
Einführung in GenAI für die Datenextraktion
GenAI gibt es schon seit einiger Zeit und ihre Möglichkeiten erweitern sich schnell. Der Hype um KI ist groß und die Erwartungen sind hoch. Dennoch gelingt es vielen Unternehmen nicht, mit GenAI einen echten Mehrwert zu schaffen. Warum ist das so? Warum wird uns so viel versprochen und doch so wenig erreicht? Was ist noch Fantasie und welches konkrete Potenzial besteht? Was sollte automatisiert werden und was nicht? In diesem Blogpost untersuchen wir das GenAI-Automatisierungspotenzial, das heute für die Datenextraktion besteht.
Gemeinsam lernen wir etwas über:
- Warum GenAI Datenextraktion
- Die Automatisierungsstufen
- Das Automatisierungspotenzial
Fangen wir an!
1. Warum GenAI Datenextraktion
Warum genau sollten wir uns für die Datenextraktion mit GenAI interessieren? Lassen Sie uns dies anhand von 4 Anwendungsbeispielen in verschiedenen Bereichen und mit verschiedenen Datentypen wie Text, Bilder, Dokumente oder Audio motivieren.
- Versicherungsansprüche (Text)
- Menükarten (Bilder)
- Jahresberichte (PDF-Dokumente)
- Anrufe beim Kundendienst (Audio)
Versicherungsansprüche (Text)
Stellen Sie sich vor, Sie leiten ein Versicherungsunternehmen und Ihre Mitarbeiter sind mit der Bearbeitung von Versicherungsansprüchen beauftragt. Schadensfälle werden oft in einem freien Format übermittelt: E-Mail, Telefonanruf, Chat, kurz: unstrukturierte Daten. Ihre Mitarbeiter müssen diese Informationen dann verarbeiten, um den Schaden zu bearbeiten: die internen Datenbanken aktualisieren, ähnliche Schadenfälle finden usw. Nehmen wir den Fall an, dass wir diese Informationen in Form von Freiformtexten wie E-Mails erhalten.
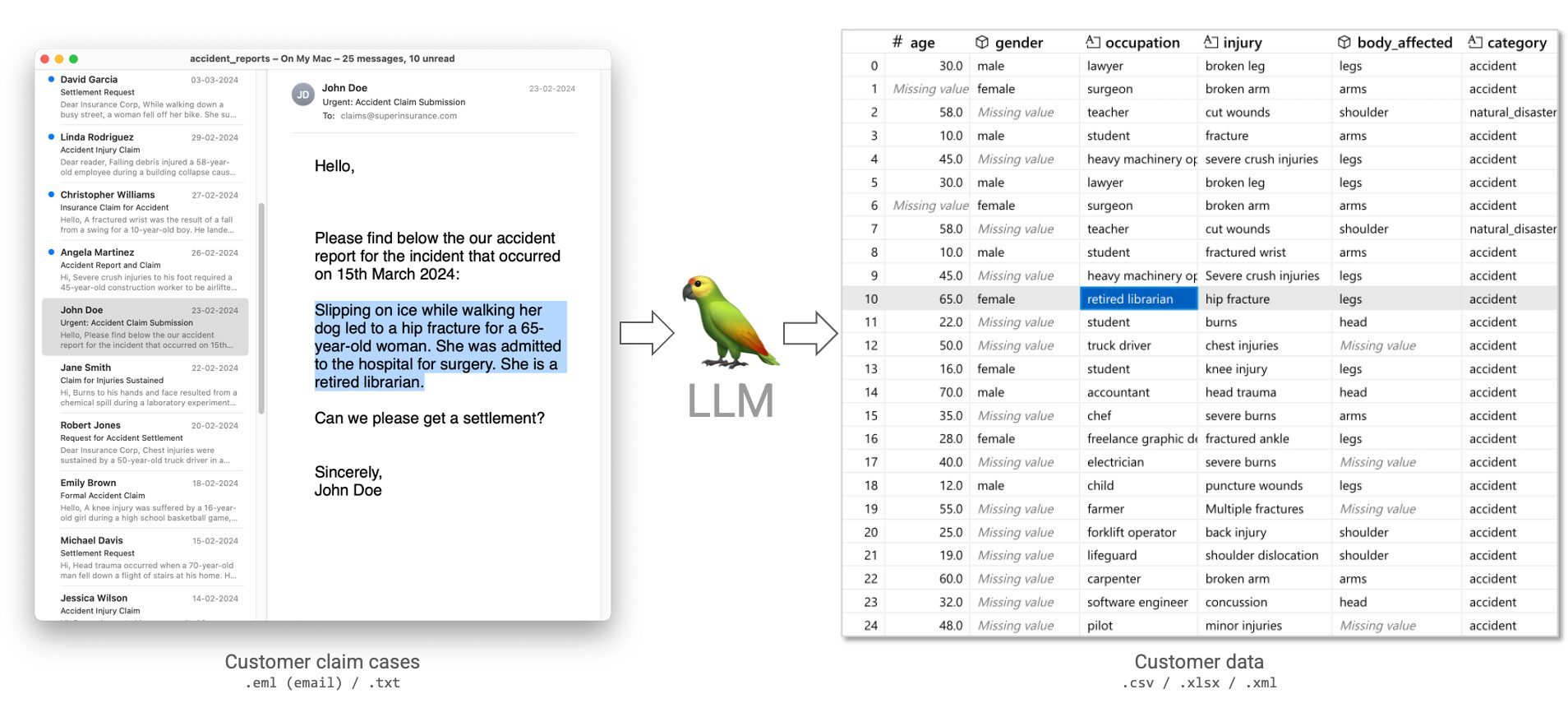
Wir weisen den LLM an, seine Antworten im strukturierten Format zu geben
[ref]
zu geben, so dass wir seine Ausgabe leicht bearbeiten und umwandeln können. Um dieses gesamte E-Mail-Postfach mit etwa 25 E-Mails zu leeren, benötigte Gemini 2.0 Flash etwa 15 Sekunden. Das heißt, wenn es sequentiell ausgeführt wird. Wenn es parallel ausgeführt wird, kann diese Datenmenge in wenigen Sekunden verarbeitet werden. Wenn dies auf die Verarbeitung eines Postfachs mit 100.000 E-Mails skaliert würde, würden wir etwa $1,52 ausgeben. Nicht sehr viel, wenn man bedenkt, dass wir hier eine Menge Zeit sparen können. Wir können diese Kosten auch halbieren, wenn wir stattdessen die Batch-API von Gemini verwenden. Wie lange würde ein Mensch brauchen, um 100k E-Mails zu verarbeiten? Was ist seine Zeit wert?
Das Extrahieren von Kundendaten aus dieser E-Mail-Nachricht dauerte bei Gemini 2.0 Flash etwa 0,5 Sekunden und kostete $0,000015.
Menükarten (Bilder)
Ein anderer Anwendungsfall. Stellen Sie sich vor, Sie betreiben eine Online-Plattform für Essenslieferungen. Sie möchten die Menükarten digitalisieren, damit das Angebot in standardisierter Form in Ihre eigene Plattform aufgenommen werden kann. Sie stellen eine Reihe von Mitarbeitern ein, die Sie bei dieser Aufgabe unterstützen. Die Menükarten kommen im Bildformat an. Können wir den Prozess der Konvertierung der Speisekarten beschleunigen?
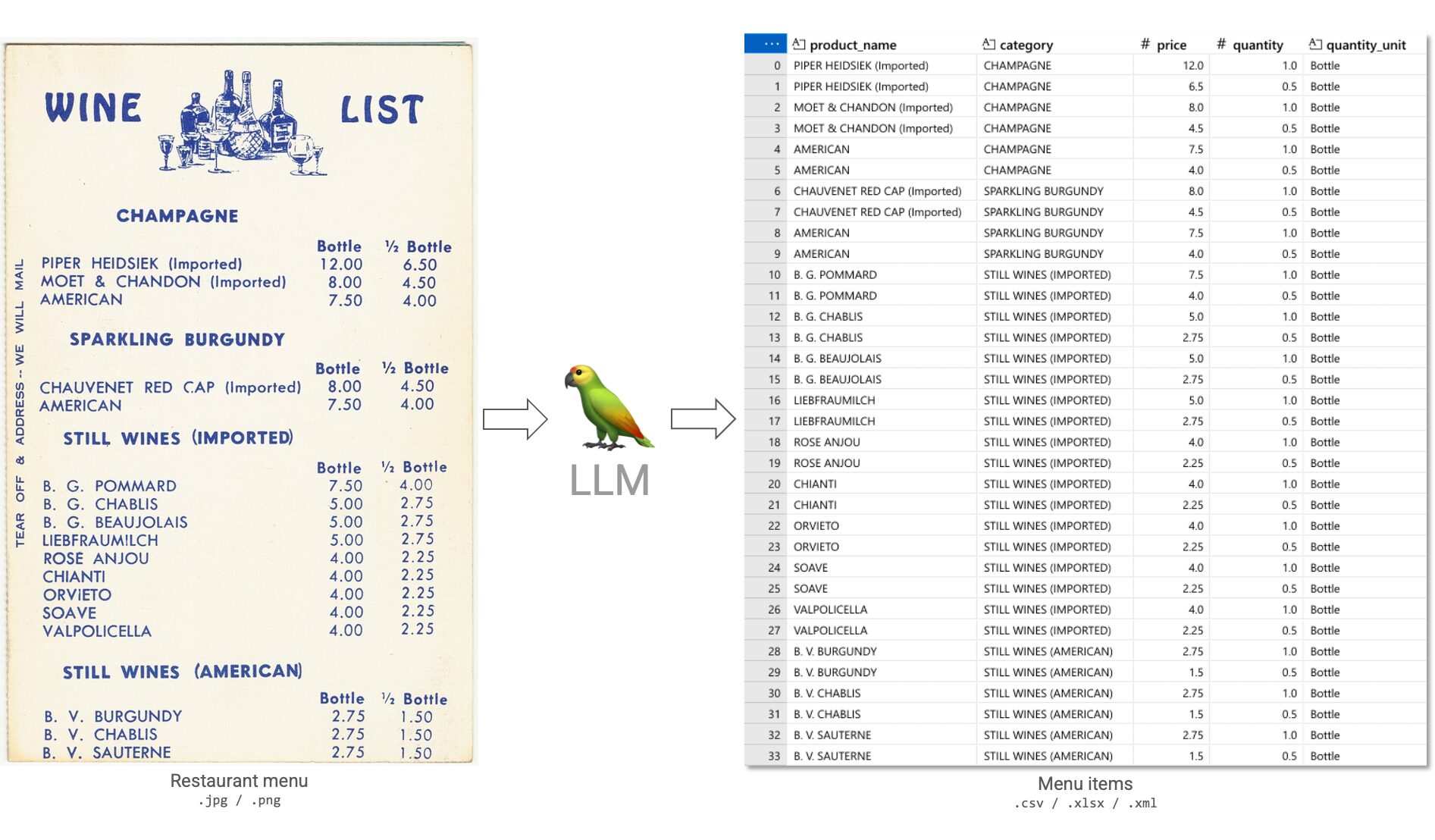
Ja: Wir können dies beschleunigen. LLMs betrachten das Bild als Ganzes und sind auch in der Lage, Textdetails im Bild genau zu verarbeiten. Da wir ein generisches Modell verwenden, können Bilder in vielen Kontexten mit demselben Modell verarbeitet werden, ohne dass wir eine Feinabstimmung für bestimmte Situationen vornehmen müssen.
Die Konvertierung dieser Menükarte dauerte bei Gemini 2.0 Flash etwa 10 Sekunden und kostete $0,0005. Wie lange würde ein Mensch brauchen?
Jahresberichte (PDF-Dokumente)
Stellen Sie sich vor, Sie sollen Fragen anhand von Finanzdokumenten beantworten. Sie sollen jede Frage durchgehen und die Antwort auf der Grundlage der in den Dokumenten enthaltenen Informationen begründen. Nehmen Sie zum Beispiel Jahresabschlüsse. Unternehmen auf der ganzen Welt sind verpflichtet, diese Abschlüsse zu veröffentlichen, und die Unternehmensfinanzen müssen geprüft werden. Die Durchsicht solcher Dokumente ist zeitaufwändig. Nehmen Sie einen Jahresbericht im PDF-Format. Können wir den Mitarbeitern helfen, Antworten auf der Grundlage dieses Dokuments schneller zu formulieren?
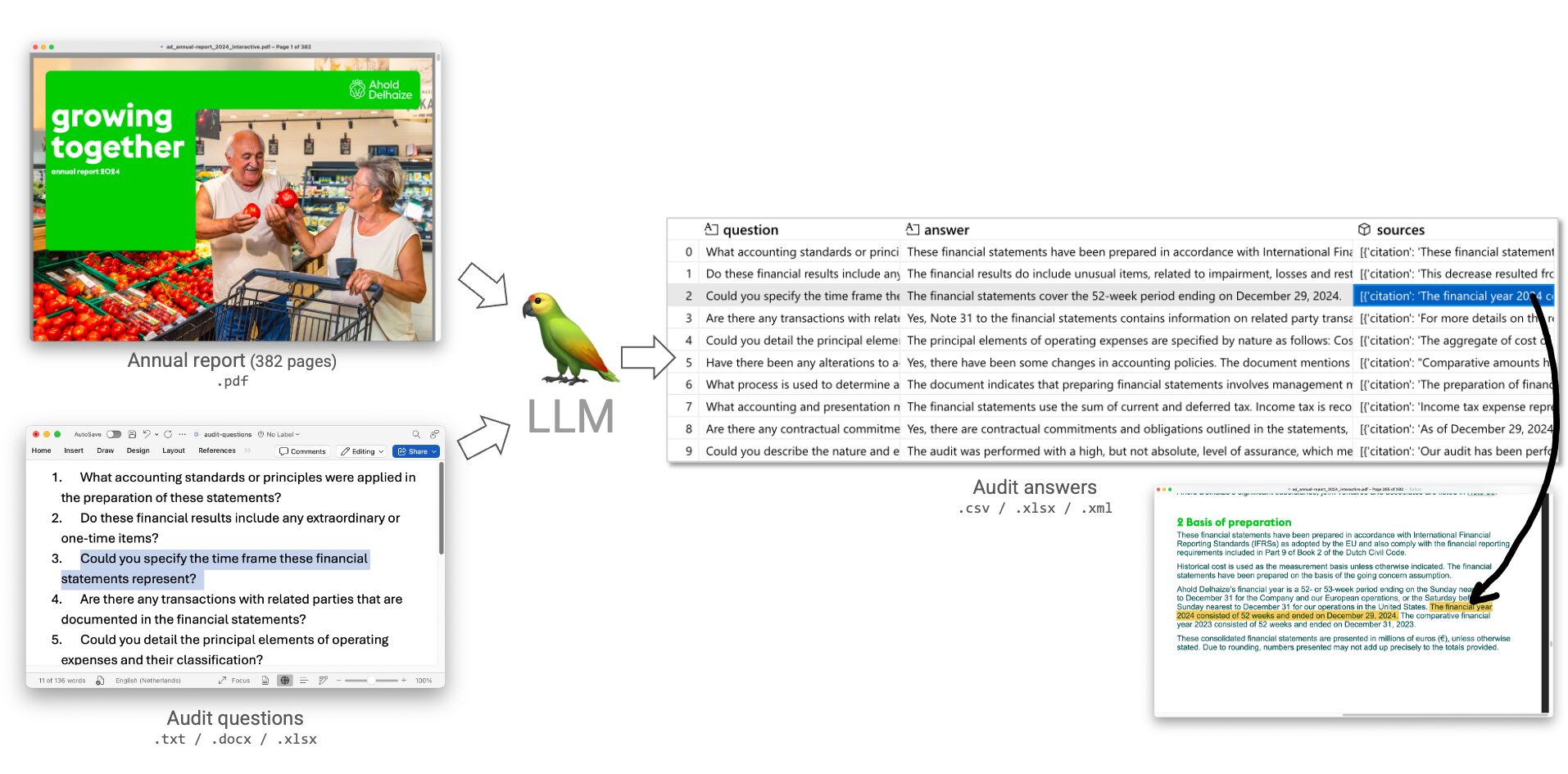
Ja. Das Dokument fügt sich auf einmal in den Kontext des Modells ein, so dass das Modell eine umfassende Sicht auf das Dokument erhält und sinnvolle Antworten formulieren kann. Tatsächlich nehmen LLMs wie die Gemini-Modelle von Google bis zu 2 Millionen Token auf einmal in den Kontext auf
[ref]
. So können bis zu 3.000 PDF-Seiten in die Eingabeaufforderung eingefügt werden. PDF-Seiten werden von Gemini als Bilder verarbeitet
[ref]
.
Für die Beantwortung dieser Fragen benötigte Gemini 2.0 Flash knapp 1 Minute und kostete 0,015 $. Wie lange würde ein Mensch brauchen?
Anrufe beim Kundendienst (Audio)
Stellen Sie sich vor, Sie haben eine Kundendienstabteilung und bearbeiten täglich viele Anrufe. Die Kundendienstmitarbeiter tun ihr Bestes, um nützliche Informationen während des Anrufs zu dokumentieren und aufzuzeichnen, aber sie können unmöglich alle wertvollen Informationen dokumentieren. Die Anrufe werden zu Analysezwecken vorübergehend aufgezeichnet. Die Anrufe können abgehört werden, um das Kundenproblem, die Ursache, die Lösung und die Meinung des Kunden herauszufinden. Diese Informationen sind wertvoll, denn es handelt sich um notwendige Feedback-Informationen, um den Kundenservice gezielt zu verbessern. Welche Probleme konnten wir am häufigsten nicht lösen? In welchen Situationen sind unsere Kunden unzufrieden?
Die Erkenntnisse sind wertvoll, aber schwer zu erreichen. Die Daten sind in einem Audioformat versteckt.
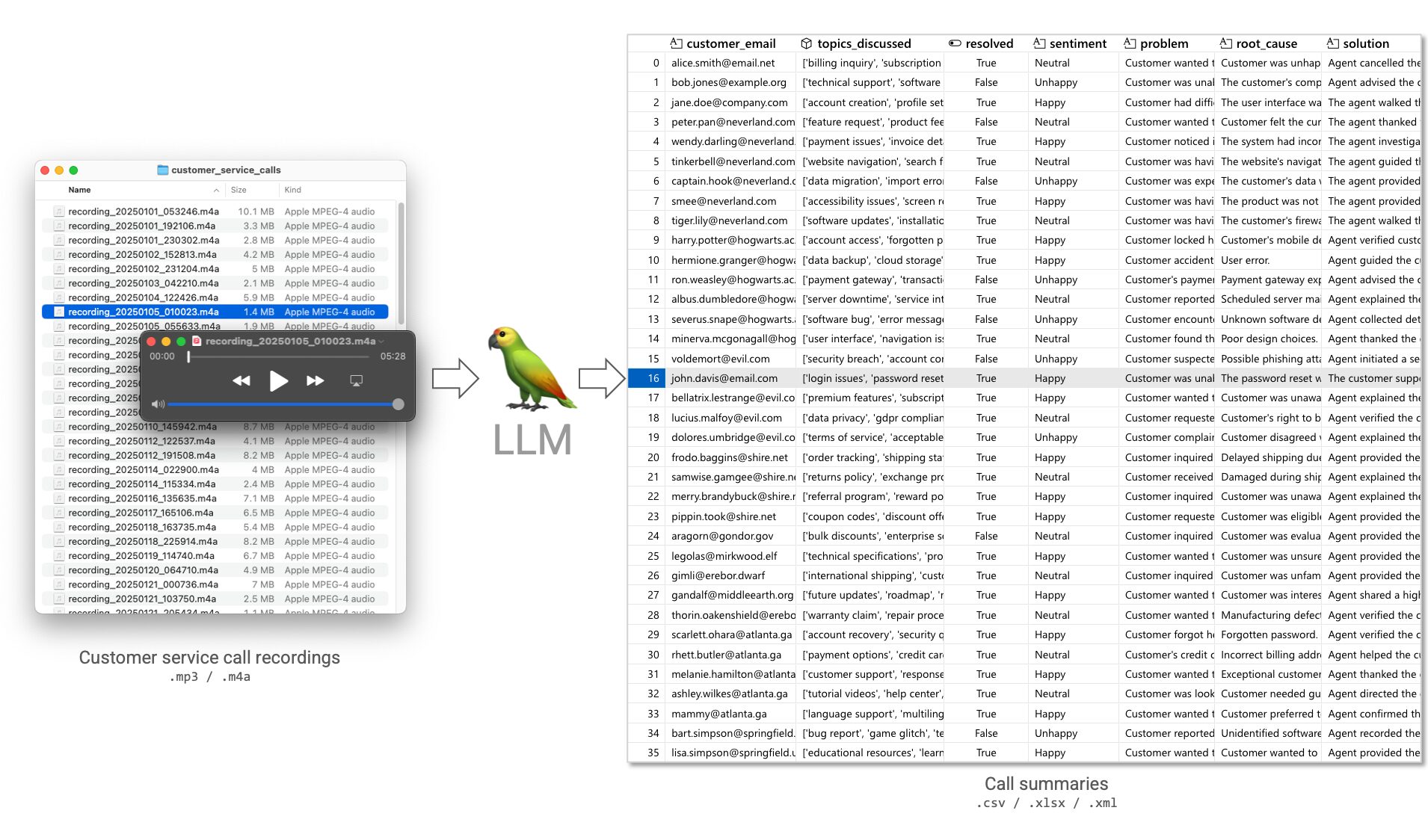
Gemini 2.0 Flash hat diesen 5-minütigen Anruf beim Kundendienst in 3 Sekunden bearbeitet und dabei 0,0083 $ ausgegeben. Das ist schneller, als ein Mensch braucht, um den Anruf anzuhören und zu bearbeiten. LLMs können auch Audiodaten präzise verarbeiten, ohne dass zuvor eine Transkription erforderlich ist. Da das Modell mit der rohen Audiodatei in Berührung kommt, können mehr als nur die gesprochenen Worte berücksichtigt werden. Auf welche Weise spricht dieser Kunde? Ist dieser Kunde glücklich oder unglücklich? LLMs von der Stange können ohne Modifikation und nur durch Eingabeaufforderung verwendet werden, um strukturierte Daten aus Audiodaten zu extrahieren
[ref]
.
Aus den 4 Anwendungsbeispielen haben wir Folgendes gelernt.
- LLMs für die Datenextraktion: LLMs können verwendet werden, um strukturierte Daten aus Freiformformaten wie Text, Bildern, PDFs und Audio zu extrahieren.
- Größere Kontexte: Wachsende LLM-Kontextfenster ermöglichen die Verarbeitung größerer Dokumente auf einmal. Dies stärkt die Anwendbarkeit für die Datenextraktion mit LLMs, ohne dass zusätzliche Abrufschritte erforderlich sind.
- Wettbewerbsfähige Preise: Niedrigere Inferenzkosten machen mehr Anwendungsfälle der Datenextraktion realisierbar.
- GenAI Datenextraktion ROI: LLMs können Datenextraktionsaufgaben schneller als Menschen und zu geringeren Kosten erledigen. Das Ziel ist es, ein System zu schaffen, das gut genug ist, um Menschen bei ihrer Arbeit zu unterstützen und einen geschäftlichen Nutzen zu bieten, auch wenn es noch nicht perfekt ist.
Das ist wirklich cool. LLMs werden immer leistungsfähiger und billiger und ermöglichen mehr Anwendungsfälle als früher. Was genau ist nun diese Datenextraktion? Wie können wir sie zu unserem Vorteil nutzen, um Geschäftsprozesse zu automatisieren? Welche Automatisierungsgrade gibt es bei der Datenextraktion?
2. Die Automatisierungsstufen
Um herauszufinden, was mit GenAI Datenextraktion möglich ist, werden wir in 4 Stufen zunehmender Automatisierung unterteilen.
- Stufe 0: Manuell
- Stufe 1: Assistiert
- Stufe 2: Autopilot
- Stufe 3: Autonom
Stufe 0: Manuelle Arbeit
Es findet keine Automatisierung statt. Es ist menschliche Arbeit erforderlich, um Daten im gewünschten Format zu extrahieren. Die extrahierten Daten werden dann von einem menschlichen Benutzer verwendet. Die gesamte Datenextraktion, die Bewertung der Datenqualität und alle Aktionen, die mit den Daten durchgeführt werden müssen, sind manuelle Prozesse.
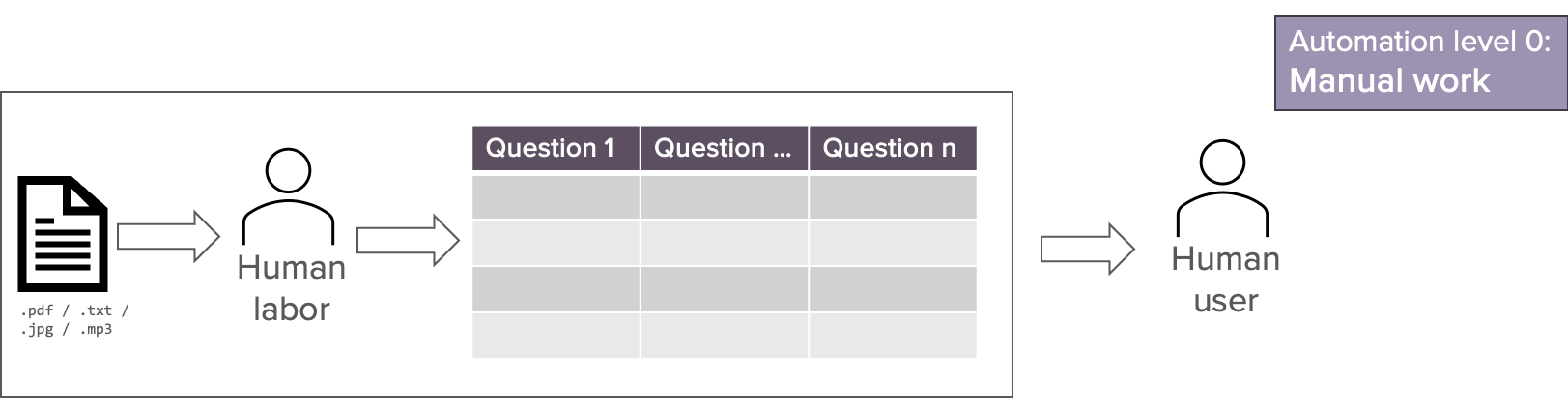
Wir können es besser machen. LLMs können verwendet werden, um einen Teil dieses Prozesses zu automatisieren und den Menschen in der assistierten Automatisierungsstufe zu unterstützen.
Stufe 1: Assistiert
In dem unterstützten Arbeitsablauf wird ein LLM verwendet, um nützliche Daten zu extrahieren. Diesen Prozess bezeichnen wir als strukturierte Datenextraktion.
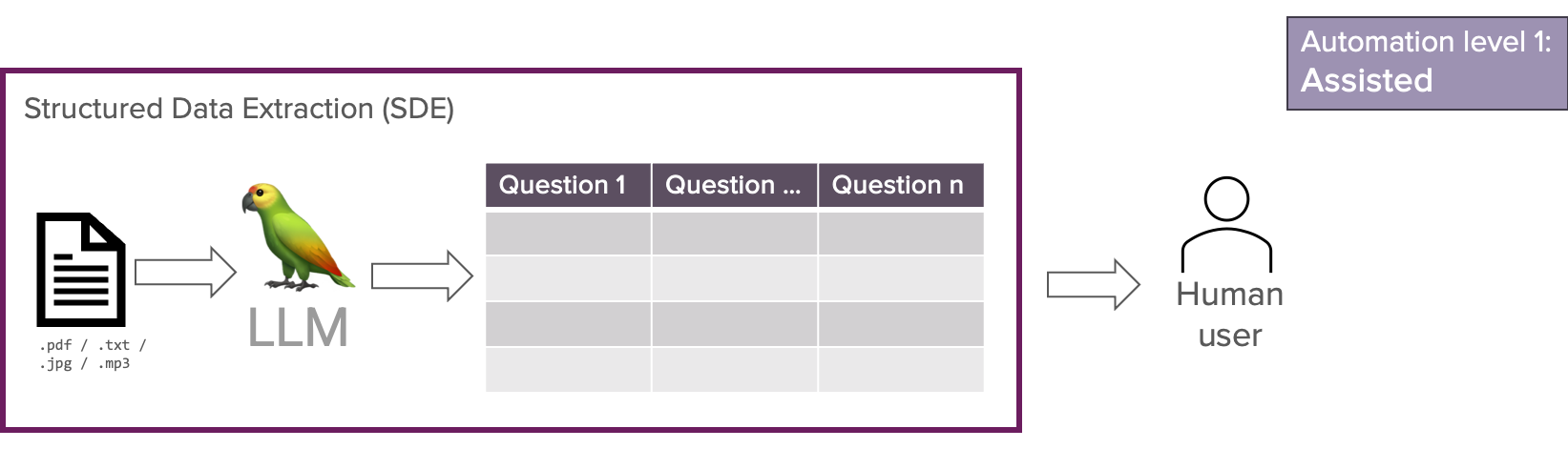
Das kann bereits eine Menge Zeit sparen. Zuvor mussten wir den mühsamen Prozess der Verarbeitung des Dokuments manuell durchführen, um Antworten im Zielformat zu formulieren. Bei dieser Automatisierungsstufe zielen wir jedoch immer noch auf einen menschlichen Benutzer als Ausgabe ab. Der menschliche Benutzer ist für die gesamte Auswertung der LLM-Ausgabe und die Entscheidung, was mit den Daten zu tun ist, verantwortlich. Dies gibt dem Menschen die Kontrolle, kostet aber auch zusätzliche Zeit. Das können wir im Autopilot besser machen.
Stufe 2: Autopilot
Mit dem Autopilot-Workflow gehen wir noch einen Schritt weiter. Die extrahierten Daten werden direkt in ein Data Warehouse aufgenommen, wodurch sich neue Automatisierungsmöglichkeiten ergeben. Mit den Daten im Data Warehouse können die Daten effizienter genutzt werden. Wir können die Daten nun für Dashboards und Einblicke sowie für Anwendungsfälle des maschinellen Lernens nutzen.
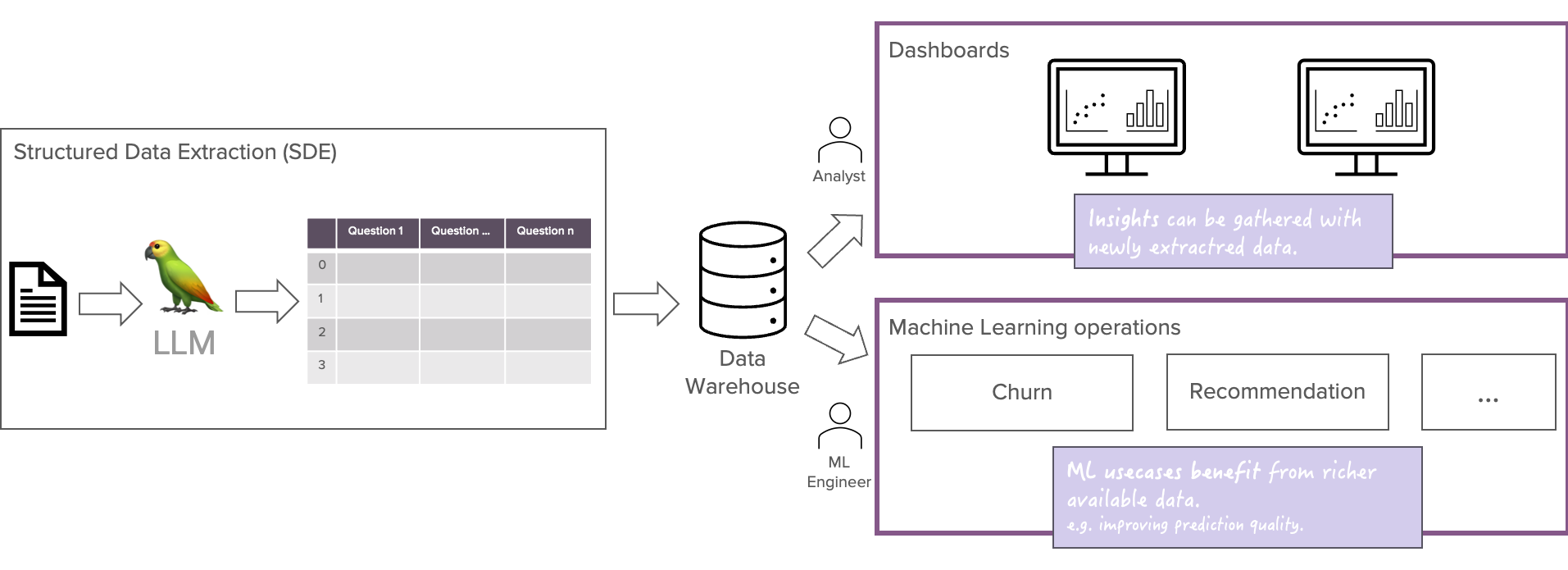
Die direkte Aufnahme dieser Daten in ein Data Warehouse kann in der Tat von Vorteil sein. Aber mit der Einführung dieser automatisierten Aufnahme müssen wir auch vorsichtig sein. Die Nutzer des Data Warehouse sind weiter vom Extraktionsprozess entfernt und können die Qualität der Daten nicht beurteilen. Wir müssen uns immer fragen: Sind diese Daten zuverlässig?
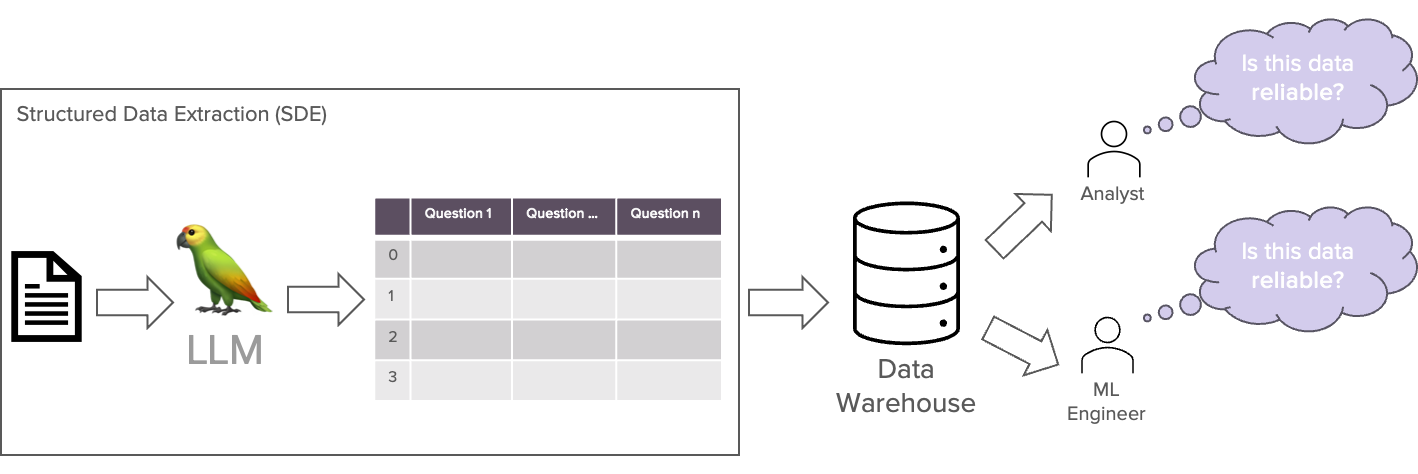
Eine schlechte Datenqualität kann später zu irreführenden Erkenntnissen und schlechten Entscheidungen führen. Das ist nicht das, was wir wollen! Wir brauchen quantifizierte Metriken, die uns über die Zuverlässigkeit der Daten informieren. Diejenigen, die sich mit dem Datensatz auskennen und die am Extraktionsprozess beteiligt sind, müssen uns dabei helfen. Dies sind in der Regel ein KI-Ingenieur und ein Fachexperte. Wir müssen einen Bewertungsschritt einführen.
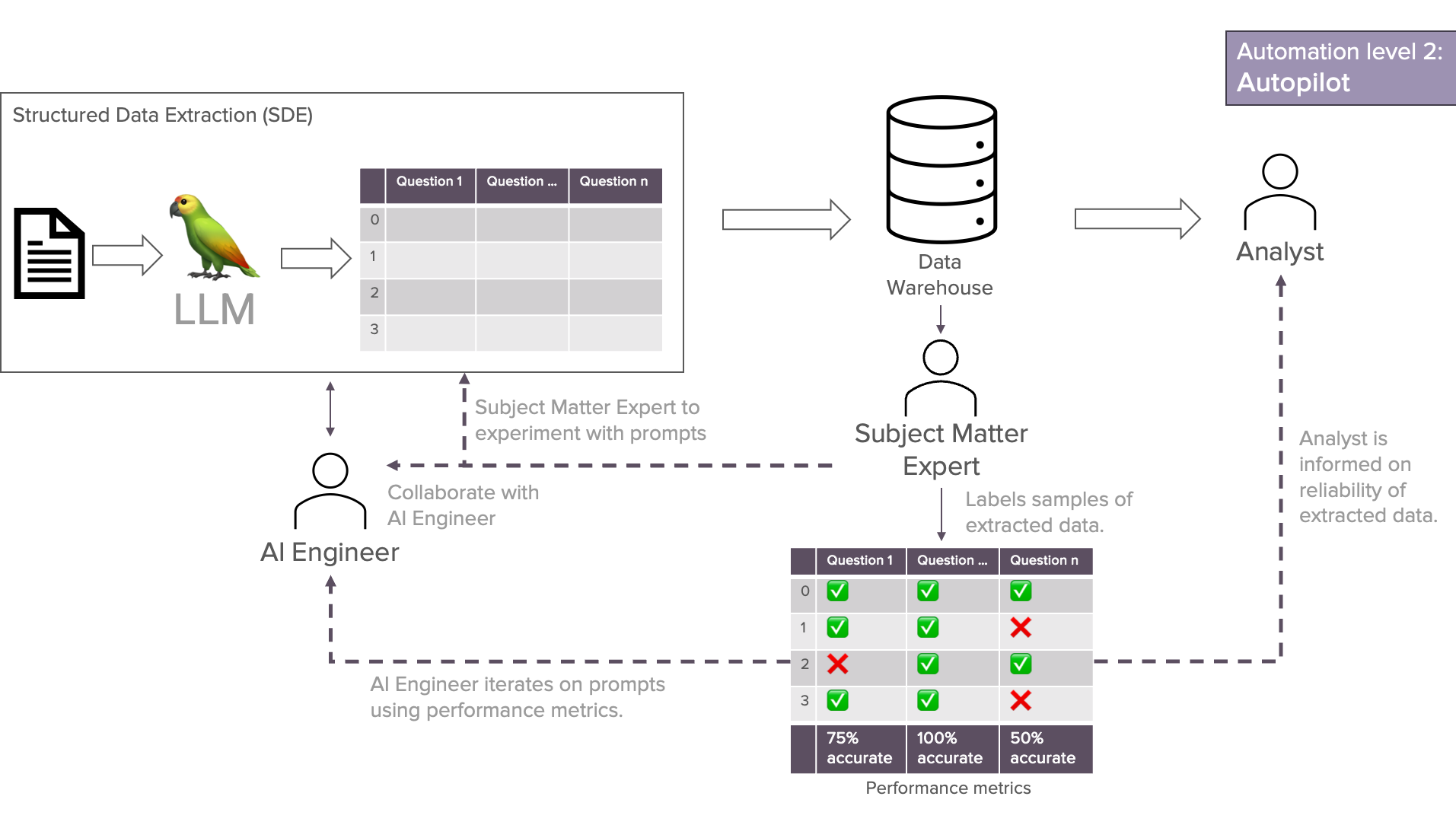
Es werden weitere Schritte eingeführt, die den Menschen in der Schleife halten. Diese Schritte sind jedoch notwendig. Der Fachexperte spielt eine Schlüsselrolle bei der Gewährleistung der Qualität und Zuverlässigkeit der Daten. Dadurch erhalten Data Warehouse-Kunden das Vertrauen, das sie suchen, und gleichzeitig kann der KI-Ingenieur das System zur Extraktion strukturierter Daten systematischer verbessern. Wenn der Fachexperte selbst Teil des Prompting-Prozesses ist, verkürzt sich die Iterationszeit und der Kontext geht bei der Übersetzung zwischen dem KI-Ingenieur und dem Fachexperten nicht verloren. Eine Win-Win-Situation.
Wir können sogar noch weiter automatisieren. Lassen Sie uns zur letzten Stufe übergehen: Autonom.
Stufe 3: Autonom
Auf dieser Stufe sollten die letzten menschlichen Interaktionen automatisiert werden. Die Bewertung, die zuvor manuell vom Fachexperten vorgenommen wurde, wird nun von Qualitätssicherungs- und Bewertungswerkzeugen übernommen.
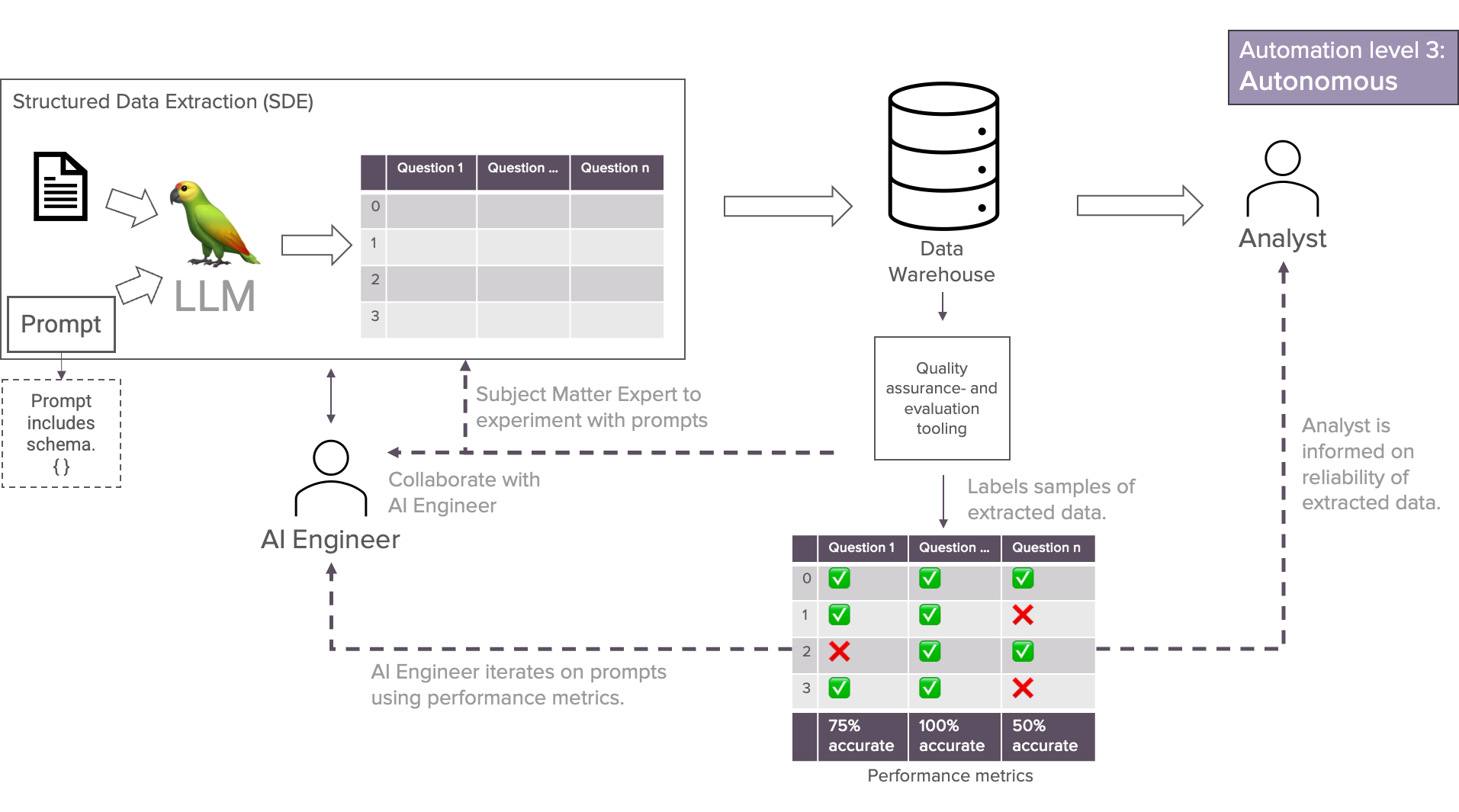
Was meinen wir also mit solchen Werkzeugen? Wir wollen Werkzeuge, die uns dabei helfen, das Ergebnis und die Qualität unserer Daten ohne minimales menschliches Eingreifen zu gewährleisten. Das können zum Beispiel LLM-as-a-Judge-Systeme sein. Der Aufwand, der erforderlich ist, um solche Systeme erfolgreich zu implementieren und sie sicher zu betreiben, ist jedoch hoch. Man erhält einen Gegenwert durch zusätzliche Automatisierung, aber die Frage ist, ob dies den Aufwand und die Kosten wert ist. Lassen Sie uns die Automatisierungsgrade vergleichen und das Potenzial zusammenfassen.
3. Das Automatisierungspotenzial
Wir haben jede der vier verschiedenen Automatisierungsstufen für die Datenextraktion mit GenAI kennengelernt. Außerdem haben wir für jede Stufe erforscht, wie ein System zur strukturierten Datenextraktion architektonisch aussehen würde. Das ist großartig, aber wo liegt nun das meiste Potenzial? Lassen Sie uns zunächst die Automatisierungsstufen wie folgt zusammenfassen:
| Ebene | Automatisierung | Beschreibung | Mensch-im-Schleifen-Modus |
|---|---|---|---|
| 0 | Manuell | Der Mensch führt alle Arbeiten aus. Der Mensch ist für die Datenextraktion, die Qualitätssicherung und die Verwendung der Daten verantwortlich. |
Ja |
| 1 | Assistiert | Der Mensch wird bei den Aufgaben unterstützt, hat aber immer noch die Kontrolle und die Verantwortung. Die Daten werden mithilfe eines LLM extrahiert. Die extrahierten Daten werden zur Unterstützung menschlicher Benutzer verwendet. |
Ja |
| 2 | Autopilot | Die Aufgaben sind weitgehend automatisiert - der Mensch überwacht sie. Die extrahierten Daten werden direkt in ein Data Warehouse eingefügt. Eine systematische Auswertung ist notwendig und die Einbeziehung von Fachexperten ist entscheidend. |
Ja |
| 3 | Autonome | Vollständig automatisierte Aufgaben. Der Auswertungsschritt soll mit Hilfe von Qualitätssicherungs- und Auswertungswerkzeugen automatisiert werden. Vollständig automatisierte Pipelines: kein menschliches Eingreifen oder Überwachung. |
Nein |
Nehmen wir an, Sie denken über die Implementierung eines Anwendungsfalls zur Datenextraktion nach. Was ist das ultimative Ziel? Das ultimative Ziel muss nicht immer darin bestehen, so viel wie möglich zu automatisieren: Es sollte darin bestehen, einen Mehrwert zu schaffen. Denn vielleicht können Sie von Ihrem Anwendungsfall weitgehend genug profitieren, wenn Assisted- oder Autopilot-Automatisierung angewendet wird und die zusätzliche Investition in eine vollständige Automatisierung lohnt sich nicht. Wenn wir das Beispiel der Menükarte von vorhin nehmen, wie sähe dann die potenzielle Zeitersparnis aus?
Zeitersparnis bei der Automatisierung der Datenextraktion (Beispiel):
30 Minuten (manuell) → 5 Minuten (assistiert) → 1 Minute (Autopilot) → 0 Minuten (autonom).
Wir können sehen, dass die Zeitersparnis nicht linear ist. Je mehr Automatisierung wir anwenden, desto weniger Zeit sparen wir. Dabei ist der letzte Schritt am schwierigsten und am teuersten zu implementieren. Es lohnt sich nicht immer, den Aufwand und die Kosten für diesen letzten Schritt zu betreiben. Dies sind die abnehmenden Erträge der Automatisierung, die sich wie folgt darstellen lassen:
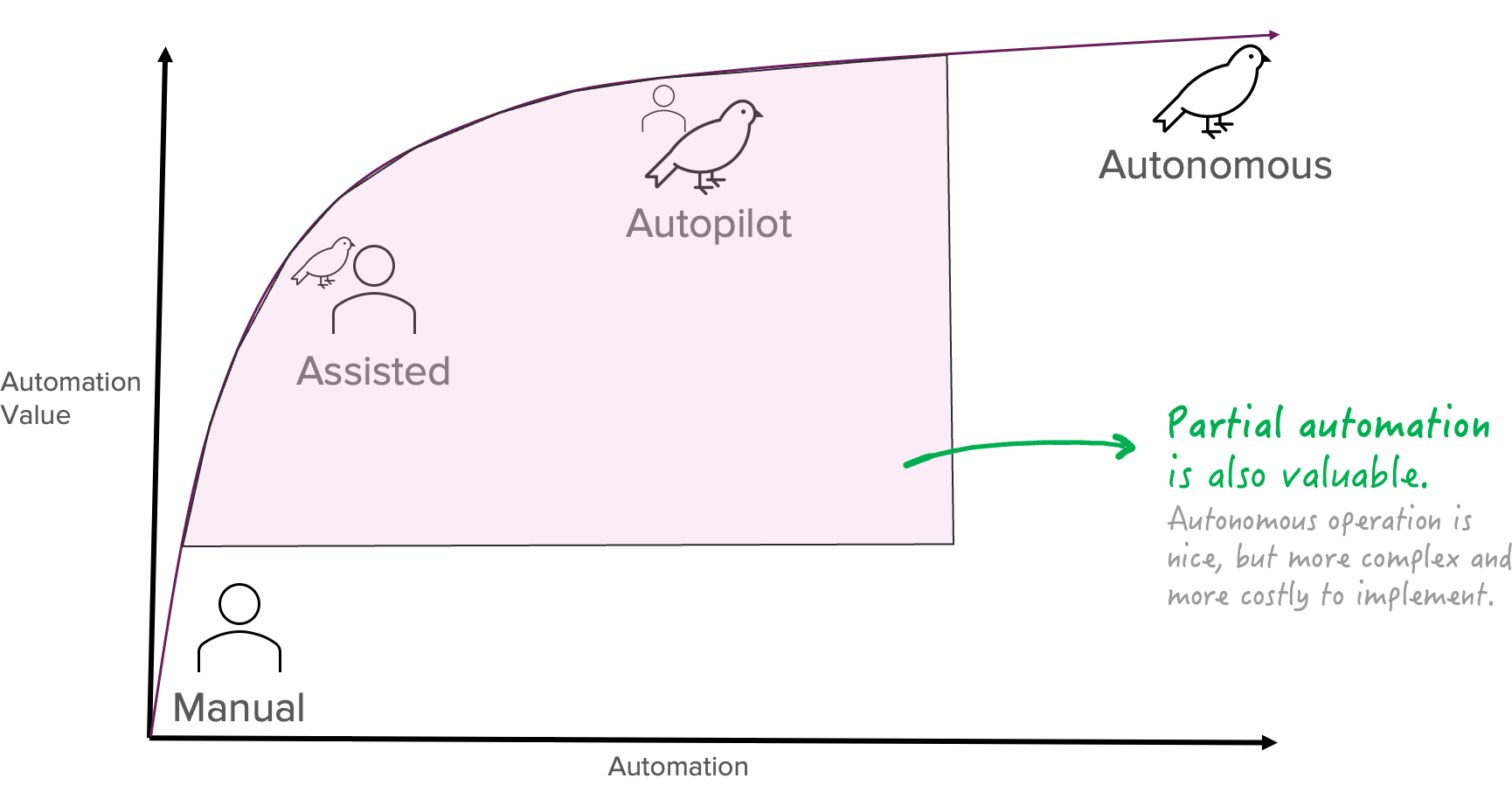
Lassen Sie uns die Dinge zusammenfassen. Zusammenfassend lässt sich sagen, dass GenAI für die Datenextraktion ist:
- Nützlich für eine Vielzahl von Anwendungsfällen mit verschiedenen Datentypen wie Text, Bilder, PDFs und Audio.
- Wahrscheinlicher ist ein ROI aufgrund von 1) günstigeren Modellen, 2) größeren Kontextfenstern und 3) leistungsfähigeren Modellen, die multimodale Daten verarbeiten können.
- Sehr gut geeignet für eine Teilautomatisierung: Sie können einen geschäftlichen Nutzen erzielen, ohne dass zusätzliche Investitionen für eine vollständige Automatisierung erforderlich sind.
Viel Glück mit Ihren eigenen Anwendungsfällen für die GenAI-Datenextraktion ♡.
Verfasst von

Jeroen Overschie
Machine Learning Engineer
Jeroen is a Machine Learning Engineer at Xebia.




Contact