Blog
Implementierung der fein abgestuften Autorisierung in Databricks Unity Catalog

Einführung
Daten sind ein wichtiges und zugleich sensibles Gut für Unternehmen. Aber wie können wir sensible Informationen schützen und gleichzeitig sicherstellen, dass die richtigen Personen Zugriff darauf haben?
Die fein abgestufte Autorisierung in Databricks Unity Catalog ermöglicht es Unternehmen, robuste, rollenbasierte Datensicherheitsrichtlinien zu implementieren. Durch den Einsatz von Funktionen wie Zeilenfiltern und Spaltenmasken können Unternehmen die Sichtbarkeit von Daten genau kontrollieren. Dies gewährleistet nicht nur die Einhaltung strenger Data Governance-Richtlinien, sondern fördert auch die sichere Zusammenarbeit zwischen Teams und Abteilungen innerhalb des Data Lakehouse.
Da die Bedenken hinsichtlich der Datensicherheit und des Datenschutzes weiter zunehmen, wird die Implementierung fein abgestufter Berechtigungen zu einem Eckpfeiler moderner Data Governance-Strategien. Mit Tools wie Unity Catalog können Unternehmen das perfekte Gleichgewicht zwischen dem Schutz sensibler Daten und datengesteuerter Entscheidungsfindung herstellen.
In diesem Beitrag beschäftige ich mich mit der Implementierung eines anspruchsvollen Datenfiltermodells für den Databricks Unity Catalog. Ich werde Zeilenfilter und Spaltenmasken verwenden, um auch die komplexesten Zugriffsanforderungen zu erfüllen. Kommen Sie mit!
Databricks Unity-Katalog:
Der Unity Catalog ist die zentrale Governance-Ebene innerhalb der Databricks Lakehouse-Plattform. Er vereinfacht und stärkt die Datenverwaltung, indem er einen einheitlichen Rahmen für die Verwaltung von Daten, KI-Modellen und anderen Ressourcen bietet. Zu seinen Kernfunktionen gehören Zugriffskontrollen, Tools für die Auffindbarkeit von Daten, die Möglichkeit, Datensätze mit beschreibenden Metadaten zu versehen und die Nachverfolgung der Daten von ihrer Quelle bis zu dem Punkt, an dem sie verbraucht werden.
Durch die Zentralisierung des Zugriffs und der Verwaltung ermöglicht Unity Catalog eine sichere teamübergreifende Zusammenarbeit und verbessert gleichzeitig die Transparenz. So können Unternehmen den vollen Wert ihrer Daten ausschöpfen, das Vertrauen aufrechterhalten und die Einhaltung gesetzlicher Vorschriften gewährleisten.
In der immer komplexer werdenden Datenlandschaft von heute reicht es nicht mehr aus, den Zugriff auf einer breiten Asset-Ebene zu verwalten (z.B. den Zugriff auf einen gesamten Datensatz zu gewähren). Mit dem Wachstum von Unternehmen wachsen auch deren Anforderungen an die Datensicherheit. Die Vermeidung von Datensilos und die Berücksichtigung verschiedener Benutzerrollen erfordern einen detaillierteren Ansatz für die Zugriffskontrolle. Hier kommt die feingranulare Autorisierung ins Spiel.
Die Notwendigkeit einer fein abgestuften Autorisierung:
Zugriffskontrollen für Assets, z. B. wer lesen und schreiben darf, sind eine grundlegende Voraussetzung. Was aber, wenn Sie nicht den gesamten Inhalt eines Assets freigeben möchten? Was ist, wenn Sie nur eine Teilmenge davon freigeben möchten, z. B. bestimmte Zeilen oder Spalten? Beispiele für sensible Daten, die dieses Maß an Schutz erfordern könnten, sind Einkaufspreise, Gewinnspannen und Kundendaten. Kurz gesagt, alle Informationen, die leicht von Konkurrenten ausgenutzt werden könnten.
Eine einfache, aber nicht ideale Lösung besteht darin, sensible Daten in verschiedene Datensätze aufzuteilen und den Zugriff nur einer privilegierten Gruppe zu gewähren. Dieser Ansatz ist jedoch im großen Maßstab nicht mehr tragbar. Die mehrfache Aufteilung von Datensätzen führt zu Problemen bei der Wartbarkeit und Übersicht.
Eine bessere Lösung besteht darin, die Zugriffskontrolle feinkörnig zu gestalten, d.h. detaillierte Berechtigungen auf Zeilen- und Spaltenebene festzulegen. In Databricks Unity Catalog bedeutet dies die Anwendung von Filtern auf Zeilenebene und Masken auf Spaltenebene für Tabellen.
Ein einfaches Beispiel:
Wie bereits erwähnt, müssen Sie für die Implementierung fein abgestufter Zugriffskontrollen Zeilenfilter und Spaltenmasken erstellen. Diese werden als Funktionen definiert und direkt auf Tabellen im Unity-Katalog angewendet. Nachfolgend finden Sie ein Beispiel für Filter auf Zeilenebene:
CREATE OR REPLACE FUNCTION
governance.row_level_security.udf_row_filter ()
RETURNS BOOLEAN
RETURN IF(is_account_group_member("Xebia Data"), True, False);
;
ALTER TABLE catalog.schema.sample_table
SET ROW FILTER governance.row_level_security.udf_row_filter on ();
Innerhalb der obigen Funktion: is_account_group_member() prüft, ob der current_user() Teil der Gruppe ist, in diesem Fall: "Xebia Data". Die Gruppe muss innerhalb von Databricks existieren, es könnte sein, dass sie z.B. von Azure EntraID mit Databricks synchronisiert wird.
Voraussetzungen und Überlegungen:
Bevor Sie die Möglichkeiten von Zeilenfiltern und Spaltenmasken erkunden, sollten Sie ein paar Überlegungen anstellen:
-
Implementieren Sie eine feingranulare Autorisierung auf dem konsumierenden Endpunkt. Wenn die Daten beispielsweise von einem Dashboarding-Tool genutzt werden, kann es sinnvoller sein, die Autorisierung dort durchzuführen. Wenn die Verbraucher die Databricks-Plattform verwenden, dann ist Unity Catalog der ideale Ort, um eine feinkörnige Autorisierung zu implementieren. Andernfalls müssen Sie die feinkörnige Autorisierung möglicherweise an anderen Endpunkten erneut anwenden.
-
Verstehen Sie die technischen Einschränkungen: In den Azure Databricks Zeilen- und Spaltenfiltern (Unterstützung und Einschränkungen) finden Sie Details zu möglichen Einschränkungen.
Fortgeschrittenes Beispiel
Stellen Sie sich ein Szenario vor, in dem Sicherheitsrichtlinien rollenbasierte Zugriffsbeschränkungen erzwingen. Zum Beispiel können Kundenbetreuer die Daten der ihnen zugewiesenen Kunden einsehen, aber nicht auf die Einkaufspreise der Produkte zugreifen. In ähnlicher Weise können Einkäufer nur die Verkaufsdaten für die ihnen zugewiesenen Produkte einsehen, einschließlich des Kaufpreises, aber sie können nur die Kunden-ID sehen, nicht aber detaillierte Kundeninformationen. Diese Trennung stellt sicher, dass sensible Unternehmensdaten wie Kundendaten und Gewinnspannen geschützt sind.
Die folgende Tabelle veranschaulicht dieses Szenario anhand von Kundenauftragszeilen:
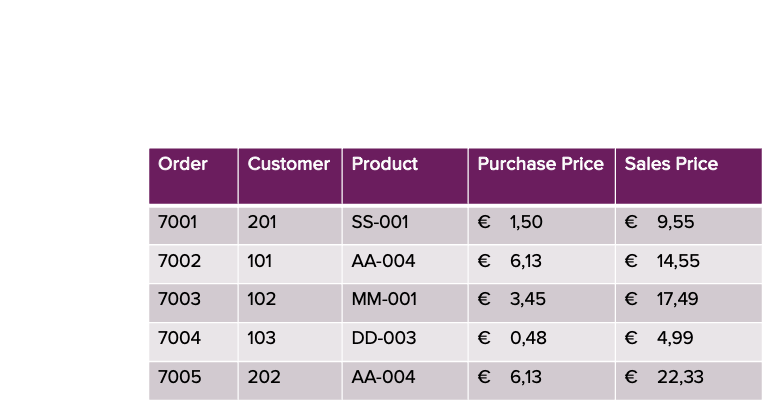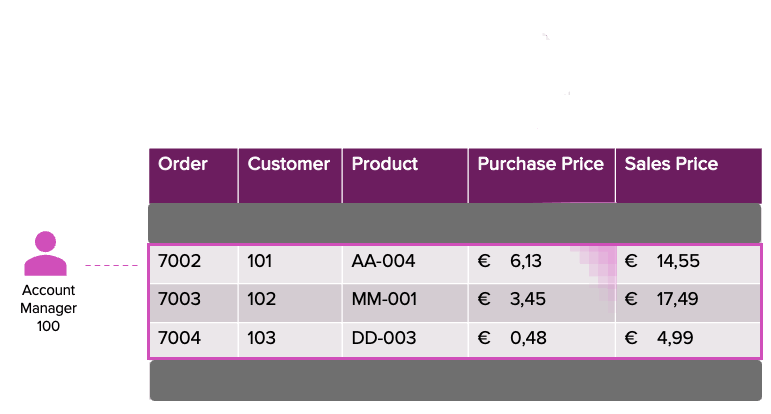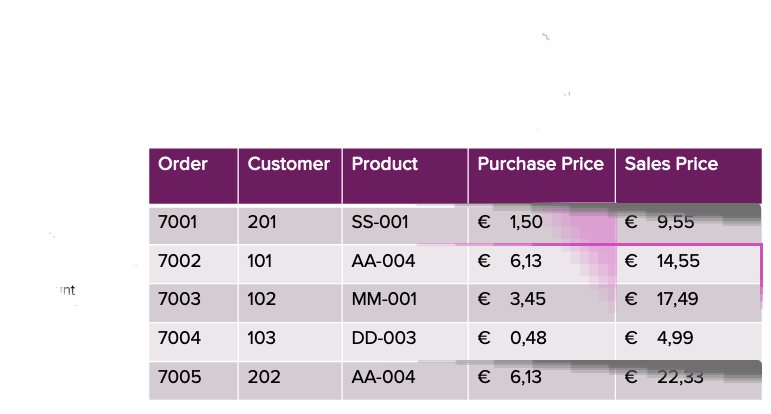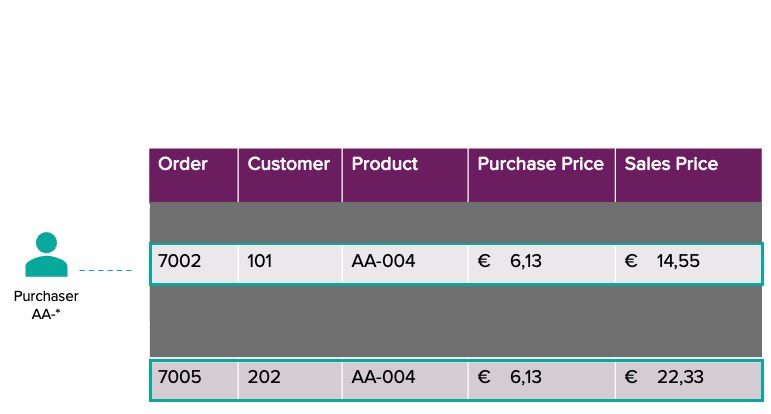
Mit Filtern auf Zeilenebene und Spaltenmasken werden wir diese Anforderung ermöglichen. Um eine fein abgestufte Autorisierung durchzusetzen, müssen wir zunächst Zugriffsberechtigungen auf Benutzerebene definieren und speichern. Dies erreichen wir durch die Erstellung einer Zuordnungstabelle, die festlegt, welche Benutzer Zugriff auf bestimmte Daten haben.
Definieren einer Mapping-Tabelle für fein abgestuften Zugriff
Zur Steuerung des Zeilenfilters und der Spaltenmasken habe ich eine Quelle verwendet, die den erlaubten Zugriff auf Benutzerebene festlegt. Ich habe diese Daten nachgebildet und in eine Nachschlagetabelle umgewandelt: 'user_customer_product' und sie in Databricks gespeichert.
Wenn Sie sich dafür interessieren, wie Sie die Nachschlagetabelle erstellen, klicken Sie hier, um den Code zu erweitern:
geschrieben in pyspark:
from pyspark.sql.types import StructType, StructField, StringType, ArrayType, IntegerType, BooleanType
# mapping table: user_customer_product
user_customer_product = [
{
"user": "maurice@xebia.com",
"role": "Account Manager",
"customer_key": [11185, 11142],
"product_key": None,
"purchase_price": False
},
{
"user": "ruben@xebia.com",
"user": "maurice.veltman@xebia.com",
"role": "Purchaser",
"customer_key": None,
"product_key": [225, 484, 485, 479, 214, 528],
"purchase_price": True
},
{
"user": "ken@xebia.com",
"role": "Admin",
"is_admin": True
}
]
# Schema
schema = StructType([
StructField("user", StringType(), False),
StructField("role", StringType(), False),
StructField("customer_key", ArrayType(IntegerType()), True),
StructField("product_key", ArrayType(IntegerType()), True),
StructField("purchase_price", BooleanType(), True),
StructField("is_admin", BooleanType(), True)
])
# dataframe
df = spark.createDataFrame(data=user_customer_product, schema=schema)
# create table
table_name = "governance.row_level_security.user_customer_product"
table_location= 'abfss://governance@xdnldataplatform.dfs.core.windows.net/authorization/user_customer_product'
df.write.mode("overwrite").option("path", table_location).saveAsTable(table_name)
display(spark.table(table_name))
Diese Informationen, die zur Erstellung einer ähnlichen Nachschlagetabelle benötigt werden, können wahrscheinlich aus einem ERP-System abgeleitet werden. Was abgeleitet werden muss, ist: - der zugewiesene Kundenbetreuer aus der Kundentabelle - der zuständige Einkäufer für ein Produkt aus der Produkttabelle
Die Tabelle in diesem Beispiel sieht wie folgt aus:

Die Spalte user entspricht dem current_user(), der die Daten abrufen wird. Die Spalten is_admin setzt die Zeilenfilter und Spaltenmasken außer Kraft.
Sobald die Zuordnungstabelle erstellt ist, besteht der nächste Schritt darin, eine Zeilenfilterfunktion zu implementieren. Diese Funktion stellt sicher, dass nur die Zeilen aus dem Datensatz zurückgegeben werden, auf die ein Benutzer Zugriffsrechte hat.
Implementieren von Filtern auf Zeilenebene:
Um Sicherheit auf Zeilenebene zu erzwingen, müssen wir eine Funktion erstellen und sie auf eine Tabelle anwenden. Zum Beispiel enthält sales_order_line Verkaufsdatensätze, die gesichert werden müssen. Der folgende Code enthält eine SQL-Funktion, die TRUE zurückgibt, wenn der Zugriff auf eine Zeile erlaubt ist, und FALSE, wenn der Zugriff nicht erlaubt ist, basierend auf dem Inhalt der obigen Mapping-Tabelle.
CREATE OR REPLACE FUNCTION
governance.row_level_security.udf_row_filter_adventureworks_sales_order_line (CustomerKey INT, ProductKey INT)
RETURNS BOOLEAN
LANGUAGE SQL
NOT DETERMINISTIC
READS SQL DATA
RETURN
EXISTS(
SELECT
NULL -- Selecting NULL as we only care about existence
FROM
governance.row_level_security.user_customer_product AS row_filter
WHERE
row_filter.user = current_user()
AND CASE
-- Check access conditions based on user permissions
-- Full access
WHEN row_filter.is_admin = TRUE THEN TRUE
-- Access for specific products, allowing all customers
WHEN array_contains(row_filter.product_key, ProductKey)
AND row_filter.customer_key IS NULL THEN TRUE
-- Access for specific customers, allowing all products
WHEN array_contains(row_filter.customer_key, CustomerKey)
AND row_filter.product_key IS NULL THEN TRUE
-- Access for specific products and customers
WHEN array_contains(row_filter.product_key, ProductKey)
AND array_contains(row_filter.customer_key, CustomerKey) THEN TRUE
-- No access if none of the conditions are met
ELSE FALSE
END
)
;
ALTER TABLE staging.adventureworks.sales_order_line
SET ROW FILTER governance.row_level_security.udf_row_filter_adventureworks_sales_order_line
ON (CustomerKey, ProductKey);
Wenn man sich den obigen Code ansieht, mag es überraschend erscheinen, die EXISTS Klausel zu finden, aber sie ist die optimale Lösung für die Überprüfung der Existenz von Zeilen. Der Hauptvorteil von EXISTS besteht darin, dass die Verarbeitung angehalten wird, sobald eine Übereinstimmung gefunden wird, was die Effizienz erhöht, insbesondere bei der Arbeit mit größeren Datensätzen oder Nachschlagetabellen. Im Vergleich zu einer reinen select-Anweisung erfordert eine SELECT -Anweisung eine GROUP BY oder LIMIT 1, um einen einzelnen Booleschen Wert zurückzugeben. LIMIT 1 kann sich jedoch unerwartet verhalten, wenn mehrere Zeilen für einen Benutzer existieren - etwas, das nicht passieren sollte, aber nicht garantiert werden kann. Außerdem führt die Verwendung von GROUP BY zur Zusammenfassung von Ergebnissen zu einem einzigen booleschen Wert zu zusätzlichem Overhead, da eine Zwischenergebnismenge erzeugt wird, die sortiert und dedupliziert werden muss. Das macht es weniger effizient im Vergleich zum Verhalten der EXISTS Klausel.
Während die Zeilenfilterfunktion den Zugriff auf bestimmte Zeilen einschränkt, benötigen wir auch eine Möglichkeit, den Zugriff auf sensible Spalten wie den Kaufpreis zu kontrollieren. An dieser Stelle kommt die Spaltenmaskierung ins Spiel.
Implementierung der Spaltenmaskierung
Um die Maskierung von Spalten zu erzwingen, erstellen wir eine Funktion, die sensible Daten, wie z.B. den Kaufpreis, vor nicht autorisierten Benutzern verbirgt. Es ist wichtig zu wissen, dass die Spalte selbst im Datensatz sichtbar bleibt, aber ihre Werte werden für Benutzer ohne die erforderlichen Berechtigungen maskiert.
Nachfolgend finden Sie den Code für die Implementierung der Spaltenmaskierungsfunktion:
CREATE OR REPLACE FUNCTION
governance.row_level_security.udf_mask_purchase_price (column FLOAT)
LANGUAGE SQL
NOT DETERMINISTIC
READS SQL DATA
RETURN
IF (
EXISTS(
SELECT
NULL -- Selecting NULL as we only care about existence
FROM
governance.row_level_security.user_customer_product mask
WHERE
mask.user = current_user()
AND CASE
-- Check access conditions based on user permissions
-- Full access
when mask.is_admin = TRUE THEN TRUE
-- Access for purchase price
when mask.purchase_price = TRUE THEN TRUE
-- No access if none of the conditions are met
ELSE FALSE
END
),
column,
NULL
);
ALTER TABLE staging.adventureworks.sales_order_line
ALTER COLUMN purchasePrice SET MASK governance.row_level_security.udf_mask_purchase_price;
Beachten Sie, dass in dem obigen Code kein Rückgabetyp definiert ist. Dies gibt Ihnen die Flexibilität, die Maskierungsfunktion auf mehrere Spalten anzuwenden, z.B. auf Ganzzahlen, Fließkommazahlen oder Dezimalzahlen, ohne dass Sie für jeden Typ eine eigene Funktion erstellen müssen.
Ab diesem Zeitpunkt wird die fein abgestufte Autorisierung auf Benutzerebene angewendet. Die Benutzer Maurice, Ruben und Ken (die in der Mapping-Tabelle angegeben sind) können die Daten sehen, für die sie berechtigt sind. Alle anderen Benutzer können keine Datensätze sehen.
Validierung
Um die Funktionalität zu überprüfen, werden wir die Tabelle: sales_order_line unter den Benutzerkonten von Maurice, Ruben und Ken abfragen.
Die nachstehende Abfrage wird verwendet, um die Implementierung zu testen:
SELECT
CURRENT_USER() as user,
COLLECT_LIST(DISTINCT CustomerKey) AS Customer,
COLLECT_LIST(DISTINCT ProductKey) AS Product,
ROUND(AVG(purchasePrice),2) AS avg_price
FROM
staging.adventureworks.sales_order_line
GROUP BY CustomerKey
LIMIT 10
Fall: Kundenbetreuer
Benutzer: Maurice
Zugriff: Kunden [11185, 11142] ohne Einkaufspreise zu sehen.
Ergebnis:
| user | Customer | Product | avg_price |
|--------|----------|-----------------------------------------|-----------|
| maurice| 11142 | [480, 528, 538, 490, 537, 487, 465, 472,| null |
| | | 463, 481, 477, 529, 536, 222, 217, 535, | |
| | | 541, 475, 214, 539, 234, 483, 530] | |
| maurice| 11185 | [530, 538, 217, 480, 471, 485, 237, 225,| null |
| | | 479, 528, 535, 541, 539, 475, 489, 537, | |
| | | 465, 488, 477, 486, 536, 491, 214, 484, | |
| | | 228, 529, 540, 222, 472] | |
Validierung: Erfolg
Maurice sieht nur die beiden zugewiesenen Kunden (11185 und 11142) mit allen zugehörigen Produkten. Wie erwartet, sind die Werte für den Einkaufspreis maskiert (null).
Fall: Käufer
Benutzer: Ruben
Zugriff: Produkte [225, 484, 485, 479, 214, 528] mit Zugriff auf Einkaufspreise.
Ergebnis:
| user | Customer | Product | avg_price |
|--------|----------|-----------------------------------------|-----------|
| ruben | 11142 | [528, 214] | 10.65 |
| ruben | 11185 | [225, 484, 485, 479, 214, 528] | 7.48 |
| ruben | 15277 | [528] | 1.87 |
| ruben | 22773 | [485, 528] | 5.04 |
| ruben | 11451 | [214, 485] | 10.65 |
Validierung: Erfolg
Ruben sieht Bestellungen von verschiedenen Kunden, aber nur für die Produkte, die er sehen darf (225, 484, 485, 479, 214, 528). Außerdem ist für diese Produkte, wie erwartet, der Kaufpreis sichtbar.
Zum Beispiel:
- Für den Kunden 11142 sind nur die Produkte [528, 214] enthalten.
- Für den Kunden 11185 sind nur die Produkte [225, 484, 485, 479, 214, 528] enthalten.
Fall: Admin
Benutzer: Ken
Zugriff: Voller Zugriff auf alle Kunden und alle Produkte, einschließlich der Einkaufspreise.
Ergebnis:
| user | Customer | Product | avg_price |
|--------|----------|-----------------------------------------|-----------|
| ken | 11142 | [480, 528, 538, 490, 537, 487, 465, 472,| 11.33 |
| | | 463, 481, 477, 529, 536, 222, 217, 535, | |
| | | 541, 475, 214, 539, 234, 483, 530] | |
| ken | 11185 | [530, 538, 217, 480, 471, 485, 237, 225,| 10.52 |
| | | 479, 528, 535, 541, 539, 475, 489, 537, | |
| | | 465, 488, 477, 486, 536, 491, 214, 484, | |
| | | 228, 529, 540, 222, 472] | |
| ken | 15277 | [465,485,477,214,478] | 7.21 |
| ken | 22773 | [485,528,536,486] | 5.04 |
| ken | 11451 | [575,478,472,214,217,359,344,477,485] | 523.31 |
Validierung: Success
Ken hat als Admin uneingeschränkten Zugriff auf alle Kunden, alle Produkte und die Einkaufspreise. Die Abfrageergebnisse bestätigen, dass für diesen Benutzer keine Einschränkungen auf Zeilen- oder Spaltenebene gelten. Beispiel:
- Für den Kunden 11142 sind alle zugehörigen Produkte sichtbar, wobei der durchschnittliche Einkaufspreis berechnet wird.
- Für den Kunden 11185 ist der gleiche uneingeschränkte Zugriff zu beobachten.
Fazit:
Der Validierungsprozess bestätigt, dass die feingranulare Autorisierung korrekt funktioniert:
- Maurice (Kundenbetreuer): Der Zugriff ist auf bestimmte Kunden (11185 und 11142) beschränkt, wobei die Einkaufspreise maskiert sind.
- Ruben (Einkäufer): Der Zugriff ist auf bestimmte Produkte (225, 484, 485, 479, 214, 528) beschränkt, wobei die Einkaufspreise sichtbar sind.
- Ken (Verwalter): Voller Zugriff auf alle Daten ohne jegliche Einschränkungen.
Diese Überprüfung unterstreicht die Effektivität der Implementierung von Filtern auf Zeilenebene und Spaltenmaskierung zur Durchsetzung einer fein abgestuften Zugriffskontrolle. Indem Sie die Sichtbarkeit von Daten auf einzelne Rollen zuschneiden, können Unternehmen sicherstellen, dass sensible Informationen geschützt werden, während sie den Benutzern die Daten zur Verfügung stellen, die sie für ihre Arbeit benötigen.
Was kommt als Nächstes?
Mit Blick auf die Zukunft verspricht die Einführung der attributbasierten Zugriffskontrolle (ABAC) noch mehr Flexibilität, da sie Richtlinien und verwaltete Tags ermöglicht. Mit dieser Fähigkeit entfällt die Notwendigkeit, Funktionen auf einzelne Tabellen anzuwenden, da wir Richtlinien auf Katalog- oder Schemaebene definieren können. So können wir beispielsweise Zeilenfilter oder Spaltenmasken erzwingen, wenn eine Tabelle oder Spalte mit einem "governed tag" (einer neuen Funktion) wie "company-secret", "PII" oder "purchase_price" für eine bestimmte Gruppe von Benutzern markiert ist.
Außerdem hoffe ich, dass die fein abgestuften Zugriffskontrollen auch auf Volumes innerhalb von Unity Catalog ausgeweitet werden, um den Schutz von Pfaden für nicht-tabellarische Daten zu ermöglichen. Diese Erweiterung würde die Datensicherheit weiter stärken, indem sie auf unstrukturierte und halbstrukturierte Daten ausgedehnt wird und einen umfassenden Ansatz für den Datenschutz gewährleistet.
Unsere Ideen
Weitere Blogs




Contact