Zu Beginn des Jahres 2025 waren viele Datenexperten - auch wir - noch dabei herauszufinden, wie Agenten und LLMs in reale Projekte passen. LinkedIn war voll von Beiträgen, die das Potenzial neuer agentenbasierter Arbeitsabläufe aufzeigten und den Anschein erweckten, dass Probleme leicht gelöst werden könnten, mit der Implikation, dass einfache Eingabeaufforderungen und Arbeitsabläufe einen Mitarbeiter oder sogar eine ganze Abteilung automatisieren könnten. Nachdem wir im vergangenen Jahr an der Entwicklung und Bereitstellung von Agenten für die Produktion gearbeitet haben, sehen wir jetzt, wie naiv diese Vorstellung war.
Tatsache ist, dass Agenten ein enormes Potenzial aufweisen, aber für einige Aufgaben und Geschäftsprobleme müssen sie angepasst und sorgfältig konzipiert werden, um ihre Versprechen zu erfüllen. Es gibt einige harte Lektionen, die wir lernen müssen. Wir haben auf dem Weg dorthin eine Menge Fehler gemacht, und deshalb haben wir beschlossen, diese Lektionen mit Ihnen zu teilen.
Wir haben festgestellt, dass Probleme nicht schon bei der Entwicklung Ihres ersten einfachen Agenten auftreten. Sie tauchen auf, wenn Ihre Arbeitsabläufe immer komplexer werden: wenn Sie mehrere Agenten miteinander verketten, wenn Tools große Datenmengen zurückgeben, wenn sich Gespräche über viele Runden erstrecken. Die Muster, die wir hier vorstellen, sind keine neuen Erfindungen, sondern praktische Lösungen, die wir bei der Skalierung unserer Produktionssysteme (manchmal schmerzhaft) entdeckt haben.
Ganz gleich, ob Sie gerade erst mit Agenten beginnen oder bestehende Implementierungen verbessern möchten, Sie finden hier praktische Ratschläge, was Sie nicht tun sollten und wie Sie sowohl Ihre Entwicklererfahrung als auch Ihre Anwendung verbessern können. Zu diesen Tipps gehören die Verbesserung Ihrer Agentenarchitektur, das Schreiben besserer Tools und das Bewusstsein, wie wichtig es ist, Tracing und Evaluierung von Anfang an in das Projekt zu implementieren.
Was ist ein KI-Agent?
Im Kern ist ein KI-Agent ein LLM, der mit Tools ausgestattet ist, die es ihm ermöglichen, komplexe, mehrstufige Aufgaben zu erledigen. Im Gegensatz zu einem einfachen Chatbot, der nur Text erzeugt, kann ein Agent mit der Außenwelt interagieren, indem er Tools verwendet, um Datenbanken abzufragen, das Internet zu durchsuchen, E-Mails zu versenden oder APIs aufzurufen.
Der grundlegende Ablauf ist einfach: Ein Benutzer gibt eine Eingabeaufforderung ein, der Agent entscheidet, welche Tools verwendet werden sollen, führt sie aus, verarbeitet die Ergebnisse und arbeitet entweder weiter, indem er weitere Tools aufruft, oder gibt eine endgültige Antwort zurück. Diese Schleife wird fortgesetzt, bis die Aufgabe abgeschlossen ist. Das folgende Diagramm veranschaulicht einen Arbeitsablauf mit nur einem Agenten.
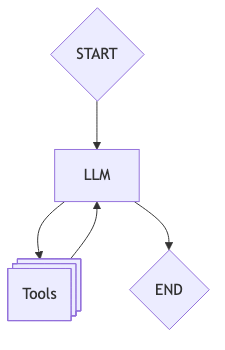
Beispiele für Tools sind Websuchfunktionen, API-Aufrufe und Datenbankinteraktionen. Dies sind die Möglichkeiten, mit denen der LLM mit externen Systemen interagieren kann. Auf der Grundlage der bereitgestellten Ergebnisse entscheidet er über die nächsten Schritte, indem er entweder ein anderes Tool (oder dasselbe mit anderen Parametern) aufruft oder die Schleife durch Rückgabe des Ergebnisses an den Benutzer beendet.
Das Problem: Kontextfenster-Einschränkungen
Das Konzept eines Agenten ist einfach: alles, was man braucht, ist ein LLM und einige Tools. Mit Frameworks wie LangGraph und Pydantic AI können Sie innerhalb weniger Minuten einen Agenten definieren. Es scheint so einfach zu sein. Was kann schon schief gehen?
Das erste große Problem, auf das wir stießen, war das Kontextfenster. Unsere Agenten, die Zugang zu Web-Suchwerkzeugen hatten, fanden und extrahierten Informationen aus riesigen Webseiten und füllten damit das Kontextfenster. Die Benutzer sahen dann nichtssagende Fehlermeldungen, und wenn das passiert, haben Sie ein Problem.
Wie sich Kontext anhäuft
Jeder LLM hat ein Kontextfenster, d.h. die maximale Menge an Informationen, die er auf einmal berücksichtigen kann. Moderne Modelle rühmen sich mit beeindruckenden Fenstern von 200k+ Token bis hin zu 2M Token, aber hier ist der Haken: Der Kontext füllt sich schnell und nicht alles erhält die gleiche Aufmerksamkeit.
Mit jeder Interaktion wächst Ihr Kontext. Er umfasst die Systemaufforderung, die Anfrage des Benutzers, die Antwort des Agenten, alle Tooldefinitionen, Toolaufrufe und Toolergebnisse. In einer Konversation mit mehreren Gesprächsrunden wird der Kontext auch durch frühere Dialoge beeinflusst. Was als einfache Eingabeaufforderung beginnt, kann sich schnell zu einem massiven Kontext auswachsen, der an die Grenzen des Modells stößt.

Aber selbst wenn Ihr Kontext technisch gesehen in dieses Fenster passt, gibt es ein tieferes Problem: LLMs kümmern sich nicht gleichermaßen um alle Teile eines großen Kontextes. Es ist fast so, als würden Sie einen Kollegen bitten, ein Buch zu lesen und ihn dann nach einem winzigen Detail auf Seite 121 fragen. Sie werden sich wahrscheinlich nicht erinnern. Wir haben das am eigenen Leib erfahren: Ein Agent, der Informationen über die Verfügbarkeit eines Produkts in Mexiko finden sollte, antwortete, nachdem er Tausende von Seiten im Internet durchforstet hatte, mit einem Gedicht auf Spanisch. Der Agent hatte sein ursprüngliches Ziel vergessen, verloren im Lärm des angesammelten Kontexts.
Der Hauptunterschied zwischen einem einfachen LLM-Aufruf und einem Agenten besteht darin, dass Agenten per Definition über einen Argumentationsschritt verfügen, der möglicherweise beschließt, ein anderes Tool aufzurufen, weil die Aufgabe noch nicht abgeschlossen ist. Daher kann eine Kombination aus schlechtem Werkzeugdesign (das zu einem erheblichen Backtracking zum LLM führt) und unzureichender Kontextverwaltung dazu führen, dass Sie die Kontextgrenzen überschreiten, was dazu führt, dass der LLM einen Fehler zurückgibt (oder noch schlimmer: überhaupt nichts zurückgibt).

Eine einfache Möglichkeit, mit der Einschränkung des Kontextfensters umzugehen, besteht darin, den Nachrichtenverlauf zu kürzen. Bei diesem Ansatz löschen oder filtern wir einfach Nachrichten, die für die Aufgabe nicht relevant sein könnten. Wenn der Agent beispielsweise mit Benutzern in einer Chat-Struktur interagiert, können wir alte Nachrichten herausfiltern und die neuesten Nachrichten behalten. Die Einschränkung besteht darin, dass der Agent möglicherweise den relevanten Kontext für die aktuelle Aufgabe verliert. Daher brauchen wir für komplexere Arbeitsabläufe einen intelligenteren Ansatz.
Strukturierte Ausgaben
Eine robustere Lösung, die wir vorschlagen, ist die bessere Verwaltung der Ergebnisse Ihres Tools durch die Bereitstellung strukturierter Ausgabeschemata. Dies hat sich in mehrfacher Hinsicht als vorteilhaft erwiesen:
- Sie können festlegen, welche Felder und Informationen Sie speziell aus Ihrem Toolaufruf extrahieren möchten.
- Sie können direkt auf das Feld verweisen, das Sie an Ihren nächsten Agenten oder Kontextverlauf weitergeben möchten. Wenn zum Beispiel nur der Preis relevant ist, können Sie dieses Feld einfach aus der bereitgestellten strukturierten Antwort auswählen.
- Sie reduzieren den Kontext des Hauptagenten drastisch - in unseren Experimenten reduzierten strukturierte Ausgaben die an den Hauptagenten zurückgegebenen Daten um 90-98% im Vergleich zu rohen Webinhalten. Beachten Sie, dass der zwischengeschaltete LLM immer noch den gesamten Inhalt verarbeitet, so dass die Gesamtnutzung von Token im System nicht unbedingt reduziert wird. Die tatsächlichen Vorteile sind jedoch beträchtlich: Der Hauptagent kann mehr Tool-Aufrufe tätigen, ohne an Kontextgrenzen zu stoßen, seine Aufmerksamkeit bleibt auf relevante Informationen gerichtet (kleinerer Kontext bedeutet bessere Schlussfolgerungen) und nachfolgende Aufrufe in der Schleife des Agenten sind billiger, da sie einen kleineren Kontext tragen.
- Bei den nachfolgenden Aufgaben verbessern Sie die Fähigkeit des Agenten zum logischen Denken, indem Sie ihm gezielte, genaue Informationen anstelle von verrauschten Rohdaten liefern.
- Vielleicht unerwartet zwingt Sie die Definition von Schemata dazu, mit den Beteiligten darüber zu sprechen, welche Daten wirklich wichtig sind. Diese Anforderung - im Voraus zu wissen, welche Felder zu extrahieren sind - mag wie eine Einschränkung erscheinen, aber sie wird zu einem Vorteil: Sie macht Ihre Agenten berechenbarer und gibt Ihnen die ausdrückliche Kontrolle darüber, was durch Ihr System fließt.

Das folgende Beispiel zeigt eine Klasse, die nur die relevanten Bitcoin-Kursinformationen mithilfe eines Pydantic-Modells erfasst:

Dann betten wir einen LLM direkt in das Tool ein. Bei jedem Aufruf der Websuche extrahiert und strukturiert dieser eingebettete LLM die relevanten Informationen, bevor er die Ergebnisse an den Hauptagenten zurückgibt:
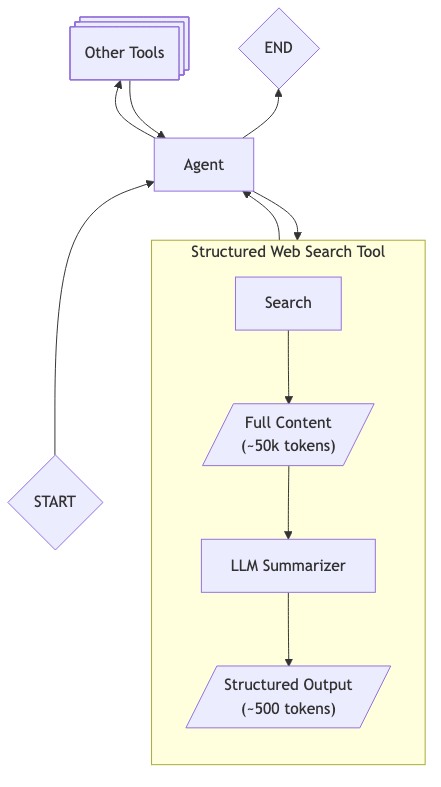
Dieser Ansatz ermöglicht es dem Agenten, in einem besseren Kontext zu entscheiden, ob er die Websuche fortsetzen soll, um Informationen zu ergänzen, oder ob er sie einfach beenden und eine Antwort an den Benutzer zurückschicken soll.
Beachten Sie, wie sich diese Extraktion für jeden einzelnen Tool-Aufruf davon unterscheidet, dass wir die Nachrichtenhistorie nur beschneiden, wenn die Kontextgrenzen erreicht sind. Indem wir jedes Tool-Ergebnis einzeln verarbeiten, optimieren wir die Genauigkeit und sorgen dafür, dass sich der LLM auf die Extraktion relevanter Informationen aus jeweils einer Quelle konzentriert.
Es gibt einen Nachteil: Dieser Ansatz erhöht die Latenz, da jeder Toolaufruf nun einen zusätzlichen LLM-Aufruf zur Strukturierung erfordert. Sie können dies jedoch abmildern, indem Sie Toolaufrufe nach Möglichkeit parallelisieren. Noch wichtiger ist jedoch, dass die Alternative - das Überschreiten von Kontextgrenzen oder der Verlust des Überblicks über die Ziele der Agenten - für die Benutzererfahrung wesentlich schlechter ist. Wir hielten die Kosten für die Latenz für akzeptabel, wenn man den Gewinn an Zuverlässigkeit und die Möglichkeit bedenkt, komplexe, mehrstufige Arbeitsabläufe zu bewältigen, die andernfalls fehlschlagen würden.
Strukturierte Ausgaben sind kein Allheilmittel, und das Muster der Verwendung eines LLM zur Strukturierung von Toolergebnissen ist nicht neu. Aber die systematische Anwendung auf Multi-Agenten-Workflows hat sich für uns als äußerst effektiv erwiesen: Der Kontext des Hauptagenten bleibt schlank und ermöglicht mehr Tool-Aufrufe, bessere Schlussfolgerungen und eine explizite Kontrolle darüber, welche Daten durch Ihr System fließen.
Beachten Sie, dass strukturierte Ausgaben für sich genommen keine vollständige Lösung darstellen. Der Kontext kann immer noch über viele Runden hinweg ins Unendliche wachsen, so dass das Verfolgen von Agentenaufrufen, das Überprüfen des Nachrichtenverlaufs und das Entfernen unnötiger Inhalte für Ihren Anwendungsfall immer noch relevant sein können.
Fazit
In diesem ersten Blog-Beitrag der Serie haben wir Muster vorgestellt, die wir bei der Skalierung unserer Agenten-Workflows für die Produktion gelernt haben. Das von uns beschriebene Problem - dass der Kontext außer Kontrolle gerät und die Agenten den Fokus verlieren - tritt nicht bei einfachen Demos auf. Es tritt auf, wenn Ihre Arbeitsabläufe komplexer werden, wenn Sie mehrere Agenten verketten und wenn Tools große Datenmengen zurückgeben.
Dieser Ansatz ist mit Abstrichen verbunden. Sie müssen Ihre Schemata im Voraus definieren, was voraussetzt, dass Sie wissen, welche Daten wichtig sind. Durch den zusätzlichen LLM-Aufruf pro Tool erhöht sich die Latenzzeit. Aber wir fanden, dass sich diese Kompromisse lohnen: Die Schemaanforderung zwang zu wertvollen Gesprächen mit den Beteiligten, und der Gewinn an Zuverlässigkeit übertraf bei weitem die Kosten für die Latenzzeit.
In der nächsten Iteration werden wir noch weiter darauf eingehen, wie diese Probleme gemildert werden können, indem wir eine Multi-Agenten-Architektur vorstellen, die sich darauf konzentriert, spezialisierte Sub-Agenten zu schaffen, die an einer Vielzahl von verschiedenen Aufgaben arbeiten.
Verfasst von
Victor De Oliveira
I appreciate feedback: https://www.linkedin.com/in/victor-de-oliveira-b0634449/




Contact