
Apache Sedona ist ein verteiltes System, das Ihnen die Möglichkeit gibt, riesige Mengen von Geodaten auf verschiedenen Rechnern zu laden, zu verarbeiten, zu transformieren und zu analysieren. Es erweitert Apache Spark um unveränderliche verteilte Datensätze (SRDDs) und bietet außerdem Spatial SQL, um schwierige Probleme zu vereinfachen.
Apache Sedona bietet eine API in Sprachen wie Java, Scala, Python und R und auch SQL, um komplexe Probleme mit einfachen Codezeilen auszudrücken.
Wenn Sie zum Beispiel Geschäfte in einer bestimmten Entfernung zur Straße finden möchten, können Sie einfach schreiben:
SELECT s.shop_id, r.road_id
FROM Geschäfte AS s, Straßen AS r
WHERE ST_Distance(s.geom, r.geom) < 500;
So einfach wird ein komplexes Problem auf 3 Codezeilen vereinfacht. Diese Abfrage bietet Ihnen alle Sedona-Optimierungen wie z.B.:
- räumliche Aufteilung
- räumliche Indizierung
- Serialisierung räumlicher Daten
Apache Sedona Architektur
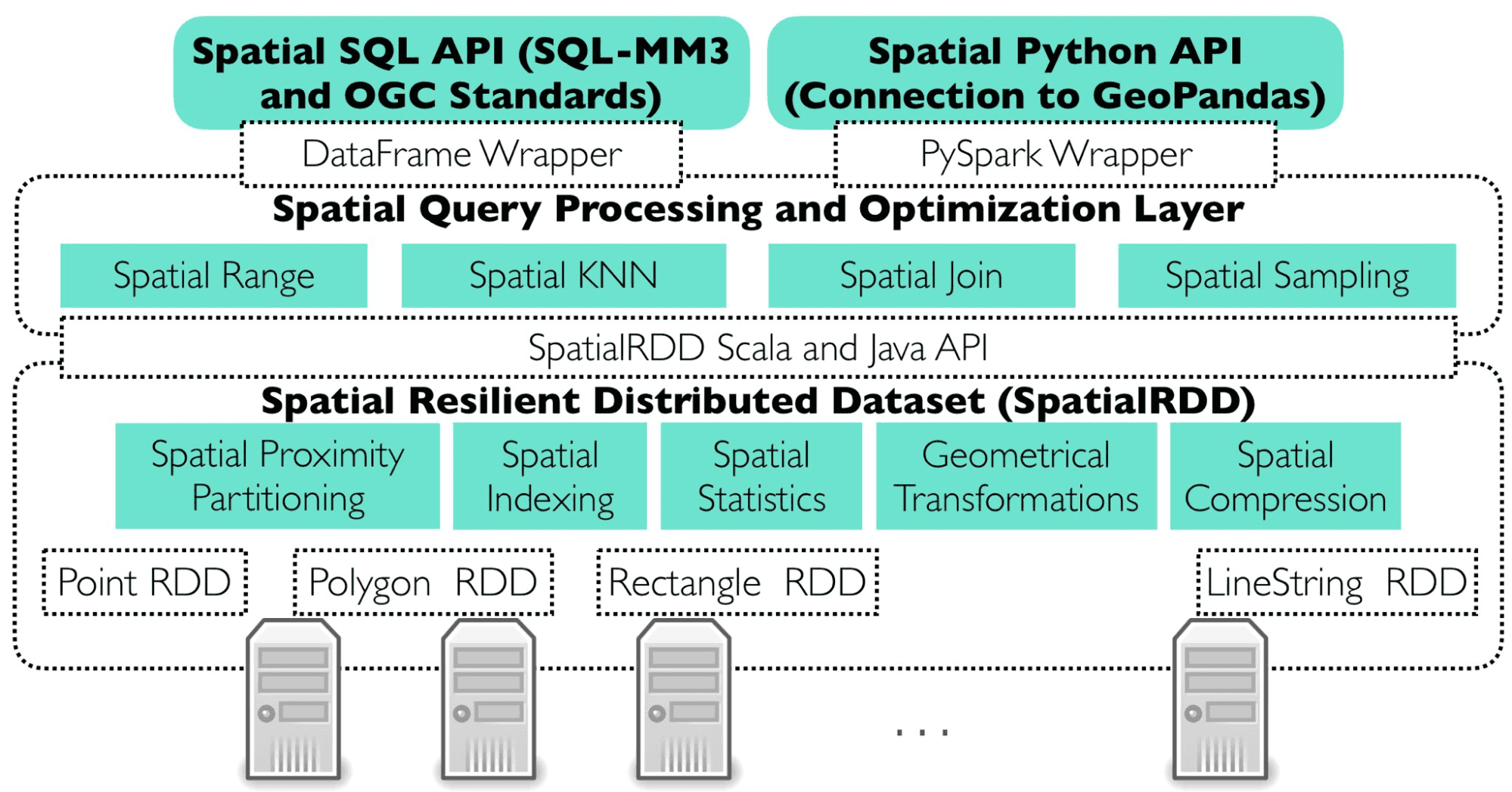
Apache Sedona fügt Apache Spark neue Join-Pläne hinzu, um Daten effizient zu verarbeiten und typische räumliche Probleme auf verteilte Weise zu lösen. Sedona führt automatisch Range-, Join-, Query- und Distance-Join-Abfragen durch. Im Falle von Broadcast-Joins muss der Benutzer die Broadcast-Funktion für einen räumlich verbundenen Datenrahmen aktivieren.
Bereich verbinden
Diese Optimierung wird verwendet, wenn bei der Ausführung der Spark Join-Methode Operationen wie ST_Contains, ST_Intersects, ST_Within verwendet werden. Der physische Plan der Abfrage sieht wie folgt aus:

Entfernung Verbinden
Die Optimierung wird verwendet, um Objekte innerhalb eines bestimmten Radius zu finden. Der physische Plan sieht in etwa so aus: 
Broadcast Join
Nützlich, wenn die Daten auf der rechten Seite der Verknüpfung klein genug sind, um sie auf alle Rechner zu kopieren. Datenmischung und räumliche Partitionierung auf der rechten Seite können übersprungen werden. Standardmäßig ist diese Funktion nicht aktiviert. Sie muss mit den Broadcast-Funktionen aus spark.sql.functions verwendet werden. Der physische Plan sieht wie folgt aus:

Prädikat Pushdown
Vor der räumlichen Verknüpfung ist eine Bereichsfilterung erforderlich. Sedona filtert zunächst den Bereich und fügt dann die Datenrahmen räumlich zusammen.

Zentrale Konzepte:
Räumliche Partitionierung
Um die Daten auf verschiedene Rechner zu verteilen, weist Apache Sedona jeder Geometriepartition zu, wo sie verarbeitet werden soll.
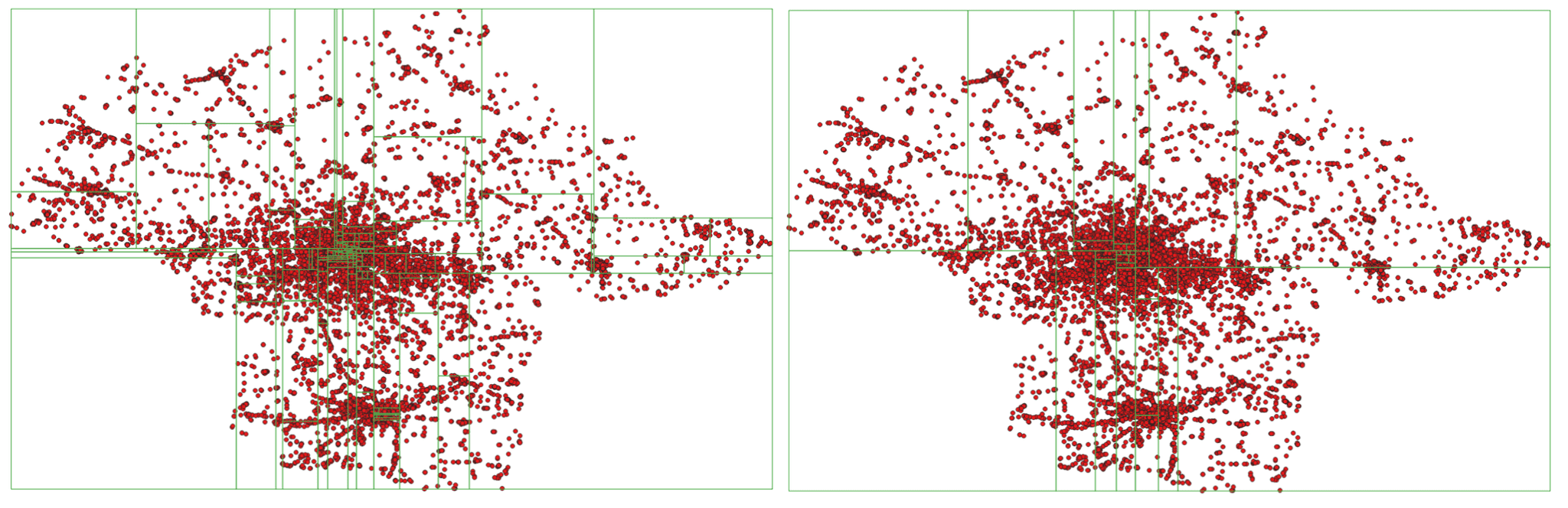 KDB Tree räumliche Partitionierung mit 100 und 20 Partitionen
KDB Tree räumliche Partitionierung mit 100 und 20 Partitionen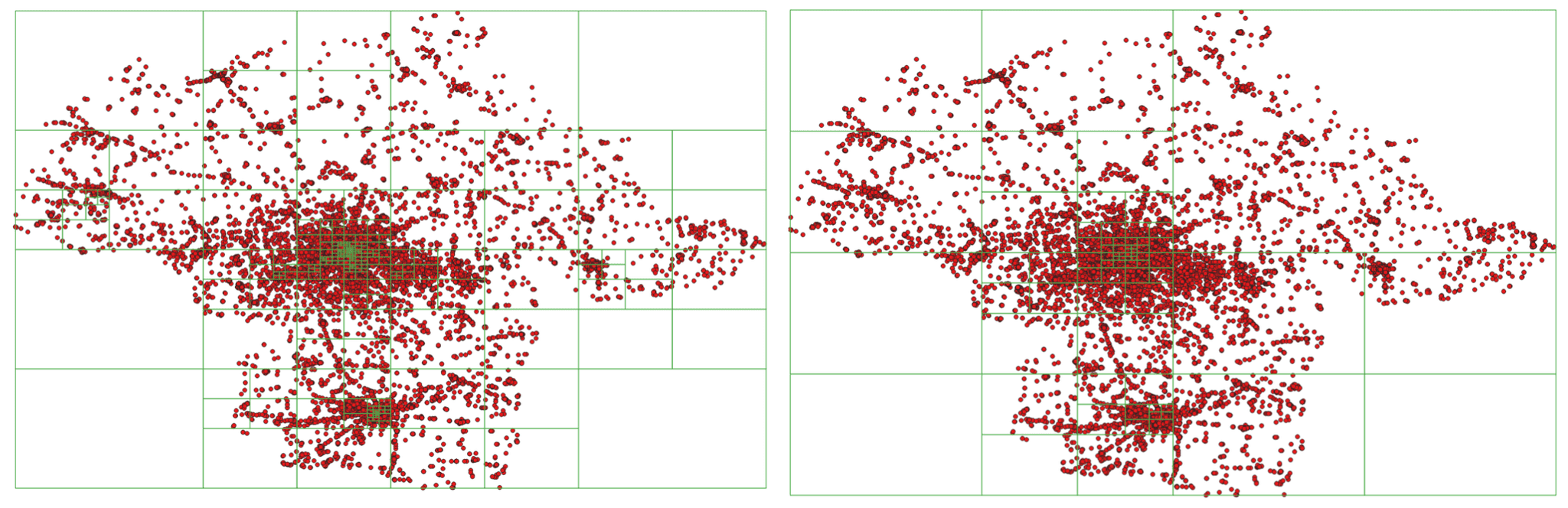 Quad Tree räumliche Partitionierung mit 100 und 20 Partitionen
Quad Tree räumliche Partitionierung mit 100 und 20 Partitionen
Wie Sie in den Beispielen sehen können, ist die Größe der Partition (räumliche Größe, Breite und Höhe) umso kleiner, je mehr Punkte innerhalb des Bereichs liegen.
Derzeit unterstützt Apache Sedona zwei Arten der räumlichen Partitionierung
- KDBTree
- QuadTree
Räumliche Indizierung
Apache Sedona erstellt zwei Indizes, während es riesige Mengen von Geodaten verarbeitet, sowohl global als auch lokal.
Das Hauptziel des globalen Indexes besteht darin, Partitionen zu entfernen, die keine Daten enthalten, die bei der Abfrage nicht mehr nützlich sind. Dies wiederum beschleunigt die Abfrage, da es keine Worker mit leeren Partitionen zu verarbeiten gibt.
Lokale Indizes werden in jeder Partition separat erstellt, um die Anzahl der Vergleiche zwischen Geometrien zu verringern. Dies ist besonders wichtig, wenn die analysierten Geometrien komplex sind, wie z.B. Polygone mit einer großen Anzahl von Eckpunkten. Derzeit unterstützt Apache Sedona drei Arten von Indizes:
- RTree
- KdTree
- KDBTree
Broadcast verbinden
Dies ist nützlich, wenn die Daten auf einer Seite einer räumlichen Verknüpfung klein genug sind, um Kopien der Daten auf die Rechner zu verteilen. Dies kann die Menge an Ressourcen und die Verarbeitungszeit erheblich reduzieren. Es besteht keine Notwendigkeit, eine Seite der Verknüpfung räumlich zu partitionieren, so dass wir auf kostspielige Shuffles verzichten können.
Serialisierung räumlicher Daten
Um die Auswirkungen der Verarbeitung von Geodaten zu verringern, implementiert Apache Sedona die Objektserialisierung. Die Methode ist definitiv schneller als der in Spark implementierte Standard, kryo serializer. Die Serialisierung von räumlichen Objekten wie Punkten, Polygonen und Linestrings reicht nicht aus - in vielen Fällen kann der räumliche Index genauso groß oder sogar größer sein als die räumlichen Objekte insgesamt. Apache Sedona serialisiert diese Objekte ebenfalls, um den Speicherbedarf zu reduzieren und Berechnungen weniger kostspielig zu machen.
Um den Spatial Index zu serialisieren, verwendet Apache Sedona den DFS-Algorithmus (Depth For Search).
Apache Sedona verwendet wkb als Methode, um Geometrien als Arrays von Bytes niederzuschreiben. Ein Beispiel für die Dekodierung von Geometrien sieht wie folgt aus:
POINT(21 52)
Example Point(50.323281, 19.029889)
1 | 1 0 0 0 |-121 53 -107 69 97 41 73 64 | -103 -126 53 -50 -90 7 51 64
Das erste Byte ist die Byte-Reihenfolge, die nächsten vier entsprechen dem Geometrie-Datentyp und die letzten 16 kodieren entsprechend die X- und Y-Koordinaten.
Wie Sie Apache Sedona verwenden
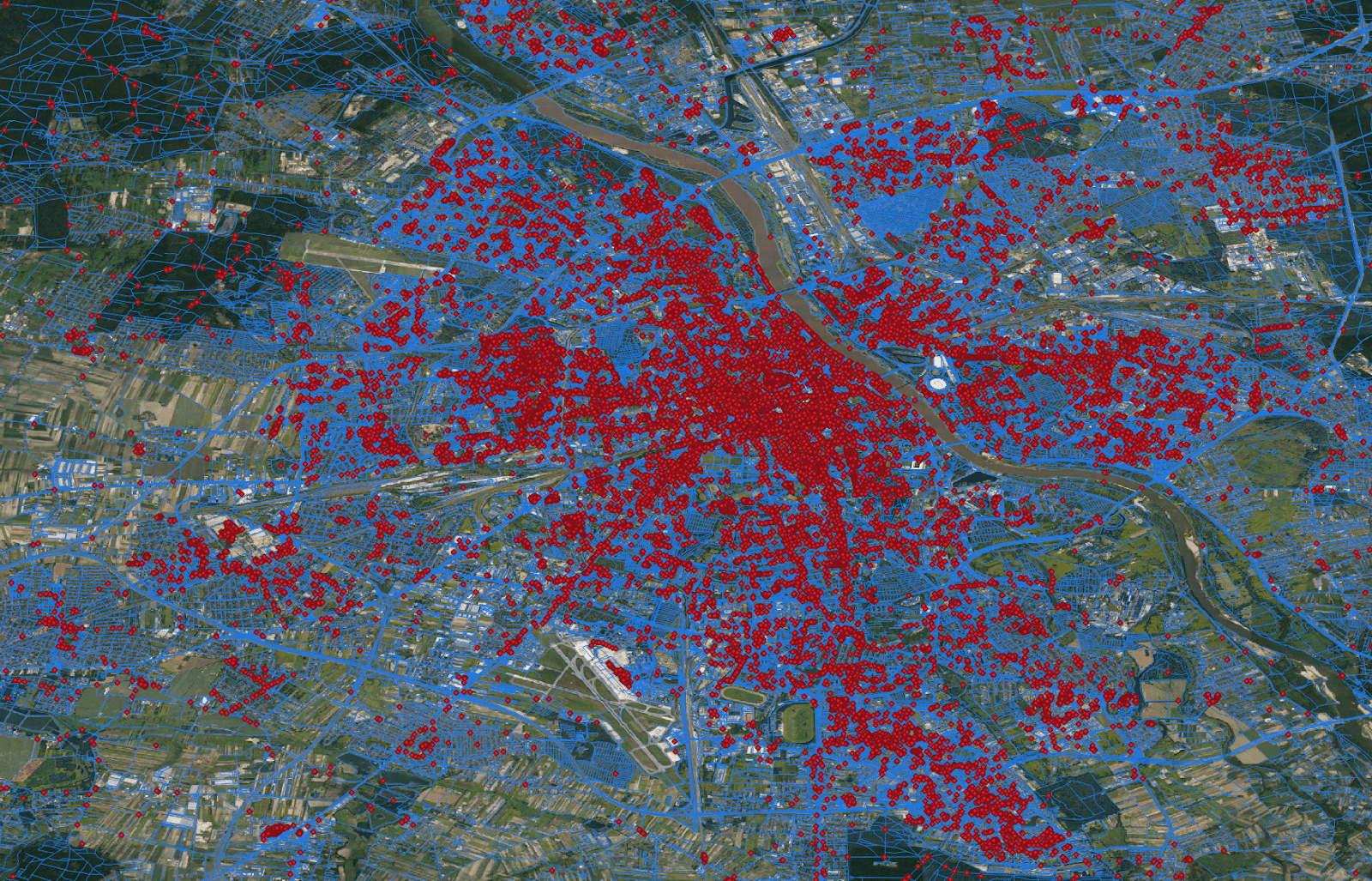
In diesem Beispiel werden wir versuchen, Restaurants im Umkreis von 200 m von bestimmten Straßen in der Woiwodschaft Masowien zu finden. Zuerst schreiben wir die Abfrage mit der SQL-API, danach wechseln wir zur Core RDD-API, wo eine definierte räumliche Partitionierung und räumliche Indizierung gewählt werden kann.
SQL API
Nehmen wir an, dass unser Datensatz wie folgt aussieht: 
Der Datensatz mit den Straßen wurde bereits in den Geodatenrahmen geladen: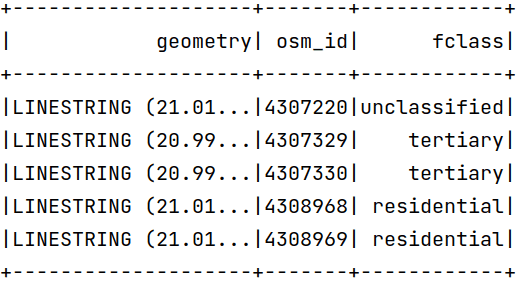
Wie Sie sehen können, haben die Datenrahmen Koordinaten in Grad, aber das Prädikat ist in Metern - Apache Sedona wandelt Koordinaten nicht automatisch in Meter um. Um die Koordinaten in Meter zu ändern, können wir die Funktion ST_Transform verwenden. Die Koordinaten in EPSG:2180 sollten wie folgt aussehen: 
Um die Lösung mit Scala und der SQL-API auszudrücken, können wir einen einfachen Code schreiben:
val restaurants = sparkSession.read.parquet("pois").where("fclass == 'restaurant'")
.withColumn("geometry", expr("ST_Transform(geometry, 'EPSG:4326', 'EPSG:2180')"))
val roads = sparkSession.read.parquet("roads")
.withColumn("geometry", expr("ST_Transform(geometry, 'EPSG:4326', 'EPSG:2180')"))
restaurants.createOrReplaceTempView("restaurants")
roads.createOrReplaceTempView("roads")
sparkSession.sql(
"""
|SELECT rt.osm_id AS rt_id, rd.osm_id AS rd_id, ST_Distance(rd.geometry, rt.geometry) AS dist
|FROM roads AS rd, restaurants AS rt
|WHERE ST_Distance(rt.geometry, rd.geometry) <= 200
|""".stripMargin
)Dadurch wird ein physischer Plan erstellt: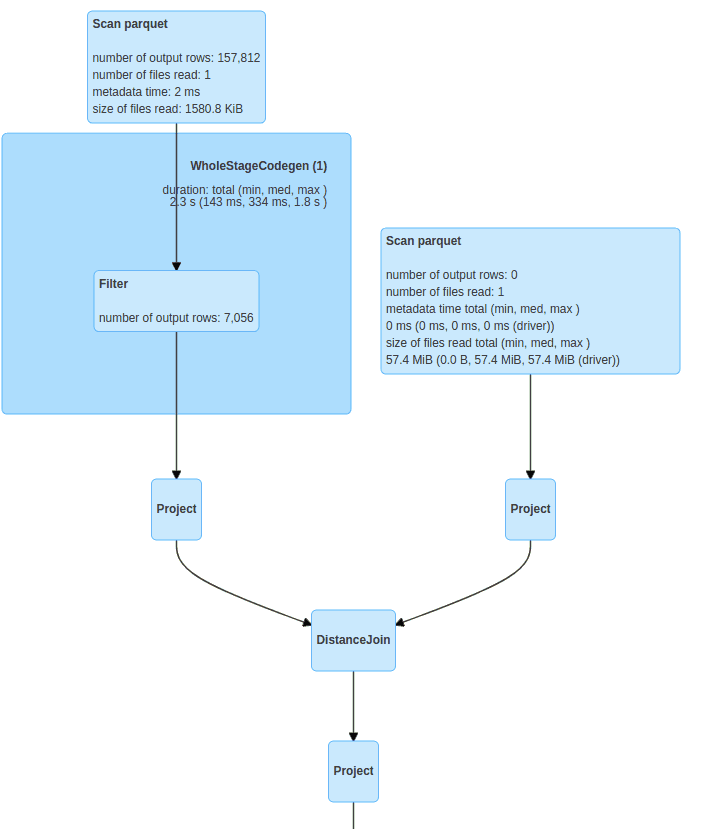
Da die Apache Sedona RDD-API aufgrund von Spark-Einschränkungen schneller ist als die DataFrame-API, sah der zuvor verwendete entsprechende Code wie folgt aus:
// finding desired transformation
val sourceCrsCode = CRS.decode("EPSG:4326")
val targetCrsCode = CRS.decode("EPSG:2180")
val transformation = CRS.findMathTransform(sourceCrsCode, targetCrsCode, false)
// reading shapefile format to SpatialRDD
val pois = ShapefileReader.readToGeometryRDD(
sparkSession.sparkContext, "pois"
)
// filter to restaurants and transform to metric coordinate system
pois.rawSpatialRDD = pois.rawSpatialRDD.filter(row => row.getUserData.toString.split("\t")(2) == "restaurant")
pois.rawSpatialRDD = pois.rawSpatialRDD.repartition(100)
pois.rawSpatialRDD = pois.rawSpatialRDD.map(geom => JTS.transform(geom, transformation))
// reading roads to SpatialRDD
val roads = ShapefileReader.readToGeometryRDD(
sparkSession.sparkContext, "roads")
// transforming to metric coordinate system
roads.rawSpatialRDD = roads.rawSpatialRDD.map(geom => JTS.transform(geom, transformation))
// Creating Circle rdd based on points and given radius
val circleRDD = new CircleRDD(roads, 200)
// analyzing data to optimize spatial partitioning
circleRDD.analyze()
// apply spatial partitioning
circleRDD.spatialPartitioning(GridType.KDBTREE)
// building spatial index, we also apply spatial indexing on spatial partitions to prune empty partitions
circleRDD.buildIndex(IndexType.RTREE, true)
// apply spatial partitioning from left side of the join to the right side
pois.spatialPartitioning(circleRDD.getPartitioner)
// performing spatial join between roads buffers and restaurants, as third argument we chose to use index and as
// fourth we still match points which lays on boundaries.
val spatialResult = JoinQuery.DistanceJoinQueryFlat(pois, circleRDD, true, true)
// converting result to dataframeVorteile der Verwendung von Apache Sedona
Möglichkeit, Daten aus verschiedenen Datenquellen zu laden
Apache Sedona bietet die Möglichkeit, die Daten aus verschiedenen Datenquellen zu laden, wie z.B.:
- Shapefile
- geojson
- wkt
- wkb
- postgis
- räumliches Parkett
Benutzerfreundlichkeit
Drücken Sie komplexe Probleme mit einer einfachen SQL-Abfrage aus:
SELECT superhero.name
FROM city, superhero
WHERE ST_Contains(city.geom, superhero.geom)AND city.name = 'Gotham'
Integration mit gängigen Bibliotheken
Laden Sie die Daten mit Hilfe von Geopandas, der Liste der geformten Objekte, konvertieren Sie die Sequenz der locationtech Geometrieobjekte direkt in den Geospatial Data Frame.
Einfach einzurichten
Installieren Sie über PyPI, fügen Sie der Spark-Sitzung zusätzliche Jars hinzu und das ist alles. Im Falle von jvm-basierten Anwendungen fügen Sie Apache Sedona als Abhängigkeit hinzu und erstellen ein Fat Jar.
Skalierbarkeit
Sie können Ihre Geodaten-Workflows auf viele Rechner verteilen.
Funktioniert überall in der Cloud und vor Ort
Führen Sie es überall aus
- Auf einem Prämisse-Hadoop-Cluster
- GCP-Datenverarbeitung
- Amazon EMR und Kleber
- Datenbausteine
- usw.
Fazit
Apache Sedona (incubating) ist eine vielversprechende Bibliothek, die die Skalierung von Arbeitslasten bei der Verarbeitung von Geodaten ermöglicht. Sie kann problemlos in der Cloud wie AWS, Azure oder GCP eingesetzt werden. Sie bietet APIs in den gängigsten Sprachen wie Java, Scala, Python und R.
Apache Sedona Hauptobjekte:
Benutzerfreundlichkeit: Umfassende API für die Verarbeitung und Transformation von Geodaten
Skalierbarkeit: Sedona kann eine räumliche Verknüpfung von 4 Milliarden Punktdaten und 200 Tausend Polygondaten in ~3 Minuten auf 4 Rechnern durchführen
Integrierbarkeit: Integration mit moderner Data-Science-Infrastruktur und GIS-Tools
Einsatzfähigkeit: Einfache Bereitstellung bei den wichtigsten Cloud-Anbietern
Popularität: ~1k Sterne auf GitHub und fast 200k monatliche Downloads auf PyPI
Wenn Sie mehr wissen möchten, lesen Sie bitte die Dokumentation von Apache Sedona.
Hat Ihnen dieser Blogbeitrag gefallen? Schauen Sie sich unsere anderen Blogs an und melden Sie sich für unseren Newsletter an, um auf dem Laufenden zu bleiben!
Verfasst von
Paweł Tokaj
Unsere Ideen
Weitere Blogs




Contact