Blog
Bereitstellung von sicherem MLflow auf AWS

Eine der wichtigsten Funktionen einer MLOps-Plattform ist die Fähigkeit, Experimente zu verfolgen und aufzuzeichnen, die dann gemeinsam genutzt und verglichen werden können. Dazu gehört auch die Speicherung und Verwaltung von Machine Learning-Modellen und anderen Artefakten.
MLFlow ist ein populäres Open-Source-Projekt, das die oben erwähnten Funktionen bietet. Allerdings fehlt der Standard-MLFlow-Installation ein Authentifizierungsmechanismus. Jedem den Zugriff auf Ihr MLFlow-Dashboard zu gestatten, ist sehr oft ein No-Go. Wir bei GetInData unterstützen die ML-Bemühungen unserer Kunden, indem wir MLFlow in ihrer Umgebung so einrichten, wie sie es benötigen, und zwar mit einem Minimum an Wartung. In diesem Blogpost beschreibe ich, wie Sie ein oauth2-geschütztes MLFlow in Ihrer AWS-Infrastruktur bereitstellen können(Die Bereitstellung von serverlosem MLFlow auf Google Cloud Platform mit Cloud Run deckt die Bereitstellung in GCP ab).
Überblick über die Lösung
Sie können MLFlow auf viele Arten einrichten, einschließlich einer einfachen Localhost-Installation. Aber um die gemeinsame Verwaltung von Experimenten und Modellen zu ermöglichen, werden die meisten Produktionsimplementierungen wahrscheinlich in einer verteilten Architektur mit einem entfernten MLFlow-Server und entfernten Backend- und Artefaktspeichern enden.
Das folgende Diagramm stellt die High-Level-Architektur eines solchen verteilten Ansatzes dar.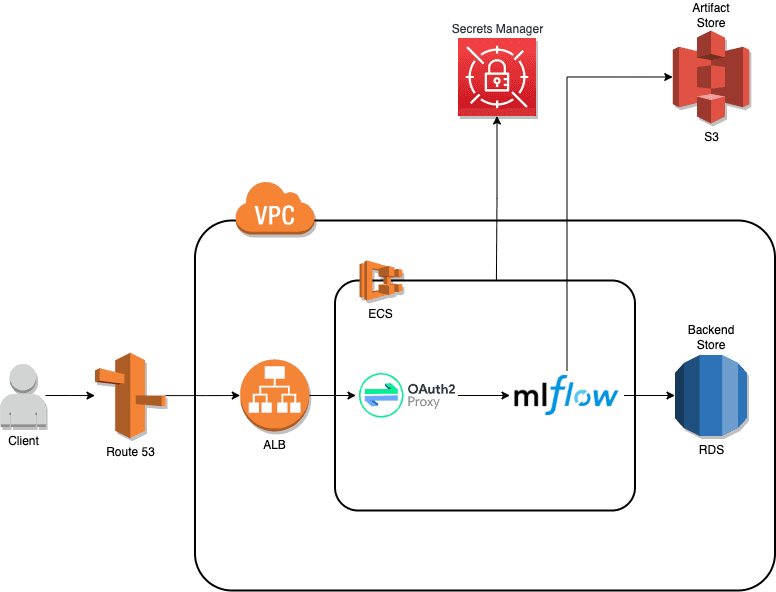
Die wichtigsten MLFlow-Infrastrukturkomponenten sind:
- MLFlow Tracking Server, der eine API für die Protokollierung von Parametern, Metriken, Experimenten, Metadaten und eine Benutzeroberfläche für die Visualisierung der Ergebnisse bereitstellt.
- Amazon Aurora Serverless wird als Backend-Speicher verwendet, in dem MLFlow Metadaten über Experimente und Läufe speichert, d.h. Metriken, Tags und Parameter.
- AWS S3 wird als Artefaktspeicher verwendet, in dem MLFlow Artefakte speichert, z. B. Modelle und Datendateien.
- Oauth2-Proxy schützt MLFlow-Endpunkte, die OAuth2-kompatible Anbieter verwenden, z.B. Google.
Die anderen AWS-Komponenten bieten eine Laufzeit-/Rechenumgebung (Elastic Container Service, ECS), Routing (Application Load Balancer, ALB, und Route 53 als DNS-Service) und Sicherheit (Secrets Manager und Virtual Private Cloud, VPC).
OAuth 2.0-Client einrichten
Um unseren MLFlow-Server zu sichern, müssen wir ihn mit einem OAuth2-Anbieter integrieren. oauth2-proxy unterstützt die wichtigsten OAuth2-Anbieter und Sie können den von Ihnen gewünschten Anbieter konfigurieren. Bitte beachten Sie bei der Auswahl eines Authentifizierungsanbieters, dass nicht alle unterstützten Anbieter es Ihnen ermöglichen, ein Autorisierungs-Token zu erhalten, das für den programmatischen Zugriff erforderlich ist (z.B. CI/CD-Pipelines oder die Protokollierung von Metriken aus geplanten Experimentdurchläufen). In diesem Beispiel haben wir den Google-Anbieter verwendet. Folgen Sie den Anweisungen zum Einrichten von OAuth 2.0, um einen OAuth 2.0-Client zu erstellen. Während des Prozesses:
- Notieren Sie sich die generierte
Client Idund das Client Secret, die Sie später benötigen werden. - Geben Sie
https://<your_dns_name_here>/oauth2/callbackin das FeldAuthorized redirect URIsein.
Elastischer Containerdienst
Wir stellen MLFlow- und oauth2-proxy-Dienste als Container mit Elastic Container Service, ECS, bereit. AWS App Runner wäre eine gute Serverless-Alternative, doch zum Zeitpunkt der Erstellung dieses Blogposts war er nur an wenigen Orten verfügbar. Wir haben zwei Container in einer ECS-Aufgabe definiert. Da mehrere Container innerhalb einer ECS-Aufgabe im Netzwerkmodus awsvpc den Netzwerk-Namensraum gemeinsam nutzen, können sie über localhost miteinander kommunizieren (ähnlich wie Container im gleichen Kubernetes-Pod).
Eine entsprechende Terraform-Container-Definition für den MLFlow-Dienst ist unten abgebildet.
{
name = "mlflow"
image = "gcr.io/getindata-images-public/mlflow:1.22.0"
entryPoint = ["sh", "-c"]
command = [
<<EOT
/bin/sh -c "mlflow server \
--host=0.0.0.0 \
--port=${local.mlflow_port} \
--default-artifact-root=s3://${aws_s3_bucket.artifacts.bucket}${var.artifact_bucket_path} \
--backend-store-uri=mysql+pymysql://${aws_rds_cluster.backend_store.master_username}:`echo -n $DB_PASSWORD`@${aws_rds_cluster.backend_store.endpoint}:${aws_rds_cluster.backend_store.port}/${aws_rds_cluster.backend_store.database_name} \
--gunicorn-opts '${var.gunicorn_opts}'"
EOT
]
portMappings = [{ containerPort = local.mlflow_port }]
secrets = [
{
name = "DB_PASSWORD"
valueFrom = data.aws_secretsmanager_secret.db_password.arn
}
]
}Die Einrichtung des Containers ist einfach - wir starten einfach den MLFlow-Server mit einigen Optionen. Sensible Daten, z.B. ein Datenbankpasswort, werden von Secrets Manager geholt (eine billigere, aber weniger robuste Option wäre die Verwendung des Systems Manager Parameter Store). Allerdings ist die Übergabe der URI des Backend-Speichers im Moment noch etwas kompliziert. AWS ECS erlaubt es nicht, während der Laufzeit Geheimnisse in CLI-Argumente zu interpolieren, so dass wir eine Shell benötigen. Vorzugsweise sollte der MLFlow-Server die Möglichkeit bieten, diesen Wert über eine Umgebungsvariable festzulegen (es gibt ein offenes Thema dazu).
Die ECS-Aufgabe hat auch die Aufgabe, auf S3 zuzugreifen, wo MLFlow Artefakte speichert.
resource "aws_iam_role_policy" "s3" {
name = "${var.unique_name}-s3"
role = aws_iam_role.ecs_task.id
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Action = ["s3:ListBucket"]
Resource = ["arn:aws:s3:::${aws_s3_bucket.artifacts.bucket}"]
},
{
Effect = "Allow"
Action = ["s3:*Object"]
Resource = ["arn:aws:s3:::${aws_s3_bucket.artifacts.bucket}/*"]
},
]
})
}Die Container-Definition auf oauth2-proxy lautet wie folgt;
{
name = "oauth2-proxy"
image = "bitnami/oauth2-proxy:7.2.1"
command = [
"--http-address", "0.0.0.0:8080",
"--upstream", "http://localhost:${local.mlflow_port}",
"--email-domain", "*",
"--provider", "google",
"--skip-jwt-bearer-tokens", "true",
"--extra-jwt-issuers", "https://accounts.google.com=32555940559.apps.googleusercontent.com"
]
portMappings = [{ containerPort = local.oauth2_proxy_port }]
secrets = [
{
name = "OAUTH2_PROXY_CLIENT_ID"
valueFrom = data.aws_secretsmanager_secret.oauth2_client_id.arn
},
{
name = "OAUTH2_PROXY_CLIENT_SECRET"
valueFrom = data.aws_secretsmanager_secret.oauth2_client_secret.arn
},
{
name = "OAUTH2_PROXY_COOKIE_SECRET"
valueFrom = data.aws_secretsmanager_secret.oauth2_cookie_secret.arn
},
]
}Dies ist eine minimale Konfiguration. In einer Produktionsumgebung müssten Sie wahrscheinlich die Authentifizierung auf bestimmte Domänen beschränken (--email-domain Option) und weitere Optionen definieren, z.B. --cookie-refresh.
Beachten Sie, dass die Konfigurationsoption --extra-jwt-issuers erforderlich ist, um den programmatischen Zugriff zu unterstützen.
Die Prämisse unserer Einrichtung ist es, oauth2-proxy vor den MLFlow-Server zu setzen und so Autorisierungsfunktionen hinzuzufügen. Aus diesem Grund haben wir den Load Balancer des ECS-Dienstes so konfiguriert, dass er auf den Container oauth2-proxy zeigt, der, wie der Name schon sagt, als Proxy für den MLFlow-Server fungiert.
resource "aws_ecs_service" "mlflow" {
# other attributes
load_balancer {
target_group_arn = aws_lb_target_group.mlflow.arn
container_name = "oauth2-proxy"
container_port = local.oauth2_proxy_port
}
}Deployment
Hier ist ein kompletter Terraform-Stack für die einfache und automatische Bereitstellung aller erforderlichen AWS-Ressourcen verfügbar.
Der Terraform-Stack erstellt die folgenden Ressourcen
- Eine VPC mit der dazugehörigen Netzwerkeinrichtung, z.B. Subnetze, auf denen die meisten AWS-Ressourcen laufen
- Ein S3-Bucket zum Speichern von MLFlow-Artefakten
- Erforderliche IAM-Rollen und -Richtlinien für den Zugriff auf den S3-Bucket, Geheimnisse im Secrets Manager und die Ausführung von ECS-Aufgaben
- Eine Aurora Serverless-Datenbank zum Speichern von MLFlow-Metadaten
- Ein ECS-Cluster mit einem Dienst, auf dem MLFlow Tracking Server und oauth2-proxy Container laufen
- Ein Application Load Balancer, ALB, zur Weiterleitung des Datenverkehrs an den ECS-Dienst und zur SSL-Terminierung
- Ein A-Eintrag in Route 53, um den Verkehr zu ALB zu leiten
Bevor Sie jedoch Terraform-Befehle ausführen, müssen Sie einige Schritte manuell durchführen.
Voraussetzungen
Sie müssen die folgenden Tools installiert haben
- AWS CLI
- Terraform CLI (v1.0.0+)
Manuelle Schritte
- Erstellen Sie einen S3-Bucket zum Speichern des Terraform-Status. Dieser Schritt ist jedoch nicht unbedingt erforderlich, wenn Sie den Status lokal speichern möchten
export TF_STATE_BUCKET=<bucketname>
aws s3 mb s3://$TF_STATE_BUCKET
aws s3api put-bucket-versioning --bucket $TF_STATE_BUCKET --versioning-configuration Status=Enabled
aws s3api put-public-access-block \
--bucket $TF_STATE_BUCKET \
--public-access-block-configuration "BlockPublicAcls=true,IgnorePublicAcls=true,BlockPublicPolicy=true,RestrictPublicBuckets=true" Die Aktivierung der Versionierung und die Sperrung des öffentlichen Zugriffs sind optional (aber empfohlen).
- Erstellen Sie eine DynamoDB-Tabelle für State Locking. Dieser Schritt ist nicht unbedingt erforderlich, wenn Sie State Locking und Konsistenzprüfung nicht aktivieren.
export TF_STATE_LOCK_TABLE=<tablename>
aws dynamodb create-table \
--table-name $TF_STATE_LOCK_TABLE \
--attribute-definitions AttributeName=LockID,AttributeType=S \
--key-schema AttributeName=LockID,KeyType=HASH \
--provisioned-throughput ReadCapacityUnits=1,WriteCapacityUnits=1aws secretsmanager create-secret \
--name mlflow/oauth2-cookie-secret \
--description "OAuth2 cookie secret" \
--secret-string "<cookie_secret_here>"
aws secretsmanager create-secret \
--name mlflow/store-db-password \
--description "Password to RDS database for MLFlow" \
--secret-string "<db_password_here>"
# This is a Client Id obtained when setting up OAuth 2.0 client
aws secretsmanager create-secret \
--name mlflow/oauth2-client-id \
--description "OAuth2 client id" \
--secret-string "<oauth2_client_id_here>"
# This is a Client Secret obtained when setting up OAuth 2.0 client
aws secretsmanager create-secret \
--name mlflow/oauth2-client-secret \
--description "OAuth2 client secret" \
--secret-string "<oauth2_client_secret_here>"Der mitgelieferte Terraform-Stack geht davon aus, dass Sie eine bestehende Route 53 gehostete Zone und ein öffentliches SSL/TLS-Zertifikat von Amazon haben.
MLFlow bereitstellen
Führen Sie den folgenden Befehl aus, um alle erforderlichen Infrastruktur-Ressourcen zu erstellen.
terraform init \
-backend-config="bucket=$TF_STATE_BUCKET" \
-backend-config="dynamodb_table=$TF_STATE_LOCK_TABLE"
export TF_VAR_hosted_zone=<hosted_zone_name>
export TF_VAR_dns_record_name=<mlflow_dns_record_name>
export TF_VAR_domain=<domain>
terraform plan
terraform applyDie Einrichtung der AWS-Infrastruktur kann ein paar Minuten dauern. Sobald sie abgeschlossen ist, können Sie zur MLFlow-Benutzeroberfläche navigieren (die URL wird in der Ausgabevariablen
Programmatischer Zugang
Viele MLFlow-Anwendungsfälle beinhalten den programmatischen Zugriff auf die MLFlow Tracking Server API, z.B. die Protokollierung von Parametern oder Metriken in Ihren Kedro-Pipelines. In solchen Szenarien müssen Sie ein Bearer-Token in der HTTP AuthorizationKopfzeile übergeben. Die Beschaffung eines solchen Tokens ist von Anbieter zu Anbieter unterschiedlich. Bei Google beispielsweise können Sie das Token mit folgendem Befehl abrufen:
gcloud auth print-identity-tokenEin autorisierter curl-Befehl, der Ihre Experimente auflistet, würde wie folgt aussehen:
Die Weitergabe des Autorisierungstokens an andere Tools ist SDK-spezifisch. Das MLFLow Python SDK unterstützt zum Beispiel die Bearer-Authentifizierung über die Umgebungsvariable MLFLOW_TRACKING_TOKEN.
Zusammenfassung
In diesem Tutorial haben wir beschrieben, wie Sie einen Open-Source MLflow-Server auf AWS mit ECS, Amazon S3 und Amazon Aurora Serverless auf sichere Weise hosten können. Wie Sie sehen können, ist dies keine komplizierte Lösung und bietet gute Sicherheitsmaßnahmen (sowohl in Bezug auf den Benutzerzugriff als auch auf die Datensicherheit), minimale Wartung und faire Kosten für die Bereitstellung. Wenn Sie die Google-Infrastruktur bevorzugen, besuchen Sie bitte Serverless MLFlow auf der Google Cloud Platform mit Cloud Run bereitstellen.
–
Interessieren Sie sich für ML- und MLOps-Lösungen? Wie können Sie ML-Prozesse verbessern und die Lieferfähigkeit von Projekten steigern? Sehen Sie sich unsere MLOps-Demo an und melden Sie sich für eine kostenlose Beratung an.
Verfasst von
Marek Jędraszewski
Unsere Ideen
Weitere Blogs




Contact