
AWS SageMaker bietet eine Plattform zum Entwickeln, Trainieren und Bereitstellen von Modellen für maschinelles Lernen. In einem Satz: Das Training funktioniert, indem Sie ein Docker-Image mit einer train ausführbaren Datei bereitstellen, die AWS SageMaker ausführt, um Ihren Trainingsauftrag auszuführen. Die Eingabe- und Ausgabedaten sollten in einem bestimmten Verzeichnis bereitgestellt werden, damit die Arbeit korrekt ausgerichtet werden kann. Sie legen den zugrundeliegenden Instanztyp fest und AWS fährt die Ressourcen hoch, führt den Auftrag aus, schreibt die Ausgabe und fährt sie wieder herunter.
Kürzlich stand ich vor der Herausforderung eines großen Trainingsauftrags, bei dem eine einzige Instanz die Aufgabe nicht mehr erfüllen konnte, sowohl was die Verarbeitungsleistung als auch die (erwartete) Zeit bis zur Fertigstellung anging. Eine schnelle Google-Suche führte mich zu zwei Ressourcen:
- Ein Blog mit dem Namen"Verteiltes Training mit Amazon SageMaker", das auf eine Reihe von Notebooks verweist.
- Eine Seite namens"Parallelisierte Datenverteilung", eine Seite, die zwei Strategien für die Datenverteilung unter Verwendung mehrerer SageMaker-Instanzen demonstriert.
Zwar verwenden beide Ressourcen vorgefertigte AWS-Modelle (und die 2. Ressource erwähnt sogar, dass das Training auf mehreren Rechnern ein "nicht trivialer Prozess" ist), aber beide gehen nicht ins Detail, wie man mit SageMaker wirklich verteilte Verarbeitung durchführt. Ich hatte jedoch genug Grund zu der Annahme, dass es möglich sein würde, einen DIY-Trainingsauftrag auf verteilte Weise auszuführen. Im Nachhinein betrachtet war der Prozess in der Tat nicht trivial und führte mich in ein Kaninchenloch, daher der Grund für diesen Blogbeitrag.
Zusammenfassung der Schulung eines DIY AWS SageMaker-Modells
Bevor wir uns der verteilten Schulung zuwenden, lassen Sie uns kurz rekapitulieren, wie die DIY-Schulung mit AWS SageMaker funktioniert (lesen Sie dazu auch meinen früheren Blogbeitrag über DIY-SageMaker-Modelle). Mit "DIY" meine ich, dass Sie Ihr eigenes Docker-Image für die Schulung bereitstellen.
SageMaker benötigt eine ausführbare Datei im Docker-Image mit dem Namen train, die es zum Training aufruft. Innerhalb dieses Trainingsauftrags können Sie jeden beliebigen Code ausführen, den Sie möchten. Um dem Job Daten zur Verfügung zu stellen, konfigurieren Sie die InputDataConfig Schlüssel in der Auftragskonfiguration, der eine Liste von sogenannten"Channels" enthält, wobei jeder Channel in den Trainingscontainer auf /opt/ml/input/data/[channel name] eingebunden ist. Nehmen wir an, Sie möchten Eingabedaten bereitstellen, die auf S3 gespeichert sind:
{
"TrainingJobName": "my-training-job",
...
"InputDataConfig": [
{
"ChannelName": "my-input-data",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://my-bucket/training-data/"
}
}
}
]
}Die obige Konfiguration teilt SageMaker mit, dass alle S3-Objekte mit dem Präfix s3://my-bucket/training-data/ in den Trainingscontainer eingebunden werden sollen. Die Eigenschaft ChannelName wird auf "my-input-data" gesetzt, so dass die Daten innerhalb des Containers auf /opt/ml/input/data/my-input-data zugänglich sind. Alle verfügbaren Einstellungen herauszufinden, kann mühsam sein und erfordert oft ein sorgfältiges Lesen der Dokumentation.
Genau wie die Eingabedaten werden auch die Ausgabedaten in /opt/ml erwartet, in /opt/ml/model/.... Nach Abschluss des Trainings wird alles, was sich in diesem Verzeichnis befindet, mit der folgenden Konfiguration automatisch wieder in S3 gespeichert:
"OutputDataConfig": {
"S3OutputPath": "s3://my-sagemaker-output/output-path"
}Visuell ist dies der Prozess, den SageMaker erleichtert:

Verteilte SageMaker-Schulung
Im obigen Beispiel wird ein einziges Docker-Image ausgeführt. Wie können wir also mehrere ausführen? Dies könnte wünschenswert sein, wenn Ihr Trainingsauftrag leicht in mehrere kleinere Aufträge aufgeteilt werden kann und Sie viel Rechenleistung benötigen.
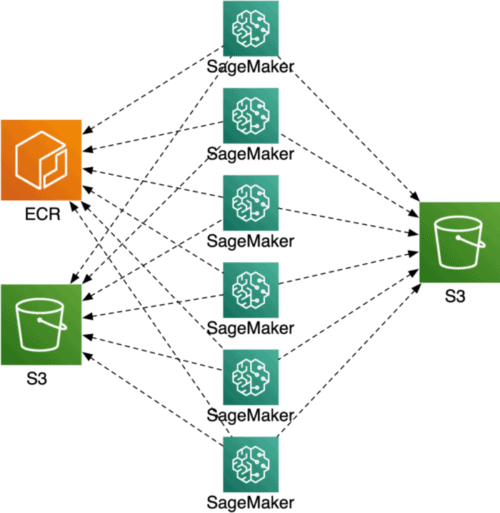 Wie kann ich die Arbeit auf mehrere SageMaker-Trainingsinstanzen verteilen?
Wie kann ich die Arbeit auf mehrere SageMaker-Trainingsinstanzen verteilen?
Mehrere Instanzen konfigurieren
Werfen Sie zunächst einen Blick auf den Abschnitt ResourceConfig in der SageMaker-Konfiguration. Zum Beispiel:
"ResourceConfig": {
"InstanceType": "ml.c5.4xlarge",
"InstanceCount": 10,
"VolumeSizeInGB": 5,
},Alle drei Konfigurationsschlüssel (InstanceType, InstanceCount und VolumeSizeInGB) sind erforderlich. Setzen Sie InstanceCount einfach auf einen Wert größer als 1, um mehrere Instanzen zu erstellen.
Konfigurieren der Eingabedaten für mehrere Instanzen
In der Konfiguration Ihrer Eingabedatenquellen müssen Sie entscheiden, wie die Eingabedaten auf die Trainingsinstanzen verteilt werden sollen, mit einem Schlüssel namens "S3DataDistributionType":
{
"TrainingJobName": "my-training-job",
...
"InputDataConfig": [
{
"ChannelName": "my-input-data",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://my-bucket/training-data/",
"S3DataDistributionType": "FullyReplicated"
}
}
}
]
}Der Wert von S3DataDistributionType kann entweder "FullyReplicated" oder "ShardedByS3Key" sein, wobei FullyReplicated eine Kopie des angegebenen Datensatzes in jeder Instanz zur Verfügung stellt und ShardedByS3Key [# der Dateien]/[# der Instanzen] Teile der Daten in jede Instanz kopiert. Wenn Ihre Eingabedaten also 20 Dateien enthalten und Sie 6 Instanzen haben, erhält jede Instanz 20/6=3,33 Dateien, wobei einige Instanzen je nach Schlüssel der Datei 3 Dateien und andere 4 Dateien erhalten.
Jede einzelne Instanz führt den Trainingsauftrag mit den in der Instanz bereitgestellten Daten aus und schreibt die Ausgabe auf /opt/ml/model. Nach Abschluss aller Trainingsaufträge werden die Daten dann von Amazon gesammelt und in einer einzigen Datei namens model.tar.gz gespeichert. Wenn S3OutputPath auf "s3://my-sagemaker-output/output-path" eingestellt ist, lautet der vollständige Ausgabepfad:
s3://my-sagemaker-output/output-path/[sagemaker job id]/output/model.tar.gzDabei enthält model.tar.gz alle Ausgabedateien, die in jeder einzelnen Trainingsinstanz gespeichert sind. Wenn Sie also eine einzige Datei benötigen, müssen Sie einen zusätzlichen Nachbearbeitungsschritt durchführen, in dem Sie alle Ausgabedateien aus model.tar.gz extrahieren und in einer einzigen Ergebnisdatei zusammenfassen.
Wie kann man feststellen, welche Instanz was tut?
Wenn Ihr Trainingsauftrag so beschaffen ist, dass er auf einzelnen Datenpaketen trainieren kann, werden Sie mit der Aufteilung Ihrer Eingabedaten in Teile und deren automatischer Verteilung mit S3DataDistributionType auf ShardedByS3Key kein Problem haben.
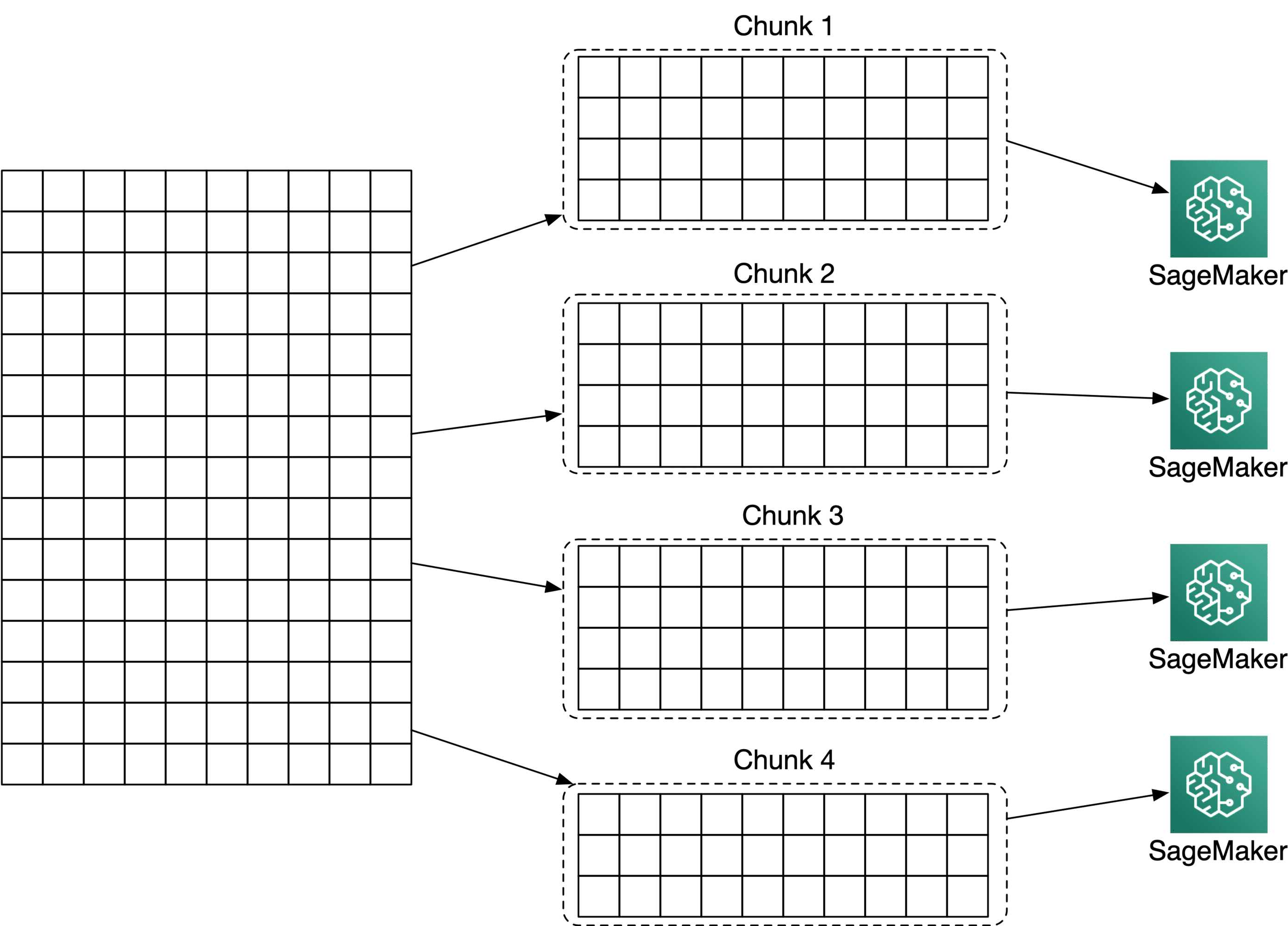 Wenn Ihr Eingabedatensatz in separaten Blöcken "verarbeitbar" ist, können Sie dies in einem Vorverarbeitungsschritt tun und diese an SageMaker-Instanzen mit "S3DataDistributionType" verteilen: "ShardedByS3Key".
Wenn Ihr Eingabedatensatz in separaten Blöcken "verarbeitbar" ist, können Sie dies in einem Vorverarbeitungsschritt tun und diese an SageMaker-Instanzen mit "S3DataDistributionType" verteilen: "ShardedByS3Key".
Nehmen wir jedoch an, Ihre Trainingsaufgabe umfasst eine große Matrix wie oben, über die Sie die Kosinusähnlichkeit zwischen allen Zeilen berechnen möchten. Eine solche Berechnung kann zwar in Teile aufgeteilt werden, indem jede Instanz nur eine Teilmenge der Zeilen abdeckt, aber jede Instanz benötigt dennoch Zugriff auf den gesamten Datensatz. Sie können jeder Instanz die vollständige Matrix zur Verfügung stellen, indem Sie "S3DataDistributionType": "FullyReplicated" einstellen und innerhalb jeder Instanz festlegen, wer was tun soll. Um zu bestimmen, welche Instanz welchen Teil der Matrix verarbeiten soll, sehen wir uns die verfügbaren Informationen innerhalb einer SageMaker-Trainingsinstanz genauer an.
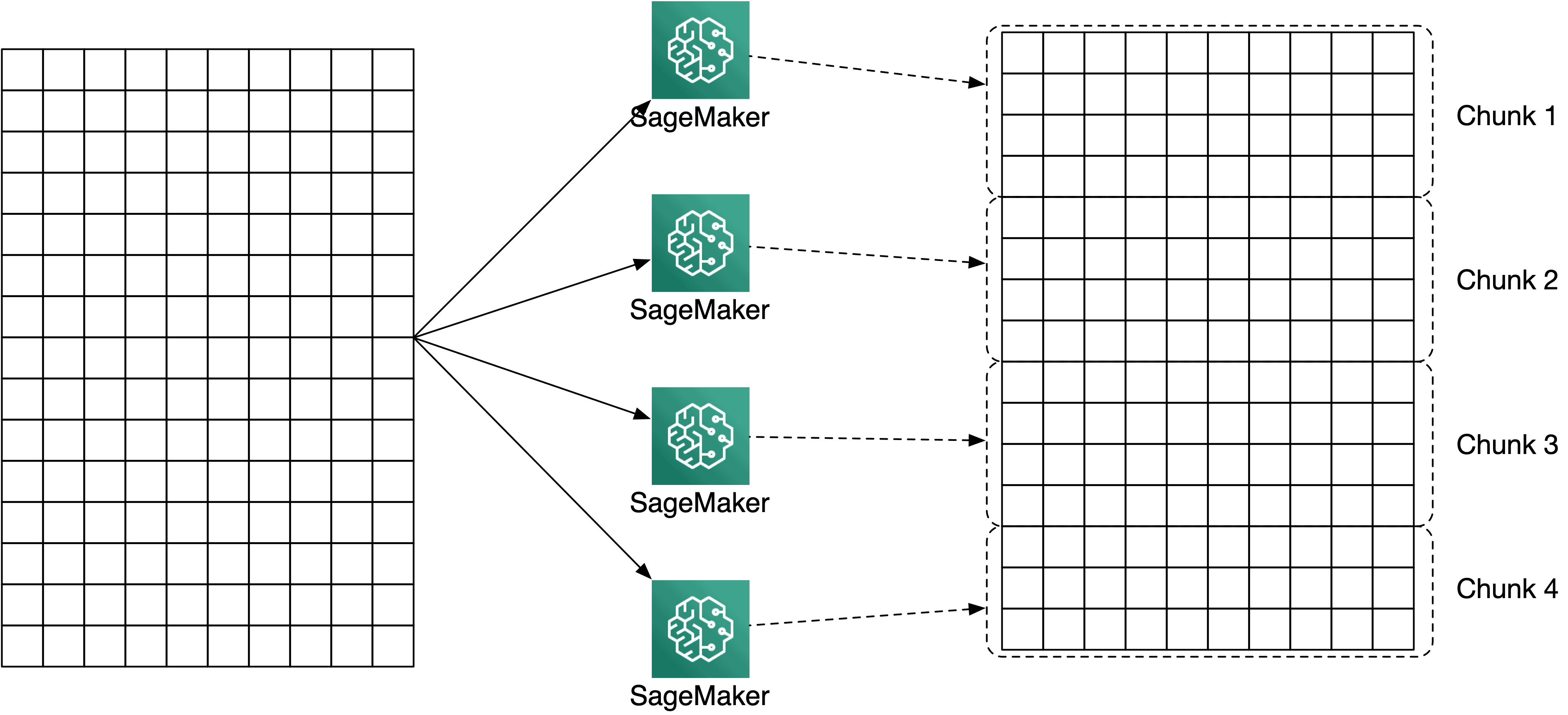 Wenn jede Trainingsinstanz den gesamten Datensatz zur Verarbeitung benötigt, können Sie den Datensatz an jede Instanz mit "S3DataDistributionType" senden: "FullyReplicated" senden und innerhalb der Instanz festlegen, welchen Teil des Eingabedatensatzes die jeweilige Instanz abdeckt.
Wenn jede Trainingsinstanz den gesamten Datensatz zur Verarbeitung benötigt, können Sie den Datensatz an jede Instanz mit "S3DataDistributionType" senden: "FullyReplicated" senden und innerhalb der Instanz festlegen, welchen Teil des Eingabedatensatzes die jeweilige Instanz abdeckt.
SageMaker-Konfiguration pro Instanz
Jede SageMaker-Trainingsinstanz enthält eine Reihe von Umgebungsvariablen und Dateien, die wir für unsere Zwecke verwenden können. Wenn Sie alle Umgebungsvariablen innerhalb einer Trainingsinstanz ausdrucken, erhalten wir die folgenden Informationen:
{
"PATH": "/opt/conda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"HOSTNAME": "ip-10-4-9-44.eu-west-1.compute.internal",
"ECS_CONTAINER_METADATA_URI": "http://169.254.170.2/v3/6214c0a1-6ca6-4249-9553-d999154dd547",
"AWS_EXECUTION_ENV": "AWS_ECS_EC2",
"AWS_REGION": "eu-west-1",
"DMLC_INTERFACE": "eth0",
"NVIDIA_VISIBLE_DEVICES": "void",
"TRAINING_JOB_ARN": "[my training job ARN]",
"TRAINING_JOB_NAME": "[my training job name]",
"AWS_CONTAINER_CREDENTIALS_RELATIVE_URI": "/v2/credentials/5bd0f5f7-304a-415f-9523-4493ec3f1360",
"LANG": "C.UTF-8",
"LC_ALL": "C.UTF-8",
"HOME": "/root",
"KMP_DUPLICATE_LIB_OK": "True",
"KMP_INIT_AT_FORK": "FALSE",
}Unter /opt/ml finden Sie außerdem eine Reihe nützlicher Dateien:
.
└── opt
└── ml
├── input
│ ├── config
│ │ ├── hyperparameters.json
│ │ ├── init-config.json
│ │ ├── inputdataconfig.json
│ │ ├── metric-definition-regex.json
│ │ ├── resourceconfig.json
│ │ ├── trainingjobconfig.json
│ │ └── upstreamoutputdataconfig.json
│ └── data
│ ├── my-input-data/
│ └── my-input-data-manifest
├── model/
└── output
├── data/
└── metrics
└── sagemaker/Die json-Dateien in /config enthalten Konfigurationen, die entweder automatisch von Amazon bereitgestellt oder von Ihnen selbst in der Konfiguration des Trainingsauftrags konfiguriert werden. Um ein Beispiel für den Inhalt dieser Dateien zu geben, sehen Sie hier den Inhalt eines meiner Trainingsaufträge. Die Inhalte hängen jedoch natürlich davon ab, was Sie in Ihren Trainingsaufträgen konfiguriert haben:
hyperparameters.json
Enthält: Hyperparameter-Konfiguration
Beispiel: {}
trainingjobconfig.json
Enthält: Die an SageMaker übermittelte Trainingsjob-Konfiguration
Beispiel: {"TrainingJobName": "...", ...}
inputdataconfig.json
Enthält: Die Konfiguration der Eingabedaten, die in der Konfiguration des Trainingsauftrags angegeben ist
Beispiel: {'my-data': {'TrainingInputMode': 'File', 'S3DistributionType': 'ShardedByS3Key', 'RecordWrapperType': 'None'}, ...}
upstreamoutputdataconfig.json
Enthält: Unbekannt
Beispiel: []
metric-definition-regex.json
Enthält: Metrik-Definitionen
Beispiel: []
resourceconfig.json
Enthält: Informationen über alle Instanzen
Beispiel: {'current_host': 'algo-8', 'hosts': ['algo-1', 'algo-2', 'algo-3', 'algo-4', 'algo-5', 'algo-6', 'algo-7', 'algo-8', 'algo-9', 'algo-10'], 'network_interface_name': 'eth0'}
init-config.json Enthält: Verschiedene Informationen zur Auftragskonfiguration Beispiel:
{
"inputMode": "FILE",
"channels": {
"my-input-data": {
"s3DataSource": {
"s3DataType": "S3_PREFIX",
"s3Uri": "s3://my-bucket/training-data/",
"s3DataDistributionType": "FULLY_REPLICATED",
"attributeNames": None,
},
"fileSystemDataSource": None,
"compressionType": "NONE",
"recordWrapper": "NONE",
"shuffleConfig": None,
"inputMode": "FILE",
"sharded": False,
},
},
"checkpointChannel": None,
"hostConfig": {"clusterSize": 10, "hostNumber": 8},
"enableDataAgentDownloads": False,
"jobRunInfo": None,
}Die resourceconfig.json (auch init-config.json) enthält genau die benötigten Informationen:
{'current_host': 'algo-8', 'hosts': ['algo-1', 'algo-2', 'algo-3', 'algo-4', 'algo-5', 'algo-6', 'algo-7', 'algo-8', 'algo-9', 'algo-10']}
input_dataset = pd.read...
with open("/opt/ml/input/config/resourceconfig.json") as f:
resourceconfig = json.load(f)
n_hosts = len(resourceconfig["hosts"])
current_host = resourceconfig["current_host"]
current_host_idx = resourceconfig["hosts"].index(current_host)
total_rows = input_dataset.shape[0]
start_row = round(current_host_idx * total_rows / n_hosts)
end_row = round((current_host_idx + 1) * total_rows / n_hosts)Wann funktioniert das?
Das oben beschriebene verteilte Training ist geeignet, wenn Ihr Eingabedatensatz nicht zu groß ist, aber viel Rechenleistung erfordert. Der Eingabedatensatz wird in jede Instanz kopiert, was eine gewisse Netzwerknutzung und Speicherplatz für jede Instanz erfordert, so dass Sie idealerweise die Größe des Eingabedatensatzes minimieren sollten.
Zweitens findet keine Kommunikation zwischen den Containern statt, so dass dies nur dann anwendbar ist, wenn Ihre Aufgabe dies nicht erfordert, z.B. wenn kein Mischen erforderlich ist und es in Ordnung ist, die Endergebnisse anschließend wieder zusammenzuführen.
Gedanken
In meinem Fall musste ich eine sehr große Kosinusähnlichkeitsberechnung über alle Zeilen einer sehr großen Matrix durchführen. Aus verschiedenen Gründen entschieden wir uns gegen EMR und Spark, also begann ich, die verteilte Verarbeitung mit SageMaker zu untersuchen. Ich war angenehm überrascht von der Leistung des Systems, sobald ich alle Teile zum Laufen gebracht hatte. Ich begann mit mehreren ml.c5.2xlarge-Instanzen und erwartete eine ähnliche Leistung pro Chunk wie auf meinem Macbook, aber jeder Chunk wird in erheblich kürzerer Zeit abgeschlossen als ein Chunk auf meinem Laptop. Mit dem obigen Python-Skript zur Bestimmung der zu berechnenden Teilmenge von Zeilen ist die einzige Variable die Anzahl der Instanzen in der Konfiguration des Trainingsauftrags, und die Teilmenge von Zeilen wird automatisch auf der Grundlage dieser Anzahl berechnet.
Eine Sache, die Sie beachten sollten, ist, dass Spot-Instanzen eine Option sein könnten, um den Preis niedrig zu halten. Kontrollpunkte sind in SageMaker-Jobs konfigurierbar, aber ich habe das zu diesem Zeitpunkt nicht untersucht.
Unsere Ideen
Weitere Blogs




Contact