Eine der weniger diskutierten Anwendungen des maschinellen Lernens ist die Zeitreihenvorhersage, die für die Vorhersage der zukünftigen Werte Ihrer Geschäftskennzahlen, aber auch für die Identifizierung der Saisonalität der Nachfrage in Ihrer spezifischen Branche verwendet werden kann. Hier möchte ich ein genaues Beispiel dafür zeigen, wie dies funktioniert - und warum es so vorteilhaft ist.
Wir werden den Prescriptive Analytics-Ansatz von Gartner anwenden, um Rückblicke, Einblicke und Voraussichten über die Aktivitäten des Carsharing-Netzwerks Traficar zu gewinnen. Wir werden erfahren, wie genau wir in der Lage sind, die Nutzung der Autoflotte vorherzusagen, die derzeit auf den Straßen von Wrocław - unserer Heimatstadt - unterwegs ist.
Einsicht
Vielleicht erinnern Sie sich an unsere Analyse des elektrischen Carsharing-Netzwerks Vozilla aus dem Jahr 2018, als wir ein Whitepaper veröffentlichten, in dem wir beschrieben, was wir aus der langen Beobachtung der Autoverfügbarkeitskarte lernen können. Wir haben die Daten eines halben Jahres analysiert, aber es gibt eine Sache, die wir Ihnen damals nicht gesagt haben: Wir haben nicht nur die Web-API von Vozilla gecrappt, sondern auch den lokalen Konkurrenten, das Carsharing-Unternehmen Traficar.
Es ist einige Zeit vergangen und während ich diese Zeilen schreibe, haben wir die Website von Traficar seit über 21 Monaten im Minutentakt durchforstet.
In der folgenden Analyse war Web Scraping die einzige Datenquelle und wir können nicht für die Richtigkeit der Daten garantieren. Alle Schlussfolgerungen in Bezug auf die Einnahmen oder die Rentabilität von Traficar können schlichtweg falsch sein.
Ein einzelner, isolierter API-Daten-Snapshot liefert nicht viele Informationen - er liefert uns lediglich eine Liste der zu einem bestimmten Zeitpunkt zur Vermietung verfügbaren Autos, mit Tankfüllständen und Koordinaten. Erst wenn wir beginnen, solche Daten über längere Zeiträume zu verfolgen, können wir damit beginnen, die Ereignisse nachzubilden und alle sich abzeichnenden Muster zu verfolgen.
Wenn wir die Aktivitäten von Traficar in unserer Stadt Wrocław verfolgen, sollte die erste Frage lauten: Wie viele Autos sind/waren zur Vermietung verfügbar?
Wenn wir unsere Aufzeichnungen nach Tagen gruppieren und die täglichen Nummernschilder zählen, sehen wir das folgende Diagramm - bis zu 149 Autos sind auf einmal verfügbar, aber in einem bestimmten Zeitraum waren genau 200 Autos in der Region verfügbar. Einige kamen hinzu, während andere verschwanden - für einen kurzen Zeitraum waren auch einige elektrische Renault ZOEs verfügbar. In der folgenden Analyse werden wir uns jedoch nur auf die Fahrten mit dem Reno Clio Pkw konzentrieren, die über 95% des gesamten Verkehrsaufkommens des Unternehmens ausmachen.
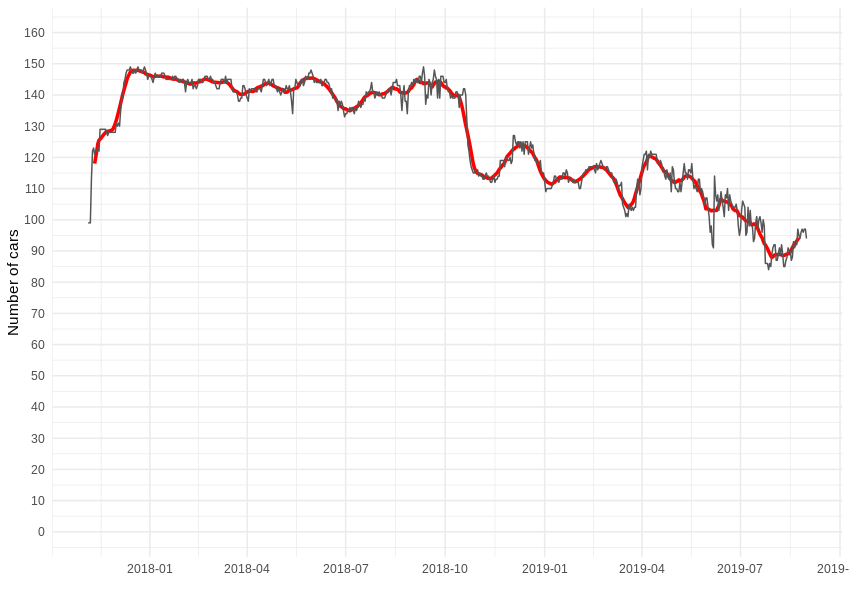
Wenn es um die Vermietungsaktivität geht, ist es mit einigem Aufwand verbunden, Ereignisse im Zusammenhang mit bestimmten Fahrzeugen zu rekonstruieren. Zunächst müssen wir für jedes Fahrzeug eine Reihe von ununterbrochenen minutengenauen Berichten zu "verfügbaren" zusammengesetzten Zeiträumen zusammenstellen, die zu bekannten Zeiten beginnen und enden. Dann können wir die Lücken zwischen diesen Zeiträumen identifizieren, die "Mietperioden" darstellen. Wenn zum Beispiel ein Auto an einem Ort und zu einer bestimmten Zeit verschwindet, aber an einem anderen Ort wieder auftaucht, können wir die Dauer und die Bewegung dieser bestimmten Anmietung bestimmen.
Im Gegensatz zu Vozilla ist Traficar mit klassischen Verbrennungsfahrzeugen ausgestattet, die nicht aufgeladen werden müssen, so dass fast jede dieser "Anmietungen" tatsächlich eine Anmietung ist. Um Ausreißer zu eliminieren, lassen wir ein Dutzend hundert Ereignisse, die länger als 12 Stunden dauern, weg und analysieren anschließend über 213.000 kürzere Ereignisse.
Mit "etwas Arbeit" meinen wir natürlich das Schreiben und Ausführen von Skripten, die fast eine Million Dateien durchgehen und weit über hundert Millionen Datensätze extrahieren, die die Aktivitäten von 200 Autos über 21 Monate abdecken. Wie üblich müssen wir einige kleine Löcher in den Daten flicken (z.B. eine oder zwei fehlende Minuten hier und da) und uns mit längeren Datenlücken befassen, die in der Regel durch die Wartung der Website von Traficar verursacht werden. Wir ignorieren solche Lücken weitgehend, da über 99% der Daten gültig sind und wir uns lieber auf langfristige Trends als auf kurzfristige Schwankungen konzentrieren.
Wie viele Anmietungen und Reservierungen haben wir also pro Tag verzeichnet? Und wie viele Minuten haben wir insgesamt aufgezeichnet?
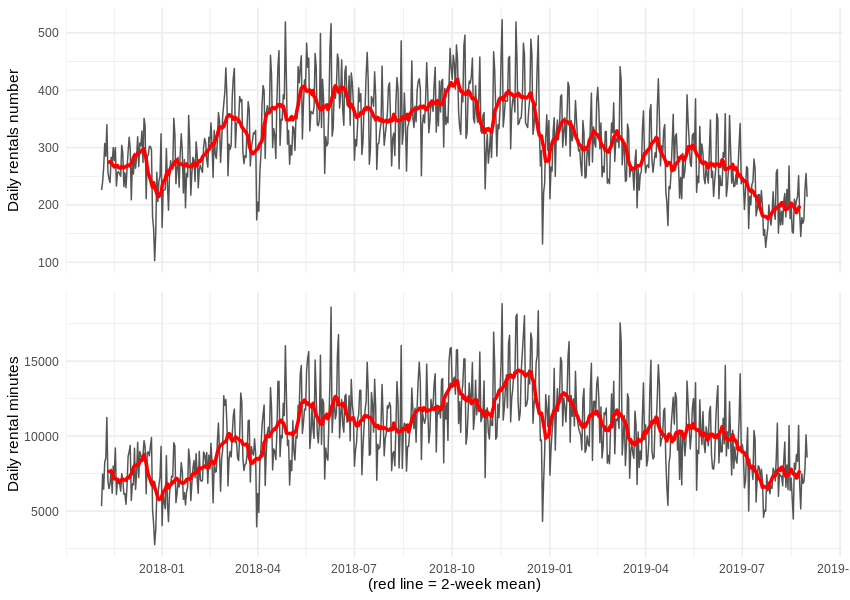
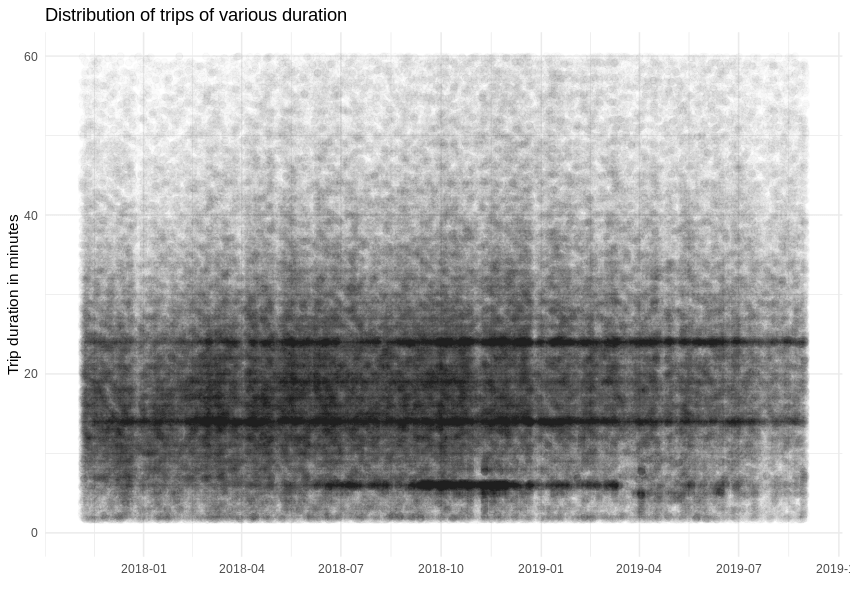
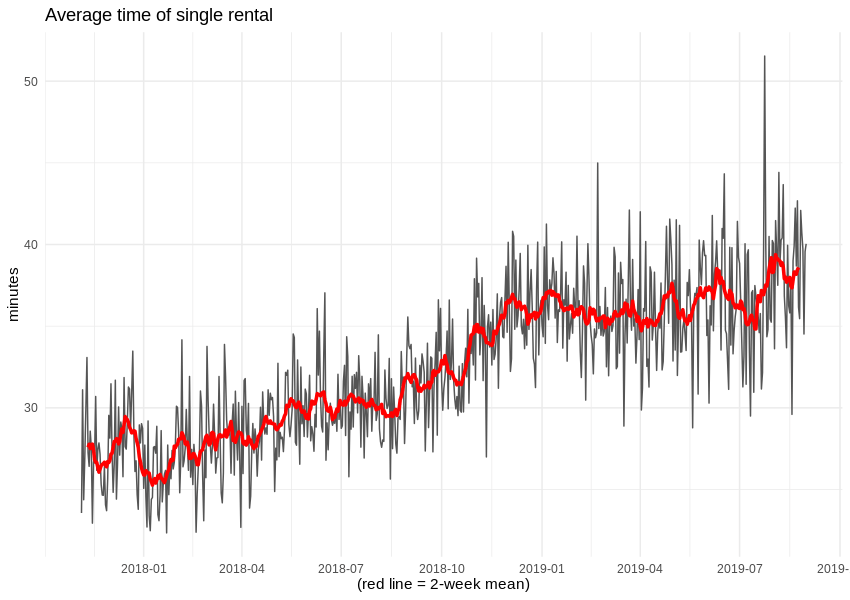
Die Dauer einer einzelnen Fahrt ändert sich während des untersuchten Zeitraums kaum, aber wir können eine seltsame Popularität in Bezug auf Ereignisse feststellen, die 14 und 24 Minuten dauern.
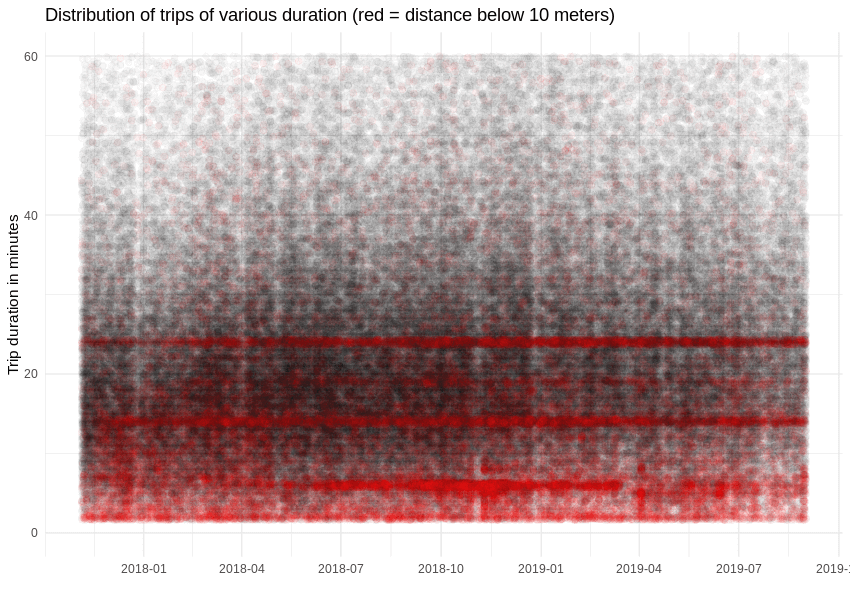
Da das Reservierungslimit für Autos 15 Minuten beträgt und in 5-Minuten-Schritten verlängert werden kann, stammen die 14/24-Minuten-Muster vielleicht von Autos, die sich überhaupt nicht bewegt haben? Fügen wir noch etwas Farbe für Ereignisse hinzu, bei denen der Abstand zwischen Start- und Zielort kleiner als 10 Meter ist. Wenn das geschehen ist, bestätigt sich unser Verdacht, denn etwa 16 % der Ereignisse sind aufgegebene Reservierungen. Wir werden sie von nun an ignorieren.
Wir können nun einen Blick auf die Effektivität der Nutzung des Autonetzes werfen - insbesondere auf die Anzahl der Minuten, die jedes Auto im Durchschnitt pro Tag gemietet wurde. Es scheint, dass sich die Bürger mit der Zeit an Traficar als Pendelmethode gewöhnt haben.
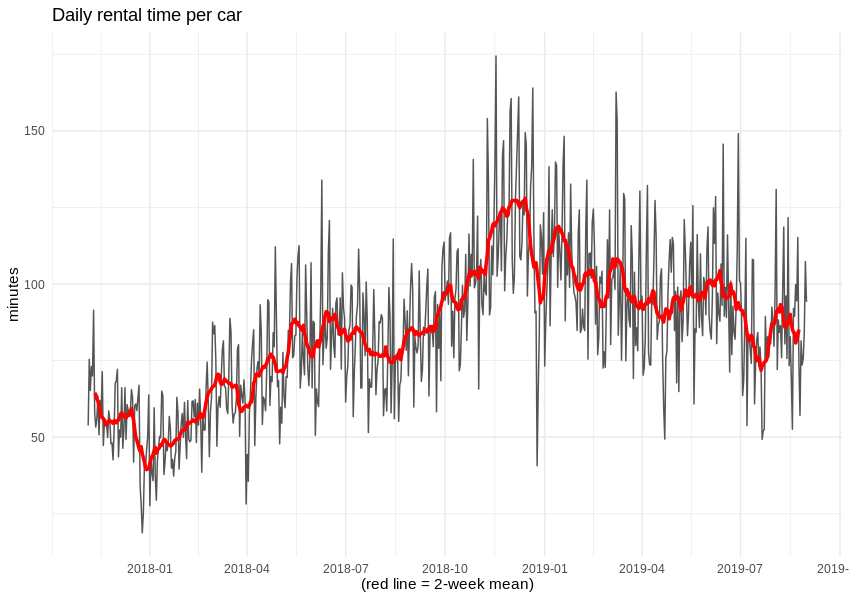
Trotz der Verringerung der Anzahl der verfügbaren Fahrzeuge stieg die durchschnittliche Dauer einer einzelnen Anmietung um 10 Minuten. Leider können wir die Dauer der Pausen während der einzelnen Anmietungen nicht kennen, so dass wir nicht in der Lage sind, die Einnahmen des Betreibers zu schätzen.
Einsicht
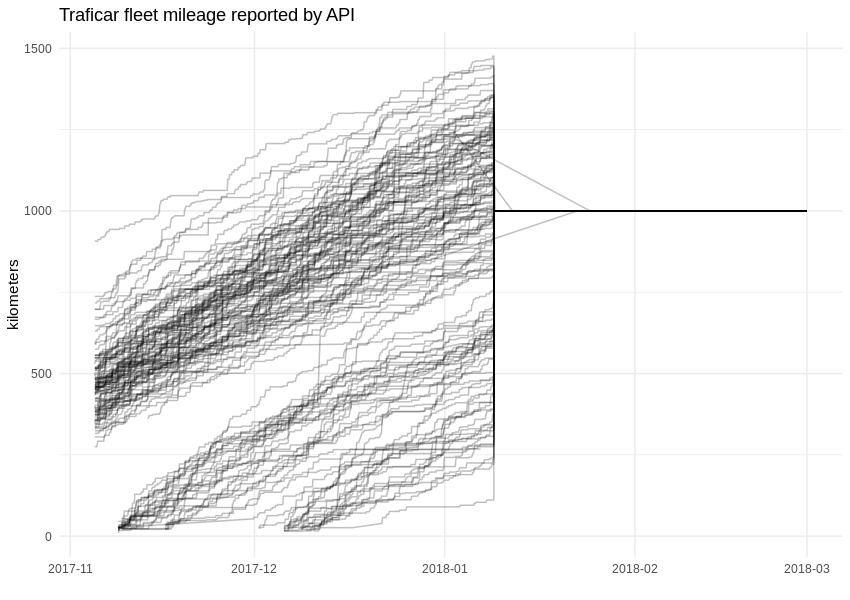
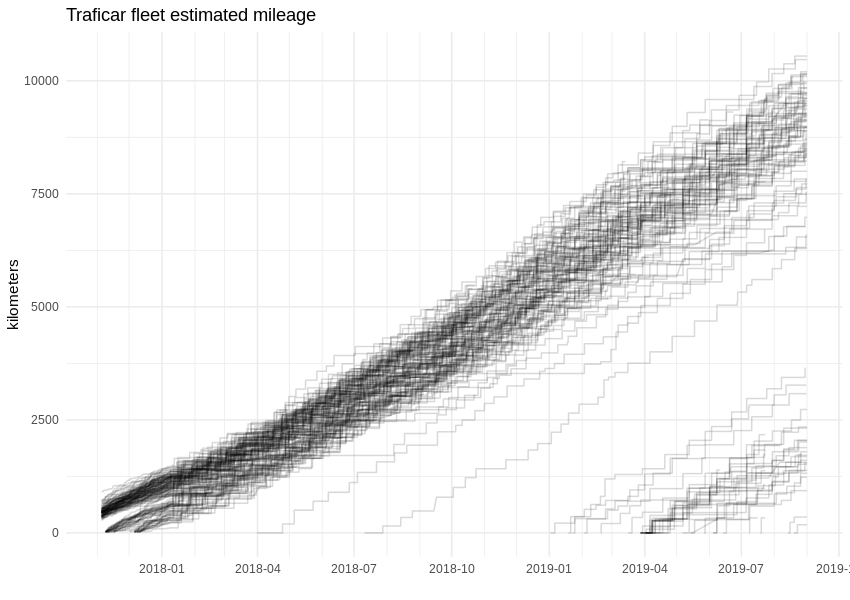
Bei der Arbeit mit Daten besteht eines der Hauptziele darin, verborgene Abhängigkeiten aufzudecken und Wissen zu erlangen, das zuvor nicht verfügbar war. Mit diesem Ansatz können wir zum Beispiel den Kilometerstand der Fahrzeuge von Traficar ermitteln. Natürlich ist dies dem Unternehmen bekannt, aber die API begann etwa zwei Monate, nachdem wir mit der Datenerfassung begonnen hatten, diese spezielle Variable zurückzuhalten. Nach dem 9. Januar 2018 wurde das Feld "distanceAccumulated" in der API-Antwort auf einen konstanten Wert von 1.000 km gesetzt.
Glücklicherweise wurden die Autos in dieser Zeit etwa 100 Mal vollgetankt, so dass wir den durchschnittlichen Kraftstoffverbrauch (oder besser gesagt, die pro Liter Benzin zurückgelegte Strecke) berechnen können. Die Korrelation zwischen zurückgelegter Strecke und verbrauchtem Benzin ist sichtbar linear.
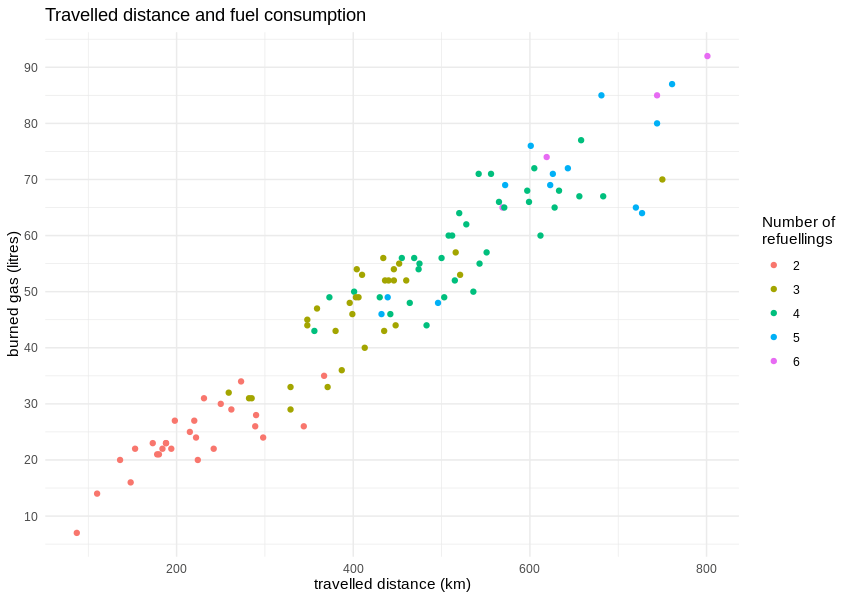
Nach Angaben des Herstellers soll ein Renault Clio TCe 90 in einem völlig künstlichen, aber standardisierten "gemischten Zyklus" bis zu 6 Liter Benzin auf 100 km verbrauchen. Die realen Daten aus dem echten Stadtverkehr zeigen einen Durchschnittsverbrauch von weit über 10 Litern pro 100 km, was 8,98 km Fahrstrecke mit einem Liter Benzin ergibt.
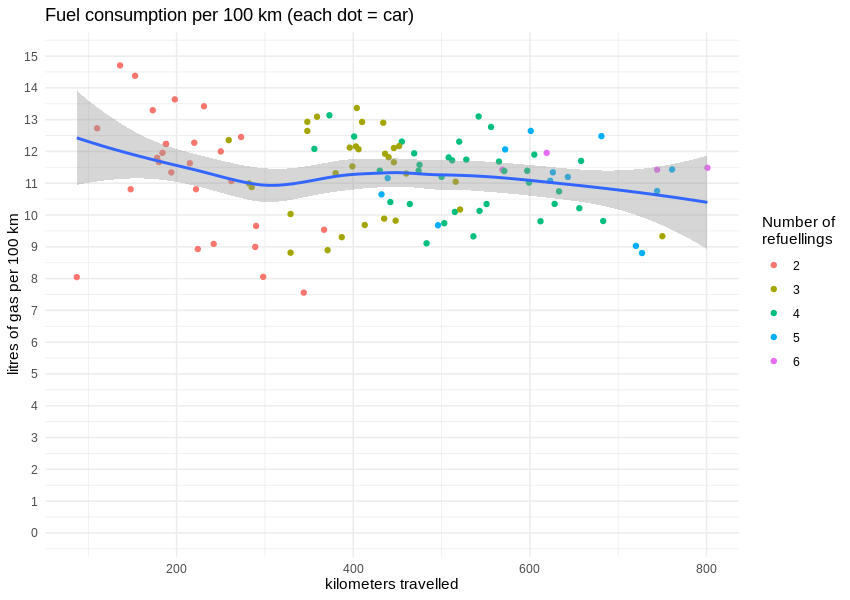
Mit dieser Zahl können wir die Kilometerleistung der gesamten Flotte leicht schätzen, indem wir sie auf den Kraftstoffverbrauch anwenden, der für den gesamten Zeitraum bekannt ist. Das Diagramm sieht jetzt etwas eckiger aus, da alle paar hundert Kilometer getankt wird. Wenn wir richtig liegen, haben einige Traficar-Fahrzeuge bereits die 10.000 km-Marke überschritten.
Vorausschauend
Wenn Sie einen kontinuierlichen Dienst betreiben, ist eine ständige Überwachung unerlässlich, um zu wissen, was hier und jetzt passiert. Online-Dashboards sind ein gängiges Analysewerkzeug, das Disponenten und Wartungspersonal von Kernkraftwerken, Stromnetzdiensten, dem Fuhrparkmanagement von Unternehmen und sogar Cloud-Anbietern hilft und bis hinunter zu winzigen eCommerce- und einzelnen Website-Betreibern skaliert.
Aber das "Hier und Jetzt" ist nicht genug. Sie müssen sich auch Gedanken darüber machen, was als Nächstes (oder sogar noch weiter in der Zukunft) passieren wird und wie Sie darauf reagieren werden, wenn es passiert. Im Falle des Carsharing-Flottenmanagements werden (und sollten) Sie die Nachfrage vorhersagen wollen, aber auch den Grenzgewinn bestimmen, wenn Sie das Angebot ändern.
Hier kommen das maschinelle Lernen und die Zeitreihenprognose ins Spiel. Die allgemeine Idee ist trivial: Füttern Sie den Algorithmus mit historischen Daten, lassen Sie ihn die Muster und internen Abhängigkeiten finden und wenden Sie dann die entdeckten Regeln an, um zukünftige Werte vorherzusagen.
Es gibt nur ein Problem - wir können die Anzahl der Fahrten oder der Mietminuten nicht vorhersagen, da dies streng von der Anzahl der verfügbaren Fahrzeuge abhängt. Dieser letzte Wert ist nicht flexibel, da das Autoleasing strenge Termine hat, einige Fahrzeuge beschädigt werden und so weiter. Wir können jedoch die Auslastung der Flotte überwachen und vorhersagen. In diesem Fall wird die Anzahl der Fahrzeuge zu einem unabhängigen Parameter. Wie wir sehen, werden im Durchschnitt etwa 10% der Autos vermietet, aber je nach Stunde und Wochentag schwankt dieser Wert zwischen 0% und mehr als 30%. Insgesamt weist die Carsharing-Nachfrage starke saisonale Schwankungen auf, mit klaren täglichen, wöchentlichen und monatlichen Mustern.
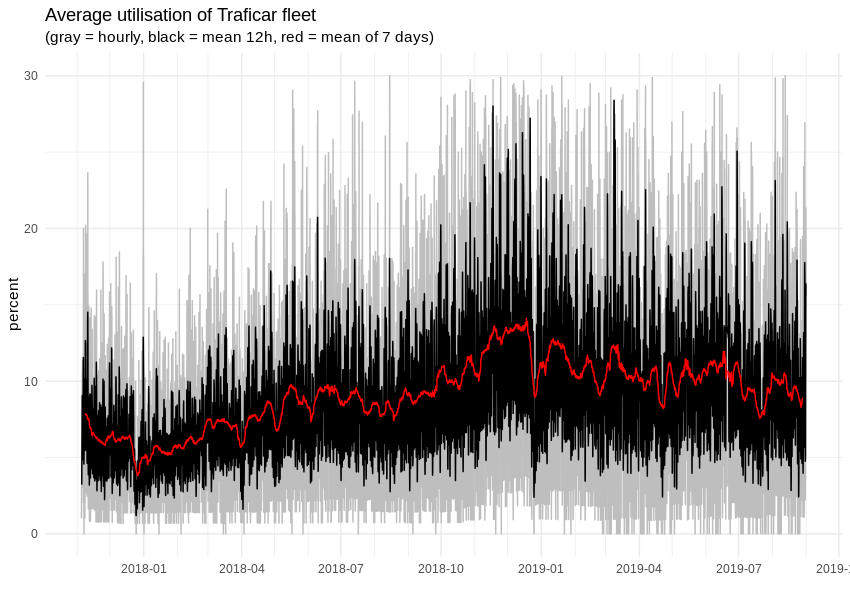
Wenn wir auf eine beliebige 7-Tage-Spanne zoomen, sieht es so aus:
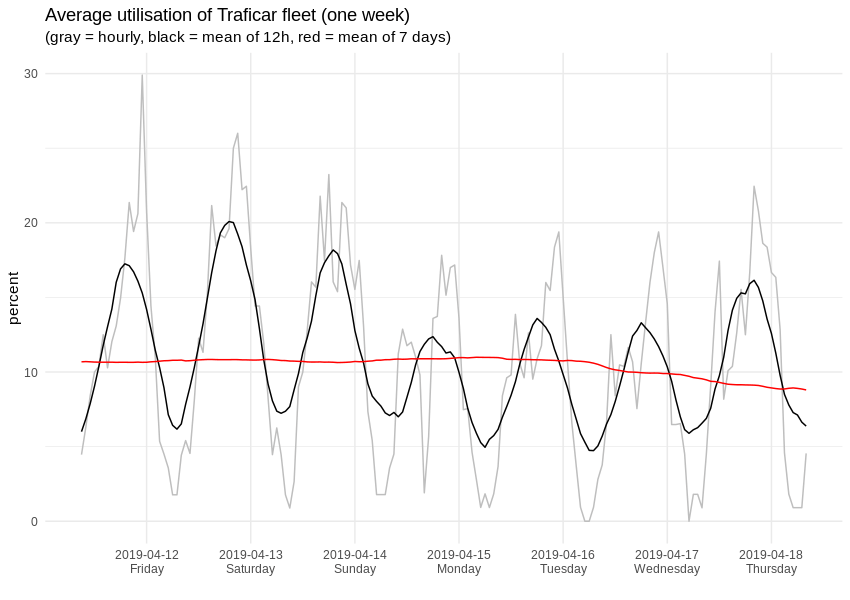
Für die Erstellung konkreter Vorhersagen haben wir uns für die von Facebook entwickelte Open-Source-Bibliothek Prophet entschieden, die nicht nur in der Lage ist, saisonale Muster automatisch zu erkennen, sondern auch die Verwendung benutzerdefinierter Prädiktoren ermöglicht. Aus der Analyse der Daten von Vozilla wissen wir, dass sich die kurzfristige Carsharing-Nachfrage zwischen Werktagen und Wochenenden merklich unterscheidet. Vor diesem Hintergrund haben wir die einfache stündliche Saisonalität durch eine doppelte ersetzt, wobei wir die arbeitsfreien Tage separat berücksichtigen.
Prophet bietet eine schöne Möglichkeit, die erkannten saisonalen Komponenten anzuzeigen, was Ihnen hilft zu verstehen, wie die endgültige Vorhersage zustande kommt. Hier sehen Sie die Aufschlüsselung einer 30-tägigen Vorhersage der Flottenauslastung (die y-Achse ist der prozentuale Anteil der gemieteten Autos an der gesamten Flotte):
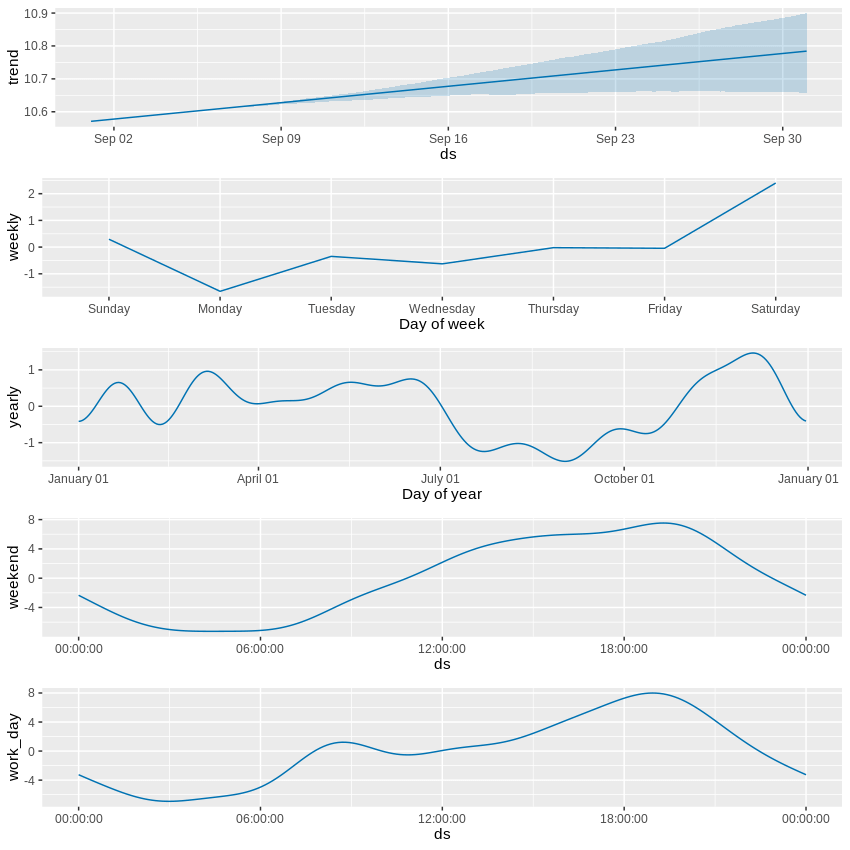
Der erste Abschnitt beschreibt einen langsam ansteigenden langfristigen Trend, aber gleichzeitig beobachten wir eine wachsende Unsicherheit der zukünftigen Werte. Insgesamt liegt der Basiswert der Nutzung des Carsharing-Netzwerks etwas über der 10-Prozent-Marke. Der zweitstärkste Indikator ist das stündliche Muster, sowohl an Werktagen als auch an Wochenenden (ersteres weist einen morgendlichen Nachfrageschub auf, der bei letzterem fehlt) - dieser Teil bewegt die Nadel um 8 Prozentpunkte. Der Wochentag trägt bis zu 2 Prozentpunkte bei, während der Einfluss der Jahreszeit sogar noch schwächer ist - doch auch hier können wir beispielsweise eine geringere Nachfrage während der Sommerferien und höhere Spitzenwerte um Weihnachten herum feststellen.
Zum Vergleich: Die unten dargestellte 30-Tage-Vorhersage ist weitaus kryptischer und Korrelationen zwischen den Komponenten sind viel schwieriger zu erkennen.
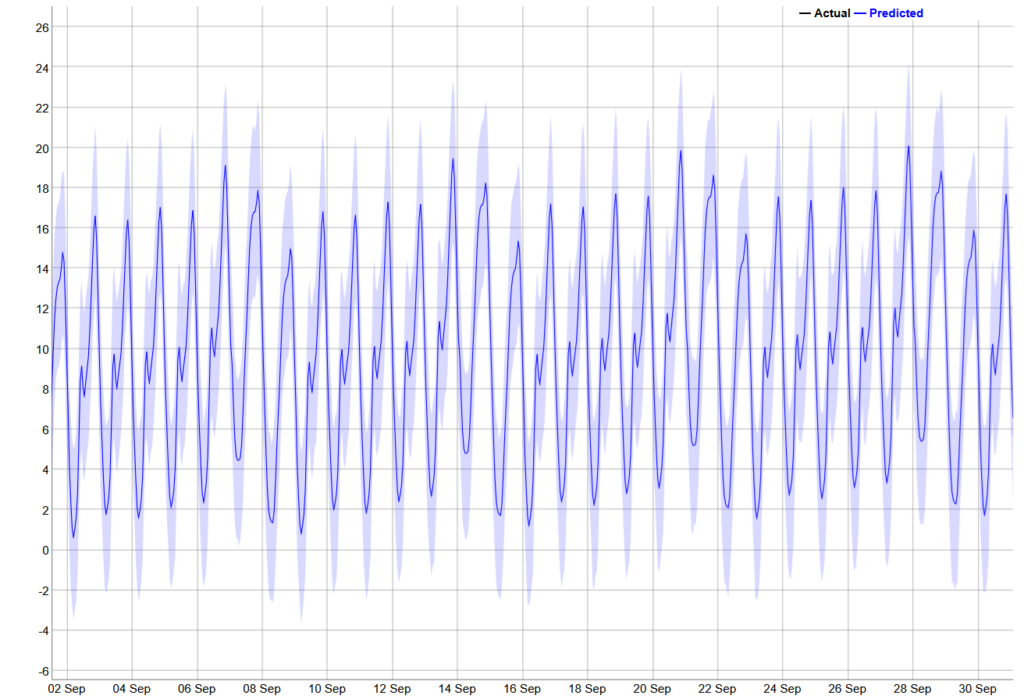
Natürlich beschreiben unsere Daten nur die Nachfrage in der Stadt Wrocław. Wenn Traficar für eine andere Stadt ein umgekehrtes saisonales Muster erkennen kann (d.h. eine hohe Nachfrage im Sommer und einen Rückgang um Neujahr herum), könnte es sinnvoll sein, die Fahrzeuge regelmäßig zwischen solchen Standorten zu verschieben, um die durchschnittliche Auslastung zu maximieren. Dies könnte ein Beispiel für eine durch maschinelles Lernen ermöglichte Voraussicht sein, die bei der täglichen Wartung des Fuhrparks viel schwieriger zu erkennen ist.
Ein weiteres Beispiel für die Nutzung dieser Voraussicht im täglichen Flottenmanagement wäre die Identifizierung von Gebieten mit hoher und niedriger Nachfrage, um die Wahrscheinlichkeit abzuschätzen, dass ein bestimmtes Auto innerhalb weniger Stunden vermietet wird. Ein solches Unternehmen muss jede Woche einige Autos technisch überprüfen. Mit diesen Daten könnten die Servicemitarbeiter sicherstellen, dass sie ein Auto mit der geringsten Vermietungswahrscheinlichkeit auswählen.
Es ist schwer, Prophezeiungen zu machen, insbesondere über die Zukunft
Nun, da unsere Vorhersage fertig ist, würden wir gerne wissen, wie zuverlässig sie ist. Nun, im Gegensatz zu anderen Bereichen des maschinellen Lernens können wir das nicht. Die Zukunft ist unbekannt. Eine typische Validierungsmethode des maschinellen Lernens, bei der die Daten in Lern- und Testsets aufgeteilt werden, funktioniert hier aufgrund der zeitlichen Abhängigkeiten in unserem einzigen Datenstrom nicht.
Was wir tun können, ist zu lernen, wie unser Algorithmus eine bereits bekannte Vergangenheit vorhersagen würde. Wir könnten zum Beispiel 4 Monate in der Zeit zurückgehen und eine Vorhersage für 1 Monat erstellen und diese irgendwo speichern. Dann könnten wir eine Woche weitergehen, eine Vorhersage für 1 Monat erstellen und diese speichern. Spülen und wiederholen Sie das Ganze noch ein Dutzend Mal und überprüfen Sie dann die erreichte Genauigkeit. Da wir nur mit historischen Daten arbeiten, können wir die Vorhersagen mit den tatsächlich beobachteten Werten vergleichen.
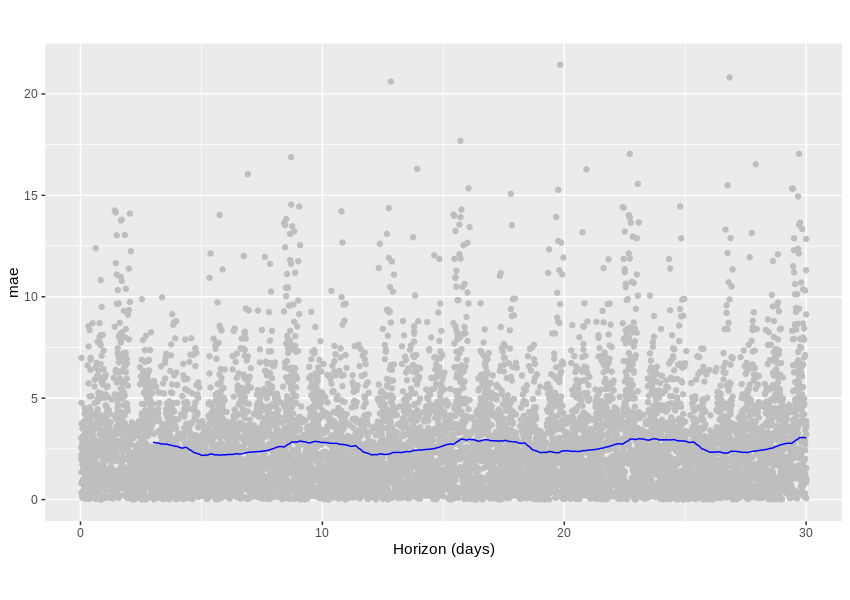
Das Diagramm unten zeigt die Metrik des mittleren absoluten Fehlers, die uns genau das sagt - wie viele Prozentpunkte wir normalerweise vom wahren Wert abweichen. Ein durchschnittlicher Fehler liegt bei etwas unter 2,5 Prozentpunkten, was für eine vorhergesagte Variable, die zwischen 0 und 30 Prozent liegt, nicht sehr schlecht klingt.
Ist es gut genug? Das ist schwer zu sagen, insbesondere angesichts der Tatsache, dass unsere gescrapten Daten einige unbekannte Fehler enthalten können, aber es ist auf jeden Fall ein vielversprechender Anfang.
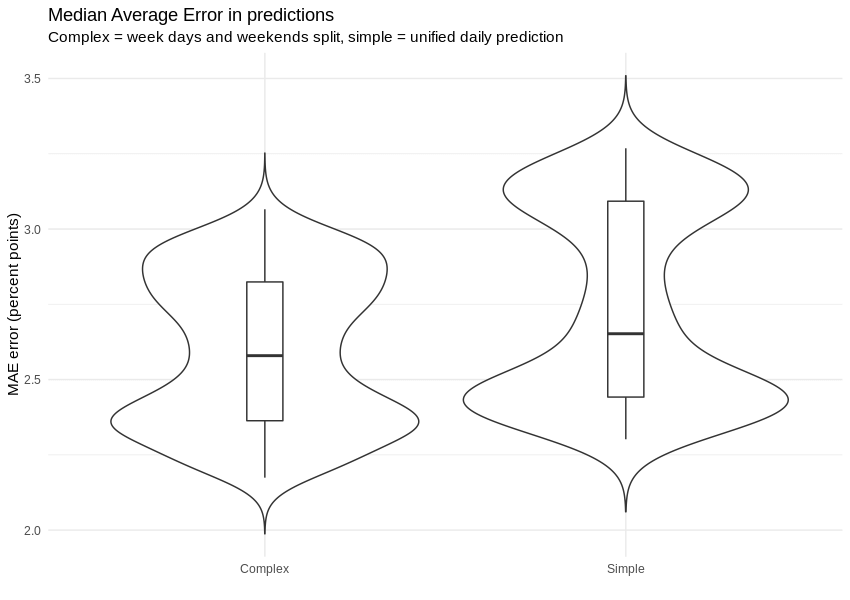
Wir können die Verteilung des durchschnittlichen absoluten Fehlers mit (links) und ohne (rechts) Arbeitstag-/Wochenend-Prädiktorsplit vergleichen. Wie wir in der folgenden Grafik sehen, konnten wir Schätzungen mit Fehlern erstellen, die nicht nur kleiner, sondern auch kohärenter verteilt sind. Ein einfacher stündlicher Prädiktor kann die Merkmale von Arbeitstag und Wochenende nicht gleichzeitig erfassen.
Visualisierung von KPI-Vorhersagen
Key Performance Indicators (KPI) sind Leistungskennzahlen zur Bewertung des Erfolgs einer Organisation oder einer bestimmten Aktivität. Wir zeigen Ihnen drei Methoden zur Erstellung eines Online-Dashboards mit Live-Überwachung der wichtigsten Metriken des Carsharing-Netzwerks. Alle Methoden verwenden rohe Zahlen aus Berechnungen, die mit der Sprache R durchgeführt wurden, aber die Visualisierungsmethoden unterscheiden sich. Wichtig ist, dass wir neben einfachen Diagrammen auch die Positionen und den aktuellen Status der Autos auf dem Stadtplan visualisieren wollen.
Unser erster Ansatz bestand darin, ein Web-Dashboardeines Drittanbieters zu verwenden, und wir sind grandios gescheitert. Es gibt Dutzende oder sogar Hunderte von Online-KPI-Dashboard-Tools, aber den allermeisten von ihnen fehlt es selbst an grundlegenden Kartenwerkzeugen oder Widgets. Auch die Anzahl der externen Datenkonnektoren und die Qualität der Datenverarbeitungswerkzeuge ließen zu wünschen übrig. Wir waren enttäuscht über solche Unzulänglichkeiten, wie z.B. die Tatsache, dass Benutzer keine Möglichkeit haben, zwei Datenreihen in einem einzigen Diagramm darzustellen, oder dass es nicht möglich ist, Zeilen aus zwei separaten Dateien zu verbinden, selbst wenn die Schemata vollständig übereinstimmen.
Später beschlossen wir, Power BI und Tableau auszuprobieren, zwei führende Tools zur Datenvisualisierung, die für ihre Erweiterbarkeit und Flexibilität gelobt werden. Unsere Erfahrungen waren hier viel besser, da wir mit beiden Produkten Daten importieren und visualisieren konnten - meistens so, wie wir es wollten.
Allerdings stießen wir schnell an die Grenzen der Anpassbarkeit, da wir die Kartenansichten oft nicht so weit verändern konnten, wie wir es wollten. Bei PowerBI und Bing Maps mussten wir uns beispielsweise zwischen den Zoomstufen "zu groß" und "zu klein" entscheiden, und dazwischen gab es nichts.
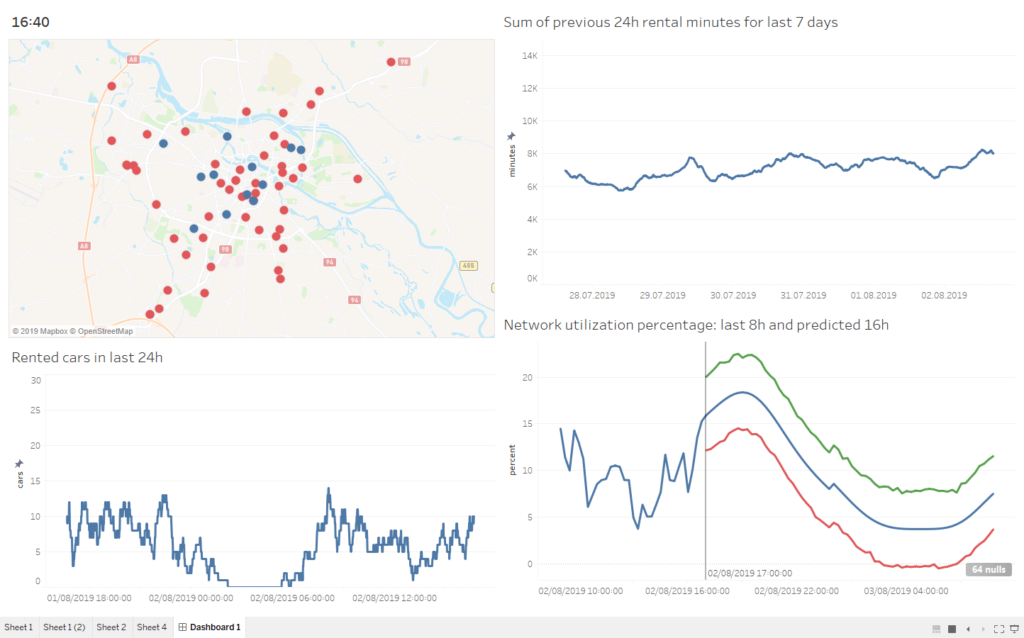
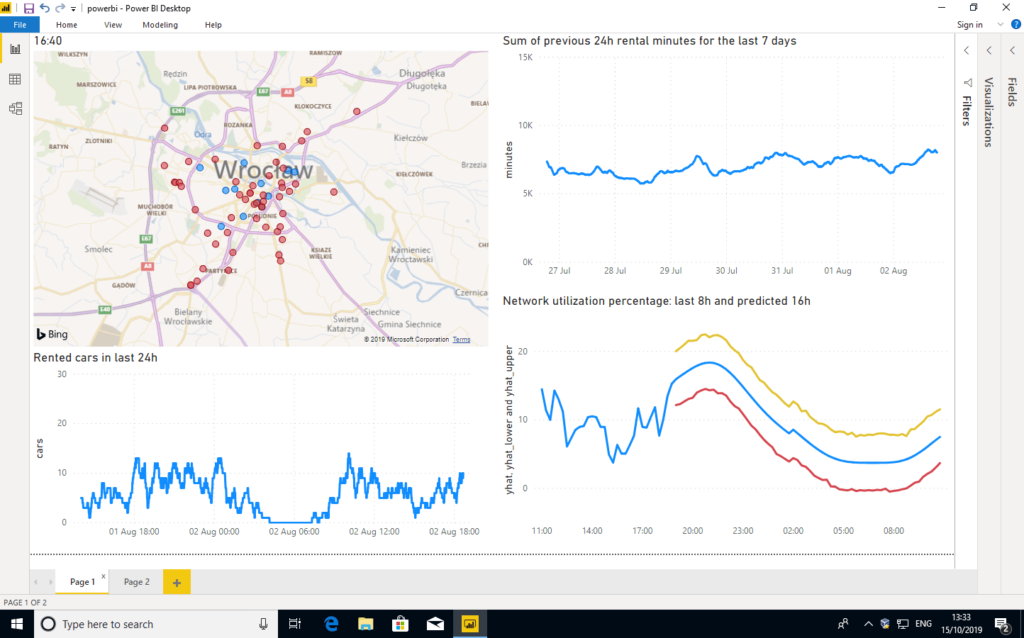
Das flexibelste und am besten anpassbare Dashboard wurde mit der Sprache R selbst erstellt. Natürlich erfordert diese Methode Programmierkenntnisse und ist für Menschen, die an grafische Oberflächen gewöhnt sind, sicher nicht angenehm. Aber ein erfahrener Entwickler kann jeden gewünschten visuellen Effekt erzielen - entweder durch die Verwendung vorhandener Widgets oder durch die Erstellung neuer Widgets von Grund auf. Nachdem die Dashboard-Engine fertig war, war es trivial, aufeinanderfolgende Dashboard-Bilder zu generieren. Im Folgenden präsentieren wir Ihnen ein Video, das die gesamten 24 Stunden des Traficar-Betriebs mit der aktuellen Leistung und der prognostizierten Auslastung zeigt.
Zusammenfassung
Wie Sie sehen, konnten wir selbst mit öffentlich zugänglichen Informationen eine Menge herausfinden und eine Reihe von wichtigen Erkenntnissen gewinnen. Stellen Sie sich nur vor, was wir mit dem Zugang zu allen Daten tun könnten!
Geschäftsperspektive
Die Analyse von Daten über bestimmte Zeiträume kann viele Möglichkeiten aufzeigen, von der saisonalen Verfügbarkeit bis hin zu den besten Zeiten, um einen wettbewerbsfähigeren Service anzubieten. Um dies zu erreichen, müssen Sie jedoch zunächst historische und aktuelle Daten betrachten, um die wichtigsten Trends zu erkennen - etwas, das fortschrittliche Datenlösungen leicht vereinfachen können!
Verfasst von
Xebia Author




Contact