Heutzutage produzieren wir immer mehr Geodaten. Viele Unternehmen haben Schwierigkeiten, diese Daten zu analysieren und zu verarbeiten. Viele dieser Daten stammen von IOT-Geräten, autonomen Autos, Anwendungen, Satelliten-/Drohnenbildern und ähnlichen Quellen. Wie wir sehen, besteht die Notwendigkeit, die Daten nahezu in Echtzeit zu verarbeiten. Dabei gibt es wichtige Herausforderungen, wie z.B. die Verwendung von Geodaten-Techniken wie Indizierung und räumliche Partitionierung im Falle von Streaming-Daten. Wie können wir die Abfragekomplexität reduzieren, um Cross-Join zu vermeiden und unseren Code reibungslos ablaufen zu lassen? Wie können wir Geohashes und andere hierarchische Datenstrukturen einsetzen, um die Abfrageleistung zu verbessern?
Außerdem müssen wir irgendwie die Anzahl der Codezeilen reduzieren, die wir schreiben, um typische georäumliche Probleme zu lösen, wie z.B. Objekte, die sich enthalten, schneiden, berühren oder in andere georäumliche Koordinatenreferenzsysteme transformieren.
Apache Spark ist eines der Tools in der Big Data-Welt, dessen Effektivität bei der Problemlösung immer wieder unter Beweis gestellt wurde. Der Mangel an nativer Unterstützung für Geodaten kann durch das Hinzufügen von Apache Sedona-Erweiterungen zu Apache Spark behoben werden.
Jetzt können wir es:
- Geodaten mit räumlichen Funktionen wie ST_Area, ST_Length usw. zu bearbeiten.
- Geodaten auf der Grundlage von Prädikaten validieren
- Geodaten mit räumlichen Verknüpfungstechniken anreichern (Stream-to-Table-Join oder Stream-to-Stream-Join).
Lassen Sie uns versuchen, Apache Sedona und Apache Spark zu verwenden, um Echtzeit-Streaming-Probleme im Bereich Geodaten zu lösen. Zunächst müssen wir die von Apache Sedona bereitgestellten Funktionalitäten hinzufügen.
Wie Sie strukturierte Streaming-Anwendungen von Spark mit geografischen Funktionen erweitern.
Sie können dies erreichen, indem Sie einfach Apache Sedona zu Ihren Abhängigkeiten hinzufügen.
Scala/Java
Bitte sehen Sie sich das Beispielprojekt an
Python
pip install apache-sedona
Sie müssen auch zusätzliche jar-Dateien zum Ordner spark/jars hinzufügen oder sie beim Definieren der spark-Sitzung schreiben. Ein Beispiel für diese Vorgehensweise finden Sie unter diesem Link.
Eine Spark-Session-Definition sollte wie folgt aussehen:
spark = SparkSession. \
builder. \
appName('appName'). \
config("spark.serializer", KryoSerializer.getName). \
config("spark.kryo.registrator", SedonaKryoRegistrator.getName). \
config('spark.jars.packages',
'org.apache.sedona:sedona-python-adapter-3.0_2.12:1.1.0-incubating,org.datasyslab:geotools-wrapper:1.1.0-25.2'). \
getOrCreate()Nachdem Sie die Spark-Sitzung für eine Scala/Java- oder Python-Anwendung definiert haben, fügen Sie zusätzliche Funktionen, Serialisierung von Geo-Objekten und räumliche Indizes hinzu, indem Sie den Funktionsaufruf wie unten beschrieben verwenden:
Python
SedonaRegistrator.registerAll(spark)
Scala/Java
SedonaSQLRegistrator.registerAll(spark)
Nun, da wir das alles vorbereitet haben, lassen Sie uns ein paar Probleme aus der realen Welt lösen.
Spatial SQL-Funktionen zur Bereicherung Ihrer Streaming-Workloads
Zurzeit implementiert Sedona über 70 SQL-Funktionen, mit denen Sie Ihre Daten anreichern können:
- Geodaten-Transformationsfunktionen wie ST_SubDivide, St_Length, ST_Area, ST_Buffer, ST_isValid, ST_GeoHash usw.
- Geodaten-Prädikate wie ST_Contains, ST_Intersects, ST_Within, ST_Equals, ST_Crosses, ST_Touches, ST_Overlaps
- Geodaten-Aggregation ST_Envelope_Aggr, ST_Union_Aggr, ST_Intersection_Aggr
- Konstruktorfunktionen wie ST_Point, ST_GeomFromText, ST_GeomFromWkb
Wir können vorwärts gehen und sie in die Tat umsetzen.
Filtern von Geodatenobjekten auf der Grundlage bestimmter Prädikate
Lassen Sie uns Polen als Beispiel nehmen.
Zunächst müssen wir die Form von Polen erhalten, was durch das Laden der Geodaten mit Apache Sedona erreicht werden kann. Sie können die Shapes für alle Länder hier herunterladen.
Der Einfachheit halber nehmen wir an, dass die an das Kafka-Thema gesendeten Nachrichten im json-Format mit den unten angegebenen Feldern vorliegen:
{
"location": {
"lon": "21.00",
"lat": "52.00",
"crs": "EPSG:4326"
},
“velocity”: {
“value”: 21.0,
“unitOfMeasure”: “km/h”
}
“id”: “11aa7c89-6209-4c4b-bc01-ac22219d6b64”
}Um die Filterung zu beschleunigen, können wir zunächst die Komplexität der Abfrage reduzieren. Bei Punkten, die weit entfernt liegen, können wir zunächst versuchen, zu prüfen, ob sie sich innerhalb des Begrenzungsrahmens von Polen befinden. Wenn dies der Fall ist, sollten wir mit einer komplexeren Geometrie prüfen.
Erstellen Sie die Geometrie Polens:
val countryShapes = ShapefileReader.readToGeometryRDD(
spark.sparkContext, “location”
)
val polandGeometry = Adapter.toDf(countryShapes, spark)
.filter("cntry_name == 'Poland'")
.selectExpr("ST_ASText(geometry)", "ST_ASText(ST_Envelope(geometry))")
.as[(String, String)]
.collect().head
val polandShape = polandGeometry._1
val polandEnvelope = polandGeometry._2Schritt der Transformation und Filterung
df
.selectExpr("decode(value, 'UTF-8') AS json_data", "timestamp")
.select(from_json($"json_data", schema).alias("measure"), $"timestamp")
.select(
expr("ST_Point(measure.location.lon, measure.location.lat)").alias("geom"),
col("measure"))
.select(
expr("""ST_Transform(geom, measure.location.crs, 'epsg:4326')""").alias("geom"),
col("measure"))
.filter(
expr(s"ST_Within(geom, ST_GeomFromWkt('$polandEnvelope'))")
)
.filter(
expr(s"ST_Within(geom, ST_GeomFromWkt('$polandShape'))")
)

Wir können ganz einfach Punkte herausfiltern, die weit von der polnischen Begrenzungsbox entfernt sind.
Broadcast Join für Feature-Anreicherung
In vielen Geschäftsfällen besteht die Notwendigkeit, Streaming-Daten mit anderen Attributen anzureichern. Mit Apache Sedona können wir diese Attribute mit räumlichen Operationen wie räumlichen Verknüpfungen anwenden.
Bleiben wir beim vorigen Beispiel und weisen wir eine polnische Gemeindekennung namens TERYT zu. Dazu benötigen wir geografische Shapes, die wir von der Website herunterladen können. 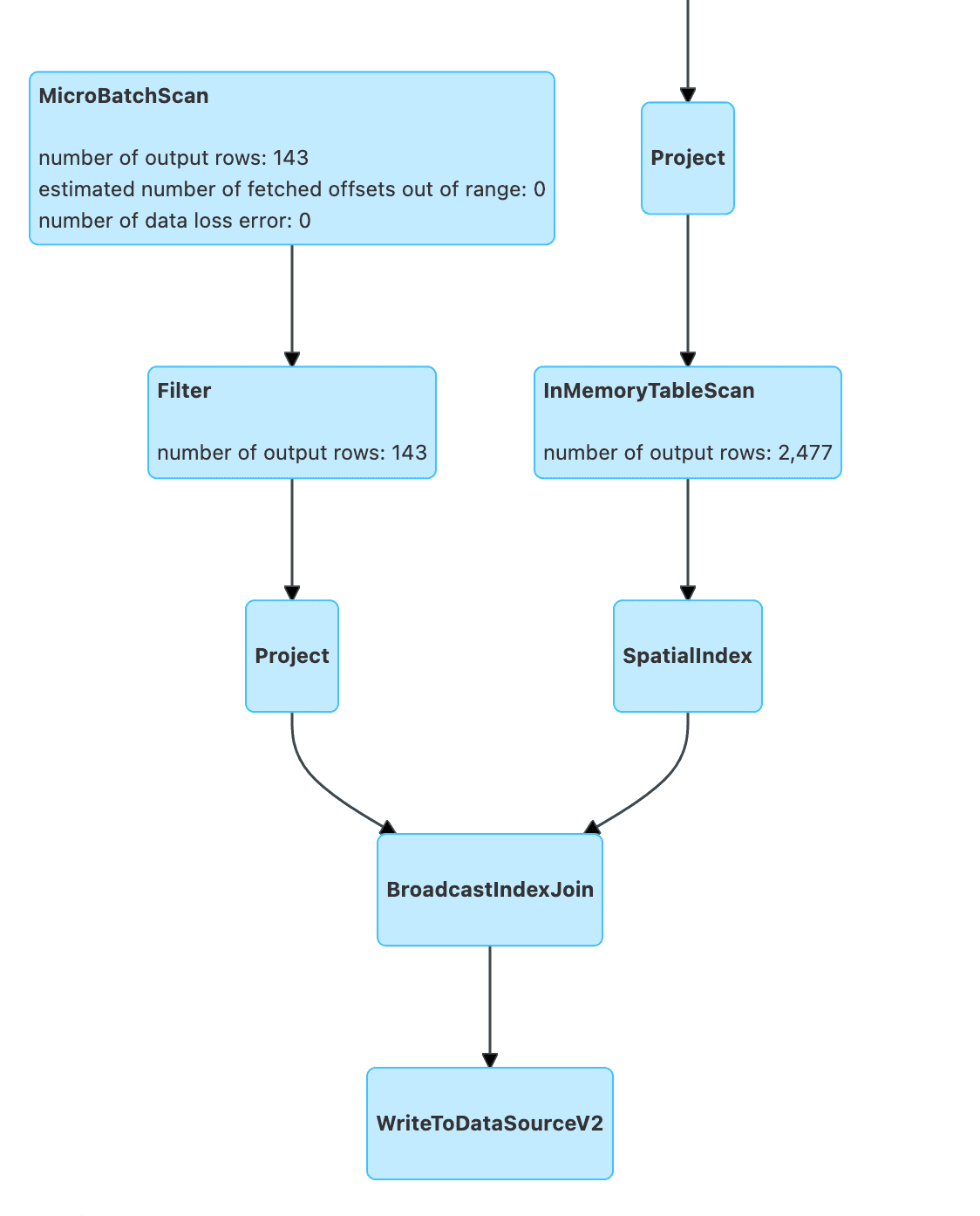
Zuerst müssen wir die Shapes der Geospatial municipalities laden
val municipalities = ShapefileReader.readToGeometryRDD(
spark.sparkContext,
"path"
)# Transformation, um die Koordinaten in der richtigen Reihenfolge zu erhalten und sie in das gewünschte Koordinatenreferenzsystem zu transformieren
val municipalitiesDf = Adapter.toDf(municipalities, spark)
.selectExpr("geometry", "JPT_KOD_JE AS teryt")
.selectExpr("ST_FlipCoordinates(ST_Transform(geometry, 'epsg:2180', 'epsg:4326')) AS geometry", "teryt")
.cache()# Senden wir unsere Daten
val broadcastedDfMuni = broadcast(GemeindenDf)
Der nächste Schritt besteht darin, den Streaming-Datensatz mit dem übertragenen Datensatz zu verbinden. Dazu muss dem vorherigen Beispiel ein kleines Stück Code hinzugefügt werden (siehe Filtern von Geodatenobjekten auf der Grundlage bestimmter Prädikate).
join(broadcastedDfMuni, expr("ST_Intersects(geom, geometry)"))
GeoHash
Um die Abfragekomplexität zu verringern und die Berechnungen zu parallelisieren, müssen wir die Geodaten irgendwie in ähnliche Teile aufteilen, die parallel verarbeitet werden können. Hierfür können wir den GeoHash-Algorithmus verwenden.
GeoHash ist eine hierarchisch aufgebaute Methode zur Unterteilung der Erdoberfläche in Rechtecke, wobei jedem Rechteck eine Zeichenfolge aus Buchstaben und Ziffern zugewiesen wird. Die Länge der Kennung hängt von der Unterteilungsebene ab. Beispiel:
lat 52.0004 lon 20.9997 mit der Genauigkeit 7 ergibt den Geohash u3nzvf7 und wie Sie vielleicht erraten können, um eine Genauigkeit von 6 zu erhalten, erstellen Sie eine Teilzeichenkette mit 6 Zeichen, die u3nzvf ergibt.

Indexed Join zwei Datenströme
Derzeit verfügt Sedona nicht über optimierte räumliche Verknüpfungen zwischen zwei Streams, aber wir können einige Techniken anwenden, um unsere Streaming-Aufgabe zu beschleunigen. In unserem Beispiel können wir Gemeindekennungen verwenden, um sie zunächst abzugleichen und dann einige räumliche Prädikate auszuführen.
leftGeometries
.join(rightGeometries.alias("right"),
expr("right_muni_id == left_muni_id")
)
.filter("ST_Intersects(left_geom, ST_Buffer(right_geom, 1000))")Zweitens können wir von Apache Sedona bereitgestellte integrierte Geofunktionen wie geohash verwenden, um die Daten zunächst auf der Grundlage der geohash-Zeichenkette zusammenzuführen und anschließend nach bestimmten Prädikaten zu filtern.
Beispiel:
für den Puffer 1000 um den Punkt lon 21 und lat 52 sind Geohashes auf der 6-Präzisionsstufe:
- 't5q0eq',
- 't5q0er',
- 't5q0et',
- 't5q0ev',
- 't5q0ew',
- 't5q0ex',
- 't5q0ey',
- 't5q0ez',
- 't5q0g2',
- 't5q0g3',
- 't5q0g8',
- 't5q0g9',
- 't5q0gb',
- 't5q0gc',
- 't5q0gd',
- 't5q0gf'.
Um Punkte innerhalb des angegebenen Radius zu finden, können wir Geohashes für Puffer und Geohash für Punkte generieren (verwenden Sie die von Apache Sedona bereitgestellten Geohash-Funktionen). Verbinden Sie die Daten auf der Grundlage von geohash und filtern Sie dann auf der Grundlage des Prädikats ST_Intersects.
Warum sollten Sie Apache Sedona verwenden, um Streaming-Daten mit Apache Spark zu verarbeiten?
Apache Sedona bietet Ihnen von Haus aus eine Vielzahl von räumlichen Funktionen, Indizes und Serialisierung. Sie brauchen sie also nicht selbst zu implementieren. Bei der Stream-Verarbeitung gibt es eine Menge zu tun.
Apache Sedona (incubating) ist ein System zur Verarbeitung von Geodaten, mit dem große Datenmengen auf vielen Rechnern verarbeitet werden können. Zur Zeit unterstützt es APIs für Scala, Java, Python, R und SQL-Sprachen. Es ermöglicht die Verarbeitung von Geospatial-Workloads mit Apache Spark und seit kurzem auch mit Apache Flink. Es erfreut sich zunehmender Beliebtheit (zum Zeitpunkt der Erstellung dieses Artikels hat es 440k monatliche Downloads auf PyPI) und soll noch in diesem Jahr zu einem Apache-Projekt auf höchster Ebene werden. Wenn Sie mehr über Apache Sedona erfahren möchten, lesen Sie unseren früheren Blog "Einführung in Apache Sedona".
—
Hat Ihnen dieser Blogbeitrag gefallen? Schauen Sie sich unsere anderen Blogs an und melden Sie sich für unseren Newsletter an, um auf dem Laufenden zu bleiben!
Verfasst von
Paweł Tokaj
Unsere Ideen
Weitere Blogs




Contact