
In der dynamischen Welt des E-Commerce ist ein außergewöhnlicher Kundenservice keine Option mehr - er ist eine Notwendigkeit. Der Aufstieg des Online-Shoppings hat die Nachfrage nach personalisierten Einkaufserlebnissen und einem Rund-um-die-Uhr-Support verstärkt. An dieser Stelle kommen Chatbots ins Spiel, die von Large Language Models (LLMs) unterstützt werden. In diesem Blog-Beitrag erfahren Sie, wie Sie mit LLMs einen effizienten E-Commerce-Einkaufsassistenten erstellen, warum solche Chatbots unverzichtbar sind, wie sie entwickelt werden und was die Möglichkeiten und Herausforderungen dieser leistungsstarken Sprachmodelle sind.
Warum sollten Sie einen Chatbot brauchen?
Mit dem rasanten Wachstum des E-Commerce ist der Bedarf an Einkaufsassistenten für Kunden wichtiger denn je geworden. Kunden erwarten beim Online-Einkauf personalisierte Erlebnisse und Empfehlungen, und die Unternehmen müssen mit dieser Nachfrage Schritt halten, um wettbewerbsfähig zu bleiben.
Darüber hinaus bieten Chatbots eine 24/7-Verfügbarkeit und entlasten Ihre Mitarbeiter. Die Verfügbarkeit ermöglicht es Kunden, auch außerhalb der Geschäftszeiten Hilfe zu erhalten. Durch die Übernahme von Routine- und sich wiederholenden Aufgaben, wie z.B. die Beantwortung häufig gestellter Fragen, können Chatbots Ihre Mitarbeiter entlasten, damit sie sich auf anspruchsvollere Aufgaben konzentrieren können.
Insgesamt kann die Implementierung eines Chatbots E-Commerce-Shops dabei helfen, einen besseren Kundenservice zu bieten, Abläufe zu rationalisieren und den Umsatz zu steigern.
Entstehung von großen Sprachmodellen
Die jüngsten Fortschritte im Bereich der Sprachmodellierung, insbesondere das Aufkommen großer Sprachmodelle, haben ganz neue Möglichkeiten in vielen verschiedenen Bereichen eröffnet. Chatbots, die natürliche Sprache verstehen und Kundenfragen auf eine menschenähnliche Art und Weise beantworten können, verändern die Landschaft des Online-Shoppings und ermöglichen es Chatbots, maßgeschneiderte Produktempfehlungen zu geben und Kunden während des gesamten Kaufprozesses zu unterstützen.
Diese Fähigkeit hat LLMs bei der Entwicklung von Konversationsschnittstellen nützlich gemacht, die eine menschenähnliche Konversation imitieren können. Durch den Einsatz von Sprachmodellen können Einkaufsassistenten natürliche und nahtlose Unterhaltungen mit Kunden führen, was zu einem besseren Einkaufserlebnis führen kann.
Ein E-Commerce-Geschäft könnte zum Beispiel einen LLM-gesteuerten Chatbot verwenden, um Kunden bei der Suche nach Produkten zu helfen, indem er Fragen zu ihren Vorlieben stellt oder ähnliche Artikel vorschlägt. Der Chatbot könnte auch Fragen zu Produktdetails, Preisen und Versandinformationen beantworten. LLMs können auch als natürlichsprachliches Zusammenfassungstool dienen, das auf einem Empfehlungssystem aufbaut, was die Kundenzufriedenheit erhöhen und den Umsatz steigern kann.
Insgesamt haben LLMs es ermöglicht, ausgefeiltere und intelligentere Einkaufsassistenten zu entwickeln, die den Kunden ein natürlicheres und persönlicheres Erlebnis bieten können.
Wichtige Überlegungen für einen Chatbot
Beim Aufbau eines Kundeneinkaufsassistenten mit LLMs gibt es mehrere wichtige Überlegungen, die berücksichtigt werden müssen, einschließlich der potenziellen Herausforderungen und Einschränkungen bei der Verwendung von LLMs.
Eine der größten Herausforderungen bei der Verwendung von LLMs ist, dass sie Halluzinationen hervorrufen können, d.h. Antworten, die zwar technisch korrekt, aber kontextuell nicht angemessen sind. Ein Beispiel für eine Halluzination im Zusammenhang mit GPT-3.5 ist die Frage nach Ereignissen oder Informationen, die nach dem Stichtag der Trainingsdaten im September 2021 eingetreten sind. Obwohl GPT-3.5 keinen Zugang zu aktuellen Informationen hat, kann es sein, dass er trotzdem versucht, Antworten zu generieren. Dies kann zu einer frustrierenden Benutzererfahrung führen.
Eine weitere Überlegung ist LLMs Stochastik. LLMs haben zwar großes Potenzial bei der Generierung von menschenähnlichem Text gezeigt, aber die Inkonsistenz bei der Reproduktion der Ergebnisse wirft weitere Bedenken hinsichtlich der Zuverlässigkeit der Ausgaben auf. Es ist schwierig, zu garantieren, dass dieselbe Eingabe stets dieselbe Ausgabe ergibt, was sich auf die Vertrauenswürdigkeit und Zuverlässigkeit von LLM-basierten Anwendungen auswirken kann.
Der Einsatz von Modellen des maschinellen Lernens (ML), einschließlich LLMs, erfordert ebenfalls sorgfältige Überlegungen. Es ist wichtig, sicherzustellen, dass das Modell auf sichere und konforme Weise eingesetzt wird, um sensible Kundeninformationen zu schützen und den Datenschutz zu wahren. Aus diesem Grund empfehle ich Ihnen, diesen Artikel darüber zu lesen, wie Sie Ihr erstes privates Large Language Model (LLM) auf der Google Cloud Platform betreiben.
LLM-basierter Entwicklungszyklus
Die Entwicklung von LLM-basierten Lösungen wird sich deutlich von Standard-ML-Problemen unterscheiden. Wenn Sie LLMs in Ihren Produkten verwenden möchten, ist es vielleicht besser, zunächst eine Machbarkeitsstudie an einigen ausgewählten Beispielen durchzuführen, um zu verstehen, ob das Projekt realisierbar ist. Es empfiehlt sich, mit kostenpflichtigen APIs wie OpenAI, Google oder Cohere zu beginnen, um von deren besten vortrainierten Modellen und gut dokumentierten APIs zu profitieren.
Sobald Sie bestätigt haben, dass Ihr Projekt durchführbar ist, können Sie versuchen, entweder auf Open-Source-Modelle oder kostengünstigere kostenpflichtige APIs umzusteigen. Indem Sie Ihre Infrastruktur für LLMs selbst verwalten, können Sie die Kosten senken und den Datenschutz gewährleisten. Außerdem wird Ihre Lösung nicht von externen APIs abhängig sein. Beachten Sie jedoch, dass Open-Source-Modelle möglicherweise mehr Anpassungen (z.B. Feinabstimmung) erfordern und nicht so leistungsfähig sind wie kostenpflichtige Lösungen.
Aber woher wissen Sie, ob Sie Fortschritte machen? LLMs sind bekanntermaßen schwer zu bewerten, und es kann schwierig sein, festzustellen, ob ein Sprachmodell besser ist als ein anderes. Es gibt zwar öffentliche Benchmarks, aber Sie sollten sich darüber im Klaren sein, dass diese Benchmarks nicht immer das geeignetste Maß für den Erfolg bei Ihrer speziellen Aufgabe sind. In einigen Fällen können hochmoderne Modelle außerhalb der Domäne schlechter abschneiden als Modelle, die speziell mit Domänenwissen trainiert wurden. Sich ausschließlich auf öffentliche Benchmarks zu verlassen, liefert nicht immer eine genaue Einschätzung der Fähigkeiten eines Sprachmodells. Um mit LLMs wirkliche Fortschritte zu erzielen, ist eine
Wenn Sie Ihre Lösungen in Produktion geben, müssen Sie unbedingt die Randfälle überwachen und gute Leitplanken einrichten, um sicherzustellen, dass das LLM wie vorgesehen funktioniert und keine unangemessenen Reaktionen auslöst. Es gibt auch erhebliche Vorteile, wenn Sie einen Human-in-the-Loop-Ansatz einbeziehen. Durch die Überwachung durch den Menschen können Sie sicherstellen, dass die Sprachmodelle wie erwartet funktionieren, und in Fällen, in denen dies nicht der Fall ist, kann der Mensch eingreifen und die notwendigen Korrekturen vornehmen. Darüber hinaus können Menschen Rückmeldungen geben, die für die Verbesserung der Leistung Ihres Systems in nachfolgenden Iterationen nützlich sein können. Dieser iterative Prozess, bei dem Menschen und LLMs zusammenarbeiten, kann zu robusteren und effektiveren Lösungen führen.
Wie können Sie Ihre Prompts verbessern?
Ok, Sie haben also beschlossen, es mit LLMs zu versuchen und fragen sich, wie Sie Ihre Prompts verbessern können. Vielleicht haben Sie schon von neuen Stellen für Prompt-Ingenieure gehört, aber wie können Sie Ihre Prompts in der Zwischenzeit verbessern? Prompts sind sehr experimentell und manchmal kann das Hinzufügen eines einzigen Satzes die Ergebnisse völlig verändern.
Es gibt jedoch viele Techniken, die zur Verbesserung der LLM-Antworten beitragen können. Der erste Ansatz ist Soufflieren mit wenigen Schuss, bei dem Sie dem Modell in einer Eingabeaufforderung einige Beispiele für die Aufgabe vorgeben. Dadurch ist das Sprachmodell in der Lage, sich an die zugrunde liegenden Muster anzupassen und besser auf neue Beispiele zu verallgemeinern. Nehmen wir an, Sie versuchen, eine Stimmungsanalyse für Kundenrezensionen durchzuführen. Sie könnten Beispiele wie dieses anführen:
```
What is the sentiment of the following product review? Give your answer as a SINGLE WORD, either "POSITIVE" or "NEGATIVE".
Here are some examples:
Review: Love these headphones! Great sound quality and comfortable to wear.
Sentiment: POSITIVE
Review: Terrible product and customer service, don't waste your money.
Sentiment: NEGATIVE
Review: {{insert_review}}
Sentiment:
```Prompts mit wenigen Worten können die Leistung des Modells erheblich verbessern.
Eine allgemeine Faustregel lautet: Schreiben Sie klare und spezifische Anweisungen und bitten Sie um eine strukturierte Ausgabe, z. B. `JSON` oder `HTML`, die später leicht analysiert werden kann. Es gibt auch Tricks, mit denen sich die Eingabeaufforderung verbessern lässt, wie z.B. die Begrenzung der Ausgabe (z.B. "Verwenden Sie höchstens 2 Sätze") oder die Aufforderung an das Modell, sich auf die spezifischen Aspekte der Aufgabe zu konzentrieren (z.B. "Die Beschreibung ist für Einzelhändler bestimmt, sollte also technisch sein"). Wenn Sie mehr über effektive Prompting-Techniken erfahren möchten, empfehle ich Ihnen den Kurs von Andrew Ng, der umfassende Einblicke und Strategien zur Optimierung von Anweisungen bei der Arbeit mit großen Sprachmodellen bietet.
Wenn es um LLM-basierte Produktentwicklung geht, ist es wichtig, die probabilistische Natur dieser Modelle zu akzeptieren. Anders als bei der traditionellen Softwareentwicklung können Sie sich nicht mehr den Luxus leisten, genau zu wissen, welche Eingabe zu welcher Ausgabe führen wird. Daher ist es im Allgemeinen am besten, mit LLMs in Anwendungen zu beginnen, bei denen es Ihrem Produkt nicht schadet, wenn Sie nicht immer richtig liegen. Diese Anwendungsfälle sind ein guter Ausgangspunkt, um die Möglichkeiten von LLMs zu erkunden und gleichzeitig das Risiko negativer Auswirkungen auf Ihr Unternehmen oder Ihre Kunden zu minimieren. Indem Sie die probabilistische Natur von LLMs annehmen und mit diesen sichereren Anwendungsfällen beginnen, können Sie besser verstehen, wie Sie diese Modelle in ihrem vollen Umfang nutzen können.
Bringen wir unserem LLM ein paar Werkzeuge bei
Nachdem wir nun ein solides Verständnis der Grundlagen erworben haben, ist es an der Zeit, dieses Wissen zu nutzen, um einen leistungsstarken Chatbot-Assistenten zu konstruieren.
Um Genauigkeit und Zuverlässigkeit zu gewährleisten, ist es ratsam, den Chatbot mit der Fähigkeit auszustatten, auf eine externe Datenbank für Informationen zuzugreifen, anstatt sich nur auf sein internes Wissen zu verlassen. Hier kommt das
Das ReAct-Framework ermöglicht es großen Sprachmodellen (LLMs),
Wie funktioniert ReAct also? Lassen Sie uns das anhand eines Beispiels erläutern. Es ist allgemein bekannt, dass LLMs oft Schwierigkeiten mit mathematischen Berechnungen haben. Bringen wir also dem LLM mit Hilfe von ReAct bei, wie man einen Taschenrechner benutzt.
```python
react_prompt = """
You run in a loop of Thought, Action, PAUSE, Observation.
At the end of the loop, you output an Answer.
Use Thought to describe your thoughts about the question you have been asked. Use Action to run one of the available actions - then return PAUSE.
Observation will be the result of running those actions.
Your available actions are:
calculate:
e.g. calculate: 4 * 7 / 3 - runs a calculation and returns the number
Example session:
Question: What is 5 * 2 / 5 ^ 2
Thought: I should use the calculator for calculation.
Action: calculate: 5 * 2 / 5 ^ 2
PAUSE
Observation: 5 * 2 / 5 ^ 2 = 0.4
Answer: The output of the calculation is 0.4
"""
```Dies ist ein einfaches Beispiel, das als Demonstration des ReAct-Musters dient. Sie können eine Aktion mit regulären Ausdrücken erfassen (`re.compile('^Action: (\w+): (.*)$')`). Die Frage stellt die Anfrage des Benutzers dar, während Thought und Action dem internen Denkprozess des LLM entsprechen. Die Beobachtung ist das Ergebnis der Ausführung des bereitgestellten Codes. Die Antwort schließlich stellt die endgültige Antwort dar, die der LLM erzeugt.
Durch die Verwendung dieses Musters kann der Chatbot dynamisch mit verschiedenen Tools arbeiten und so seine Fähigkeiten über seine ursprüngliche Wissensbasis hinaus erweitern.
Erforschung der Werkzeuge eines Chatbot-Assistenten
Welche Tools kann ein Chatbot-Assistent also nützlich finden? Nehmen wir zum Beispiel einen Chatbot, der ein Online-Einkaufserlebnis verbessern soll. Die Kunden würden von personalisierten Empfehlungen profitieren, die auf der Grundlage ihrer Einkaufshistorie erstellt werden, was wir durch die Integration eines Empfehlungssystems in unseren Chatbot ermöglichen können. Um Kunden bei der Entdeckung neuer Artikel zu helfen, könnte unser Chatbot eine robuste semantische Suchfunktion einsetzen, um die interne Datenbank nach ansprechenden Produkten zu durchsuchen. Außerdem erfordern viele Kaufentscheidungen eine differenzierte Konversation - eine einzige Anfrage reicht oft nicht aus, um sich für das ideale Produkt zu entscheiden. Dies erfordert die Fähigkeit, Dialoge mit mehreren Gesprächspartnern zu führen, um detailliertere Präferenzen des Kunden zu ermitteln, bevor er maßgeschneiderte Empfehlungen erhält!
Hier ist ein Auszug aus der Eingabeaufforderung, die an das große Sprachmodell (LLM) gesendet wird:
```python
shopping_assistant_prompt = """
The commands to seek information are:
| Command | Arguments | Description |
| --- | --- | --- |
| semantic_search | text | Runs a semantic search query against a database to find particular articles |
| recommendation | text | Runs a personalized recommendation engine, and returns few articles |
| chat | text | Chats with a customer |
Use the `semantic_search` command when you know what you are searching for.
Use the `recommendation` command when you want a random recommendation.
Use the `chat` command to either ask customers about details of what they are interested in, present recommendations to a customer, or just chat with them in general.
Your response will be in JSON and will include a "Thought" + "Action" to retrieve data or recommend a product. When data has been retrieved, it will be included as an "Observation". You will continue generating thoughts and actions until you get to an answer, or conclude that you can't.
Please remember to only write about products that are provided to you.
When you recommend a specific product to a customer, include the Product_id in the JSON answer. If the product id is not known, leave that field empty.
Your JSON response should be formatted as follows: {"thought": Thought, "action": {"command": Command, "text": Text, "id": Product_id}}
"""
```Die hier beschriebenen Aktionen dienen unterschiedlichen Zwecken:
- `semantic_search` wird eingesetzt, wenn der Kunde bereits weiß, wonach er sucht.
- Der `recommendation` Befehl ist perfekt für die Momente, in denen Kunden einen spontanen Vorschlag wünschen.
- `chat` fördert die Interaktion mit Kunden, sei es durch das Einholen weiterer Informationen, das Vorstellen von Produktempfehlungen oder einfach nur durch ein zwangloses Gespräch.
Wir haben Markdown-Tabellen verwendet, um die verfügbaren Aktionen anzuzeigen, da große Sprachmodelle am besten mit gut formatierten Daten arbeiten. Indem wir ein JSON-Antwortformat erzwingen, können wir die Ausgabe leicht parsen und gleichzeitig eine nahtlose Interaktion mit nachgelagerten Anwendungen wie der Warenkorbfunktion oder der Anzeige von Produktbildern durch die Aufnahme von `product_id` in die Antwort sicherstellen.
Wie funktioniert das also in der Praxis?
So könnte ein typisches Gespräch mit einem Kunden aussehen: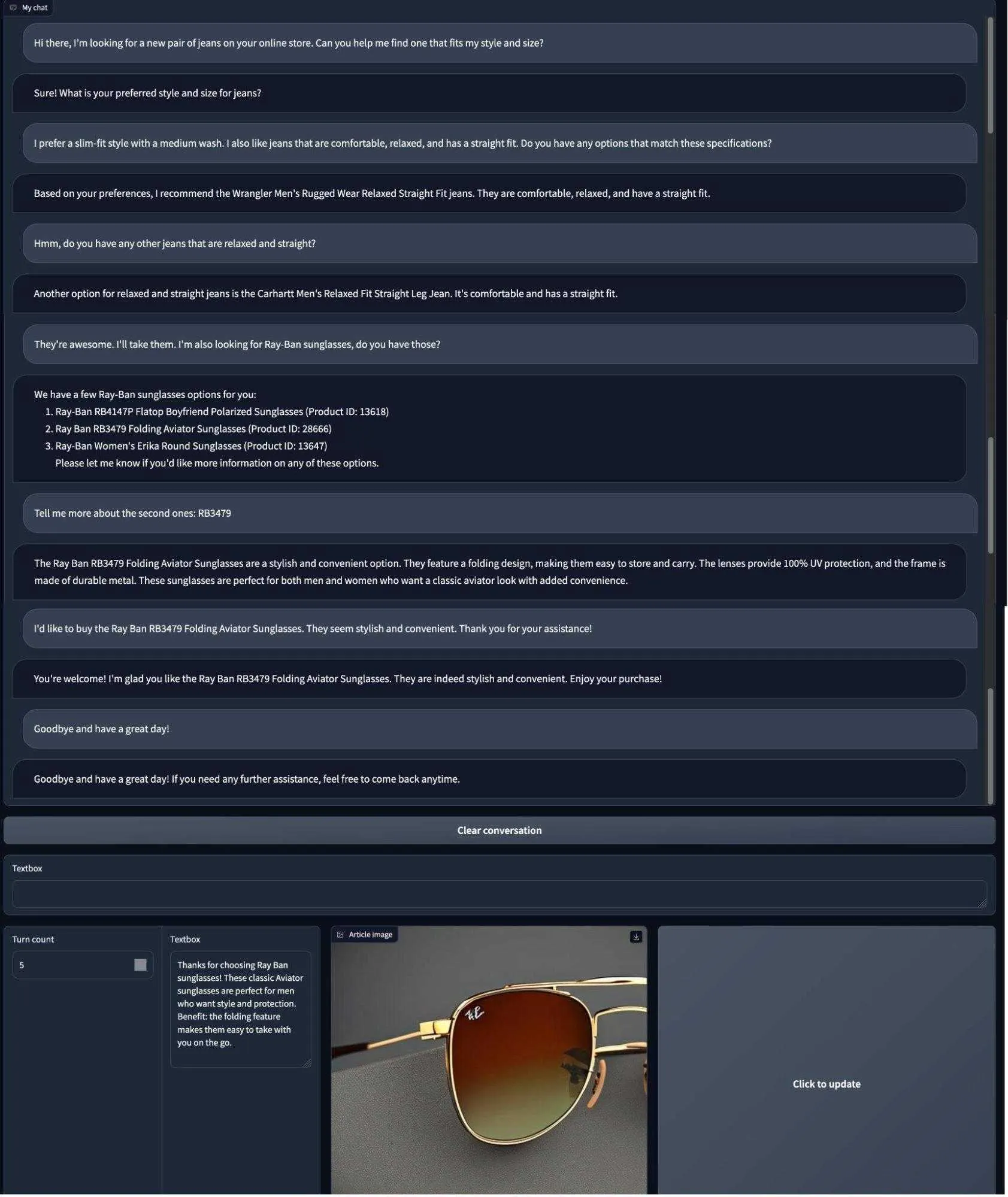
Unsere Demo verwendet ein gradio-FrontendEin Large Language Model (LLM) ist mit umfangreichen Werkzeugen ausgestattet, um Informationen über Produkte zu sammeln und so sicherzustellen, dass es genaue und hilfreiche Antworten geben kann. Wenn es um ein bestimmtes Produkt geht, kann das LLM ein JSON mit der product_id generieren, das Sie auf Ihrer Website zusammen mit den Metadaten des Artikels anzeigen können. Diese Integration verbessert das Kundenerlebnis und vereinfacht den Prozess der Bereitstellung relevanter Informationen.
So sieht die Interaktion zwischen einem Kunden und einem Assistenten unter der Haube aus:
Kunde: Sie sind großartig. Ich nehme sie mit. Ich bin auch auf der Suche nach einer Ray-Ban Sonnenbrille, haben Sie die auch?
LLM Kundenassistent:
{
"thought": "I should search the internal database against Ray-Ban sunglasses",
"action": {
"command": "semantic_search",
"text": "Ray-Ban sunglasses",
"id": ""
}
}Beobachtung:
`# relevant item metadata are presented here in a Markdown table as a string`
Kunde:
{
"thought": "Given items from Observation, I should present the Ray-Ban sunglasses options",
"action": {
"command": "chat",
"text": "We have a few Ray-Ban sunglasses options for you:
1. Ray-Ban RB4147P Flatop Boyfriend Polarized Sunglasses (Product ID: 13618)
2. Ray Ban RB3479 Folding Aviator Sunglasses (Product ID: 28666)
3. Ray-Ban Women's Erika Round Sunglasses (Product ID: 13647)
Please let me know if you'd like more information on any of these options.",
"id": ""
}
}Kunde:
Tell me more about the second ones: RB3479LLM Kundenassistent:
{
"thought": "I should provide more information about Ray Ban RB3479 Folding Aviator Sunglasses",
"action": {
"command": "chat",
"text": "The Ray Ban RB3479 Folding Aviator Sunglasses are a stylish and convenient option. They feature a folding design, making them easy to store and carry. The lenses provide 100% UV protection, and the frame is made of durable metal. These sunglasses are perfect for both men and women who want a classic aviator look with added convenience.",
"id": "28666"
}
}
Kunde:
` I'd like to buy the Ray Ban RB3479 Folding Aviator Sunglasses. They seem stylish and convenient. Thank you for your assistance!`LLM Chatbots: Bereit für die Hauptbühne?
Gegenwärtig gibt es noch einige Hindernisse, die die vollständige Integration dieser Chatbots in die Produktionsumgebung verhindern. Latenz, Zuverlässigkeit und prompte Injektionen sind die wichtigsten dieser Probleme. Das `ReAct`-Muster hat die Zuverlässigkeit deutlich verbessert, aber das Problem nicht vollständig beseitigt. Wenn die Funktionen des Chatbots erweitert werden (mehr Tools), ist ein leistungsfähigeres Modell erforderlich, um diese komplexen Aufgaben auszuführen - was aber wiederum zu einer noch höheren Latenz führt.
Um diese Hürden zu überwinden, erforschen wir die Feinabstimmung kleinerer Modelle für Chat-Interaktionen. Diese Richtung scheint ein vielversprechender Weg zu sein, und wir freuen uns darauf, die Feinabstimmung großer Open-Source-Sprachmodelle in unseren kommenden Advanced Analytics Labs Initiativen zu vertiefen.
Verfasst von
Michał Madej
Unsere Ideen
Weitere Blogs


KI als Kraftmultiplikator: Wie Unternehmen und ISVs mit weniger mehr erreichen...
Kiran Madhunapantula, COO


Contact