Bei GetInData entwickeln wir elastische MLOps-Plattformen, die den Bedürfnissen unserer Kunden entsprechen. Eine der wichtigsten Funktionen der MLOps-Plattform ist die Möglichkeit, Experimente zu verfolgen und die trainierten Modelle in Form eines Modell-Repositorys zu verwalten. Unsere flexible Plattform ermöglicht es unseren Kunden, die besten Technologien zur Bereitstellung dieser Funktionen auszuwählen, unabhängig davon, ob es sich um Open Source oder kommerzielle Technologien handelt. MLFlow ist eines der Open-Source-Tools, das sich für diese Aufgabe sehr gut eignet. In diesem Blogbeitrag zeige ich Ihnen, wie Sie MLFlow auf Cloud Run, Cloud SQL und Google Cloud Storage einsetzen können, um einen vollständig verwalteten, serverlosen Dienst für die Verfolgung von Experimenten und das Modell-Repository zu erhalten. Der Dienst wird durch OAuth2.0-Autorisierung und SSO mit Google-Konten geschützt.
Voraussetzungen
- Zugang zur Google Cloud Platform
- Service-Konto für die Ausführung von MLFlow in Cloud Run
- OAuth 2.0 Client ID und Client Secrets für die Autorisierung
- Docker-Installation (für die Erstellung des Images, aber dies kann auch in CI erfolgen)
Ziel einrichten
Die endgültige Einrichtung, die in diesem Blogbeitrag beschrieben wird, sieht folgendermaßen aus: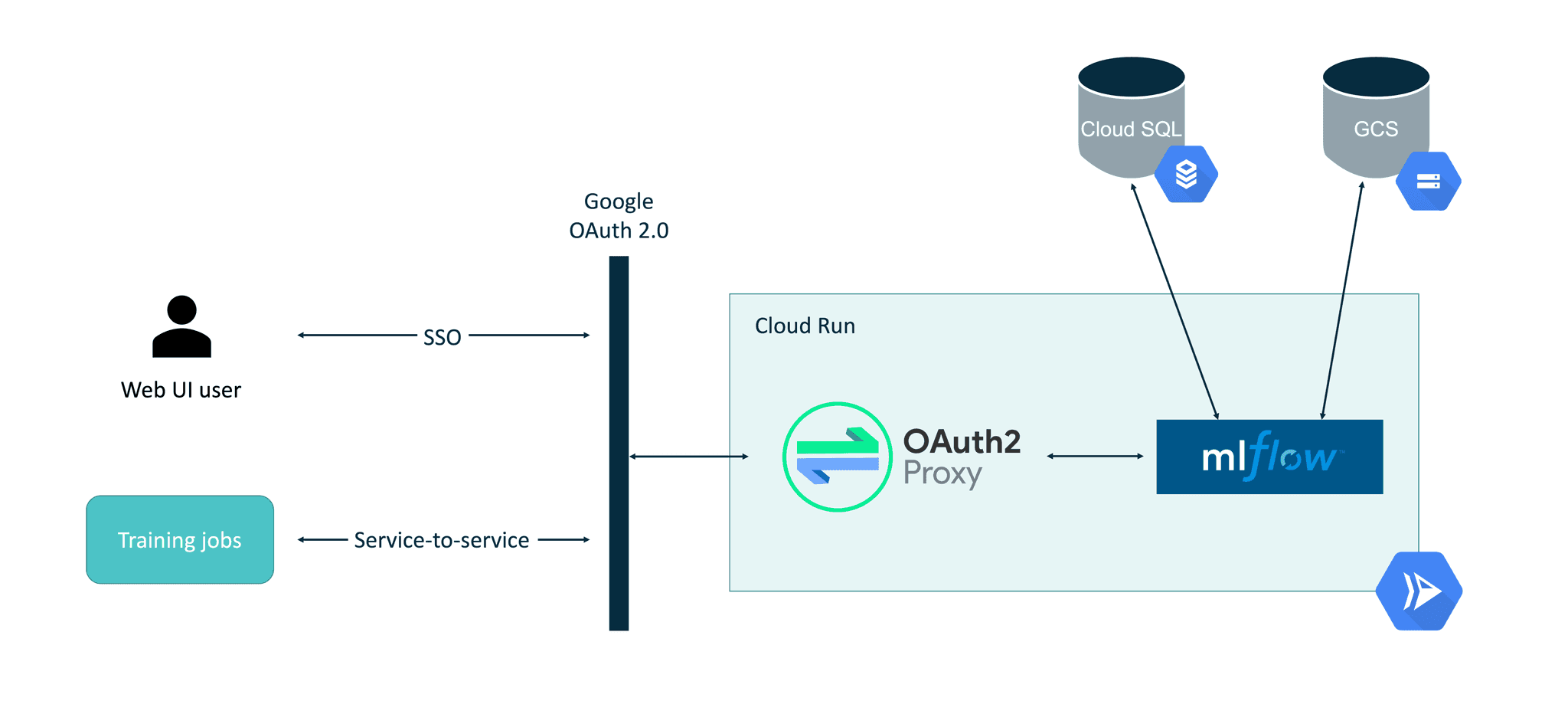
Einer der wichtigsten Aspekte dabei ist die Verwendung des OAuth2-Proxy als mittlere Schicht innerhalb des Cloud Run-Containers. Die Verwendung des in Cloud Run eingebauten Autorisierungsmechanismus (Option
Schritt 1: Angemessene Berechtigungen festlegen
Das Dienstkonto, das für die Ausführung von MLFlow in Cloud Run verwendet wird, muss über die folgenden Berechtigungen verfügen:
- Cloud SQL Client
- Secret Manager Secret Accessor (optional kann dies direkt für jedes Geheimnis separat eingestellt werden)
- Speicherobjekt-Betrachter
Schritt 2: Vorkonfiguration des OAuth 2.0 Client
Um die OAuth 2.0 Autorisierung in Cloud Run zu integrieren, wird OAuth2-Proxy als Proxy über MLFlow verwendet. OAuth2-Proxy kann mit vielen OAuth-Anbietern arbeiten, darunter GitHub, GitLab, Facebook, Google, Azure und andere. Die Verwendung eines Google-Anbieters ermöglicht die einfache Integration von SSO in die interaktive MLFlow-Benutzeroberfläche, erleichtert aber auch die Autorisierung von Dienst zu Dienst unter Verwendung von Inhaber-Tokens. Dadurch wird MLFlow von seinem Python-SDK aus sicher zugänglich sein, z.B. wenn der Modell-Trainingsauftrag ausgeführt wird.
Die Client ID / das Client Secret können Sie erstellen, indem Sie https://console.cloud.google.com/apis/credentials/oauthclient besuchen und den neuen Client wie unten gezeigt als Webanwendung konfigurieren. Während der Vorkonfiguration bleiben die 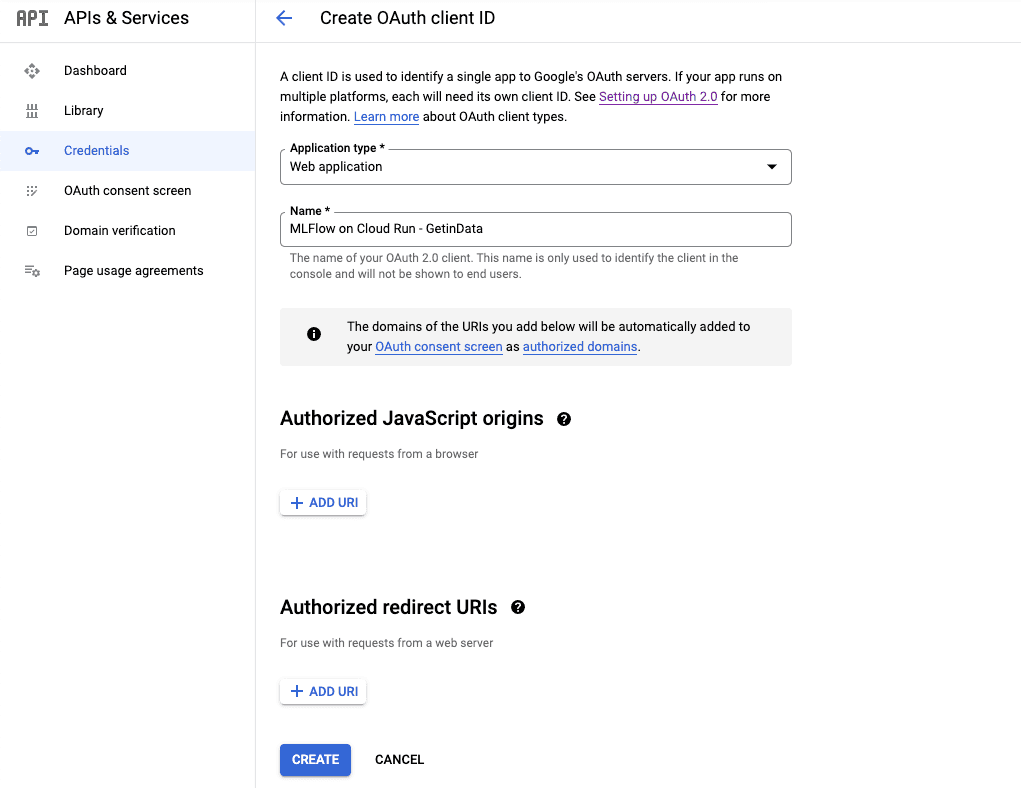
Nach der Erstellung werden die Client ID und das Client Secret angezeigt. Sie müssen für eine spätere Konfiguration sicher aufbewahrt werden.
Schritt 3: Konfigurieren von Cloud SQL / Cloud Storage
Sowohl die Cloud SQL- als auch die Cloud Storage-Konfigurationen sind unkompliziert und werden in diesem Blogbeitrag übersprungen. Die offizielle GCP-Dokumentation zur Verbindung von Cloud SQL mit Cloud Run deckt alle Aspekte dieser Einrichtung gut ab.
- Je nach Auslastung können Cloud SQL-Instanzen je nach Bedarf hochskaliert werden. Für kleine Einsätze sollte eine Standardinstanz mit 1 vCPU ausreichend sein.
- Es ist wichtig, dass sich sowohl Cloud SQL als auch der GCS-Bucket in derselben GCP-Region befinden wie die Cloud Run-Instanz, um sowohl die Latenzzeit als auch die Kosten für die Datenübertragung zu minimieren.
- Bevor Cloud SQL verwendet werden kann, muss eine Datenbank namens mlflow erstellt werden.
- Jede von MLFlow unterstützte Datenbankart kann verwendet werden.
Es ist eine gute Praxis, einen separaten GCS-Bucket für die Verwendung durch MLFlow zu haben.
Schritt 4: Speichern der Konfiguration im Secret Manager
Sowohl MLFlow als auch OAuth2-Proxy erfordern eine Konfiguration, die sensible Daten enthält (z.B. OAuth2.0 Client Secret, Datenbankverbindungsstring). Diese Konfiguration wird im Secret Manager gespeichert und dann über Umgebungsvariablen und Dateien in den Cloud Run-Dienst eingebunden. Es sollten zwei Secrets erstellt werden:
- Geheimnis mit Verbindungszeichenfolge zum Cloud SQL (für MLFlow)
- Secret mit der OAuth2.0 Proxy-Konfigurationsdatei gemäß der unten stehenden Vorlage:
email_domains = [
"<SSO EMAIL DOMAIN>"
]
provider = "google"
client_id = "<CLIENT ID>"
client_secret = "<SECRET>"
skip_jwt_bearer_tokens = true
extra_jwt_issuers = "https://accounts.google.com=32555940559.apps.googleusercontent.com"
cookie_secret = "<COOKIE SECRET IN BASE64>"Das Cookie-Geheimnis kann mit head -c 32 /dev/urandom | base64 erstellt werden.
Der zusätzliche Parameter JWT issuers ist erforderlich, damit die Autorisierung von Dienst zu Dienst richtig funktioniert.
Schritt 5: Vorbereiten des MLFlow Docker-Images
Das Docker-Image für die Ausführung von MLFlow mit OAuth2-Proxy wird auf dem öffentlichen MLFlow-Docker-Image von GetInData basieren: https://github.com/getindata/mlflow-docker (da MLFlow noch kein Image bereitstellt). Es sind zwei Änderungen erforderlich:
- Installation des OAuth2-Proxy.
- Installation von Tini entrypoint.
OAuth2-Proxy wird eine Autorisierungsschicht für MLFlow sein, die im Hintergrundprozess des Containers ausgeführt wird. Tini wird für die Verwaltung des Einstiegspunkts des Containers verwendet.
Dockerdatei
FROM gcr.io/getindata-images-public/mlflow:1.22.0
ENV TINI_VERSION v0.19.0
EXPOSE 4130
RUN apt update && apt install -y curl netcat && mkdir -p /oauth2-proxy && cd /oauth2-proxy && \
curl -L -o proxy.tar.gz https://github.com/oauth2-proxy/oauth2-proxy/releases/download/v6.1.1/oauth2-proxy-v6.1.1.linux-amd64.tar.gz && \
tar -xzf proxy.tar.gz && mv oauth2-proxy-*.linux-amd64/oauth2-proxy . && rm proxy.tar.gz && \
rm -rf /var/lib/apt/lists/*
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /tini
RUN chmod +x /tini
COPY start.sh start.sh
RUN chmod +x start.sh
ENTRYPOINT ["/tini", "--", "./start.sh"]start.sh
#!/usr/bin/env bash
set -e
mlflow server --host 0.0.0.0 --port 8080 --backend-store-uri ${BACKEND_STORE_URI} --default-artifact-root ${DEFAULT_ARTIFACT_ROOT} &
while ! nc -z localhost 8080 ; do sleep 1 ; done
/oauth2-proxy/oauth2-proxy --upstream=http://localhost:8080 --config=${OAUTH_PROXY_CONFIG} --http-address=0.0.0.0:4180 &
wait -nEinzelheiten zu diesem Einstiegspunkt finden Sie im Abschnitt Schritt 6 weiter unten. Sobald das Image erstellt ist, muss es an GCR übertragen werden, damit Cloud Run es bereitstellen kann.
Schritt 6: Einsatz von MLFlow mit OAuth2-Proxy auf Cloud Run
Sobald das Docker-Image erstellt ist, kann es in Cloud Run bereitgestellt werden.
Einstellen der Cloud Run-Parameter
Die Standardparameter sollten wie folgt eingestellt werden:
- Containerbild-URL - Pfad zum Bild, das in Schritt 5 in den GCR übertragen wurde.
- Containerhafen - 4180
- Container-Befehl / Container-Argumente - können leer gelassen werden, da sie in der Dockerdatei konfiguriert sind
- CPU-Zuweisung und Preise - siehe unten
- Kapazität - 1GiB Speicher und 1 vCPU reichen für eine kleine Arbeitslast aus. Kann je nach Bedarf aufgestockt werden
- Zeitüberschreitung für Anfragen - 300s (Standard).
- Maximale Anfragen pro Container - 80 (Standard). Kann je nach Auslastung feinabgestimmt werden.
- Autoskalierung - Min. 0, Max. N (abhängig von der Last).
- Ingress - Sämtlichen Verkehr zulassen
- Authentifizierung - Erlauben Sie unauthentifizierte Aufrufe - sie werden von OAuth2-Proxy authentifiziert.
- Verbindungen / Cloud SQL-Verbindungen - wählen Sie die zuvor erstellte Cloud SQL-Instanz.
- Sicherheit / Dienstkonto - wählen Sie das Dienstkonto, das Sie zuvor für diese Bereitstellung erstellt haben.
Wichtiger Hinweis zur Einstellung der CPU-Zuweisung und der Preise
Aus dem Code des Einstiegspunkts ist ersichtlich, dass zwei Dienste gleichzeitig in einem einzigen Container ausgeführt werden. Der Front-End-Dienst ist OAuth2-Proxy und der Back-End-Dienst ist die eigentliche MLFlow-Instanz. Aufgrund dieser Konfiguration muss der Einstiegspunkt warten, bis der MLFlow-Server startet, bevor er mit dem nächsten Schritt, dem Start des OAuth2-Proxy, fortfahren kann. Ohne die Warteschleife wird der Dienst nicht ordnungsgemäß gestartet und der Zugriff auf den bereitgestellten Cloud Run-Dienst führt zu Bad Gateway: Fehler bei der Proxy-Verbindung zum Upstream-Server: 
Der Grund, warum dies geschieht, hängt direkt mit der Konfiguration des Cloud Run zusammen. Derzeit gibt es bei der Bereitstellung eines Cloud Run-Dienstes zwei Optionen für CPU-Zuweisung und Preisgestaltung:
- Die CPU wird nur während der Verarbeitung von Anfragen zugewiesen - Sie werden pro Anfrage und nur dann berechnet, wenn die Container-Instanz eine Anfrage verarbeitet.
- CPU wird immer zugewiesen - Sie werden für den gesamten Lebenszyklus der Container-Instanz berechnet.
Die erste Option, die Standardoption, die "die serverloseste" ist, bedeutet, dass der eingesetzte Container nur CPU-Zeit erhält, wenn die Anfrage ausgeführt wird. Da MLflow ein Hintergrundprozess ist, erhält er nur dann CPU-Zeit für den Start des Servers, wenn der Front-End-Prozess (in diesem Fall OAuth2-Proxy) die HTTP-Anfrage verarbeitet. Da die Anfragen an OAuth2-Proxy kurz sind, wird die CPU beansprucht und der MLFlow-Server kann nicht starten. Wenn Sie den Einstiegspunkt für OAuth2-Proxy dazu zwingen, zu warten, bevor der MLFlow-Server startet, verhindern Sie, dass der MLFlow-Server startet oder nicht, je nachdem, wie viele CPU-Zyklen der Container während der Initialisierung erhalten hat.
Die zweite Option ist teurer, da die für den Container zugewiesene CPU immer verfügbar ist. Diese Option eignet sich gut für Dienste, die Backend-Verarbeitungen durchführen (z. B. Pub/Sub-Nachrichten verarbeiten). Sie ist zwar teurer, aber die permanente Zuweisung der CPU verhindert, dass der MLFlow-Server gedrosselt wird, und sein Prozess kann korrekt initialisiert werden, ohne dass HTTP-Anfragen an den Container gestellt werden (mit Ausnahme der ersten bei der Skalierung auf 0). Es ist jedoch zuverlässiger, zunächst alle Prozesse innerhalb des Containers zu initialisieren, bevor Sie dem Executor-Dienst (hier: Cloud Run) den Status "bereit" melden.
Geheimnisse konfigurieren
Die in Schritt 4 erstellten Secrets müssen in den Cloud Run-Dienst eingebunden werden. Die Konfiguration ist unten dargestellt: 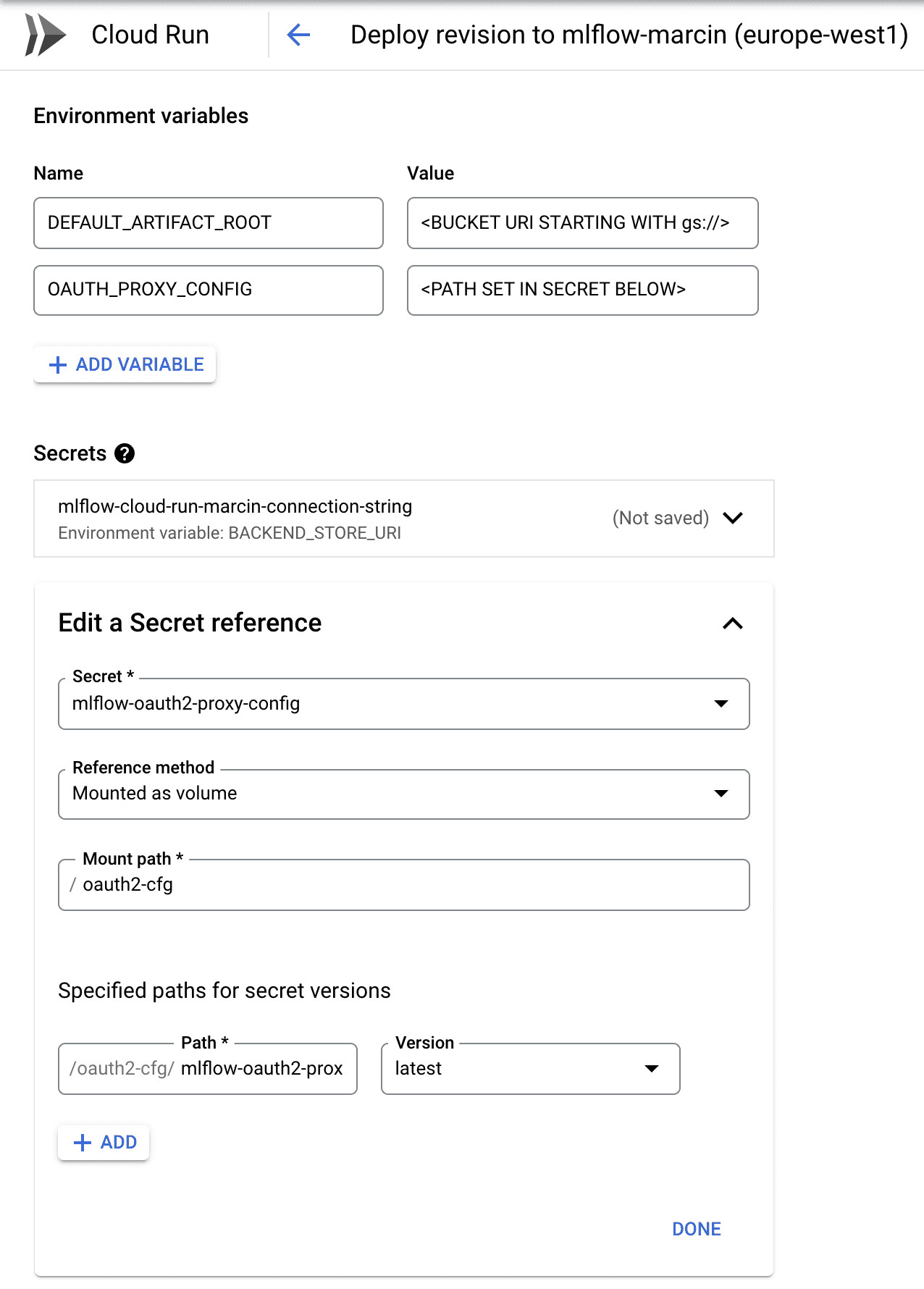
Die Verbindungszeichenfolge zur Datenbank (erstes Geheimnis) sollte als Umgebungsvariable BACKEND_STORE_URI eingebunden werden - sie wird vom MLFlow Server verwendet. Die Konfiguration für den OAuth2-Proxy sollte als Volume gemountet werden und der hier angegebene Pfad sollte in der Umgebungsvariablen OAUTH_PROXY_CONFIG übergeben werden (siehe setup.sh oben, um die Übergabe dieser Parameter zu verstehen).
Schritt 7: Fertigstellung der OAuth2.0-Konfiguration
In Schritt 2 wurde der OAuth 2.0-Client vorkonfiguriert, aber die autorisierten Umleitungs-URIs wurden leer gelassen. Sobald der Cloud Run-Dienst bereitgestellt ist, wird seine URL in der Benutzeroberfläche verfügbar sein: 
Diese URL muss in der OAuth 2.0-Client-Konfiguration wie folgt angegeben werden:
https://mlflow-.a.run.app/oauth2/callback
, damit die Umleitungen richtig funktionieren.
Zugriff auf die serverlose MLFlow-Bereitstellung
Nach der Bereitstellung kann der MLFlow-Dienst entweder über den Browser oder über einen Backend-Dienst aufgerufen werden.
Browser
Der eingesetzte Cloud Run-Dienst löst den OAuth 2.0-Fluss aus, um den Benutzer zu autorisieren.
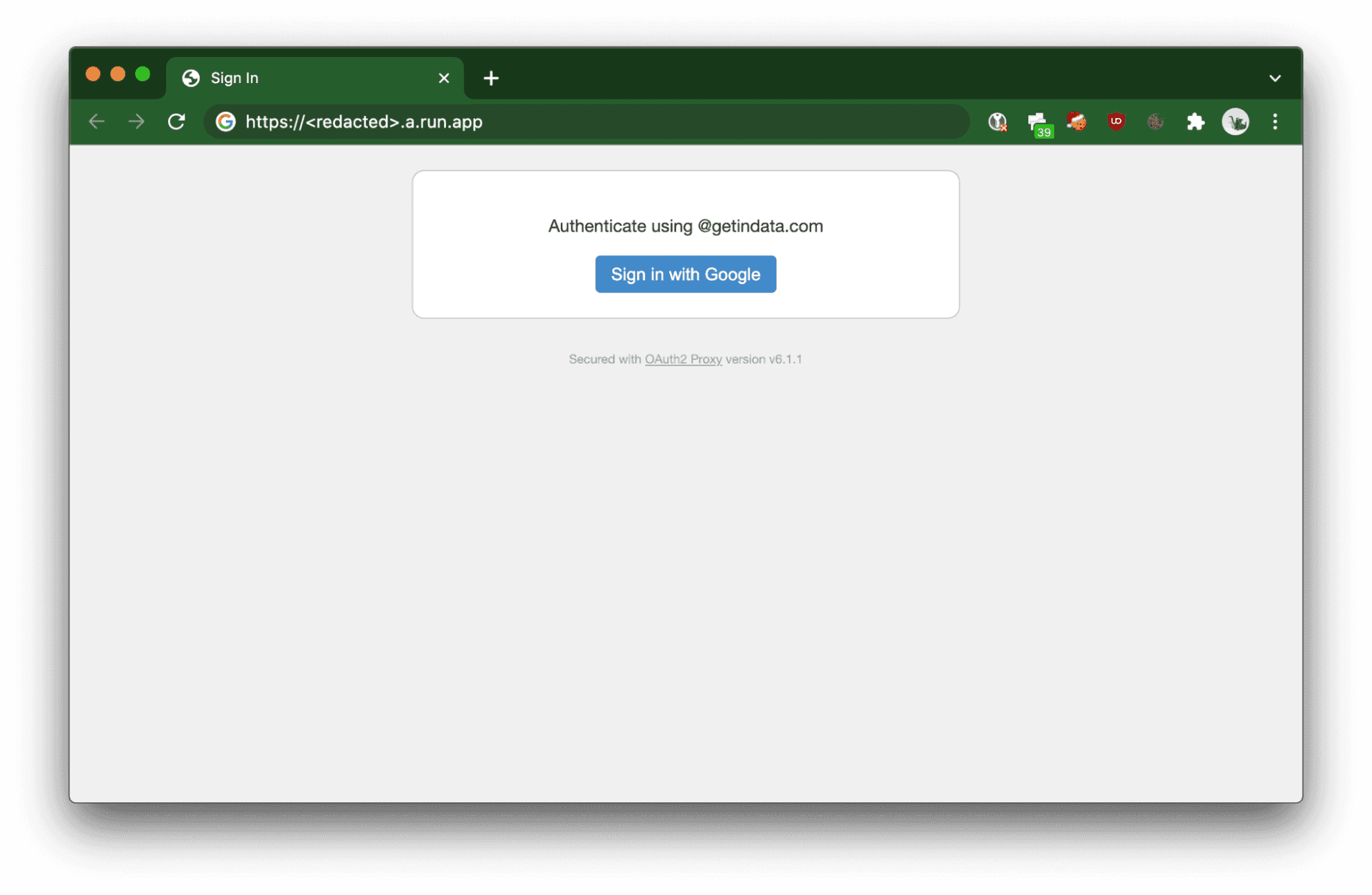
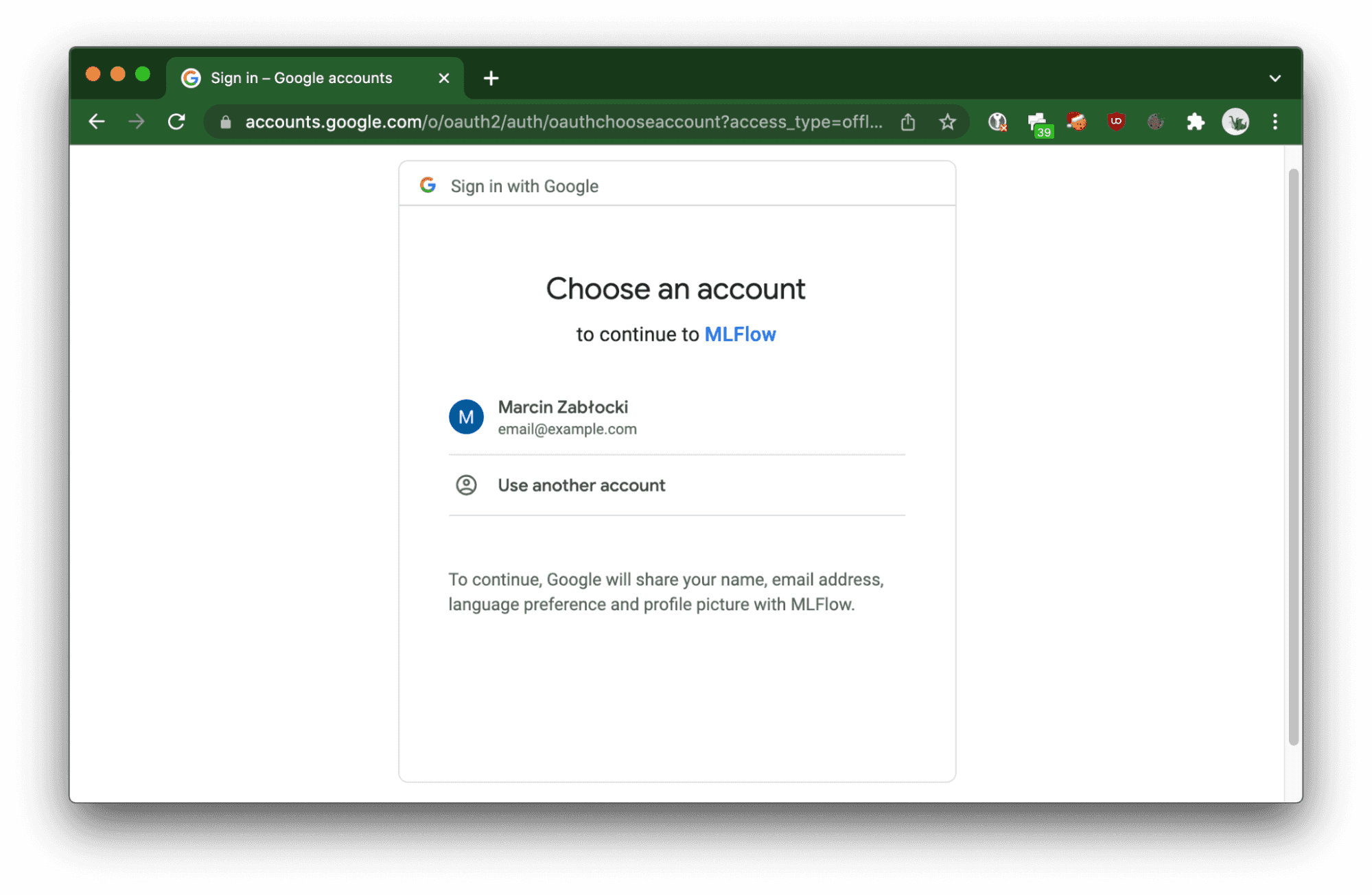
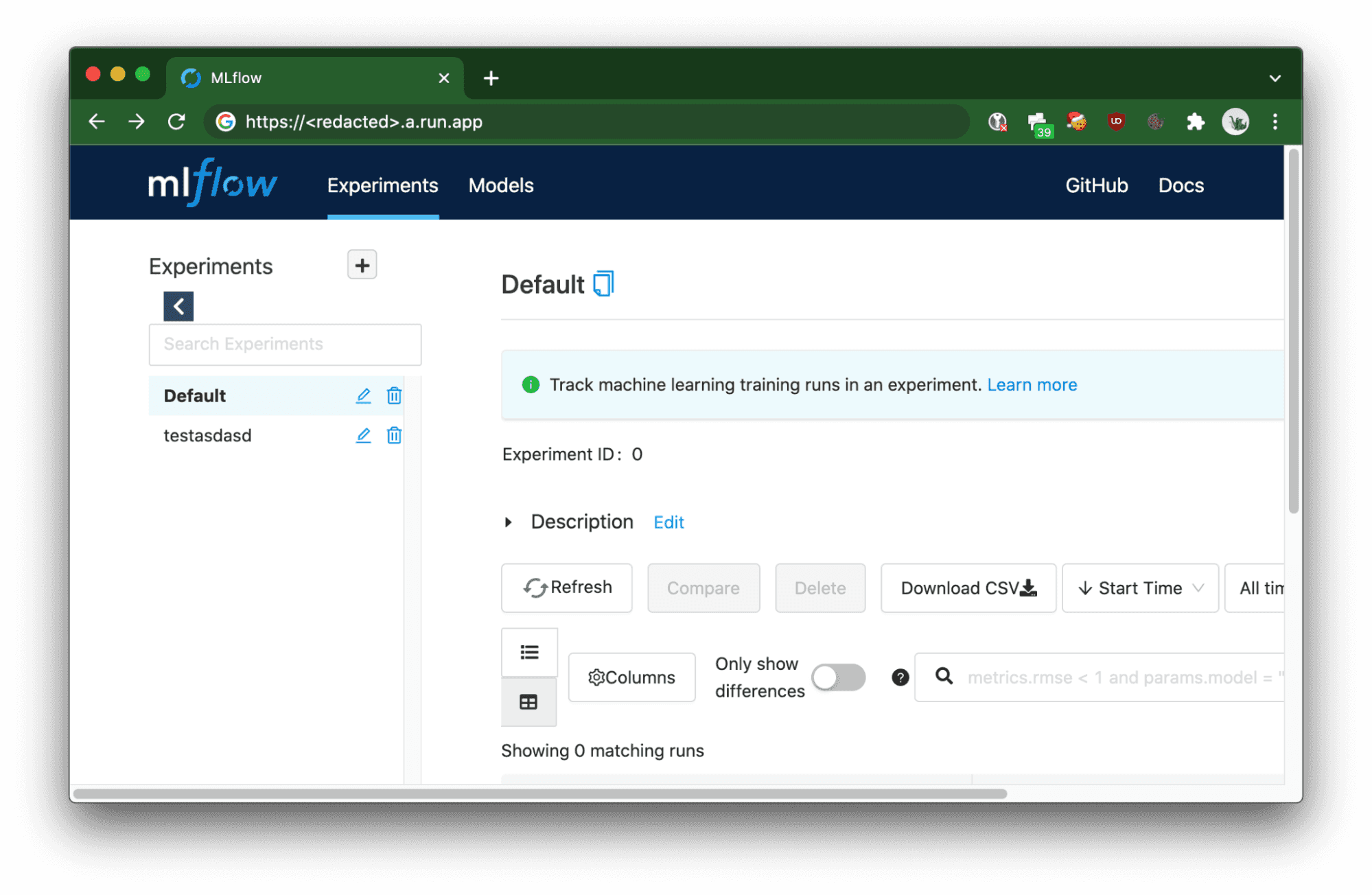
Dienst-zu-Dienst
Bei der Verwendung von CI/CD-Jobs, curl oder Python SDK für MLFlow müssen Anfragen autorisiert werden, indem der Authorization HTTP-Header mit einem Bearer-Token übergeben wird, der vom OAuth 2.0-Token-Anbieter bereitgestellt wird, in diesem Fall Google (beachten Sie, dass nicht alle vom OAuth2-Proxy unterstützten Anbieter es Ihnen ermöglichen, ein Server-zu-Server-Token zu erhalten).
Um das Token zu erhalten, kann der Befehl verwendet werden. Vergewissern Sie sich, dass das Konto, das den Token anfordert, über die entsprechenden Berechtigungen innerhalb des GCP-Projekts verfügt (Viewer sollte ausreichen).
curl -X GET https://<redacted>.a.run.app/api/2.0/mlflow/experiments/list -H "Authorization: Bearer $(gcloud auth print-identity-token)"
{
"experiments": [
{
"experiment_id": "0",
"name": "Default",
"artifact_location": "gs://<redacted>/0",
"lifecycle_stage": "active"
},
{
"experiment_id": "1",
"name": "testasdasd",
"artifact_location": "gs://<redacted>/1",
"lifecycle_stage": "active"
}
]
}Die Autorisierung des Python SDK erfordert nur die Übergabe des generierten Tokens an die Umgebungsvariable MLFLOW_TRACKING_TOKEN, es sind keine Änderungen am Quellcode erforderlich(Beispiel aus den MLFlow-Dokumenten):MLFLOW_TRACKING_TOKEN=$(gcloud auth print-identitytoken)MLFLOW_TRACKING_URI=https://<redacted>.a.run.app python sklearn_elasticnet_wine/train.py
Zusammenfassung
Ich hoffe, diese Anleitung hat Ihnen geholfen, schnell skalierbare MLFlow-Instanzen auf der Google Cloud Platform einzusetzen. Viel Spaß beim (serverlosen) Experimentieren!
Besonderen Dank an Mateusz Pytel und Mariusz Wojakowski, die mir bei der Recherche zu diesem Einsatz geholfen haben.
Interessieren Sie sich für ML- und MLOps-Lösungen? Wie können Sie ML-Prozesse verbessern und die Lieferfähigkeit von Projekten steigern? Sehen Sie sich unsere MLOps-Demo an und melden Sie sich für eine kostenlose Beratung an.
Verfasst von
Marcin Zabłocki
Unsere Ideen
Weitere Blogs




Contact