GoDataDriven hilft der NS (Niederländische Eisenbahn) dabei, ein datengesteuertes Unternehmen zu werden. Insbesondere sammeln wir die Sensormessungen der Zugflotte kontinuierlich in großen Mengen und in hohem Tempo. Denken Sie an die Geschwindigkeit und den Standort des Zuges, die Temperatur, die Spannung und den Druck mechanischer Komponenten, aggregierte Diagnosemeldungen, Zustandsänderungen usw. Zum Zeitpunkt der Erstellung dieses Artikels nähern wir uns der erstaunlichen Zahl von 100 Milliarden Sensormessungen.
Prädiktive Wartung
Das ist alles schön und gut, aber die wichtige Frage ist natürlich, was man mit den Daten macht, um einen Mehrwert für die NS zu schaffen. Zu diesem Zweck forschen die Mitarbeiter der Abteilung 'Maintenance Development' an der Nutzung von Sensordaten für die vorausschauende Wartung - eines der wichtigsten Anwendungsgebiete des maschinellen Lernens. Unter ihnen ist Wan-Jui Lee. Nachdem sie in Taiwan in Elektrotechnik promoviert und mehrere F&E-Positionen in Wissenschaft und Industrie bekleidet hatte, entschied sie sich, bei der NS mitzuarbeiten und an der Entwicklung von Lösungen für die vorausschauende Wartung mitzuwirken. Insbesondere entwickelte sie eine Methode zur frühzeitigen Erkennung von Luftlecks in den Bremsleitungen der Züge. Ein funktionierendes Bremssystem ist natürlich eine Voraussetzung für den Betrieb des Zuges. Daher ist es von entscheidender Bedeutung, einen solchen Ausfall zu erkennen und die Leitung oder den Kompressor genau zum richtigen Zeitpunkt zu ersetzen oder zu reparieren. Dies erspart die Kosten, die mit einem vorzeitigen oder überfälligen Austausch verbunden sind - ganz zu schweigen von den Schäden, die den Fahrgästen entstehen. Darüber hinaus sind Luftleckagen an lauten Wartungsarbeitsplätzen bekanntermaßen schwer zu erkennen, so dass die Automatisierung hier sehr nützlich ist.
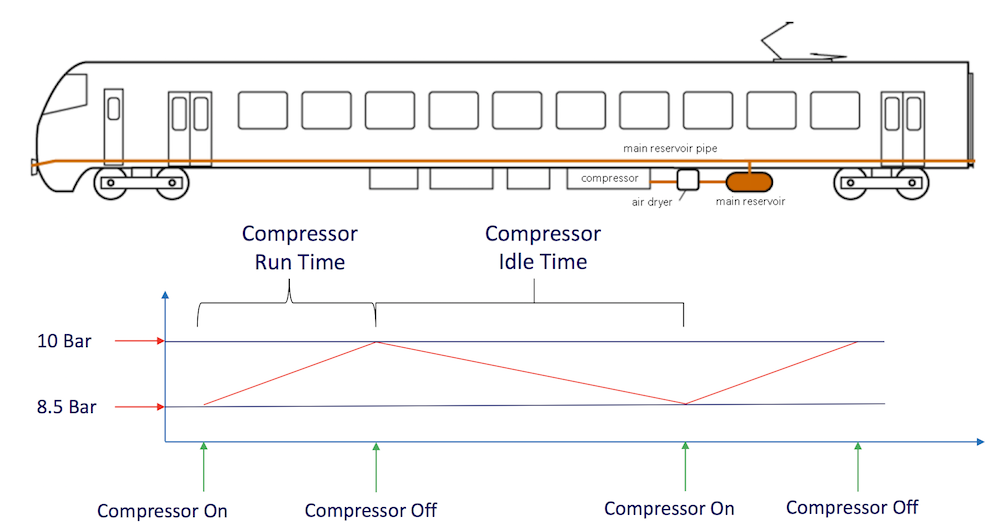
Die von Wan-Jui entwickelte Erkennungsmethode umfasst eine Reihe relativ einfacher statistischer Modelle, die auf den Kompressorprotokollen basieren - d.h. den Zeitstempeln des Ein- und Ausschaltens des Kompressors. Denn wenn sich der Kompressor häufiger einschaltet, könnte dies auf eine Luftleckage zurückzuführen sein. Auf der Grundlage der Echtzeitüberwachung des Kompressorverhaltens kann eine Luftleckage typischerweise 2 bis 3 Wochen vor einem Totalausfall erkannt werden und lässt daher genügend Spielraum für die betriebliche Handhabung. Die Arbeit wurde 2017 im International Journal of Prognostics and Health Management veröffentlicht.
Riesige Daten
Um die Forschung von Wan-Jui zu operationalisieren, muss die Methode so implementiert werden, dass die riesigen Mengen an Sensordaten, die täglich gesammelt werden, zur Erstellung der Vorhersagemodelle verwendet werden können. Hier kommt GoDataDriven ins Spiel: Wir bringen das Wissen und die Fähigkeiten mit, um die Methode in Python (oder Scala, je nach der Rolle des Datenwissenschaftlers/Ingenieurs) zu implementieren und Spark als Verarbeitungsmaschine für den Umgang mit den großen und verteilten Datenmengen zu verwenden, die auf Hadoop gespeichert sind.
Wir haben die Methode so implementiert, dass jede Nacht für jeden Zug neue Modelle trainiert werden können, wobei die neuesten Messungen verwendet werden. Hierfür hat sich unser Mitarbeiter Ivo Everts mit Cyriana Roelofs und Mattijs Suurland aus der Abteilung 'Daten & Analyse' zusammengetan. Die Implementierung ist abgeschlossen, und wir treten nun in die Phase ein, in der die algorithmischen Ergebnisse in einer betrieblichen Umgebung getestet werden. Das heißt, wir stellen eine Verbindung zu den Wartungstechnikern am Arbeitsplatz her und leiten sie an, die Bremsleitungen, in denen ein Luftleck entdeckt wurde, sorgfältig zu überprüfen.
Angewandte Künstliche Intelligenz mit Spark

Diese Arbeit ist ein klarer und eindeutiger Fall, in dem die Leistungsfähigkeit des maschinellen Lernens in einem industriellen Umfeld demonstriert wird. Spark ist hierfür eine ausgezeichnete Wahl, da es eine bequeme programmatische Schnittstelle zu riesigen Datensätzen bietet und eine Vielzahl von Standardalgorithmen für maschinelles Lernen direkt implementiert. In Anbetracht der Tatsache, dass KI das neueste Schlagwort ist (es ist eigentlich eine Obermenge von maschinellem Lernen), ist es naheliegend, dass sich unsere Arbeit für eine nette Sitzung auf dem nächsten Spark+AI-Gipfel Anfang Juni in San Francisco eignet. See you there!?
Unsere Ideen
Weitere Blogs




Contact