
In diesem Blog zeigen wir Ihnen, wie einfach es ist, einen Neo4j HA-Cluster auf einem Raspberry Pi-Cluster zu erstellen, einschließlich eines vorgelagerten Proxy-Servers, um das Beste aus der Einrichtung herauszuholen. Sie werden vielleicht denken: "Warum sollte man einen Neo4j-Cluster auf einem Raspberry installieren?" Nun, um ehrlich zu sein: Weil es Spaß macht und weil wir es können ;).
Ich persönlich bin bekanntlich ein großer Fan von Neo4j, einfach weil es eine großartige Graph-Datenbank ist. Meistens arbeite ich nur mit einer einzigen Instanz. Die meisten Produktionssysteme laufen jedoch in einem Hochverfügbarkeits-Setup. In der letzten Zeit habe ich mit der Einrichtung eines solchen Raspberry Pi-Clusters experimentiert. In diesem Artikel erzähle ich Ihnen, was ich bei diesem Experiment gelernt habe.
Um mit dem Aufbau unseres Clusters zu beginnen, brauchten wir etwas Hardware. Ich habe verwendet:
- 4 Raspberry Pi 2 Modell B 1GB
- 4 Transcend 16GB Klasse 10 MicroSDHC
- 1 8-Port Gigabit-Switch
- 1 USB 3.0-Hub mit 4 Anschlüssen
- Einige Drähte und Gehäuse
 Ein Haufen Himbeeren
Ein Haufen Himbeeren Raspberry Pi-Cluster
Raspberry Pi-ClusterWie man ein Diagramm aufteilt
Vor einigen Jahren war der Hype um NoSql / Hadoop auf seinem Höhepunkt. Die Unternehmen verzeichneten einen drastischen Anstieg der von ihnen gespeicherten Datenmengen. Die damals verfügbaren Lösungen konnten mit diesen Datenmengen oder der Komplexität nicht umgehen. Viele der NoSql-Lösungen lösten das Problem des hohen Datenvolumens, indem sie eine Sharding-Lösung für Daten anboten. Dies funktioniert hervorragend für unverbundene Daten. Schlüsselwertspeicher und Dokumentenspeicher wie Redis oder Mongo db speichern Datensätze in Partitionen und können problemlos horizontal skaliert werden.
In Abbildung 3 sehen Sie, was mit einem Graphen passieren würde, wenn Sie ihn auf die gleiche Weise splitten würden. Neo4j konzentriert sich auf die Bereitstellung einer Lösung für eine schnelle Online-Graph-Datenbank. Wenn Sie Daten abfragen möchten, die auf verschiedenen Rechnern gespeichert sind, ist es ein nahezu unmögliches Problem, dies schnell zu machen.
Dabei ist die Lösung, die Neo4j HA bietet, ein vollständig replizierter Cluster, siehe Abbildung 4. Jede Neo4j-Instanz im Cluster enthält den kompletten Graphen. Die HA-Lösung sorgt dafür, dass alle Instanzen synchronisiert bleiben.
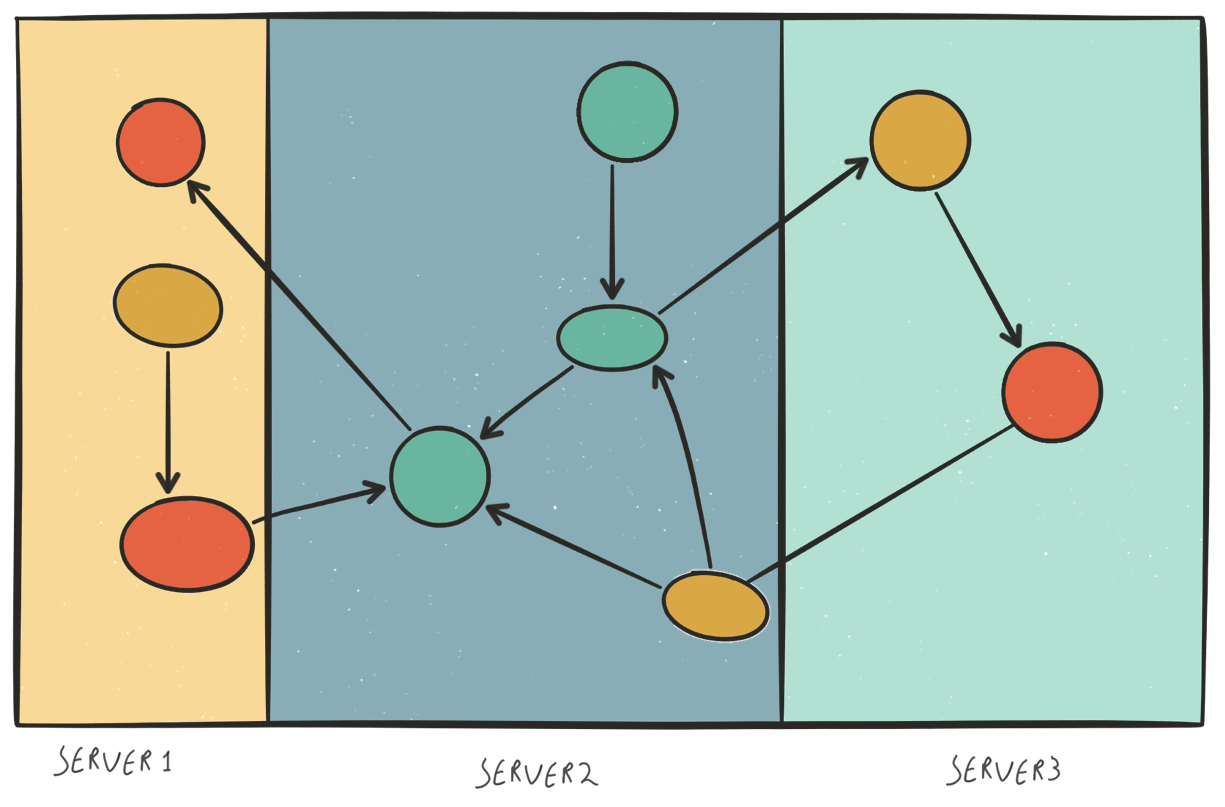 Bild 3
Bild 3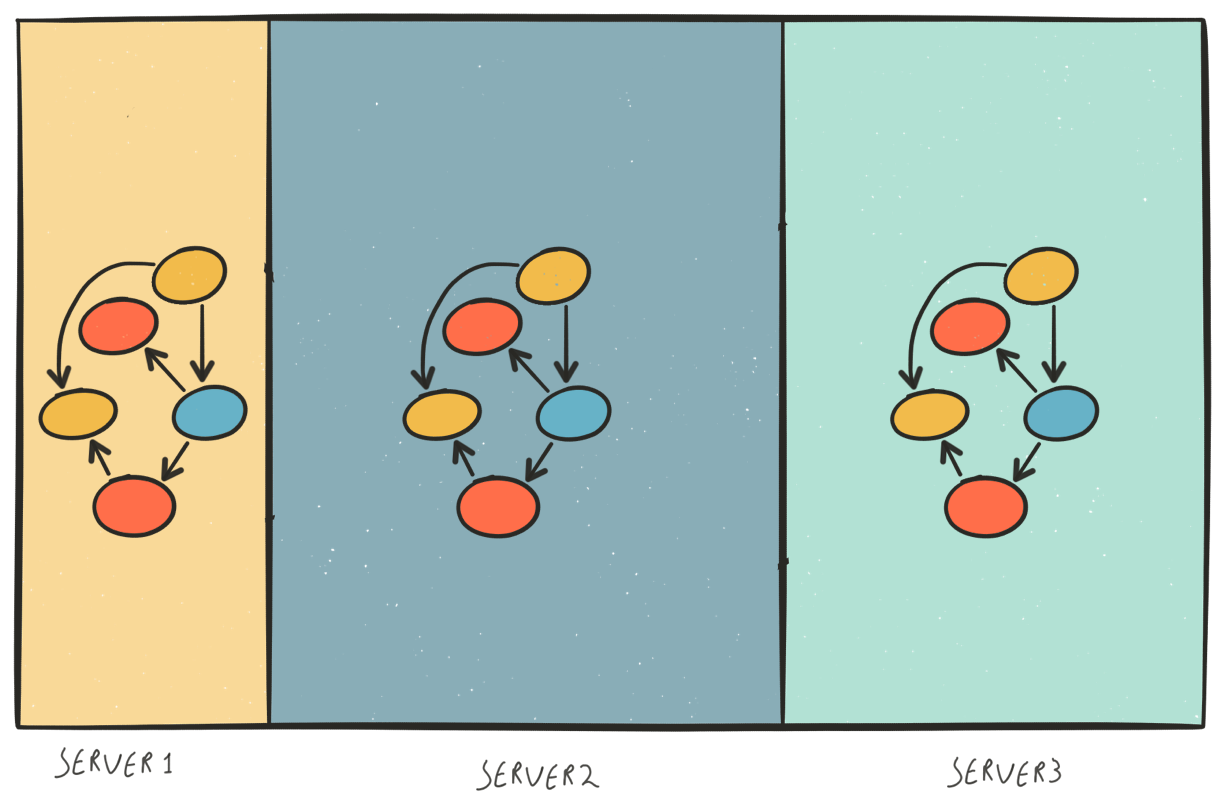 Bild 4
Bild 4Die Himbeere zubereiten
Zurück zu dem Cluster. Bevor wir einen Neo4j-Cluster erstellen können, müssen wir ein Betriebssystem auf den Raspberry Pi's installieren. Um das Betriebssystem Raspbian zu installieren, können Sie sudo raspi-config konfigurieren. Die Dinge, die Sie wahrscheinlich konfigurieren möchten, sind:
- Hostname
- Erweitern Sie das Dateisystem (standardmäßig wird die Partition nur 2GB groß sein, aber wir haben 16GB zur Verfügung)
Neo4j Einrichtung
Das Einrichten eines Neo4j-Clusters ist ganz einfach. Sie müssen nur 6 Eigenschaften in 2 Dateien ändern und schon sind Sie fertig:
Die folgenden Eigenschaftsdateien müssen auf allen Cluster-Instanzen geändert werden.
neo4j-server.properties
# Datenbank-Modus # Erlaubte Werte: # HA - Hochverfügbarkeit # SINGLE - Einzelner Modus, Standard. # Um im Hochverfügbarkeitsmodus zu arbeiten, konfigurieren Sie die Konfigurationsdatei neo4j.properties und entfernen Sie dann diese Zeile: org.neo4j.Server.Datenbank.Modus=HA # Lassen Sie den Webserver nur auf die angegebene IP lauschen. Standard ist localhost (nur # lokale Verbindungen akzeptieren). Entfernen Sie den Kommentar, um jede Verbindung zuzulassen. Bitte beachten Sie die # Sicherheit Abschnitt im neo4j Handbuch, bevor Sie diese ändern. org.neo4j.Server.Webserver.Adresse=0.0.0.0
neo4j.properties
# Uncomment and specify these lines for running Neo4j in High Availability mode. # Weitere Einzelheiten zu diesen Einstellungen finden Sie in der Anleitung zur Einrichtung der Hochverfügbarkeit. # http://neo4j.com/docs/2.3.1/ha-setup-tutorial.html # ha.server_id ist die Nummer der einzelnen Instanzen im HA-Cluster. Sie sollte sein # eine ganze Zahl (z.B. 1), die für jede Cluster-Instanz eindeutig sein sollte. ha.server_id=1 # ha.initial_hosts ist eine kommagetrennte Liste (ohne Leerzeichen) der Host:Ports # wo der ha.cluster_server aller Instanzen lauschen wird. Normalerweise # dies ist für alle Cluster-Instanzen gleich. ha.initiale_hosts=192.168.2.8:5001,192.168.2.7:5001,192.168.2.9:5001 # IP und Port für diese Instanz zum Abhören, um den Cluster-Status zu übermitteln # Informationen über andere Instanzen (siehe auch ha.initial_hosts). Die IP # muss die konfigurierte IP-Adresse für eine der lokalen Schnittstellen sein. ha.cluster_server=192.168.2.8:5001 # IP und Port, auf denen diese Instanz für die Kommunikation mit der Transaktion lauschen soll # Daten mit anderen Instanzen (siehe auch ha.initial_hosts). Die IP # muss die konfigurierte IP-Adresse für eine der lokalen Schnittstellen sein. ha.Server=192.168.2.8:6001
Eine vollständige Anleitung finden Sie auf der Neo4j-Website
Wenn alles korrekt eingerichtet ist und die neo4j-Instanzen gestartet sind ($NEO4J_HOME/bin/neo4j start), sollten Sie die Abfrage :sysinfo in der Webkonsole ausführen können. In unserem Fall: raspberrypi_2:7474/browser/. Die folgenden Bilder zeigen das Ergebnis sowohl für die Master- als auch für die Slave-Instanz.
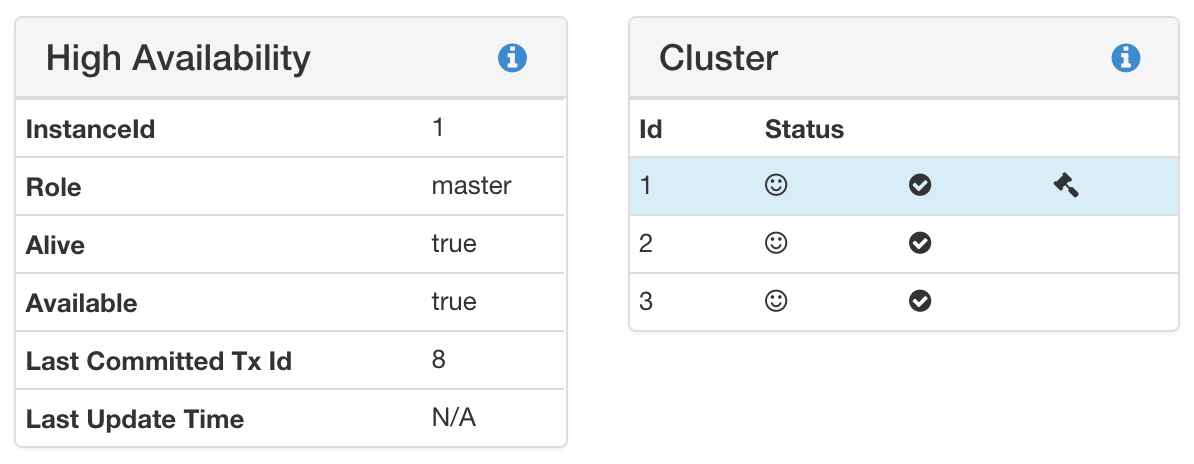 :sysinfo master
:sysinfo master
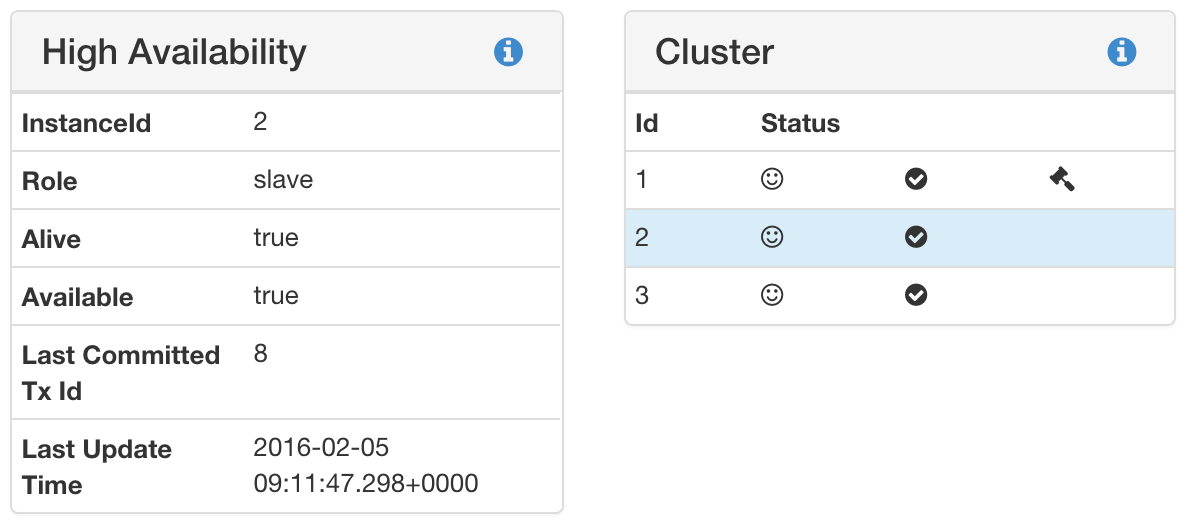 :sysinfo Sklave
:sysinfo SklaveUnsere Ideen
Weitere Blogs




Contact