Blog
Haben Sie die Dokumentation aktualisiert?

Niemand schreibt gerne Dokumentation. Es ist eine langweilige und mühsame Aufgabe. Und das Schlimmste ist, dass sie in dem Moment, in dem Sie sie schreiben, schon wieder veraltet ist. Und doch ist sie einer der wichtigsten Bestandteile der Software, die wir erstellen. Egal, wie oft Entwickler sagen: "Der Code ist selbsterklärend", das ist er nicht. Die Dokumentation hilft neuen Mitarbeitern, sich schneller einzuarbeiten, und - was noch wichtiger ist - sie kann die Zusammenarbeit zwischen Teams verbessern. Dokumentation ist der Schlüssel, wenn Sie Anwendungen erstellen, die APIs offenlegen.
Im Falle von APIs werden die meisten Entwickler zunächst nach einer OpenAPI-Spezifikation als Dokumentation ihrer Wahl fragen. Wenn Sie mit OpenAPI nicht vertraut sind, handelt es sich um eine Standardmethode zur Beschreibung Ihrer API. Diese Datei enthält alle Informationen über Ihre API, wie die Endpunkte, die Anfrage- und Antwortkörper und die Authentifizierungsmethoden. Sie wird oft über eine Swagger-Benutzeroberfläche angezeigt, die eine benutzerfreundliche Möglichkeit bietet, die API über Ihren Browser zu erkunden. Diese Dateien werden automatisch aus Ihrer Codebasis generiert, so dass es kein Problem ist, sie zu erstellen und weiterzugeben. Allerdings versteht nicht jeder diese Spezifikationen oder hat die Tools, um sie zu interpretieren. Manche Leute, ja, sogar Entwickler, lesen lieber eine von Menschen lesbare Dokumentation.
Das stellt uns vor ein Problem. Das typische Klischee eines Entwicklers besagt, dass wir die folgenden drei Dinge nicht mögen:
- Dokumentation schreiben
- Schreiben von Unit-Tests
- Reguläre Ausdrücke schreiben
Es überrascht nicht, dass die neueste Welle von LLMs im Jahr 2022 damit begann, Werkzeuge zu entwickeln, die die beiden letztgenannten Probleme lösen. Vor allem Github Copilot hat für viele Entwickler die Welt verändert. Sie können es zwar verwenden, um Dokumentation aus Ihrem Code zu extrahieren, aber es hat ein großes Problem: Es ist ein Kopilot, kein Kapitän. Es kann Ihnen beim Schreiben der Dokumentation helfen, aber Sie müssen es dazu anweisen. Wenn Sie nicht daran denken, Dokumentation zu schreiben, warum sollten Sie dann Copilot bitten, sie für Sie zu schreiben? Wie es sich für einen Entwickler gehört, ist der beste Weg, etwas Langweiliges nicht mehr tun zu müssen, ein Tool dafür zu schreiben.
Kontinuierliche Integration/kontinuierliche Dokumentation
Wir bauen derzeit eine Integrationsplattform für unseren Kunden auf. Die Plattform bietet Entwicklern eine schnelle Möglichkeit, ihre Integrationen auf den Weg zu bringen, unabhängig von der Programmiersprache, die sie verwenden möchten. Bei vielen dieser Integrationen handelt es sich um APIs, die alle dokumentiert werden müssen. Im Rahmen unseres Platform Engineering verbringen wir viel Zeit und Aufmerksamkeit mit der Perfektionierung unserer Integrations- und Bereitstellungspipelines. Neben all den großen Aufgaben wie dem Erstellen, Testen und Bereitstellen verwenden wir diese Pipelines, um uns die Arbeit zu erleichtern. Also haben wir beschlossen, die Maschinen mit der Aufgabe zu betrauen, die wir sicher vergessen würden. Wir können für alle APIs, die auf unserer Plattform landen, automatisch eine von Menschen lesbare Dokumentation aus der OpenAPI-Spezifikation erstellen.
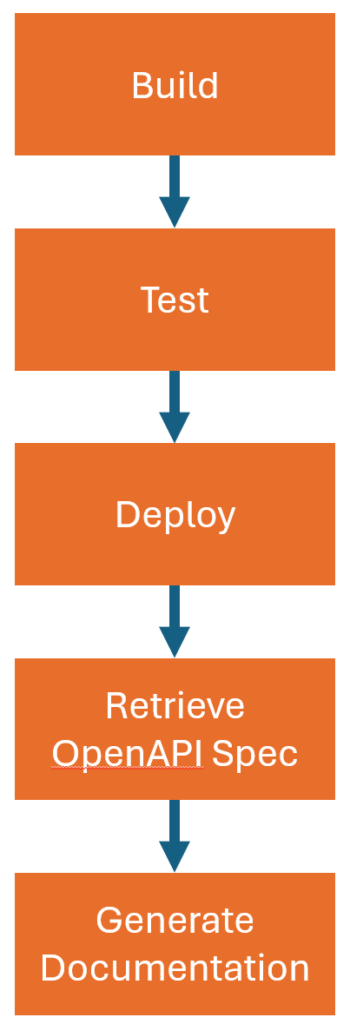
Nachdem wir unsere Software erstellt, getestet und bereitgestellt haben, müssen wir die OpenAPI-Spezifikation erwerben und sie einem Large Language Model (LLM) anbieten. Die Software, die wir zu diesem Zweck geschrieben haben, könnte auf verschiedene Weise implementiert werden, von der Erstellung eines benutzerdefinierten Pipelineschritts bis hin zur Verwendung eines einfachen Skripts in unserer Pipeline. Wie auch immer die Lösung aussieht, wir benötigen Zugangsdaten für das LLM sowie Zugangsdaten, um die Dokumentation an Confluence zu übermitteln. Zwar könnten wir diese Zugangsdaten in allen unseren Pipelines sicher erhalten, doch müssten sie für alle Pipelines, die wir für diese verschiedenen APIs ausführen, zugänglich sein. Stattdessen haben wir beschlossen, einen separaten Dienst in unserer Integrationsplattform zu erstellen, den alle Pipelines aufrufen können. Dieser Dienst generiert die Dokumentation und überträgt sie an Confluence. Alle unsere API-Pipelines laufen mit einem eigenen Dienstprinzipal, dem Zugriff auf diesen Dienst gewährt werden kann. Auf diese Weise können wir die Anmeldeinformationen für LLM und Confluence an einem Ort aufbewahren und müssen sie nur an einem Ort verwalten.
Der Dienst
Dieser zentrale Dienst ist eine API, die auf ASP.NET Core aufbaut und zwei verschiedene Technologien nutzt: Semantic Kernel und Prompty. Sie können zwar dasselbe mit der Azure OpenAI REST API erreichen, aber diese Tools machen Ihnen das Leben leichter. Semantic Kernel abstrahiert von spezifischen LLM-Implementierungen und ist hilfreich beim Bootstrapping der Authentifizierung in Azure OpenAI. Prompty ist eine praktische Möglichkeit, Ihre Eingabeaufforderung, Parameter und Beispieleingaben in einer einzigen Datei zu bündeln. Mehr über Prompty erfahren Sie in einem anderen Artikel in diesem Magazin: "Hören Sie auf, Inhalte mit ChatGPT zu erstellen!". Zusammen machen diese beiden Tools die Interaktion mit LLMs zu einem Kinderspiel. Sie reduzieren den Code, den Sie ausführen müssen, auf nur ein paar Zeilen:
KernelArguments kernelArguments = new()
{
{ "specification", openApiSpec }
};
var prompty = kernel.CreateFunctionFromPromptyFile("./Prompts/openapi.prompty");
var promptResult = await prompty.InvokeAsync<string>(kernel, kernelArguments);
```
The Prompty file includes all the instructions the LLM needs to turn a complex JSON file into English. It also contains part of the Confluence documentation that describes the specific formatting rules for a Confluence page. This way, the LLM can generate the documentation in the correct format. The API then takes the generated documentation and uploads it to Confluence.
All the different workloads that make up our integration platform run on our Azure Landing Zones. These landing zones come with a lot of benefits for networking, security, and governance. To host this central service, we gave it its own Azure Landing Zone. The Landing Zone offers us a blank canvas to deploy our service, and in our case, this is limited to just a few services.
First of all, we need something to run our code. Azure offers many different compute products to host a simple API. We decided on an Azure Container App. This has easily become our hosting model of choice in our integration platform because it offers container-based hosting with many different scaling options. This might sound like overkill for a relatively simple API that is called maybe once or twice per hour, but a benefit is that the API can automatically scale back to zero instances, so it does not cost any money. This makes it a very cost-effective solution.
Next to the Container App, the API needs to interact with an LLM in order to generate the documentation. For this, we decided to use the Azure OpenAI service and deployed the GPT-4o model. Through Azure OpenAI, we get access to all leading LLMs without a matching price tag. Just like with Container Apps, you only pay for what you actually use. In the case of our GPT-4o model, we only pay for the amount of tokens we exchange. When we generate documentation, the LLM costs are below 2 cents per run. When no documentation is generated, we pay nothing for these resources. The API sets up a secure connection through the Managed Identity, which is built into the Container App, which saves us from having to manage credentials for it. As long as the identity has the correct access permissions, it can connect.
Finally, we also need a place to store the credentials that are needed to upload the documentation to Confluence. This is simply solved by adding a Keyvault and having the API connect to it to retrieve the necessary credentials.
<h3>Using it</h3>
Now that it is all available and running, we can actually use it in our pipelines. We have multiple environments, and as all of them can have different versions of an API running, we need to generate the documentation per environment. We have accomplished this by adding a 'Generate documentation' step after all our deployments, which will retrieve the OpenAPI specification from the deployed resource and call the documentation service with the retrieved specification as content, together with the identifier of the environment. The documentation service will make sure that a page on Confluence is created or updated for that environment and that the generated documentation is on that page. To make it easier for all users of our platform, we turned it into a templated step. So, all they have to do is add the following to their pipeline:
```yml
- job: generate_documentation_nonprod
displayName: Generate Documentation Nonprod
steps:
- script: curl -o swagger.json https://apiname.nonprod.integrations.clientname.org/swagger/v1/swagger.json
displayName: Download Swagger JSON
- template: /pipelines/templates/steps/generate-documentation.yml@platform
parameters:
name: ApiName
environment: nonprod
filePath: swagger.jsonFazit
Wir bauen eine Integrationsplattform auf, die Dutzende von APIs verschiedener Autoren mit unterschiedlichen Programmiersprachen beherbergen wird. Bei jeder Entscheidung, die wir auf unserem Weg der Plattformentwicklung treffen, versuchen wir, die Automatisierung zu maximieren, um die Erfahrung der Entwickler so gut wie möglich zu gestalten. Alle Nutzer unserer Plattform können nun unsere API zur Dokumentationserstellung nutzen, um sicherzustellen, dass ihre Dokumentation kontinuierlich mit ihren tatsächlichen Funktionen übereinstimmt. Auf diese Weise können wir sicherstellen, dass die Dokumentation immer auf dem neuesten Stand ist und wir uns auf die Dinge konzentrieren können, die wir am liebsten tun, nämlich durch die Entwicklung von Funktionen einen Mehrwert zu schaffen.
Dieser Artikel ist Teil von XPRT.#17. Laden Sie das Magazin hier herunter.

Verfasst von
Matthijs van der Veer
Matthijs is a consultant at Xebia, with a strong focus on Generative AI. He loves helping people achieve more in the cloud.
Unsere Ideen
Weitere Blogs

Wo die GitHub Copilot Erweiterungspunkte die Governance brechen
Viele der jüngsten Ergänzungen des GitHub Copilot-Ökosystems bieten einen echten Mehrwert für einzelne Entwickler, erweitern aber auch die...
Rob Bos


Contact