Blog
NiFi Ingestion Blog Serie. TEIL IV - Ein Universum aus Flow-Dateien - NiFi-Architektur

Apache NiFi, eine Big Data Processing Engine mit grafischer WebUI, wurde entwickelt, um Nicht-Programmierern die Möglichkeit zu geben, Datenpipelines schnell und ohne Programmieraufwand zu erstellen und sie von den schmutzigen, textbasierten Implementierungsmethoden zu befreien. Leider leben wir in einer Welt der Kompromisse, und diese Funktionen haben ihren Preis. In unserer Blogserie möchten wir unsere Erfahrungen und Erkenntnisse aus der Arbeit mit produktiven NiFi-Pipelines vorstellen. Dies wird in den folgenden Artikeln geschehen:
Apache NiFi - warum lieben und hassen Dateningenieure es gleichzeitig?
Teil I - Schnelle Entwicklung, mühsame Pflege
Teil II - Wir haben bereitgestellt, aber zu welchem Preis... - CI/CD des NiFi-Flows
Teil IV - Ein Universum aus Flow-Dateien - NiFi-Architektur
Ich habe nur eine Regel und die lautet ... - Empfehlungen für die Verwendung von Apache NiFi
Es ist bekannt, dass Sie kein Tool bauen können, das in jeder Hinsicht gut ist. Sie müssen entscheiden, was Sie priorisieren möchten. Diese Entscheidungen haben einen großen Einfluss darauf, wozu Ihr Tool in der Lage ist und wie gut es funktionieren wird. In diesem Beitrag werfen wir einen Blick auf diese Entscheidungen und ihre Auswirkungen in Apache Nifi.
Sie sind im Stadtrat, aber... - Meisterlose Architektur
Es gibt wahrscheinlich niemanden in der Big Data-Welt, der noch nie von der Master-Worker-Architektur gehört hat. Die Idee ist recht einfach: In einem Cluster gibt es zwei spezialisierte Arten von Knoten: Worker, die alle Berechnungen durchführen, und Master, die für Aufgaben wie die Verteilung von Aufträgen, die Überprüfung ihres Status und die Gesundheitsprüfung der Worker-Knoten zuständig sind. Die Entwickler von NiFi haben beschlossen, von dieser Idee abzuweichen und alle Knoten mit der Verarbeitung zu beauftragen, wobei einige von ihnen auch zusätzliche Aufgaben übernehmen. Der erste ist der Koordinationsknoten, der für die Verwaltung des Clusters zuständig ist, Heartbeats empfängt und die neueste Flow-Version bereithält. Der zweite ist der primäre Knoten, der sich um bestimmte Arten von Verarbeitungsaufgaben kümmert.
Der Standort des Koordinators und des primären Knotens wird während des Starts dynamisch in einem Prozess namens Wahl festgelegt. Der offensichtliche Vorteil der dynamischen Auswahl ist, dass bei einem Ausfall eines dieser Knoten der andere gewählt werden kann und dessen Platz einnimmt, was automatisch geschieht. Leider bedeutet dies auch, dass sie sich Zeit nehmen müssen, um einen neuen Knoten für die Rolle zu wählen, was normalerweise ein etwas langwieriger Prozess ist.
Der Unterschied zwischen diesen Ansätzen wird deutlich, wenn wir Aufgaben erledigen wollen, die nur auf einem Rechner ausgeführt werden müssen. Wenn wir einen Master haben, kann er einen der Worker dynamisch mit der Ausführung dieser Aufgabe beauftragen. NiFi löst dieses Problem, indem diese Aufgaben nur auf dem primären Knoten ausgeführt werden. Diese Funktion wird als Isolierung der Verarbeitung bezeichnet und löst dieses Problem zwar im Allgemeinen recht gut, bringt aber auch seine eigenen Probleme mit sich.
Boxen nicht anfassen - Selbständige Arbeitnehmer
Wenn wir die Verarbeitung durch MapReduce konzeptualisieren, können wir die Kopplung zwischen den Elementen deutlich erkennen. Alle Worker sind mit dem Master-Knoten verbunden, der ihnen einen Auftrag zur Ausführung erteilt, die Ergebnisse synchronisiert, einen weiteren erteilt und so weiter. Im Fall von NiFi haben wir einige wenige Worker-Knoten, die einfach nur da sind und zufällig alle denselben Ablauf ausführen, ohne jegliche Kopplung.
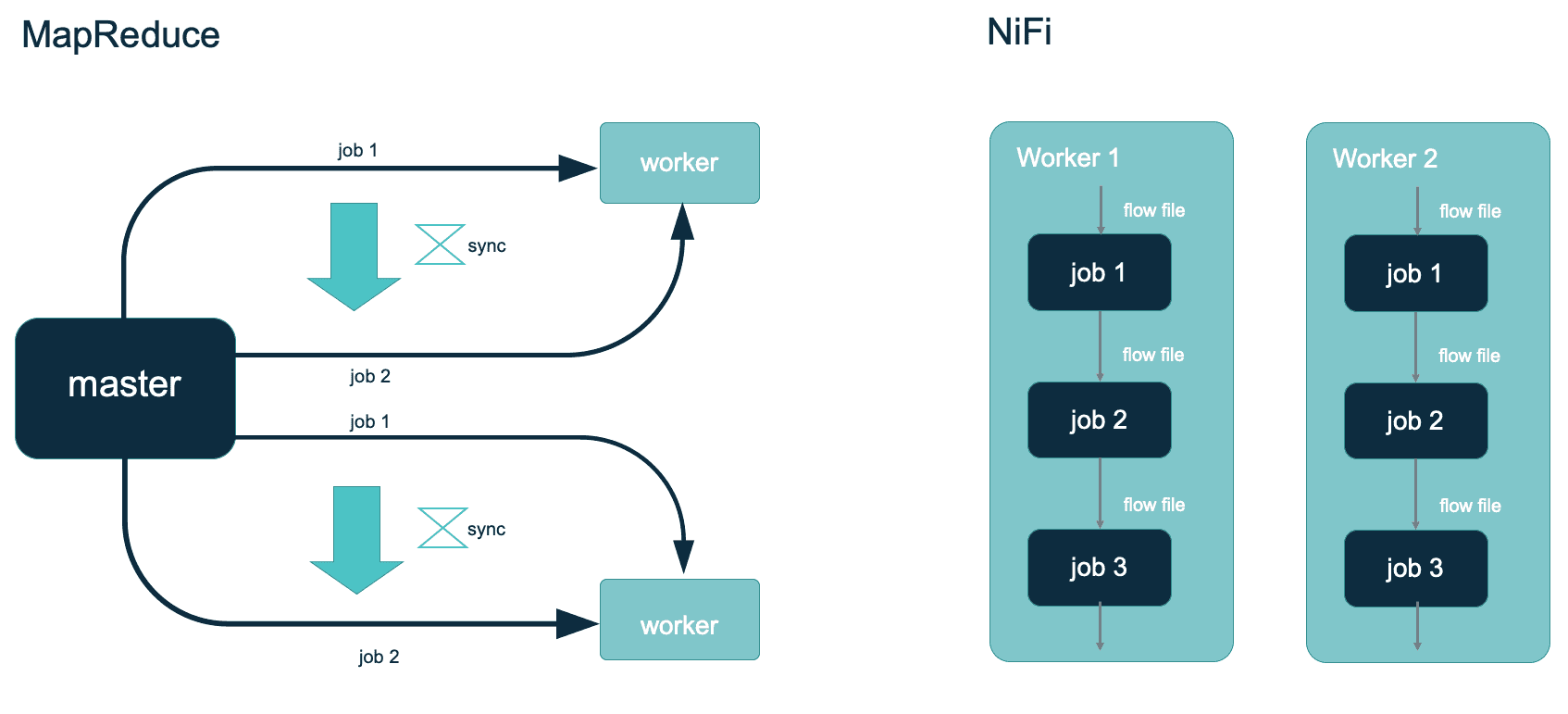
Wenn wir uns nicht mit den Besonderheiten der Architektur befassen wollen, ist die Verarbeitung durch NiFi viel einfacher zu verstehen, und Sie können sie auch viel einfacher auf der Leinwand von Webui darstellen. Diese "einfache" Art der Arbeitsverteilung auf einem Cluster eignet sich gut für die Datenumwandlung, die Verarbeitung von Nachrichten aus Warteschlangen oder einfach die allgemeine Datenverarbeitung. Ohne jegliche Synchronisierung erreichen wir eine großartige Skalierbarkeit (weil wir einfach einen weiteren Knoten hinzufügen können, der zufällig das Gleiche tut wie der Rest), aber gleichzeitig gibt es Einschränkungen für das, was wir auf einfache Weise erreichen können. Eine offensichtliche Einschränkung ist die Datenaggregation. Wenn wir die Daten aller Knoten zusammenfassen wollen, haben wir eigentlich nur zwei Möglichkeiten. Erstens, alle Teilergebnisse auf einem Rechner zu sammeln. Das ist machbar, aber wir müssen uns selbst um die Vollständigkeit der Daten kümmern, also definitiv nicht einfach. Zweitens müssen wir die Teilergebnisse an ein externes Tool senden, aber können wir das dann noch NiFi-Verarbeitung nennen? NiFi fehlt es auch an einigen Failsafe-Funktionen, die in Master-Worker-Architekturen üblich sind, z.B. eingebaute Wiederholungsrichtlinien oder die Verlagerung der Last zwischen Knoten im Falle eines Ausfalls. Ein weiteres Problem ist, dass eine große Datei von einem einzigen Worker verarbeitet wird, es sei denn, wir teilen sie explizit auf. Wenn eine Datei zu groß für einen einzelnen Rechner ist, schlägt die Verarbeitung fehl, egal wie groß unser Cluster ist.
Verteilte, aber lokale, duale Natur von Flowfiles
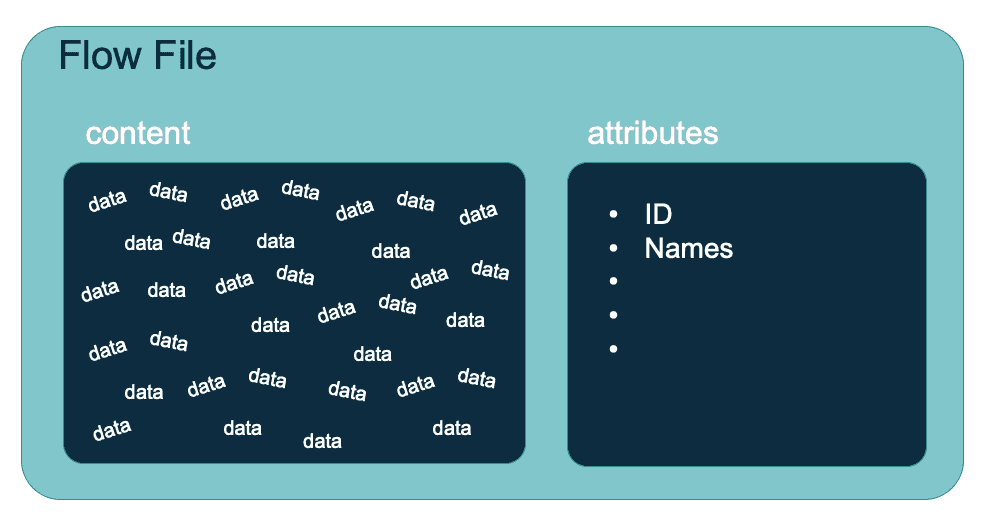 Flowfiles sind die Abstraktion, die über alle von NiFi verarbeiteten Daten gelegt wird. Es kann sich um eine Datei, ein Ereignis oder ein anderes Datenpaket handeln. Sie bestehen aus zwei Teilen: Inhalt - in der Entität gespeicherte Daten und Attribute - Daten, die die Entität beschreiben. Sie sind so konzipiert, dass es möglich ist, auf die Historie des Flowfiles zuzugreifen, es erneut auszuführen oder seine Abstammung zu überprüfen.
Flowfiles sind die Abstraktion, die über alle von NiFi verarbeiteten Daten gelegt wird. Es kann sich um eine Datei, ein Ereignis oder ein anderes Datenpaket handeln. Sie bestehen aus zwei Teilen: Inhalt - in der Entität gespeicherte Daten und Attribute - Daten, die die Entität beschreiben. Sie sind so konzipiert, dass es möglich ist, auf die Historie des Flowfiles zuzugreifen, es erneut auszuführen oder seine Abstammung zu überprüfen.
NiFi legt großen Wert auf Langlebigkeit. Es sind mehrere Mechanismen implementiert, um diese Eigenschaften zu gewährleisten. Die Daten der Flowfiles werden in 3 Verzeichnissen auf der Festplatte gespeichert,
- Flowfile-Repository - speichert die Attribute des Flowfiles
- Content Repository - speichert alle im Flowfile enthaltenen Daten
- Provenance Repository - speichert Informationen über die Historie des Flowfiles
Hinweis: Im Allgemeinen werden die Attribute im RAM-Speicher der Nifi-Knoten gespeichert, damit sie schnell abgerufen werden können. Um jedoch zu vermeiden, dass sie bei einem Anwendungsfehler verloren gehen, werden sie auch auf der Festplatte gespeichert.
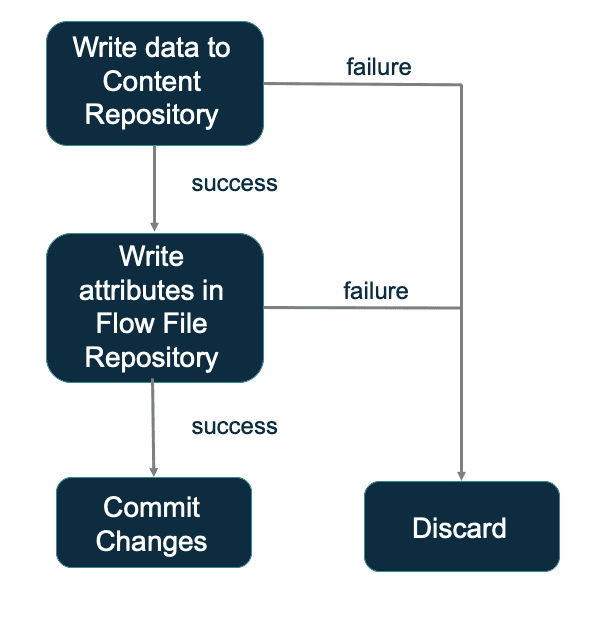 Eine andere Methode, um Dauerhaftigkeit zu erreichen, ist die Verwendung eines Write-Ahead-Protokolls. Während der Prozessor eine Flow-Datei verarbeitet, schreibt er alle Änderungen in temporäre Strukturen und weist diese Werte erst dann der Flow-Datei zu, wenn er damit fertig ist. Dadurch werden keine Änderungen an der eigentlichen Flow-Datei vorgenommen und im Falle eines Fehlers wird die Datei zurückgesetzt, da alle Änderungen verworfen werden.
Eine andere Methode, um Dauerhaftigkeit zu erreichen, ist die Verwendung eines Write-Ahead-Protokolls. Während der Prozessor eine Flow-Datei verarbeitet, schreibt er alle Änderungen in temporäre Strukturen und weist diese Werte erst dann der Flow-Datei zu, wenn er damit fertig ist. Dadurch werden keine Änderungen an der eigentlichen Flow-Datei vorgenommen und im Falle eines Fehlers wird die Datei zurückgesetzt, da alle Änderungen verworfen werden.
Wie wir uns erinnern, berühren sich die Boxen leider nicht. Das bedeutet, dass die Flowfile an einen einzelnen Knoten auf NiFi gebunden ist. Wenn der Knoten ausgefallen ist, gibt es derzeit keine Möglichkeit, auf seine Daten zuzugreifen, so dass alle Flowfiles nicht verfügbar sind, bis er gestartet und wieder mit dem Cluster verbunden wird. Ein weiterer Nachteil ist die Tatsache, dass der Inhalt der Flowfiles physisch in einem lokalen Speicher liegen muss, was zu zusätzlicher Latenz aufgrund der Kopierzeit führt und alle Vorteile von verteilten Quellen wie HDFS oder S3 zunichte macht.
Anatomie der Flow-Datei
NiFi bietet Zugriff auf die gesamte Änderungshistorie einer Flow-Datei. Um eine solche Funktion zu erreichen, müsste es entweder die Änderungen zwischen den Versionen oder die vollständigen Versionen sammeln. Der zweite Ansatz wurde gewählt, weil er die Lesegeschwindigkeit optimiert, denn das ist der Vorgang, der am häufigsten durchgeführt wird. Jedes Mal, wenn Sie eine Flowfile "ändern", erstellen Sie eigentlich eine neue Flowfile und verwerfen die alte.
Da sich Attribute häufiger ändern als Inhalte, war es sinnvoll, sie separat zu speichern, um das unnötige Neuschreiben von Inhalten zu vermeiden. Eine weitere Optimierungsmöglichkeit ist die gemeinsame Nutzung eines Verweises auf Inhalte durch Flow-Dateien. Auf diese Weise können mehrere Flow-Dateien Inhalte gemeinsam nutzen, die unabhängig von den Änderungen innerhalb der Dateien sind. Die Referenz wird durch 4 Werte definiert:
- Container - definiert einen der Speicherorte für Inhalte, die in Eigenschaften definiert sind
- Abschnitt - Verzeichnis aggregierter Ansprüche
- Claim - Datei, enthält den Inhalt einer oder mehrerer Flowfiles
- Offset - Position im Anspruch (in Bytes)
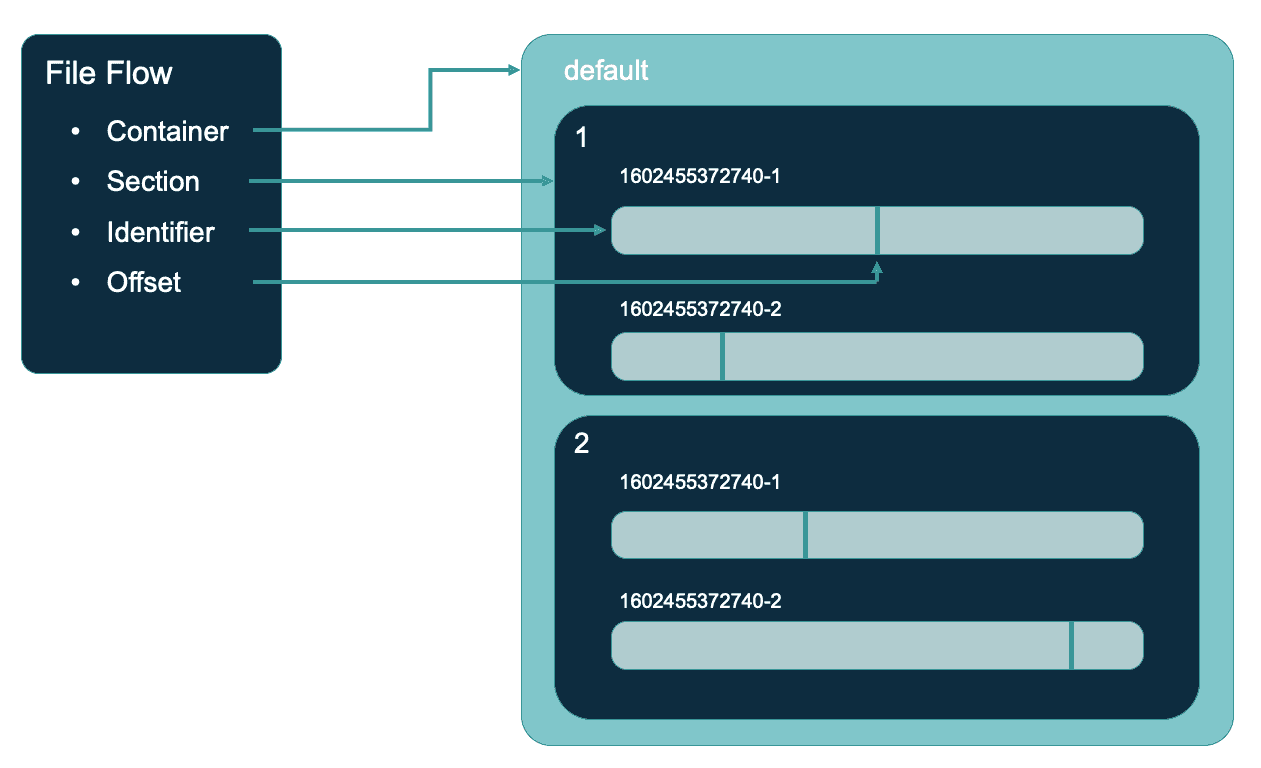
Claims sind Dateien, die den Inhalt von in der Regel mehreren Flow-Dateien enthalten. Diese Optimierung zielt darauf ab, die Belastung des Dateisystems zu begrenzen, indem die Anzahl der von NiFi verwendeten Inodes verringert wird. Wenn man über die Struktur nachdenkt, auf die mehrere Entitäten verweisen, stellt sich eine Frage: Wann können wir sie entfernen? NiFi verfügt über einen müllsammelähnlichen Mechanismus für Claims. Wenn es keine Flow-Dateien gibt, die auf den Claim verweisen, wird er gelöscht oder archiviert (je nach Konfiguration). Dieser Mechanismus ist die Ursache für eines der Probleme, die für neue NiFi-Benutzer am schwierigsten zu beheben sind. Das "Flowfile-Problem unterschiedlicher Größe", das das "Problem kleiner Dateien" in HDFS ersetzt. 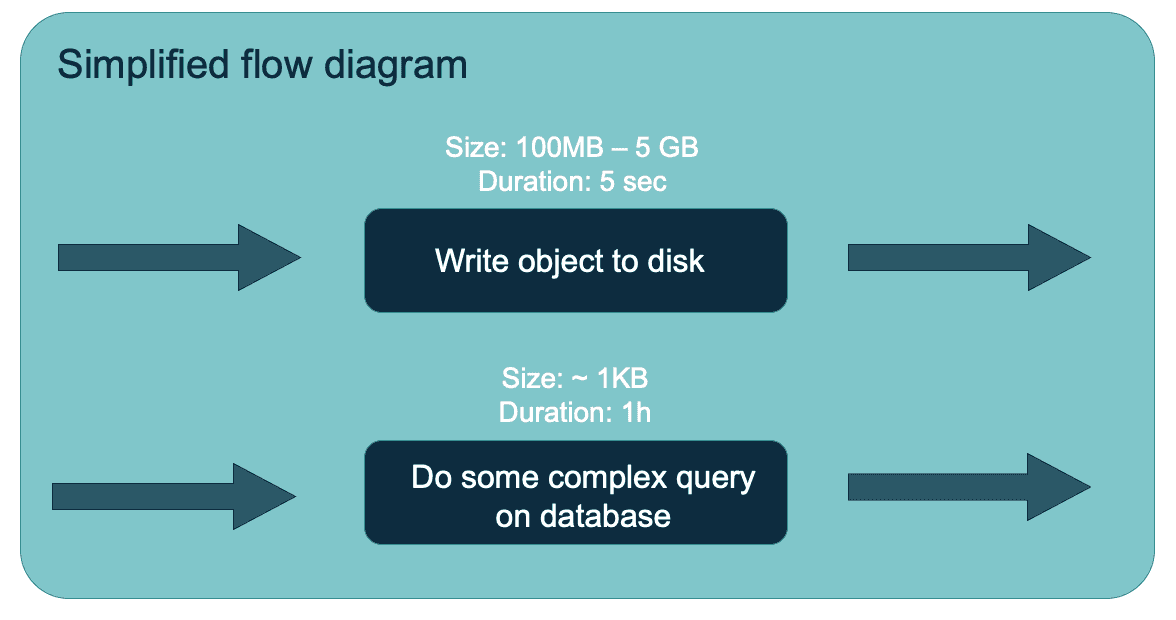
Hier haben wir zwei parallele Abläufe, einer nimmt die Dateien und schreibt sie auf die Festplatte, der andere führt eine Abfrage in einer Datenbank durch. Die erste verarbeitet große Flow-Dateien, aber nur für einen kurzen Zeitraum, so dass der Inhalt schnell gelöscht werden sollte. Die zweite führt nur die Abfrage aus, so dass die Flow-Dateien klein sind, aber es dauert lange, bis eine Flow-Datei verarbeitet wird. Nehmen wir den schlimmsten Fall an: Jede Flow-Datei aus dem ersten Flow erscheint kurz nach der Flow-Datei aus dem zweiten. In der Webui sehen Sie, dass die Warteschlangen 10 % der Kapazität Ihres Inhaltsspeichers einnehmen, aber es wird eine Fehlermeldung angezeigt, dass der Speicher voll ist, und der Fluss stürzt ab. Warum ist das passiert? Schauen wir uns die Situation aus der Perspektive der Flow-Dateien an
- Ein kleines Flowfile hat einen separaten Anspruch erstellt
- Eine große Datei sah einen kleinen Anspruch, also schloss sie sich ihm an.
- Die nächste kleine Flowfile sah einen großen Anspruch (kleine und große Flowfile), also wurde eine neue Flowfile erstellt
- Der nächste große Flowfile sah den kleinen Claim und schloss sich ihm an.
Dieser Prozess dauerte eine Weile an und jetzt haben wir eine Menge Ansprüche mit dem Inhalt einer großen Flow-Datei und einer kleinen, die nicht gelöscht werden können, bevor die kleinen verarbeitet sind. Nach einiger Zeit war der für all diese Ansprüche erforderliche Speicherplatz größer als das Content Repository und ein Fehler trat auf. Dieses Problem kann auch auftreten, wenn wir unbenutzte Prozessgruppen mit Flowfiles darin belassen.
Fazit
Was wir geliebt haben? NiFi bietet großartige Funktionen in Bezug auf die Beibehaltung der Abstammung, Langlebigkeit und Debugging von Datenströmen mit Provenance und Unveränderlichkeit der Datenströme.
Was wir gehasst haben? Das Fehlen der eingebauten Fähigkeit, Flowfiles von ausgefallenen Knoten zu verschieben und die gemeinsame Nutzung von Ressourcen zwischen ihnen kann die Möglichkeiten von Nifi stark einschränken. Auch das "Problem der unterschiedlichen Größe der Flowfiles" ist eine ziemliche Falle für neue Entwickler.
Verfasst von
Tomasz Nazarewicz
Unsere Ideen
Weitere Blogs




Contact