Blog
Von 0 auf MLOps mit ❄️ Snowflake Data Cloud in 3 Schritten mit dem Kedro-Snowflake Plugin

MLOps auf Snowflake Data Cloud
Der Bereich des maschinellen Lernens entwickelt sich ständig weiter, und da die Auswahl an verwalteten und cloud-nativen maschinellen Lerndiensten täglich wächst, kann es eine Herausforderung sein, sich in den verfügbaren Optionen zurechtzufinden. Bei der Fülle an verwalteten und Cloud-nativen maschinellen Lerndiensten ist es entscheidend, die richtige Plattform für die Ausführung von maschinellen Lernpipelines und die Bereitstellung von trainierten Modellen zu wählen. Allerdings gibt es in der MLOps-Landschaft nach wie vor drei große Probleme:
- Fehlender einfacher Zugriff auf die wertvollen Daten des Unternehmens,
- der Bedarf an schneller lokaler Iteration in ML-Pipelines
- Fehlen eines nahtlosen Übergangs zur Cloud-Umgebung.
Snowflake ist ein leistungsstarkes Data Warehouse und Snowpark ist einfach zu bedienen. Zusammen sind sie ein guter Kandidat für die Erstellung komplexer ML-Pipelines. Wenn Sie mit Snowpark noch nicht vertraut sind, gibt es eine Menge großartiger Artikel, in denen die Kernkonzepte vorgestellt werden und wie Sie es für das Schreiben von Data Science- und Machine Learning (ML)-Code verwenden können, z.B. hier , hier oder hier .
Es gibt jedoch zumindest einige Unzulänglichkeiten der derzeit vorgeschlagenen Ansätze, die noch nicht behoben wurden:
- Orchestrierung von ML-Pipelines - im derzeitigen Zustand können zwei Strategien verfolgt werden:
- Verwendung eines externen Orchestrator-Dienstes oder -Tools, wie AzureML Pipelines oder Apache Airflow, um Snowpark-Code direkt aufzurufen
- Manuelles Einbinden von Snowpark-Code in Python UDFs und diese für den Aufbau eines gerichteten azyklischen Graphen (DAG) der Schritte der nativen Snowflake Aufgaben Mechanismus
Leider scheint keine dieser Methoden frei von Mängeln zu sein. Bei der ersten müssen zusätzliche Planungskomponenten in die Architektur aufgenommen werden, was sie komplexer und weniger plattformunabhängig macht. Die zweite Methode ist weniger benutzerfreundlich, da sie nicht nur die Entwicklung von Trainingscode erfordert, sondern auch die Definition von Snowflake DAGs von Aufgaben mit Hilfe von einfachem SQL oder Terraform Programmiersprache.
- ML-Modell-Lebenszyklusmanagement - es gibt keine Automatisierung, die es einfach macht, Trainingspipelines zwischen verschiedenen Stadien/Laufzeitumgebungen - d.h. Entwicklung - Test - Produktion - zu fördern/einzusetzen. Dies erfordert die Vorbereitung von Continuous Integration/Continuous Training (CI/CT) Prozessen auf eigene Faust.
- Code-Standardisierung und Projektvorlagen - in seinem derzeitigen Zustand verfügt Snowpark über keinen eingebauten Mechanismus für die Strukturierung von Code, Unit-Tests oder die automatische Erstellung von Dokumentation.
Die obige Liste der Herausforderungen zeigt deutlich, dass die Integration der Snowflake-Umgebung mit einem MLOps-Framework wie Kedro fehlt.
Heute kündigen wir stolz eine Lösung an, die diese Lücke schließen wird - die kedro-Snowflake Plugin. Im nächsten Beitrag werden wir Sie auch durch die gesamte MLOps-Plattform und die Bereitstellung von ML-Modellen auf Snowflake führen. Doch lassen Sie uns zunächst einen Blick darauf werfen, was Kedro ist, und dann in 3 einfachen Schritten eine ML-Pipeline in Kedro erstellen und in der Snowflake-Umgebung ausführen.
Kedro - das MLOps Framework
Kedro ist ein weit verbreitetes, quelloffenes Python-Framework, das den Anspruch erhebt, die Technik in die Welt der Datenwissenschaft zurückzubringen. Die Gründe für die Verwendung von Kedro als Framework für die Erstellung von wartbarem und modularem Trainingscode ähneln in vielerlei Hinsicht der Bevorzugung der Terraform-Technologie gegenüber dem nativen SDK eines Cloud-Anbieters für die Bereitstellung von Infrastrukturen und lassen sich in den folgenden Punkten zusammenfassen:
- Standardisierung des ML-Projektlayouts,
- Portabilität von ML-Pipelines,
- Wiederverwendbarkeit von Codebasis, Modulen oder sogar ganzen Pipelines,
- eine schnellere Entwicklungsschleife dank der Möglichkeit, Pipelines lokal auszuführen/zu testen,
- eine klare und wartbare Codebasis ohne Abhängigkeiten von Cloud-spezifischen APIs (in Analogie zu Terraform-Anbietern) und eine Trennung der Laufzeitkonfigurationen
- Multi-Cloud-Bereitschaft
- Haken für die weitere Automatisierung,
- nahtlose Integration mit dem Plugin-Mechanismus mit Tools von Drittanbietern wie MLflow, Pandas-Profiling oder Docker,
- geeignet für die einfache Integration mit CI/CD-Tools für eine echte MLOps-Erfahrung.
Wir bei GetInData|Part of Xebia sind starke Befürworter des Kedro-Frameworks als Technologie unserer Wahl für die Bereitstellung robuster und benutzerfreundlicher MLOps-Plattformen auf vielen Cloud-Plattformen. Mit unseren Open-Source-Kedro-Plugins können Sie Ihren Pipeline-Code schreiben und sich auf das Zielmodell konzentrieren. Mit den Kedro-Plugins können Sie es dann auf jeder unterstützten Plattform bereitstellen (siehe: Kedro ausführen... überall? Pipelines für maschinelles Lernen auf Kubeflow, Vertex AI, Azure und Airflow - GetInData ), ohne den Code zu ändern, so dass lokale Iterationen schnell und der Wechsel in die Cloud nahtlos erfolgen kann.
Ab Mai 2023 unterstützen wir:
- Google Cloud Plattform ( http://github.com/getindata/kedro-vertexai ),
- Microsoft Azure ( https://github.com/getindata/kedro-azureml ),
- Amazon Web Services ( https://github.com/getindata/kedro-sagemaker ),
- Luftstrom ( https://github.com/getindata/kedro-airflow-k8s ),
- Kubeflow ( https://github.com/getindata/kedro-kubeflow ).
Jetzt ist die Zeit für Snowflake gekommen...
Kedro-Snowflake Plugin hinter den Kulissen
Kedro-Snowflake ist unser neuestes Plugin, mit dem Sie komplette Kedro-Pipelines in Snowflake ausführen können. Im Moment unterstützt es:
- Kedro-Starter , um Sie schnell auf Touren zu bringen
- automatische Erstellung von Snowflake Stored Procedures aus Kedro-Knoten (mit Snowpark SDK )
- Übersetzung der Kedro-Pipeline in Snowflake-Aufgaben-DAGs
- Ausführung der Kedro-Pipeline vollständig in Snowflake, ohne ein externes System
- unter Verwendung von Kedros offiziellem SnowparkTableDataSet
- automatische Speicherung von Datenzwischenergebnissen als Transiente Tabellen (wenn Snowparks DataFrames verwendet werden)
Die Kernidee dieses Plugins besteht darin, eine Kedro-Pipeline programmatisch zu durchlaufen und ihre Knoten in entsprechende Stored Procedures zu übersetzen und sie gleichzeitig in Snowflake-Tasks zu verpacken, wobei die Abhängigkeiten zwischen den Knoten erhalten bleiben, um genau die gleiche Pipeline-DAG auf der Snowflake-Seite zu bilden. Das Endergebnis ist eine Snowflake DAG von Aufgaben wie diese:
Drücken Sie die Eingabetaste oder klicken Sie, um das Bild in voller Größe anzuzeigen 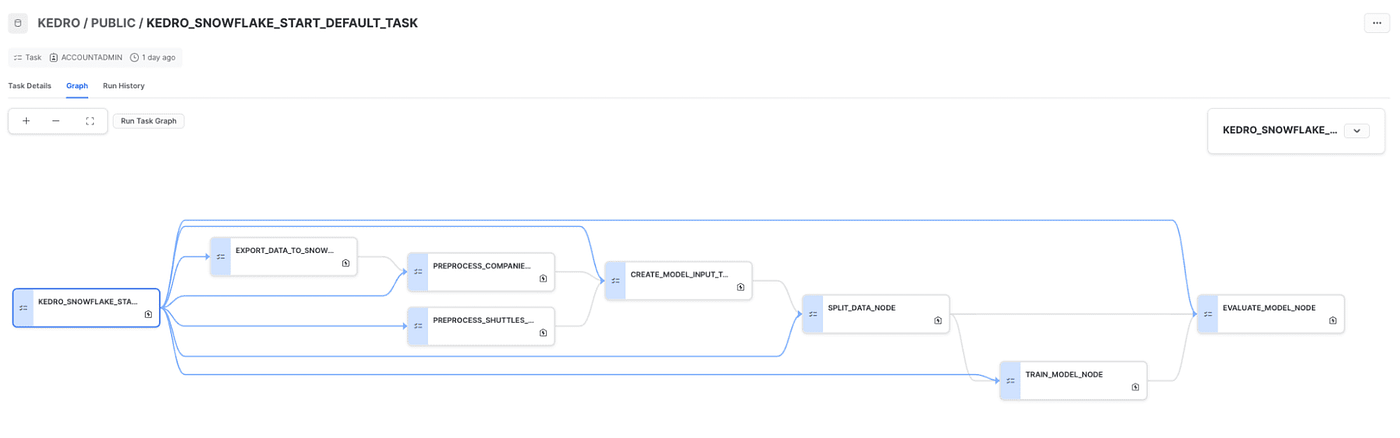
die der Kedro-Pipeline entsprechen:
Drücken Sie die Eingabetaste oder klicken Sie, um das Bild in voller Größe zu sehen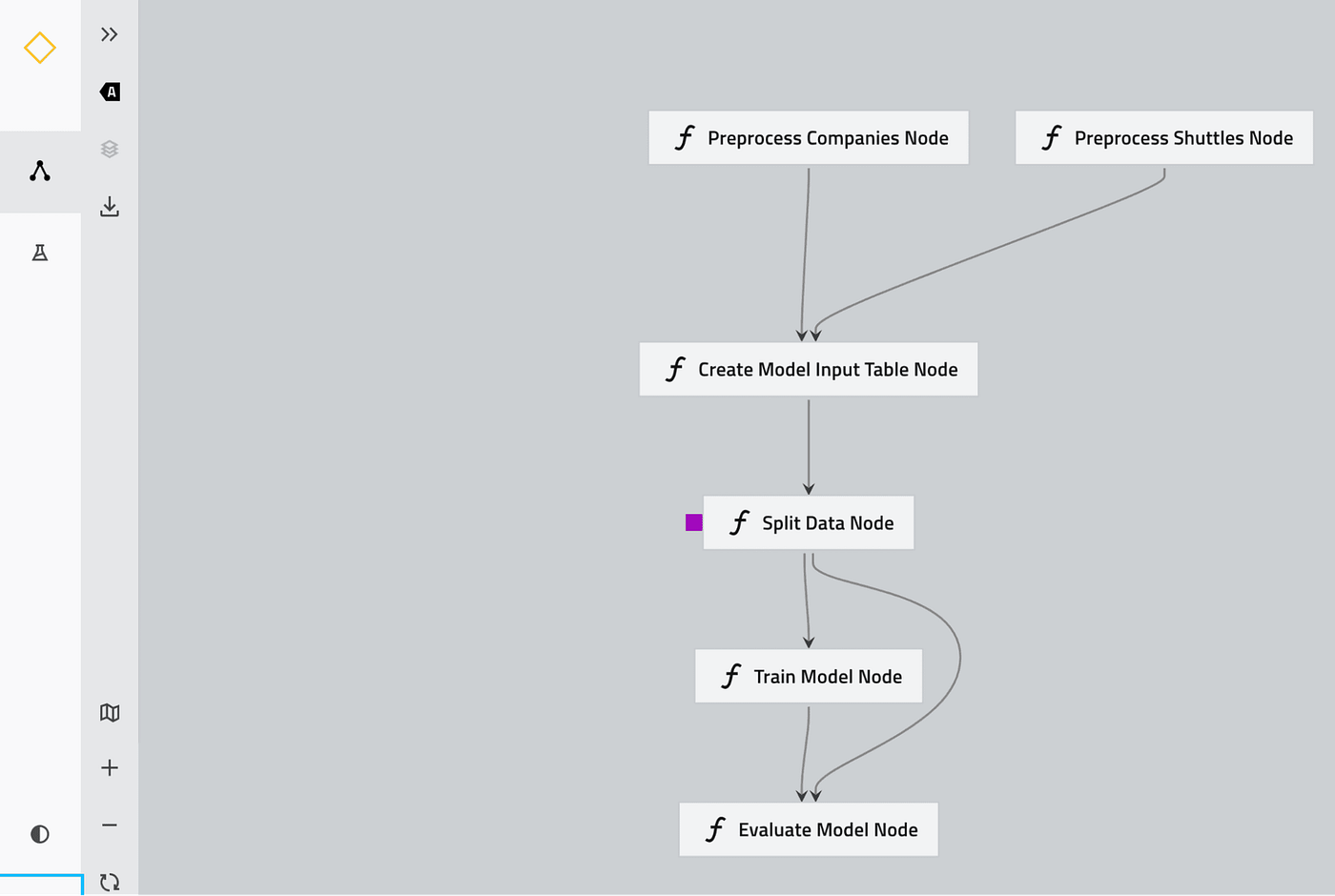
Es kommt auch mit einem eingebauten
snowflights
(Portierung des offiziellen
spaceflights
, erweitert um Snowflake-bezogene Funktionen), mit dem Sie Ihre Snowflake-basierten ML-Projekte in Sekundenschnelle starten können.
Schnellstart - Ihre ML-Pipeline in 3 Schritten mit dem Kedro-Snowflake-Plugin
Beginnen wir mit den
Schneeflüge
Kedro-Starter. Bereiten Sie zunächst Ihre Umgebung vor (d.h. Ihre bevorzugte virtuelle Python-Umgebung). Installieren Sie zunächst unser kedro-snowlake Plugin:
pip install "kedro-snowflake>=0.1.2"Als nächstes erstellen Sie Ihre erste ML-Pipeline mit Kedro und Snowlake. Der Starter führt Sie durch die Konfiguration der Snowflake-Verbindung, einschließlich der Angaben zum Snowlake-Konto und zum Warehouse:
kedro new --starter=snowflights --checkout=0.1.2Führen Sie dann die Starter-Pipeline aus:
kedro snowflake run --wait-for-completionDas war's! Sie können die Ausführung der ML-Pipeline in der Snowflake-Benutzeroberfläche sehen:
Drücken Sie die Eingabetaste oder klicken Sie, um das Bild in voller Größe anzuzeigen 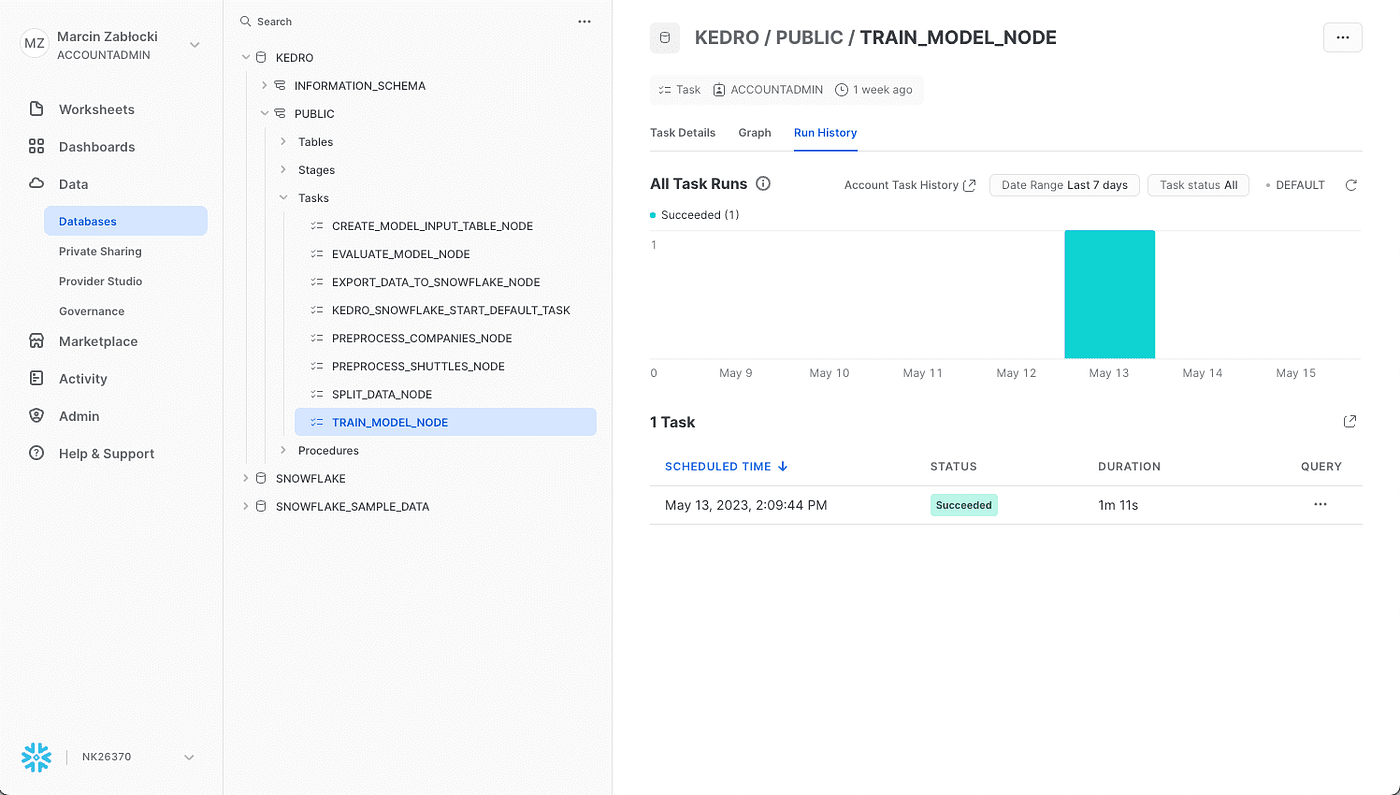
und im Terminal:
Drücken Sie die Eingabetaste oder klicken Sie, um das Bild in voller Größe zu sehen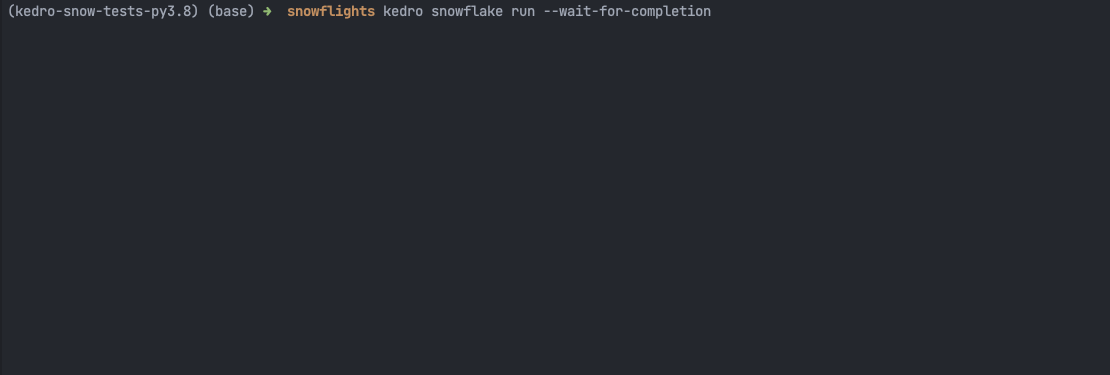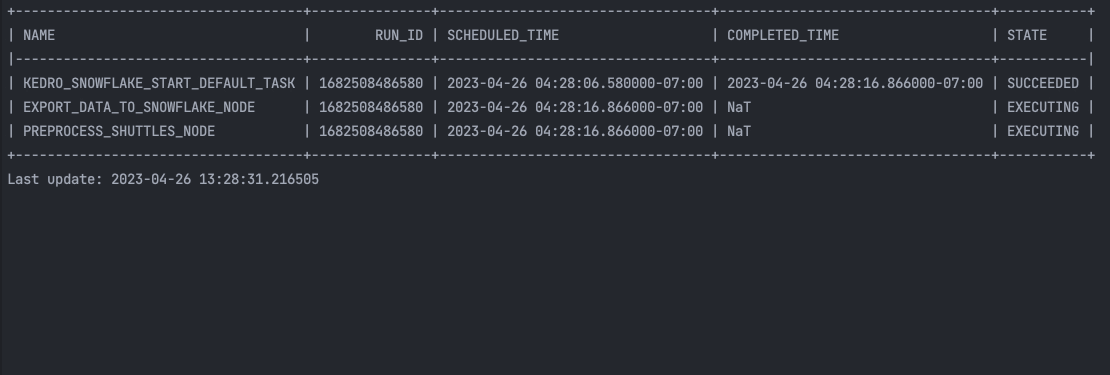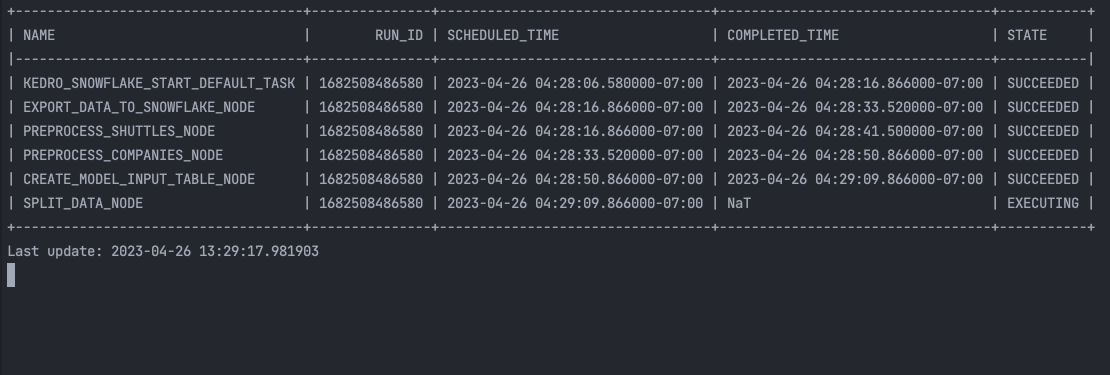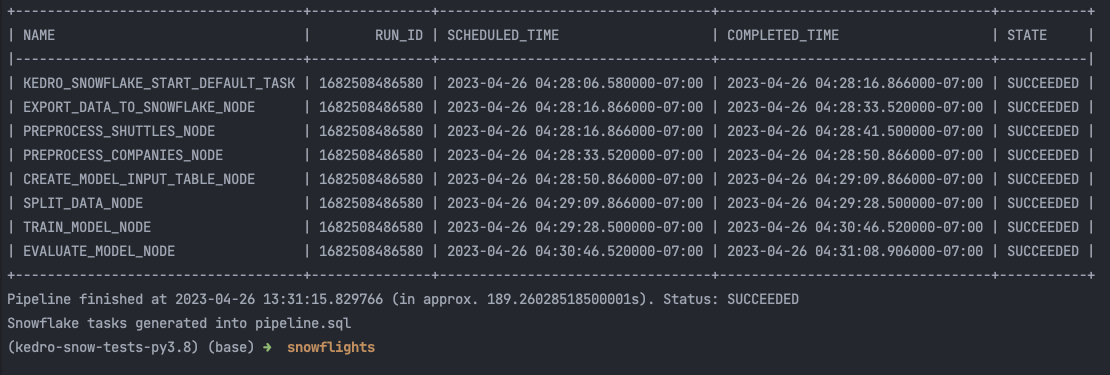
Dieser Starter zeigt die Kedro-Snowflake-Integration, einschließlich der Verbindung mit Snowflake, der Umwandlung einer ML-Pipeline in Kedro in ein Snowflake-kompatibles Format und der Ausführung der Pipeline in der Snowflake-Umgebung. Sie können Ihre eigene Pipeline auf der Grundlage dieses Starters oder von Grund auf mit unserem Plugin erstellen. Weitere Informationen finden Sie in der folgenden Plugin-Dokumentation: Kedro Snowflake Plugin Dokumentation!
Wir empfehlen Ihnen auch unser Video-Tutorial, in dem Marcin Zabłocki zeigt, wie Sie eine ML-Pipeline auf Snowflake ausführen.
Zusammenfassung
In diesem kurzen Blogbeitrag stellen wir unser neuestes kedro-snowflake Plugin vor. Dank dieses Plugins können Sie Ihre ML-Pipelines in Kedro erstellen und sie in einer skalierbaren Snowflake-Umgebung in drei einfachen Schritten ausführen. Bleiben Sie dran für den zweiten Teil dieses Blogposts, in dem wir die gesamte MLOps-Plattform und die Bereitstellung von ML-Modellen mit dem kedro-snowflake-Plugin als Kernkomponente vorstellen werden.
Interessieren Sie sich für ML- und MLOps-Lösungen? Wie können Sie ML-Prozesse verbessern und die Lieferfähigkeit von Projekten steigern? Sehen Sie sich unsere MLOps-Demo an und melden Sie sich für eine kostenlose Beratung an.
Verfasst von
Marcin Zabłocki
Unsere Ideen
Weitere Blogs




Contact