Blog
GetInData Modern Data Platform - Funktionen & Tools

Über die Moderne Datenplattform
In unserem vorherigen Artikel haben Sie erfahren, was wir von der Modern Data Platform halten und dass wir einige Schritte unternommen haben, um sie zu etwas Greifbarem zu machen, das unseren Kunden einen Mehrwert bietet. Ich denke, dass Ihr Appetit nun geweckt ist und Sie bereit für den Hauptgang sind, nämlich die wichtigsten Funktionen und Komponenten unserer Lösung. Zum Dessert erfahren Sie außerdem, was Sie tun müssen, um unsere Plattform in Ihrem Unternehmen einzuführen. Machen Sie sich also bereit für einen tiefen Tauchgang!
Hinweis: Alle unten aufgeführten Diagramme und Beispiele beziehen sich auf GCP, aber wir unterstützen alle drei gängigen öffentlichen Clouds (GCP, AWS und Azure).
Unsere Lösung bietet
Nachdem wir nun die wichtigsten Ziele definiert haben, ist es an der Zeit, einen genaueren Blick darauf zu werfen, wie wir sie mit unserer Plattform erreicht haben. Wie bereits erwähnt, glauben wir, dass der Stack selbst nicht nur ein Haufen beliebter Tools ist. Er ist eine solide Grundlage, aber in Wirklichkeit nur ein Teil der erfolgreichen Einführung einer modernen Datenplattform. Was wir darüber hinaus noch hinzugefügt haben, nennen wir das DP Framework. Hinter diesem Begriff verbergen sich nicht nur unsere Artefakte (Integrationspakete, Konfigurationen und andere Beschleuniger), sondern auch Best Practices für die Datenarchitektur und das Engineering, die wir im Laufe unserer jahrelangen Erfahrung in der Datenwelt gesammelt haben. 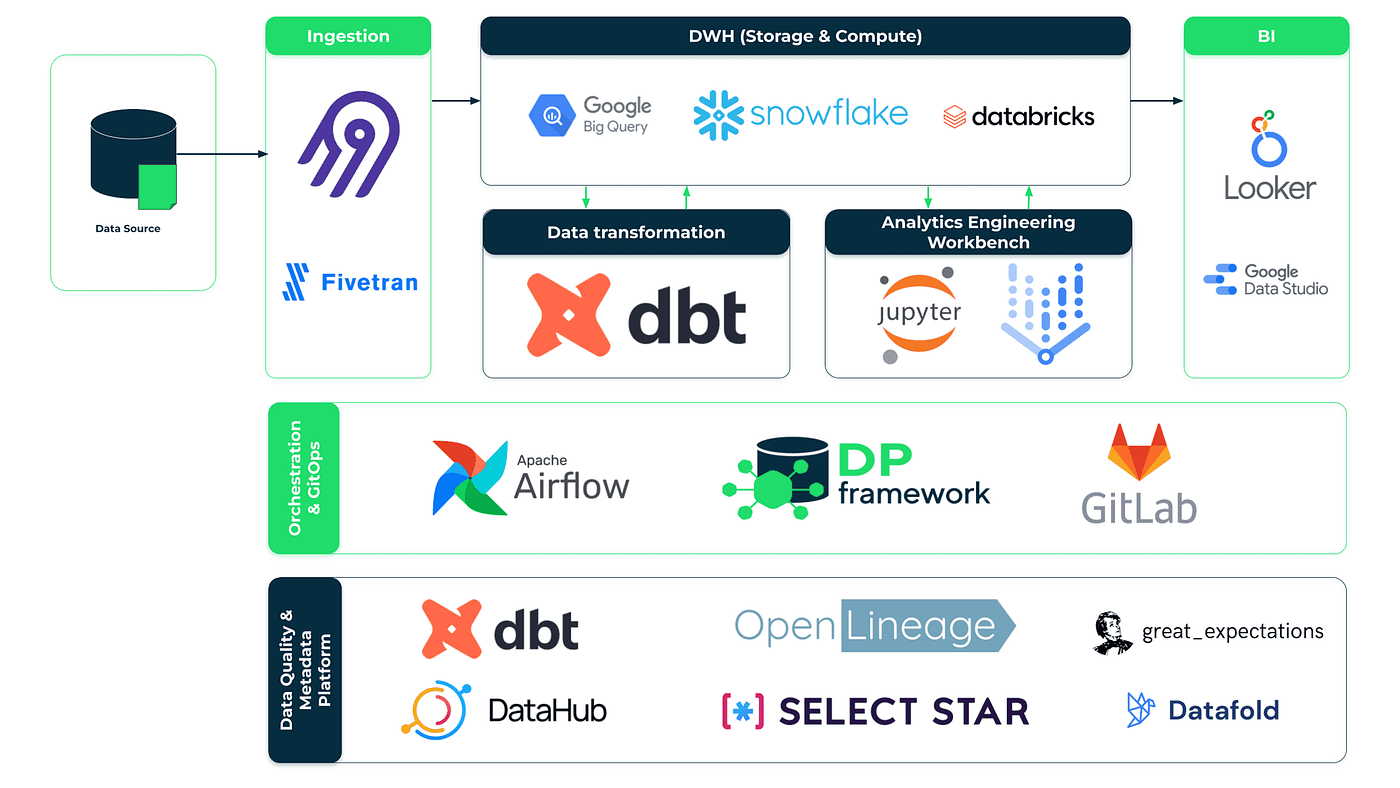
Der DV-Rahmen
Um all die oben genannten Funktionen bereitzustellen, haben wir ein Framework entwickelt, das aus Tools, Konfigurationen, Standards und Integrationspaketen besteht, die die nahtlose Integration der Komponenten unseres Stacks sicherstellen und eine benutzerfreundliche Schnittstelle bieten. Eine der wichtigsten Komponenten unseres Frameworks ist eine data-pipelines-CLI Paket, das die technische Komplexität der Datenpipeline-Verwaltung hinter einer benutzerfreundlichen Oberfläche abdeckt. Es vereinfacht auch die Automatisierung von Transformationen, Bereitstellungen und die Kommunikation zwischen verschiedenen Tools in einem modernen Daten-Stack. Ein weiteres Paket, das sich als nützlich erwiesen hat, ist dbt-airflow-factorydas bei der Integration von Transformations- und Scheduling-Funktionen hilft. Dank dieses Pakets werden dbt- und Airflow-Artefakte mühelos und automatisch zur Laufzeit übersetzt, so dass der Benutzer die Datenverarbeitungslogik an einer einzigen Stelle definieren kann. Beide Pakete wurden in unseren R&D DataOps Labs entwickelt und als Open Source zur Verfügung gestellt. Feedback und Beiträge sind sehr willkommen! 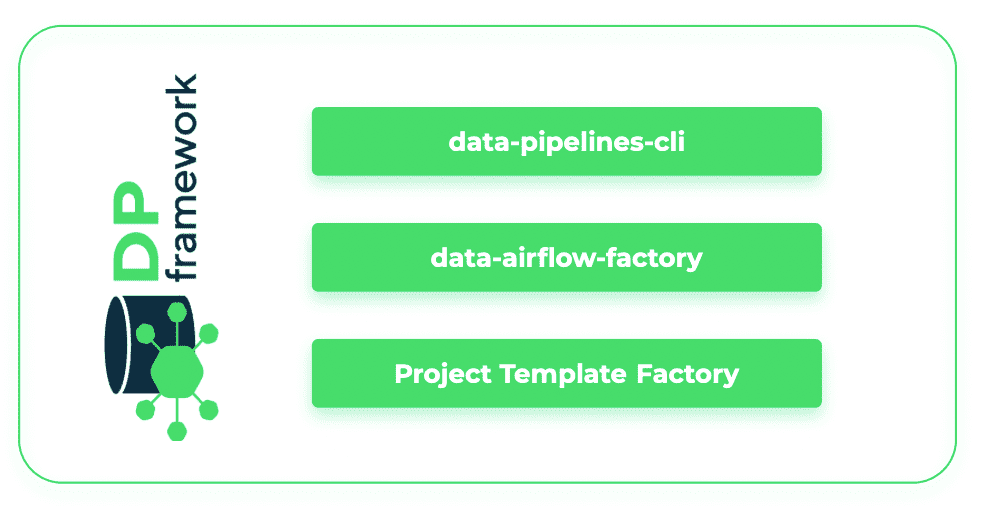
Bewährte Verfahren für Evergreen Engineering
Wir haben bereits erwähnt, dass die Fähigkeit, bewährte Verfahren aus der Welt der Softwareentwicklung zu übernehmen, einer der Eckpfeiler des modernen Data Stack ist. Wir verstehen jedoch, dass Analytiker oder Analysten - unsere Hauptnutzer - vielleicht einen anderen Hintergrund haben. Aus diesem Grund haben wir einige der anspruchsvollsten Schritte in CI/CD-Pipelines gekapselt und automatisiert. Wir haben auch eine Infrastruktur-Automatisierung (IaaC) vorbereitet, damit die Lösung in jeder Umgebung und in der Cloud auf skalierbare Weise eingesetzt werden kann.
Auch die Standards für Datensicherheit und Zugriffskontrolle sind uns sehr wichtig. Daher stellen wir Richtlinien zur Verfügung und fördern die Verwendung von Richtlinien für die Definition aller erforderlichen Einstellungen an der Quelle, mit Weitergabe der Rollen und Berechtigungen an die übrigen Komponenten des Stacks. Auf diese Weise wird sichergestellt, dass der Benutzer unabhängig vom verwendeten Client den gleichen, gut synchronisierten Zugriff auf die Daten hat.
Datenbeobachtbarkeit als Ihr Datengesundheitsmonitor
Datenqualitätstests werden zum Zeitpunkt der Entwicklung definiert und validiert. Falls Unstimmigkeiten auftreten, wird eine Warnung über einen speziellen Slack-Kanal gesendet. Außerdem ist die Historie der Datenqualitätsprüfungen über einen Datenkatalog verfügbar. Sie können auch die Lineage-Funktionalität nutzen, um Probleme in Ihren Datenpipelines zu beheben.
Drücken Sie die Eingabetaste oder klicken Sie, um das Bild in voller Größe anzuzeigen 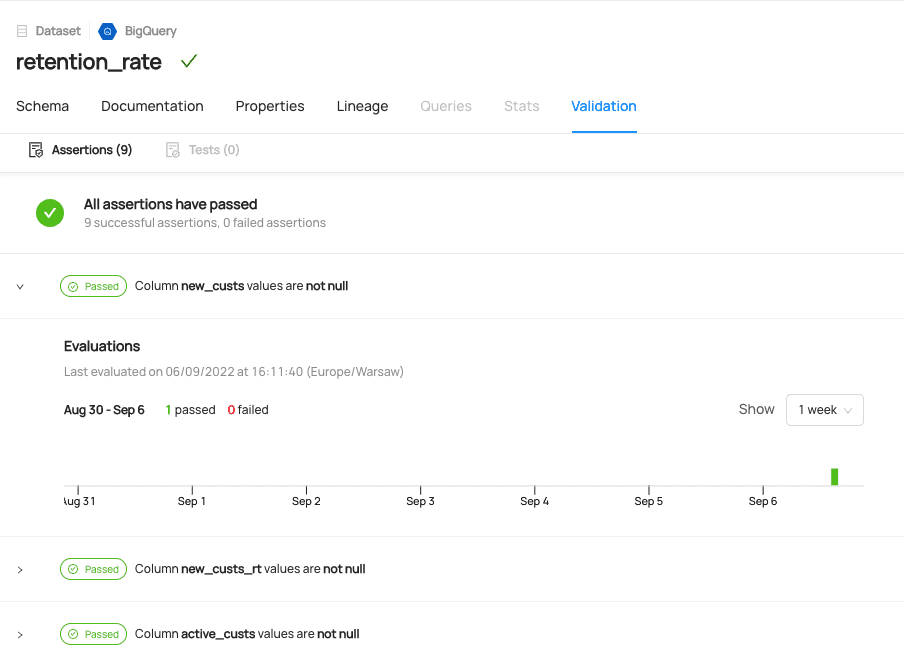
Datenkatalog als einzige Quelle der Wahrheit über Ihre Daten
Dank der Integration mit dem Datenkatalog (z.B. DataHub) ist die Datenerkennung ein integraler Bestandteil des Stacks. So können die Benutzer ganz einfach die Daten und die zugehörigen Metadaten finden, die sie für ihre Arbeit benötigen, einschließlich Nutzungsstatistiken, Abfrageverlauf, Datendokumentation und sogar Datenprofilierung. 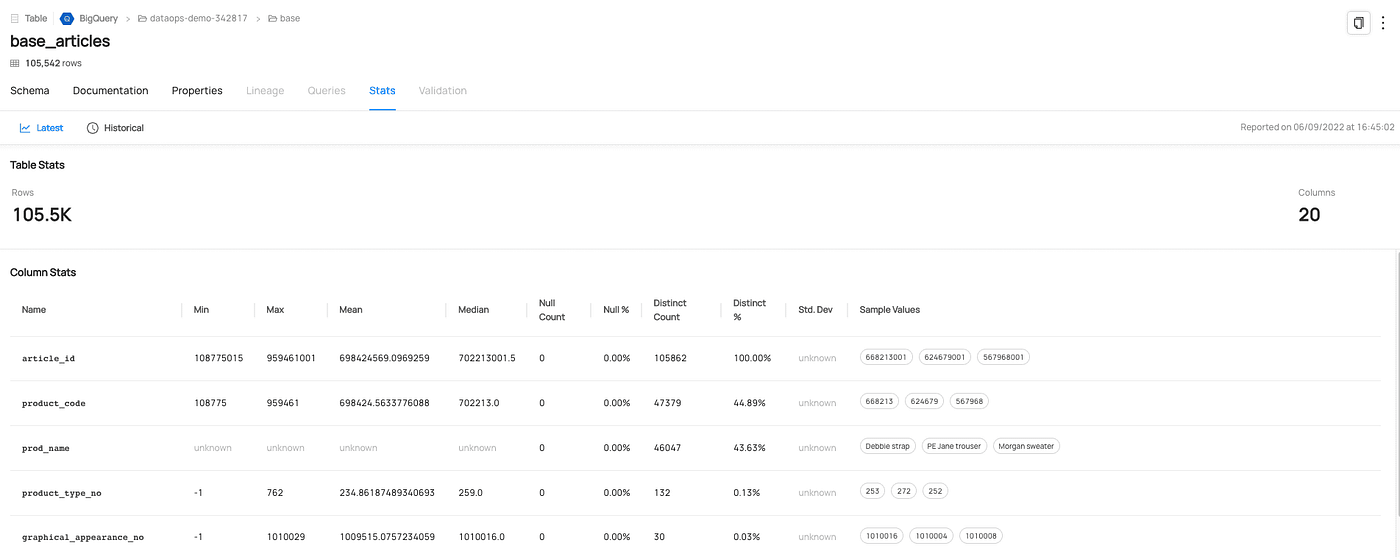
Standardisierung bedeutet Skalierbarkeit
Aus unserer Erfahrung wissen wir, dass die Verwaltung eines Portfolios von Datenprojekten in großen Unternehmen eine Herausforderung sein kann. Es kommt immer wieder zu Doppelarbeit und die Teams müssen das Rad immer wieder neu erfinden, was oft dazu führt, dass mehrere Standards und Frameworks das Gleiche tun. Wir haben festgestellt, dass es viel Raum für wiederverwendbare und konfigurierbare Komponenten wie Projektstrukturen, Prozesse und Benutzeroberflächen gibt, die wiederverwendet werden können. Als Unternehmen oder Team könnten Sie Ihre eigene Basis von Vorlagen aufbauen, die Sie zur Standardisierung Ihrer Projekte und zur Verkürzung Ihres Weges zur Wertschöpfung nutzen können. Wenn Sie mehr darüber erfahren möchten, wie wir dies tun, sehen Sie sich unsere bereits erwähnte data-pipelines-CLI Paket. 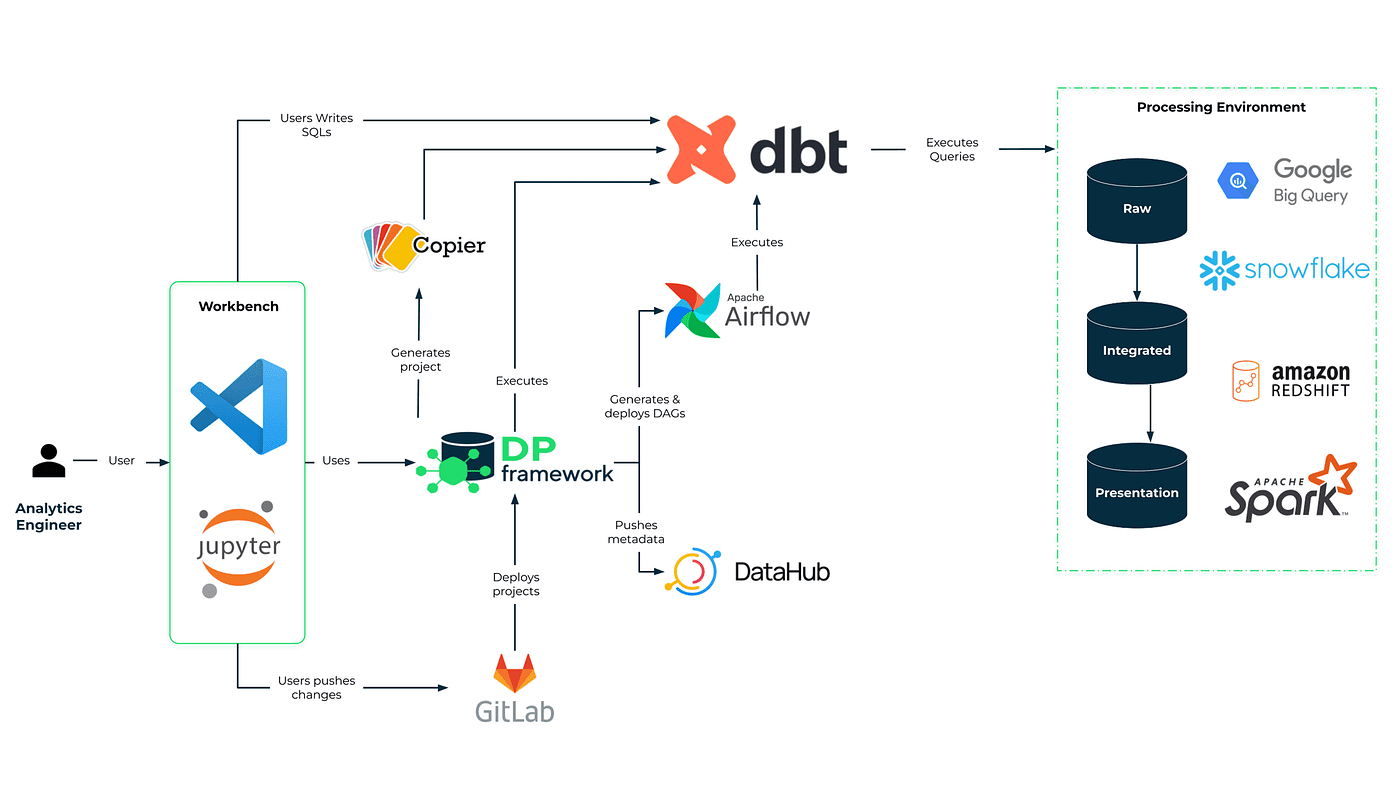
Architekturentwürfe mit Erfahrung
Für diejenigen, die unser Unternehmen gut kennen, ist es keine Überraschung, dass Sie überall Open-Source-Lösungen sehen. Wir waren schon immer von Open Source begeistert und... sind es immer noch. Das Wichtigste für uns ist jedoch, die Welt aus der Perspektive der Bedürfnisse unserer Kunden zu sehen. Und dabei stellt sich manchmal heraus, dass es einige sehr wettbewerbsfähige proprietäre oder verwaltete Lösungen gibt, die es wert sind, in unsere moderne Datenplattformarchitektur aufgenommen zu werden.
Deshalb finden Sie in unseren Blueprints oft eine schöne Kombination aus unserer Erfahrung mit Open Source, proprietären und verwalteten Lösungen.
GID Modern Data Platform - unser Portal & Workbench
Schauen wir uns nun die wichtigsten Benutzeroberflächen der GID Modern Data Platform an.
Im Interesse der Benutzerfreundlichkeit und Einfachheit haben wir ein Portal erstellt, über das die Benutzer nach einmaliger Anmeldung Zugang zu allen Tools an einem Ort haben. So könnte eine einfache Version des GID-Portals für den Benutzer aussehen:
Drücken Sie die Eingabetaste oder klicken Sie, um das Bild in voller Größe anzuzeigen 
Eines der Symbole im GID-Portal ist die eigentliche Spielwiese des Benutzers mit Zugriff auf alle Tools zur Datenverarbeitung - GID MDP Workbench (hier unter Verwendung von Vertex AI auf GCP). Von hier aus kann der Benutzer die Daten mit Cloud Beaver untersuchen, auf die VSCode IDE für Datentransformationsdefinitionen in dbt zugreifen oder die gesamte Pipeline über data-pipelines-CLI im Terminal verwalten.
Drücken Sie die Eingabetaste oder klicken Sie, um das Bild in voller Größe anzuzeigen 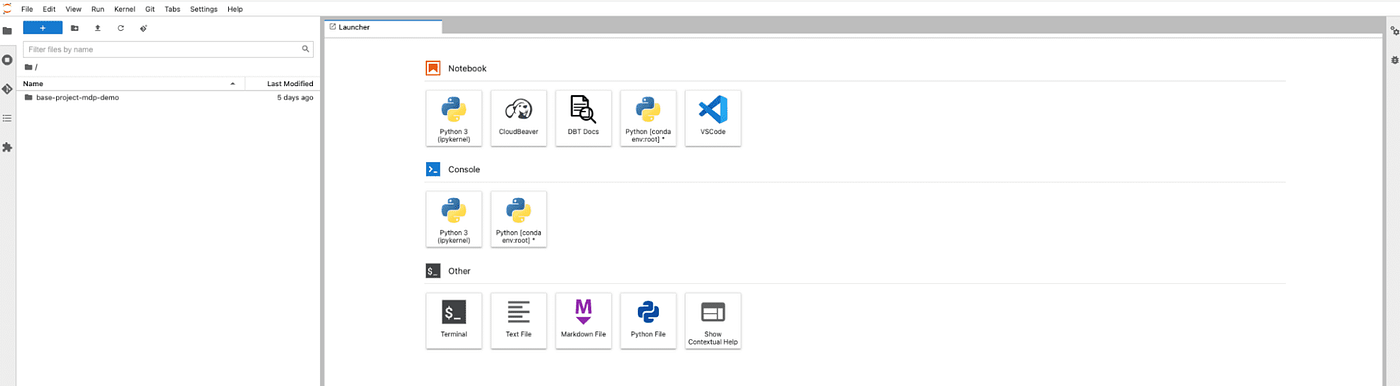
Rollout Modelle
Wir glauben nicht, dass es so etwas wie eine auf den Kunden zugeschnittene, generische, moderne Blackbox-Datenplattform gibt. Wenn wir uns gemeinsam mit unseren Kunden auf den Weg machen, stellen wir daher sicher, dass die von uns zusammengestellten Bausteine nicht zusammenbrechen, wenn sich die Marktbedingungen oder die Bedürfnisse des Kunden ändern. Nachdem wir eine solide Grundlage für unsere Plattform und unser Framework geschaffen haben, arbeiten wir mit unseren Kunden zusammen, um sicherzustellen, dass die Einrichtung und Konfiguration ihre wichtigsten strategischen Ziele widerspiegelt. Ich empfehle Ihnen, sich unsere Demo anzuschauen, um ein besseres Gefühl dafür zu bekommen, welche Werte sie Ihrem Unternehmen bringen kann. Wir haben auch einige Erfolgsgeschichten zu erzählen - Sie werden bald von einer unserer Modern Data Platform-Einführungen für einen unserer FinTech-Kunden hören - bleiben Sie dran!
Probieren Sie es aus
Wie bereits erwähnt, basiert unsere Lösung auf Open-Source. Schnappen Sie sich also die Zugangsdaten für Ihre Cloud und probieren Sie es aus. Ein Tutorial mit einer schrittweisen Einführung in unsere Plattform finden Sie hier: https://github.com/getindata/first-steps-with-data-pipelines
Was kommt als Nächstes? Live-Demo
Wir würden gerne hören, was Sie über unsere Lösung denken - jedes Feedback und jeder Kommentar ist willkommen.
Wenn Sie mehr über unseren Stack erfahren möchten, sehen Sie sich bitte unten einen Demo-Trailer an und melden Sie sich für eine vollständige Live-Demo an hier.
Bleiben Sie auch auf dem Laufenden, um mehr über unsere Modern Data Platform zu erfahren - einschließlich Tutorials, Anwendungsfällen und zukünftigen Entwicklungsplänen. Bitte denken Sie daran, unseren Newsletter zu abonnieren, um keine wertvollen Inhalte zu verpassen.
Verfasst von
Michał Rudko
Unsere Ideen
Weitere Blogs




Contact