Der Bedarf an einem einheitlichen Format für Geodaten
In den letzten Jahren wurden viele Geodaten-Frameworks entwickelt, um große Geodaten aus verschiedenen Datenquellen zu verarbeiten und zu analysieren. Viele von ihnen kämpften mit einem einheitlichen Datenformat, das über viele Rechner verteilt werden kann. Das bisher beliebteste Geodatenformat ist Shapefile, aber es hat viele Nachteile, wie z.B.:
- mehrere Dateiformate (.shp, .shx, .dbf und .prj und sogar einige optionale Formate)
- es lässt sich nicht gut komprimieren
- er ist durch die Größe seines Spaltennamens (10 Zeichen) begrenzt.
- es unterstützt keine verschachtelten Felder
- es hat eine Größenbeschränkung von 2 GB
- es kann nur ein Geometriefeld in der Datei gespeichert werden, und mit der Größe des Shapefiles sinkt auch die Verarbeitungseffizienz erheblich
- Sein Format ist nicht speziell für verteilte Systeme konzipiert.
Geojson kann verschachtelte Felder speichern, aber es wird nicht verteilt. Es gab einen Ansatz, Geojson als separate Zeilen zu speichern, um die Verteilung dieser Dateien zu ermöglichen:
{"type": "Feature", "geometry": {"type": "Point", "coordinates": [21.022516, 52.207257] }, "properties": { "city": "Warszawa"}}
{"type": "Feature", "geometry": {"type": "Point", "coordinates": [19.511426, 51.765019] }, "properties": { "city": "Łódź"}}
{"type": "Feature", "geometry": {"type": "Point", "coordinates": [2.121482, 41.381212] }, "properties": { "city": "Barcelona"}}Allerdings ist es nicht komprimiert und wird als reiner Text gespeichert, so dass es, wie Sie sehen können, sehr groß ist. Außerdem können Sie mit geojson nur jeweils ein Geometriefeld speichern und es unterstützt keine räumlichen Indizes.
Es gibt auch ein Geopaket, das ein SQLLite-Container ist. Es ist kleiner als Shapefile und relativ neu, aber nicht für verteilte Systeme konzipiert.
In Geospatial-Big-Data-Frameworks wie Geomesa und Apache Sedona (in der Inkubationsphase) verwendet die Community häufig Parquets zum Speichern von Geodaten, aber in vielen Fällen wird nur wkb oder wkt zum Speichern von Geodatenobjekten verwendet, ohne dass es Verbesserungen bei Metadaten oder Indizierungstechniken gibt.
Parkett Einführung
Apache Parquet ist ein quelloffenes, spaltenförmiges Datenspeicherformat, das Daten für effiziente Ladevorgänge speichert, sie gut komprimiert und die Datengröße enorm verringert. Es verfügt über eine API für Sprachen wie Python, Java, C++ und mehr und ist gut mit Apache Arrow integriert. Weitere Informationen hierzu finden Sie auf der offiziellen Website von apache parquet https://parquet.apache.org/docs/.
Lassen Sie uns einen Blick auf die größten Vorteile von Parkett werfen:
- Es ist gut komprimiert, so dass es die Speicherkosten in der Cloud reduziert.
- Das Überspringen von Daten und Feldstatistiken kann dazu beitragen, die Leistung der Datenverarbeitung zu verbessern, indem kleinere Teile der Daten geladen werden.
- Entwickelt für die Speicherung großer Datenmengen jeder Art
Parquet ist ein großartiges Datenformat für die Speicherung komplexer, großer Datenmengen, aber es fehlt die Unterstützung von Geodaten, und so entstand die Idee zu Geoparquet.
Ziel des Geoparketts
- Einführung eines kolumnaren Geodatenformats, das die Effizienz in analytischen Anwendungsfällen erhöht. Aktuelle Datenformate wie Shapefile können nicht einfach partitioniert und auf vielen Rechnern verarbeitet werden.
- Einführung eines kolumnaren Datenformats in die Welt der Geodaten. Die meisten aktuellen Tools zur Analyse von Geodaten profitieren nicht von all den bahnbrechenden Entwicklungen der letzten Jahre.
- Ein einheitliches, leicht austauschbares Datenformat zu schaffen, das in modernen Analysesystemen wie BigQuery, Snowflake, Apache Spark oder Redshift austauschbar ist. Derzeit kann das Laden von Geodaten in solchen Systemen problematisch sein. In Redshift beispielsweise können Geodaten nur mit dem Befehl copy from shapefile* geladen werden. Apache Spark-Benutzer speichern die Daten oft im wkt- oder wkb-Format, aber Geoparquet kann auf viele Arten (mit crs oder ohne, mit ewkt oder wkt) Interoperabilitätsprobleme lösen.
- Zur Persistenz von Geodaten aus Apache Arrow (GeoArrow spec wurde parallel zu geoparquet entwickelt).
Wir haben uns die Vorteile von Geoparquet angesehen, nun wollen wir uns die Dateispezifikation ansehen.
Spezifikation des Geoparquet-Formats
Die wichtigsten Komponenten von Geoparkett sind:
- Geometrie Spalten
- Metadaten
- Datei-Metadaten
Spalten-Metadaten
Geometrie Spalten
Geometriespalten werden im wkb (well known binary) Datenformat gespeichert. Wkb übersetzt ein Geometrieobjekt in ein Array von Bytes.
Die ersten beiden Bytes geben die Byte-Reihenfolge an
00 - bedeutet Big Endian
01 - bedeutet Little Endian
Als nächstes wird der Geometrietyp (der auch die Geometriedimension enthält) vierfach codiert, d.h. der 2D-Punkt wird durch 0001 dargestellt. Die letzten 16 Bytes stellen die x- und y-Koordinaten (8-Byte-Fließkommazahlen) für Punkte dar.
PUNKT(50.323281, 19.029889)
01 | 1 0 0 0 |-121 53 -107 69 97 41 73 64 | -103 -126 53 -50 -90 7 51 64
Für weitere Details besuchen Sie bitte https://libgeos.org/specifications/wkb/
* Es kommt häufig vor, dass eine Geometriespalte im wkt- oder wkb-Format viele Punkte enthält und die Länge der Rotverschiebungsspalte überschreitet.
* Dieser Blog wurde geschrieben, als die Version 0.4 festgelegt wurde.
Datei-Metadaten
Version - die Version der Geoparquet-Datei zum Zeitpunkt der Erstellung dieses Artikels war geoparquet 0.4.0
Primäre_Spalte - der Name der primären Geometriespalte. Einige Systeme erlauben die Speicherung mehrerer Geometriespalten und benötigen die Standardspalten.
Spalten - eine Übersicht über die Namen der Geometriespalten und ihre Metadaten.
Metadaten der Geometriespalte
- encoding - die Geometriespalte wird in Bytes kodiert. Der ursprüngliche Ansatz ist wkb, aber in späteren Versionen der Spezifikation können weitere Methoden aufgenommen werden. Dieses Feld bezieht sich auf die Kodierungsmethode.
- geometry_type - definiert den Geometrietyp der Spalte wie "Point", "LineString", "Polygon" - für 3D-Punkte ist es PointZ. Dies ist nützlich, um das Laden der Daten zu optimieren und bei komplexen Operationen wie der räumlichen Verknüpfung kann die vorherige Information über den Typ der Geometriespalte nützlich sein.
- crs - Angabe des Koordinatenreferenzsystems im PROJJSON-Format. Dieser Parameter ist optional. Wenn er nicht verfügbar ist, sollten die Daten im Format Längengrad-Breitengrad gespeichert werden (EPSG:4326 crs).
- Ausrichtung - Die Koordinaten können im oder gegen den Uhrzeigersinn angeordnet sein.
- Kanten - gibt an, wie die Kante zwischen zwei Punkten betrachtet werden soll, ob als kartesische Gerade oder als sphärischer Abstand, mögliche Optionen sind planar und sphärisch.
- bbox - definiert die Boundary Box für jede Geometriespalte. Sie kann die Lesezeiten beschleunigen, indem sie nur das Parkett innerhalb einer bestimmten Boundary Box ausschneidet. Dies kann besonders bei Abfragen zwischen großen Datensätzen nützlich sein. Wenn Sie mehrere Geometriespalten bereitstellen, können Sie außerdem die Boundary Box für alle Spalten vorberechnen, was die Leistung der räumlichen Verknüpfung für komplexe Geometrieobjekte (z.B. Polygone mit vielen Koordinaten) verbessern kann. Bbox ist ein Array mit minimalen und maximalen Koordinaten für jede Dimension.
- Epoche ist der Zeitpunkt, an dem die Koordinaten gemessen wurden. Dies ist wichtig für Punkte, die auf der Oberfläche gemessen wurden, die sich im Laufe der Zeit ändern kann.
Eigenschaften von Geoparkett
- Mehrere räumliche Bezugssysteme - es ist wichtig, die Informationen über Koordinatenbezugssysteme in der Datei zu behalten, um verschiedene Datensätze vergleichen zu können.
- Mehrere Geometriespalten - die Spezifikation sagt uns etwas über eine bestimmte Geometrie-Standardspalte oder viele andere.
- Große Komprimierung / kleine Dateien - der große Nachteil von Shapefiles, Geojson-Dateien oder KML ist ihre Größe; Parkett reduziert die Dateigröße.
- Geoparquet arbeitet sowohl mit planaren als auch mit sphärischen Koordinaten und unterstützt 2D- und 3D-Daten.
- Spaltenbasierte Datenformate wie Parquet eignen sich hervorragend für leseintensive Analyse-Workflows und ermöglichen das kostengünstige Lesen einer Teilmenge von Spalten oder das Filtern anhand von Spaltenstatistiken.
- Unterstützung für die Datenpartitionierung - Parquet ermöglicht die Aufteilung von Daten, um die Parallelität zu erhöhen. Geoparquet zielt darauf ab, geospatiale Partitionen zu erstellen, um Daten effizient aus dem Data Lake zu laden.
- Aktivieren Sie räumliche Indizes - für die bestmögliche Leistung sind räumliche Indizes unerlässlich.
Der Fahrplan des Geoparkett-Projekts
Das Geoparquet-Projekt zielt darauf ab, innerhalb von Monaten, nicht Jahren, ein einheitliches Datenformat bereitzustellen; das offizielle Repository wurde im August 2021 eingerichtet.
0.1 - Grundlagen geschaffen, Ziel für Implementierungen
0.2 / 0.3 - Erste Rückmeldung, Unterstützung von 3D-Koordinaten, Geometrietypen, crs optional.
0.x - räumliche Indizes usw.
1.0.0-RC.1 - 6 Implementierungen, die interoperabel arbeiten.
1.0.0 - Die erste Version wird veröffentlicht, sobald 12 funktionierende Implementierungen verfügbar sind.
Aktuelle Implementierungen
Pakete, die derzeit Geoparquet implementieren
- Geopandas (Python)
- Sfarrow (R)
- GDAL/OGR (C++, Wrapper für viele Sprachen wie Python)
- GeoParquet.jl (Julia)
- Geopandas Beispielcode (Python)
Lassen Sie uns einige Points of Interest-Daten aus Kalifornien analysieren (heruntergeladen als Shape-Dateien geofabrik).
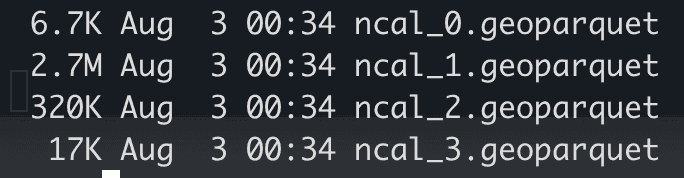
Wie Sie auf dem Bildschirm sehen können, haben die Shape-Dateien, die Nordkalifornien repräsentieren, eine Gesamtgröße von etwa 13 MB. Wenn die Daten in die Geopandas geladen werden, enthält der Datenrahmen 82425 Datensätze und 5 Spalten. 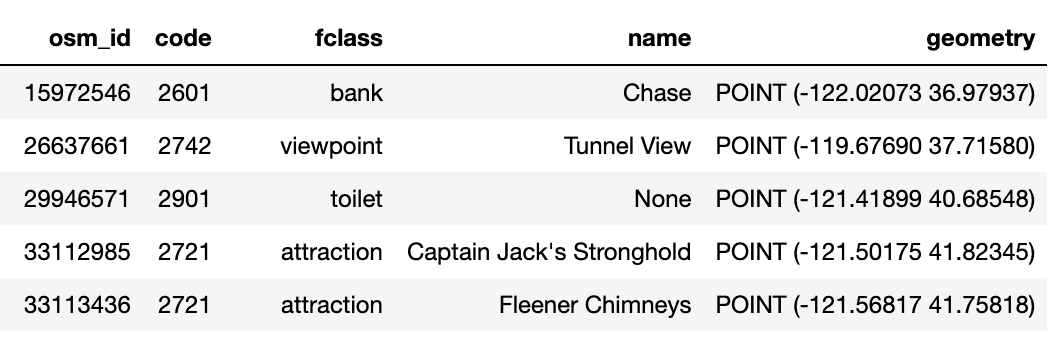
Lassen Sie uns die Daten direkt, ohne Änderungen, im Geoparquet-Datenformat als eine Datei speichern. Dazu können wir geopandas Implementierung von geoparquet ( v0.4 zum Zeitpunkt der Erstellung dieses Blogs) verwenden.
Zum Speichern in Geoparquet benötigen wir eine Zeile Code (unter der Annahme, dass unser Datensatz gdf heißt)
gdf.to_parquet(
"ncal_points.geoparquet"
)
Wir haben die Größe der Datei bereits auf 2,7 MB reduziert. Außerdem ist die Lesezeit schneller, und Sie können ganz einfach nur die Spalten auswählen, die Sie analysieren möchten.
Jetzt können wir uns die Metadaten der Datei ansehen. 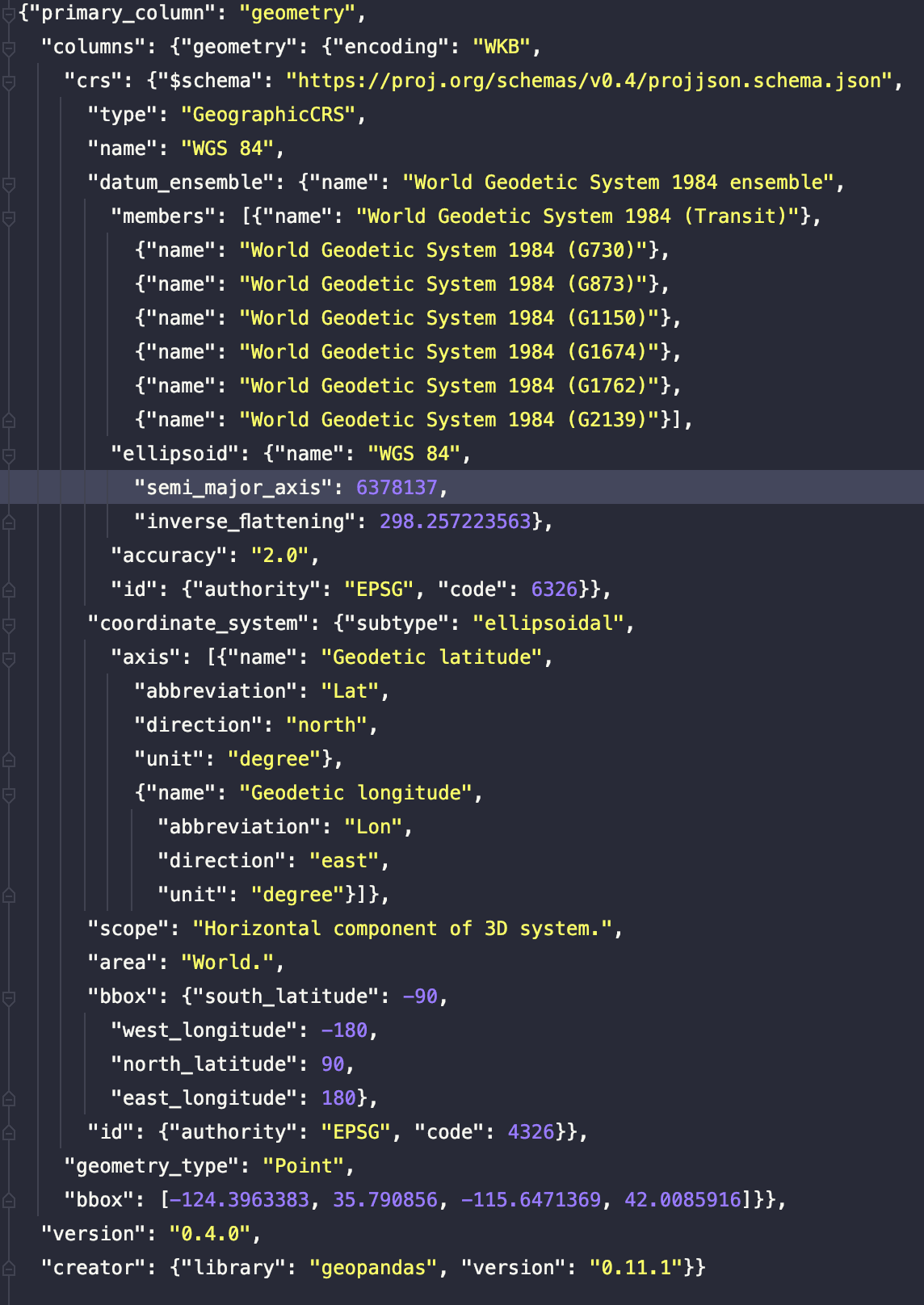
Wir können Informationen über die primäre Geometriespalte, ihre Crs, den Geometrietyp und die bbox sehen. Aus der Sicht einer Abfrage ist das Feld bbox sehr wichtig, da wir so ganz einfach nur die Parkettdateien auswählen können, die wir für unsere räumlichen Operationen wie z.B. die räumliche Verknüpfung benötigen.
Lassen Sie uns nun den Bereich in kleinere Rechtecke aufteilen und darauf basierend Parkettdateien erstellen.
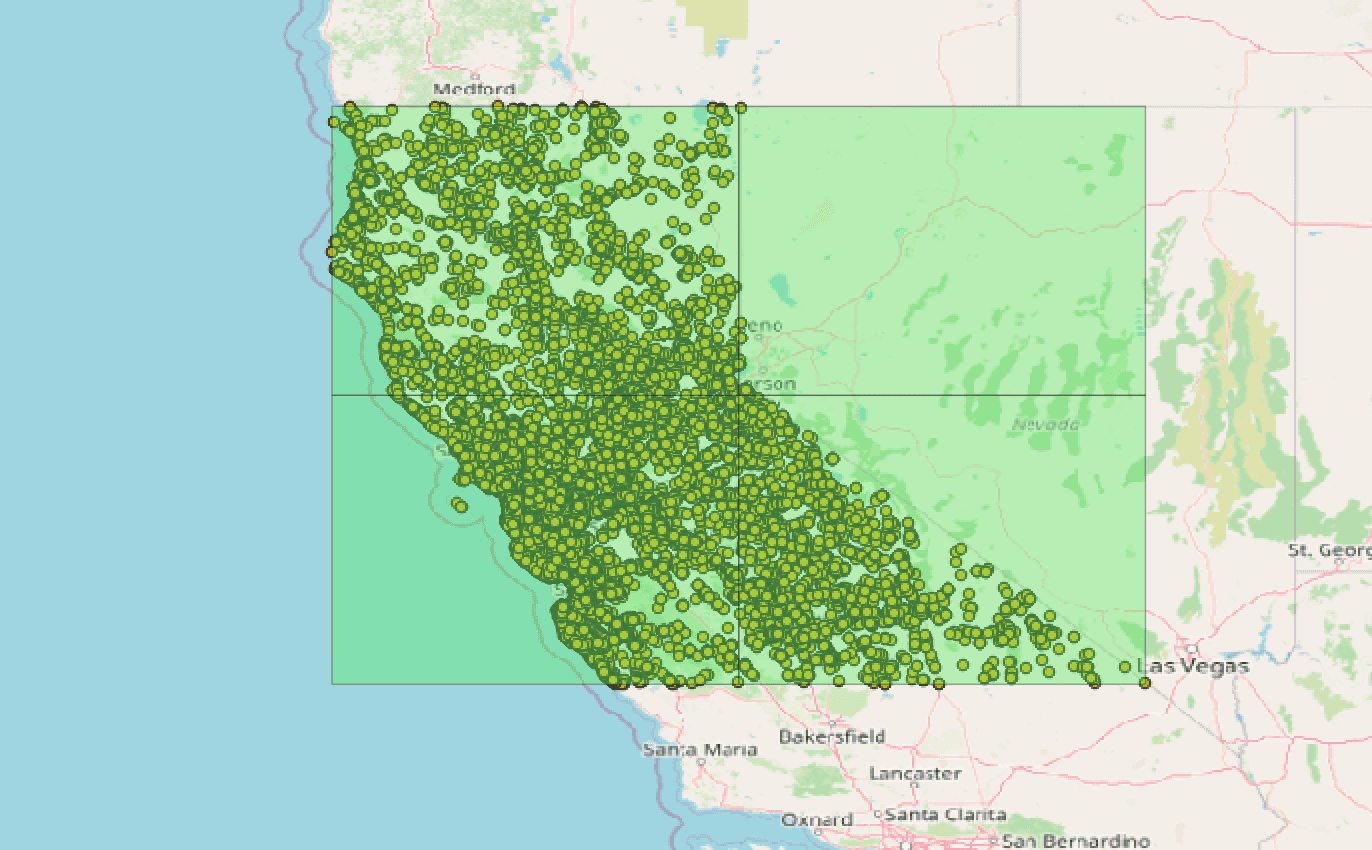
Die Zieldateigrößen sehen wie unten abgebildet aus. Wir können auch andere Datenaufteilungen in Betracht ziehen, um die Daten gleichmäßig zu verteilen, aber für die Zwecke dieses Blogs wollen wir es einfach halten. 
Eine Partition ist völlig leer, aber für die anderen 3 sieht die bbox wie folgt aus:
'bbox': [-123.67493, 35.790856, -120.0241473, 38.8988234]
'bbox': [-124.3963383, 38.8997457, -120.0221298, 42.0085916]
'bbox': [-120.0214167, 38.9019867, -119.9051073, 41.99494]
Die Aufteilung der Daten in kleinere Dateien ermöglicht Techniken wie das Überspringen von Daten, was die Abfrageleistung enorm verbessern kann. Außerdem sollen im Geoparquet-Format Indizes implementiert werden, die den Zeitaufwand für die Analyse von Geodaten im großen Maßstab drastisch reduzieren können.
Ist Geoparquet die Zukunft der Geodatenverarbeitung im großen Maßstab?
Die Geodaten-Community benötigt ein einheitliches Datenformat für die Speicherung und Verarbeitung großer Geodaten-Workloads. Derzeit kämpfen viele Dateningenieure mit der systemübergreifenden Integration von Geodaten. Oft werden wkt- und wkb-Spalten als austauschbare Verarbeitungseinheiten zwischen Systemen behandelt, können aber in einigen Fällen von anderen Systemen nicht verarbeitet werden (z.B. Redshift). Viele Geodaten werden nicht optimal verarbeitet, weil es in den gängigen Big Data-Formaten wie Parquet und Orc keine Unterstützung für Geodaten gibt. Es ist üblich, dass die Daten geladen und dann in einem bestimmten Umfang gefiltert werden, um räumliche Verknüpfungen durchzuführen, was kein optimaler Ansatz ist. Mit Geoparquet lässt sich durch die effiziente Speicherung großer Geodaten viel Rechenleistung und Datenspeicher einsparen. Viele Frameworks optimieren das Laden von Daten (Überspringen, Filtern, Indizieren), um Geodatenabfragen noch schneller durchzuführen. Es gibt noch viel zu tun, um das Geoparquet-Format für die Community akzeptabel zu machen, damit es weit verbreitet und produktionsreif ist, aber das ist genau das, was die Geodatenverarbeitung im großen Maßstab braucht.
Verfasst von
Paweł Tokaj
Unsere Ideen
Weitere Blogs




Contact