Blog
Hochverfügbarer Airflow-Cluster in Amazon AWS

Heutzutage ist es für Unternehmen, die sich mit Big Data beschäftigen, selbstverständlich, dass sie ihre Technologien aus einer Vielzahl von verfügbaren Lösungen zusammenstellen. Auch wenn die Bedürfnisse von Unternehmen zu Unternehmen unterschiedlich sind, gibt es ein wesentliches Element, das gleich bleibt: die Orchestrierung von Arbeitsabläufen und Datenverarbeitung. In diesem Artikel möchte ich Ihnen zwei Möglichkeiten vorstellen und beschreiben, wie Sie einen Airflow-Cluster mit Amazon AWS-Technologie einrichten können. Jeder Weg ist HA-orientiert, um eine maximale Zuverlässigkeit des Clusters zu gewährleisten.
Dieser Artikel erfordert grundlegende Kenntnisse der AWS-Services.
Was ist Apache Airflow?
Airflow wurde ursprünglich von AirBnB entwickelt, wurde aber später in ein Apache Incubator Projekt umgewandelt. Laut seiner Website ist Airflow eine "von der Community geschaffene Plattform zur programmatischen Erstellung, Planung und Überwachung von Arbeitsabläufen". Mit anderen Worten, es bietet eine Reihe von Funktionen zur Definition, Erstellung, Planung, Ausführung und Überwachung von Daten-Workflows. Das klingt ziemlich mächtig, nicht wahr? Heutzutage, in dieser von Big Data bestimmten Ära, findet Airflow weltweit immer mehr Beachtung. Natürlich ist die Big Data-Welt nicht die einzige Anwendung für diese Software. Mehrere IT-Unternehmen wie Slack, 9GAG oder Wallmart haben behauptet, dass sie Airflow in ihrem Technologie-Stack verwenden. Der Grund dafür ist seine Robustheit und seine Flexibilität durch die Verwendung von Python.
Stellen Sie sich eine einfache Pipeline vor, die Daten aus AWS S3 lädt, einen ephemeren EMR-Cluster hochfährt, die Daten mit Flink oder Spark verarbeitet, die erforderlichen Funktionen extrahiert und die Ergebnisse in einer Datenbank oder einem Data Warehouse speichert. In Airflow kann das alles als eine einzige Python-Datei eingerichtet werden. Airflow hilft Ihnen bei der Planung und Ausführung komplexer Pipelines und bietet eine einfache Möglichkeit, diese zu überwachen und zu pflegen. Dank der großen Community von Airflow und seiner Mitwirkenden ist es wirklich schwer, einen Dienst zu finden, mit dem Airflow nicht zusammenarbeiten könnte.
Kernkonzepte
Airflow hat einige Kernideen, die für das Verständnis der Orchestrierung der Pipelines entscheidend sind. In diesem Artikel möchte ich mich nur auf die Ideen konzentrieren, die für die Bereitstellung von Hochverfügbarkeit relevant sind.
DAG: Dies ist ein Akronym für einen gerichteten azyklischen Graphen. Eine Sammlung aller Aufgaben, die Sie ausführen möchten, organisiert in einer Weise, die ihre Beziehungen und Abhängigkeiten widerspiegelt. Ein DAG wird in einem Python-Skript definiert, das die Struktur des DAGs (Aufgaben und ihre Abhängigkeiten) als Code darstellt.
Aufgabe: Definiert eine Arbeitseinheit innerhalb einer DAG. Eine einzelne Aufgabe wird als einzelner Knoten im DAG-Graphen dargestellt. Sie wird ebenfalls in Python geschrieben und ist normalerweise Teil der DAG-Datei.
Operator: Ein Operator steht für eine einzelne, idealerweise idempotente Aufgabe. Operatoren bestimmen, was genau getan wird und welche Aktionen während der Ausführung einer Aufgabe durchgeführt werden.
Planer: Der Scheduler überwacht alle Tasks und alle DAGs und löst die Task-Instanzen aus, deren Abhängigkeiten erfüllt sind. Er ist so konzipiert, dass er als dauerhafter Dienst in einer Airflow-Produktionsumgebung läuft. Er ist das Gehirn aller von Airflow durchgeführten Aktionen. Der Scheduler verwendet den konfigurierten Executor, um Aufgaben auszuführen, die bereit sind.
Webserver: Eine Python-Flask-Webanwendung zur Verwaltung von DAGs: Pause/Unpause, Trigger, Änderung und Überwachung des Ausführungsstatus
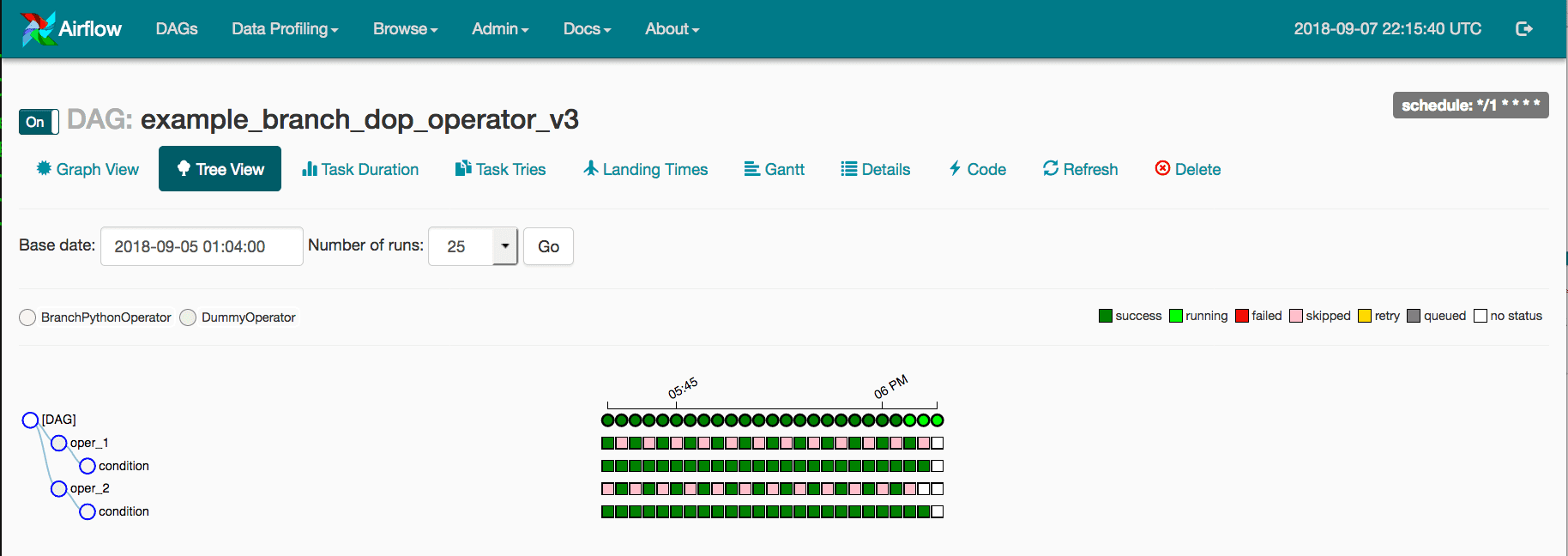 Eine Baumansicht einer DAG-Instanz (https://airflow.apache.org/docs/stable/ui.html)
Eine Baumansicht einer DAG-Instanz (https://airflow.apache.org/docs/stable/ui.html)
Executor: Executors sind der Mechanismus, mit dem Aufgabeninstanzen ausgeführt werden. In diesem Artikel werden wir uns auf den Celery Executor und den Kubernetes Executor konzentrieren.
Message Broker: Wird nur mit Celery Executor verwendet. Dabei handelt es sich in der Regel um einen RabbitMQ- oder Redis-Dienst, der es Celery ermöglicht, eine zuverlässige verteilte Nachrichtenwarteschlange zu erstellen. Wenn Celery Executor verwendet wird, konsumieren die Airflow-Arbeiter Aufgaben aus dieser Warteschlange und aktualisieren den Status der Aufgaben in der Results Backend-Datenbank.
Metadaten- und Ergebnis-Backend-Datenbanken: Die Metadaten-Datenbank ist ein Ort, an dem alle dag-bezogenen Informationen gespeichert werden: Läufe, Konfiguration, fehlgeschlagene Ausführungen, usw. Die Results Backend-Datenbank ist eine Metadaten-Datenbank für den Celery-Dienst. Sie speichert Informationen über Nachrichten, deren Status und Ausführungszeiten. Es können mehrere DB-Engines verwendet werden, z.B. MySQL oder PostgreSQL.
Wie können wir Airflow hochverfügbar machen?
Trotz der Tatsache, dass Airflow mehrere Möglichkeiten zur Konfiguration der verteilten DAG-Verarbeitung bietet, werden im gesamten Airflow-Projekt keine offiziellen Einzelheiten zu seiner HA diskutiert. Die Lösung kann jedoch ganz in Ihrer Nähe liegen. Wie wir alle wissen, ist Ihr Dienst so hoch verfügbar wie seine am wenigsten hoch verfügbare Komponente. Wir werden uns mit zwei Implementierungsmethoden beschäftigen, jedes Element ihrer Architektur beschreiben und Methoden vorstellen, um sie fehlertolerant zu halten.
Mit der verteilten Aufgaben-Warteschlange von Celery
Nach einer Analyse der Kernelemente, der möglichen Konfigurationen und der Lektüre mehrerer Blogbeiträge über produktionsreife Implementierungen stellte sich heraus, dass wir einen Celery Executor verwenden sollten.
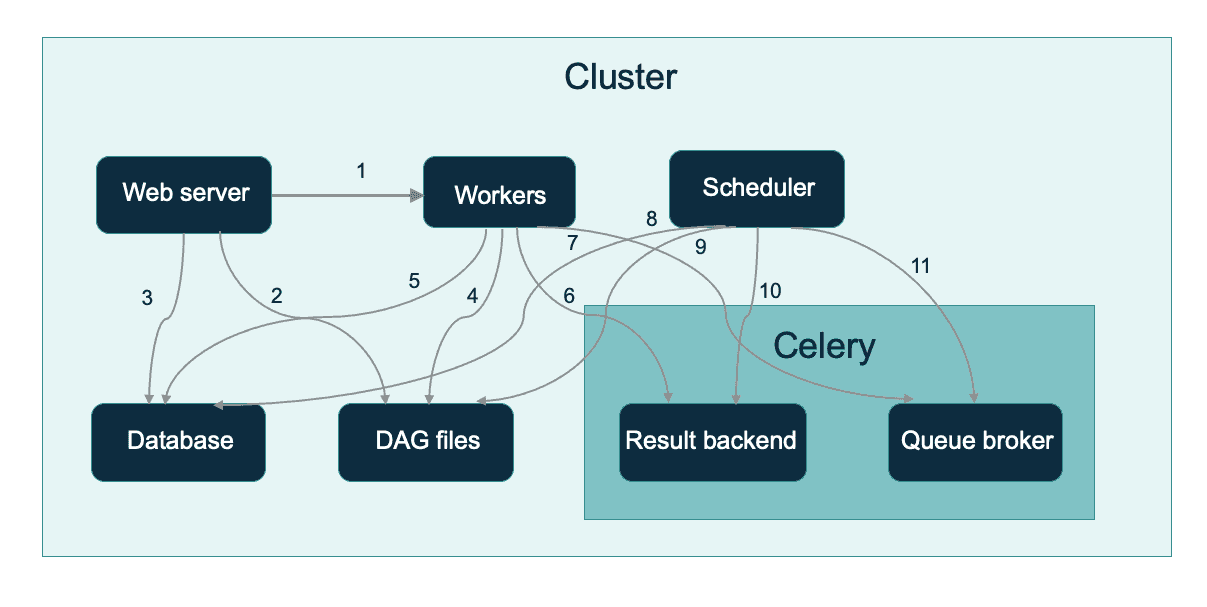 Airflow + Sellerie Architektur
Airflow + Sellerie Architektur
Nachdem wir dieses Diagramm zerlegt haben, haben wir die folgenden Komponenten:
- Workers - Führen Sie die zugewiesenen Aufgaben aus. Airflow Celery Worker konsumieren vom Celery's Queue Broker und führen den in den Nachrichten gespeicherten Befehl lokal aus. Ein Worker kann alles sein, was in der Lage ist, Python-Code auszuführen, aber jeder Worker muss Zugriff auf den Code der DAGs haben. Es gibt zwei Hauptansätze:
- Wenn Sie besondere Anforderungen an Ihre Pipeline haben, z. B. eine hohe CPU/RAM-Auslastung oder GPU-Computing-Aufgaben, empfiehlt es sich, Airflow-Worker als AWS EC2-Instanzen bereitzustellen. Die Instanzen können für jeden Worker einzeln oder als Auto Scaling-Gruppe bereitgestellt werden.
- Wenn nicht - verwenden Sie AWS Fargate. Seit Fargate in Version 1.4.0 verfügbar ist, ist es möglich, den Task-Instances ein gemeinsam genutztes EFS-Volume zuzuordnen, so dass die Anforderung des Codezugriffs leicht erfüllt werden kann. Task-Instances können auf die gleiche Weise wie EC2-Instances automatisch skaliert werden, sind jedoch in vordefinierten Größen erhältlich.
Es ist jedoch auch möglich, einen hybriden Ansatz zu verfolgen. Mit Celery Executor haben Sie die Möglichkeit, Warteschlangen innerhalb Ihrer verteilten Warteschlange zu definieren. Das bedeutet im Grunde, dass Sie mehrere Gruppen von Arbeitern zuweisen und aus mehreren verschiedenen Warteschlangen konsumieren können. Die DAG-Natur des Airflow ermöglicht es Ihnen, jede Aufgabe einer anderen Warteschlange zuzuordnen. Wenn Sie z.B. eine Pipeline mit umfangreichen GPU-Berechnungen haben und nicht möchten, dass die gesamte Pipeline auf diesem bestimmten Worker läuft, ist es möglich, Nicht-GPU-Aufgaben mit anderen Workern auszuführen (möglicherweise Fargate Task Instances oder kleinere/günstigere EC2-Instanzen). Die Aufgabenprotokolle können auf EBS-Platten oder EFS-Volumes (im Falle von Fargate) persistiert werden. In der AWS-Welt können Sie Airflow-Arbeiter jedoch so konfigurieren, dass sie Protokolle direkt in S3 schreiben.
- Scheduler - Verantwortlich für das Hinzufügen der erforderlichen Aufgaben zur Warteschlange. Leider wurde der Scheduler nicht für die parallele Ausführung mehrerer Instanzen konzipiert. Im Airflow-System mit Celery-Backend gibt es auch nur einen Produzenten für die RabbitMQ-Broker zu einer bestimmten Zeit. Nichtsdestotrotz ist der Scheduler bei hoher Verfügbarkeit kein Problempunkt. Selbst wenn er ausfällt, konsumieren die Worker weiterhin aus der Warteschlange, die Aufgaben werden ausgeführt und der Status wird in der Result Backend-Datenbank aktualisiert (solange es etwas zu konsumieren gibt). Andererseits ist dies ein guter Grund, das RabbitMQ/Redis-Backend von den Scheduler-Instanzen fernzuhalten. Wenn eine einzige Scheduler-Instanz immer noch ein Problem darstellt, gibt es Open-Source-Lösungen, um einen Failover-Controller einzurichten.
- Webserver- der HTTP-Server ermöglicht den Zugriff auf die Statusinformationen der DAG/Aufgaben. Er ist standardmäßig installiert und wird auf demselben Rechner wie der Scheduler gestartet. Die einzige Abhängigkeit besteht darin, dass der Webserver als Zugriff auf die Metadaten-Datenbank für mehr als eine Instanz läuft, und ein Elastic Load Balancer sollte für HA ausreichen.
- Metadaten-Datenbank - Enthält Informationen über den Status von Aufgaben, DAGs, Variablen, Verbindungen usw. Dies ist ganz einfach. Stellen Sie diese Datenbank als Multi-AZ-Instanz von AWS RDS mit Backups und einer Kapazität bereit, die Ihren Anforderungen entspricht.
- Staudensellerie- bestehend aus:
- Broker - Speichert Befehle zur Ausführung. Wie bereits erwähnt, sind die beiden empfohlenen Nachrichten-Broker RabbitMQ und Redis. Beide sind gleich gut, beide werden von Celery standardmäßig unterstützt und beide unterstützen den Warteschlangenmechanismus. Aus den beim Scheduler beschriebenen Gründen ist es empfehlenswert, diese Dienste in einem separaten Cluster einzusetzen. RabbitMQ verfügt über ein Plugin für die automatische Erkennung von Peers auf AWS, so dass der Cluster bei der Bereitstellung als Auto Scaling-Gruppe selbst gewartet wird. Einen guten Artikel dazu finden Sie hier.
- Ergebnis-Backend - Speichert den Status der abgeschlossenen Befehle. Dies ist die gleiche Situation wie bei der Metadaten-Datenbank - eine Multi-AZ-Instanz in AWS RDS sollte ausreichen.
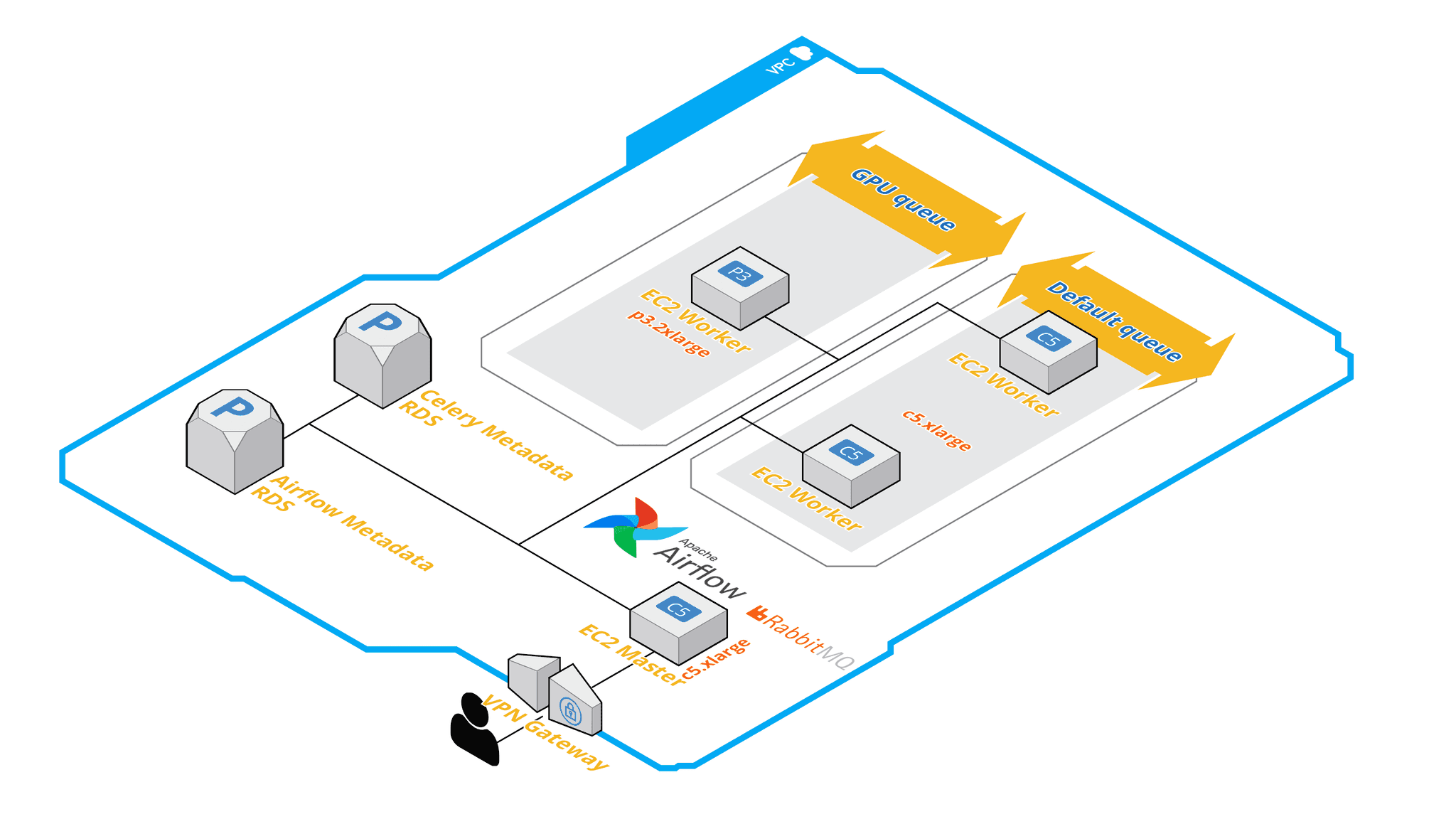 Airflow + Celery Architektur Übersicht
Airflow + Celery Architektur Übersicht
Wie Sie aus den obigen Beschreibungen ersehen können, kann der Airflow-Cluster sehr flexibel und zuverlässig sein und so konfiguriert werden, dass er die Anforderungen fast aller Pipelines erfüllt. Auf der anderen Seite müssen mehrere Komponenten bereitgestellt, konfiguriert und gewartet werden. Wenn dieser Aspekt ein Problem darstellt, sollten Sie sich den Kubernetes Executor ansehen!
Mit Kubernetes
Seit der Version 1.10.10 von Airflow wurde ein Kubernetes Executor eingeführt. Dadurch wird die Planungsmethode grundlegend geändert. Der größte Unterschied besteht darin, dass die RabbitMQ + Celery Messaging-Warteschlange vollständig aus der Planungskette entfernt wurde. Jede Aufgabe wird als separater Pod in Ihrem Kubernetes-Cluster ausgeführt und erzeugt. Die Pods sind unabhängig voneinander und Airflow Master ist für die Verfolgung des Ausführungsstatus verantwortlich. Dies ist ein sehr wichtiger Unterschied, denn Pods haben keinen Zugriff auf die Ressourcen der anderen. Es gibt jedoch einige Aspekte, die im Falle der Hochverfügbarkeit diskutiert werden müssen.
- Cluster-Bereitstellung- Wenn wir den Kubernetes-Weg einschlagen wollen, brauchen wir als allererstes einen Kubernetes-Cluster. Ich bin mir ziemlich sicher, dass Sie heutzutage bereits einen haben, aber wenn nicht, muss einer bereitgestellt werden. Der AWS EKS Service Control Plane Service ist per Definition hochverfügbar. Nachdem Sie einen Cluster in EKS bereitgestellt haben, müssen Sie Node Groups hinzufügen. Knotengruppen sind Gruppen von EKS-verwalteten Clusterknoten, aber eine Knotengruppe kann nur aus einer Größe von EC2-Instanzen bestehen. Wenn Sie verschiedene Arten von Instanzen benötigen, fügen Sie mehrere Knotengruppen hinzu. Diese Gruppen können auch autoskaliert werden. Ich empfehle die Verwendung eines offiziellen eksctl-Tools. Ein Cluster mit mehreren Knotengruppen lässt sich als yaml-Datei definieren und mit einem einzigen Befehl bereitstellen. Der Hauptvorteil von eksctl ist, dass es alle EKS-bezogenen Ressourcen wie IAM-Rollen, EC2-Instanzprofile und EC2-Sicherheitsgruppen bereitstellt und Sie sich nicht um CloudFormation oder Terraform-Vorlagen kümmern müssen.
- Platzierung des Master-Knotens - Eine einzelne oder replizierte (mit dem Failover-Controller) Master-Instanz kann vom EKS-Cluster getrennt werden, aber in diesem Fall müssen alle EC2-Instanzen über IAM und die Airflow-Konfiguration zugelassen werden, um auf den EKS-Cluster zugreifen zu können, Kubernetes-Pods zu erzeugen, ihren Status zu überprüfen usw. Eine viel intelligentere Lösung ist es, eine Master-Instanz direkt in Kubernetes einzusetzen! Readiness- und Liveness-Probes können dafür sorgen, dass der Master immer läuft, und er kann über einen Load Balancer einfach in Ihrer VPC bereitgestellt werden. Setzen Sie Ihren Diensttyp auf
type: LoadBalancerund vergessen Sie nicht, Folgendes hinzuzufügenannotations:service.beta.kubernetes.io/aws-load-balancer-internal: “true”service.beta.kubernetes.io/aws-load-balancer-type: nlb(oder einen Load Balancer-Typ Ihrer Wahl). Auf diese Weise können alle Verantwortlichkeiten für die Wartung des Master-Service an AWS/Kubernetes-Services delegiert werden. - Volumes- Master- und Worker-Instanzen müssen Zugriff auf den Code der DAGs haben. Diese Anforderung ist Executor-unabhängig. In Kubernetes können wir ein PersistentVolume und einen PersistentVolumeClaim bereitstellen, um einen gemeinsamen Speicherplatz für den Python-Code zu schaffen. Diese Volumes können als EBS-Speicher oder als EFS-Freigabe bereitgestellt werden. Da es sich bei Python-Code nur um mehrere Textdateien handelt, sollte 1 GB ausreichend sein. Wenn die S3-Option nicht konfiguriert bzw. nicht verfügbar ist, können Sie für die Persistenz der Protokolle der Aufgabenausführung denselben Implementierungspfad wählen, allerdings in einer viel größeren Größe. Die Trennung von Volumes für Logs und Dags sollte ebenfalls eine gute Praxis sein, denn wenn das Log-Volume voll ist, wird die Funktionsfähigkeit von Airflow nicht beeinträchtigt und umgekehrt.
- Datenbank- mit Kubernetes Executor ist die Celery-Metadaten-Datenbank nicht mehr erforderlich. Alle Metadaten werden in der Standard-Airflow-Datenbank gespeichert. In den meisten Airflow-Helmdiagrammen wird die Datenbank als Postgres-Container in StatefulSets bereitgestellt, aber mit Blick auf hohe Verfügbarkeit ist eine RDS-Postgres-Instanz die klügere Wahl. Der RDS-Dienst bietet Clustering, schreibgeschützte Slaves, Backups und vieles mehr. Eine in mehreren Verfügbarkeitszonen replizierte Instanz sollte eine kugelsichere Lösung sein.
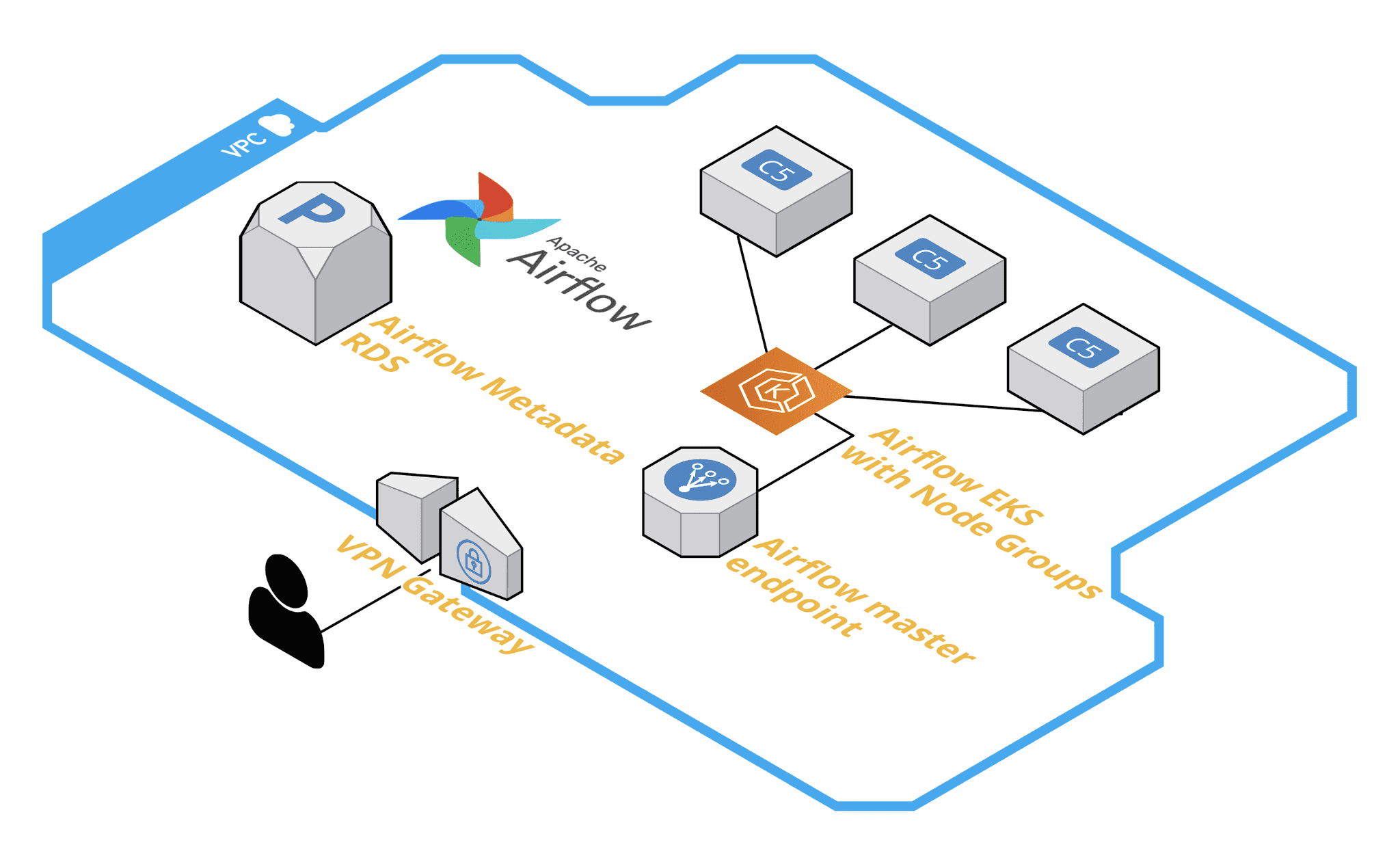 Airflow + EKS Architektur Übersicht
Airflow + EKS Architektur Übersicht
Wie Sie aus der Beschreibung ersehen können, sieht Airflow auf einem EKS-Cluster ganz anders aus als Airflow mit Celery-Einsatz. Auf den ersten Blick sieht es auf der Infrastrukturebene viel einfacher und weniger komplex aus, aber auf der anderen Seite gibt es eine zusätzliche Abstraktionsschicht im Namen von Kubernetes. Außerdem ist die Kubernetes-basierte Implementierung in der Konfigurationsflexibilität eingeschränkt, es gibt keine strikte Implementierung von Warteschlangen und der Datenaustausch zwischen aufeinanderfolgenden Aufgabenausführungen ist schwieriger.
Zusammenfassung
In diesem Artikel wurden die beiden wichtigsten Ansätze für die Bereitstellung hochverfügbarer Airflow-Cluster in der Amazon Web Services-Cloud vorgestellt. Die erste Möglichkeit ist die Bereitstellung mit einer Celery-Warteschlange, um Aufgaben auf mehrere Knoten zu verteilen, wobei die Knoten in mehrere Warteschlangen gruppiert werden können und jede Warteschlange eine andere Servergröße/einen anderen Servertyp haben kann. Auf diese Weise erhalten die Pipelines eine große Flexibilität. Wenn Sie einen allgemeineren und vielseitigeren Ansatz benötigen, wählen Sie den zweiten Weg. Airflow mit einem EKS-Cluster ist einfacher zu implementieren und zu warten und bietet dieselben Funktionen und Merkmale. Wenn beide Wege für Sie Nachteile haben, gibt es eine komplexere, aber leistungsfähigere Implementierung. Ein Airflow-Cluster mit Celery-Backend kann auch auf einem EKS-Cluster eingesetzt werden, wobei Sie sowohl die Vorteile von Kubernetes als auch die Flexibilität von Celery nutzen können. Aber das ist ein Thema für einen ganz anderen Artikel.
Verfasst von
Szymon Grzemski
Unsere Ideen
Weitere Blogs




Contact