
Flink ist ein Open-Source-Framework für die Stream-Verarbeitung, das sowohl Stapelverarbeitung als auch Daten-Streaming-Programme unterstützt. Das Streaming erfolgt, während die Daten durch das System fließen, ohne zwingende zeitliche Beschränkungen bei der Ausgabe. Flink wird in vielen Projekten eingesetzt und wir sehen es in Aktion bei regelbasierter Alarmierung, Systemen zur Erkennung von Anomalien, Webanwendungen mit personalisierten Inhalten oder der Personalisierung des Angebots im E-Commerce. Es kann in das Hadoop-Ökosystem und Kubernetes integriert werden, aber auch eigenständig laufen.
Kubernetes hat sich zum wichtigsten Akteur auf dem Gebiet der Containerisierung entwickelt. Es bietet eine Menge Vorteile und neue Herausforderungen - wir können es als den nächsten Schritt der IT-Evolution bezeichnen. Die Reife und die wichtigsten Funktionen von Kubernetes ermöglichen es, dass immer mehr Dienste verfügbar werden und direkt auf Kubernetes bereitgestellt werden können. Apache Flink ist ein hervorragendes Beispiel für einen solchen Dienst. Es gibt mehrere Möglichkeiten, ihn direkt auf Kubernetes zu installieren und auszuführen, was eine bessere Skalierbarkeit, eine einfachere Implementierung von Continuous Integration und Continuous Deployment, einfachere Versions-Upgrades und die Wiederverwendung von Containern ermöglicht.
Der wichtigste Unterschied zwischen den unten genannten Lösungen ist, dass sie verschiedene Operatoren enthalten. Operatoren sind Software-Erweiterungen für Kubernetes, die benutzerdefinierte Ressourcen zur Verwaltung von Anwendungen und deren Komponenten nutzen. Operatoren werden aufgrund ihrer Flexibilität verwendet (Entwickler können ihre eigenen Objekte erstellen und die Bereitstellung vereinfachen) und bieten die Möglichkeit, benutzerdefinierte Logik hinzuzufügen, allerdings ist die Vorbereitung und Validierung von Operatoren nicht einfach - sie erfordert viel Arbeit.
Hinweis: Apache Flink stellt standardmäßig seine eigene Web-UI mit einer Beschreibung des Auftrags, Metriken, einem Diagramm der Anwendung und Informationen über TaskManager zur Verfügung.
Gemeinsame Aspekte von Flink in Kubernetes
Lassen Sie uns mit der Überwachung beginnen. Wir können den Exporter wie den Prometheus-Exporter einrichten, Annotationen zu unseren Pods hinzufügen und damit beginnen, Metriken von allen Pods zu sammeln, auf denen wir Flink-Jobs ausführen. Das ist ganz einfach, wenn wir Prometheus und die Kubernetes Service Discovery-Funktion verwenden, mit der wir Ziel-Annotationen definieren können.
Der zweite Punkt ist die Hochverfügbarkeit. Zunächst müssen wir Flink-Jobs mit einem Objektspeicher oder HDFS in Hochverfügbarkeit verbinden, in dem wir Daten speichern und Flink seine Checkpoints und Savepoints speichern kann. Außerdem benötigt Flink einen zusätzlichen Dienst, um zwei JobManager zu betreiben, damit eine hohe Verfügbarkeit gewährleistet ist. Hier können wir sie mit Zookeeper verbinden oder den Kubernetes-Dienst verwenden, um die aktive Flink-Instanz zu verwalten.
Flink K8S Betreiber
GitHub-Repository:

Dieser Dienst wird von Lyft entwickelt und ist ein großartiges Beispiel für Software, die von der Community ständig verbessert wird. Der Operator fungiert als Kontrollebene zur Verwaltung des gesamten Lebenszyklus der Anwendung. Es ist erwähnenswert, dass die letzte Version dieses Operators Ende April 2020 mit der Version v0.5.0 veröffentlicht wurde. Es gibt auch einen eigenen Slack-Arbeitsbereich für die Benutzer. In der README-Datei ist vermerkt, dass sich das Projekt noch in der Betaphase befindet.
Die Installation und der Upgrade-Prozess sind ganz einfach. Wir können mit Kubernetes-Manifesten oder Helm-Diagrammen arbeiten - wenn wir etwas ändern möchten, können wir direkt auf GitHub zum Fork-Repository gehen und tun, was wir wollen.
Der CICD-Prozess ist recht einfach. Wir können Kubernetes-Manifeste oder Helm-Charts mit allen Aktualisierungen und Konfigurationen verwenden. Hier verwenden wir benutzerdefinierte Definitionen, die vom Betreiber verwaltet werden, wie den JobManager Deployment and Service oder den TaskManager. Wenn Sie Erfahrung mit der Bereitstellung von Anwendungen in Kubernetes haben, werden Sie wissen, dass dies ein reibungsloser Prozess ist. Wir können zusätzliche Prüfungen durchführen, um sicherzustellen, dass unser Job erfolgreich gestartet wurde, indem wir den Flink-Job direkt aufrufen. Dieser Operator sorgt für Blue Green Deployment, eine wertvolle Funktion. Blue-Green Deployment ist eine Technik, die Ausfallzeiten und Risiken reduziert, indem zwei identische Produktionsumgebungen, genannt Blue und Green, betrieben werden. Zu jeder Zeit ist nur eine der Umgebungen live, wobei die Live-Umgebung den gesamten Produktionsverkehr bedient - in diesem Fall ersetzen wir den alten Auftrag durch den neuen, wenn beide laufen und nur eine von ihnen Daten verarbeitet.
Die Geschwindigkeit, mit der neue Aufträge eingereicht werden, ist nicht die beste und hängt vor allem von der Menge der verfügbaren Ressourcen ab - die blau-grüne Bereitstellung kann mehrere Minuten dauern, während einige hier beschriebene Lösungen viel schneller sind.
Jede Konfiguration im Zusammenhang mit dem Auftrag wird auf die gleiche Weise verwaltet wie im YARN-Cluster und kann durch die Verwendung von Vorlagen mit im Repository gespeicherten ConfigMaps erreicht werden. Es gibt keine Probleme mit der Anbindung von Flink an Objektspeicher, kerberisierte Komponenten wie Kafka oder HDFS.
Vorteile:
- Blau-Grüner Einsatz
- Schön funktionierende benutzerdefinierte Objekte in Kubernetes
- Open-Source-Code verfügbar auf GitHub
- leichte Lösung
- einfaches Hinzufügen von Seitenwagencontainern
Nachteilig:
- keine zentrale Verwaltung von Aufträgen
- kein SQL-Editor verfügbar
- wir können keine Sitzungscluster ausführen
- Die Aufnahme eines Jobs kann einige Zeit dauern - noch in der Beta-Phase
Kubernetes Operator für Apache Flink
GitHub-Repository:
Es ist im Google Cloud Repository verfügbar, aber es ist erwähnenswert, dass es nicht offiziell von dem Unternehmen aus Mountain View unterstützt wird. Apropos Operator: Die Installation ist ziemlich einfach und wir können Kubernetes-Manifeste oder Helm-Charts verwenden, um es in unserer Umgebung einzusetzen.
Er erstellt eine benutzerdefinierte Ressourcendefinition FlinkCluster und führt einen Controller-Pod aus, um die benutzerdefinierten Ressourcen zu überwachen. Sobald eine benutzerdefinierte FlinkCluster-Ressource erstellt und vom Controller erkannt wurde, erstellt der Controller die zugrunde liegende Kubernetes-Ressource (z. B. JobManager Pod) auf der Grundlage der Spezifikation der benutzerdefinierten Ressource.
CICD-Pipelines sind einfach zu erstellen, da wir unseren Flink-Job im Helm-Diagramm oder im Kubernetes-Manifest beschreiben. Es handelt sich also um eine ganz typische Einrichtung für eine Anwendung, die in einer containerisierten Umgebung läuft. Natürlich ist es wichtig zu überprüfen, ob ein Job läuft, indem Sie die Kubernetes-API aufrufen und den Status der Pods und des Objekts von Flink abrufen.
Die neueste Version, Versionsnummer 0.2.0, wurde im September 2020 hinzugefügt und ist eine recht frühe Betaversion. Sie bietet die Möglichkeit, fehlgeschlagene Aufträge vom letzten Speicherpunkt aus neu zu starten und wir können auch eine Batch-Planung für JobManager- und TaskManager-Pods einrichten.
Vorteile:
- Open-Source-Code verfügbar auf GitHub
- leichte Lösung
- einfaches Hinzufügen von Seitenwagencontainern
- Job- und Session-Cluster verfügbar
- Unterstützung für GCP-Dienste (Google Cloud Storage Connector, IAM-Dienstkonten)
- Unterstützung für Python Apache Beam
Nachteilig:
- keine zentrale Verwaltung von Aufträgen
- kein SQL-Editor verfügbar
- Beta-Version 0.2.0 - nicht die ausgereifteste Lösung
Ververica Plattform
Ververica ist eine Plattform, die von dem Team entwickelt wurde, das hinter Apache Flink steht. Wir können also sicher sein, dass wir es mit einem Produkt eines erfahrenen Unternehmens zu tun haben, das Flink versteht und weiß, wie es unter der Haube funktioniert. Eine der einzigartigsten Funktionen der Ververica-Plattform ist ein Web-Dashboard, in dem der Benutzer Deployment-Ziele erstellen kann (fügen Sie Informationen über den Namen der Zielgruppe hinzu und ordnen Sie sie dem gewählten Namespace zu), die Standardkonfiguration von Flink-Jobs, Session-Cluster, auf denen wir Flink-SQL-Abfragen oder -Jobs ausführen können, die Verwaltung des Lebenszyklus unserer Anwendung und darüber hinaus eine ziemlich leistungsfähige REST-API zur Verwaltung der Job-Konfiguration und zur Erstellung neuer Jobs. Ververica wendet neue Verbesserungen an, die auf dem Feedback der Benutzer basieren.
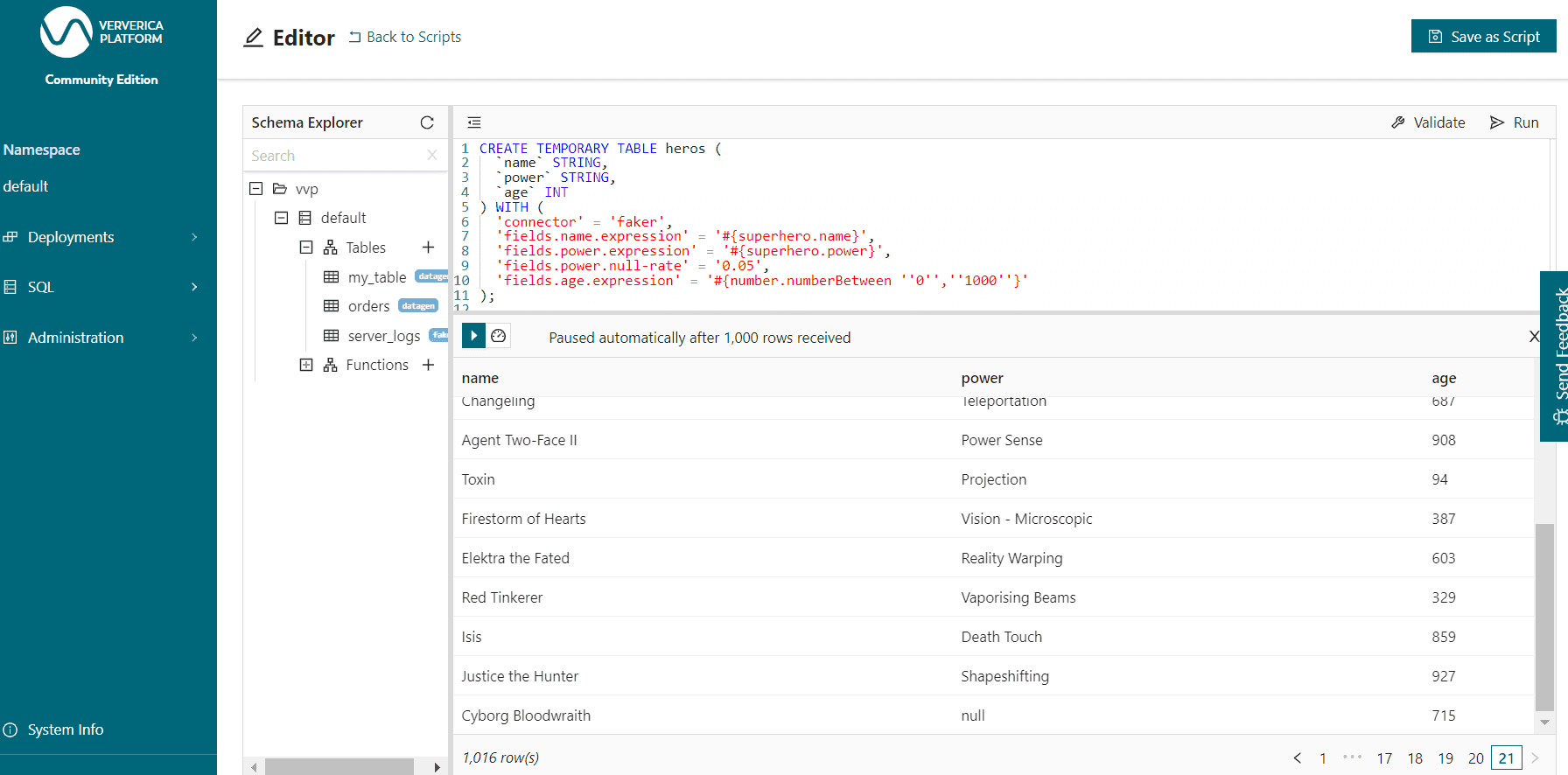
Es ist auch eine nützliche Plattform, um Flink-SQL-Abfragen direkt von Ververica aus auszuführen und die Ergebnisse über die Benutzeroberfläche statt über das Terminal zu betrachten.
Der CICD-Prozess erfordert die Verwendung der REST-API, an die wir Anfragen mit der Konfiguration im YAML- oder JSON-Format senden, so dass er leicht in jedes CICD-Tool wie Gitlab CI, Jenkins oder GitHub-Aktionen implementiert werden kann.
Die Installation der Ververica-Plattform wird mit einer eigenen SQLite-Datenbank geliefert (sie kann bei allen Versionen außer der Community Edition durch PostgreSQL oder MySQL ersetzt werden), in der alle Daten gespeichert werden. Sie vereinfacht auch die Konfiguration eines externen Blob-Speichers, der als Artefakt für Flink JARs sowie als Speicherort für Speicherpunkte und Checkpoints von Jobs verwendet werden kann. Es funktioniert sowohl mit S3-kompatiblem Objektspeicher als auch mit kerberisiertem HDFS.
Die Ververica-Plattform ist als kostenlose Community Edition mit einer Beschränkung auf einen Namespace für Aufträge und ohne Authentifizierung, als Startup Edition und als Enterprise Edition erhältlich. Es ist erwähnenswert, dass die Autoren ihr Produkt ständig verbessern und wir häufige Updates sehen können.
Vorteile:
- einfacher Installationsprozess
- leistungsstarke REST-API, die für CICD-Pipelines nützlich ist
- Verwaltung von Flink-Aufträgen (Konfiguration, Status)
- Flink SQL-Editor
- Autostart-Mechanismus direkt innerhalb der Ververica-Plattform (nicht nur in Flink-Jobs)
Nachteilig:
- Einschränkungen in der Community Edition, d.h. eine begrenzte Anzahl aktiver Namespaces und keine Authentifizierung
- Die Verwendung von benutzerdefinierten Flink-Images erfordert mehrere Änderungen in der Dockerdatei und in den verwendeten Flink-Shell-Skripten
Natives Kubernetes vom offiziellen Apache Flink
Dokumentation:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/deployment/resource-providers/standalone/kubernetes.html
Wir dürfen nicht die Möglichkeiten vergessen, die bereits direkt in Apache Flink verfügbar sind. Seit der Veröffentlichung von 1.12.0 hat Flink alle Aspekte der Ausführung in Kubernetes verbessert. Es sind keine zusätzlichen CustomObjects oder zusätzlichen Anwendungen für die Verwaltung von Flink erforderlich.
In diesem Fall haben wir die folgenden Einsätze:
- Ein Flink Session-Cluster wird als langlaufende Kubernetes-Bereitstellung ausgeführt. Sie können mehrere Flink-Aufträge in einem Session-Cluster ausführen. Jeder Auftrag muss an den Cluster übermittelt werden, nachdem der Cluster bereitgestellt wurde.
- Ein Flink-Anwendungscluster ist ein dedizierter Cluster, auf dem eine einzige Anwendung läuft
Native Kubernetes erfordert keine Bediener und die Installation ist recht einfach. Außerdem sind wir sicher, dass der Dienst ständig weiterentwickelt und verbessert wird, da er von einer großen Gruppe von Mitwirkenden von Apache Flink unterstützt wird. Zurzeit ist er noch sehr begrenzt, aber in manchen Fällen könnte er ausreichen.
Der CICD-Prozess ist derselbe wie bei jeder anderen Anwendung, die in Kubernetes läuft - wir stellen alles direkt aus dem CICD-Tool bereit und müssen überprüfen, ob die Anwendung läuft oder ob es Probleme gibt.
Vorteile:
- keine Installation erforderlich
- einfaches Hinzufügen von Seitenwagencontainern
Nachteilig:
- keine benutzerdefinierten Objekte
- keine Unterstützung für Pro-Job-Cluster
- eingeschränkte Funktionen und kein Neustart-Mechanismus, der Flink-Jobs direkt ausschließt.
Mehrere Möglichkeiten, Flink auf Kubernetes laufen zu lassen
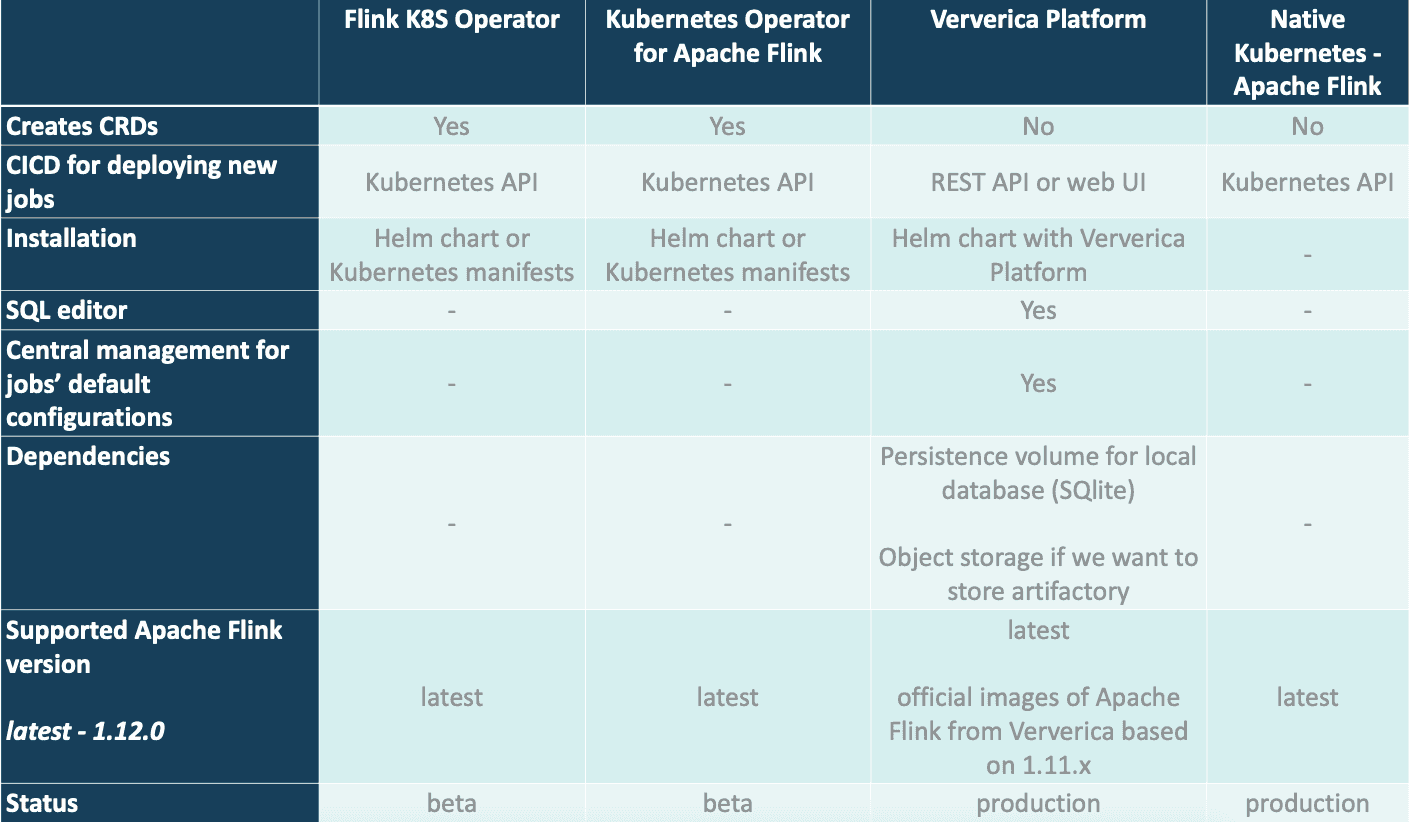
Aus unserer Erfahrung heraus können wir Ververica Platform als zuverlässige Lösung für die meisten Anwendungsfälle empfehlen. Sie bietet eine schnelle Möglichkeit, den Flink-Job auszuführen - der Neustart des Jobs mit dem neuen Cluster ist im Vergleich zu z.B. Flink, das auf Lyft Operator basiert, recht schnell und wir können einige nützliche Funktionen wie den Flink SQL-Editor finden.
Sicherlich hängt die Wahl des perfekten Flink-Operators vom genauen Anwendungsfall, den technischen Anforderungen und der Anzahl der Aufträge ab. Alle vorgestellten Operatoren stammen von starken Akteuren auf dem Big Data-Markt.
Bei GetInData haben Sie Zugang zu mehr als 50 Experten für verteilte Systeme und Clouds, die mit Big Data-Systemen auf der Basis von Apache Flink in verschiedenen Konfigurationen arbeiten. Zögern Sie nicht, sich mit uns in Verbindung zu setzen. Unser Team bespricht gerne mit Ihnen Ihr Echtzeit-Big-Data-Streaming-Projekt.
Verfasst von
Albert Lewandowski
Unsere Ideen
Weitere Blogs




Contact