In diesem Blogbeitrag zeige ich Ihnen, wie Sie Kafka-Consumer-Offsets lesen, sie in Prometheus übertragen und mit Grafana visualisieren können. Dies ist sehr nützlich, wenn Sie eine Streaming-Anwendung betreiben, die aus Kafka liest, und wissen möchten, ob Ihre Anwendung auf dem neuesten Stand ist oder hinterherhinkt.
Abrufen von Kafka-Konsumenten-Offsets
Sie haben also z.B. eine Spark ETL-Pipeline geschrieben, die aus einem Kafka-Topic liest. Es gibt mehrere Möglichkeiten, die Topic-Offsets zu speichern, um zu verfolgen, welcher Offset zuletzt gelesen wurde. Eine davon ist die
Lesen Sie alle Verbrauchergruppen:
./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --list meine-gruppe-01 meine-gruppe-02 meine-gruppe-03
Lesen Sie die Offsets für eine bestimmte Verbrauchergruppe:
./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --describe --group my-group-01 TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID Thema1 0 11412 11415 3 consumer-1-1555f25e-bc14-4e61-a82d-f36dd06ef46f /127.0.0.1 consumer-1 Thema1 1 11355 11355 0 consumer-1-1555f25e-bc14-4e61-a82d-f36dd06ef46f /127.0.0.1 consumer-1 Thema1 2 11103 11104 1 consumer-1-1555f25e-bc14-4e61-a82d-f36dd06ef46f /127.0.0.1 consumer-1 Thema1 3 11085 11085 0 consumer-1-1555f25e-bc14-4e61-a82d-f36dd06ef46f /127.0.0.1 consumer-1 Thema1 4 11282 11282 0 consumer-1-1555f25e-bc14-4e61-a82d-f36dd06ef46f /127.0.0.1 consumer-1
Offsets werden pro Verbraucher, pro Thema und pro Partition gespeichert. Das obige Beispiel zeigt einen Verbraucher, der von einem Thema aus fünf Partitionen liest. Die Gesamtverzögerung beträgt vier Nachrichten, da zwei Partitionen im Rückstand sind: Partition 0 ist um 3 Nachrichten im Rückstand und Partition 2 um eine Nachricht im Rückstand. Das ist gut zu wissen, aber Sie wollen diese rohen Zahlen nicht alle paar Sekunden lesen. Geben Sie eine Zeitreihen-Datenbank ein: Prometheus.
Verbraucher-Offsets für Prometheus freigeben
Prometheus arbeitet mit einem Pull-Modell, so dass wir die Verzögerung in einem Format ausgeben müssen, das Prometheus auslesen kann. Es gibt mehrere Exporter im Internet. Ich habe die ersten vier, die ich bei Google gefunden habe, getestet und mich für GitHub entschieden - echojc/kafka-offset-exporter. Er ist in Go geschrieben und Sie müssen die Binärdatei selbst erstellen:
go get github.com/echojc/kafka-offset-exporter
cd $GOPATH/src/github.com/echojc/kafka-offset-exporter
bauen gehen.
Ich habe einen PR erstellt, der eine Dockerdatei hinzufügt. Diese enthält auch eine Anleitung, wie man mit einigen Optimierungen bauen kann.
Sobald Sie die Go-Binärdatei erstellt haben, führen Sie sie aus: ./kafka-offset-exporter. Standardmäßig liest es von your-machine:9092 und holt nur die Offsets der Themen und nicht die Offsets der Verbrauchergruppen. Geben Sie also Argumente an, um Offsets für alle Gruppen und alle nicht-internen Themen zu holen:
./kafka-offset-exporter -brokers 127.0.0.1:9092 -topics ^[^_]* -Gruppen .
Standardmäßig läuft dies auf Port 9000:
> curl localhost:9000 # HELP kafka_offset_consumer Aktueller Offset für eine Verbrauchergruppe # TYPE kafka_offset_consumer gauge kafka_offset_consumer{Gruppe="meine-gruppe-01",Partition="0",Thema="Thema1"} 11412 kafka_offset_consumer{Gruppe="meine-gruppe-01",Partition="1",Thema="Thema1"} 11355 kafka_offset_consumer{Gruppe="meine-gruppe-01",Partition="2",Thema="Thema1"} 11103 kafka_offset_consumer{Gruppe="meine-gruppe-01",Partition="3",Thema="Thema1"} 11085 kafka_offset_consumer{Gruppe="meine-gruppe-01",Partition="4",Thema="Thema1"} 11282 # HELP kafka_offset_newest Neuester Offset für eine Partition # TYPE kafka_offset_newest gauge kafka_offset_newest{Partition="0",Thema="Thema1"} 11415 kafka_offset_newest{Partition="1",Thema="Thema1"} 11355 kafka_offset_newest{Partition="2",Thema="Thema1"} 11104 kafka_offset_newest{Partition="3",Thema="Thema1"} 11085 kafka_offset_newest{Partition="4",Thema="Thema1"} 11282 # HELP kafka_offset_oldest Oldest offset for a partition # TYPE kafka_offset_oldest gauge kafka_offset_oldest{Partition="0",Thema="Thema1"} 0 kafka_offset_oldest{Partition="1",Thema="Thema1"} 0 kafka_offset_oldest{Partition="2",Thema="Thema1"} 0 kafka_offset_oldest{Partition="3",Thema="Thema1"} 0 kafka_offset_oldest{Partition="4",Thema="Thema1"} 0
Visualisieren Sie die Verzögerung
Verweisen Sie Ihren Prometheus auf Ihren Exporter, um die Metriken abzurufen. Wir haben es fast geschafft, aber der Exporter gibt die Anzahl der verspäteten Nachrichten nicht selbst aus, wir müssen sie in Prometheus berechnen. Das ist ein wenig knifflig:
Summe(kafka_offset_newest - ein(Thema,Partition) group_right kafka_offset_consumer) von (Gruppe, Thema)
Unsere Verzögerung wird als kafka_offset_newest - kafka_offset_consumer berechnet. Da wir jedoch eine Eins-zu-viele-Arithmetik verwenden, müssen wir nach Thema und Partition gruppieren, ähnlich wie RIGHT JOIN ... GROUP BY topic, partition in der SQL-Welt. Zum Schluss addieren Sie pro Gruppe und pro Thema, um die Verzögerung für alle Verbraucher in einer Gruppe zu einem einzigen Thema zu sehen.
Visualisieren Sie mit Grafana:
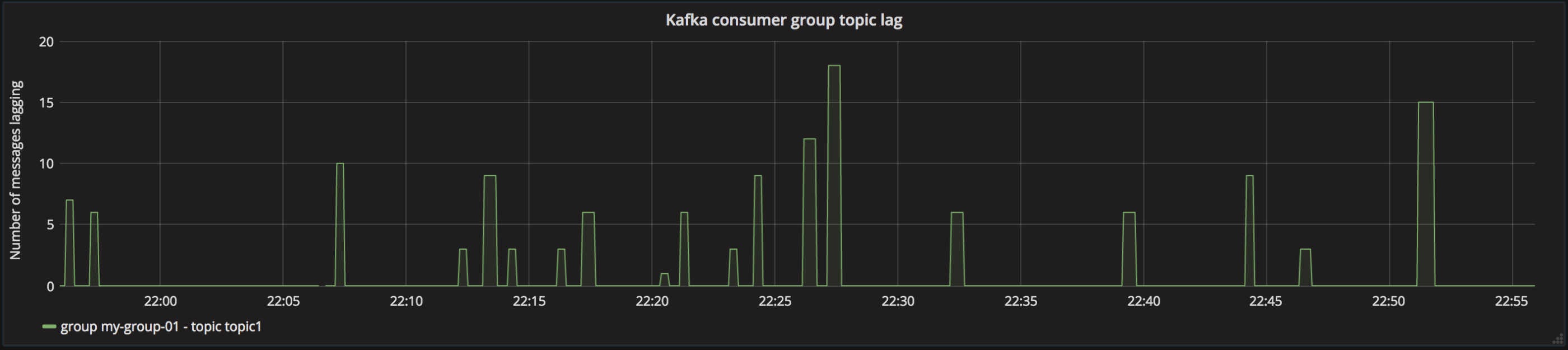
Jetzt haben wir ein übersichtliches Dashboard, das die Verzögerung anzeigt. Oft ist ein zunehmender Themenrückstand ein Indikator dafür, dass mit einem Auftrag etwas nicht in Ordnung ist, so dass Sie zusätzlich eine Warnung einrichten können. Viel Glück!
Unsere Ideen
Weitere Blogs




Contact