Blog
Grüne Software ist ereignisgesteuert und kohlenstoffbewusst, mit Kubernetes und KEDA

Wussten Sie, dass Rechenzentren mehr Kohlenstoff ausstoßen als der Luft- oder Schiffsverkehr? Und das Tempo nimmt nicht ab. Einige Studien prognostizieren, dass die Datenverarbeitung bis 2040 zu 14% der globalen Emissionen beitragen wird. Noch schlimmer ist, dass ein erheblicher Teil dieser Emissionen für nicht produktive Ressourcen verschwendet wird, die außerhalb der Bürozeiten laufen, so dass Ihre Anwendung immer nur zu Spitzenzeiten genutzt werden kann. Das ist nicht nur schlecht für den Planeten, sondern auch für Ihre Cloud-Rechnung.
Wie können wir das besser machen? Anstatt eine feste Anzahl von Anwendungsreplikaten zu haben, sollten wir den Umfang unserer Anwendungen darauf abstimmen:
- Aktuelle Ereignisse, zum Beispiel in Form von eingehenden Webanfragen oder Nachrichten in einem Kafka-Thema. Die Dimensionierung Ihrer Anwendung auf der Grundlage des Arbeitsaufkommens verringert die Überbelegung und die ständig verfügbaren Ressourcen.
- Die Verfügbarkeit von sauberer Energie. Der Strom im Stromnetz des Rechenzentrums stammt aus verschiedenen Quellen, z. B. aus Kohle, Kernkraft und Sonnenenergie. Wir sollten mehr tun, wenn die Energie sauberer ist, d.h. wenn die Kohlenstoffintensität geringer ist, um die Emissionen weiter zu reduzieren.
Dieser Artikel zeigt, wie wir unsere Anwendungen grüner machen können, indem wir sie
ereignisgesteuert und kohlenstoffbewusst machen. Wir werden diese Eigenschaften auf der Ebene des Kubernetes-Clusters mit
Der Webshop, der grüner werden will
Stellen Sie sich einen einfachen Webshop mit nur zwei Anwendungen vor: einen Webserver, der die Website für Kunden bereitstellt, und ein Bestellsystem, das sich um alles andere kümmert. Wenn ein Kunde eine Bestellung aufgibt, stellt der Webserver eine Nachricht mit allen notwendigen Informationen in eine Warteschlange und bedankt sich sofort für den Kauf. Das Bestellsystem konsumiert diese Nachrichten asynchron, prüft das Lager, versendet die Lieferung und schickt dann eine Bestätigungs-E-Mail an den Kunden.
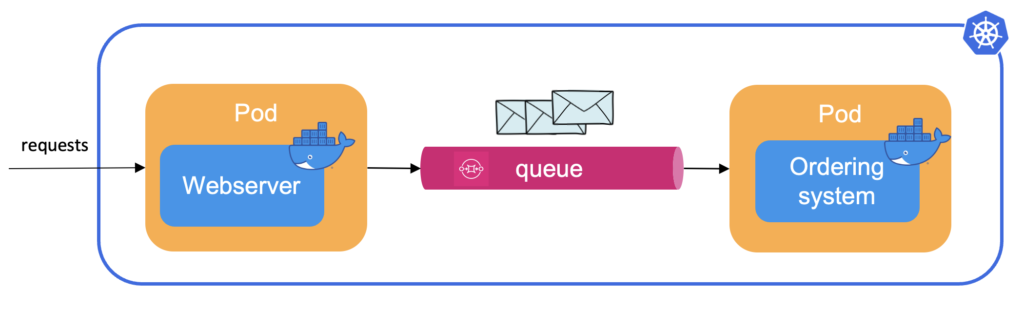
Obwohl die Anzahl der Kunden im Laufe des Tages schwankt, werden beide Anwendungen derzeit mit einer festen Anzahl von Replikat-Pods eingesetzt, die für die Stoßzeiten geeignet sind. Unten sehen Sie ein Diagramm mit der Anzahl der Nachrichten in der Warteschlange und den Replikaten des Bestellsystems im Cluster. Die rote Linie zeigt die Anzahl der Nachrichten in der Warteschlange und die blaue Linie zeigt die Anzahl der Pods.
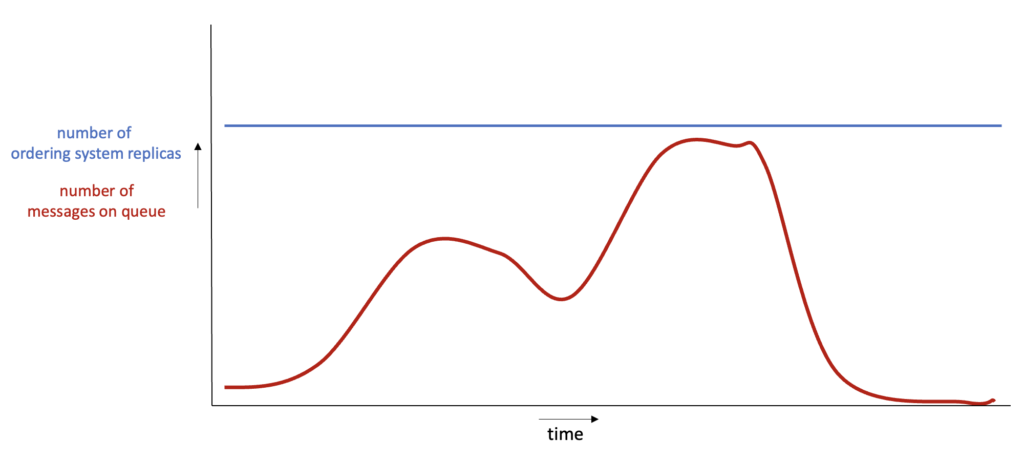
Der Einfachheit halber nehmen wir an, dass sich die Replikate und Nachrichten an einer bestimmten y-Koordinate genau die Waage halten, d.h. es gibt genau genügend Replikate für diese Anzahl von Nachrichten. In diesem Fall bezieht sich die Fläche unter der blauen und der roten Linie auf den gesamten bzw. den nützlichen Ressourcenverbrauch. Die Differenz sind verschwendete Ressourcen.
Der Webshop ist stolz auf seinen nachhaltigen Ruf und möchte auch die Cloud-Kosten senken. Der Inhaber des Webshops hat mit Kunden gesprochen und erfahren, dass der Webserver zwar immer verfügbar und schnell sein sollte, es aber in Ordnung ist, wenn die asynchrone E-Mail-Bestätigung etwas später eintrifft.
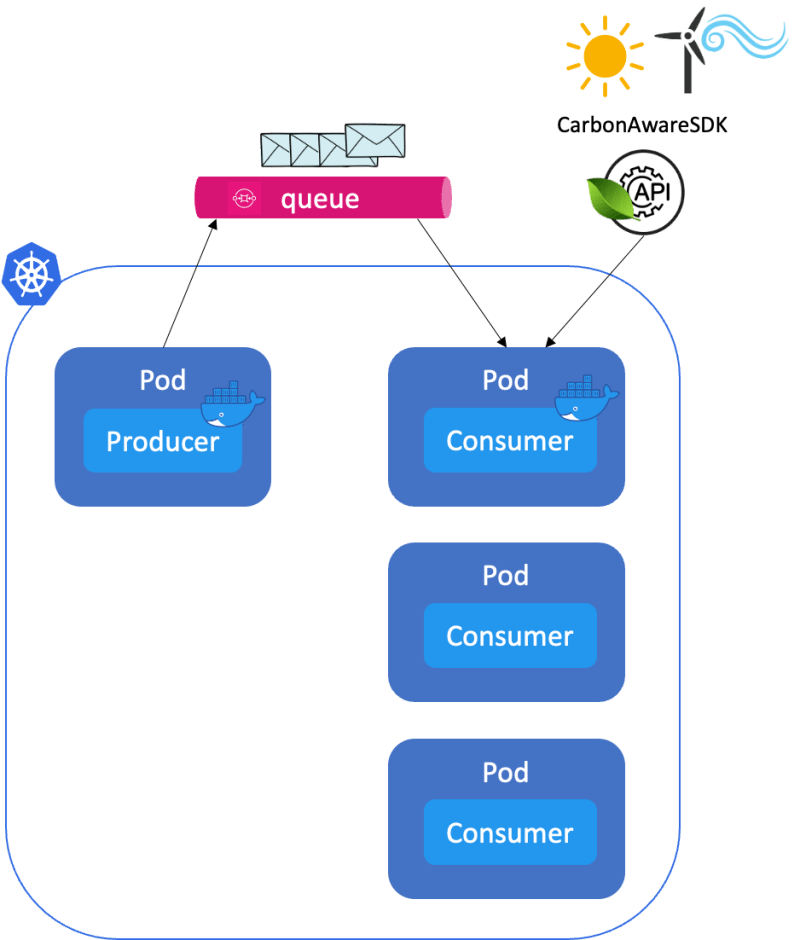
Der Eigentümer des Webshops möchte das Bestellsystem in Abhängigkeit von der Größe der Warteschlange und der Verfügbarkeit von sauberer Energie skalieren. Mit anderen Worten: Wenn die Kohlenstoffintensität niedrig ist und viele Nachrichten in der Warteschlange warten, kann das Bestellsystem auf Hochtouren laufen:
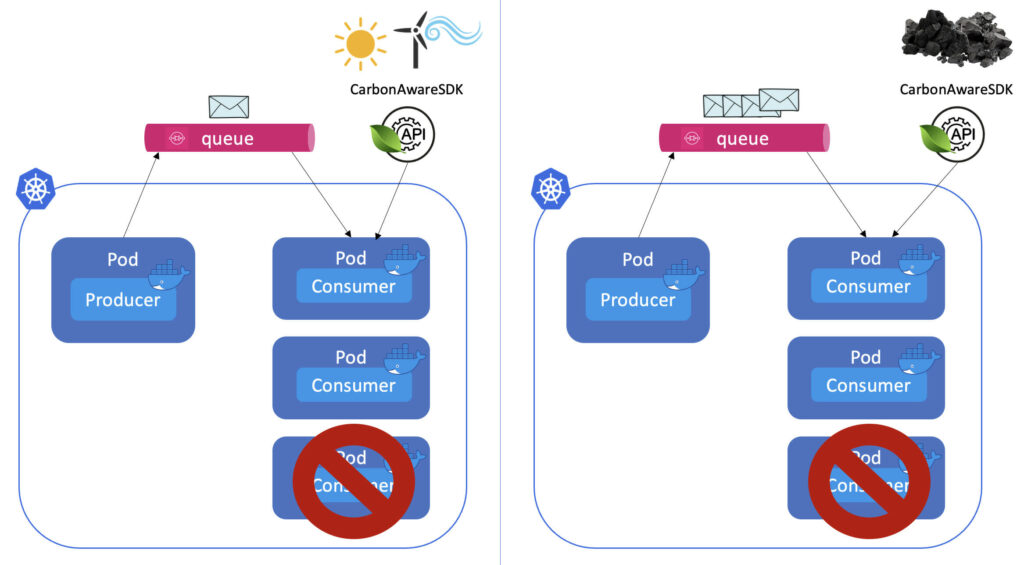
Wenn andererseits entweder die Kohlenstoffintensität hoch oder die Anzahl der Nachrichten niedrig ist, sollten wir die Anzahl der Replikate ausgleichen:
Lassen Sie uns herausfinden, wie wir dies mit KEDA erreichen können.
Ereignisgesteuerte Skalierung von Pods
Wir wollen weg von einem immer aktiven Bestellsystem mit zu vielen Replikaten. Um das Bestellsystem dynamisch anhand der Anzahl der Nachrichten in der Warteschlange zu skalieren, verwenden wir ScaledObject erstellen:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: ordering-system-scaler
spec:
scaleTargetRef:
name: ordering-system
pollingInterval: 5
cooldownPeriod: 5
idleReplicaCount: 0
minReplicaCount: 1
maxReplicaCount: 10
fallback:
failureThreshold: 4
replicas: 5
triggers:
- type: aws-sqs-queue
authenticationRef:
name: ordering-system-triggerauth
metadata:
queueURL: <AWS-DOMAIN>/000000000000/ordering-queue
awsEndpoint: <AWS-DOMAIN>
queueLength: "50"
awsRegion: "eu-west-1"
identityOwner: podDie obige YAML besteht aus ungefähr drei Teilen:
- Wir müssen der
ScaledObjectmitteilen, welche Anwendung wir skalieren wollen. Dies geschieht über den SchlüsselscaleTargetRef. In diesem Fall ist das Zielordering-systemdieDeployment, die die Replikate des Bestellsystems verwaltet. - Dann konfigurieren wir , wie wir die Anwendung skalieren möchten.
minReplicaCountundmaxReplicaCountbestimmen den Bereich der Skalierung, und wir können auch viele andere Eigenschaften konfigurieren. - Schließlich geben wir in
triggersan, welche(s) Ereignis(e) skaliert werden soll(en). Hier haben wir den AWS SQS Queue Trigger definiert und ihm gesagt, dass er sich um 50 Nachrichten in der Warteschlange bemühen soll.
Das Diagramm von vorhin ändert sich wie folgt:
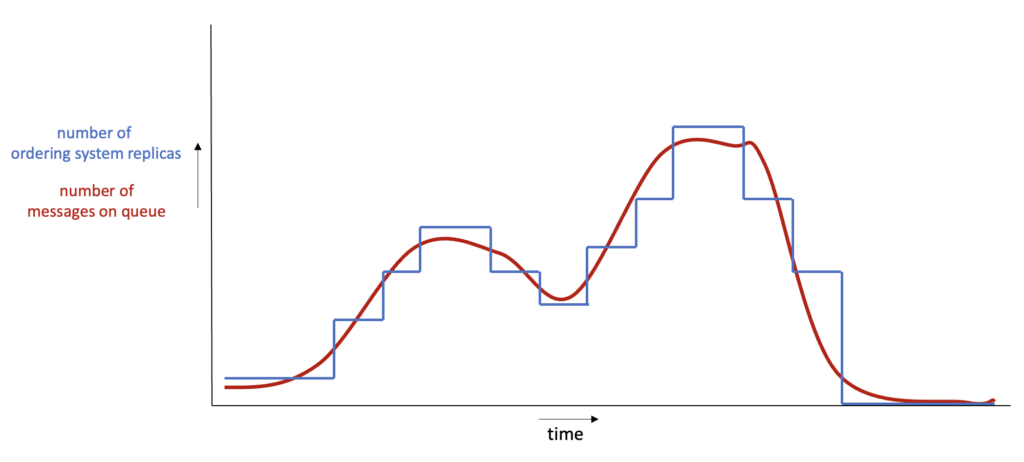 Der Unterschied in der Fläche unter beiden Linien ist jetzt viel kleiner, was auf eine effizientere Ressourcennutzung hinweist.
Der Unterschied in der Fläche unter beiden Linien ist jetzt viel kleiner, was auf eine effizientere Ressourcennutzung hinweist.
Was mir an KEDA wirklich gefällt, ist, dass es nicht versucht, das Rad neu zu erfinden. Stattdessen nutzt es den in Kubernetes eingebauten external Metriken verwenden, die auf externen Metrics Servern basieren. KEDA implementiert 'einfach' einen External Metrics Server, der Daten über die Auslöser bereitstellt, die wir in unserem ScaledObject definieren.
Kohlendioxid-bewusste Grenzen der Skalierung
Mit der ereignisgesteuerten Skalierung von KEDA hat sich unser Ressourcenverbrauch bereits drastisch verändert. Dennoch berücksichtigt das Bestellsystem nicht die aktuelle Verfügbarkeit von sauberer Energie. Wenn der Webshop in Momenten mit weniger sauberer Energie stärker ausgelastet ist, können wir immer noch viel mehr emittieren, als uns lieb ist. Sehen wir uns an, wie wir mit dem Carbon Aware KEDA Operator das Bewusstsein für Kohlenstoff hinzufügen können. Dieser Kubernetes-Operator schränkt ein, wie weit KEDA unseren Verbraucher auf der Grundlage der Kohlenstoffintensität skalieren kann. Dieser Operator legt im Wesentlichen eine Obergrenze für die erlaubte
apiVersion: carbonaware.kubernetes.azure.com/v1alpha1
kind: CarbonAwareKedaScaler
metadata:
name: carbon-aware-ordering-system-scaler
spec:
maxReplicasByCarbonIntensity:
- carbonIntensityThreshold: 237
maxReplicas: 10
- carbonIntensityThreshold: 459
maxReplicas: 6
- carbonIntensityThreshold: 570
maxReplicas: 3
kedaTarget: scaledobjects.keda.sh
kedaTargetRef:
name: ordering-system-scaler
namespace: default
carbonIntensityForecastDataSource:
mockCarbonForecast: true
localConfigMap:
name: carbon-intensity
namespace: kube-system
key: dataÄhnlich wie bei der ScaledObject gezielt eine Deployment durch seine scaleTargetRef, dies CarbonAwareKedaScaler zielt auf eine ScaledObject definiert in kedaTargetRef. Dies sorgt für einen sauberen, mehrschichtigen Ansatz, bei dem jede Schicht nichts von der darüber liegenden Schicht weiß.
Der wichtigste Teil der obigen YAML-Definition ist der Schlüssel maxReplicasByCarbonIntensity, mit dem wir zunehmend strengere Skalierungsgrenzen auf der Grundlage der Verfügbarkeit von sauberer Energie konfigurieren können.
Der Operator ruft die aktuelle Kohlenstoffintensität aus der ConfigMap ab, die wir unter dem Schlüssel carbonIntensityForecastDataSource definieren, aber das eigentliche Befüllen der ConfigMap kann er nicht für Sie erledigen. Glücklicherweise hat Microsoft einen begleitenden Operator namens Carbon Intensity Exporter entwickelt, der auf dem CarbonAwareSDK der Green Software Foundations aufbaut und Daten zur Kohlenstoffintensität im Kubernetes-Cluster bereitstellt. Wenn Sie jedoch nur herumspielen möchten, können Sie den Schlüssel ConfigMap mit gefälschten Kohlenstoffintensitätsdaten.
Mit dem Carbon Aware KEDA Operator, der in unserem Cluster konfiguriert ist, können wir die Kohlenstoffemissionen unseres Webshops weiter senken, indem wir mehr tun, wenn die Energie sauberer ist:
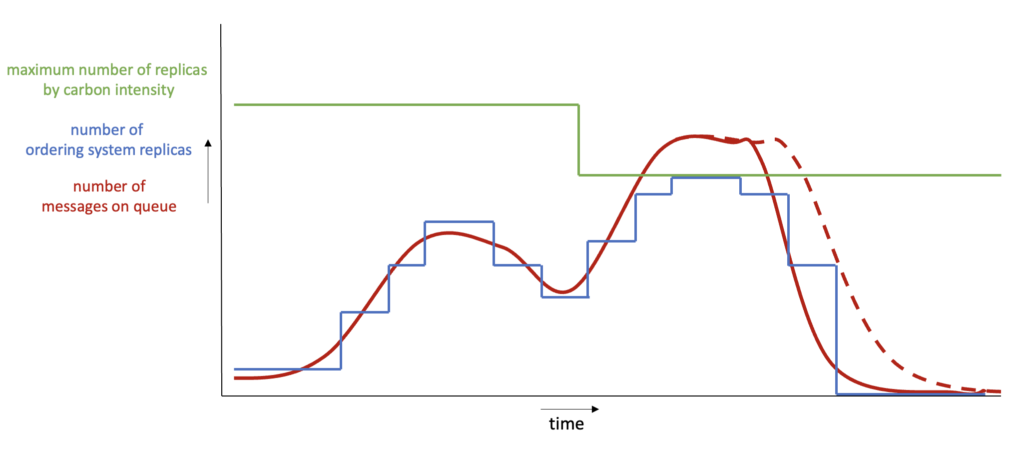
In der zweiten Spitze werden die Nachrichten etwas langsamer konsumiert, weil die Kohlenstoffintensität in diesem Moment zu hoch ist. Der Kunde muss vielleicht ein paar Sekunden länger auf die Bestätigungs-E-Mail warten, aber er wird es wahrscheinlich gar nicht bemerken.
Fazit
Die Datenverarbeitung trägt erheblich zu den weltweiten Kohlenstoffemissionen bei, und die Digitalisierung zeigt keine Anzeichen einer Verlangsamung. Wir sollten daher unsere Ressourcen effizienter nutzen. Dieser Artikel zeigt, wie wir KEDA nutzen können, um ereignisorientierter und kohlenstoffbewusster zu werden und die Überbelegung unserer Anwendungen zu reduzieren.
Foto von Lucie Hošová auf Unsplash
Verfasst von

Bjorn van der Laan
Software engineer at Xebia Software Development
Unsere Ideen
Weitere Blogs


Wo die GitHub Copilot Erweiterungspunkte die Governance brechen
Viele der jüngsten Ergänzungen des GitHub Copilot-Ökosystems bieten einen echten Mehrwert für einzelne Entwickler, erweitern aber auch die...
Rob Bos


Contact