Blog
Umfassen Sie das Chaos, um Stabilität zu erreichen

Stellen Sie sich Folgendes vor. Sie haben eine Website erstellt, um die Produkte Ihres Unternehmens zu verkaufen. Nach ein paar Monaten harter Arbeit geht die Anwendung endlich online. Natürlich ist die Anwendung gründlich getestet worden. Alles begann mit Unit Tests. Zunächst auf dem lokalen Rechner und nachdem die Ingenieure einen Pull Request eingereicht hatten, wurde eine ganze Reihe von Prüfungen durchgeführt. Jedes Quality Gate wurde erfolgreich bestanden und eine vollautomatisierte Pipeline hat die Anwendung erfolgreich in einer Cloud-Umgebung bereitgestellt. Aber Sie sind noch einen Schritt weiter gegangen. Sie führten Lasttests, Sicherheitstests, Pen-Tests und Smoke-Tests durch. Und schließlich haben Sie Failover-Szenarien und Disaster-Recovery-Pläne erstellt und implementiert, um sicherzustellen, dass Sie so wenig Ausfallzeiten wie möglich haben, wenn die Kacke am Dampfen ist. Jetzt sind Sie bereit. Lassen Sie den Verkauf beginnen!
Und dann... wird alles schwarz. Das Rechenzentrum ist ausgefallen, und die Ausfallsicherung, die Sie sorgfältig eingerichtet haben, funktioniert nicht wie erwartet. Und nach ein paar Stunden Stress, wenn sich das Rechenzentrum wieder erholt hat, geht der Weg zurück nicht gut.
Dieses Szenario existiert nicht nur in einer Fantasiewelt. Es ist ein reales Szenario. Dinge passieren und Sie müssen darauf vorbereitet sein. Und die Wahrheit ist, dass Sie sich nicht auf alles vorbereiten können. Wenn Sie ein Unternehmen in der Cloud (aber auch in Ihren eigenen Rechenzentren) betreiben, müssen Sie sich mit der Tatsache abfinden, dass etwas schief gehen kann. Die Frage ist, wie gut Sie damit umgehen können.
Chaos Engineering
Als Netflix 2011 in die Cloud wechselte, wollte das Unternehmen die Tatsache angehen, dass es in der Produktion nicht genügend Ausfallsicherheitstests gab. Um sicherzustellen, dass sie auf unerwartete Ausfälle in der Produktion vorbereitet waren, entwickelten sie ein Tool namens Chaos Monkey. Dieses Tool verursachte Ausfälle und Zusammenbrüche auf zufällig ausgewählten Servern. Durch das Testen dieser "unerwarteten" Szenarien konnten sie überprüfen und lernen, ob ihre Infrastruktur mit Ausfällen umgehen und sich davon auf elegante Weise erholen konnte. Ohne es zu wollen, führte Netflix eine völlig neue Praxis ein. Chaos Engineering.
Das Einbrechen von Servern war eine Möglichkeit, dies zu testen, aber schnell wurden andere Szenarien relevant. Langsame Netzwerke, unzuverlässige Nachrichtenübermittlung, korrupte Daten, usw. Nicht viel später übernahmen auch andere Tech-Unternehmen, insbesondere diejenigen, die große und komplexe Landschaften in der Cloud betrieben, ähnliche Praktiken. Diese Praktiken, bei denen die Denkweise von der Erwartung stabiler Produktionssysteme zur Erwartung von Chaos in der Produktion wechselt, werden Chaos Engineering genannt.
Chaos Engineering ist ein Konzept, das Hypothesen und Experimente verwendet, um das erwartete Verhalten komplexer Systeme zu validieren. Auf diese Weise können Sie Vertrauen in die Zuverlässigkeit und Belastbarkeit dieser Systeme gewinnen.
Warum Chaos Engineering?
Mit Chaos Engineering können Sie vergleichen, was Sie denken, was passieren wird, und was tatsächlich in Ihren Systemen passiert. Sie machen buchstäblich "Sachen kaputt", um zu lernen, wie Sie widerstandsfähigere Systeme bauen können. Aber es gibt ein paar wichtige Unterschiede. Daher können Sie Chaos Engineering als eine Art Testübung betrachten. Aber es gibt wichtige Unterschiede. Zunächst einmal wird Chaos Engineering, wenn es richtig gemacht wird, auch auf Produktionssystemen durchgeführt. Zweitens testen Sie bei Chaos Engineering nicht wirklich auf Fehler. Sie testen im Voraus und versuchen durch Chaos-Experimente zu beweisen, dass die Annahmen, die Sie in Ihren Testszenarien und Ihrer Architektur getroffen haben, tatsächlich gültig sind und funktionieren.
Mit der zunehmenden Komplexität unserer Infrastruktur, bedingt durch Softwarearchitekturen wie Microservices, aber auch durch die "vernetzten" Systeme, die wir heutzutage aufbauen, reicht der traditionelle QS-Ansatz nicht mehr aus. Es gibt einfach zu viel, was schief gehen kann, und angesichts der Dynamik der Software und des Infrastruktur-Stacks kann dies jeden Tag anders sein. Beim Chaos Engineering beginnt alles mit einer Hypothese. Und auf der Grundlage dieser Hypothese definieren Sie Experimente und führen diese durch, um zu beweisen, dass Ihre Hypothese funktioniert.
Zum Beispiel: "Wenn der externe Zahlungsanbieter, den ich verwende, nicht verfügbar ist, erhalten meine Kunden die Möglichkeit, nachträglich zu bezahlen und den Bestellvorgang fortzusetzen".
Die 5 Prinzipien des Chaos Engineering
Um mit Chaos Engineering zu beginnen, können Sie diesen einfachen Plan nutzen, um eine Reihe von Schritten zu durchlaufen, die ich im weiteren Verlauf dieses Artikels näher erläutern werde
Bevor wir das tun, ist es gut zu verstehen, dass Chaos Engineering nicht etwas ist, das Sie an einem verregneten Sonntagnachmittag machen können. Chaos Engineering erfordert eine sorgfältige Planung und eine Analyse der Auswirkungen. Sie müssen verstehen, was passiert, wenn Ihre Hypothese falsch ist. Sie müssen auch den "Explosionsradius" verstehen. Mit anderen Worten, was passiert, wenn die Dinge nicht so laufen, wie Sie es geplant haben. Und damit verbunden: Sind während der Durchführung des Experiments Personen verfügbar?
Die Website Principles of Chaos Engineering beschreibt 5 Prinzipien, die Sie beim Chaos Engineering berücksichtigen sollten
- Erstellen Sie eine Hypothese über das stationäre Verhalten Das bedeutet, dass Sie sich auf das konzentrieren sollten, was für den Kunden sichtbar ist. Nicht die interne Funktionsweise eines Systems oder Dinge, die Sie nur beeinflussen können, wenn Sie das Innenleben kennen. Konzentrieren Sie sich auf den Steady-State und die Metriken, die zu einem Steady-State gehören
- Variieren Sie die realen Ereignisse Priorisieren Sie die Ereignisse auf der Grundlage der erwarteten Häufigkeit. Berücksichtigen Sie alles, was den stabilen Zustand des Systems beeinflussen kann. Zum Beispiel Festplattenausfälle, Serversterben oder Netzwerkausfälle.
- Führen Sie Experimente in der Produktion durch Simulationen und Stichproben sind großartig, aber die Verwendung von realen Daten und Metriken ist noch besser. Versuchen Sie, wann immer möglich, in der Produktion zu arbeiten. Das erfordert natürlich eine sorgfältige Planung und die Einbeziehung der Mitarbeiter. Normalerweise geschieht dies an so genannten Spieltagen, wenn die Leute bereit für das "Spiel" sind. Wenn Sie mit Chaos Engineering beginnen, ist es vielleicht besser, Ihre Hypothesen an nicht produktiven Systemen zu überprüfen. Fangen Sie dort an, um eine Vorstellung davon zu bekommen, was Sie erwarten und was Sie messen sollten. Die Produktion bringt eine zusätzliche Ebene der Komplexität und Kontrolle mit sich, denn Sie müssen sicherstellen, dass Ihre Benutzer nicht beeinträchtigt werden.
- Automatisieren Sie Experimente, damit sie kontinuierlich laufen Wie bei fast allem in DevOps. Automatisierung ist der Schlüssel. Die Durchführung von Experimenten und das Sammeln von Metriken ist zeitintensiv und mühsam. Stellen Sie sicher, dass Sie dies automatisieren, damit Sie das Experiment wiederholt durchführen können. Aufgrund der Natur des Chaos Engineering können im Laufe der Zeit Dinge passieren.
- Minimieren Sie den Explosionsradius Experimente in der Produktion können den Kunden unnötige Schmerzen bereiten. Seien Sie sich dessen also bewusst. Stellen Sie sicher, dass in Ihrem Fehlerbudget noch Platz ist, oder bereiten Sie sich auf Probleme vor. Negative Auswirkungen müssen einkalkuliert werden, aber halten Sie die Auswirkungen von Experimenten möglichst gering.
Wie funktioniert das?
Beim Chaos Engineering müssen Sie eine Reihe von Schritten durchlaufen. Diese Schritte werden bei jedem neuen Experiment befolgt. Wie ich bereits beschrieben habe, ist es wichtig, dies sorgfältig zu planen. Da viele der Chaos-Experimente auf Produktionssystemen durchgeführt werden, können Sie leicht Dinge kaputt machen, die Auswirkungen auf die Kunden haben. Oft entscheiden sich Unternehmen dafür, sogenannte Game Days zu organisieren. An diesen Tagen wissen die Mitarbeiter, dass Chaos-Experimente durchgeführt werden, und können in Bereitschaft bleiben oder besonders vorsichtig sein, um die Systeme auf seltsames Verhalten zu überwachen.
Bei der Durchführung von Chaosexperimenten können Sie dieser Struktur folgen:
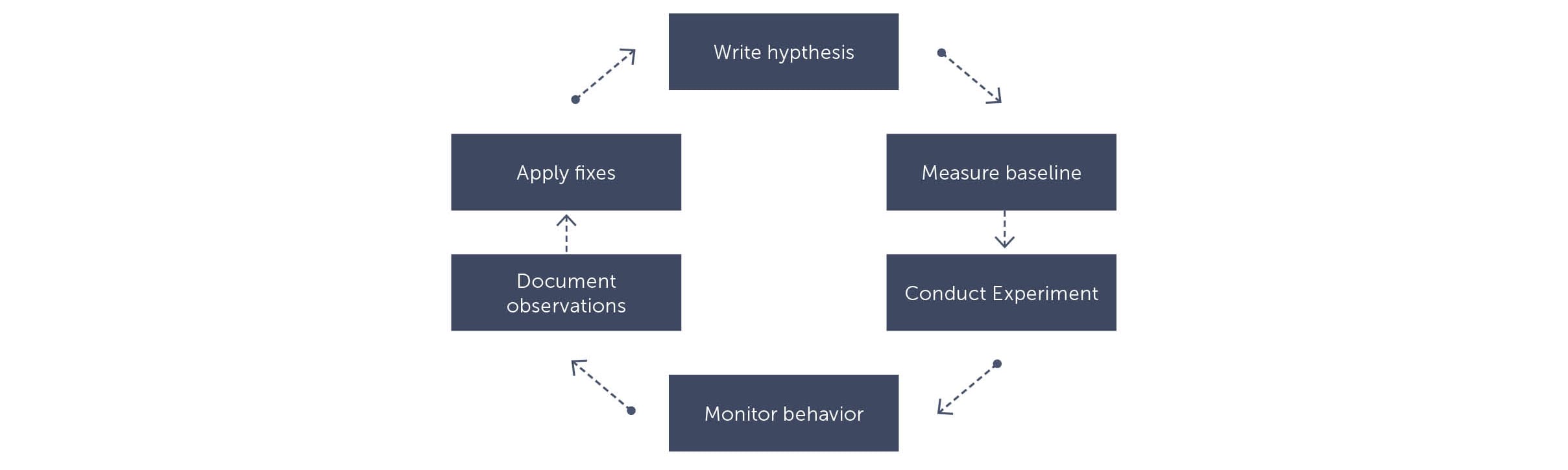
Schreiben Sie eine Hypothese
Beim Chaos Engineering beginnt alles mit einer Hypothese. Das ist wichtig! Es handelt sich nicht um einen Test. Die Hypothese "Der Zahlungsdienst sollte reagieren" ist zum Beispiel keine gültige Hypothese. Das ist etwas, das Sie bereits in Ihrer Testsuite behandelt haben sollten. Beim Chaos Engineering geht es darum, Ihre Anwendung widerstandsfähiger zu machen. Sie sollten sich bereits ziemlich sicher sein, dass Ihr System mit unbekannten Situationen umgehen kann, und Ihre Hypothese sollte darauf aufbauen. Zum Beispiel. "Wenn der Zahlungsdienst ausfällt, bieten wir unseren Kunden eine alternative Zahlungsmethode an". Denken Sie an den Benutzer. Wie kann der Benutzer seine Reise mit den geringsten Auswirkungen fortsetzen? Ein gutes Beispiel, das Netflix anwendet, wenn die Anmeldefunktion nicht mehr funktioniert, ist, dass sie ihre Dienste kostenlos anbieten, ohne sich anzumelden. Auf diese Weise können die Nutzer immer noch tun, was sie tun müssen.
Messen Sie das Ausgangsverhalten
Bevor Sie ein Experiment durchführen, sollten Sie sich über das Grundverhalten im Klaren sein. Wie reagiert Ihr System normalerweise? Mit anderen Worten, können Sie Anomalien erkennen? Sie sollten eine gute Vorstellung von der Ausgangssituation haben, da Sie sonst die falschen Schlüsse ziehen können. Wenn Sie z.B. ein Experiment durchführen, um zu beweisen, dass Ihre Antwortzeiten gleich bleiben wie "gewöhnlich", sollten Sie wissen, was gewöhnlich ist. Vielleicht variiert diese Zeit im Laufe des Tages aufgrund des Verkehrs auf Ihrer Website. Wenn Sie ein Experiment in diesem Zeitrahmen durchführen, könnten Sie seltsame Dinge sehen, die durch andere Faktoren als Ihr Experiment verursacht werden.
Wenn Sie über die Erstellung der Baseline nachdenken, sollten Sie an Metriken und Benutzerkennzahlen denken, die im Hinblick auf das Experiment und die Hypothese, an der Sie arbeiten, wichtig sind. Nicht alles ist zur gleichen Zeit relevant.
Experiment durchführen
Wenn Sie die Hypothese und die Basislinie erstellt haben, können Sie ein Experiment durchführen. Ein Experiment zu starten bedeutet, das Verhalten hervorzurufen, das Ihre Hypothese widerlegen würde. Also Verlangsamung des Datenverkehrs, Herunterfahren eines Dienstes, Abschalten oder Töten von Containern usw. Verschiedene Tools können Ihnen bei der Durchführung von Chaos-Experimenten helfen. Viele von ihnen zielen auf virtuelle Maschinen oder einen Kubernetes-Cluster ab und richten auf der Infrastrukturebene Chaos an. Natürlich können Sie auch Ihre eigenen Skripte oder Tools schreiben, die Ihnen bei Ihren Experimenten helfen können.
Die wichtigsten Tools, die Sie verwenden können, sind:
- Gremlin ( gremlin Website)
- Chaos Toolkit(Chaos Toolkit Website)
- Chaos Mesh(Chaos Mesh Website )
- Azure Chaos Studio(Azure Chaos Studio Website )
Überwachen Sie das resultierende Verhalten
Wenn Sie das Experiment durchgeführt haben, ist es an der Zeit, sich die Metriken erneut anzusehen. Was sehen Sie? Sehen Sie das erwartete Verhalten Ihres Systems? Ist die Hypothese gültig? Wenn Sie sehen, dass sich das System nicht wie erwartet verhält, versuchen Sie, so viele Informationen wie möglich zu sammeln, warum dies der Fall ist. Stellen Sie außerdem sicher, dass Sie den Explosionsradius und die tatsächlichen Auswirkungen auf die Benutzer im Auge behalten.
Dokumentieren Sie den Prozess und Ihre Beobachtungen.
Nach dem Experiment haben Sie Ihre Hypothese entweder bewiesen oder widerlegt. Stellen Sie sicher, dass Sie den Prozess, den Sie durchgeführt haben, dokumentieren und vor allem, wenn Sie feststellen, dass Ihre Hypothesen gescheitert sind, stellen Sie sicher, dass Sie Ihr Lernen dokumentieren. Machen Sie vielleicht eine tadellose Lernkontrolle, um herauszufinden, was passiert ist, und schreiben Sie die Lernkontrolle für die Zukunft auf.
Identifizieren Sie Korrekturen und wenden Sie sie an
Wenn Sie feststellen, dass Ihre Hypothesen nicht funktionieren, nehmen Sie die notwendigen Korrekturen vor und automatisieren Sie das Experiment. Stellen Sie sicher, dass Sie die Experimente mehrmals durchführen können. Vielleicht sogar nach einem Zeitplan. Systeme ändern sich und Umgebungen ändern sich, und Sie müssen Ihre Hypothesen immer wieder überprüfen.
Wie kann ich mit Chaos Engineering beginnen?
Mit Chaos Engineering können Sie jederzeit beginnen, solange Sie die Auswirkungen auf den Benutzer und den Explosionsradius berücksichtigen. Eine gängige Methode, Chaos einzuführen, besteht darin, absichtlich Fehler einzufügen, die zum Ausfall von Systemkomponenten führen. Das ultimative Ziel von Chaos Engineering ist es, eine widerstandsfähigere und zuverlässigere Anwendung zu schaffen. Mit den Praktiken des Chaos Engineering müssen Sie testen und validieren, dass Ihre Anwendung tatsächlich widerstandsfähiger ist. Architekturmuster wie Circuit Breakers, Failover und Retry können wirklich dazu beitragen, Ihre Anwendung robuster zu machen. Nachdem Sie Ihre Anwendung erstellt haben, müssen Sie die Zuverlässigkeit Ihres Systems unter ungünstigen Umständen beobachten, überwachen, darauf reagieren und verbessern. Wenn Sie beispielsweise Abhängigkeiten offline schalten (API-Anwendungen stoppen, VMs herunterfahren usw.), den Zugriff einschränken (Firewall-Regeln aktivieren, Verbindungsstrings ändern usw.) oder ein Failover erzwingen (Datenbankebene, Front Door usw.), ist dies ein guter Weg, um zu überprüfen, ob die Anwendung in der Lage ist, Fehler anständig zu behandeln.
Ein wichtiger Hinweis ist, dass Sie klein anfangen sollten. Beginnen Sie mit der Definition einer Hypothese und einem sehr kleinen Experiment und gehen Sie die verschiedenen Schritte durch, die ich oben beschrieben habe. Um Ihre erste Hypothese zu definieren, sollten Sie sich Dinge ansehen, von denen Sie erwarten, dass sie richtig sind, die Sie aber nie wirklich betrachtet haben. Eine gute Inspirationsquelle ist eine Keynote von Adrian Cockroft Sehen Sie sich das YouTube-Video an. In dieser Keynote erklärt er einige grundlegende Dinge, die schief laufen. Zu Ihrer Erleichterung habe ich eine Reihe dieser Kategorien und Dinge, die schief gehen können, aufgelistet
Ausfälle der Infrastruktur
| Gerätefehlfunktionen | Festplatte, Stromversorgung, Verkabelung, Platine, Firmware |
| CPU-Ausfälle | Cache-Beschädigung, Logik-Fehler |
| Ausfälle im Rechenzentrum | Stromversorgung, Konnektivität, Kühlung, Feuer, Überschwemmung, Wind, Erdbeben |
| Internet-Ausfälle | DNS, ISP, Internet-Routen |
Software Stapel Ausfälle
| Zeitbomben | Zählerumlauf, Speicherleck |
| Datumsbomben | Schaltjahr, Schaltsekunde, Epoche |
| Ende der Unix-Zeit | |
| Verfall | Zertifikate verfallen |
| Entzug | Schließung der Lizenz oder des Kontos durch den Anbieter |
| Ausnutzen | Sicherheitslücken, z.B. Heartbleed |
| Fehler in der Sprache | Compiler, Interpreter |
| Laufzeit-Fehler | JVM, Docker, Linux, Hypervisor |
| Probleme mit dem Protokoll | Latenzabhängige oder schlechte Fehlerbehebung |
Anwendung Ausfälle
| Zeitbomben (im Anwendungscode) | Zählerumlauf, Speicherleck |
| Datumsbomben (im Anwendungscode) | Schaltjahr, Schaltsekunde, Epoche, Y2K |
| Inhalt Bombe | Datenabhängige Ausfälle |
| Konfiguration | Falsche Konfiguration oder falsche Syntax |
| Versionierung | Inkompatible Versionen |
| Kaskadierende Fehler | Fehler in der Fehlerbehandlung |
| Kaskadierende Überlastung | Übermäßige Protokollierung, Sperrkonflikte, Hysterese |
| Wiederholungsstürme | Zu viele Wiederholungsversuche, Arbeitsverstärkung, schlechte Timeout-Strategie |
Operationen Ausfälle
| Schlechte Kapazitätsplanung | |
| Unzureichendes Management von Zwischenfällen | |
| Versäumnis, einen Vorfall zu initiieren | |
| Zugriff auf Überwachungs-Dashboards nicht möglich | |
| Unzureichende Beobachtbarkeit von Systemen | |
| Falsche Korrekturmaßnahmen |
Zusammenfassung
Chaos Engineering ist für viele Menschen ziemlich neu. Obwohl es schon seit einigen Jahren existiert, ist es noch nicht bei einem breiten Publikum angekommen. Das ist schade, denn Chaos Engineering kann Ihnen wirklich helfen, widerstandsfähigere Systeme zu bauen. Indem Sie Hypothesen aufstellen und Experimente durchführen, um Ihre Hypothesen zu beweisen, können Sie Ihr System auf unerwartete Situationen hin testen. Es gibt viele kleine Experimente, die Sie mit Ihrem System durchführen können, so dass der Einstieg sehr einfach sein sollte. Berücksichtigen Sie jedoch immer die möglichen Auswirkungen auf die Benutzer und den Explosionsradius und planen Sie Ihren Spieltag sorgfältig.
Der geschäftliche Nutzen von Chaos Engineering
Chaos Engineering. Das scheint etwas zu sein, das Sie um jeden Preis vermeiden sollten. Jeder Vorstand würde es wahrscheinlich ablehnen, dies im Unternehmen einzuführen. Aber das Gegenteil ist der Fall. Was wäre, wenn wir Chaos Engineering wie folgt erklären könnten: "In einem kontrollierten Rahmen die Belastbarkeit und Wiederherstellungsmöglichkeiten Ihrer Systeme kontinuierlich überprüfen". Denn darum geht es beim Chaos Engineering im Grunde genommen. Es geht nicht darum, Dinge absichtlich kaputt zu machen, sondern um die Verifizierung von ausgereiften Experimenten, um zu sehen, wie sich Ihre Systeme verhalten.
Um den Geschäftswert von Chaos Engineering zu bestimmen, können wir verschiedene Ansätze verwenden. Wenn Sie den "Ausfallzeit-Rechner" von Atlassian verwenden, können wir den Geldbetrag berechnen, der verloren geht, wenn unsere Systeme ausfallen. Aber es geht um mehr als nur um Geld. Wenn Ihre Kunden Ihre Systeme nicht nutzen können, kommen auch noch andere Faktoren ins Spiel:
- Das Geschäft der Kunden wird gestört
- Auswirkungen auf Loyalität und Ruf
- Verlorene Einnahmen für Sie und Ihre Kunden
- Produktivität der Mitarbeiter
Indem Sie Chaosexperimente durchführen, versuchen Sie ständig, Hypothesen über Ihr System zu widerlegen. Und Sie überprüfen ständig, ob sich das System so verhält, wie es sollte. Indem Sie Hypothesen widerlegen, wächst das Vertrauen in das System und seine Widerstandsfähigkeit. So können Sie Ihren Kunden einen besseren Service bieten, ihnen vielleicht eine bessere SLA anbieten und damit Ihre Position gegenüber der Konkurrenz stärken.
Das Gute an Chaos Engineering ist, dass es keine großen Vorabinvestitionen erfordert. Sie können klein anfangen. Wenn Ihr Unternehmen auf Disaster Recovery spezialisiert ist oder bereits über ein Team verfügt, das sich mit der Überwachung von SLAs oder der Verfügbarkeit befasst, dann betreiben Sie bereits ein wenig Chaos Engineering. Von hier aus können Sie das Bewusstsein und die Fähigkeiten dieser Leute zu wirkungsvolleren Praktiken des Chaos Engineering ausbauen.
Verfasst von
Rene van Osnabrugge
As Global Consulting Director, Rene enables consultants to help organizations and leadership teams to build an engineering culture that allows them to build, deliver, and operate software in a secure and compliant way. With a focus on both the technical and cultural aspects of a company, Rene helps clients transform their work processes, operating model, and culture to become high-speed, innovative, and productive. Rene is passionate about learning new technologies and exploring the cultural and people aspects of companies. He believes that by focusing on both technical implementation and cultural development, we can drive our industry forward. He loves sharing his knowledge and insights at conferences and training events. As a frequently asked speaker at well-known industry events like GitHub Universe, NDC, Techorama, AllDayDevOps, NDC, and Visual Studio Live!, Rene is known for his expertise in Microsoft Azure, DevOps, and DevOps Culture. In addition to being a Microsoft MVP since 2012, he is also the founder of the popular community events Global DevOps Bootcamp and Global DevOps Experience.
Contact