
Die Verwendung von AWS Glue in Ihren Datenverarbeitungspipelines kann wirklich leistungsstark sein. Allerdings stoßen Sie auf etwas, das auf den ersten Blick kontraintuitiv oder schwierig zu beheben scheint.
Ein Beispiel hierfür ist ein Problem mit einer Datenverarbeitungspipeline, die nicht in der Lage war, Schemaänderungen in den eingehenden Daten zu verarbeiten. Die Pipeline funktionierte einwandfrei, aber dann hörte sie plötzlich auf zu funktionieren. In den Protokollen hieß es: "Parkett-Spalte kann nicht in Datei konvertiert werden". Nach einigem Herumstochern war klar, dass sich das Schema zwischen den verschiedenen Parkettdateien aufgrund einer Änderung im Upstream-Quellsystem geändert hatte.
Aber sollte Glue nicht in der Lage sein, Schemaänderungen zu verarbeiten?
Nun, ja und nein. Obwohl Glue selbst mit Schemaänderungen umgehen kann, wurde es als Erweiterung für Apache Spark entwickelt. Wenn also die Parkettdateien in den dynamischen Rahmen geladen werden, erwartet Spark, dass die Dateien ein kompatibles Schema haben. Das ist etwas anderes als das Laden von schemafreien Quelldateien wie JSON oder CSV. In diesem Fall reicht es Spark vollkommen aus, alle Daten zu laden und dem dynamischen Frame von Glue die Entscheidung zu überlassen, welche Datentypen verwendet werden sollen, indem ResolveChoice und ApplyMapping verwendet werden.
Um das oben beschriebene Problem zu beheben, wollte ich den Schemakonfliktfehler mit einem wirklich einfachen Datensatz reproduzieren. Die Ausnahme konnte durch das Laden von Parkettdateien ausgelöst werden, die einige Kundenkontoinformationen und einen Saldo enthalten. In der ersten Datei habe ich ein Schema mit dem Saldo als Ganzzahl erstellt, die zweite Datei enthält einen Saldo als Double. Um die Sache ein wenig aufzupeppen, habe ich eine dritte Datei erstellt, die auch ein neues Adressfeld im Schema enthält.
import pandas as pd
pd.DataFrame({"name": ["Homer Simpson", "Bart Simpson"], "age": [36,10], "balance": [-500,-100]}).to_parquet("dataset1.parquet")
pd.DataFrame({"name": ["Marge Simpson", "Lisa Simpson"], "age": [34,8], "balance": [24990.50,500.21]}).to_parquet("dataset2.parquet")
pd.DataFrame({"name": ["Maggie Simpson"], "age": [1], "balance": [10], "address": "742 Evergreen Terrace"}).to_parquet("dataset3.parquet")
Nachdem ich die Dateien in S3 hochgeladen hatte, ließ ich einen Glue Crawler laufen, um die Dateien zu indizieren und eine Tabelle zu erstellen, die das folgende Schema ergab.
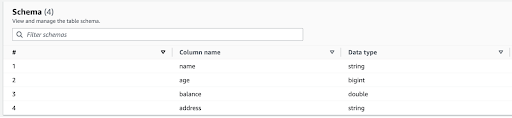
Interessanterweise liefert mir Glue nur eine einzige Schema-Version mit Balance als Double.
Als nächstes öffne ich eine interaktive Glue-Sitzung und versuche, die Daten aus der Glue-Tabelle zu lesen und sie anzuzeigen.
dyf = glueContext.create_dynamic_frame.from_catalog(database='blog', table_name='people')
dyf.printSchema()
Die Ausgabe ähnelt der, die wir in der Glue-Konsole gesehen haben, was auch Sinn macht, da sie einfach aus dem Datenkatalog gelesen wird.
root |-- name: string |-- age: long |-- balance: long |-- address: string
Sobald wir jedoch versuchen, die Daten im Dynamic Frame zu lesen, wird eine Ausnahme ausgelöst.
dyf.show()
Py4JJavaError: An error occurred while calling o87.showString.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 1.0 failed 4 times, most recent failure: Lost task 1.3 in stage 1.0 (TID 5) (172.34.254.19 executor 1): org.apache.spark.sql.execution.QueryExecutionException: Parquet column cannot be converted in file s3://conflicting-schemas-blog-post/people/dataset2.parquet. Column: [balance], Expected: bigint, Found: DOUBLE
at org.apache.spark.sql.errors.QueryExecutionErrors$.unsupportedSchemaColumnConvertError(QueryExecutionErrors.scala:706)
Das direkte Lesen der Daten aus S3 mit Spark, auch mit der Option mergeSchema, verursacht das gleiche Problem.
bucket_name = 'conflicting-schemas-blog-post'
prefix = 'people/'
df = spark.read.option("mergeSchema", "true").parquet(f's3://{bucket_name}/{prefix}')
df.printSchema()
Py4JJavaError: An error occurred while calling o94.parquet.
: org.apache.spark.SparkException: Failed merging schema:
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- balance: double (nullable = true)
|-- address: string (nullable = true)
…
Caused by: org.apache.spark.SparkException: Failed to merge fields 'balance' and 'balance'. Failed to merge incompatible data types bigint and double
Obwohl Spark in der Lage ist, verschiedene Schemata zusammenzuführen, erwartet es immer noch, dass die Felder im Datenrahmen in allen Dateien denselben Datentyp haben*.. Um die widersprüchlichen Dateien an ein bestimmtes Schema anzupassen, können Sie die Parkettdateien einzeln vorverarbeiten. Ein einfaches Beispiel dafür, wie dies geschehen könnte, finden Sie unten:
import boto3
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import col
s3 = boto3.resource('s3')
bucket = s3.Bucket(bucket_name)
# A variable to store the union of all dataframes
dfa = None
# Loop through the objects in your path
# or change this to go through the files from the Glue bookmark
for obj in bucket.objects.filter(Prefix=prefix):
if obj.key == prefix:
# This is the bucket prefix itself, ignore
continue
# Open the file
df = spark.read.parquet(f's3://{bucket_name}/{obj.key}')
# Test if the problematic column exists
if "balance" in df.columns:
# Cast it to the correct value
df = df.withColumn("balance", col("balance").cast("double"))
# Create a dynamic frame to merge it and allow for other schema changes
dyf = DynamicFrame.fromDF(df, glueContext, "adjusted_schema")
# Merge the dynamic frames
dfa = dfa.mergeDynamicFrame(dyf, []) if dfa else dyf
dfa.printSchema()
dfa.show()
Das Ergebnis ist ein Datenrahmen, in dem alle Einträge in allen Feldern denselben Datentyp haben.
root
|-- name: string
|-- age: long
|-- balance: double
|-- address: string
{"name": "Homer Simpson", "age": 36, "balance": -500.0}
{"name": "Bart Simpson", "age": 10, "balance": -100.0}
{"name": "Marge Simpson", "age": 34, "balance": 24990.5}
{"name": "Lisa Simpson", "age": 8, "balance": 500.21}
{"name": "Maggie Simpson", "age": 1, "balance": 10.0, "address": "742 Evergreen Terrace"}
Mit diesem zusammengeführten dynamischen Rahmen können Sie nun Ihren ETL-Prozess fortsetzen. Sie können den obigen Code entweder in Ihren Glue-Auftrag aufnehmen oder ihn als Vorverarbeitungsauftrag in Ihren Workflow einfügen.
Wenn Sie Fragen zu Daten und Analysen auf AWS haben, können Sie sich gerne an uns wenden.
* Siehe https://spark.apache.org/docs/3.3.0/sql-data-sources-parquet.html#schema-merging
Verfasst von
Thomas Wijntjes
Unsere Ideen
Weitere Blogs




Contact