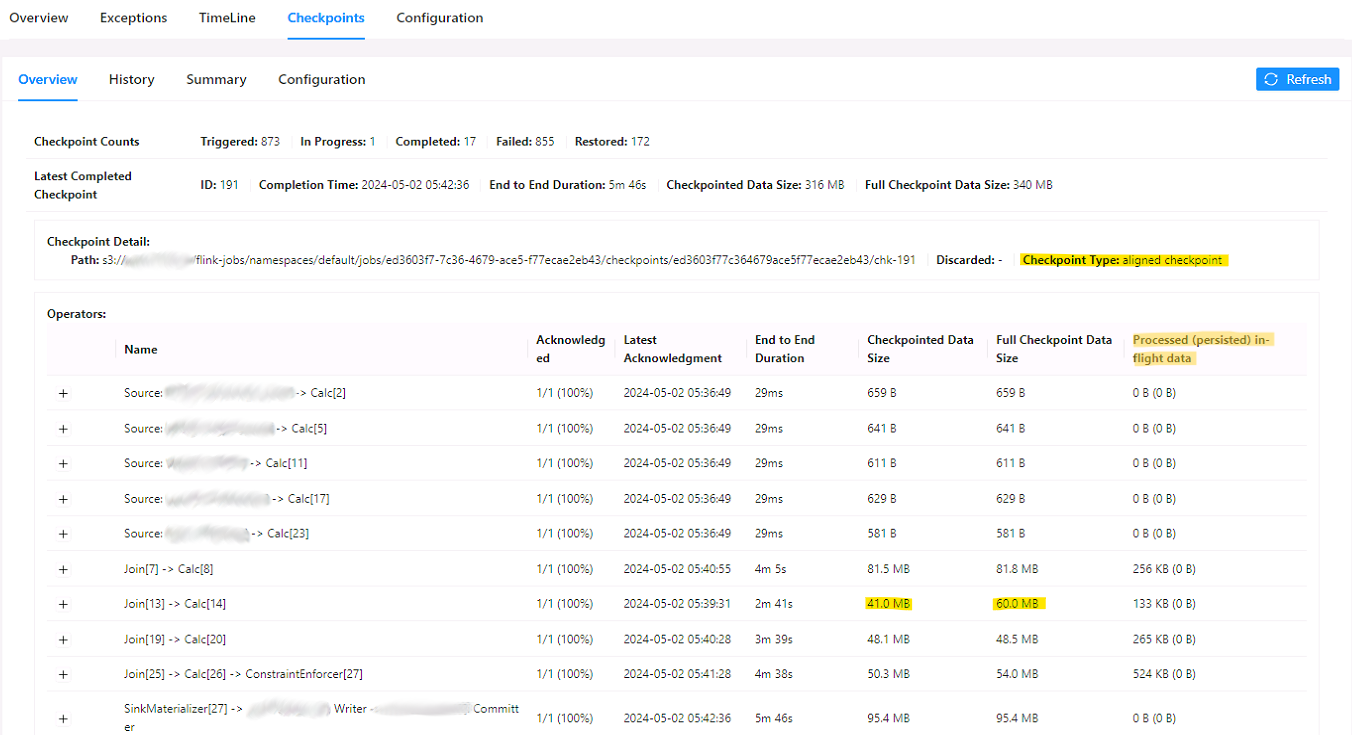
Da wir nun wissen, wie wir die Statusgröße der Operatoren überprüfen können, lassen Sie uns den Anwendungsfall Job analysieren.
Auftrag zur Datenanreicherung
Der Kunde benötigt eine Left-Join-Operation zwischen der Haupttabelle TABLE_A und 8 Wörterbüchern (DICT_[1-8]) sowie die Ausgaben von 3 weiteren Flink-Jobs (JOB_[1-3]). Das gewünschte Ergebnis sind denormalisierte Daten, die sich für die Speicherung in einem Warehouse zu Berichtszwecken eignen. Dieses Szenario stellt eine typische Datenanreicherung dar.
Im Folgenden finden Sie eine kurze Analyse der in der Tabelle aufgeführten Eingabedaten: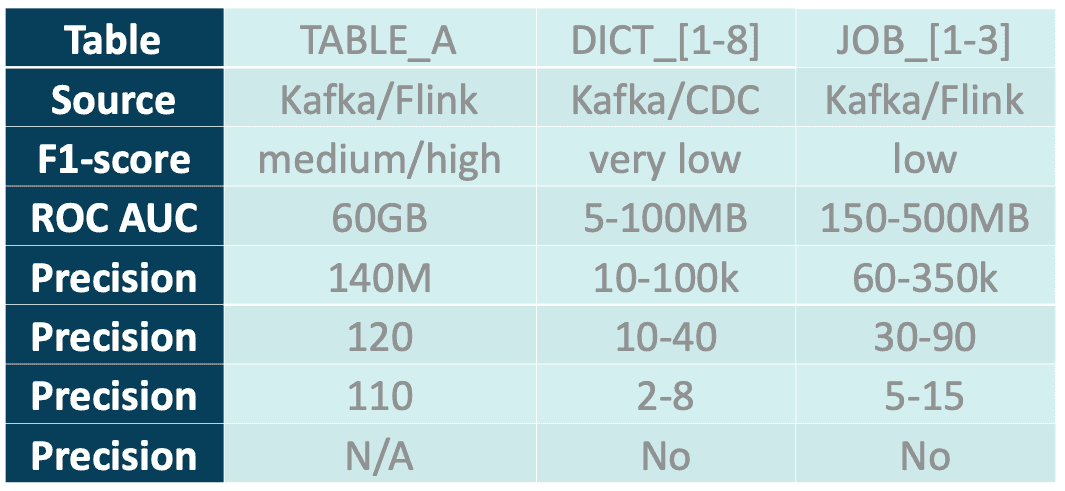
- Source: Indicates the source of the data.
- Kafka/Flink - Daten, die von einem anderen Flink-Auftrag als Änderungsprotokoll erzeugt und von einem Upsert-Kafka-Connector gespeichert werden.
- Kafka/CDC: Daten, die als Änderungsdatenerfassung (CDC) erzeugt werden, zum Beispiel von Debezium.
- Ratenhöhe der eingehenden Daten: Vereinfachte Ratenhöhe der eingehenden Daten.
- Ursprüngliche Größe/Zeilenzahl: Die Größe/Zeilenzahl des Kafka-Topics nach dem Laden des anfänglichen Snapshots (CDC) oder der Verarbeitung von Daten durch andere Flink-Jobs.
- Spalten in der Tabelle: Anzahl der Felder im Schema der Nachricht bzw. in der Spalte der Tabelle.
- Erforderliche Spalten: Anzahl der für den Auftrag erforderlichen Spalten.
- Benötigt die neueste Version - wenn Aktualisierungen auf verarbeitete Daten übertragen werden müssen (nur für Tabellen auf der rechten Seite)
Die erste (naive) Implementierung - reguläre Verknüpfung
Der erste Ansatz besteht darin, eine reguläre Verknüpfung zu verwenden. Diese Methode ist einfach zu implementieren: Es gibt keine Einschränkungen bei der Verknüpfungsbedingung, und es ist kein Wasserzeichen oder Datenabgleich erforderlich. Sie kann sowohl Eins-zu-Eins- als auch Eins-zu-Viel-Beziehungen berücksichtigen. Ein einzigartiges Merkmal regulärer Verknüpfungen ist ihre Fähigkeit, Ereignisse zu erzeugen, wenn auf der rechten Seite der Verknüpfung Änderungen auftreten.
Ich habe die DAG abgeschnitten, um die wesentlichen Operatoren hervorzuheben.
Bei der Untersuchung der Metriken für die Zustandsgröße habe ich schwere Operatoren identifiziert:

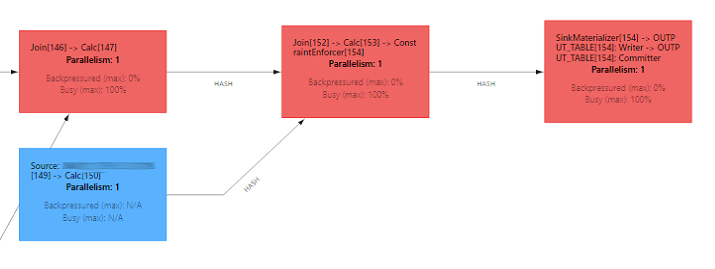
- ChangelogNormalize
Der upsert-kafka-Konnektor wandelt Kafka-Nachrichten in einen Changelog-Stream um. Durch die Verwendung des Primärschlüssels und des Zustands der verarbeiteten Nachrichten kann er Typen wie Insert/Update/Delete erkennen und die UpdateBefore-Zeile konstruieren. - Join
Der reguläre Join muss sowohl die linke als auch die rechte Seite des Joins im Status halten. Er findet Übereinstimmungen und gibt verbundene Zeilen frei. Insbesondere in Szenarien mit eins-zu-vielen-Beziehungen kann dies zu einer Datenexplosion führen, wenn ein Ereignisoperator Tausende von verknüpften Daten freigibt.
Zeilen werden standardmäßig für immer im Status gehalten. Dieses Verhalten kann jedoch mit dem Parameter table.exec.state.ttl geändert werden, der es ermöglicht, den Zustand nach einer bestimmten Zeit zu bereinigen. Ab Flink 1.18 kann die TTL auf Operator-State-Ebene konfiguriert werden. Mit Flink 1.19 wird dieser Prozess durch die Einführung des Sql-Hinweises STATE_TTL weiter vereinfacht. Es ist wichtig, die Zustandsbereinigung mit Vorsicht zu verwenden, da sie die vom Operator erzeugten Daten beeinflussen kann! - SinkMaterializer
Dieser Operator behandelt Race Conditions zwischen Teilaufgaben. Der Algorithmus ist zwar gut erklärt, aber er hat auch seine Grenzen. Zum Beispiel funktioniert er nicht mit dynamischen Spalten (z.B. CURRENT_TIMESTAMP). Außerdem erfordert er einen vollständigen Changelog-Stream mit UpdateBefore-Ereignissen, eine Bedingung, die durch Operatoren wie temporale Joins nicht immer gewährleistet werden kann.
In meiner Pipeline habe ich 4 Quellen mit ChangelogNormalize, was nur für TABLE_A besonders schwer ist. Diese größte Tabelle muss von jedem der 11 Joins verarbeitet werden. Schließlich ist da noch SinkMaterializer. Wie Sie sehen können, muss ich TABLE_A in 13 Operatoren verwalten, was nach der Verarbeitung der Anfangsdaten zu einem Status von etwa 780 GB führt. Dies ist nur eine Schätzung - einige Objekte werden dedupliziert, und die anderen Tabellen habe ich nicht berücksichtigt. Die endgültige Größe der serialisierten und komprimierten Objekte in RocksDB kann geringer sein, aber insgesamt ist es immer noch mehr als ein halbes Terabyte.
Es ist möglich, eine solche Pipeline zu optimieren, indem Sie:
- Begrenzung der Spalten in der Quelle. Die Einschränkung der aus der Quelle abgerufenen Spalten kann die Menge der von ChangelogNormalize gespeicherten und nachgelagert verarbeiteten Daten reduzieren.
- Begrenzung von Joins mit der größten Tabelle. Durch die Verknüpfung kleinerer Tabellen mit der Haupttabelle kann die Anzahl der Verknüpfungen mit der größten Tabelle minimiert werden. Dies kann erreicht werden, indem Sie Ansichten erstellen oder Common Table Expressions (CTEs) verwenden, um kleinere Tabellen zu verbinden, bevor Sie sie mit der Haupttabelle verbinden.
- Intelligente Reihenfolge der Verknüpfungen in der Abfrage. Ordnen Sie die Verknüpfungen in der Abfrage an, um die Leistung zu optimieren. Flink-Planer erledigt das nicht für Sie! Da die Ausgabe jeder Verknüpfung von nachgeschalteten Operatoren verarbeitet werden muss, sollten Sie die schwersten Verknüpfungen an das Ende der Sequenz setzen. Dadurch wird sichergestellt, dass die leichteren Operationen zuerst ausgeführt werden, was die gesamte Rechenlast verringern kann.
Wie hat der Job funktioniert? Zunächst schien alles in Ordnung zu sein: Die Puffer füllten sich schnell mit Daten, und der Status begann zu wachsen. Doch nach der ersten Stunde nahm der Pipeline-Durchsatz deutlich ab, und die Checkpoints brauchten Minuten, um abgeschlossen zu werden. Die Bearbeitung des Status verbrauchte eine beträchtliche Menge an CPU-Ressourcen und wurde langsam. Später begann der Auftrag aufgrund von Checkpoint-Timeouts zu scheitern und konnte nicht mehr fortgesetzt werden. Angewandte Optimierungen halfen zwar ein wenig, aber sie verschoben die Timeouts nur. Habe ich schon erwähnt, dass dieses Verhalten nach der Optimierung von RocksDB und Checkpointing auftrat? Eine Katastrophe!
Nachschlagen verbinden
Die Hauptursache für die Zeitüberschreitungen beim Checkpointing ist der große Zustand der regulären Joins. Daher kam ich auf die Idee, sie durch zustandslose Lookup-Join-Operatoren zu ersetzen. Aber wie funktioniert das?
Die Lookup-Verknüpfung erweitert eine Tabelle um Daten, die aus einem externen Speicher abgefragt werden. Er kann zur Modellierung von Eins-zu-Eins- und Eins-zu-Viel-Beziehungen verwendet werden, bei denen keine Notwendigkeit besteht, auf Aktualisierungen von der rechten Seite des Joins zu reagieren. Eine Wörterbuch-Tabelle ist ein hervorragender Kandidat für einen Lookup-Join. Es handelt sich um eine Dimensionstabelle, die sich nur langsam ändert, und der Datenabgleich sollte kein Problem sein. Folglich können die Werte vom Operator zwischengespeichert werden.
Lookup Join bietet mehrere Vorteile. Die Verknüpfung wird an Ort und Stelle ausgeführt, ohne dass die Daten neu gemischt werden, was sie unempfindlich gegen Datenschiefstände macht. Einer der wichtigsten Vorteile ist, dass Lookup Join ein zustandsloser Operator ist.
Ich habe Wörterbücher in eine Datenbank importiert, sie mit Flink verbunden und den Auftrag erstellt. SinkMaterializer wurde aufgrund seiner Einschränkungen deaktiviert (table.exec.sink.upsert-materialize) und durch die Funktion Rank ersetzt.
Ergebnisse
Der Auftrag war stabil, skalierbar und performant. Lookup-Joins mit Zwischenspeicherung (mit einem 1-minütigen Ablauf-Timeout nach dem Schreiben) haben gut funktioniert. Flink verkettete alle Lookups in einem Operator und führte alles an Ort und Stelle aus, ohne Daten zu übertragen. Als Nebeneffekt verschwand die Datenschieflage bei Joins mit Wörterbüchern.
Acht schwere Joins wurden durch zustandslose Operatoren ersetzt. Der Auftrag enthielt immer noch einige schwere Operatoren:
- ChangelogNormalisieren für TABLE_A
- Zwei reguläre Verbindungen, und
- Rangfunktion am Ende.
Diese Zahl hätte noch weiter reduziert werden können, aber der Kunde hat die Lösung mit dem externen Speicher nicht akzeptiert. Für diese Entscheidung gab es zwei Gründe: Der Kunde wollte den Speicher nicht überlasten und den Flink-Auftrag nicht von einem externen Dienst abhängig machen.
Schritt zurück - Zeitliche Verbindung
Der Kunde hat sich gegen eine Lösung mit einem Lookup-Join entschieden. Eine andere Möglichkeit ist eine temporale Verknüpfung, bei der nur die rechte Seite im Status bleibt. Die temporale Verknüpfung ist mit einigen Einschränkungen verbunden:
- Es erfordert gut definierte Wasserzeichen/Datenausrichtung.
- Es kann nicht für eins-zu-viele-Beziehungen verwendet werden.
- Für die Deduplizierung ist ein Primärschlüssel in der rechten Tabelle erforderlich, der für die Verknüpfungsbedingung verwendet wird. Alternativ kann eine temporäre Ansicht mit einem neu definierten Schlüssel verwendet werden, die nur den Datenstrom und nicht das Änderungsprotokoll unterstützt.
Zum Glück konnte ich diese Bedingungen erfüllen. Die CDC-Daten enthalten Audit-Daten und können für den Datenabgleich verwendet werden, und die Verknüpfungsbeziehung ist in meinem Fall eins-zu-eins.
Aufgrund der Datenschieflage musste ich einige Vorverarbeitungen vornehmen, bevor ich die Wörterbücher mit der Haupttabelle verbinden konnte. Ich habe diese Methode als Pseudo-Broadcast-Join bezeichnet und sie hier beschrieben.
Diese Technik arbeitet mit einer zeitlichen Ansicht, die nur auf einem Append-Only-Stream aufgebaut werden kann. Aufgrund dieser Einschränkung musste ich das Changelog von CDC-Ereignissen vorher konvertieren. Dies kann in PyFlink geschehen, indem der Datenstrom als View zurück in Flink SQL exportiert wird. Ein Beispielcode ist in der folgenden Auflistung enthalten.
Beachten Sie, dass der Code DELETE-Ereignisse überspringt, was vielleicht nicht immer sinnvoll ist.
# PyFlink 1.16.1
from pyflink.table import Row, Schema
from pyflink.table.types import RowKind
from pyflink.common.typeinfo import RowTypeInfo, Types
from pyflink.datastream import FlatMapFunction
class AppendOnlyConverter(FlatMapFunction):
def flat_map(self, row: Row):
# ignore DELETE and UPDATE_BEFORE
if row.get_row_kind() in (RowKind.INSERT, RowKind.UPDATE_AFTER):
yield Row(op_type=RowKind.INSERT, **row.as_dict())
# read from table
source_table = table_env.sql_query(f"SELECT * FROM {table_name}")
# table to stream
source_stream = table_env.to_changelog_stream(source_table)
output_type = Types.ROW_NAMED(fields, types) # the same as input
output_schema = Schema.new_builder() \
.column("ID", "BIGINT NOT NULL") \
# the other columns, may be only a subset of input
.watermark("LAST_UPDATE_DATE", "LAST_UPDATE_DATE - INTERVAL '5' SECONDS") \
.build()
# converting changelog to append-only stream
output_stream = source_stream.flat_map(AppendOnlyConverter(), output_type=output_type)
# exposing datastream as view back to Flink SQL
output_table = table_env.from_data_stream(output_stream, output_schema)
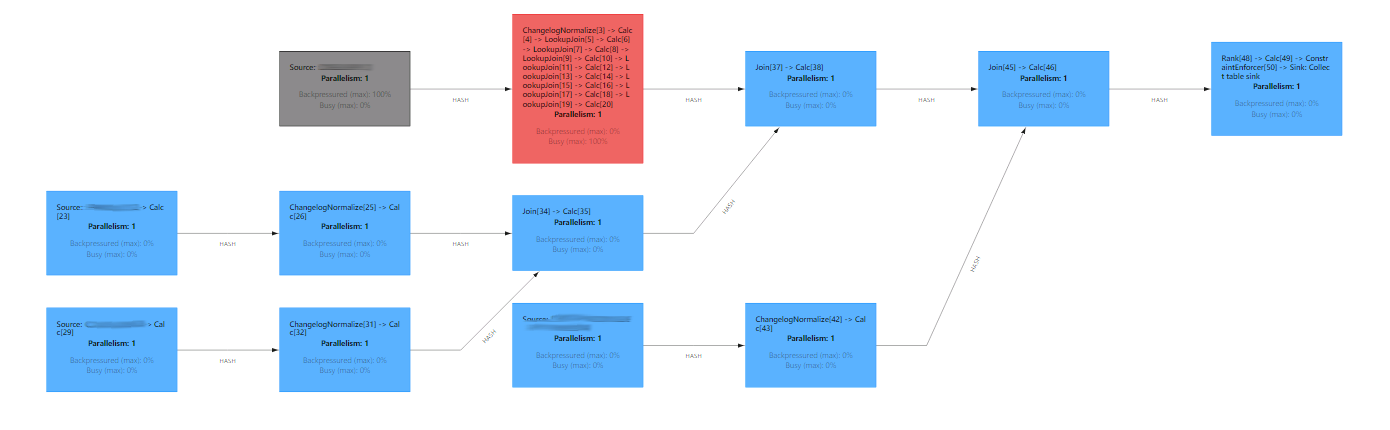
table_env.create_temporary_view(output_table_name, output_table)Nachdem ich diese Änderungen vorgenommen habe, sieht mein Auftrag wie das folgende Diagramm aus. Er umfasst 11 zeitliche Verknüpfungen in Folge, wobei die Haupttabelle gelb hervorgehoben ist.
Der Deduplizierungsoperator ist eine Komponente der temporalen Ansicht, die für die Verfolgung von Zeilenaktualisierungen verantwortlich ist. Trotz der Verwendung des Status bleibt er für Dictionaries klein.
Ich habe den Connector von upsert-kafka auf kafka für TABLE_A umgestellt. Das Ergebnis war, dass Flink einen Datenstrom anstelle eines Changelogs ohne schweres ChangelogNormalize erstellte. Ich konnte dies tun, weil für TABLE_A keine DELETE-Ereignisse erzeugt wurden und für die linke Tabelle im temporalen Join keine Deduplizierung erforderlich ist.
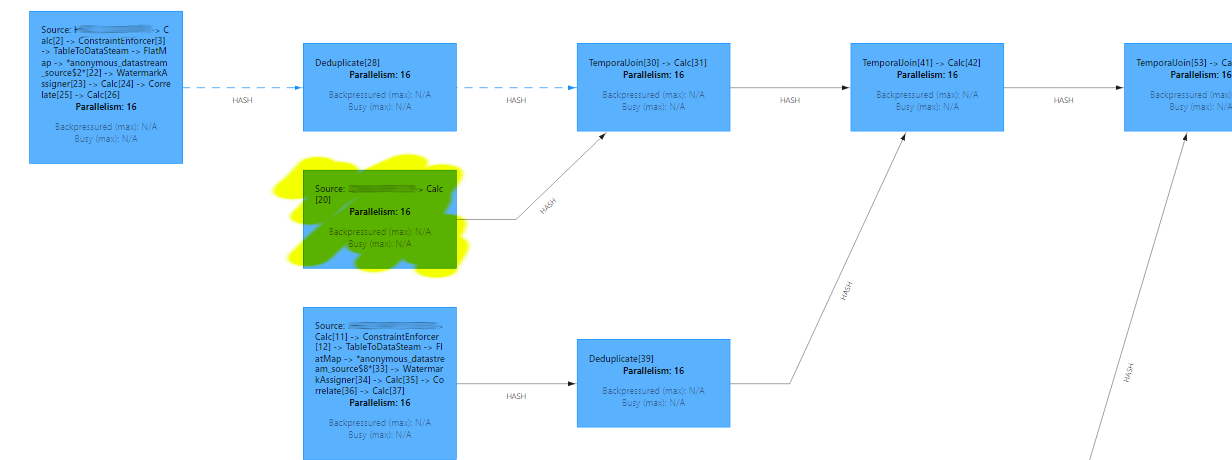
Beachten Sie, dass die Pipeline eine Sortierung erfordert, um Race Conditions zu vermeiden. Ursprünglich wollte ich dies mit der Flink Rank-Funktion bewerkstelligen, aber ich habe mich dafür entschieden, diese Aufgabe an das Warehouse zu delegieren.
Eine alternative Lösung zur Reduzierung des Rank-Status ist die Verwendung des TTL-Parameters für den Status auf Operator-Ebene (veröffentlicht in Flink 1.18). Dieser Parameter legt fest, wie lange der Status eines Schlüssels beibehalten wird, ohne dass er aktualisiert wird, bevor er entfernt wird. Anstatt den gesamten Status beizubehalten, um Race Conditions aufzulösen, müssen nur die jüngsten Werte aufbewahrt werden.
Ergebnisse
Der Auftrag ist stabil. Es gibt keine schweren Operatoren, und der Checkpoint wird in fast konstanter Zeit (einige Sekunden) erstellt. Die Gesamtgröße des Checkpoints liegt unter 4 GB! Das ist etwa 200 Mal kleiner als die geschätzte Größe des Status für denselben Auftrag mit regulären Joins, der nicht einmal den gesamten Datensatz verarbeiten konnte.
Zusammenfassung
Wenn es um die Größe des Zustands geht, sind die Lookup-Joins entscheidend. Verkettete Joins an Ort und Stelle mit Cache sind viel leistungsfähiger als temporale Joins in Reihe, die immer noch viel zustandseffizienter sind als reguläre Joins. Die Verarbeitung eines Changelogs anstelle eines reinen Append-Streams ist mit Kosten verbunden, die nicht immer notwendig sind. Außerdem können SQL-Abfragen, selbst wenn sie semantisch gleichwertig sind, zu unterschiedlichen Abfrageplänen und DAGs führen, die von Flink SQL erstellt werden, was die Leistung erheblich beeinträchtigt.
In diesem Blogbeitrag habe ich Ihnen einige Tipps und Tricks zur Minimierung des Auftragsstatus gegeben, angefangen bei der Ermittlung der schwersten Operatoren und deren Ersetzung durch geeignetere Alternativen. Es ist zwar nicht immer möglich, dies zu tun, aber in den meisten Fällen ist es machbar. Im Ergebnis wird Ihr Auftrag stabil sein, nach einem Ausfall schnell wieder anlaufen und weniger Ressourcen verbrauchen. Sie werden auch eine Leistungssteigerung feststellen. Checkpointing ist ein wichtiger Bestandteil eines Flink-Auftrags und darf nicht vernachlässigt werden.
Sind Sie bereit, Ihre Flink-SQL-Aufträge für bessere Leistung und Zuverlässigkeit zu optimieren? Melden Sie sich noch heute für eine kostenlose Beratung durch unsere Experten an.
Verfasst von
Maciej Maciejko
Unsere Ideen
Weitere Blogs




Contact