Blog
Weniger Daten, weniger Probleme: Die Spaltenauswahl von Airbyte ist endlich da

Die Veröffentlichung von Airbyte 0.50 hat einige aufregende Änderungen an der Plattform mit sich gebracht:
- Checkpointing (damit Sie bei Unterbrechungen während der Synchronisierung nicht wieder bei Null anfangen müssen)
- automatische Schemaübertragung (so dass Sie sich nicht manuell darum kümmern müssen, wenn sich das Quellschema ändert)
- Spaltenauswahl (so dass Sie nur die Felder aus der Quelle synchronisieren, die Sie benötigen).
Die letzte Funktion - die Spaltenauswahl - war in der Community sehr begehrt gewesen. Wenn Sie das Repository von Airbyte und die Issues besuchen, können Sie diese nach dem Daumen-nach-oben-Emoji sortieren und so die Felder/Spalten einer Tabelleganz nach oben filtern.
Dieser Artikel beschreibt zwei kleine Tests der neuen Funktion, die wir durchgeführt haben, um Antworten auf die folgenden Fragen zu erhalten:
- Wie verhält sich der Spaltenauswahlmechanismus, wenn wir eine relationale Datenbank mit aktivierter CDC (Change Data Capture) auf der Quellseite der Synchronisierung haben?
- Greift Airbyte bei relationalen Datenbanken immer noch auf alle Daten aus der Quelle zu (select * from table_foo)?
Gehen wir kurz die möglichen Gründe für die Verwendung von Spaltenfiltern in Ihren Dateningestionsprozessen durch.
Säulenauswahl - warum sollten Sie sich überhaupt darum kümmern?
- Compliance & Datensicherheit - wir arbeiten oft in regulierten Umgebungen, die uns verschiedene Beschränkungen für den Umgang mit Daten auferlegen. Die DSGVO und ihr Konzept der Datenminimierung besagt, dass personenbezogene Daten "angemessen, relevant und auf das für die Zwecke, für die sie verarbeitet werden, erforderliche Maß beschränkt" sein müssen. Die Nichteinhaltung dieser Vorschrift kann sowohl finanzielle als auch rufschädigende Folgen für Unternehmen haben. Dies war auch ein Hindernis für die Einführung von Airbyte selbst in Unternehmen.
- Kosten - weniger Daten bedeuten geringere Kosten für Datenverarbeitung und Speicherung. Dies gilt insbesondere dann, wenn Sie ein Cloud-Data-Warehouse nutzen, das in der Regel auf der Grundlage der verbrauchten Ressourcen abgerechnet wird.
- Zeit - das Senden nur einer Teilmenge eines Datensatzes über das Netzwerk ist schneller. Dadurch wird auch das Laden und Normalisieren der Daten am Zielort beschleunigt.
Aber die Spaltenauswahl war schon vorher möglich...
Nun, das war es. Irgendwie.
Es gab einige Umgehungsmöglichkeiten, die bei Ihnen funktioniert haben könnten. Eine davon war die Verwendung von Datenbankansichten. Sie konnten eine Ansicht erstellen, die nur die Spalten enthielt, die Sie für die Synchronisierung benötigten, und das war's! Allerdings lösen Views nicht immer das Problem:
- Wenn Sie nicht Eigentümer des Quellsystems sind, dürfen Sie dort möglicherweise keine Datenbankobjekte erstellen.
- Ansichten werden nicht unterstützt, wenn Sie die inkrementelle Synchronisierung mit dem CDC-Mechanismus (Erfassung von Änderungsdaten) verwenden.
- Sie können keine Ansichten verwenden, wenn Sie mit einem Quellsystem arbeiten, das keine Datenbank ist (wie z.B. HTTP-APIs).
Die andere Möglichkeit, das Problem anzugehen, bestand darin, die redundanten Spalten während des Normalisierungsprozesses auszublenden (indem Sie sie aus den Select-Anweisungen innerhalb eines benutzerdefinierten DBT-Projekts entfernen). Während dies das Problem für normalisierte Tabellen löste, würden Airbyte-Rohtabellen (die mit dem Präfix _airbyte_raw_ beginnen) immer noch alle Felder aus der Quelle enthalten. Außerdem werden in Raw-Tabellen die Quelldaten als JSONB-String gespeichert, der in der Regel viel größer ist als die Quelltabellen (es ist schwierig, eine effiziente Komprimierung anzuwenden, wenn alle Datensätze als String vorliegen).
Als letzten Ausweg können Sie versuchen, einen eigenen benutzerdefinierten Konnektor mit Spaltenauswahl zu implementieren, wenn Sie sich damit auskennen.
Machen wir uns die Hände schmutzig - und bereiten die Umwelt vor
Wir werden Docker & docker-compose verwenden, um einen Container mit dem PostgreSQL 15-Image zu erstellen. Um die Dinge einfach zu halten, werden Quelle und Ziel dieselbe Postgres-Datenbank sein (aber die Daten werden zwischen verschiedenen Schemata verschoben). Wenn Sie mit dem Konzept der inkrementellen Datenübernahme mit CDC nicht vertraut sind, empfehlen wir Ihnen, die Dokumentation von Airbyte zu diesem Thema zu lesen.
Für die Aktivierung von CDC müssen einige zusätzliche Schritte ausgeführt werden.
- Setzen der Variable wal_level auf logisch
- Erstellen eines logischen Replikations-Slots
- Erstellen einer Publikation für die Tabelle, die wir synchronisieren möchten
Wir kümmern uns um sie innerhalb von docker-compose und dem SQL-Skript db init, so dass beim Start der Datenbank alles bereit ist.
Hier ist die Datei docker-compose:
version: '3.7'
services:
db:
container_name: airbyte-column-selection-db
image: postgres:15
restart: always
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
ports:
- "5555:5432"
volumes:
- postgres_airbyte_volume:/var/lib/postgresql/data
- ./init_db.sql:/docker-entrypoint-initdb.d/init_db.sql
command: ["postgres", "-c", "wal_level=logical"]
volumes:
postgres_airbyte_volume:Und hier ist die init_db.sql:
-- create schemas
CREATE SCHEMA source;
CREATE SCHEMA destination;
-- create source tables
CREATE TABLE source.table_a (
id serial primary key,
column_1 varchar,
column_2 varchar,
column_3 varchar
);
-- create replication slot & publication
SELECT pg_create_logical_replication_slot('airbyte_slot', 'pgoutput');
CREATE PUBLICATION airbyte_publication FOR TABLE source.table_a;
-- add initial records
INSERT INTO source.table_a (column_1, column_2, column_3)
VALUES
('foo1', 'foo2', 'foo3'),
('bar1', 'bar2', 'bar3'),
('baz1', 'baz2', 'baz3');Sie finden diese Dateien auch im Github-Repository, das für die Zwecke dieses Artikels erstellt wurde.
Die Umgebung kann mit dem Befehl gestartet werden:
docker-compose up -d
Lassen Sie uns einige Abfragen durchführen, um zu überprüfen, ob alles wie erwartet erstellt wurde.
docker exec -ti airbyte-column-selection-db psql -U postgres -d postgres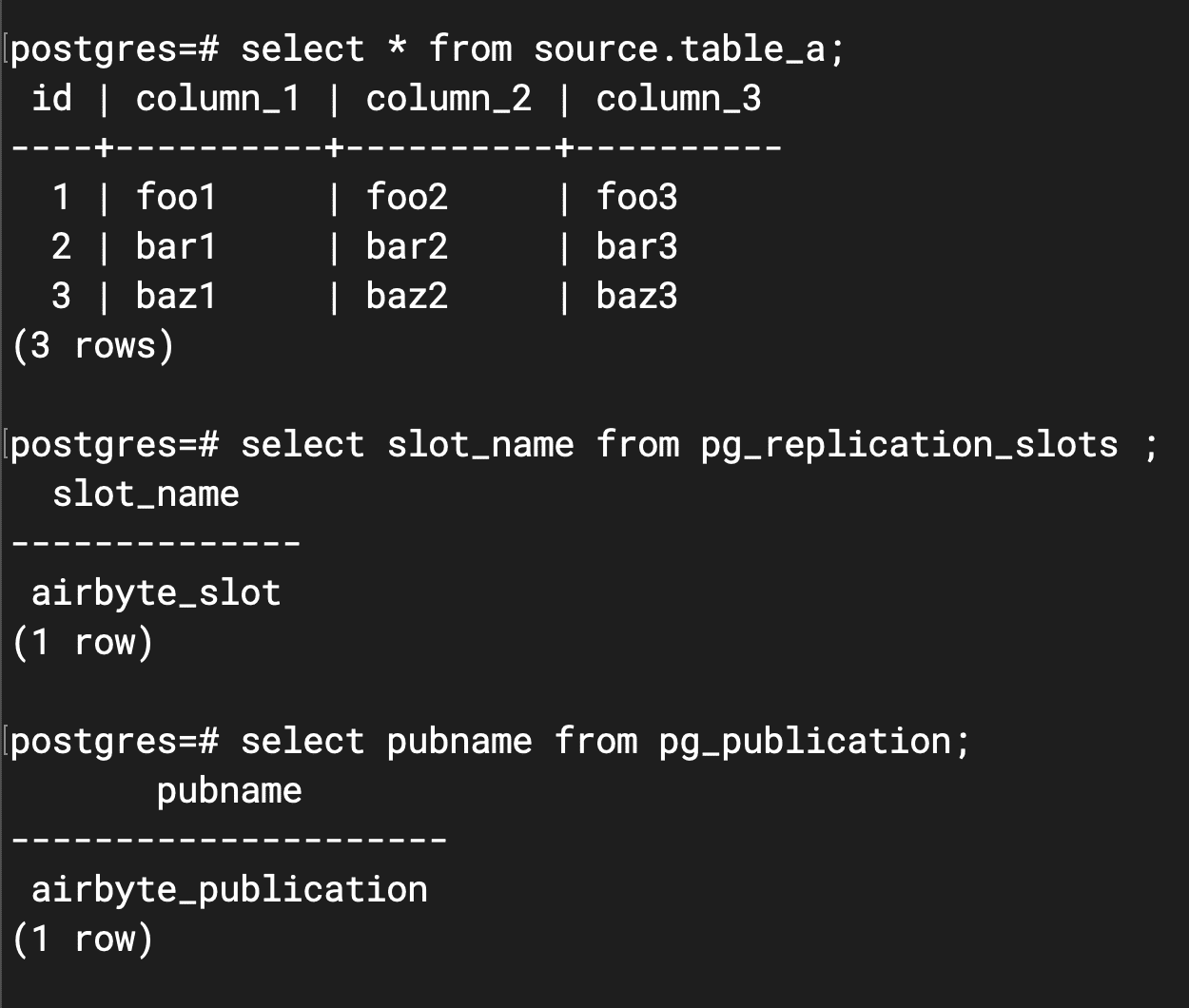
Alles scheint korrekt zu sein! Es ist an der Zeit, den ersten Test durchzuführen.
Test #1 - Wie behandelt Airbyte Aktualisierungen von abgewählten Spalten bei der Verwendung der inkrementellen CDC-Ingestion?
Ups, wir haben Duplikate!
Bevor die Spaltenauswahl eingeführt wurde, habe ich versucht, das Problem zu lösen, nur eine Teilmenge von Spalten zu synchronisieren, indem ich eine benutzerdefinierte DBT-Transformation hinzufügte, die nur die Spalten enthielt, die ich synchronisieren wollte (wobei zu bedenken ist, dass bei einem solchen Ansatz nur Spalten aus den normalisierten Tabellen entfernt werden). In der offiziellen Dokumentation gibt es einen Artikel, der die Schritte zur Erstellung des Normalisierungs-DBT-Projekts von Airbyte beschreibt (so erhalten Sie schnell den Standardcode, den Sie Ihren Bedürfnissen entsprechend anpassen können).
Das Problem bei einem solchen Ansatz ist, dass bei der Verwendung von CDC die rohen Tabellen Änderungen für alle Spalten enthalten (einschließlich derer, die wir von der Synchronisierung ausschließen möchten). Wenn Sie die unerwünschten Spalten einfach aus den Select-Anweisungen im Normalisierungs-SQL entfernen, enthält die normalisierte Tabelle doppelte Datensätze. Das folgende Diagramm zeigt eine solche Situation. Wir haben eine Tabelle mit Spalten (id, col_1, col_2, col_3) und wir möchten nur die ersten drei synchronisieren. Spalte 3 wird in der Normalisierungs-SQL entfernt.
Bei der ersten Synchronisierung wird ein vollständiger Snapshot der Daten gezogen. Bei der zweiten wird eine Aktualisierung des Wertes von Spalte 2 erfasst, so dass eine neue Version des Datensatzes an die Zieltabelle angehängt wird. Bei der dritten Synchronisierung wird eine Aktualisierung von Spalte 3 erfasst. Auch hier wird eine andere Version des Datensatzes an die Zieltabelle angehängt. Da wir jedoch die Spalte mit dem aktualisierten Wert aus der Tabelle entfernt haben, sehen wir ein Duplikat des Datensatzes mit id=1, col_1=val 1, col_2=val 2_.
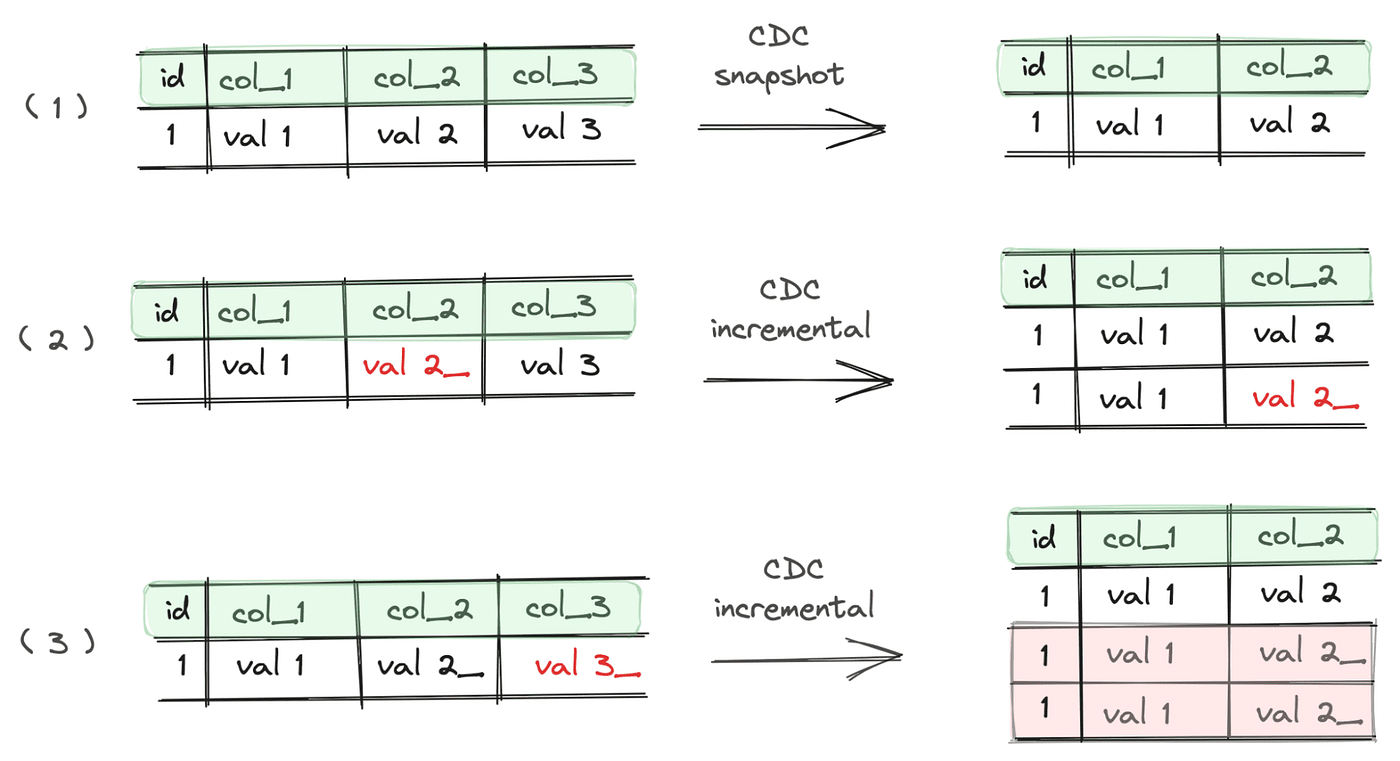
Beachten Sie, dass Airbyte einige zusätzliche Metadaten-Spalten in Bezug auf den CDC-Prozess hinzufügt (_ab_cdc_lsn - log sequence number, _ab_cdc_updated_at - timestampof update event, _ab_cdc_deleted_at - timestamp of record deletion) und ihre Werte werden unterschiedlich sein. In der Ansicht der Quelldaten erhalten wir jedoch doppelte Daten.
Als wir über dieses Problem stolperten, fügten wir im Normalisierungs-DBT-Projekt einen zusätzlichen Code hinzu, um die normalisierten Tabellen zu deduplizieren. Wir waren neugierig, ob die neue Funktion die duplizierten Daten produzierte oder nicht. Lassen Sie es uns herausfinden!
Testen des Verhaltens von Airbyte
Nachdem wir Quelle und Ziel hinzugefügt haben, die auf die entsprechenden Schemata verweisen, haben wir eine Verbindung zwischen ihnen erstellt. Im Feldauswahlbereich haben wir Spalte_3 abgewählt. Der Synchronisierungsmodus wurde auf "Inkrementell | Anhängen" eingestellt und für die Normalisierung wurde der Standardmodus verwendet.
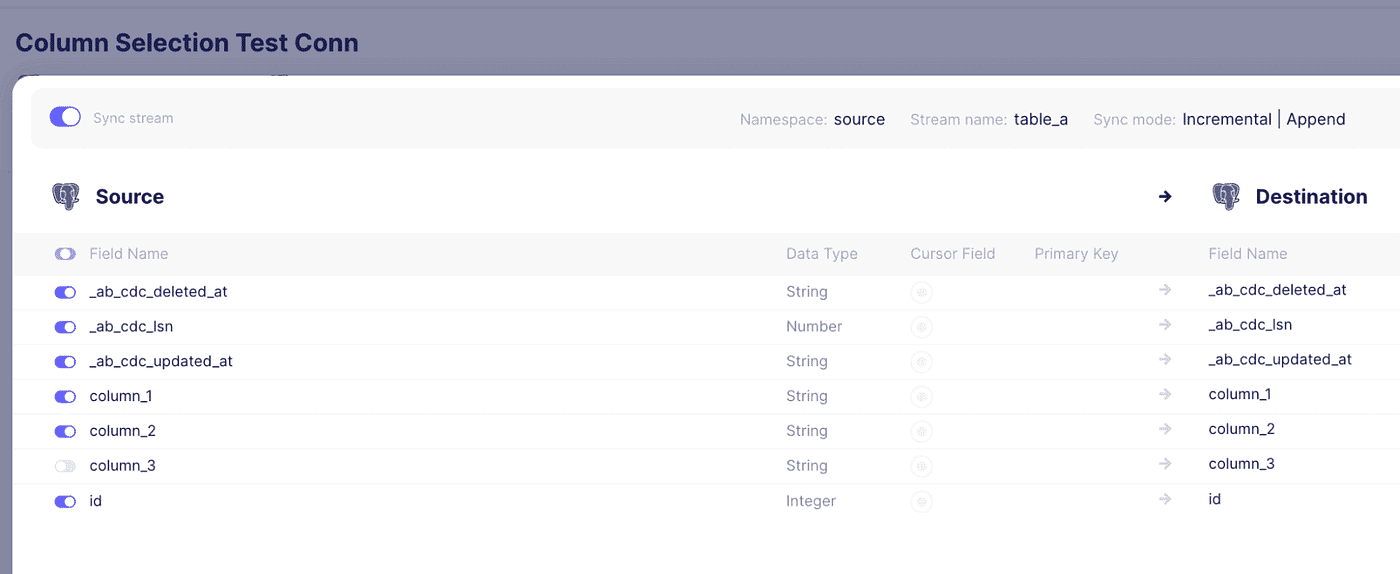
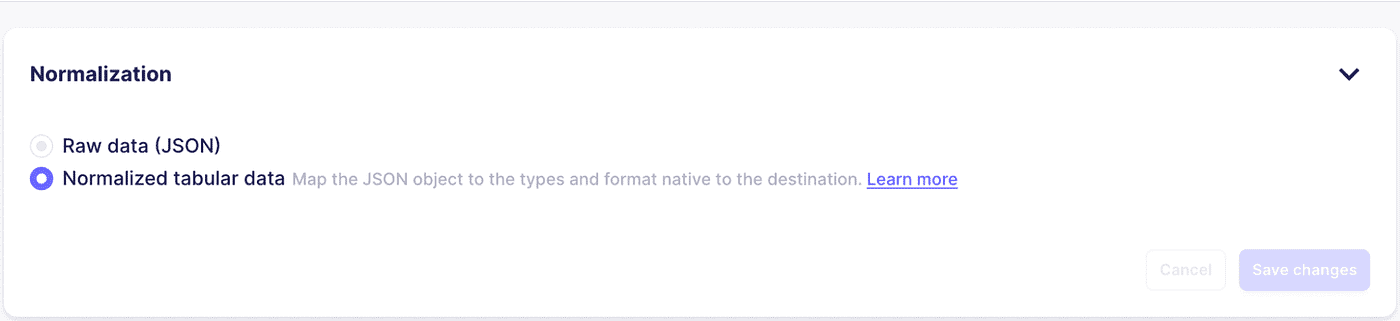
Führen Sie die erste Synchronisierung durch und kopieren Sie alle Daten auf das Ziel.
Hier sind die Ergebnisse der Zieltabelle:
Die Spaltenauswahlfunktion funktioniert wie erwartet - wir sehen Spalte_3 nicht in der Tabelle. Lassen Sie uns außerdem sicherstellen, dass diese Spalte nicht in die rohe Tabelle geladen wird. Hier ist eine formatierte JSON-Datei aus dem ersten Datensatz von _airbyte_raw_table_a table:
{
"id": 1,
"column_1": "foo1",
"column_2": "foo2",
"_ab_cdc_lsn": 23242280,
"_ab_cdc_deleted_at": null,
"_ab_cdc_updated_at": "2023-06-18T21:07:07.873Z"
}Die rohe Tabelle enthält keine abgewählten Felder. Toll!
Lassen Sie uns nun versuchen, 2 Aktualisierungen in der Quelldatenbank durchzuführen: eine für Spalte_1 und die andere für Spalte_3 (die bei unserer Synchronisierung nicht ausgewählt ist):
update source.table_a
set column_1 = column_1 || ' updated'
where id = 1;
update source.table_a
set column_3 = column_3 || ' updated'
where id = 1;Führen Sie dann die Synchronisierung durch.
Wie Sie aus den Protokollen ersehen können, wurden 2 Datensätze ausgegeben. Wenn Sie die Zieltabelle nach id=1 filtern, sehen Sie, dass es 3 Versionen des Datensatzes gibt und die letzten beiden die gleichen Werte für die Spalten id, column_1 und column_2 haben.
Drücken Sie die Eingabetaste oder klicken Sie, um das Bild in voller Größe anzuzeigen 
Die Schlussfolgerung aus diesem Test ist, dass Airbyte keine zusätzlichen Zeilen dedupliziert, die durch Aktualisierungen von Spalten erzeugt werden, die von einer Verbindung ausgeschlossen sind (in einem Szenario mit einer CDC-aktivierten Quelle). Es liegt in Ihrer Verantwortung, solche Szenarien zu handhaben.
Test #2 - extrahiert Airbyte alle Spalten aus der Quelle (PostgreSQL)?
Als wir den Artikel über die Details der Spaltenauswahl lasen, fiel uns auf, dass die Funktion auf Worker-Ebene und nicht auf der Ebene des Quellconnectors implementiert wurde. Wir haben diesen Absatz so verstanden, dass Airbyte trotz der Abwahl von Spalten aus der Synchronisierung weiterhin alle Daten aus der Quelle abruft (im Grunde läuft select * from source_table) und die abgewählten Spalten später vom Worker gelöscht werden.
Obwohl wir die Gründe für eine solche Implementierung durchaus verstehen (das Entfernen von Feldern durch den Worker erfordert keine Änderungen an den Quellkonnektoren), hatten wir gehofft, dass die Spaltenauswahlfunktion auch dazu beitragen würde, die Gesamtgröße der über das Netzwerk übertragenen Bytes zu reduzieren (was sich natürlich auf die Ausführungszeit der Synchronisierung auswirkt).
Wir beschlossen, einen kleinen Test durchzuführen und zu sehen, welche Abfrage Airbyte tatsächlich über die Quelldatenbank ausführt. Auch das haben wir mit einer PostgreSQL 15 -> PostgreSQL 15 Verbindung getestet. Die Quelltabelle (namens foobar) enthielt 11 Felder (id, column_1, column_2, ... bis column_10). Die Felder column_5 bis column_10 wurden in den Verbindungseinstellungen abgewählt. Wir füllten diese Tabelle mit ein paar mehr Datensätzen als die Tabelle aus dem vorherigen Test - so dauerte die Synchronisierung länger und wir konnten die Abfrage von Airbyte anhand der Ansicht pg_stat_activity (sie listet die aktuell laufenden Abfragen auf) sehen.
Wir haben das interaktive Terminal psql zusammen mit dem Befehl \watch verwendet, um die Ergebnisse der Select-Anweisung jede Sekunde zu aktualisieren:
\watch select query from pg_stat_activity where query ilike '%foobar%'Und das Ergebnis war eine Überraschung - auf eine gute Art :-):
select query from pg_stat_activity where query ilike '%foobar%';
SELECT "id","col_1","col_2","col_3","col_4","col_5" FROM "public"."foobar"Wie Sie sehen können, verwendet die Select-Anweisung kein Sternchen und zählt nur die in den Verbindungseinstellungen ausgewählten Spalten auf. Das war cool!
Einpacken
Zusammenfassung der Tests:
- Wenn Sie Daten aus CDC-aktivierten Quellen synchronisieren und einige Spalten von der Verbindung mit der neuen Spaltenauswahlfunktion ausschließen möchten, denken Sie daran, mögliche Duplikate zu behandeln.
- Airbyte wählt nicht unbedingt alle Felder aus der Quelle aus (zumindest ist das bei der Postgres-Quelle nicht der Fall). Wenn Sie die Auswahl vieler Spalten in der Quelltabelle aufheben, kann sich dies positiv auf die Geschwindigkeit der Synchronisierung auswirken.
Weitere Inhalte dazu folgen in Kürze! Bleiben Sie dran für zukünftige Updates zu anderen Datenlösungen.
Verfasst von
Jakub Szafran
Unsere Ideen
Weitere Blogs




Contact