Blog
Dynamische SQL-Verarbeitung mit Apache Flink

In diesem Blogbeitrag möchte ich die verborgenen Möglichkeiten der dynamischen SQL-Verarbeitung mit der aktuellen Flink-Implementierung vorstellen. Ich werde eine benutzerdefinierte Komponente auf der Basis von KeyedBroadcastProcessFunction vorstellen, die die Ereignisquelle und die SQL-Quelle als Eingabe verwenden kann und das Ergebnis jeder gesendeten Abfrage zurückgibt. Damit ist es möglich, mehrere Flink-SQL-Abfragen auf eine dynamische, benutzerorientierte Weise auszuführen.
Sehen Sie sich hier die Demo zur dynamischen SQL-Verarbeitung an. Die Implementierung basiert auf einer Demo aus dieser großartigen Blog-Serie von Alexander Fedulov. In dieser Blogserie werden Muster der dynamischen Datenpartitionierung und der dynamischen Aktualisierung der Anwendungslogik mit Fensterverarbeitung anhand der in JSON-Konfigurationsdateien festgelegten Regeln vorgestellt. Fedulovs Implementierung der dynamischen Prozessfunktionen basierte ebenfalls auf KeyedBroadcastProcessFunction, so dass es auch möglich war, einen Teil des Codes dieser Implementierung wiederzuverwenden. Darüber hinaus basiert die Webanwendung, die für die Demo der dynamischen SQL-Verarbeitung erstellt wurde, auf der Demo-Webanwendung von Fedulov, die auf unsere Bedürfnisse zugeschnitten wurde. Während die in Fedulovs Demo definierten Konfigurationsmöglichkeiten umfangreich sind, ist die Allgemeinheit der hier vorgestellten Lösung größer, da sie die dynamische Ausführung beliebiger SQLs anstelle der JSON-Vorlagen-basierten Ausführung ermöglicht.
In den folgenden Abschnitten erfahren Sie mehr über das Konzept und die Implementierung der Lösung, lernen die Demo-Funktionen kennen und erfahren, wie es weitergehen könnte.
Konzept
Betrachten wir ein Szenario, in dem ein Unternehmen daran interessiert ist, neue Datenströme für Analysezwecke zu erstellen und Flink SQL zur Abfrage der vorhandenen Datenströme zu verwenden. Das Analystenteam ist in der Lage, schnell neue Streams mit interessanten Erkenntnissen zu entwickeln, stößt aber bei der Bereitstellung dieser Streams in der Produktion auf einen Engpass. Wenn Änderungen an bestehenden Flink-Aufträgen vorgenommen wurden, mussten diese neu bereitgestellt werden, was zu möglichen Ausfallzeiten führte und den Prozess des Analyseteams noch komplexer machte.
Die vorgestellte Lösung zielt darauf ab, die Ausfallzeiten zu beseitigen, indem sie es dem Analyseteam ermöglicht, die entwickelten Abfragen nach Belieben auszuführen, ohne dass Flink-Jobs neu verteilt werden müssen, und sofort Feedback zu den Erkenntnissen zu erhalten, die durch neue Datenströme gewonnen wurden.
Das Grundkonzept, das dies möglich macht, wird im folgenden Diagramm dargestellt. Der gewünschte Operator kann die Ereignisquelle und die Quelle der SQL-Abfragen, die mit der Ereignisquelle ausgeführt wurden, als Eingabe verwenden. Bei der Ereignisquelle wird davon ausgegangen, dass sie vorverschlüsselt ist. Der SQL-Datenstrom wird an jede der physischen Partitionen der Eingabe gesendet. Für jedes eingehende übertragene SQL-Ereignis wird die SQL-Abfrage innerhalb des Ereignisses ausgeführt. Für jedes eingehende Quellereignis werden die SQL-Abfragen und ihre Ergebnisse zurückgegeben.
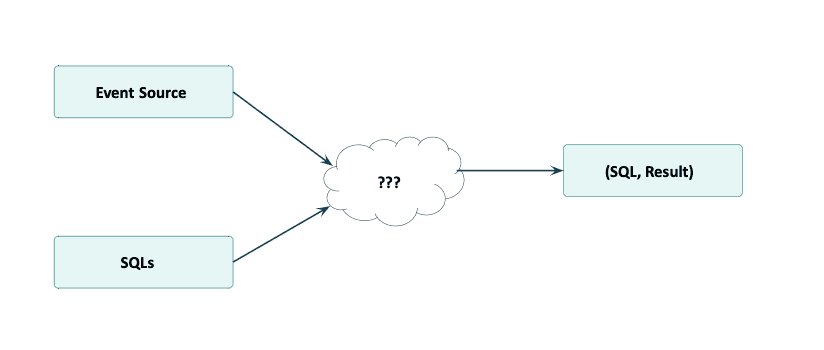
Dieses Konzept der dynamischen SQL-Ausführung ist etwas, das Flink (Stand: v1.11.1) nicht standardmäßig bietet, da es derzeit nicht möglich ist, eine neue Flink-SQL auf einem bestehenden Ablauf auszuführen, ohne den Auftrag neu zu verteilen. Der Trick, damit dies funktioniert, besteht darin, neue Flink-Instanzen dynamisch innerhalb der Flink-Prozessfunktion zu erstellen - eine "Flinkception", wenn Sie so wollen. Dieser Trick wird im Abschnitt Implementation details ausführlicher behandelt.
Demo
Um auf den Inhalt der Demo zuzugreifen, klonen Sie einfach das Repository:
git clone git@gitlab.com:<GitHub link>.gitEine ausführliche Anleitung zur Ausführung einer Demo finden Sie unter README.md. Um eine Demo in einer Standardeinstellung auszuführen, genügen jedoch die folgenden Befehle:
docker build -t demo-webapp:latest -f webapp/webapp.Dockerfile webapp/
docker build -t demo-flink-job:latest -f flink-job/Dockerfile flink-job/
docker-compose -f docker-compose-local-job.yaml up
Nachdem Sie die oben genannten Schritte durchgeführt haben, besuchen Sie die Website location:5656, um die React-Webanwendung der Demo zu sehen.
Nachdem Sie die oben genannten Schritte durchgeführt haben, besuchen Sie die Website location:5656, um die React-Webanwendung der Demo zu sehen.
Die Demo ermöglicht die Interaktion mit einem Strom von zufällig generierten Finanztransaktionen nach folgendem Schema, das wiederum aus diesem Blog kopiert wurde:
- transactionId
- eventTime
- payeeId
- beneficiaryId
- paymentAmount
- paymentType
- ingestionTimestamp
Standardmäßig wird beim Start der Anwendung bereits eine SQL-Regel ausgeführt. Von nun an sind die folgenden Aktionen verfügbar:
Fügen Sie eine SQL-Regel hinzu - wählen Sie eine der Standardregeln oder schreiben Sie Ihre eigene
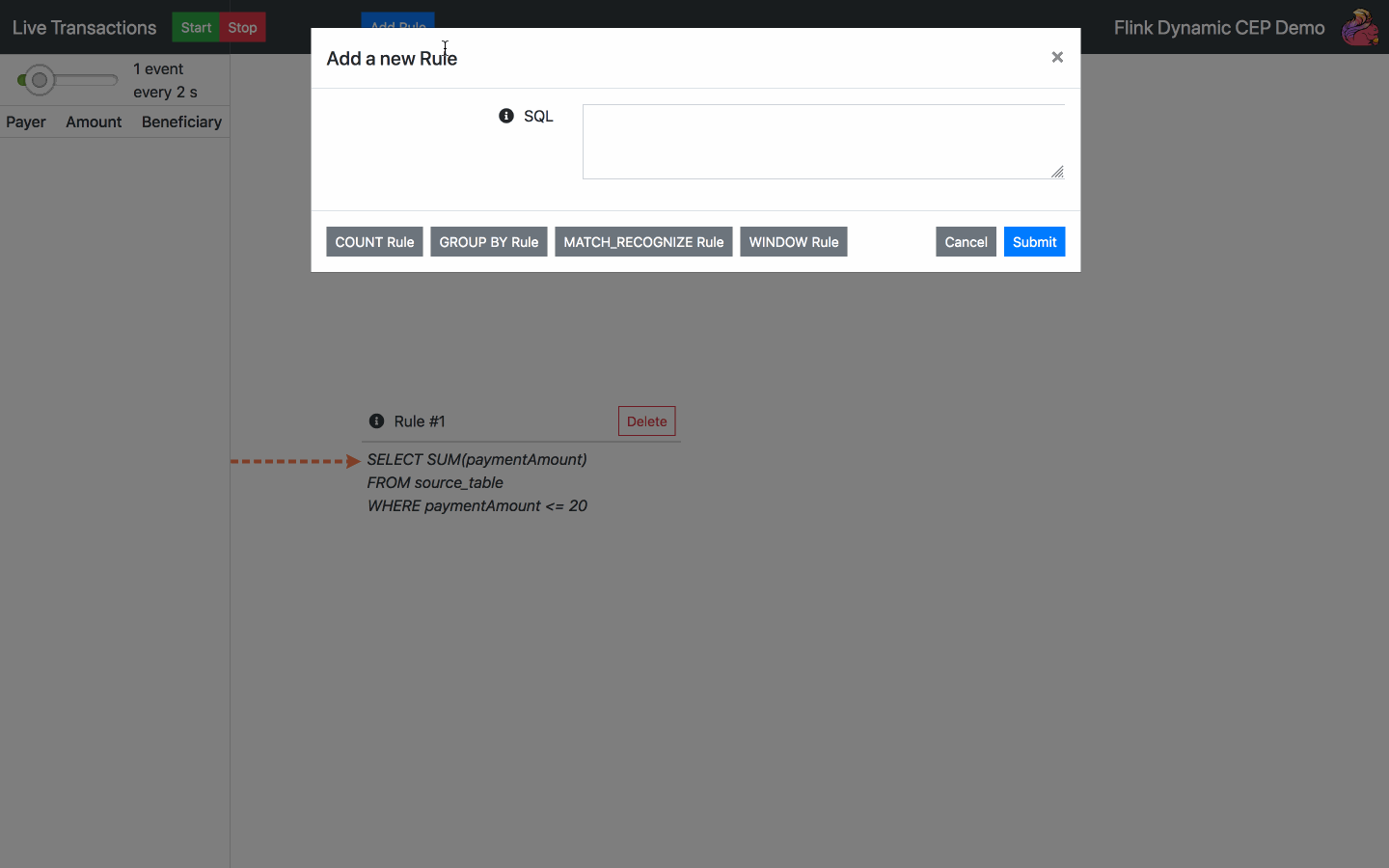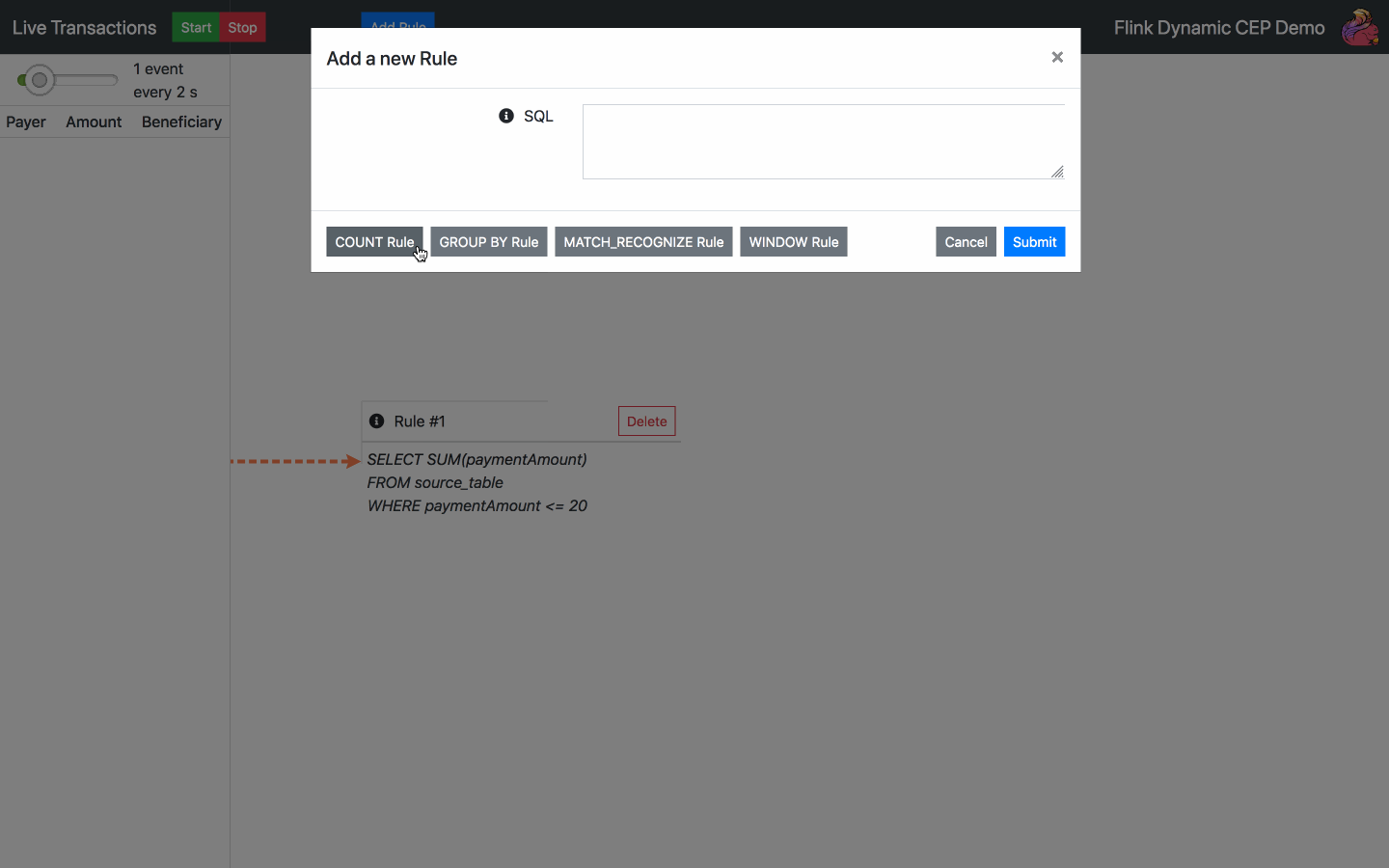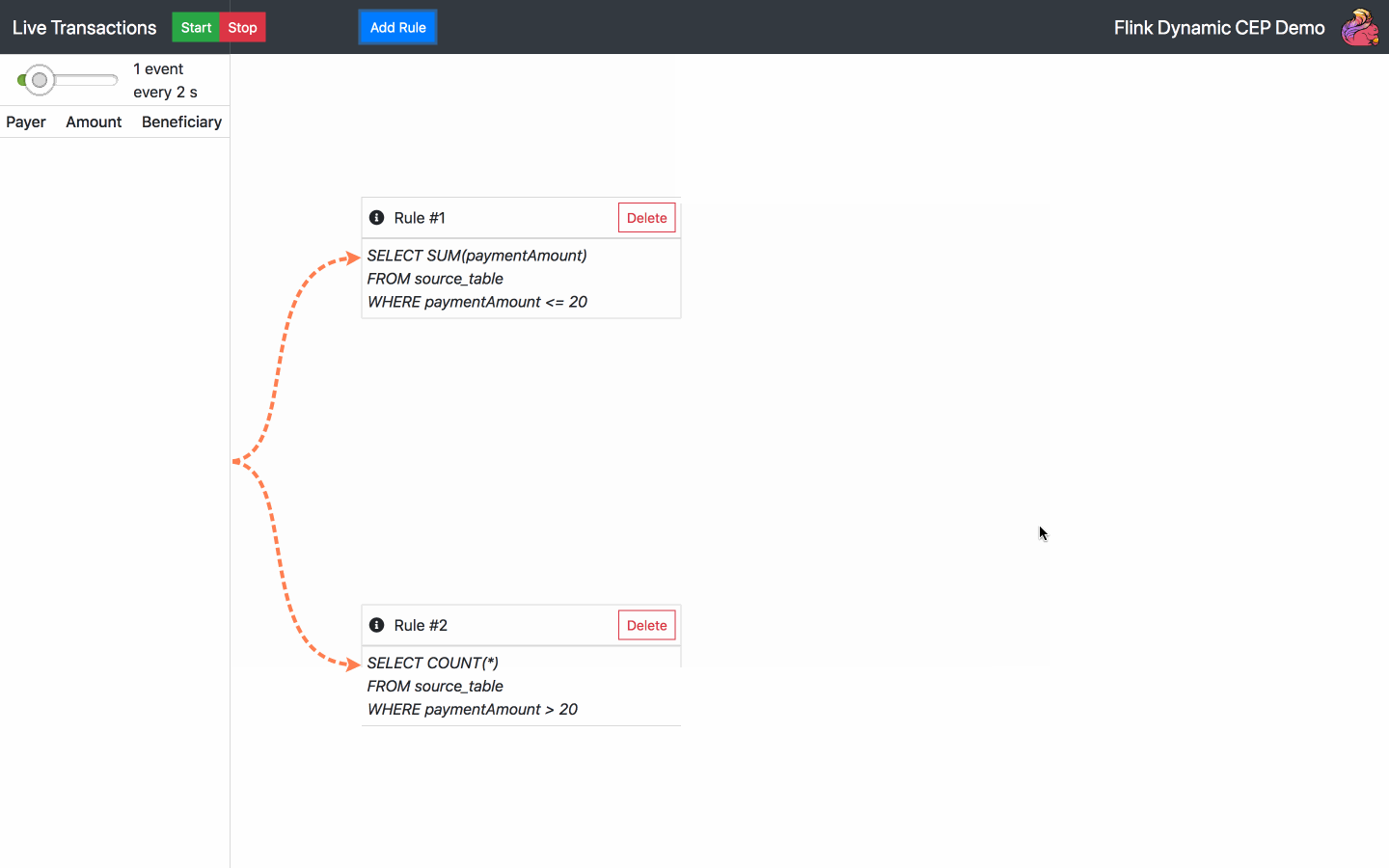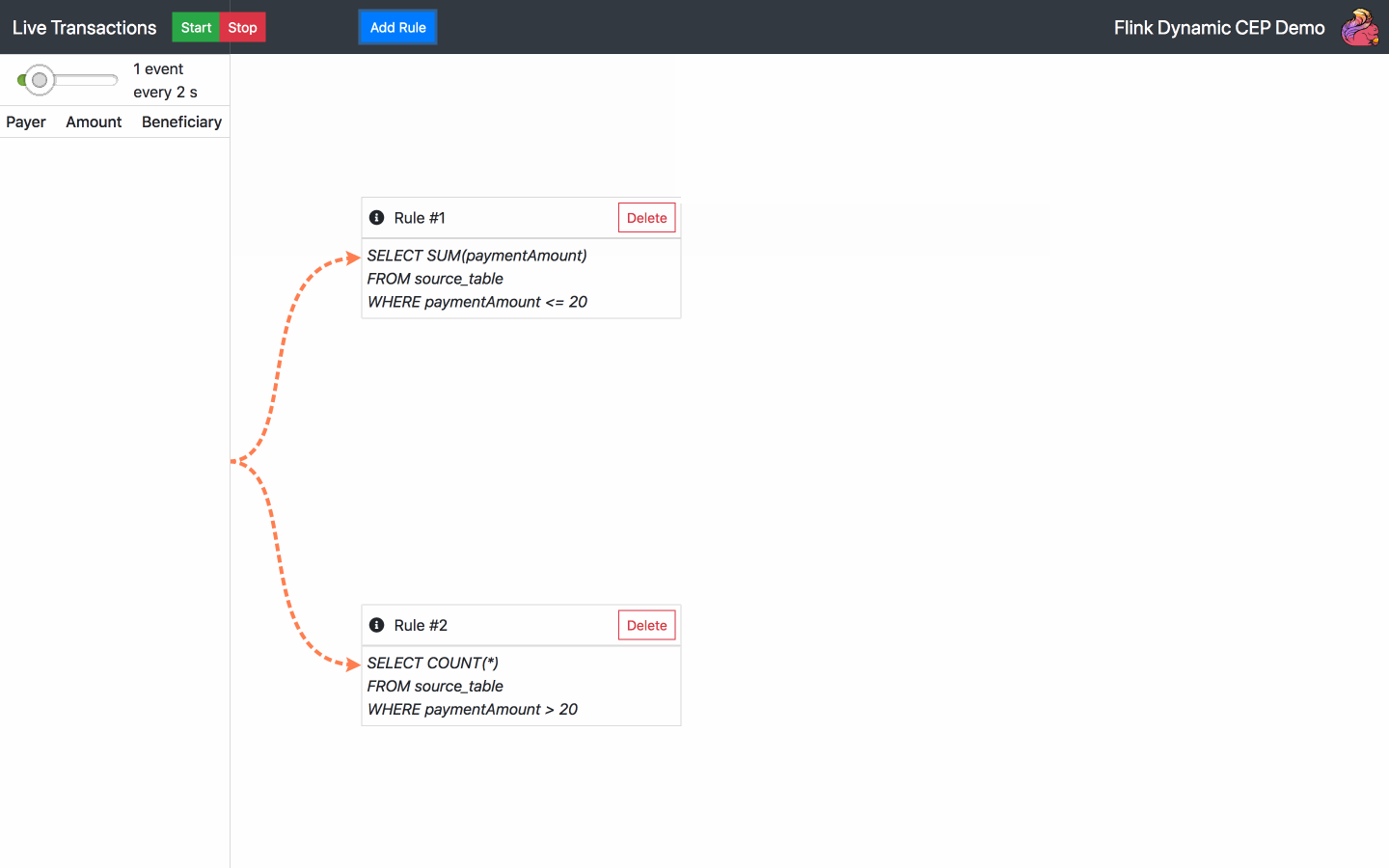
Regel löschen - wählen Sie eine der aktuellen Regeln zum Löschen aus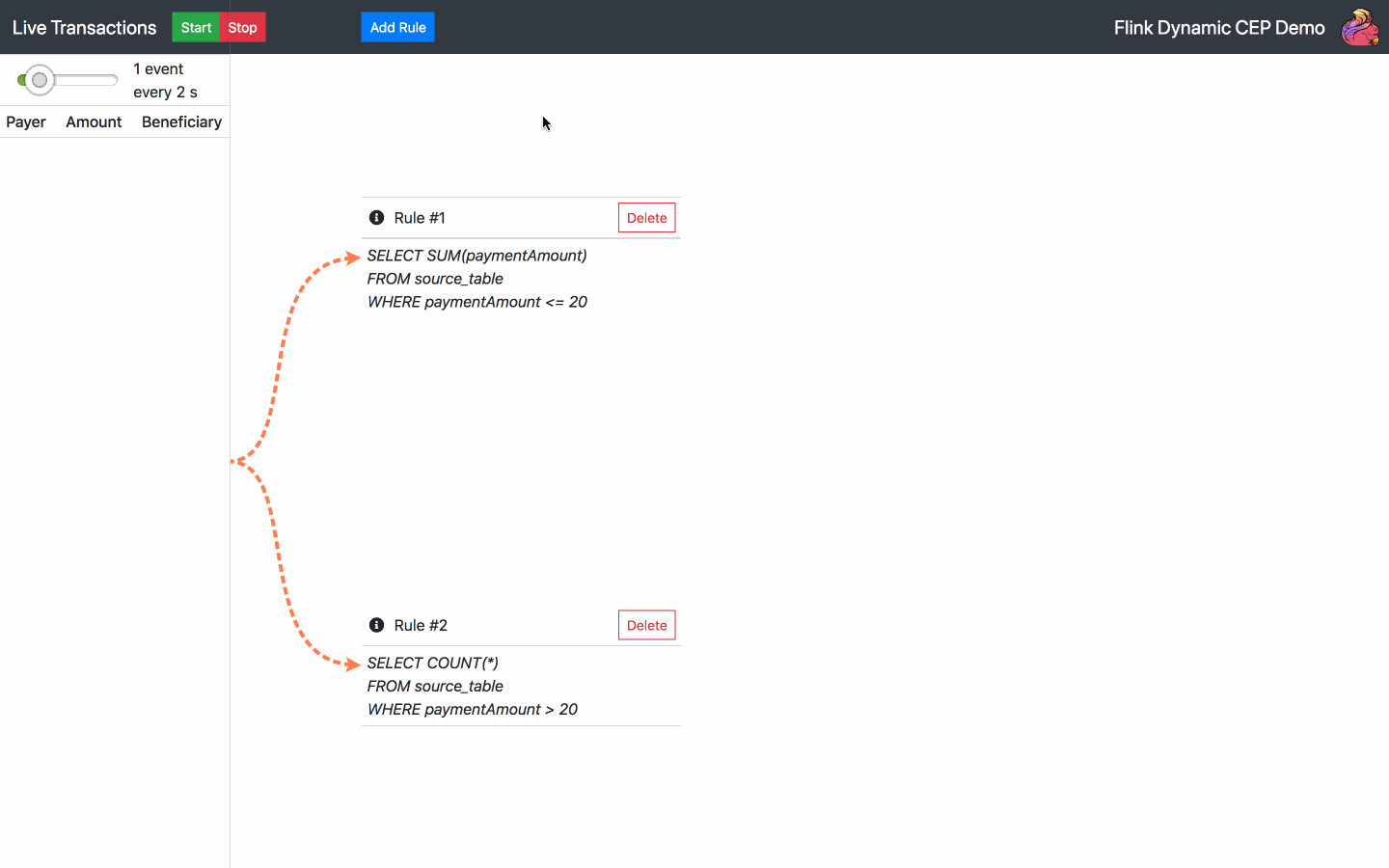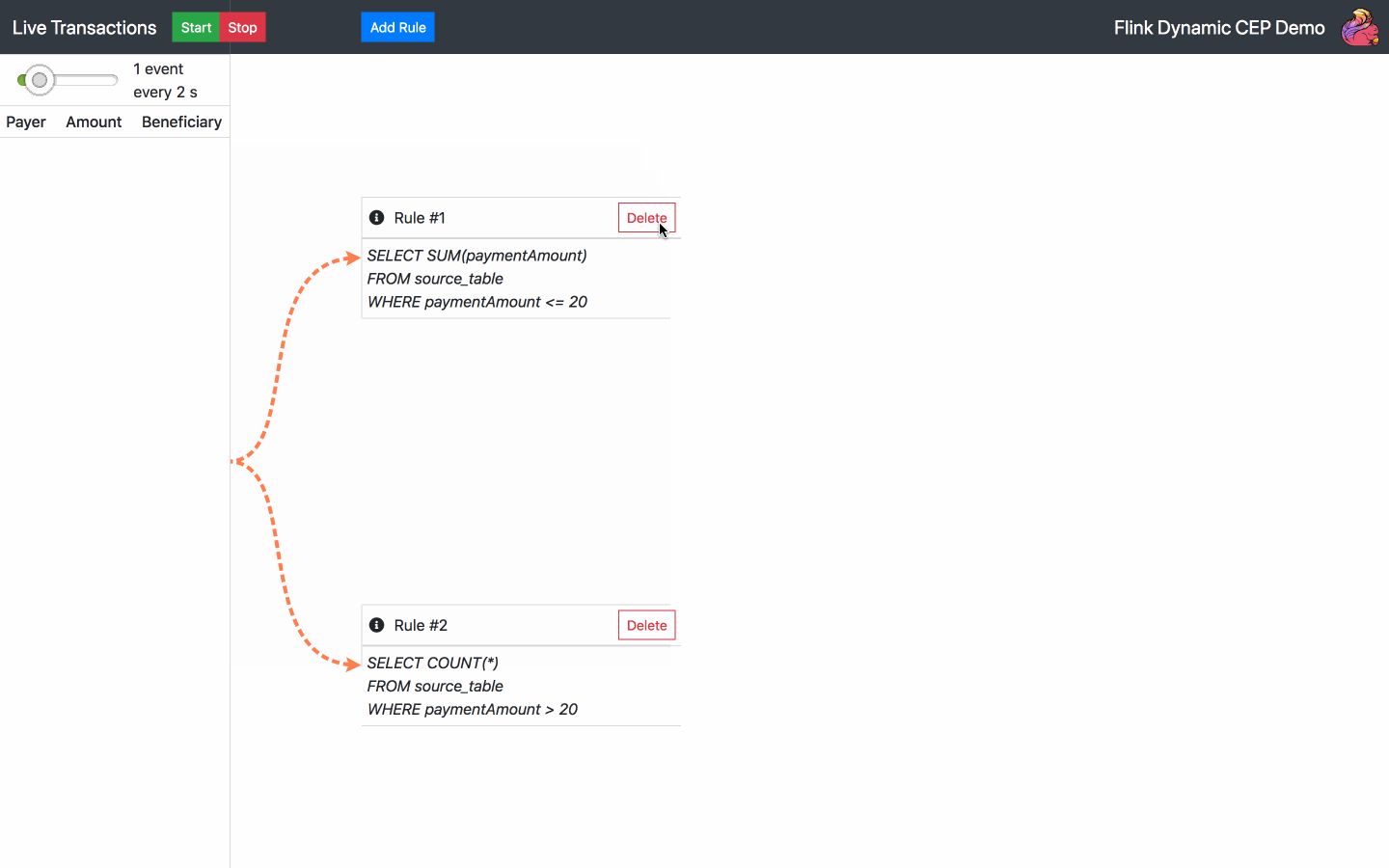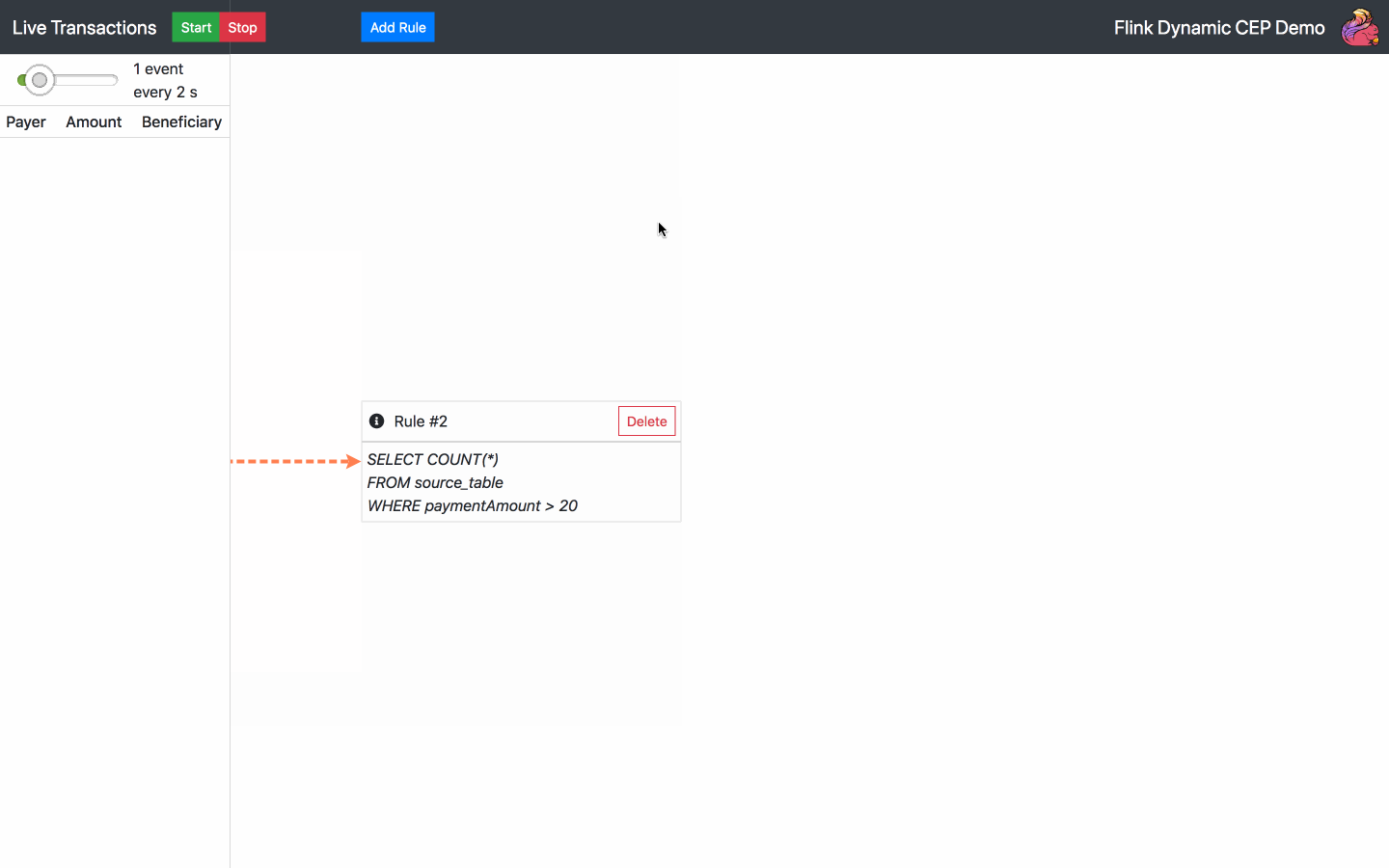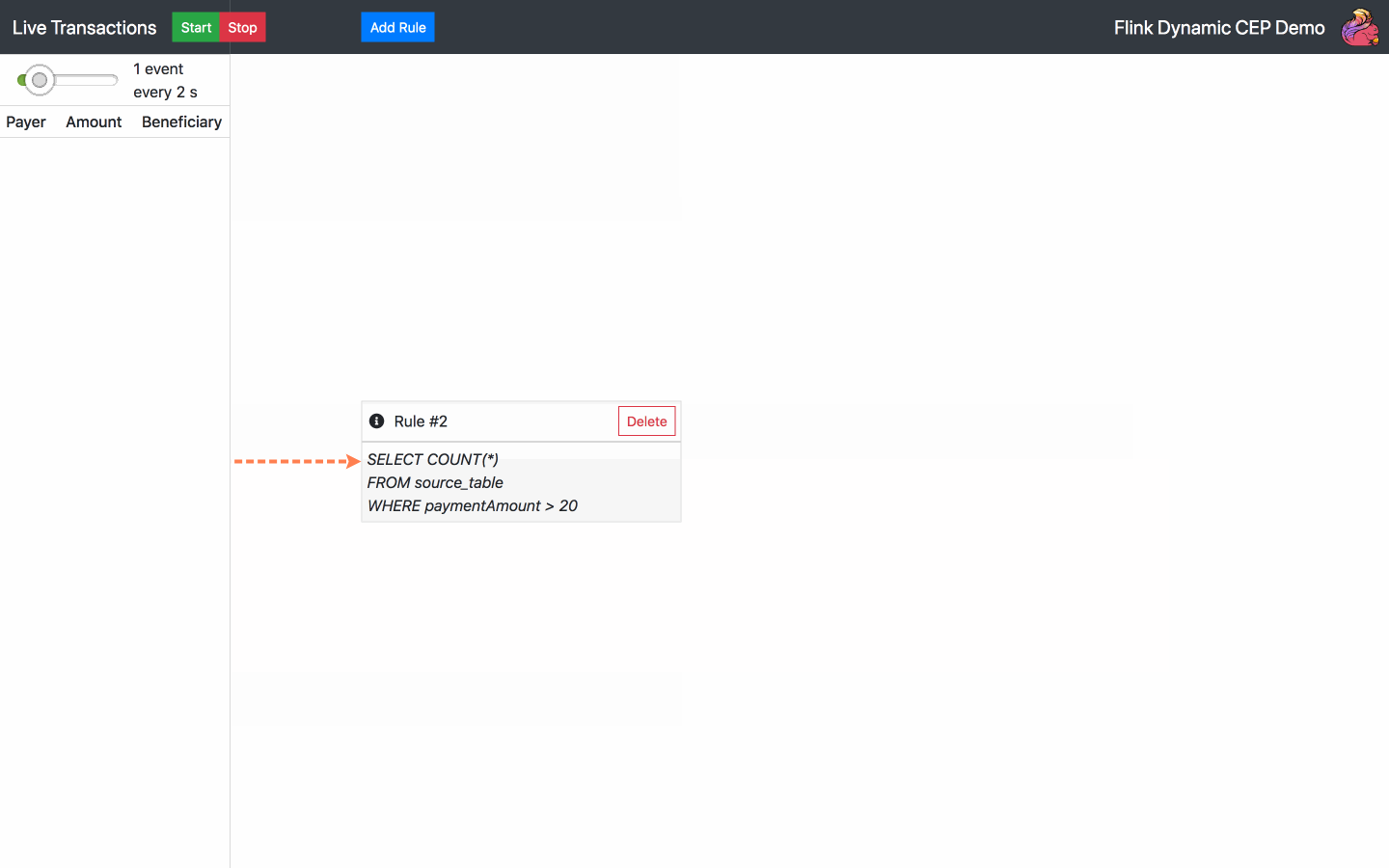
Starten, stoppen oder ändern Sie die Geschwindigkeit eines Transaktionsstroms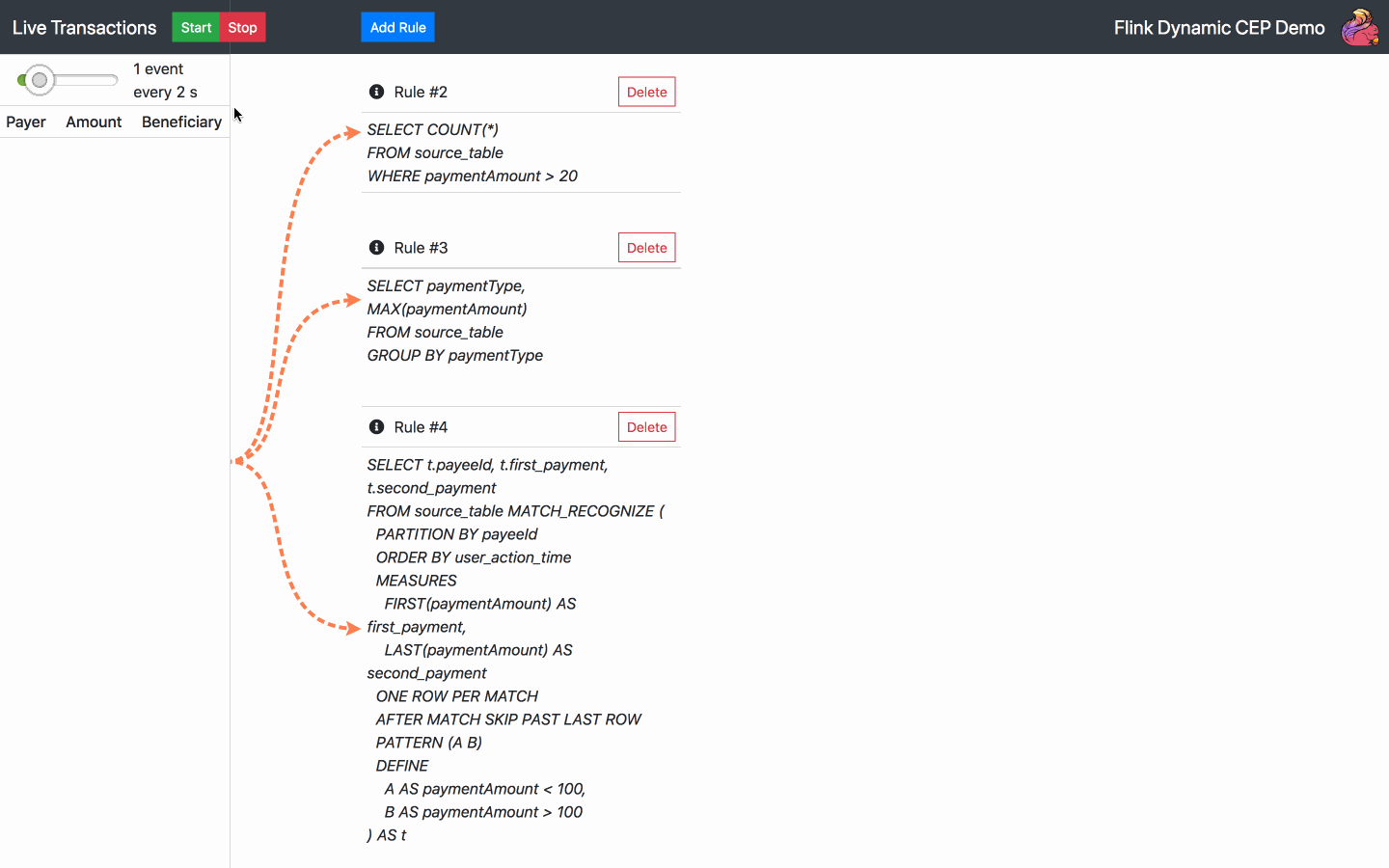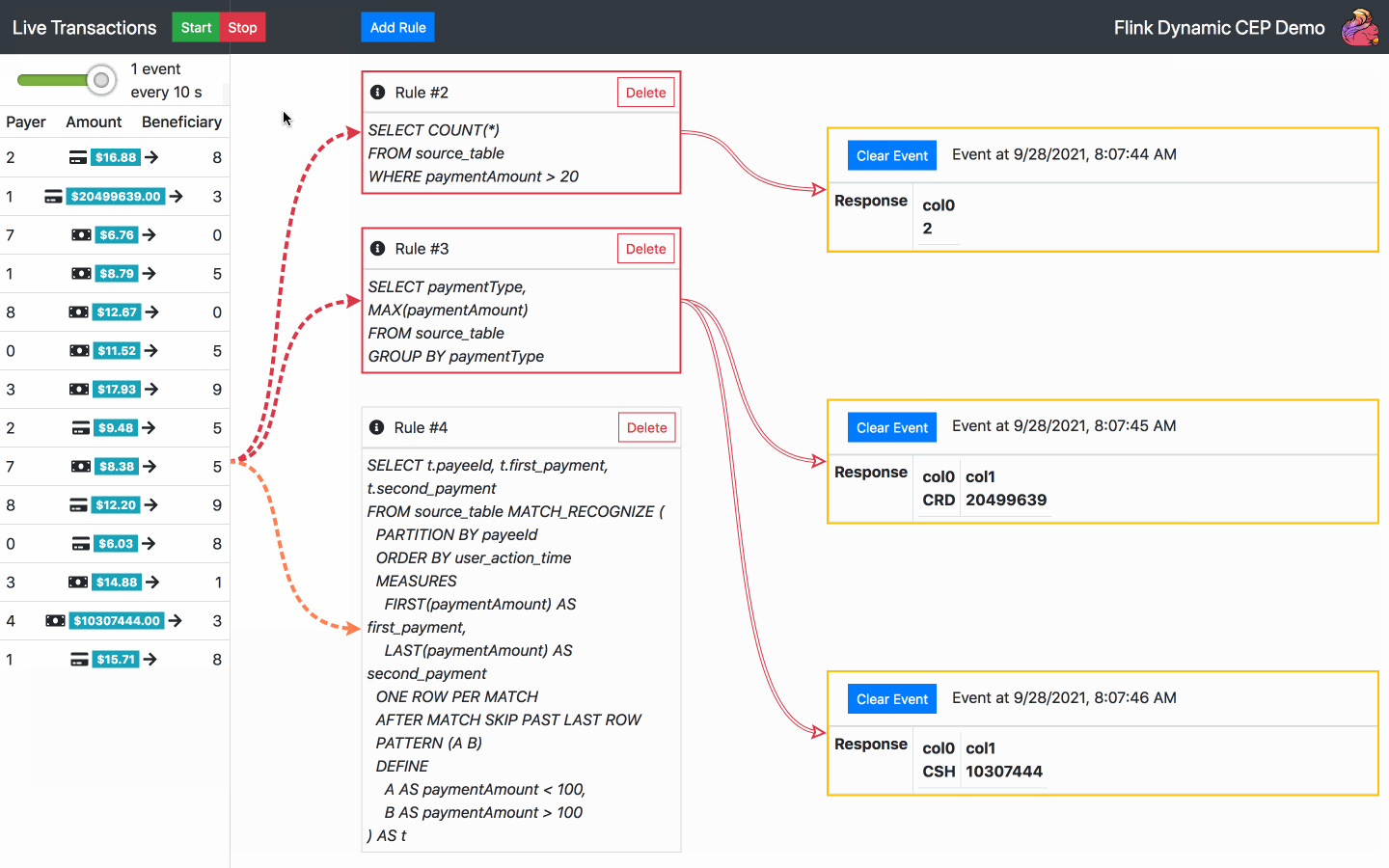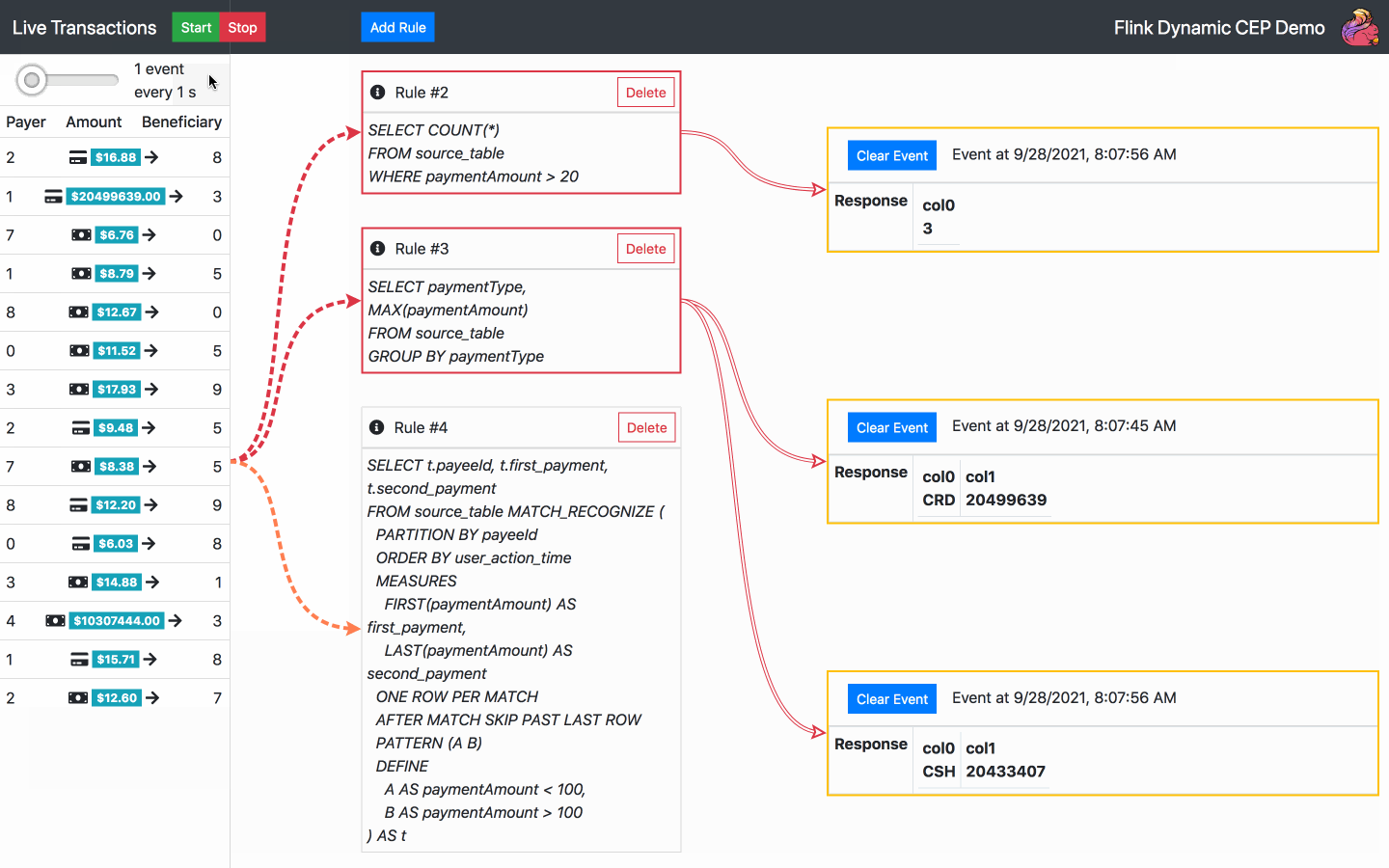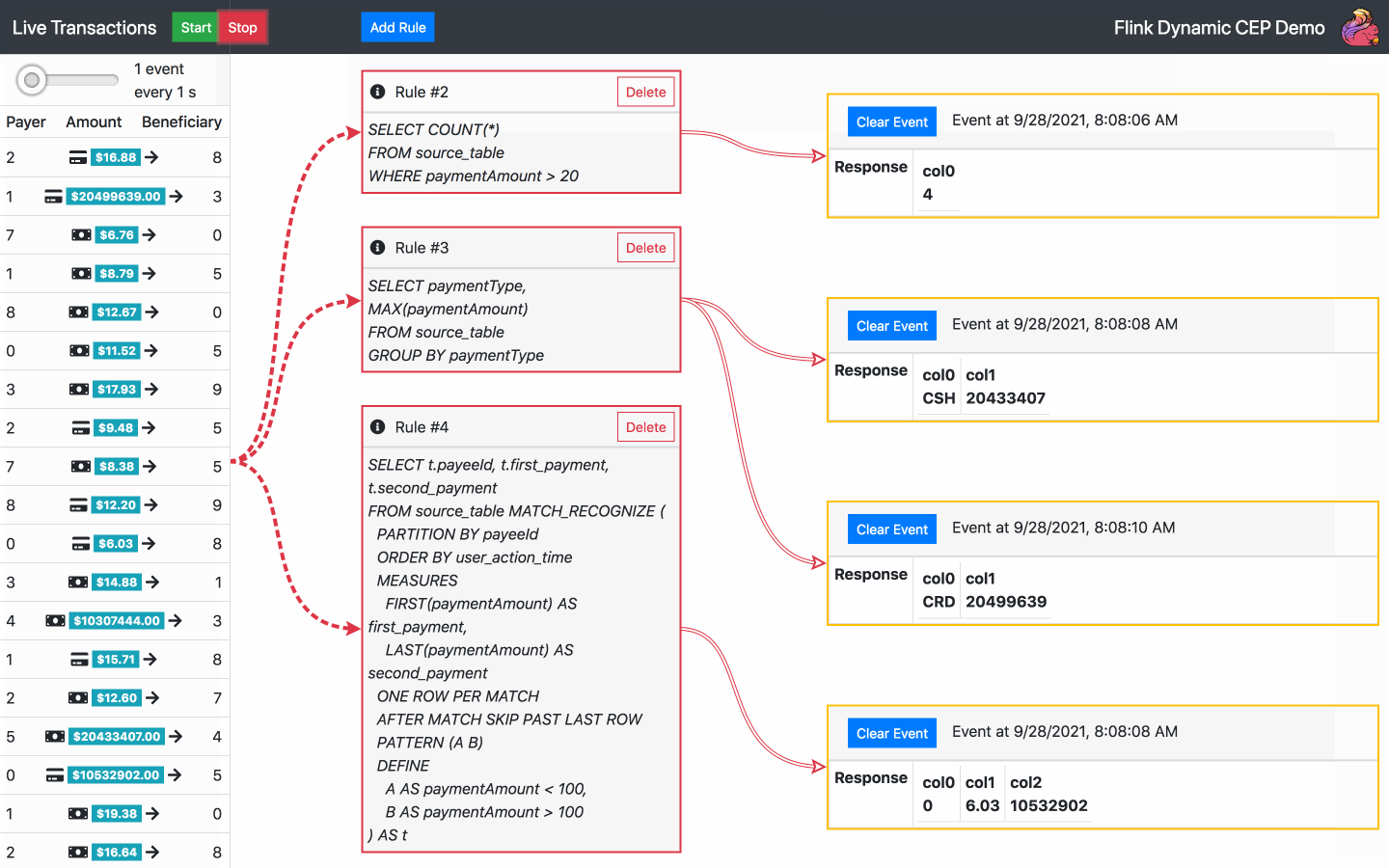
Ereignisbenachrichtigungen löschen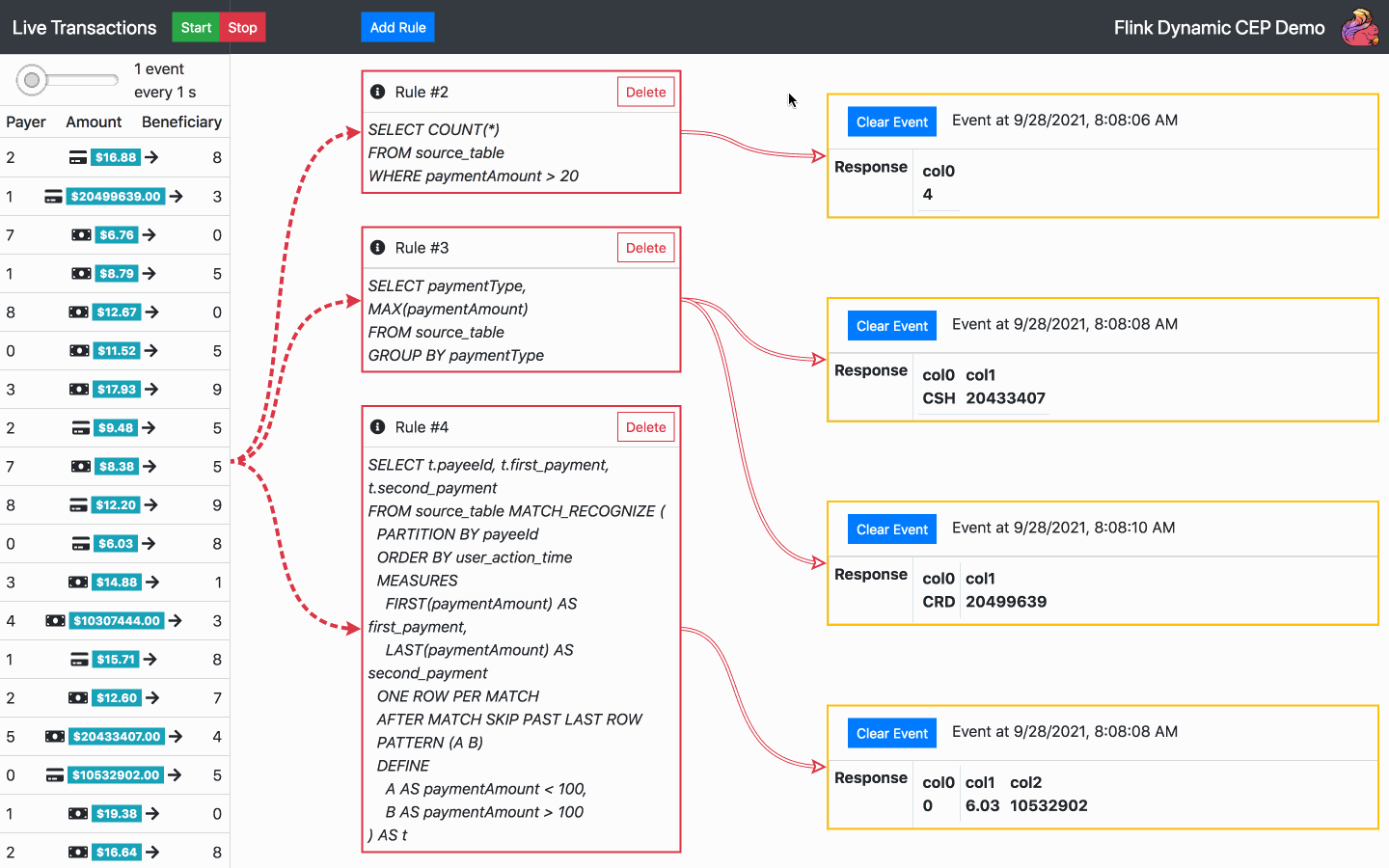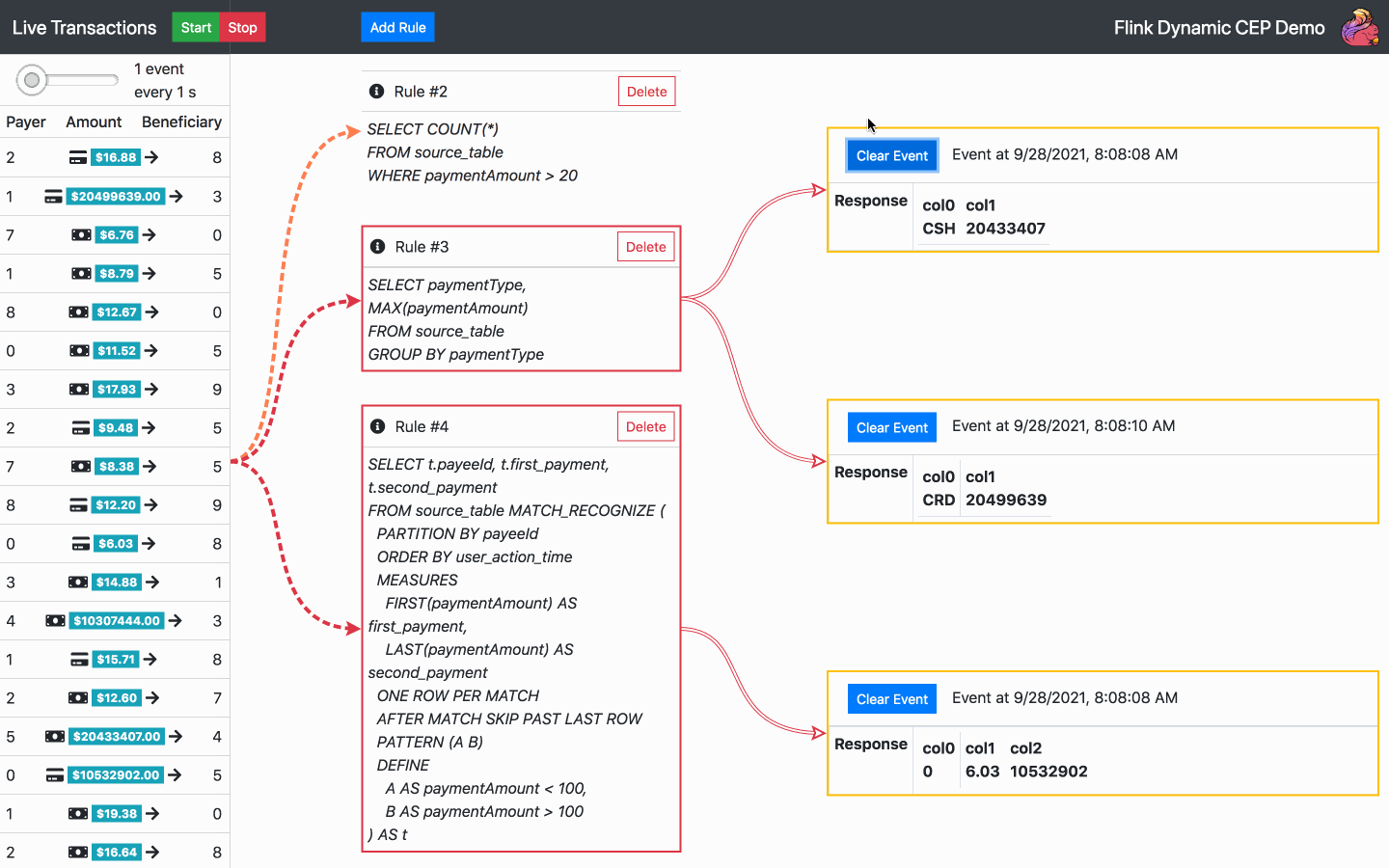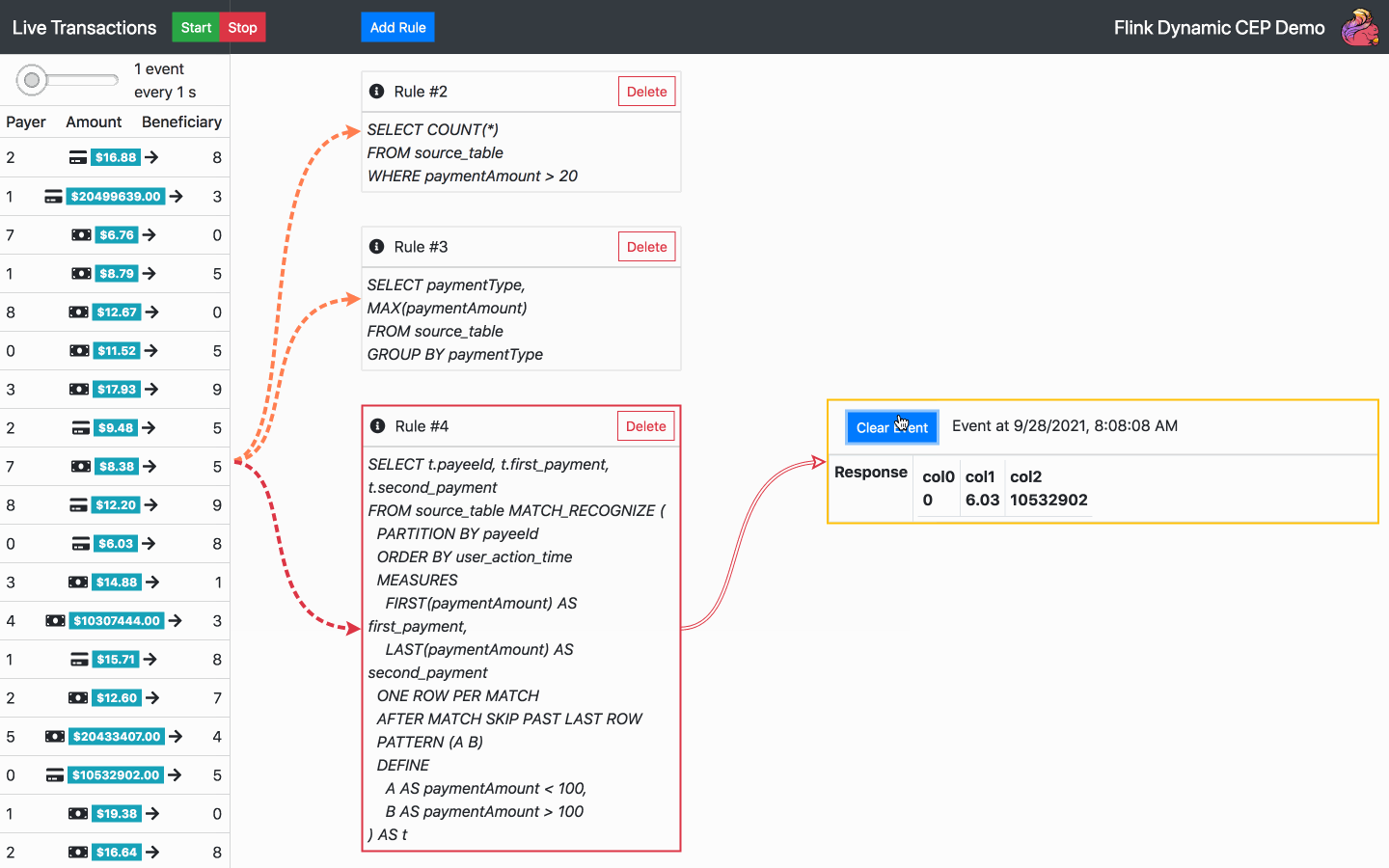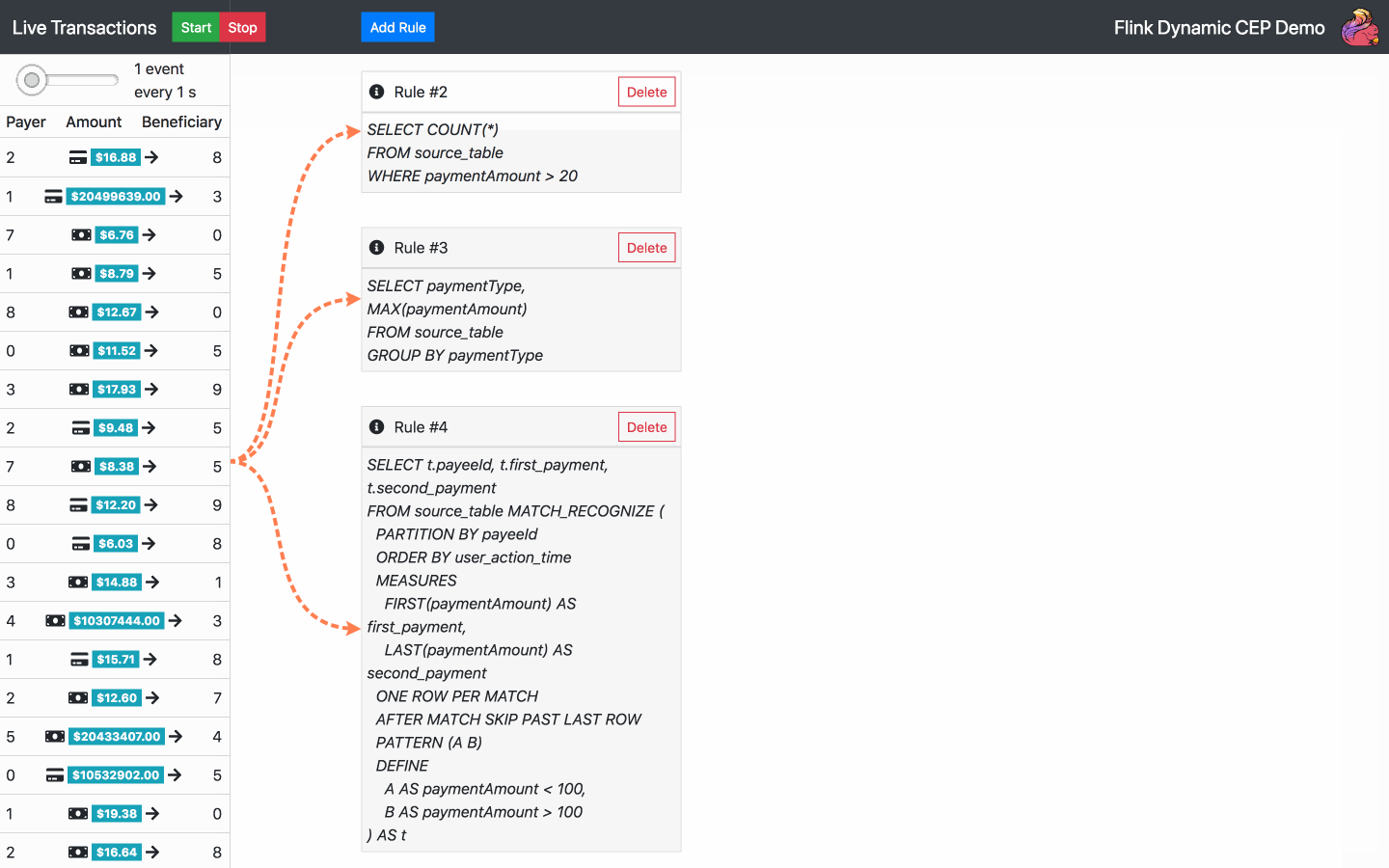
Details zur Implementierung von Dynamic SQL
Nachfolgend sehen Sie das Diagramm der für den Operator gewählten Architektur
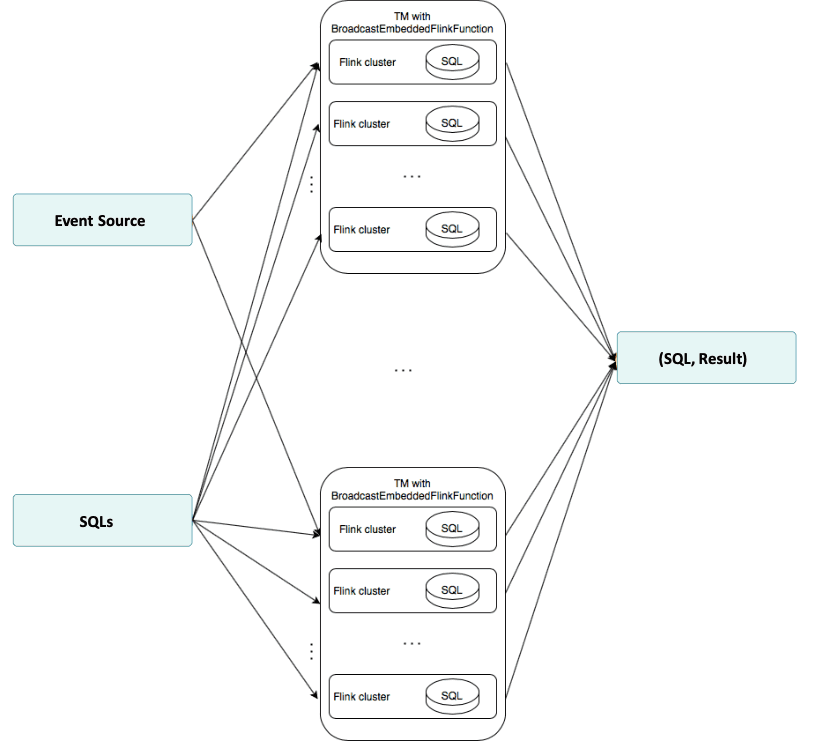
Dieses Verhalten wurde als eine Erweiterung der Funktion KeyedBroadcastProcessFunction
public class BroadcastEmbeddedFlinkFunction<KEY, IN> extends
KeyedBroadcastProcessFunction<KEY, IN, SqlEvent, Tuple4<String, Boolean, Row, Long>> {
...
public BroadcastEmbeddedFlinkFunction(
TypeInformation<IN> inTypeInfo,
List<String> expressions,
Class converterIn,
AssignerWithPeriodicWatermarks<IN> assigner)
...
}Dieser Operator benötigt die folgenden Informationen für den Konstruktor:
inTypeInfo- Typinformationen der Ereignisklasse der Ereignisquelle (IN)expressions- eine Liste vonINAttributenconverterIn- eine Klasse von benutzerdefinierten Konvertern, die die Konvertierung vonINinStringund von kommagetrenntenStringinINassigner- Wasserzeichen-Zuweiser
Das Konzept der "Flinkception" ist erwähnenswert. Dabei handelt es sich um die Ausführung eines Flink-Mini-Clusters (verfügbar in Form von MiniClusterWithClientResource) innerhalb der Broadcast-Funktion. Um die eingehende SQL auszuführen, wird in jeder physischen Partition eine neue MiniClusterWithClientResource für diese SQL erstellt.
public void processBroadcastElement(
SqlEvent value, Context ctx, Collector<Tuple4<String, Boolean, Row, Long>> out)
throws Exception {
...
BroadcastEmbeddedFlinkCluster<IN> cluster =
new BroadcastEmbeddedFlinkCluster<IN>(
value.sqlQuery, inTypeInfo, expressions, converterIn.getClass(), assigner, startTime);
cluster.open(generateSourcePort());
clusters.put(value.sqlQuery, cluster);
...
}
public class BroadcastEmbeddedFlinkCluster<IN> implements Serializable {
...
public void open(int dsSourcePort) throws Exception {
miniClusterResource =
new MiniClusterWithClientResource(
new MiniClusterResourceConfiguration.Builder()
.setConfiguration(getConfig())
.setNumberTaskManagers(NUM_TMS)
.setNumberSlotsPerTaskManager(NUM_SLOTS_PER_TM)
.build());
miniClusterResource.before();
ClusterClient<?> clusterClient = miniClusterResource.getClusterClient();
executor = createDefaultExecutor(clusterClient);
SessionContext sessionContext = new SessionContext("default", new Environment());
sessionId = executor.openSession(sessionContext);
Runtime.getRuntime().addShutdownHook(new EmbeddedShutdownThread(sessionId, executor));
StreamExecutionEnvironment keyEnv =
(StreamExecutionEnvironment)
FieldUtils.readField(executor.getExecutionContext(sessionId), "streamExecEnv", true);
tableEnv =
(StreamTableEnvironment) executor.getExecutionContext(sessionId).getTableEnvironment();
String dsSourceHostName = "localhost";
inputSource =
keyEnv.addSource(
new CustomSocketTextStreamFunction(
dsSourceHostName, dsSourcePort, "\n", 0, customLogger),
"My Socket Stream");
clientSocket = new Socket(dsSourceHostName, dsSourcePort);
customLogger.log("Client socket port" + clientSocket.getLocalPort());
writer = new OutputStreamWriter(clientSocket.getOutputStream());
if (converterIn == null) {
BroadcastEmbeddedFlinkCluster.converterIn = (StringConverter) converterInClass.newInstance();
}
DataStream<IN> inputDS =
inputSource
.map((MapFunction<String, IN>) s -> (IN) converterIn.toValue(s))
.returns(inTypeInfo)
.assignTimestampsAndWatermarks(assigner);
Expression[] defaultExpressions = {$("user_action_time").rowtime()};
Table inputTable =
tableEnv.fromDataStream(
inputDS,
Stream.concat(
expressions.stream().map(Expressions::$), Arrays.stream(defaultExpressions))
.toArray(Expression[]::new));
tableEnv.createTemporaryView("source_table", inputTable);
resultDescriptor = executor.executeQuery(sessionId, sql);
}
...
}Die Kommunikation zwischen dem "äußeren" Flink (wo die Ereignisse erfasst werden) und dem "inneren" (Mini-Cluster, der die Ereignisse verarbeitet) erfolgt über eine benutzerdefinierte Implementierung der SocketTextStreamFunction. Während der Initialisierung des Mini-Clusters wird der Socket erstellt. Anschließend wird jedes eingehende Ereignis im "äußeren" Cluster in String umgewandelt, um in den Socket geschrieben zu werden. Die Ereignisquelle
@Override
public void processElement(
IN value, ReadOnlyContext ctx, Collector<Tuple4<String, Boolean, Row, Long>> out)
throws Exception {
try {
String strValue = converterIn.toString(value);
for (BroadcastEmbeddedFlinkCluster<IN> cluster : clusters.values()) {
cluster.write(strValue);
}
for (BroadcastEmbeddedFlinkCluster<IN> cluster : clusters.values()) {
List<Tuple4<String, Boolean, Row, Long>> output = cluster.retrieveResults();
for (Tuple4<String, Boolean, Row, Long> line : output) {
out.collect(line);
}
}
} catch (Exception e) {
logger.log("processElement exception: " + e.toString());
throw e;
}
}Weitere Arbeiten
An der Leistung und Stabilität der Lösung muss noch weiter gearbeitet werden. Derzeit wird für jede eingehende SQL-Regel in jeder physischen Partition eine MiniClusterWithClientResource erstellt, was einen großen Leistungs-Overhead verursacht. Eine effizientere Lösung wäre es, nur eine MiniClusterWithClientResource pro physischer Partition zu erstellen. Diese Architektur ist im folgenden Diagramm dargestellt. Beim Testen eines solchen Ansatzes traten jedoch Probleme auf. Ein
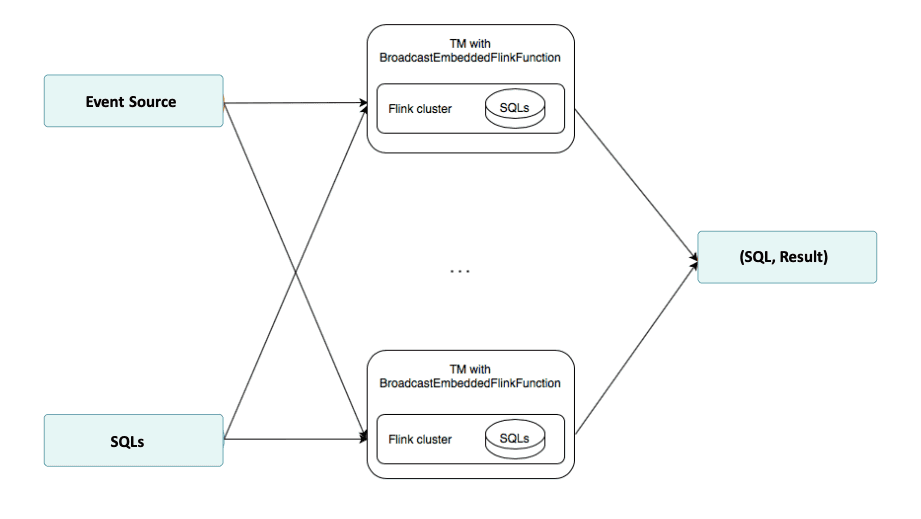
Ein weiteres Problem, an dem weiter gearbeitet werden muss, ist das Phänomen der verlorenen Ereignisse. Beim Testen der komplizierteren SQL-Funktionen, wie z.B. der LocalExecutor hatte.
Eine mögliche Lösung zur Verbesserung sowohl der Leistung als auch der Robustheit dieser Lösung wäre es, eine Kommunikation per Socket in der MiniClusterWithClientResource durch eine Java-Collection-basierte Lösung zu ersetzen. Dies würde eine einfachere Fehlersuche ermöglichen, da der gesamte Ereignispfad viel leichter verfolgt werden könnte, wenn man mit den Sammlungsobjekten im Gegensatz zur Socket-Kommunikation arbeitet. Darüber hinaus würde ein solcher Ansatz die Netzwerklast verringern, was die Zeit und die Ressourcen für die Stream-Verarbeitung reduzieren könnte.
Schließlich müssen die Zustellungsgarantien in Zukunft noch spezifiziert werden. Während die at-most-once-Garantien mit der aktuellen Implementierung, die eine einseitige Kommunikation durchführt, leicht zu erreichen sind (wenn der interne Mini-Cluster beendet wird, erscheinen die Nachrichten nicht mehr), können die exact-once- und at-least-once-Garantien nur durch eine echte Zwei-Wege-Kommunikation mit ACK-Messaging erreicht werden.
Schlussfolgerungen
Die konstruierte Demo zeigt eine interessante Möglichkeit, das wiederkehrende Problem der dynamischen SQL-Ausführung in Flink zu bekämpfen. Diese Demo ist ein Proof-of-Concept und die vorgeschlagene Lösung wurde noch nicht in der Produktion getestet. Es sind noch einige Probleme zu lösen, aber sollte dies gelingen, wird Flink in der Lage sein, hochvolumige Business Intelligence in Echtzeit in vollem Umfang durchzuführen.
Abschließend möchte ich mich bei Krzysztof Zarzycki und dem gesamten GetInData-Team für ihre unschätzbare Unterstützung bedanken - ohne ihre Hilfe wäre dies alles nicht möglich gewesen :)
Und zu guter Letzt: Wenn Sie dieses Proof-of-Concept testen oder mehr darüber erfahren möchten, zögern Sie nicht, uns zu kontaktieren!
—
Hat Ihnen dieser Blogbeitrag gefallen? Schauen Sie sich unsere anderen Blogs an und melden Sie sich für unseren Newsletter an, um auf dem Laufenden zu bleiben!
Verfasst von
Kosma Grochowski
Unsere Ideen
Weitere Blogs




Contact