Blog
KI hilft, die Welt zugänglicher zu machen - Analyse der Barrierefreiheit von Websites mit Semantic Kernel und OmniParser

 Quelle: https://unsplash.com/photos/a-close-up-of-a-street-sign-on-a-pole-3bPeMfGaGhw
Quelle: https://unsplash.com/photos/a-close-up-of-a-street-sign-on-a-pole-3bPeMfGaGhw
Bis Juli 2025 wird die digitale Barrierefreiheit kein Ziel mehr sein ⦠sie ist eine Anforderung^1. Mit KI und Spitzentechnologien können wir die Reise in Richtung Inklusion und Rechtskonformität vereinfachen.
In diesem Beitrag geht es sowohl um das Warum der Barrierefreiheit als auch um das Wie der Nutzung von KI zur Unterstützung. Wir werden uns mit einem technischen Proof-of-Concept befassen und die Architektur und spezifische Tools wie Semantic Kernel und OmniParser besprechen. Erwarten Sie ein moderates Maß an technischen Details, die für Entwickler und KI-Experten geeignet sind, die sich mit praktischen Anwendungen beschäftigen.
Die Bedeutung von Barrierefreiheit
Ein moralischer Imperativ und eine gesetzliche Verpflichtung - Barrierefreiheit ist zu einer grundlegenden Anforderung für digitale Produkte und Dienstleistungen geworden. Nach Angaben von Eurostat haben 101 Millionen oder 1 von 4 Erwachsenen in der Europäischen Union eine Behinderung^2. Es wird erwartet, dass diese Zahl mit zunehmender Alterung der Bevölkerung steigen wird. Diese Menschen stoßen häufig auf Barrieren, die eine gleichberechtigte Teilhabe an Bildung, Beschäftigung und dem täglichen Leben behindern. Im Mittelpunkt des European Accessibility Act (EAA) und des deutschen Barrierefreiheitsstärkungsgesetzes (BFSG) steht die Verpflichtung, diese Barrieren im digitalen Raum zu beseitigen. Dabei handelt es sich nicht nur um abstrakte Werte, denn sie sind mit einklagbaren Fristen verbunden.
Warum barrierefreies Design heute so wichtig ist
Statistische Daten zeigen, warum die Gestaltung barrierefreier Websites wichtig ist, und zwar nicht nur, um die Vorschriften einzuhalten, sondern auch, um sinnvolle digitale Erlebnisse und einen Wettbewerbsvorteil zu schaffen. Zum Beispiel:
- 70% der Benutzer mit Behinderungen verlassen eine Website, wenn sie nicht zugänglich ist^3.
- Mehr als 2,2 Milliarden Menschen weltweit sind sehbehindert, was bedeutet, dass mehr als 27% der Weltbevölkerung von der Verwendung von Bildschirmlesegeräten für die Navigation im Web profitieren können^4.
- Unternehmen könnten einen Markt von 13 Billionen Dollar erschließen, indem sie die Inklusion von Menschen mit Behinderungen in Angriff nehmen, wobei die Barrierefreiheit im Internet eine entscheidende Komponente dieser Strategie ist^5.
- Es wird erwartet, dass digitale Produkte, die die WCAG 2.0 vollständig erfüllen, eine um 50 % höhere Marktleistung aufweisen als ihre Konkurrenten^6.
- Unternehmen mit nicht konformen digitalen Plattformen riskieren rechtliche Anfechtungen, Geldstrafen und Rufschädigung. Im Jahr 2024 gab es allein in den USA über 4.000 Gerichtsverfahren im Zusammenhang mit der Nichteinhaltung von Vorschriften^7.
Es gibt noch viele weitere Statistiken^8, die die Bedeutung der Barrierefreiheit unterstreichen, aber die Quintessenz ist klar: Barrierefreiheit ist ein strategischer Imperativ.
Die Rolle der KI bei der barrierefreien Entwicklung
KI bietet das Potenzial, die Analyse von Websites anhand internationaler Zugänglichkeitsrichtlinien wie WCAG (Web Content Accessibility Guidelines)^9 zu automatisieren, zu rationalisieren und zu skalieren. Durch den Einsatz von maschinellem Lernen und Modellen zur Verarbeitung natürlicher Sprache können KI-gestützte Tools Webinhalte auf typische Probleme der Barrierefreiheit untersuchen, wie z. B.:
- Fehlender oder unzureichender Alt-Text für Bilder.
- Falsche semantische Struktur in HTML- oder ARIA-Tags (Accessible Rich Internet Applications).
- Unzugängliche Benutzerführung, wie z.B. unterbrochene Navigationspfade, die nur über die Tastatur zugänglich sind.
- Formularfelder ohne richtige Typen, Beschriftungen oder Anweisungen.
Neben der Analyse des Inhalts kann die KI auch visuelle Elemente wie Layout, Farbkontrast und Textgröße interpretieren, um potenzielle Probleme zu erkennen, die sich auf Benutzer mit visuellen oder kognitiven Einschränkungen auswirken könnten. Mit KI-Tools (z.B. OmniParser^10 von Microsoft) können wir die Elemente einer Website visuell extrahieren und analysieren und damit den Sprachmodellen helfen, den Kontext des Inhalts zu verstehen.
 Quelle: https://unsplash.com/photos/macbook-pro-on-white-surface-WiONHd_zYI4
Quelle: https://unsplash.com/photos/macbook-pro-on-white-surface-WiONHd_zYI4
Analyse der Zugänglichkeit
Im Rahmen unserer vierteljährlichen Innovationstage bei Xebia kamen meine Kollegen und ich auf die Idee zu untersuchen, wie KI uns helfen könnte, die Barrierefreiheit einer Website zu analysieren, wie sie heute ist. Die Idee war, moderne Tools und Frameworks zu nutzen, um Probleme mit der Barrierefreiheit zu erkennen und umsetzbare Erkenntnisse zu gewinnen. Das Ziel war nicht nur, Probleme zu erkennen, sondern auch zu demonstrieren, wie die Ergebnisse mehrerer Agenten zu einem umfassenden Bericht über die Zugänglichkeit kombiniert werden können. Am Ende dieses Tages hatten wir ein funktionierendes Proof-of-Concept, das eine Website auf Probleme mit der Barrierefreiheit analysieren konnte.
Überblick über die Lösung
Die Lösung, die wir entwickelt haben, besteht aus zwei Hauptkomponenten, wobei der Analyseteil im Mittelpunkt steht (wir werden später noch näher auf die Details eingehen):
- Erfassen des Inhalts und des Bildmaterials der Website. Mit einem Headless-Browser erhalten wir den vollständig gerenderten HTML-Quellcode und einen Screenshot der Website.
- Analyse der erfassten Ergebnisse. Dies beinhaltet die Verwendung des Prozess-Frameworks von Semantic Kernel, um den Analyse-Workflow mit mehreren spezialisierten KI-Agenten zu orchestrieren.
Für den Proof of Concept haben wir eine Reihe von Analysatoren ausgewählt, die sich auf bestimmte WCAG-Kriterien konzentrieren und das Potenzial dieses Systems demonstrieren. Der POC umfasst die folgenden Analyzer:
- HTML-Inhaltsanalyse:
- Alt-Text-Analyse.
- Semantische Code-Validierung.
- Tastaturnavigation überprüft.
- Formular-Validierung.
- Visuelle Analyse:
- Farbkontrastanalyse.
- Bewertung der Schriftgröße und Lesbarkeit.
Anstatt eine komplette Testsuite zu entwickeln, die alle WCAG-Kriterien abdeckt, haben wir den POC absichtlich auf diese sechs Analysatoren beschränkt. So konnten wir das Konzept testen und die Architektur validieren, ohne den Umfang oder die Komplexität zu überfordern.
Um die Lösung unterzubringen, haben wir sie als Minimal API^11 mit .NET 9 implementiert. Minimal-APIs in .NET bieten ein leichtgewichtiges Framework für die schnelle Entwicklung von APIs, die nur das Nötigste enthalten.
Aus einer übergeordneten Perspektive sieht der Prozess folgendermaßen aus:
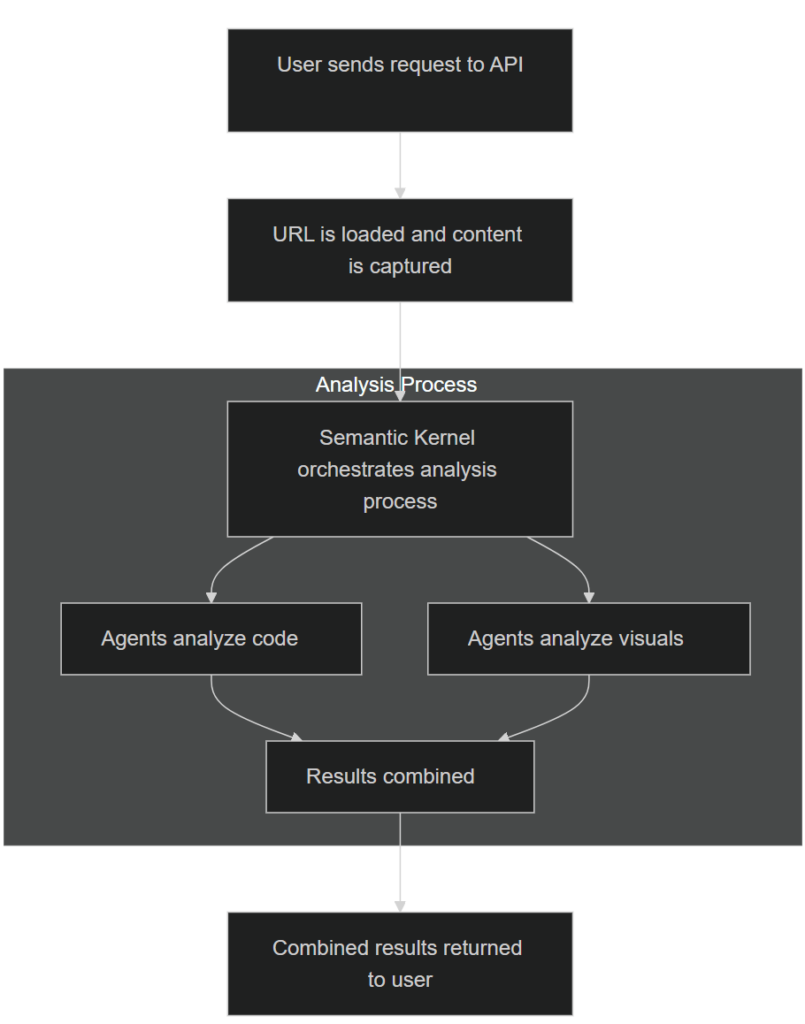
Erfassen der gerenderten Website
Eine einfache HTTP-Anfrage an die URL der Website reicht nicht aus, um den Inhalt der Website abzurufen oder einen genauen Screenshot zu erstellen. Websites verlassen sich heute oft stark auf clientseitiges JavaScript, um dynamische Elemente wie Schaltflächen, Menüs oder sogar Textinhalte darzustellen. Um sicherzustellen, dass die Seite vollständig wie vorgesehen gerendert wird, müssen wir eine Benutzerumgebung über einen Headless Browser simulieren.
Für diesen Proof of Concept haben wir die Playwright-Bibliothek^12 verwendet. Playwright lädt die Website in einem Headless-Browser, so dass JavaScript die Möglichkeit hat, ausgeführt zu werden und eine vollständig gerenderte Seite zu gewährleisten. Sobald die Seite gerendert ist, wird der HTML-Quelltext zusammen mit einem ganzseitigen Screenshot aufgezeichnet.
Wir haben uns für den größten Haltepunkt (Desktop-Ansicht) entschieden, um den Screenshot zu erstellen, da er in der Regel die umfassendste Ansicht des Inhalts einer Website bietet. In einem realen Szenario wäre es ratsam, weitere Haltepunkte zu erfassen - z. B. die Ansichten für Mobiltelefone oder Tablets -, um die Zugänglichkeit der Website auf mehreren Geräten zu prüfen.
Übergabe an Semantic Kernel
Sobald wir den Inhalt und den Screenshot haben, übergeben wir sie an den Semantic Kernel^13, insbesondere unter Verwendung seines Process Framework^14, das komplexe Arbeitsabläufe effizient verwaltet, indem es Aufgaben in modulare, wiederverwendbare Schritte unterteilt.
Mit dem Process Framework können wir Arbeitsabläufe definieren, bei denen jeder Schritt eine bestimmte Aufgabe ausführt. So können wir unsere Zugänglichkeitsanalyse in logische Komponenten aufteilen - Verarbeitung von Inhalten, Durchführung spezieller Auswertungen und Zusammenstellung der Ergebnisse. Jeder Teil kann unabhängig entwickelt und verbessert werden, wodurch die Codebasis leichter zu pflegen ist. Es vereinfacht auch die Integration verschiedener KI-Funktionen zur Bewertung bestimmter Aspekte der Barrierefreiheit.
In unserem Proof of Concept orchestriert das Process Framework unsere mehrstufige Analyse. Die Schritte werden spezialisierten KI-Agenten zugewiesen, die sich auf bestimmte Aspekte der Barrierefreiheit von Websites konzentrieren - Analyse der HTML-Struktur, Bewertung semantischer Elemente oder Überprüfung visueller Aspekte wie Textkontrast und Schriftgröße. Dank dieses modularen Aufbaus bleibt das System flexibel und ist bereit, in Zukunft zusätzliche Prüfungen zu unterstützen.
Wir haben die Funktionen des Group Chat^15 von Semantic Kernel in Betracht gezogen, fanden aber das Process Framework für unseren Anwendungsfall besser geeignet. Während Group Chat auf die Zusammenarbeit in Echtzeit ausgerichtet ist, eignet sich das Process Framework besser für die Orchestrierung komplexer, wiederholbarer Arbeitsabläufe.
Die Umsetzung des Prozesses
Um sicherzustellen, dass der Arbeitsablauf organisiert, effizient und skalierbar ist, haben wir die Analyse der Zugänglichkeit in zwei verschiedene Teilprozesse aufgeteilt: HTML-Inhaltsanalyse und visuelle Analyse. Diese Unterprozesse arbeiten unabhängig voneinander und werden von einem übergeordneten Prozess gesteuert, der ihre Ergebnisse in einem einheitlichen Bericht zur Barrierefreiheit zusammenfasst.

Jeder Teilprozess führt eine Reihe spezialisierter Schritte aus, um den entsprechenden Aspekt der Zugänglichkeit zu analysieren. Aufgaben innerhalb eines Teilprozesses, wie die Erkennung von Alt-Text oder die Bewertung des Farbkontrasts, werden nach Möglichkeit parallel ausgeführt. Dadurch wird die Gesamtzeit, die für die Analyse der einzelnen Aspekte benötigt wird, reduziert. Auch die Teilprozesse HTML-Inhaltsanalyse und Visuelle Analyse werden parallel ausgeführt, um die Leistung weiter zu optimieren und sicherzustellen, dass schnell umfassende Ergebnisse erzielt werden.
Innerhalb jedes Prozesses werden in Aggregationsschritten die Ergebnisse der einzelnen Analyseaufgaben gesammelt und konsolidiert. So sammelt beispielsweise der Teilprozess HTML-Inhaltsanalyse die Ergebnisse von Aufgaben wie der Überprüfung der Tastaturnavigation und der Formularvalidierung, während der Teilprozess Visuelle Analyse die Ergebnisse der Analyse von Schriftgröße und Farbkontrast verarbeitet. Diese aggregierten Ergebnisse werden dann an den übergeordneten Prozess zurückgegeben, der sie zu einem endgültigen Bericht über die Barrierefreiheit zusammenfasst.
Dieses modulare und parallelisierte Design gewährleistet Flexibilität, Skalierbarkeit und Geschwindigkeit. Durch die Aufteilung des Arbeitsablaufs in klar definierte Prozesse mit paralleler Ausführung können wir die Verarbeitungszeit reduzieren, Schritte wiederverwenden und den Analyserahmen erweitern oder anpassen, ohne das Gesamtsystem zu stören.
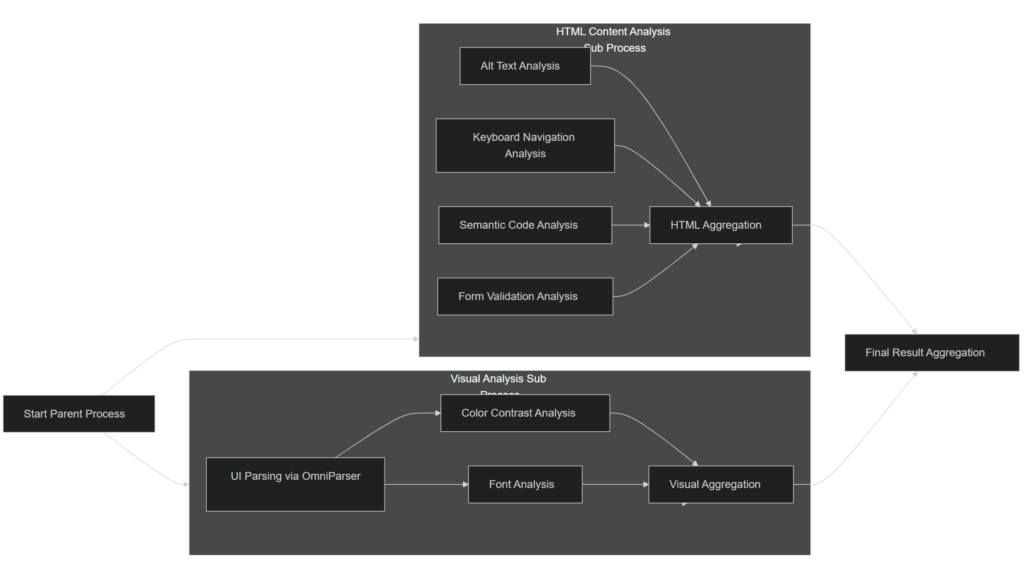
Parallele Ausführung verwalten
Um die parallele Ausführung effektiv zu verwalten, enthält jeder Prozess einen Aggregationsschritt, der die Ergebnisse aller vorherigen Schritte zusammenfasst. Diese Aggregationsschritte sind für die Synchronisierung asynchroner Arbeitsabläufe unerlässlich und stellen sicher, dass keine Aufgabe unvollständig bleibt, bevor zur nächsten Phase übergegangen wird.
Jeder Schritt des Prozesses gibt ein Ereignis aus, wenn er abgeschlossen ist. Diese Ereignisse werden an bestimmte Ereignishandler im Aggregationsschritt weitergeleitet. Der Aggregationsschritt verwaltet ein Statusobjekt mit Flags (Booleschen Flags), um den Abschluss der einzelnen Schritte zu verfolgen. Wenn ein Ereignis den Status aktualisiert, prüft der Handler, ob alle Flags auf true gesetzt sind. Sobald alle Aufgaben im Unterprozess abgeschlossen sind, sendet der Aggregationsschritt sein eigenes Ereignis aus, um dem übergeordneten Prozess ein Signal zu geben oder die nächste Stufe auszulösen.
Durch dieses Design können Aufgaben parallel ausgeführt werden, ohne zu blockieren, und die Pipeline bleibt organisiert, während sichergestellt wird, dass die Ergebnisse jedes Schritts berücksichtigt werden.
HTML-Inhaltsanalyse
Die Schritte im Teilprozess HTML-Inhaltsanalyse konzentrieren sich auf die Analyse des HTML-Quelltextes der Website. Jeder Analyseschritt wird unabhängig implementiert, von Semantic Kernel orchestriert und konzentriert sich auf einen bestimmten Aspekt der Barrierefreiheit.
Der Kern der Analyseschritte:
- Beginnen Sie mit einer Systemaufforderung für das Large Language Model (LLM), die detaillierte Anweisungen zu den Bewertungskriterien und dem erwarteten Ergebnisformat enthält.
- Verwalten Sie den schrittspezifischen Status (z. B. den Chatverlauf), um sicherzustellen, dass der Kontext über alle Interaktionen hinweg erhalten bleibt.
- Verarbeiten Sie in einer Kernel-Funktion eingehende Daten (z.B. HTML-Inhalte von der Webseite) und senden Sie sie mit dem ChatCompletionService^16 des Semantic Kernel.
- Senden Sie die Ergebnisse mit einem
EmitEventAsyncAufruf "zurück". Es wird ein Ereignis ausgegeben, mit dem der Prozess umgehen kann.
Ein Beispiel für eine Eingabeaufforderung für den Schritt Alt-Text-Analyse könnte wie folgt aussehen:
You are an accessibility expert. Your role is to analyze HTML code.
Analyze the HTML_CODE for WCAG 2.1 Level AA accessibility issues, only focusing on:
Alt Text for Images:
1. Meaningful Images Without Alt Text
- Identify images that convey meaningful content but do not have alt text
- Ensure that all images with a functional or informational purpose have descriptive alt text
- Check that alt text is concise, clear, and provides context
2. Decorative Images with Alt Text
- Check that purely decorative images (such as those styled with CSS or providing no information) do not have alt text or have an empty alt="" attribute
- Make sure that images used for visual styling (e.g., icons, borders) do not have misleading alt textVisuelle Analyse mit OmniParser v2
Der Teilprozess Visuelle Analyse funktioniert ähnlich wie der Teilprozess HTML-Inhaltsanalyse. Er verwendet unabhängige Schritte für bestimmte Aufgaben wie die Analyse des Farbkontrasts und die Bewertung der Schriftgröße. Er enthält jedoch auch einen zusätzlichen entscheidenden Schritt: UI Parsing, bei dem OmniParser v2^17 verwendet wird, um strukturierte visuelle und positionelle Daten aus dem mit Playwright erstellten Screenshot zu extrahieren.
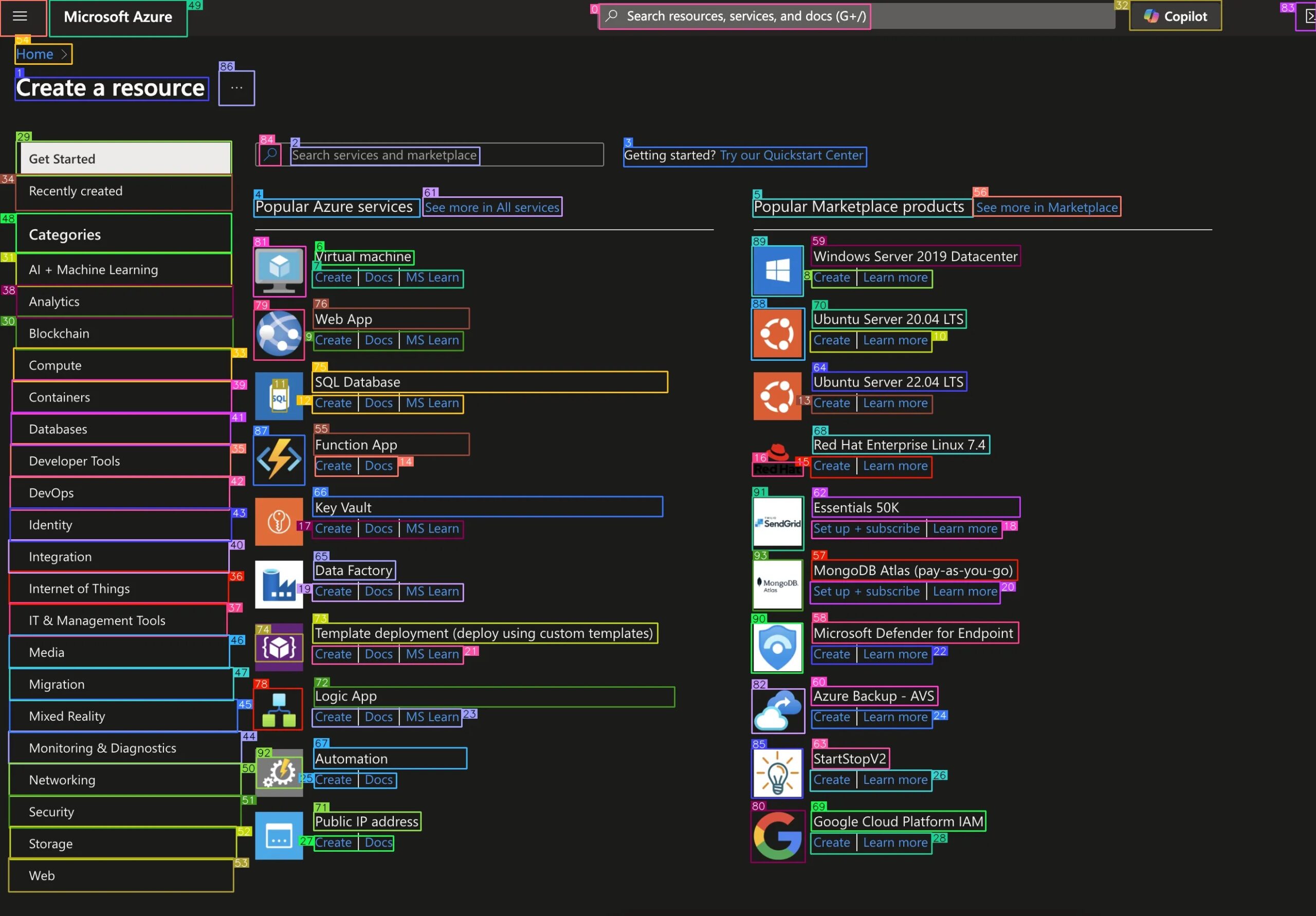
Die Rolle von OmniParser
OmniParser, wie im Microsoft Research Blog^18 beschrieben, ist ein trainiertes KI-Modell. Genauer gesagt handelt es sich um ein auf Deep Learning basierendes Computer-Vision-Modell, das entwickelt wurde, um visuelle Elemente von grafischen Benutzeroberflächen (GUIs) zu verstehen und zu parsen. OmniParser ist im Grunde ein eigenständiges maschinelles Lernmodell, das Computer Vision einsetzt, um visuelle Strukturen zu interpretieren und sinnvolle Inhalte zu extrahieren.
Durch die Verknüpfung visueller Elemente mit semantischem Kontext wandelt OmniParser zuvor unstrukturierte Schnittstellendaten in strukturierte, maschinenlesbare Formate um und ermöglicht so tiefere Einblicke und Analysen.
Im Rahmen unserer Zugänglichkeitslösung wird OmniParser im UI-Parsing-Schritt des Visual Analysis-Workflows verwendet. OmniParser verarbeitet den über Playwright erfassten Screenshot und gibt strukturierte JSON-Daten zurück. Diese Ausgabe liefert:
- Schlüssel: Ein eindeutiger Bezeichner für jedes Element, der mit der Nummer auf dem geparsten Screenshot übereinstimmt.
- Typ: Die Kategorie des Elements (z.B. "Text", "Bild").
- Bounding Box: Visuelle Koordinaten des Elements auf der Seite ([x1, y1, x2, y2]).
- Interaktivität: Ob das Element aktivierbar ist (z. B. eine anklickbare Schaltfläche oder ein Link).
- Inhalt: Der sichtbare Text oder die Beschreibung, die mit dem Element verbunden ist (z.B. Schaltflächenbeschriftungen oder Menütext).
Das vom OmniParser generierte JSON könnte zum Beispiel so aussehen:
[
{
"icon 0": {
"type": "text",
"bbox": [0.45530304312705994,0.004352557007223368,0.6613636612892151,0.03155604004859924],
"interactivity": false,
"content": "O Search resources, services, and docs (G+/)"
}
},
{
"icon 1": {
"type": "text",
"bbox": [0.011363636702299118,0.08487486094236374,0.15833333134651184,0.10990206897258759],
"interactivity": false,
"content": "Create a resource"
}
},
]Strukturierte Daten und LLM
Die von OmniParser generierten strukturierten Daten bilden zusammen mit dem von Playwright erfassten Screenshot die Grundlage für die visuelle Analyse. Indem wir die strukturierten Daten zusammen mit dem Screenshot in die Eingabeaufforderung des LLM aufnehmen, möchten wir dem LLM zusätzliche Kontextinformationen über die visuellen Elemente der Website geben, z. B. über deren Inhalt, Platzierung und Interaktivität.
Wir vermuten zwar, dass dieser Dual-Input-Ansatz die Fähigkeit des LLM zur Bewertung von Zugänglichkeitsproblemen verbessert, aber das ist noch nicht abschließend getestet worden. Theoretisch könnten die strukturierten Daten explizite räumliche Beziehungen und inhaltliche Details liefern und dem LLM helfen, visuelle Elemente umfassender zu analysieren. In Kombination mit dem Screenshot könnten diese Eingaben es dem LLM ermöglichen, visuelle und semantische Kontexte miteinander zu vergleichen, um potenzielle Probleme mit Layout, Kontrast oder Interaktivität zu identifizieren.
Arbeiten mit den Ergebnissen
Um sicherzustellen, dass die Ausgabe der einzelnen Analyseschritte strukturiert und einfach zu verarbeiten ist, fügen wir in jede Eingabeaufforderung eine Systemmeldung ein, die das erwartete Ausgabeformat definiert. Auf diese Weise werden die Ergebnisse der einzelnen Analyseprogramme standardisiert, so dass sich die Daten leicht deserialisieren lassen.
Sobald alle Analyseschritte und ihre Unterprozesse abgeschlossen sind, fasst der übergeordnete Prozess die Ergebnisse der beiden Unterprozesse HTML-Inhaltsanalyse und Visuelle Analyse zusammen. Die endgültige Ausgabe ist ein strukturiertes JSON-Objekt, das Folgendes enthält:
{
"analysis": [
{
"id": "2.1.1", // WCAG success criterion reference, e.g., "1.1.1"
"error": "Code.Keyboard.Focusable", // unique error code, 'Code' if html was analyzed, 'Visual' if screenshot was analyzed
"category": "Keyboard Accessibility", // category of the agent performing the analysis
"description": "Element is not keyboard-focusable.", // Very brief description of the issue, acts as the title
"detail": "All interactive elements must be accessible via keyboard navigation.", // Description of the issue
"location": "Line 10, Column 20: <span id="foo">Bar</span>" // Location of the issue in the code, or a description where in the screenshot if a screenshot is provided
}
]
}Um zu veranschaulichen, wie die Ergebnisse in der Praxis aussehen, sehen Sie hier ein Beispiel für die JSON-Ausgabe, die durch den Analyseprozess erzeugt wird:
{
"analysis": [
{
"id": "1.1.1",
"error": "Code.Image.MissingAlt",
"category": "Alt Text for Images",
"description": "Meaningful image lacks alt text.",
"detail": "The image at <img src="og-image.png"> is meaningful but does not have alt text. Add descriptive alt text.",
"location": "Element in meta tag with attribute: property='og:image'",
"information": []
},
{
"id": "2.4.3",
"error": "Code.Keyboard.TabOrder",
"category": "Keyboard Accessibility",
"description": "Incorrect Tab Order value used.",
"detail": "`tabindex="-1"` on non-modal elements disrupts logical navigation as it removes them from the tab order.",
"location": "Line 10: <span tabindex="-1"></span>",
"information": []
},
{
"id": "3.1.2",
"error": "Forms.Missing.Label",
"category": "Form Accessibility",
"description": "Missing form labels.",
"detail": "The 'Search' button lacks a proper label or an aria-label to describe its purpose.",
"location": "Line containing `<button aria-label='Search'>`.",
"information": []
},
{
"id": "1.3.1",
"error": "Forms.Placeholder.Misuse",
"category": "Form Accessibility",
"description": "Placeholder as label.",
"detail": "The 'Search' button uses the placeholder 'Search' as the only means of labeling, which is an incorrect accessibility practice.",
"location": "Line containing `<span class='DocSearch-Button-Placeholder'>Search</span>`.",
"information": []
},
...
],
"summary": {
"failed": 12
}
}Die Liste der Analyseergebnisse wird an die vom Benutzer aufgerufene API-Funktion zurückgegeben und als strukturierte JSON-Antwort zurückgesendet. Unser Proof of Concept endet hier, und wir haben keine Benutzeroberfläche zur Visualisierung der Ergebnisse implementiert. Die JSON-Ausgabe kann jedoch problemlos in einem Front-End-Framework oder einem Berichtstool verwendet werden, um die Ergebnisse anzuzeigen.
Fazit
Diese POC demonstrierte das Potenzial der Kombination von Semantic Kernel, OpenAI-Modellen und Tools wie OmniParser, um die Analyse der Barrierefreiheit von Websites zu automatisieren. Die Lösung erzielte solide Ergebnisse als Ausgangspunkt, insbesondere bei der Analyse der HTML-Struktur und der visuellen Elemente auf WCAG-Konformität.
Für die Orchestrierung des Analyse-Workflows haben wir uns auf Semantic Kernel verlassen. Sein Prozess-Framework vereinfachte die Implementierung des mehrstufigen Prozesses, indem es Zustandsverwaltung, Ereignisbehandlung und Koordination zwischen Agenten ermöglichte. Dieses modulare Design machte es einfach, das System zu entwickeln und zu erweitern, ohne unnötige Komplexität einzuführen.
Die OpenAI-Modelle schnitten in bestimmten Bereichen gut ab, z. B. bei der Diagnose von Alt-Text-Problemen und der semantischen Code-Validierung, aber sie waren nicht ohne Einschränkungen. Die Begrenzung der Token stellte eine Herausforderung dar, wenn größere Abschnitte des HTML-Quelltextes an mehrere Agenten gesendet werden sollten, was sorgfältige Anpassungen erforderte, um das Abschneiden wichtiger Inhalte zu vermeiden. Um die Kosten zu kontrollieren, sind wir während der Entwicklung von GPT-4 auf GPT-3.5 umgestiegen. Sowohl GPT-4 als auch GPT-3.5 produzierten gelegentlich Halluzinationen, wie z.B. die Erzeugung von nicht existierendem HTML-Code. Diese Probleme zeigen, dass bei der Verwendung von Sprachmodellen für Aufgaben, die eine hohe Genauigkeit erfordern, zusätzliche Validierungsebenen erforderlich sind.
Es gab auch einige unerwartete Herausforderungen bei der Integration von OmniParser. Die auf Hugging Face^19 gehostete Instanz gab während der Tests Fehler zurück, so dass wir OmniParser selbst hosten mussten, um fortfahren zu können.
Trotz dieser Herausforderungen haben die Ergebnisse gezeigt, dass KI - in diesem Stadium - eine Reihe von Zugänglichkeitsproblemen aufdecken und Erkenntnisse liefern kann, die für Entwickler umsetzbar sind. Die strukturierten JSON-Ausgaben unseres Systems legen den Grundstein für die Integration in Frontend-Tools oder Berichtsplattformen.
Was könnte verbessert werden?
Obwohl die Demo vielversprechende Ergebnisse zeigte, gibt es mehrere Bereiche, die für künftige Iterationen verfeinert werden könnten, darunter:
Spezialisierte Modelle für die Analyse der Zugänglichkeit
Derzeit werden allgemeine Sprachmodelle wie GPT-3.5 und GPT-4 für die Analyse verwendet. Diese Modelle haben zwar gut funktioniert, aber die Entwicklung oder Feinabstimmung spezieller Modelle, die sich speziell auf Fragen der Barrierefreiheit konzentrieren, könnte die Genauigkeit verbessern und die Wahrscheinlichkeit von Halluzinationen verringern. Ein Modell, das auf barrierefreie Datensätze trainiert wurde, wäre auch besser in der Lage, Nuancen bei der Einhaltung der WCAG zu berücksichtigen.
Optimierte Token-Verwendung
Die Begrenzung von Token war eine der größten Herausforderungen bei der parallelen Verarbeitung größerer Abschnitte des Quellcodes. Diese Einschränkung erforderte sorgfältige Anpassungen, um sicherzustellen, dass keine wichtigen Informationen vor der Analyse abgeschnitten wurden. Eine Möglichkeit, dieses Problem zu lösen, könnte darin bestehen, den HTML-Code vor dem Senden an die Modelle zu verkleinern, um die Verwendung von Token zu reduzieren. Es wären jedoch weitere Tests erforderlich, um sicherzustellen, dass dies die Erkennungsgenauigkeit nicht beeinträchtigt, insbesondere in Szenarien, in denen Formatierung oder Elementbeziehungen eine wichtige Rolle spielen.
Eine andere Lösung besteht darin, Large Language Models mit größeren Kontextfenstern zu verwenden. Neuere Modelle wie Gemini 2.0 Pro^20 bieten beispielsweise ein Kontextfenster von bis zu 2 Millionen Token, was weit über die Grenzen von GPT-3.5 oder GPT-4 hinausgeht.
Darüber hinaus bietet der Azure OpenAI Service Flexibilität bei der Verwaltung der Token-Nutzung. Die Grenzen der Token-Rate können über Azure AI Foundry für die ausgewählte LLM-Bereitstellung angepasst werden, so dass Entwickler die Einstellungen besser auf bestimmte Arbeitslasten abstimmen können. Durch die Anpassung dieser Einstellungen ist es möglich, einige der praktischen Beschränkungen bei der Eingabeverarbeitung abzuschwächen und die Arbeitsabläufe für komplexere, umfangreiche Analysen zu optimieren.
Discovering Playwright MCP
Während ich diesen Artikel schrieb, stieß ich auf das Playwright MCP Repository^21 von Microsoft, das LLMs die Möglichkeit bietet, Webseiten mit Playwright zu analysieren und mit ihnen zu interagieren.
MCP (Model Context Protocol) dient als standardisierter Weg für KI-Anwendungen zur Verbindung mit Datenquellen und Tools. Anthropic beschreibt MCP als "USB-C für KI-Anwendungen"^22 und vereinfacht den Austausch von Kontext zwischen LLMs und externen Systemen.
Das wäre ein ganzer Artikel für sich allein.
Playwright MCP ermöglicht es LLMs, auf Webseiten zu navigieren, Formulare auszufüllen, Schaltflächen anzuklicken und Daten zu extrahieren. Ein wichtiges Merkmal ist die Fähigkeit, den Zugänglichkeitsbaum einer Webseite zu verwenden, der die Elemente der Benutzeroberfläche so darstellt, wie sie von unterstützenden Technologien gesehen werden. Auf diese Weise kann das Tool Benutzeroberflächen analysieren, ohne dass der LLM direkt rohes HTML verarbeiten muss. Playwright MCP unterstützt auch die screenshotbasierte Analyse durch einen visuellen Modus, was es zu einer flexiblen Option für verschiedene Arten von Arbeitsabläufen macht.
Aufgrund seiner Fähigkeit, mit dem Zugänglichkeitsbaum zu interagieren, könnte Playwright MCP den OmniParser als Teil zukünftiger Iterationen ergänzen. Durch die Bereitstellung eines direkten, standardkonformen Mechanismus zur Bewertung von UI-Elementen verringert sich die Abhängigkeit von eigenständigen visuellen Parsing-Tools oder von HTML-Quellcode, was die Architektur vereinfachen und gleichzeitig die Ergebnisse verbessern könnte.
Auf jeden Fall einen Blick wert!
Letzte Überlegungen
Angesichts der im Juli 2025 ablaufenden Frist für die Einhaltung von Barrierefreiheitsstandards in der EU war es noch nie so wichtig wie heute, der digitalen Barrierefreiheit Priorität einzuräumen. KI-gesteuerte Tools, wie die in diesem POC untersuchten, können eine wachsende Rolle bei der Unterstützung von Entwicklern und Experten für Barrierefreiheit spielen, indem sie potenzielle Probleme identifizieren und verwertbare Erkenntnisse liefern.
KI ist zwar kein Ersatz für statische Analysetools oder menschliches Fachwissen, aber sie kann bestehende Bemühungen ergänzen, indem sie Bereiche aufspürt, die andernfalls übersehen werden könnten, und den Prüfungsprozess beschleunigt. Trotz ihrer derzeitigen Einschränkungen zeigen die hier erzielten Fortschritte, wie KI heute einen sinnvollen Beitrag zur Analyse der Barrierefreiheit leisten kann - und ihre Rolle wird mit der weiteren Verfeinerung dieser Tools nur noch wachsen.
Dieser Artikel ist Teil des XPRT. Magazin. Die Goldene Ausgabe! Laden Sie Ihr kostenloses Exemplar hier herunter

Verfasst von
Xebia Author
Contact