Blog
DIY LLM Evaluation, eine Fallstudie über das Reimen im ABBA-Schema

DIY LLM Evaluation, eine Fallstudie über das Reimen im ABBA-Schema
Das ist inzwischen allgemein bekannt: Sie sollten Ihre LLMs nicht auf der Grundlage statischer Benchmarks auswählen.
Wie Andrej Karpathy, ehemaliger CTO von OpenAI, einmal auf Twitter sagte: "Ich vertraue im Moment nur zwei LLM-Bewertungen: Chatbot Arena und dem r/LocalLlama Kommentarbereich". Chatbot Arena ist eine Website, auf der Sie eine Eingabeaufforderung einreichen können, zwei Ergebnisse sehen und dann das beste Ergebnis auswählen können. Alle Ergebnisse werden dann zusammengefasst und bewertet. Im Subreddit r/LocalLlama wird über die Feinabstimmung von LLMs für individuelle Anwendungsfälle diskutiert.
Die Lektion lautet: Vertrauen Sie nur Leuten, die LLMs bei den Aufgaben bewerten, die ihnen selbst wichtig sind.
Aber es gibt noch etwas Besseres: Bewerten Sie LLMs selbst nach Aufgaben, die Ihnen wichtig sind! Dann erhalten Sie nicht nur die relevantesten Bewertungsmetriken für Ihre Aufgabe. Sondern Sie erfahren dabei auch eine ganze Menge mehr über das Problem, das Sie eigentlich lösen wollen.
In diesem Blogpost werde ich mit Ihnen meine Reise zur Bewertung von LLMs anhand einer lächerlichen Aufgabe teilen. Seit fast einem Jahr bin ich von dieser Aufgabe besessen: Reimen im
Sind Sie neugierig, warum dies der Fall ist? Im weiteren Verlauf dieses Blogposts werde ich es Ihnen erklären:
- Warum das Reimen im ABBA-Schema eine interessante Aufgabe ist
- Was die Ergebnisse meiner Analyse waren
- Was ich bei dieser Übung gelernt habe
Warum ist das Reimen im ABBA-Schema eine interessante Aufgabe?
Ich bin schon seit Jahren davon besessen, mir auf KI einen Reim zu machen. Im Jahr 2019 schrieb ich einen Blogpost mit dem Titel
Aber die Aufgabe des Reimens blieb bei mir hängen.
Reimen ist interessant, weil es dabei um den Klang geht, während sich LLMs nur mit geschriebenem Text befassen. Einige Wörter sehen so aus, als würden sie sich reimen, klingen aber anders, z.B. flow und cow. Andere Wörter sehen anders aus, reimen sich aber, z.B. site und knight. Darüber hinaus erfordert das Reimen ein wenig Vorausdenken. Sie müssen planen, mit welchem Wort der Satz enden soll, bevor Sie ihn beginnen. Sonst treiben Sie sich selbst in die Enge.
Die gängigen LLMs verwenden jetzt automatisch regressive Decoder-Transformatoren. Diese erzeugen nur ein Wort nach dem anderen. Die besten LLMs von heute haben kein Problem damit, ein einfaches vierzeiliges Gedicht im AABB-Schema zu erstellen. Wie sich jedoch herausstellte, ist das Reimen im ABBA-Schema immer noch etwas, das sie nicht gut können! Darauf wurde ich zuerst von Michiel van Rijthoven hingewiesen, und später fand ich heraus, dass dies noch mehr Leute auf reddit verwirrte.
Meine Hypothese ist, dass AABB-Reime so häufig sind, dass die Anweisungen von ABBA nicht stark genug sind, um das Gewicht der Anziehungskraft der Trainingsdaten zu überwinden. Vor allem in Kombination mit der automatisch regressiven Architektur der meisten LLMs. Deshalb habe ich neue LLMs immer mit dieser Aufgabe getestet: wie viel Aufwand ist nötig, um sie dazu zu bringen, sich im ABBA-Schema zu reimen.
Bislang hatte ich die Sache nur mit den Augen verfolgt... aber jetzt war es Zeit für einen strukturierteren Ansatz.
Ergebnisse der Bewertung
Ich erstellte eine Liste mit 45 Gedichtthemen und ließ die LLMs Gedichte erstellen. Dann habe ich überprüft, ob sie dem ABBA-Muster folgen. In der Abbildung unten sehen Sie meine Ergebnisse.
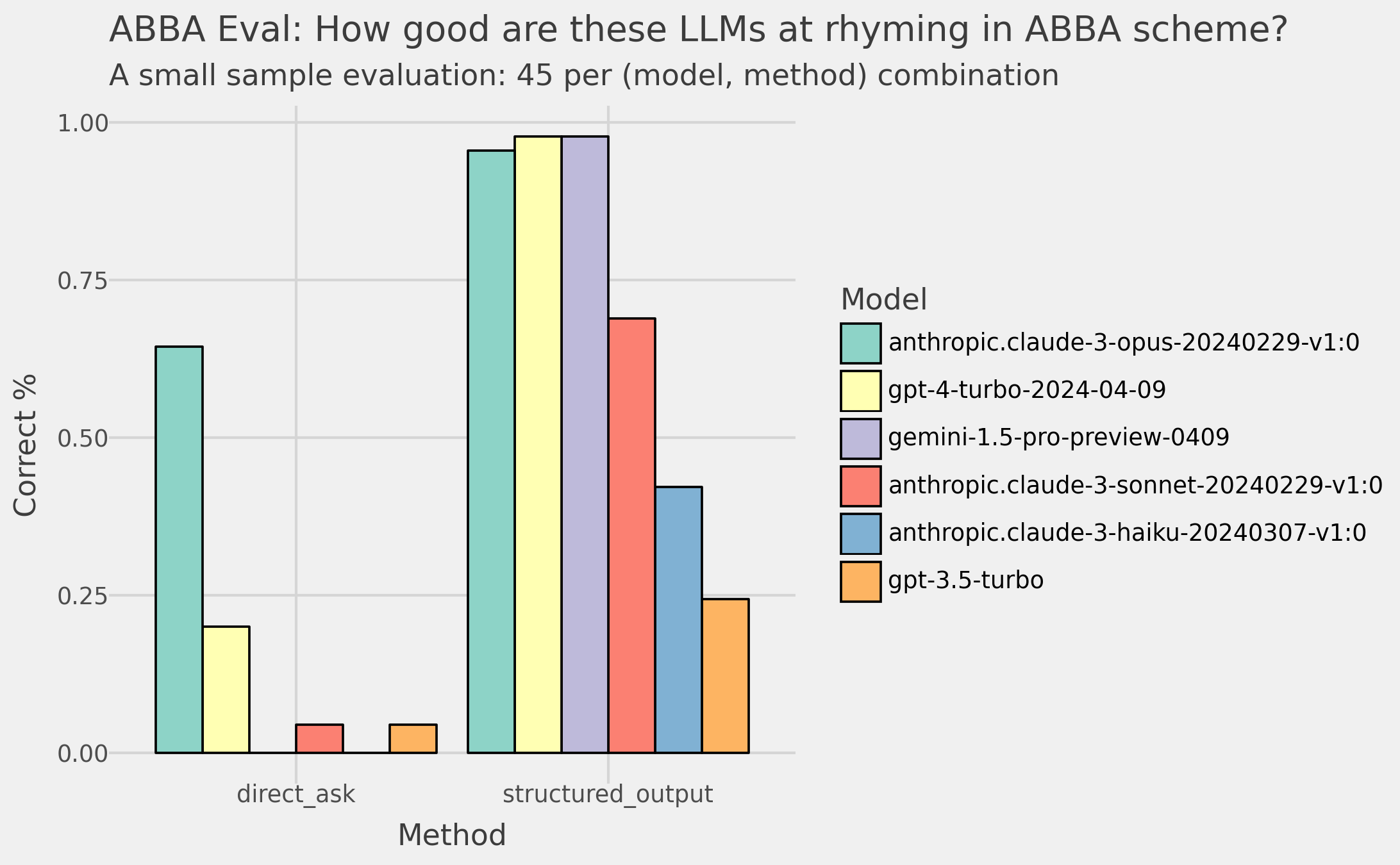
Das linke Feld zeigt die Genauigkeiten, wenn ich eine einfache Eingabeaufforderung verwende (unten). In diesem Fall lässt Claude 3 Opus die anderen Modelle mit 64% Genauigkeit weit hinter sich, wobei GPT-4 mit 25% am nächsten dran ist.
Das ist ein überraschendes Ergebnis!
prompt = f"Create a 4 line poem in ABBA rhyme scheme about the following topic: {topic}. Return only the poem."
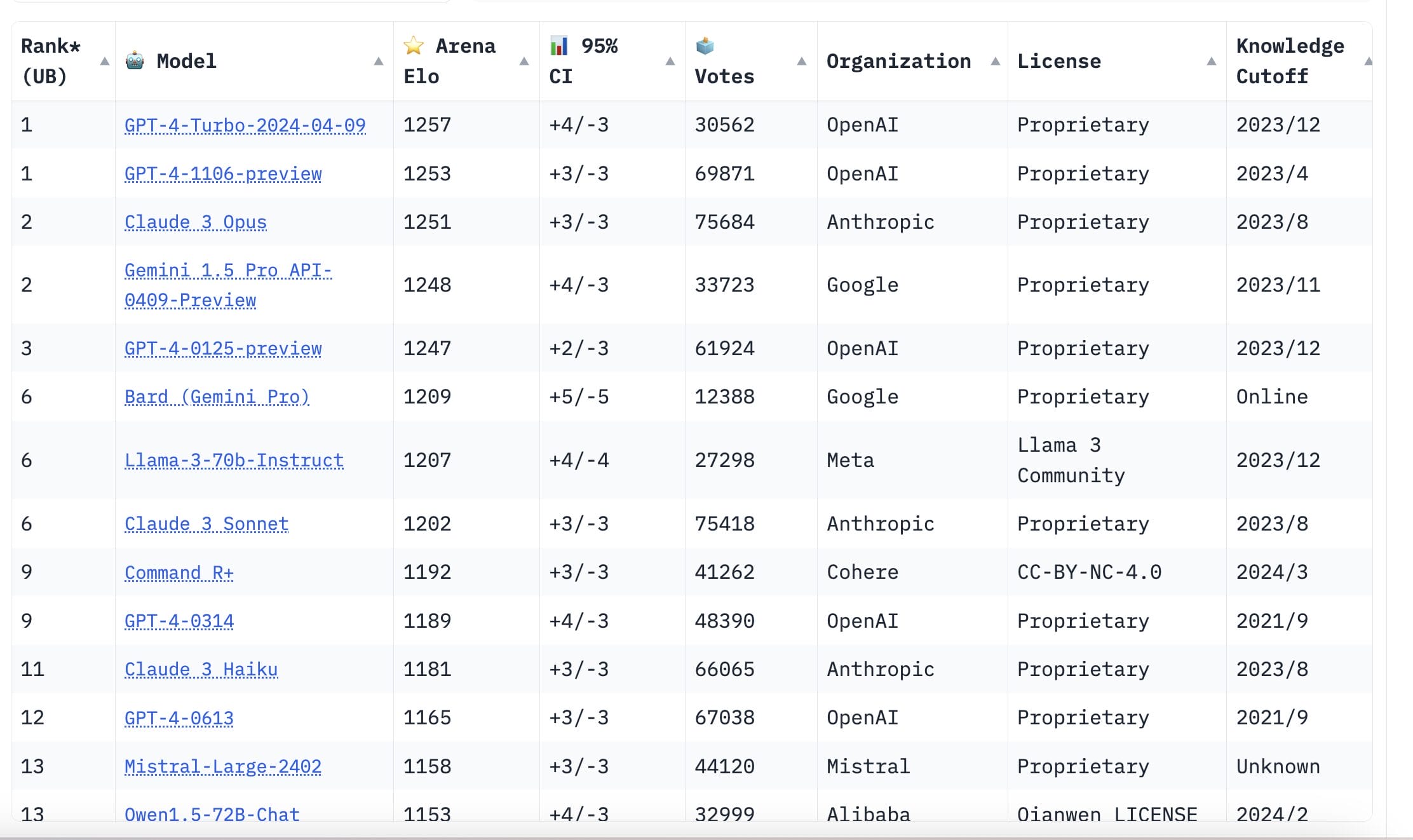
In vielen anderen Benchmarks liegen Claude 3 Opus, GPT-4 und Gemini Pro 1.5 viel näher beieinander. Wie Sie auf dem Screenshot des LMSYS Chatbot Arena Leaderboards unten sehen können.
Aber seien wir ehrlich, selbst eine 64%ige Genauigkeit ist nicht beeindruckend bei einer Aufgabe, die wir als Menschen recht einfach erledigen können.
Aber ich hatte einen Trick in petto. Nämlich die Ausgabe nach dem folgenden Schema zu erzwingen (siehe unten). Ich habe die LLMs gezwungen, zuerst das gereimte Wort zu wählen. Und erst danach den dazugehörigen Satz zu wählen.
Die Veränderung der Ergebnisse ist beeindruckend!
Im rechten Bereich der obigen Abbildung sehen Sie die Ergebnisse. Claude 3 Opus, GPT-4 und Gemini 1.5 Pro haben alle >95% Genauigkeit. Und auch alle anderen Modelle machen große Sprünge in ihrer Leistung!
from pydantic import BaseModel, Field
class Poem(BaseModel):
rhyme_word_A1: str = Field(description = "The word that sentence A1 ends with.")
sentence_A1: str = Field(description = "The sentence that ends with the rhyme word A1.")
rhyme_word_B1: str = Field(description = "The word that sentence B1 ends with. It SHOULD NOT rhyme with rhyme_word_A1.")
sentence_B1: str = Field(description = "The sentence that ends with the rhyme word B1.")
rhyme_word_B2: str = Field(description = "The word that sentence B2 ends with. It SHOULD rhyme with rhyme_word_B1. It SHOULD NOT rhyme with rhyme_word_A1.")
sentence_B2: str = Field(description = "The sentence that ends with the rhyme word B2.")
rhyme_word_A2: str = Field(description = "The word that sentence A2 ends with. It SHOULD rhyme with rhyme_word_A1. It SHOULD NOT rhyme with rhyme_word_B2.")
sentence_A2: str = Field(description = "The sentence that ends with the rhyme word A2.")
Gelernte Lektionen
Nun gut. Bis jetzt haben Sie erfahren, dass ich ein bisschen besessen bin von Reimen im ABBA-Schema. Und dass eine strukturierte Aufforderung einen großen Unterschied machen kann.
Aber es gibt noch einige weitere Dinge, die Sie aus dieser Übung mitnehmen können.
1. Bewerten Sie LLMs nach Aufgaben, die Ihnen wichtig sind
Die erste Lektion ist, dass Sie LLMs nach Aufgaben beurteilen sollten, die Ihnen wichtig sind.
Meine obigen Diagramme zeigen, dass die LLM-Leistung je nach Aufgabe stark variiert. Die Unterschiede können viel größer sein, als Sie es von öffentlichen Benchmarks erwarten würden.
2. Die Kennzeichnung von Daten ist eine äußerst wertvolle Aufgabe
Durch die Beschriftung der Daten habe ich am meisten über das Problem gelernt, das ich zu lösen versuchte.
Ich habe zum Beispiel häufig vorkommende Fehler wie die folgenden gesehen:
In fields of green, the flowers bloom (A)
As rivers flow, the birds take flight (B)
The sun shines bright, dispelling gloom (B)
In nature's arms, all is right (A)
(das LLM hat das Gedicht mit ABBA kommentiert, obwohl es eigentlich einem anderen Schema folgt)
In morning's glow, I start the grind,
A task, a purpose tightly twined.
Endless hours under ticking clock's bind,
And do it all again, tethered and resigned.
(der LLM gab ein Gedicht im Schema AAAA statt ABBA zurück)
Das brachte mich auf die Idee, dass der LLM sich selbst in die Enge getrieben hat. Er erzeugte die erste Zeile, einen Teil der zweiten Zeile und blieb dann stecken. Es musste ein Wort generieren, das sich auf die erste Zeile reimt, aber es hatte bereits einen Teil der zweiten Zeile generiert. Das führte zu einem falschen Ende.
Deshalb kam ich auf die Idee, den LLM zu zwingen, zuerst das reimende Wort und erst danach den dazugehörigen Satz zu generieren.
3. Ein bisschen geschickte Aufforderung kann viel bewirken
Die Leute machen sich gerne über den Begriff Prompt Engineering lustig. Aber ehrlich gesagt, wie wir in dieser Übung sehen, kann ein gut ausgearbeiteter Prompt einen großen Unterschied machen.
Wenn Sie die Unterschiede in den Ergebnissen der verschiedenen Prompts analysieren. Und wenn Sie dies systematisch tun, dann denke ich, dass Sie alles richtig gemacht haben.
Ich habe ein viel größeres Problem mit Leuten, die mit den Augen schielen und es dann sein lassen, auch LGTM@k genannt.
4. Verwenden Sie Tools, die Ihnen den Einstieg leicht machen
Etikettierung muss nicht so schwer sein. Für diese Analyse habe ich es einfach gehalten. Das habe ich verwendet:
-
Jupyter Notebooks -- um schnell Code zu schreiben und Ergebnisse auszuwerten
-
LiteLLM -- ein einfacher Wrapper um viele LLM-Anbieter, so dass ich die Modelle leicht austauschen kann
-
Instructor -- ein Wrapper, um LLMs zu zwingen, über Funktionsaufrufe eine strukturierte Ausgabe zurückzugeben. Diese Ausgabe muss Ihrem pydantischen Schema entsprechen. Und es lässt sich gut mit LiteLLM integrieren
-
Memo -- ein einfacher Dekorator, der die Ausgabe einer Funktion in einer jsonl-Datei protokolliert, damit ich die Daten speichern kann
-
PigeonXT -- um die Daten in meinem Notizbuch zu beschriften
Schließen
Ich hoffe, dieser Blog hat Ihnen einen Einblick in die Bedeutung der Erstellung Ihrer eigenen Benchmarks gegeben. Und ich habe Ihnen ein paar Ideen für den Anfang gegeben. Sie können den Code und die Daten auf GitHub finden. Wenn Sie ihn nützlich fanden, lassen Sie es mich wissen!
Credits für das Bannerbild an: William Warby auf Unsplash
Verfasst von
Rens Dimmendaal




Contact