Über diese Serie
Beim Aufbau einer Datenlösung auf Microsoft Fabric muss sich jedes Team mit den üblichen Herausforderungen auseinandersetzen: Organisation des Arbeitsbereichs, Namenskonventionen, Bereitstellungspipelines, Validierungs-Frameworks, Cluster-Größe und viele andere. In frühen Projekten wird oft wertvolle Zeit damit vergeudet, sich über diese Grundlagen Gedanken zu machen, während der Fokus auch auf dem eigentlichen Aufbau der Plattform liegen könnte.
In dieser Serie stellen wir Ihnen die bewährten Muster vor, auf die sich die Data Engineers von Xebia nach mehreren Proof-of-Concepts und Produktionslieferungen geeinigt haben. Betrachten Sie es als eine Abkürzung: Kopieren Sie, was funktioniert, passen Sie es dort an, wo sich Ihr Kontext unterscheidet, und verwenden Sie Ihre Energie auf das eigentliche Data Engineering.
Das Problem: Chaos am Arbeitsplatz
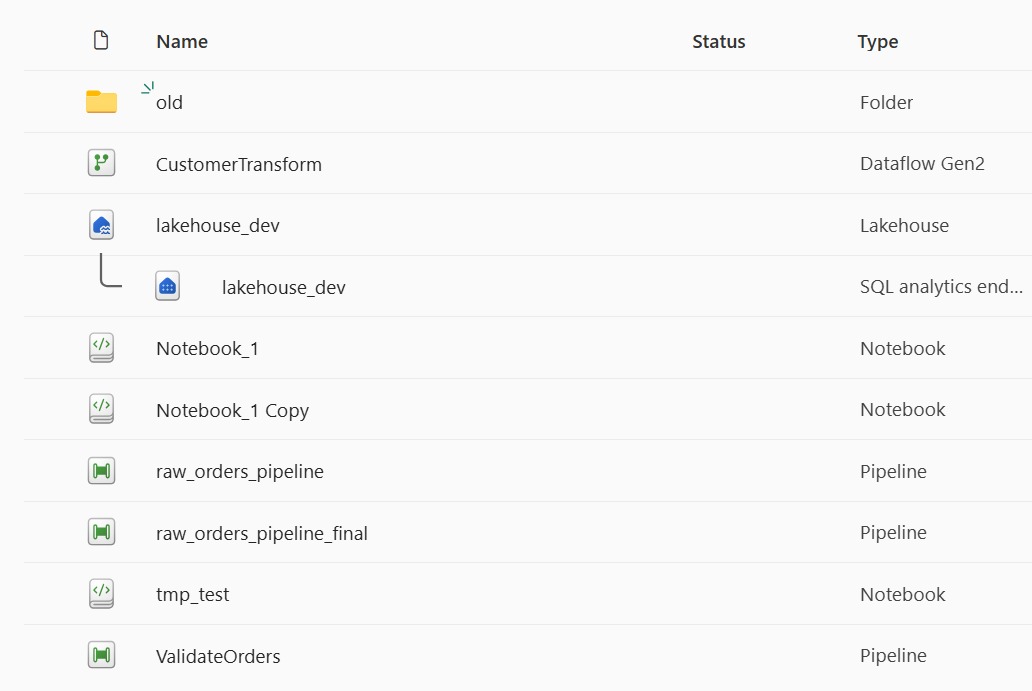
Wenn Sie einen beliebigen Fabric-Arbeitsbereich nach ein paar Wochen Projektlaufzeit öffnen, werden Sie oft ein Chaos vorfinden: Notizbücher, die im Stammverzeichnis abgelegt sind, Pipelines, die "Test" oder "Ingest2_final" heißen, Tabellen überall, jemand hat ein Präfix-Schema ausprobiert (`raw_`, `bronze_`), jemand anderes hat es ignoriert. Das Ergebnis: Neue Projektmitglieder verbringen viel Zeit mit der Suche nach Funktionalitäten und Änderungen sind riskant, weil niemand weiß, was was auslöst.
So sieht das Durcheinander aus:
Die Lösung für diesen Beitrag: Eine einfache, geordnete Struktur, die die Frage "Wohin gehört das?" deutlich macht. Nummerierte Phasenordner ganz oben (1_ingest, 2_validate, 3_transform), gemeinsam genutzte Assets im Stammverzeichnis, keine Objektpräfixe in den Objektnamen und das Objekt "Lakehouse" dort, wo die Leute Daten erwarten. Auffindbarkeit ist besser als Cleverness.
Quick Fabric Concepts (30-Sekunden-Glossar)
| Term | One-liner |
|---|---|
| Lakehouse | Storage + metadata friendly interface for files & tables. |
| Pipeline | Orchestration unit to schedule or chain activities (ingest, run notebooks). |
| Notebook | Interactive code (Spark / Python / SQL) for transformations & exploration. |
Das ist alles, was wir für diesen Beitrag brauchen.
Warum die Struktur (nicht die Präfixe) gewinnt & Leitprinzipien
Anstatt das Chaos mit längeren oder cleveren Namen zu lindern, lassen wir es mit einem vorhersehbaren Gerüst verschwinden.
Warum die Präfixe weglassen? Die Benutzeroberfläche von Fabric zeigt bereits Symbole für Pipelines, Notebooks und Tabellen an, so dass Sie auf einen Blick sehen können , was etwas ist. Das Hinzufügen von pl_, nb_ oder tbl_ Präfixen (die in Azure üblich sind) erzeugt nur Lärm. Stattdessen nutzen wir Ordner für logische Gruppierungen (Stufen wie 1_ingest/, 2_validate/), damit die Struktur die Geschichte erzählt, nicht der Name.
Hier ist zuerst die Lösung, damit Sie alles, was folgt, verankern können:

Kein Rätselraten - Wenn ein Teammitglied eine neue Qualitätsprüfung hinzufügt, wird diese direkt an 2_validate/notebooks weitergeleitet, ohne dass Sie nachfragen müssen.
Leitprinzipien:
- Beschreibende Namen - Klartext ("validate_orders") statt Abkürzungen; Icons + Ordner geben genug Kontext.
- Stage vs. Root - Stage-Ordner enthalten nur Artefakte , die die Stage benötigt. Alles, was wiederverwendet wird (Tabellen, Hilfsprogramme), befindet sich im Stammordner, damit Sie nicht duplizieren oder raten müssen.
- Prozessbestellung - Zahlen vermitteln die Reihenfolge auf einen Blick; keine Dekodierung erforderlich.
- Konsistenz statt Kreativität - Ein
verb_objectMuster und eine Gehäuseform sorgen für schnelles Scannen.
Stufe vs. Wurzel
Wenn nur eine Stufe sie benötigt (ein Ingest-spezifisches Notizbuch, eine Validierungspipeline), befindet sie sich in diesem Stufenordner. Wenn es von mehreren Stufen verwendet wird (das Lakehouse, eine Konfigurationsdatei, ein gemeinsames Dienstprogramm), befindet es sich im Stammverzeichnis. Dies verhindert Duplizierung und die Suche nach dem "Wo habe ich dieses Hilfsprogramm hingelegt?".
Betrachten Sie Phasen als logische Gruppierungen für einen Teil des Datenflusses. Jede Phase enthält nur das, was diese Phase der Verarbeitung benötigt, um zu laufen. Alles, worauf mehrere Phasen angewiesen sind, wandert in die Wurzel (lakehouse, config/, utils/). Diese klare Abgrenzung ist der Hauptgrund, warum die Leute aufhören zu raten.
Innerhalb einer Bühne gilt die gleiche einfache Regel: Halten Sie es flach, bis Sie etwas finden, das Sie verlangsamt. Ein Notizbuch? Legen Sie es direkt hinein. Eine Handvoll? Immer noch flach. Führen Sie erst dann einen minimalen Unterordner ein (Domäne, Quellsystem, Geschäftsbereich), wenn die Navigation wirklich schwierig wird. Tiefe ist eine Steuer, fügen Sie sie absichtlich hinzu.
Die Entwicklung der Struktur
Beginnen Sie minimal, wachsen Sie bewusst. Das obige Grundgerüst eignet sich für die meisten Arbeitsbereiche mit nur einem Team. Erweitern Sie es nur, wenn es sich als schwierig erweist:
Wann Sie eine neue Ebene hinzufügen sollten: Benötigen Sie eine kuratierte Ebene für die BI-Nutzung? Fügen Sie 4_publish/ mit Notebooks hinzu, die Daten speziell für die Berichterstattung aufbereiten. Benötigen Sie eine von der Transformation getrennte Raw Landing Zone? Führen Sie einen zusätzlichen Schritt ein und benennen Sie die vorhandenen Schritte so um, dass die Nummern den neuen Fluss widerspiegeln (zum Beispiel: 1_land/, 2_ingest/, 3_validate/, 4_transform/, 5_publish/). Lassen Sie den Ablauf die Phasen diktieren, nicht andersherum.
Wann Sie Domänenordner hinzufügen sollten: Eine Bühne mit mehr als 15 Notizbüchern ist schwer zu scannen. Gruppieren Sie dann nach Domäne, Quellsystem oder Geschäftsbereich innerhalb des Bühnenordners (z. B. 2_validate/notebooks/finance/, 2_validate/notebooks/marketing/). Vermeiden Sie das frühzeitige Hinzufügen von Ebenen, sie bringen nur Unruhe mit sich.
Schnelle Anti-Patterns (Was Sie vermeiden sollten)
| Smell | Why It Hurts | Fix |
|---|---|---|
| 50 items flat at root | No process order; scanning takes minutes instead of seconds | Move stage-specific items into numbered folders |
final_final_transform.ipynb | Version chaos; Git history tells the real story, not filenames | Use Git branches/commits, keep one canonical name |
Mixed CamelCase + snake_case | Slows scanning; inconsistency forces mental translation | Pick one style, enforce in code reviews |
| Over-nested folders | 1_ingest/sources/api/customers/raw/ is 5 layers deep for one file | Stay flat until navigation pain forces a split |
Was kommt als Nächstes?
In den kommenden Monaten werden wir weitere Artikel in dieser Serie veröffentlichen, die verschiedene Aspekte des Aufbaus von Microsoft Fabric behandeln. Wenn Sie Wünsche zu bestimmten Themen oder Feedback zu diesem Setup haben, können Sie sich gerne an uns wenden oder uns Ihre Ideen mitteilen - wir freuen uns über Ihren Beitrag!
Verfasst von
Rik Adegeest
Rik is a dedicated Data Engineer with a passion for applying data to solve complex problems and create scalable, reliable, and high-performing solutions. With a strong foundation in programming and a commitment to continuous improvement, Rik thrives on challenging projects that offer opportunities for optimization and innovation.
Unsere Ideen
Weitere Blogs




Contact