
Die effiziente und genaue Verwaltung von Daten ist eine große Herausforderung in der sich ständig weiterentwickelnden Landschaft der Stream-Verarbeitung. Apache Flink, ein leistungsstarkes Framework für die Datenverarbeitung in Echtzeit, bietet robuste Lösungen, hat aber auch seine Tücken. Ein kritischer Aspekt ist der Umgang mit Race Conditions, insbesondere bei der Arbeit mit Flink SQL für die Stream-Verarbeitung.
Dieser Blog-Beitrag befasst sich mit den Feinheiten von Race Conditions und Changelogs in Flink SQL. Dabei werden die potenziellen Fallstricke und Lösungen zur Gewährleistung von Datenkonsistenz und Zuverlässigkeit untersucht. Wir gehen auf die Mechanik von Changelogs, die Auswirkungen von Race Conditions und praktische Strategien zur Entschärfung dieser Probleme ein, damit Sie das volle Potenzial von Flink SQL in Ihren Streaming-Anwendungen nutzen können.
Rennbedingungen verstehen
Bei der Parallelverarbeitung können Race Conditions auftreten. Daten können mit unterschiedlichen Geschwindigkeiten und auf unterschiedlichen Wegen verarbeitet werden . Ohne Synchronisierung, die den Durchsatz und die Leistung verringert, gibt es keine Garantie, dass die Daten die gleiche Reihenfolge wie zu Beginn der Pipeline beibehalten. Dies ist ein großes Problem, wenn die Eingabereihenfolge am Ende erwartet wird, und kann zu Problemen wie verpassten Aktualisierungen und Datenbeschädigungen führen.
Eine Race Condition, die auch als Race Hazard bezeichnet wird, tritt auf, wenn ein System oder eine Anwendung von unkontrollierbaren Faktoren wie dem Timing, der Ereignisfolge, externen oder gemeinsam genutzten Zuständen oder Ressourcen beeinflusst wird. Diese Abhängigkeit kann zu falschen oder unvorhersehbaren Ergebnissen führen.
Flink, ein Framework für die Streaming-Datenverarbeitung, minimiert diese Gefahren. FIFO-Puffer, die für den Datenaustausch zwischen Teilaufgaben verwendet werden, garantieren die Reihenfolge der Ereignisse, die auf demselben Pfad verarbeitet werden. Dennoch kann es bei Ereignissen, die von verschiedenen Teilaufgaben parallel verarbeitet werden, zu Wettlaufsituationen kommen.
Stellen wir uns eine einfache Verknüpfung vor, die in Flink SQL geschrieben und parallel ausgeführt wird, wie in der Abbildung unten gezeigt.
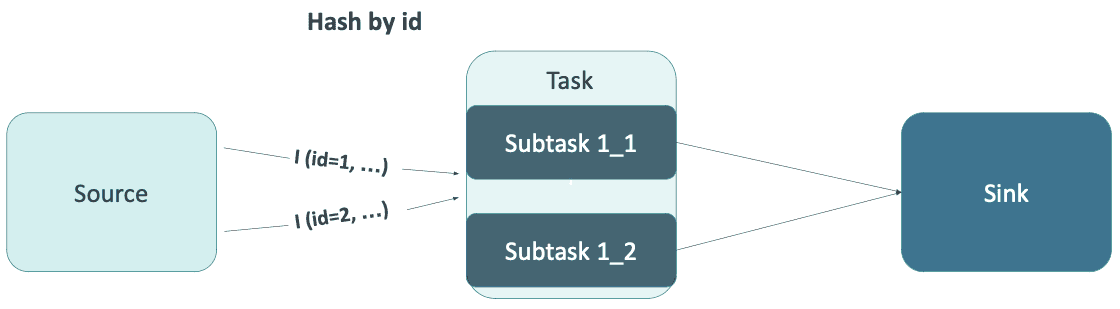
Die Quelltabelle erzeugte zwei folgende Einfügezeilenereignisse: I (id=1, ...) und I (id=2, ...). Diese Ereignisse wurden anhand des Feldes id gemischt und an verschiedene Teilaufgaben übertragen. Wie wird die Reihenfolge der Ereignisse in der Senke sein? Das ist nicht deterministisch. Flink bewahrt nur die Reihenfolge der Ereignisse, die von einer bestimmten Unteraufgabe verarbeitet werden. Es gibt keine Synchronisierung oder einen gemeinsamen Status zwischen den Unteraufgaben, was bei korrelierten Ereignissen, wie z.B. Aktualisierungen derselben Zeile, problematisch sein kann.
Changelogs in Flink SQL
Flink SQL hat das Konzept eines Changelogs übernommen, das die folgenden Zeilentypen einführt:
- Einfügen (+I)
- UpdateBefore (-U)
- UpdateAfter (+U)
- Löschen (-D)
Dieses Konzept ist aus relationalen Datenbanken bekannt (z.B. Change Data Capture) und hilft dabei, nachträgliche Änderungen in Datenbanken zu verfolgen.
Flink SQL führt das Konzept eines Änderungsprotokolls ein, das Änderungen an Daten anhand von Zeilentypen wie Insert (+I), UpdateBefore (-U), UpdateAfter (+U) und Delete (-D) verfolgt. Dieses System hilft bei der Verwaltung der Datenkonsistenz, kann aber dennoch Probleme verursachen, wenn Ereignisse asynchron verarbeitet werden.
Während +I, +U und -D intuitiv sind, scheint die Bedeutung von -U in der verteilten Verarbeitung etwas unterschätzt zu werden. UpdateBefore fungiert als "technisches" Ereignis, das die Unteraufgabe darüber informiert, dass ein Wert geändert wurde und nun abgelaufen ist. Dies ermöglicht die Bereinigung des Zustands, verhindert die Freigabe ungültiger Join-Zeilen usw. Die meisten Senken überspringen -U Ereignisse, so dass -U eine Art graue Eminenz ist. Dies ist außerhalb des Auftrags nicht sichtbar, spielt aber eine entscheidende Rolle bei der Datenverarbeitung.
Betrachten wir eine reguläre Eins-zu-Eins-Verknüpfung zwischen den Tabellen STORE und ADDRESS, beschrieben durch eine einfache Abfrage in FlinkSQL:
INSERT INTO STORE_WITH_ADDRESS
SELECT
s.id,
s.name,
s.a_id,
a.city,
a.street
FROM
STORE s
LEFT JOIN
ADDRESS a
ON
s.a_id = a.a_idZunächst erhielt der Auftrag einige Zeilen aus der Tabelle ADDRESS, gefolgt von der Einfügung und Aktualisierung (mit geänderter Adress-ID) aus der Tabelle STORE.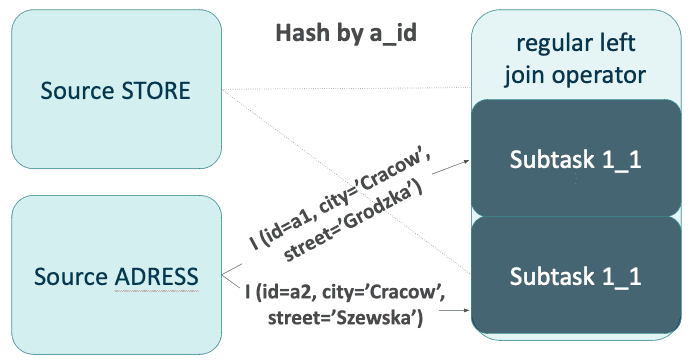
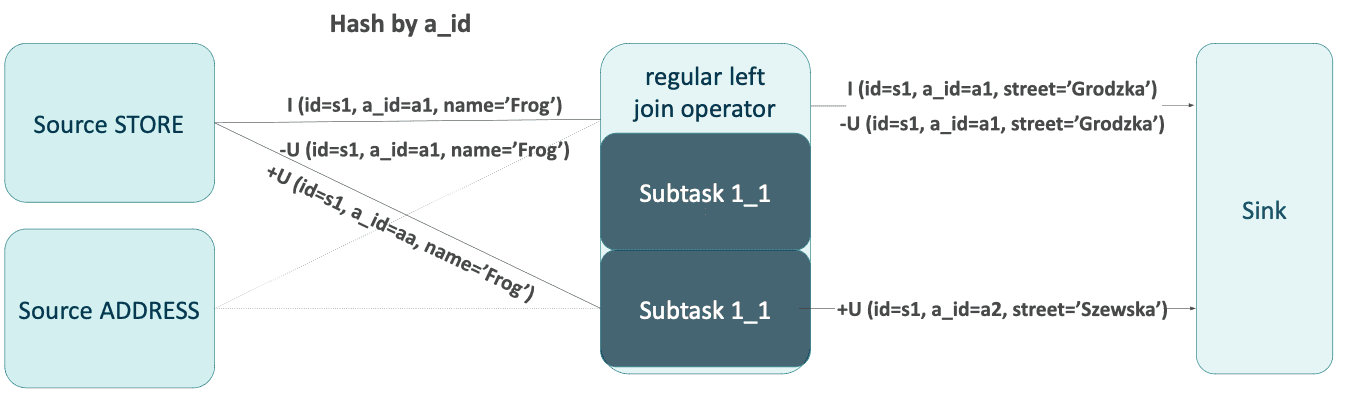
Die Reihenfolge der Ereignisse in der Senke ist nicht deterministisch. Mögliche Szenarien sind:
I, -U, +U (erwartet)
I, +U, -U
+U, I, -U
Die Senke beendet die Datenverarbeitung im Flink-Auftrag. Sie kann in einen externen Speicher schreiben oder die Ergebnisse einfach ausdrucken. Er verarbeitet die Ereignisse in der Reihenfolge, in der sie auftreten. Der upsert-Kafka-Connector speichert zum Beispiel nur Werte (ohne Zeilenart) und überspringt UpdateBefore-Ereignisse. Ein Delete-Ereignis wird als Schlüssel mit einem Null-Nachrichtentext dargestellt. Eine falsche Reihenfolge der Ereignisse, wie im dritten Szenario, wirkt sich auf die Korrektheit der Ausgabe aus. Beachten Sie, dass sich das Geschäft aus dem Beispiel jetzt in der Szewska-Straße und nicht in der Grodzka-Straße befindet!
Spüle Upsert Materializer
Anhand eines Änderungsprotokolls können Sie die richtige Reihenfolge der Ereignisse nachvollziehen und sie gegebenenfalls korrigieren. Ein Einfügeereignis sollte am Anfang des Streams oder nach einem Löschereignis stehen. Ist dies nicht der Fall, ist es entweder verspätet oder hat das Ereignis Löschen überholt. Im dritten Szenario ist es verspätet, was durch den Rückzug (-U) bestätigt wird.
Auf der Grundlage dieser Schlussfolgerung wurde ein Algorithmus entwickelt und als Sink-Upsert-Materialisierer implementiert. Sie können mehr Details darüber lesen hier . Der Flink-Planer fügt ihn bei Bedarf automatisch vor der Senke ein. Sie können dies vor der Senke des Kafka-Konnektors erwarten, aber es wird weggelassen, wenn Sie die Ergebnisse einfach ausdrucken. Dies korrigiert zwar die Reihenfolge der Daten, hat aber einige Nachteile und Einschränkungen:
- Sie ist zustandsabhängig und wirkt sich auf die Leistung und das Checkpointing aus.
- Die Verwendung dieser Option zusammen mit der TTL-Konfiguration kann die Datenintegrität beeinträchtigen.
- Es erfordert ein vollständiges Änderungsprotokoll, und die Korrektheit der Ergebnisse kann durch fehlende oder unvollständige Rücknahmen beeinträchtigt werden.
- Dynamische und nicht-deterministische Spalten wie CURRENT_TIMESTAMP können zu einer Statusexplosion führen.
Sie können dies deaktivieren, indem Sie: table.exec.sink.upsert-materialize auf "none" setzen.
Beachten Sie, dass der Sink-Materializer nur dann Race Conditions löst, wenn er korrekt funktioniert. Es funktioniert nur, wenn das Änderungsprotokoll gültig ist und es keine Probleme mit dynamischen Spalten gibt. Andernfalls verschlechtert sich nur die Arbeitsleistung.
Außerdem gibt es Szenarien, in denen der Spülenmaterialisierer die einzige Möglichkeit ist, mit Gefahren umzugehen:
- vollständige äußere Verknüpfung (Many-to-many-Beziehungen),
- das Fehlen der Version der Reihe.
Für andere Situationen sollte es möglich sein, eine benutzerdefinierte Versionierung mit Ordering zu erstellen, aber aufgrund der zusätzlichen Komplexität empfehle ich, wenn möglich den Sink Materializer zu verwenden.
Unvollständige Retraktionen
Der Sink Materializer ist kein guter Begleiter für temporale und Lookup-Joins. Es gibt Fälle, in denen er nicht funktionieren wird. Lassen Sie uns das Änderungsprotokoll einer temporalen Verknüpfung analysieren:
Drücken Sie die Eingabetaste oder klicken Sie, um das Bild in voller Größe anzuzeigen 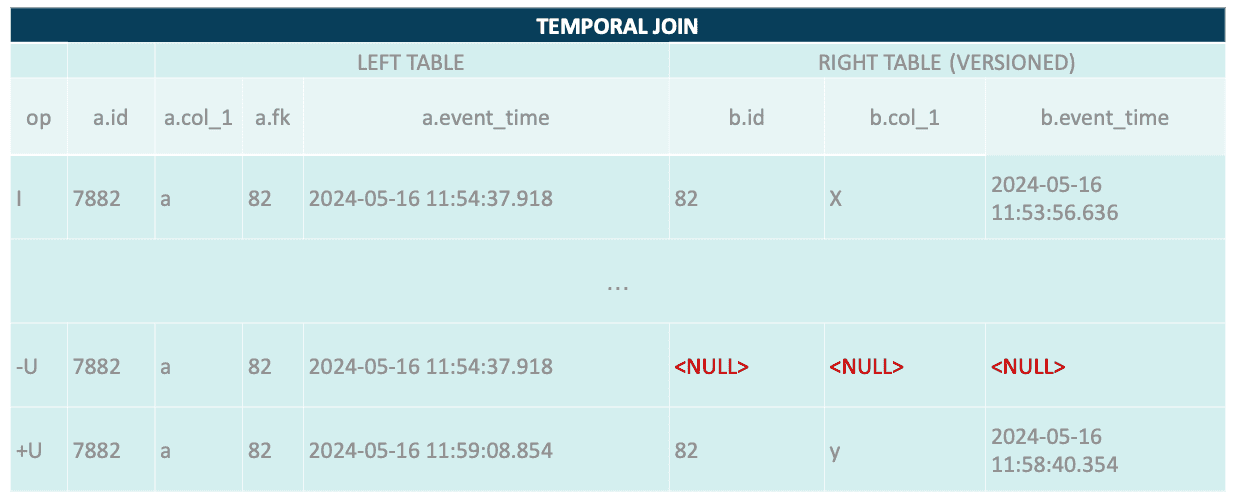
Was ist passiert? Warum sind die Werte auf der rechten Seite Null? Der temporale Verknüpfungsoperator behält die letzte Version der Zeile bei. Er kennt den vorherigen Wert nicht, so dass das UpdateBefore-Ereignis unvollständig ist. Dies kann sich auf den Sink Materializer auswirken, da er möglicherweise nicht in der Lage ist, den Rückzug mit der vorherigen Version abzugleichen.
Diese Situation kann sich verschlimmern, wenn Sie diese Zeilen mit einer regulären Verknüpfung unter Verwendung einer Spalte aus der zeitlichen Tabelle verbinden. Die SQL-Anweisung kann wie der folgende Codeausschnitt aussehen.
SELECT
*
FROM
table_a a
LEFT JOIN
temporal_table for SYSTEM_TIME AS OF a.PROC_TIME AS b
ON
a.fk = b.id
LEFT JOIN
table_c c
ON
b.col_b = c.idDie reguläre Verknüpfung am Ende (mit table_c) wird den Status für die linke Seite gruppiert nach b.col_b beibehalten. Das Zurückziehen (-U) mit b.col_b = NULL wird das Ereignis (id=7882, b.id=82, b.col_b='x') nicht entfernen, da der Schlüssel nicht übereinstimmt. Außerdem wird +U eine neue Zeile hinzufügen (id=7882, b.id=82, b.col_b='y'). Der Status der regulären Verknüpfung hat zwei Werte:
- (id=7882, b.id=82, b.col_b='x')
- (id=7882, b.id=82, b.col_b='y')
Die erste sollte zurückgezogen werden, aber das wird nicht passieren. Ereignisse aus table_c mit id='x' und id='y' werden abgeglichen und weitergereicht, während nur der Abgleich mit 'y' stattfinden sollte.
Der Lookup-Join generiert auch nicht das richtige Änderungsprotokoll. Es handelt sich um einen zustandslosen Operator, der frühere Werte nicht nachverfolgen kann. Das UpdateBefore-Ereignis enthält die gleichen Werte wie UpdateAfter. Ebenso kann es zu Datenverfälschungen kommen, wenn Sie einen regulären Verknüpfungsoperator hinzufügen, der auf den Werten aus einer Nachschlagetabelle basiert.

Beachten Sie, dass der Wert von -U X und nicht Y sein sollte.
Dieses Problem kann umgangen werden, indem Sie das Changelog neu generieren. Flink SQL erlaubt es nicht, ChangelogNormalize direkt hinzuzufügen. Um dies zu erreichen, müssen Sie Zwischenergebnisse speichern und sie z.B. mit dem upsert-Kafka-Connector lesen.
Konfiguration des Time-to-Live-Status
Flink ermöglicht die Konfiguration des Ablaufs des TTL-Status:
- weltweit,
- pro Operator (veröffentlicht in Flink 1.17),
- pro Join mit Hint (Flink 1.19).
Dies kann zwar dazu beitragen, die Größe des Status zu begrenzen und die Arbeitsleistung zu steigern, kann sich aber negativ auf die Korrektheit des Änderungsprotokolls auswirken. Das Fehlen früherer Werte im Status einer regulären Verknüpfung führt dazu, dass unvollständige Retracts erzeugt werden. Dies wirkt sich auf den Sink Materializer aus und kann die Ausgabedaten beschädigen. Sie sollten die TTL-Konfiguration mit Bedacht einsetzen und die möglichen Nebenwirkungen analysieren.
Kafka, Debezium und Metadaten
Der Kafka-Konnektor unterstützt das Debezium-Format für die Verarbeitung von Change Data Capture-Ereignissen. Jede Nachricht enthält Vor- und Nachfelder, die von Flink in separate Zeilen mit den richtigen Typen aufgeteilt werden. Alle erforderlichen Informationen sind in der Nachricht enthalten, so dass Flink mit einfachen Transformationen ein Changelog erstellen kann. Dieser Vorgang ist schnell und erfordert weder ChangelogNormalize noch einen anderen zustandsabhängigen Operator. Die Regeln der Transformation sind in der folgenden Tabelle aufgeführt.

Seien Sie vorsichtig, wenn Sie CDC mit Metadaten-Spalten verwenden, da die Korrektheit des Änderungsprotokolls leicht gefährdet werden kann. Nehmen wir an, es wurde eine neue Zeile eingefügt und aktualisiert. Debezium hat zwei Nachrichten erzeugt, die von Flink umgewandelt wurden:
- Zeile(kind=Einfügen, id=1, attr='a')
- Row(kind=UpdateBefore, id=1, attr='a')
- Zeile(kind=UpdateAfter, id=1, attr='b')
Was passiert nach dem Hinzufügen von Metadaten-Spalten wie Partition und Offset in die temporale Tabelle von Flink? Die Ereignisse werden mit den richtigen Werten angereichert und sehen dann wie folgt aus:
- Row(kind=Insert, id=1, attr='a', partition=0, offset=0)
- Row(kind=UpdateBefore, id=1, attr='a', partition=0, offset=1)
- Row(kind=UpdateAfter, id=1, attr='b', partition=0, offset=1)
Wie bereits erwähnt, hat das zweite Ereignis (-U) einen Offset, der von der aktuellen Nachricht stammt. Dieses Verhalten ist korrekt, da UpdateBefore und UpdateAfter aus derselben Nachricht mit Partition=0 und Offset=1 stammen. Dies ist jedoch nicht korrekt, wenn wir das Änderungsprotokoll betrachten, da UpdateBefore die vorherigen Werte enthalten sollte.
Die Verwendung von Metadaten-Spalten mit CDC-Ereignissen reicht aus, um SinkMaterializer zu brechen. Der Operator sammelt Zeilen im Status und bereinigt sie, wenn sie nicht benötigt werden. Die Erkennung von Zeilen erfolgt durch den Vergleich von Upsert-Schlüsseln oder ganzen Zeilen. Im zweiten Szenario ist ein Abgleich nicht möglich, da SinkMaterializer eine Zeile mit den folgenden Werten erwartet:
Row(kind=UpdateBefore, id=1, attr='a', partition=0, offset=0).
Der Ergebnisoperator behebt keine Race Hazards und es kann zu Engpässen bei der Bearbeitung des Status kommen, die immer mehr Zeit in Anspruch nehmen. Ein weiteres Symptom für dieses Problem ist die Anhäufung von Protokollen wie:
org.apache.flink.table.runtime.operators.sink.SinkUpsertMaterializer [] - The state is cleared because of state ttl. This will result in incorrect result. You can increase the state ttl to avoid this.Dieses Protokoll kann irreführend sein, denn es suggeriert, dass das Problem auf den Ablauf des Status zurückzuführen ist. Das bedeutet nur, dass die erwartete Zeile nicht im Status vorhanden ist. Dieses Problem kann nicht nur durch die TTL-Konfiguration verursacht werden, sondern auch durch Race Conditions (z.B. ein DELETE-Ereignis, das in SinkMaterializer zuerst verarbeitet wird) oder ein falsches Changelog (z.B. nicht übereinstimmende Felder zwischen UpdateBefore- und UpdateAfter-Ereignissen).
Die Schlussfolgerung ist einfach: Kombinieren Sie die Kafka-Debezium-Tabelle nicht mit Metadaten-Spalten, wenn Sie SinkMaterializer verwenden!
DIY - Rangversionierung
Die Versionierung von temporalen oder Lookup-Joins kann einfach implementiert werden. Beachten Sie, dass Übereinstimmungen nur bei Ereignissen von der linken Seite der Verknüpfung ausgegeben werden, so dass sie für Eins-zu-Eins-Beziehungen geeignet ist. Daher reicht es aus, der treibenden Tabelle eine Version hinzuzufügen und mit ihrem Primärschlüssel zu deduplizieren, geordnet nach der Spalte Version. Dies können Sie mit der TOP-N (Rang) Funktion , wobei N=1 (ROW_NUMBER() OVER(...) pattern).
Wenn Sie ein Kafka-Topic als Quelle verwenden und die Nachrichten in Kafka nach dem Primärschlüssel partitioniert sind, kann die Offset-Spalte für die Versionierung verwendet werden. Die Verwendung einer Zeitstempel-Metadatenspalte (ein Zeitstempel des Schreibens des Ereignisses in das Kafka-Topic) kann aufgrund der Millisekundenauflösung unzureichend sein.
Die Rangfunktion kann auch für reguläre Verknüpfungen verwendet werden, außer für Many-to-Many-Beziehungen (FULL OUTER JOIN). Bitte beachten Sie, dass die richtige Reihenfolge der Versionsspalten beibehalten werden muss und dass es nicht immer offensichtlich ist, wie man Versionen für eingehende Ereignisse definiert.
Die Funktion Rank ist schneller als SinkMaterializer. Sie kann in Verbindung mit einer TTL-Konfiguration verwendet werden. Ab Flink 1.17 können TTL-Parameter pro Operator eingestellt werden, was zur Begrenzung der Statusgröße beiträgt und sich auf die Leistung auswirkt. Gefährdungen können nämlich nur für die neuesten Daten auftreten.
Kennen Sie Ihren Feind
Flink SQL ist in der Tat ein großartiges Framework, aber es hat auch seine Grenzen. Meiner Meinung nach liegt das Problem nicht beim Framework selbst, sondern bei seiner Dokumentation. Die Erkenntnisse, die ich mit Ihnen geteilt habe, beruhen auf meinen Erfahrungen mit Flink SQL. Ich bin auf Probleme wie Race Conditions, Leistungseinbußen im Sink Materializer aufgrund von Zustandsexplosionen und fehlerhafte oder unvollständige Changelogs gestoßen. Oft wurden diese Probleme erst relativ spät, unter bestimmten Bedingungen oder nach der Verarbeitung einer großen Datenmenge festgestellt. Ich hoffe, dass Sie nicht auf solche Probleme stoßen und die Vorteile von Flink SQL voll zu schätzen wissen!
Denken Sie daran:
- Das Changelog in Flink SQL ist anfällig für Race Conditions.
- Vermeiden Sie die Verwendung von temporalen oder Lookup-Joins mit SinkMaterializer, es sei denn, Sie sind sicher, dass der Operator Zeilen anhand von Upsert-Schlüsseln vergleicht. Verwenden Sie stattdessen die Rangfunktion (TOP-1), um Race Conditions zu behandeln.
- Vermeiden Sie die Verwendung nicht-deterministischer Spalten mit SinkMaterializer.
- Führen Sie die Verknüpfung nicht mit einer regulären Verknüpfung und Werten aus der temporären Tabelle/Ansicht oder der Nachschlagetabelle durch, da diese nicht korrekt zurückgezogen werden.
- Metadaten-Spalten unterbrechen das vom Kafka-Connector mit dem Debezium-Format erstellte Changelog. Geben Sie sie nicht an SinkMaterializer weiter.
Bemerkungen
Alle Beobachtungen wurden mit Flink 1.16.1 gemacht.
Fazit
Flink SQL ist ein leistungsstarkes Tool für die Stream-Verarbeitung, aber das Verständnis und die Verwaltung von Race Conditions ist entscheidend für die Wahrung der Datenintegrität. Durch die Nutzung von Änderungsprotokollen, die Implementierung von Best Practices und das Bewusstsein für potenzielle Fallstricke können Sie die Komplexität der Echtzeit-Datenverarbeitung mit Flink SQL effektiv meistern. Vereinbaren Sie einen Beratungstermin mit unseren Experten, um informiert zu bleiben und diese Strategien anzuwenden, um die Vorteile Ihrer Streaming-Anwendungen zu maximieren.
Verfasst von
Maciej Maciejko
Unsere Ideen
Weitere Blogs




Contact