Blog
Beobachtbarkeit in der Praxis: wissen, wann man handeln muss

Zu wissen, wann man handeln muss, ist ein wichtiger Aspekt von Observability. Vielleicht haben Sie viele einzelne Metriken, von denen einige zum Beispiel eine Fehlerquote anzeigen. Sie könnten geneigt sein, einen Alarm für diese Fehlerraten einzurichten und sofort jemanden damit zu beauftragen, sie zu untersuchen, wenn sie ansteigen oder nicht bei Null liegen. Aber ein einzelner Fehler kann aus einer Vielzahl von Gründen auftreten, von denen viele nicht leicht zu erkennen sind und von den Endbenutzern nicht einmal bemerkt werden. Was wäre, wenn ich Ihnen sagen würde, dass Sie nicht auf jeden einzelnen Fehler reagieren müssen?
Von SRE lernen, die Theorie
Unabhängig davon, ob Sie SRE praktizieren oder nicht, bietet es eine hilfreiche Struktur zur Kategorisierung von Metriken, nämlich Service Level Indicators (SLIs), Service Level Objectives (SLOs) und Service Level Agreements (SLAs). Diese können verwendet werden, um objektiv anzuzeigen, wann Sie handeln müssen.
Service Level Indikatoren (SLIs)
- Sind einzelne Metriken, Abfragen, Log-Ereignisse, alles, was Sie wahrscheinlich bereits sammeln.
- Zum Beispiel: Anzahl der abgeschlossenen Bestellungen, Transaktionen oder einfach nur 5xx-Fehler.
- Werden verwendet, um zu berechnen, ob Ihre SLOs erfüllt sind.
Service Level Zielsetzungen (SLOs)
- Sind Ihr Zuverlässigkeitsziel. Wenn Sie z.B. einen Webshop haben, in dem Benutzer die Details eines Produkts ansehen können: 99,5% aller Ansichten von Produktdetails sollten erfolgreich sein.
- werden als Team oder Organisation festgelegt, aber aus der Perspektive des Endverbrauchers gemessen. Hier geht es nur um die Wahrnehmung. Ein Endbenutzer sollte theoretisch in der Lage sein, dies selbst zu messen und zu der gleichen Zahl zu kommen.
- Sie beziehen sich auf eine Zeitspanne, z.B. einen Tag, eine Woche oder einen Monat.
- Werden mit SLIs gemessen.
Service Level Agreements (SLAs)
- Sind eine vertragliche SLO mit Endnutzern. In der Regel nur im B2B-Bereich anwendbar, z. B. bei der Gewährleistung der Verfügbarkeit eines SaaS-Dienstes.
Die Theorie hinter diesen Kategorien ist, dass die Wahrnehmung Ihrer Endnutzer die wichtigste Messgröße ist. Wenn Ihre Endbenutzer Ihren Service als zuverlässig wahrnehmen, sind sie zufrieden und werden Ihre Dienste eher weiter nutzen. Endbenutzer nehmen keine 100%ige Zuverlässigkeit wahr, da auch jeder andere Dienst in der Kette nicht 100%ig zuverlässig ist. So können beispielsweise ihre WiFi-Verbindung, ihr Internetanbieter oder ihr Telefon ausfallen, bevor sie einen Fehler bei Ihnen bemerken. Wenn ein solcher Fehler auftritt, werden sie es wahrscheinlich erneut versuchen. Die Unzuverlässigkeit wird jedoch mit der Zeit immer deutlicher. 99,9 % Zuverlässigkeit in einer Woche bedeutet nur 10 Minuten Ausfallzeit, aber 99 % bedeuten bereits fast zwei Stunden.
Wann immer Sie Gefahr laufen, Ihr SLO nicht zu erfüllen, sollten Sie handeln, da Ihre Endnutzer Ihren Service als unzuverlässig empfinden werden. Wenn Sie ein SLA vereinbart haben, könnte dies sogar zu einer finanziellen Entschädigung für Ihre Endnutzer führen.
Auf der anderen Seite bedeutet dies aber auch, dass die Untersuchung von Fehlern, die durch einen SLI angezeigt werden, sicher verschoben oder sogar ignoriert werden kann, wenn derzeit kein Risiko besteht, dass Ihr SLO nicht erreicht wird. Das bedeutet, dass Ihre Entwicklungsteams andere Arbeiten priorisieren können und die Untersuchung von Fehlern und die Fehlerbehebung besser zwischen der Entwicklung neuer Funktionen abwägen können.
Im nächsten Abschnitt werden wir all diese Theorie in die Praxis umsetzen.
SLIs und SLOs in der Praxis
Angenommen, es gibt eine Metrik, die die Anzahl der Fehler zählt, wenn ein Benutzer eine Produktdetailseite in einem Webshop aufruft:
fetch_product_details_errorsWenn wir diese Metrik (unseren SLI) in unserem bevorzugten Überwachungstool (z.B. Prometheus, ElasticSearch) abfragen, erhalten wir eine Zahl, die die Anzahl der Fehler zu diesem Zeitpunkt angibt.
Wir könnten auch die Gesamtzahl der Produktdetailansichten abfragen und die Fehler zum Vergleich durch diese Zahl teilen:
fetch_product_details_errors
/
fetch_product_details_count
Jetzt haben wir das Verhältnis. Lassen Sie uns darauf aufbauen und einen Prozentsatz daraus machen:
(
1 – (
fetch_product_details_errors
/
fetch_product_details_count
)
) * 100Dies gibt Ihnen bereits einen grundlegenden Hinweis auf Ihre Zuverlässigkeit zu einem bestimmten Zeitpunkt. Aber wie ich bereits erwähnt habe, geht es bei SLOs um eine Zeitspanne. Lassen Sie uns dies über eine Woche berechnen:
(
1 – (
sum(rate(fetch_product_details_errors[1w]))
/
sum(rate(fetch_product_details_count[1w]))
)
) * 100Und hier haben wir die Metrik, die anzeigt, ob unser SLO erfüllt ist. Wie in der Funktion sum(rate()[1w]) angegeben, erhalten Sie so die Gesamtzahlen für eine Woche. Die gesamte Abfrage gibt einen Prozentsatz wie z.B. 99,9% aus, auf den Sie aufmerksam machen können, wenn die Gefahr besteht, dass der Schwellenwert Ihres SLO unterschritten wird. Beachten Sie, dass ich in diesen Beispielen die Prometheus-Syntax verwendet habe, aber das wird bei anderen Überwachungstools in etwa ähnlich sein.
Was ist mit SLAs?
Wenn Sie ein vertragliches SLA mit Ihren Endbenutzern haben, können Sie die gleiche Abfrage wie oben für SLOs verwenden, um zu berechnen, ob Sie dieses erfüllen. Achten Sie jedoch darauf, dass Sie Ihren SLO höher ansetzen als Ihr SLA, damit Sie eine Warnung erhalten, wenn Ihr SLO nicht erfüllt wird, bevor Sie Ihr SLA verletzen.
Wenn Ihr SLA z.B. 99,5% beträgt, setzen Sie Ihren SLO auf 99,9%.
Fehler Budgets
Um noch einen Schritt weiter zu gehen, ist eine weitere hilfreiche Kennzahl für SRE das Fehlerbudget. Diese geben an, wie viele Fehler Sie noch machen können, bevor Sie unter Ihr SLO fallen:
- Die Anzahl der Fehler , die Sie sich leisten können, bevor Sie unter Ihren SLO fallen
- Ausgedrückt in Zeit, typischerweise Stunden der Unzuverlässigkeit über einen Zeitraum von 7 Tagen
- Beispiel: Mit dem SLO "99,5% aller Ansichten von Produktdetails sollten erfolgreich sein" haben Sie ein Fehlerbudget von 0,84 Stunden über 7 Tage.
- Fehlerbudgets können mehrere SLOs in einem einzigen Budget enthalten (z. B. Latenz, Frontend-Fehler usw.), solange dies für ein Produkt und ein Team sinnvoll ist.
- Ist Ihr Budget aufgebraucht? Sie sollten der Erhöhung der Zuverlässigkeit den Vorrang geben, nicht neuen Funktionen.
Das vorherige Beispiel mit einer SLO von 99,5% benötigt die folgende Abfrage, um Ihr Fehlerbudget in Stunden über 7 Tage zu berechnen:
168 * (
0.005 – (
sum(rate(fetch_product_details_errors[1w]))
/
sum(rate(fetch_product_details_count[1w]))
)
)Da eine Woche 168 Stunden hat und Ihr SLO 99,5% beträgt, ergibt sich ein Verhältnis von 1 - 0,995 = 0,005.
Wenn Sie dies in einem Diagramm darstellen, wird besonders deutlich, wann Sie Gefahr laufen, unter Ihr Fehlerbudget zu fallen:
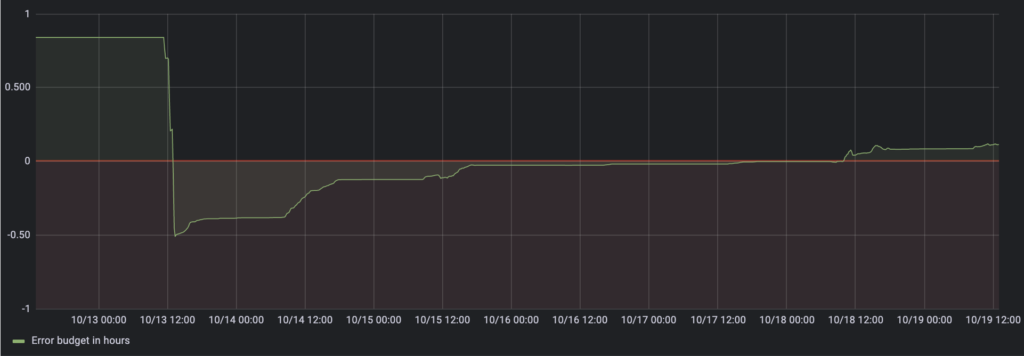
Wie Sie sehen können, beträgt das Budget 0,84 Stunden, wenn keine Fehler auftreten. Wenn viele Fehler auftreten, sinkt es unter Null, d.h. Ihr Budget ist aufgebraucht. Sie würden dann das Problem beheben und sich auf alles andere konzentrieren, was die Zuverlässigkeit verbessert. Im Laufe der Zeit steigt das Fehlerbudget wieder an, d.h. sobald es über die Schwelle von Null klettert, können Sie sich wieder auf neue Funktionen konzentrieren.
Und das war's! Ein paar praktische Möglichkeiten, mit SLOs und Fehlerbudgets objektiv anzugeben, wann Sie handeln müssen. In Zukunft werden wir an dieser Stelle weitere Beiträge zum Thema Observability veröffentlichen, z.B. zur Korrelation von Ereignissen zwischen Metriken, Protokollen und Traces, um Probleme genauer zu untersuchen, wenn es Zeit zum Handeln ist.
Verfasst von
Tariq Ettaji
Software Delivery Consultant
Unsere Ideen
Weitere Blogs


Wo die GitHub Copilot Erweiterungspunkte die Governance brechen
Viele der jüngsten Ergänzungen des GitHub Copilot-Ökosystems bieten einen echten Mehrwert für einzelne Entwickler, erweitern aber auch die...
Rob Bos


Contact