Über diese Serie
Microsoft Fabric macht den Einstieg mit einem einzelnen Arbeitsbereich und einem einzelnen Entwickler leicht. Sobald Sie ein Team hinzufügen, stellen sich unübersichtlichere Fragen: wer arbeitet wo, wie werden Zweige und Arbeitsbereiche synchronisiert und wie kann man allen nutzbare Daten zur Verfügung stellen, ohne das Lakehouse wiederholt zu klonen.
In Teil 1 sind wir in einem einzigen Arbeitsbereich geblieben und haben uns auf die interne Struktur und die Namensgebung konzentriert. In diesem Beitrag zoomen wir eine Ebene weiter: wie Sie mehrere Arbeitsbereiche und Git-Zweige einrichten, damit mehrere Entwickler parallel arbeiten können , ohne ständig ihr eigenes Seehaus neu zu bauen.
Das Problem: Multi-Entwickler-Chaos auf Fabric
Die Happy Path-Demo zeigt normalerweise einen einzelnen Entwickler in einem einzigen Arbeitsbereich. Echte Projekte sehen nicht so aus. Im wirklichen Leben:
- Sie haben mehrere Mitarbeiter, die an der gleichen Fabric-Lösung arbeiten.
- Viele von ihnen ziehen es vor, in der Fabric UI zu arbeiten, nicht nur in VS Code.
- Sie möchten Git für die Versionskontrolle und die Bereitstellung integrieren.
- Die Git-Integration von Fabric verwendet ein Modell mit 1 Arbeitsbereich = 1 Zweig.
Dieser letzte Punkt ist der Punkt, an dem es interessant wird:
Ein Arbeitsbereich kann immer nur mit einem Git-Zweig verknüpft werden. Sie können ändern, auf welchen Zweig er verweist, aber es handelt sich immer um eine Eins-zu-Eins-Beziehung.
Das wirft sofort eine Frage auf:
- Wie können Sie die Leute gleichzeitig an verschiedenen Funktionen arbeiten lassen?
- Während Sie weiterhin die Benutzeroberfläche verwenden,
- Und sich nicht gegenseitig auf die Füße treten?
Darüber hinaus stoßen Sie schnell auf ein zweites Problem: Daten.
- Arbeitsbereiche sind nicht Git-synchronisiert.
- Notebook- und Pipeline-Definitionen sind Git-synchronisiert.
- Die Metadaten von Lakehouse und Warehouse sind Git-synchronisiert, die Daten nicht.
Selbst wenn Sie das Problem mit den Arbeitsbereichen und Zweigen gelöst haben, kann es vorkommen, dass Sie Arbeitsbereiche haben, die zwar technisch "fertig" sind, aber keine nützlichen Daten enthalten.
In diesem Beitrag geht es um die Einrichtung, die sowohl die Zusammenarbeit als auch den Datenzugriff möglich macht.
Kurzes Resümee: Was Git synchronisiert (und nicht synchronisiert)
Wir brauchen hier nur ein leichtes mentales Modell:
| Item type | Git synced? | Notes |
|---|---|---|
| Workspace | No | Just a container. Binding to a branch is a setting, not in Git. |
| Lakehouse / Warehouse | Partially | Item + schema/metadata synced. Data is not in Git. Each workspace can have its own instance of a lakehouse item, but only some of them will actually contain data. |
| Notebook / Pipeline / Dataflow | Yes | Definitions stored as artifacts in Git. |
Die wichtigste Folge:
Ein brandneuer Feature-Arbeitsbereich, der mit einer Verzweigung verknüpft ist, zieht Notebooks, Pipelines, semantische Modelle und die leere Hülle Ihres Lakehouses herunter, verfügt aber nicht auf magische Weise über eine vollständige Kopie Ihrer Lakehouse-Daten.
Wenn wir in diesem Zusammenhang von "Wiederaufbau" oder "Rehydrierung" eines Lakehouse sprechen, meinen wir damit die gesamte Abfolge von Schritten, die erforderlich sind, um diese leere Hülle wieder in etwas für die Entwicklung Brauchbares zu verwandeln: das erneute Ausführen von Ingestion-Pipelines, die Neuerstellung von Tabellen, das Kopieren oder Wiederherstellen von Daten und manchmal auch die Korrektur von Berechtigungen und Konfigurationen.
Wenn jeder Entwickler "sein" Lakehouse als primäre Datenquelle behandeln würde, müsste immer noch jemand dieses Lakehouse rehydrieren: die Ingestion erneut ausführen, Daten kopieren oder einen manuellen Import durchführen. Das wird sehr schnell langweilig.
Schauen wir uns zunächst die Arbeitsplatzoptionen an, die Teams normalerweise in Betracht ziehen.
Option 1: Alle im gleichen Entwicklungsarbeitsbereich und in der gleichen Niederlassung
Die offensichtlichste Variante:
- Ein Dev-Arbeitsbereich.
- Ein Zweig (oft
mainoderdevelop). - Alle Entwickler arbeiten in diesem Arbeitsbereich, an diesem Zweig.
Auf dem Papier:
- Es gibt nur einen Ort, an dem Sie etwas finden können.
- Niemand muss mehr darüber nachdenken, welchen Arbeitsbereich er öffnen soll.
- Die Git-Integration zeigt "nur" auf diesen einen Zweig.
In der Praxis stoßen Sie schnell auf Probleme:
- Interferenzen - Personen überschreiben gegenseitig ihre Änderungen, weil sie an denselben Elementen arbeiten.
- Unausgereifte Funktionen - Es ist schwer, halbfertige Arbeiten aus dem nächsten Einsatz herauszuhalten.
- Keine saubere Isolierung - Sie können eine Funktion nicht einfach von Anfang bis Ende testen, ohne sich Gedanken darüber zu machen, was jemand anderes gerade tut.
- Git-Rauschen - Kleine "Fix"-Commits von verschiedenen Funktionen landen alle auf demselben Zweig und sind in einem PR schwer zu entwirren.
Wann kann dies noch akzeptabel sein (aber dennoch nicht empfohlen)?
- Teams von 1.
-
Teams of 2, who:
- gleichzeitig an der gleichen Funktion arbeiten,
- und sind sehr diszipliniert bei der Koordination.
Für fast alle anderen wird dies schneller zum Engpass, als Sie zugeben möchten.
Option 2: Zentraler Entwicklungs-/Test-/Prozessbereich + persönliche Arbeitsbereiche für Funktionen
Die von Microsoft empfohlene Richtung sieht folgendermaßen aus.
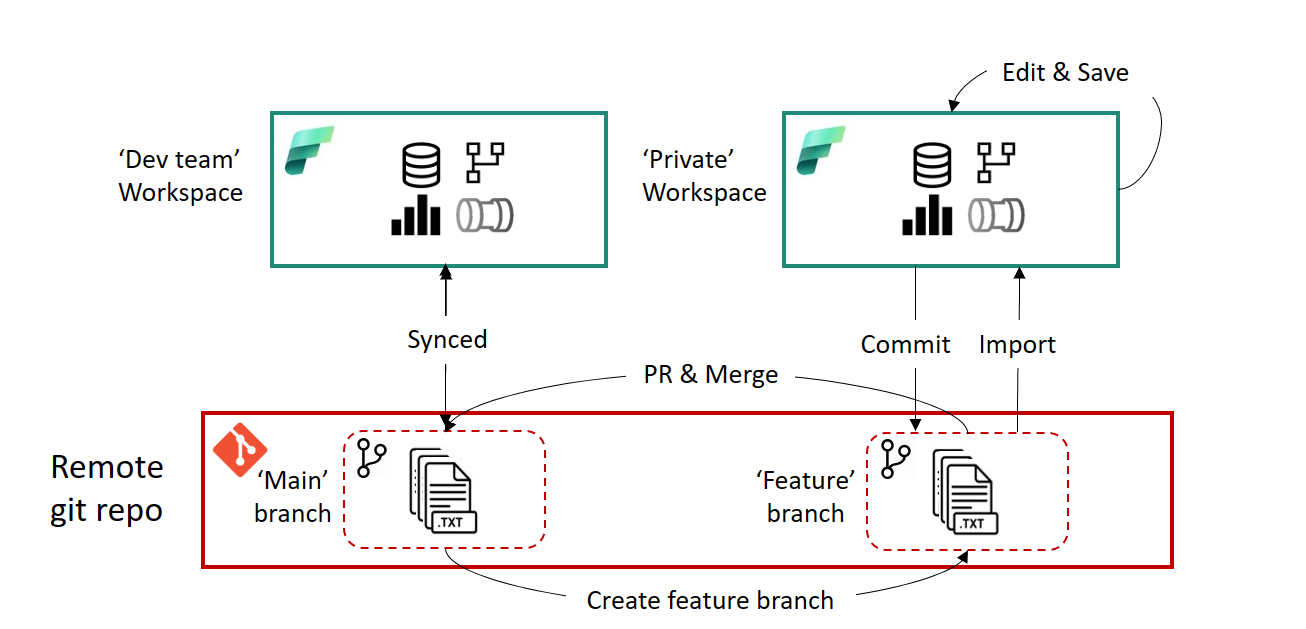
-
A set of central workspaces:
project1-devproject1-testproject1-prod
-
A set of personal workspaces, one per active developer:
project1-dev-rikproject1-dev-saraproject1-dev-joost- …
Zusammen mit einem eher klassischen Git-Verzweigungsmodell:
workspace-devist mit demmainZweig.- Jeder persönliche Arbeitsbereich ist mit einem Funktionszweig verknüpft.
Das Konzept dieses Systems bietet eine Menge Vorteile:
- Isolierte Bereiche pro Entwickler.
- Saubere Git-Historie und PRs.
- Zentrale Dev/Test/Prod für gemeinsam genutzte Umgebungen.
Aber wenn Sie es naiv umsetzen, stoßen Sie auf das bereits erwähnte Problem der Rehydrierung.
Brandneuer persönlicher Arbeitsbereich + Feature Branch = Code-Definitionen und eine leere Lakehouse-Hülle, aber standardmäßig keine nützlichen Daten.
Das Prinzip: Nur zentrale Arbeitsbereiche werden mit Daten bestückt
Hier ist die Schlüsselidee, die den Schmerz des "Rehydrierens des Seehauses" beseitigt und gleichzeitig jedem einen Seehausartikel in seinem Arbeitsbereich bietet:
Lakehouses werden über Git mit jedem Arbeitsbereich synchronisiert, aber nur der zentrale Arbeitsbereich wird mit echten Daten befüllt. Die Feature-Arbeitsbereiche haben die gleichen Lakehouse-Definitionen, aber diese bleiben meist leer und sind nicht die primäre Datenquelle.
Wonach das aussieht:
- Central Dev workspace:
- Besitzt das Haupthaus am See mit aktuellen Entwicklungsdaten.
- Ihm gehören die Pipelines, die in das Seehaus führen.
- Personal feature workspaces:
- Erhalten Sie die gleichen Lakehouse-Artefakte durch Git-Synchronisation.
- Führen Sie keine vollständige Ingestion in ihre lokalen Kopien durch.
- Notebooks und Pipelines in diesen Arbeitsbereichen verbinden sich zum Lesen und Schreiben mit dem zentralen Dev Lakehouse, anstatt sich auf die lokale, meist leere Instanz zu verlassen.
Dies ist der Teil, der sich in der Benutzeroberfläche von Fabric kontraintuitiv anfühlt:
- Das Standardmuster ist "Notizbuch an ein Seehaus im selben Arbeitsbereich anhängen".
- Hier wird Ihr Notebook in
workspace-dev-rikabsichtlich mit dem Seehaus arbeiten, das inworkspace-devlebt.
Warum es sich lohnt:
Wenn ein Entwickler einen neuen Funktionsarbeitsbereich erstellt, ihn mit einer Verzweigung verknüpft und synchronisiert, kann er die Notizbücher sofort mit echten Entwicklungsdaten vergleichen. Kein zusätzliches Einlesen, kein manuelles Kopieren, kein benutzerdefinierter Rehydrierungsschritt.
Sie haben zwei Anliegen getrennt:
- Wo Daten tatsächlich leben und kuratiert werden → in stabilen, zentralen Arbeitsbereichen.
- Wo Code bearbeitet und verzweigt wird → in flexiblen, verzweigungsgebundenen persönlichen Arbeitsbereichen, die nur die Definitionen von Lakehouse enthalten.
Ein ganz normaler Tag: Entwicklerfluss
Aus der Sicht eines Entwicklers sieht eine typische Funktion wie folgt aus:
-
Erstellen Sie einen Feature-Zweig von
main
Beispiel:feature/calculated-customer-metrics. -
Binden Sie Ihren persönlichen Arbeitsbereich an die Zweigstelle
Verknüpfen Sieworkspace-dev-rikmitfeature/calculated-customer-metricsund synchronisieren Sie. -
Connect notebooks/pipelines to the central lakehouse
- Hängen Sie an
lh_projectinworkspace-dev(oder einem anderen zentralen Entwicklungsarbeitsbereich). - Optional können Sie Zwischendaten in ein spezielles Schema oder einen Ordner für Ihre Funktion schreiben.
- Hängen Sie an
-
Develop and test
- Hinzufügen oder Aktualisieren von Notizbüchern und Pipelines.
- Führen Sie sie gegen gemeinsam genutzte Entwicklungsdaten aus, ohne etwas in Ihrem eigenen Arbeitsbereich zu rehydrieren.
-
Push and open a pull request
- Bestätigen Sie Ihre Änderungen.
- Öffnen Sie einen PR in
main. - Lassen Sie automatische Prüfungen und Code-Reviews ihre Arbeit tun.
-
Merge and sync Dev
- Führen Sie den PR zusammen.
- Synchronisieren Sie
workspace-devmitmain. - Von dort aus leiten Sie das Programm über den von Ihnen gewählten Bereitstellungsablauf an Test/Prod weiter.
Das haben Sie zu keinem Zeitpunkt getan:
- Kopieren Sie das gesamte Seehaus in jeden persönlichen Arbeitsbereich, oder
- Bitten Sie jeden Entwickler, einen vollständigen Ingestion-Job auszuführen, nur um loszulegen.
Arbeitsbereichsübergreifender Zugriff: Große Leistung, scharfe Kanten
Mit Stoffen können Sie Ihre Arbeitsbereiche ganz einfach kombinieren:
- Pipelines können andere Pipelines in einem anderen Arbeitsbereich auslösen.
- Notebooks können Daten in einem Lakehouse lesen/schreiben, das sich nicht im selben Arbeitsbereich befindet.
Das ist es, was solche Muster ermöglicht:
- Trennung zwischen Ingestion-Workspaces und Transformations-Workspaces.
- Arbeitsbereiche, die Daten in einer gemeinsamen Entwicklungsumgebung lesen und schreiben.
- Ein zentraler "Orchestrierungs"-Arbeitsbereich, der Aufträge über Domänen hinweg koordiniert.
So weit, so gut. Die scharfe Kante erscheint nur, wenn Git und Löschungen ins Spiel kommen.
Im Moment kann die Git-Synchronisierung fehlschlagen, wenn ein Commit ein Element in einem Arbeitsbereich löscht, während dasselbe Element noch von einem anderen Arbeitsbereich referenziert wird. Wenn Dev versucht, mit diesem Commit zu synchronisieren, erkennt Fabric, dass das Löschen diese arbeitsbereichsübergreifenden Referenzen zerstören würde und verweigert die Synchronisierung.
Dies zeigt sich häufig bei der Einrichtung von Funktionsarbeitsbereichen.
Beispiel: Löschen einer Pipeline in einem Feature-Arbeitsbereich
Stellen Sie sich vor, Sie haben:
- Ein zentraler Dev-Arbeitsbereich, der an
maingebunden ist. - Zwei Feature-Arbeitsbereiche, die jeweils an einen eigenen Zweig gebunden sind.
- Eine gemeinsame Pipeline namens
pl_ingest_customers, die mit allen von Git aus synchronisiert wird. - In einem der Feature-Workspaces ruft eine andere Pipeline oder ein Datenfluss noch
pl_ingest_customersauf.
Nun entscheiden Sie, dass pl_ingest_customers für Ihr Feature nicht mehr benötigt wird:
- Sie löschen
pl_ingest_customersin Ihrem Feature-Arbeitsbereich. - Sie übertragen und öffnen einen PR und fügen diese Löschung in
mainein. - Sie synchronisieren den Dev-Arbeitsbereich mit dem neuen
main.
Aus der Sicht von Git besagt der Commit: "pl_ingest_customers ist weg."
Aber in dem anderen Arbeitsbereich gibt es immer noch eine Pipeline oder einen Datenfluss, der auf pl_ingest_customers verweist.
Wenn Dev versucht, zu synchronisieren:
- Fabric sieht, dass die Anwendung des Löschens diese andere Referenz zerstören würde.
- Er verweigert die Synchronisierung und zeigt einen Fehler an.
Aus Ihrer Perspektive fühlt sich das so an:
Ich habe gerade eine Pipeline in meinem Feature-Arbeitsbereich bereinigt. Warum lässt sich Dev nicht mehr synchronisieren?
Aus der Sicht von Fabric verhindert es, dass Sie einen anderen Arbeitsbereich beschädigen, der auf dasselbe Repository zurückgreift.
Was Sie damit in der Praxis tun können
Dieses Sicherheitsnetz ist nützlich, aber es bedeutet auch, dass Sie sich genau überlegen müssen, wo Sie Abhängigkeiten zwischen Elementen schaffen.
Faustformel:
- Halten Sie die meisten Elementabhängigkeiten in einem einzigen Arbeitsbereich
Wenn eine Pipeline oder ein Datenfluss eine andere Pipeline aufruft, ziehen Sie es vor, diese Beziehung in einem einzigen Arbeitsbereich zu halten, anstatt sie über mehrere zu verteilen. - Bevorzugen Sie die datenbasierte Integration über Arbeitsbereiche hinweg
Das Lesen und Schreiben von Tabellen oder Dateien in einem gemeinsam genutzten Lakehouse führt viel seltener zu Git-Löschkonflikten als die Verkettung von Pipelines oder Datensätzen über Arbeitsbereiche hinweg.
Wie dies in das Muster des zentralisierten Seehauses passt
Für das zentralisierte Seehaus in diesem Beitrag bedeutet das Folgendes:
- Es ist in Ordnung, dass alle Arbeitsbereiche von dem zentralen Lakehouse
abhängen. Sie haben nicht vor, dieses Lakehouse zu löschen; es ist das gemeinsame Rückgrat Ihrer Lösung. - Be much more cautious with shared pipelines, dataflows and notebooks
Either:- diese Abhängigkeiten vollständig in einem zentralen Arbeitsbereich zu halten, oder
- verwalten Sie sie sorgfältig und koordinieren Sie die Löschungen.
Indem Sie fast alle Abhängigkeiten von Element zu Element lokal in einem Arbeitsbereich halten und nur das Lakehouse selbst zentralisieren, verringern Sie die Wahrscheinlichkeit, dass eine kleine Bereinigung in einem Funktionszweig die Git-Synchronisierung für alle anderen blockiert, erheblich.
Do's und Don'ts für die Skalierung des Arbeitsbereichs
Um dies zu konkretisieren, finden Sie hier eine kurze Liste, die Sie zu Teamkonventionen machen können.
Do's
- Verwenden Sie zentralisierte Arbeitsbereiche, um bevölkerte Lakehouses zu besitzen
Dev-, Test- und Prod-Lakehouses mit echten Daten leben in einer kleinen Anzahl stabiler Arbeitsbereiche. - Lassen Sie Lakehouse-Definitionen über Git
mit Feature-Workspaces synchronisieren. Dadurch werden Schemata und Tabellenstrukturen angeglichen, ohne dass die vollständigen Daten kopiert werden. - Geben Sie jedem aktiven Entwickler einen persönlichen Arbeitsbereich
, der mit seinem Funktionszweig verknüpft ist; so bleiben die Funktionen isoliert. - Standardisieren Sie den Arbeitsablauf der Entwickler
"Branch → bind workspace → develop → PR → merge → sync Dev" sollte dokumentiert und langweilig sein. - Legen Sie den arbeitsbereichsübergreifenden Zugriff eindeutig fest
Legen Sie fest, welche Arbeitsbereiche Objekte in anderen Arbeitsbereichen verwenden können und unter welchen Bedingungen.
Tadeln
- Stecken Sie nicht alle Entwickler in einen einzigen Dev-Arbeitsbereich und verzweigen Sie standardmäßig
Es mag einfach aussehen, aber ab einem sehr kleinen Team versagt es fast immer. - Füllen Sie das Lakehouse nicht in jedem Feature-Arbeitsbereich vollständig aus
. Das vervielfacht nur den Aufnahmeaufwand und erhöht das Risiko einer Datenabweichung. - Verstecken Sie Rehydrierungsschritte nicht in Stammeswissen
Wenn in einem Arbeitsbereich Daten kopiert oder wieder aufgefüllt werden müssen, automatisieren Sie dies und machen Sie es zu einem klaren, wiederholbaren Schritt.
Zusammenfassung
Mit einer internen Struktur (Teil 1) und der Einrichtung eines Arbeitsbereichs für mehrere Entwickler (dieser Beitrag) haben Sie ein Skelett, das sowohl in die Tiefe (mehr Artefakte) als auch in die Breite (mehr Entwickler) skaliert.
Wenn Sie mit Ihrer eigenen Workspace-Topologie experimentieren und dabei auf scharfe Kanten stoßen, insbesondere im Zusammenhang mit Workspace-übergreifenden Abhängigkeiten und der Git-Synchronisierung, würde ich mich freuen, Ihre Erfahrungen zu hören - sie sind genau die Art von Feedback aus der Praxis, auf der diese Serie aufbaut.
Verfasst von
Rik Adegeest
Rik is a dedicated Data Engineer with a passion for applying data to solve complex problems and create scalable, reliable, and high-performing solutions. With a strong foundation in programming and a commitment to continuous improvement, Rik thrives on challenging projects that offer opportunities for optimization and innovation.
Unsere Ideen
Weitere Blogs




Contact