Blog
Bereitstellung von MLflow auf der Google Cloud Platform mit App Engine

Die von GetInData bereitgestellten MLOps-Plattformen ermöglichen es uns, erstklassige Technologien auszuwählen, um wichtige Funktionen abzudecken. MLflow ist eine der Schlüsselkomponenten in den Open-Source-basierten MLOps-Plattformen, da es sowohl als Experiment-Tracker als auch als zentralisierte Modellregistrierung fungiert.
In meinem vorherigen Blogbeitrag habe ich über die Bereitstellung von serverlosem MLflow in GCP mit Cloud Run geschrieben. Diese Lösung hat ihre Vorteile, aber auch einige Nachteile aufgrund der Komplexität der Autorisierungsschicht. Es gibt noch andere Optionen - eine davon ist die Verwendung der
Voraussetzungen
- Zugriff auf die Google Cloud Platform, einschließlich: CloudSQL, GCS, Secret Manager, App Engine, Artifact Registry
- Terraform >= 1.1.7
- Docker (für die Erstellung des Images, kann aber auch in CI durchgeführt werden)
Ziel einrichten
Die endgültige Einrichtung, die in diesem Blogbeitrag beschrieben wird, sieht folgendermaßen aus: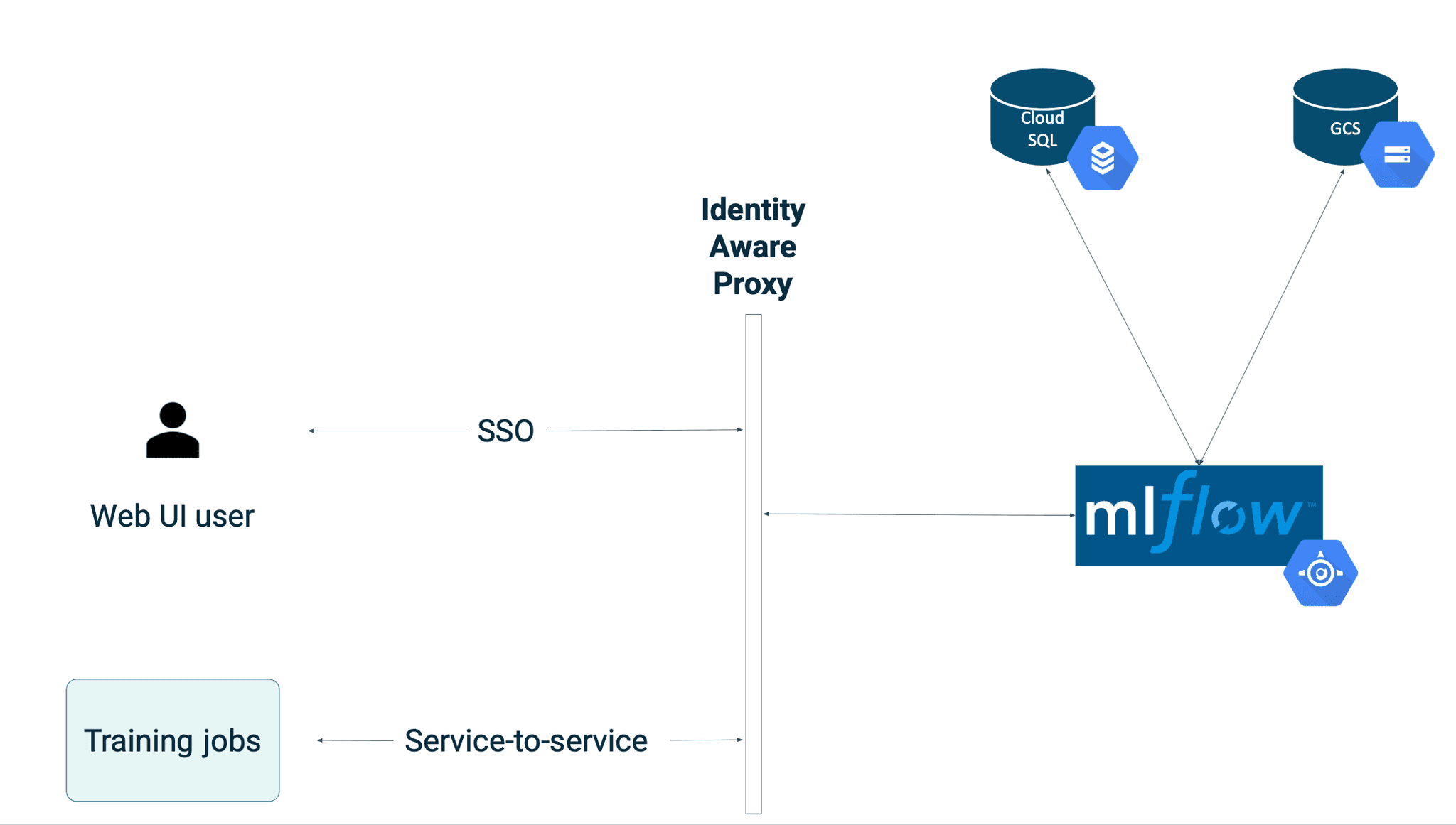
Schritt 1: Vorkonfiguration des OAuth 2.0 Client
App Engine-basiertes MLflow verwendet Identity Aware Proxy als Autorisierungsschicht. Um ihn zu konfigurieren, müssen Sie die OAuth 2.0 Client ID und das Client Secret erhalten. Folgen Sie der offiziellen Anleitung hier oder lesen Sie den vorherigen Blogbeitrag (Schritt #2).
Sobald die OAuth 2.0-Anmeldeinformationen erstellt sind, vergewissern Sie sich, dass das Feld Authorized redirect URIs einen Wert hat, der dem Muster entspricht (normalerweise wird dieser Wert mit dem korrekten Wert vorausgefüllt, aber Sie sollten dies überprüfen):
https://iap.googleapis.com/v1/oauth/clientIds/<CLIENT ID>:handleRedirect
Dies ist erforderlich, damit der IAP-Proxy ordnungsgemäß mit der App Engine funktioniert.
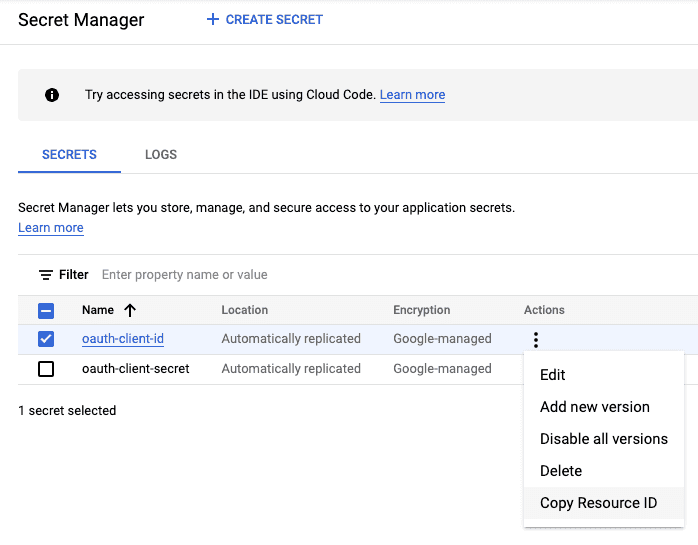
Speichern Sie die Client ID und das Client Secret in 2 separaten Secrets im Secret Manager und speichern Sie die Resource ID jedes Secrets - sie wird an die App Engine weitergegeben.
Schritt 2: Erstellen Sie das Docker-Image für MLflow auf App Engine
Das Docker-Image für MLflow wird dem öffentlichen MLflow-Docker-Image von GetInData (https://github.com/getindata/mlflow-docker) ähneln , mit dem Unterschied, dass das Basis-Image das gcloud SDK installiert hat. Der Grund für diese Anforderung ist, dass es keinen eingebauten Mechanismus gibt, um Geheimnisse aus dem Secret Manager (mit einem Datenbankpasswort) nativ in den App Engine Service einzubinden, wodurch die Verantwortung für die Beschaffung des Geheimnisses auf den eigentlichen Anwendungscode/Container-Einstiegspunkt verlagert wird.
Dockerdatei
FROM google/cloud-sdk:385.0.0
ARG MLFLOW_VERSION="1.26.0"
ENV LC_ALL=C.UTF-8
ENV LANG=C.UTF-8
RUN echo "export LC_ALL=$LC_ALL" >> /etc/profile.d/locale.sh
RUN echo "export LANG=$LANG" >> /etc/profile.d/locale.sh
ENV TINI_VERSION v0.19.0
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /tini
RUN chmod +x /tini
RUN pip3 install --no-cache-dir --ignore-installed google-cloud-storage && \
pip3 install --no-cache-dir PyMySQL mlflow==$MLFLOW_VERSION pyarrow
COPY start.sh start.sh
RUN chmod +x start.sh
ENTRYPOINT ["/tini", "--", "./start.sh"]start.sh
#!/usr/bin/env bash
set -e
echo "Obtaining credentials"
DB_PASSWORD=$(gcloud secrets versions access --project=${GCP_PROJECT} --secret=${DB_PASSWORD_SECRET_NAME} latest)
BACKEND_URI=${BACKEND_URI:-"mysql+pymysql://${DB_USERNAME}:${DB_PASSWORD}@/${DB_NAME}?unix_socket=/cloudsql/${DB_INSTANCE_CONNECTION_NAME:-"NOT_SET"}"}
mlflow server \
--backend-store-uri ${BACKEND_URI} \
--default-artifact-root ${GCS_BACKEND} \
--host 0.0.0.0 \
--port ${PORT}Erstellen Sie das Image und übertragen Sie es in die Google Artifact Registry, vorzugsweise in dieselbe Region, in der Sie die App Engine App einsetzen werden.
Schritt 3: Bereiten Sie die Terraform-Eingaben vor
Das vollständige Terraform-Modul, das die Bereitstellung von MLflow auf der App Engine regelt, finden Sie in dem unten verlinkten Repository.
Hier sind die erforderlichen Eingaben:
- Projekt - Google Cloud Platform Projekt-ID
- env - Name der Umgebung (nach Ihrer Wahl)
- prefix - zusätzliches Präfix für Ressourcen (wie CloudSQL, GCS-Buckets usw.)
- region - Region für CloudSQL, Secret Manager und GCS Buckets
- app_engine_region - Region für App Engine (folgen Sie der die offizielle Dokumentation)
- docker_image - vollständige URI des Docker-Images mit MLflow (siehe Schritt 2 oben)
- machine_type - Maschinentyp für die Cloud SQL (z.B. db-n1-standard-1)
- availability_type - Verfügbarkeitstyp für die Cloud SQL-Instanz (Standardwert: ZONAL)
- secret_for_oauth_client_secret - Secret Manager Resource ID des in Schritt 1 erhaltenen Client Secret
- secret_for_oauth_client_id - Geheime Manager-Ressourcen-ID der in Schritt 1 erhaltenen Client-ID
MLflow Terraform Modul Details
App Engine
Geheimnisse werden mit Hilfe von Datenquellen sicher weitergegeben:
data "google_secret_manager_secret_version" "oauth_client_id" {
secret = var.secret_for_oauth_client_id
}
data "google_secret_manager_secret_version" "oauth_client_secret" {
secret = var.secret_for_oauth_client_secret
}
resource "google_app_engine_application" "mlflow_app" {
project = var.project
location_id = var.app_engine_region
iap {
enabled = true
oauth2_client_id = data.google_secret_manager_secret_version.oauth_client_id.secret_data
oauth2_client_secret = data.google_secret_manager_secret_version.oauth_client_secret.secret_data
}
}Die App Engine App-Definition enthält die automatische Skalierung, die Konfiguration der Cloud SQL-Verbindung sowie einige erforderliche Umgebungsvariablen (beachten Sie, dass nur die Secret ID übergeben wird, das DB-Passwort wird nicht veröffentlicht).
⚠️ Wenn Ihr Projekt bereits eine App Engine App enthält, müssen Sie diese importieren, bevor Sie die Änderungen in terraform übernehmen, da nur eine einzige App Engine App pro Projekt erlaubt ist. Wenn Sie den Standarddienstnamen verwenden, können Sie die App nicht mit terraform destroy löschen.
resource "google_app_engine_flexible_app_version" "mlflow_default_app" {
project = var.project
service = "default"
version_id = "v1"
runtime = "custom"
deployment {
container {
image = var.docker_image
}
}
liveness_check {
path = "/"
}
readiness_check {
path = "/"
}
beta_settings = {
cloud_sql_instances = google_sql_database_instance.mlflow_cloudsql_instance.connection_name
}
env_variables = {
GCP_PROJECT = var.project
DB_PASSWORD_SECRET_NAME = google_secret_manager_secret.mlflow_db_password_secret.secret_id,
DB_USERNAME = google_sql_user.mlflow_db_user.name
DB_NAME = google_sql_database.mlflow_cloudsql_database.name
DB_INSTANCE_CONNECTION_NAME = google_sql_database_instance.mlflow_cloudsql_instance.connection_name
GCS_BACKEND = google_storage_bucket.mlflow_artifacts_bucket.url
}
automatic_scaling {
cpu_utilization {
target_utilization = 0.75
}
min_total_instances = 1
max_total_instances = 4
}
resources {
cpu = 1
memory_gb = 2
}
delete_service_on_destroy = true
noop_on_destroy = false
timeouts {
create = "20m"
}
depends_on = [
google_secret_manager_secret_iam_member.mlflow_db_password_secret_iam,
google_project_iam_member.mlflow_gae_iam
]
inbound_services = []
}CloudSQL-Instanz
Das Modul generiert ein zufälliges Passwort für die Datenbank und speichert es im Secret Manager. Standardmäßig wird die Datenbank MySQL 8.0 verwendet, kann aber in jede von MLflow unterstützte Variante geändert werden.
Die Datenbank wird von der Festplatte mit einer Option zur automatischen Größenanpassung gesichert, um die Skalierung zu bewältigen und die anfänglichen Kosten gering zu halten.
resource "random_password" "mlflow_db_password" {
length = 32
special = false
}
resource "random_id" "db_name_suffix" {
byte_length = 3
}
resource "google_sql_database_instance" "mlflow_cloudsql_instance" {
project = var.project
name = "${var.prefix}-mlflow-${var.env}-${var.region}-${random_id.db_name_suffix.hex}"
database_version = "MYSQL_8_0"
region = var.region
settings {
tier = var.machine_type
availability_type = var.availability_type
disk_size = 10
disk_autoresize = true
ip_configuration {
ipv4_enabled = true
}
maintenance_window {
day = 7
hour = 3
update_track = "stable"
}
backup_configuration {
enabled = true
binary_log_enabled = true
}
}
deletion_protection = false
}
resource "google_secret_manager_secret" "mlflow_db_password_secret" {
project = var.project
secret_id = "${var.prefix}-mlflow-db-password-${var.env}-${var.region}"
replication {
user_managed {
replicas {
location = var.region
}
}
}
}
resource "google_secret_manager_secret_version" "mlflow_db_password_secret" {
secret = google_secret_manager_secret.mlflow_db_password_secret.id
secret_data = random_password.mlflow_db_password.result
}MLflow erfordert, dass die Datenbank erstellt wird.
resource "google_sql_database" "mlflow_cloudsql_database" {
project = var.project
name = "mlflow"
instance = google_sql_database_instance.mlflow_cloudsql_instance.name
}
resource "google_sql_user" "mlflow_db_user" {
project = var.project
name = "mlflow"
instance = google_sql_database_instance.mlflow_cloudsql_instance.name
password = random_password.mlflow_db_password.result
depends_on = [google_sql_database.mlflow_cloudsql_database]
}Google Cloud-Speicher
Schließlich wird der GCS-Bucket für MLflow-Artefakte erstellt - standardmäßig verwendet er eine MULTI_REGIONAL-Klasse für höchste Verfügbarkeit. Passen Sie die Konfiguration nach Ihren Wünschen an, indem Sie z.B. die Objektversionierung aktivieren.
resource "google_storage_bucket" "mlflow_artifacts_bucket" {
name = "${var.prefix}-mlflow-${var.env}-${var.region}"
location = substr(var.region, 0, 2) == "eu" ? "EU" : "US"
storage_class = "MULTI_REGIONAL"
uniform_bucket_level_access = true
}
resource "google_storage_bucket_iam_member" "mlflow_artifacts_bucket_iam" {
depends_on = [google_app_engine_application.mlflow_app]
bucket = google_storage_bucket.mlflow_artifacts_bucket.name
role = "roles/storage.objectAdmin"
for_each = toset(["serviceAccount:${var.project}@appspot.gserviceaccount.com", "serviceAccount:service-${data.google_project.project.number}@gae-api-prod.google.com.iam.gserviceaccount.com"])
member = each.key
}Schritt 4: Bereitstellen von MLflow auf App Engine mit terraform
Stellen Sie zunächst sicher, dass Sie die folgenden APIs in Ihrem Projekt aktiviert haben: App Engine Flexible API, Cloud SQL Admin API.
Vorausgesetzt, Sie haben das Repository mit dem MLflow terraform Modul geklont (Link in der Zusammenfassung unten), führen Sie die folgenden Befehle im mlflow Verzeichnis aus. Alternativ können Sie das Modul auch in Ihr bestehendes Infrastructure-as-a-Code-Projekt integrieren.
- Vergewissern Sie sich, dass Sie Zugriff auf das Google-Zielprojekt haben (z.B. indem Sie sich mit
gcloud auth application-default loginanmelden). terraform init- Erstellen Sie die Datei
terraform.tfvars, Beispiel:
project_id="<my project>"
env="dev"
prefix="abc"
region="us-central1"
app_engine_region="us-central"
docker_image="us-central1-docker.pkg.dev/<artifact path>/mlflow:latest"
machine_type="db-f1-micro"
secret_for_oauth_client_secret="projects/<projectid>/secrets/oauth-client-secret"
secret_for_oauth_client_id="projects/<projectid>/secrets/oauth-client-id"4. ⚠️ (optional) Wenn Ihr Projekt bereits eine App Engine App enthält, müssen Sie diese mit dem folgenden Befehl importieren:terraform import google_app_engine_application.mlflow_app <my project>
5. terraform plan -out mlflow.plan
6. Verify the plan
7. terraform apply mlflow.planJe nach Einstellungen, Region usw. kann es zwischen 5 und 15 Minuten dauern, bis der gesamte Stack bereitgestellt ist.
Zugriff auf serverloses MLflow hinter Identity Aware Proxy
Nach der Bereitstellung kann der MLflow-Dienst entweder über den Browser oder über einen Backend-Dienst aufgerufen werden.
Browser
Alle Benutzerkonten (oder die gesamte Domäne) müssen über eine IAP-gesicherte Web-App-Benutzerrolle verfügen, damit sie auf MLflow zugreifen können. Beachten Sie, dass die Anwendung der Berechtigungen keine sofortige Wirkung hat und Sie wahrscheinlich einige Minuten warten müssen, bevor der Benutzer auf die MLflow-Benutzeroberfläche zugreifen kann.
Wenn Sie die bereitgestellte App Engine URL besuchen, werden Sie automatisch zur SSO-Seite für Ihr Google-Konto weitergeleitet.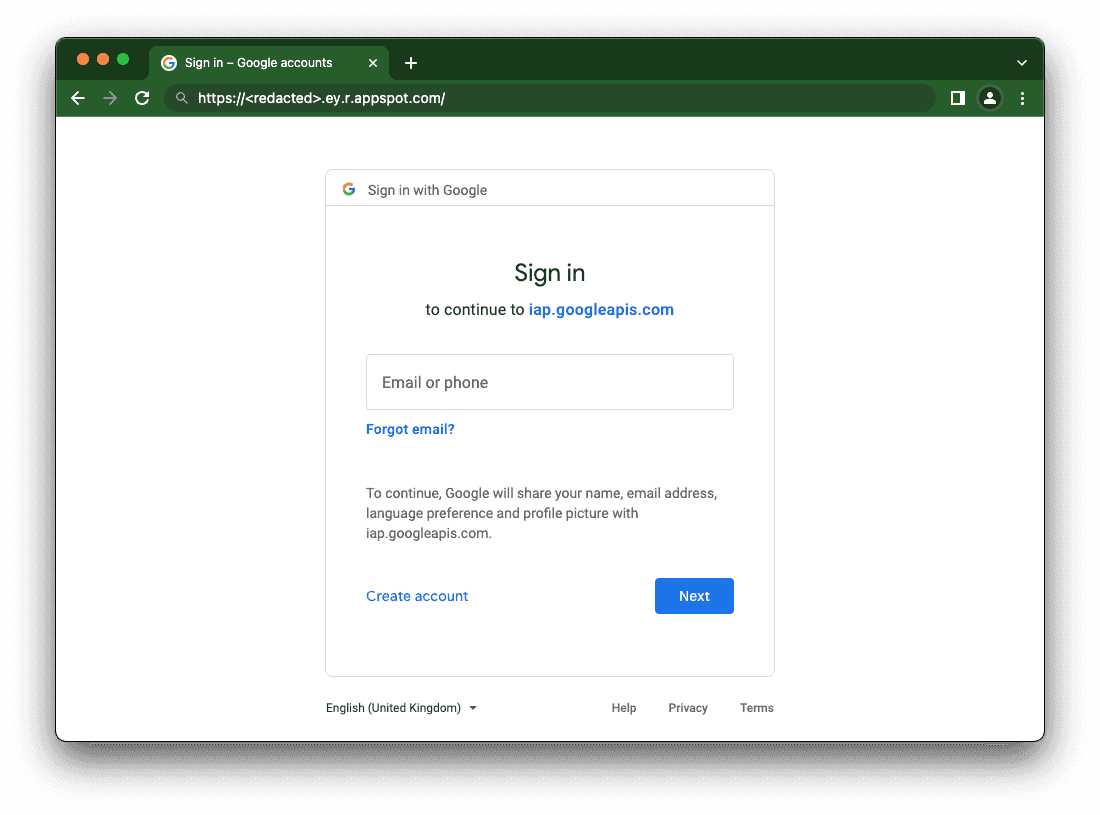
Dienst-zu-Dienst
Ob in CI/CD-Skripten oder in Python-Code, Sie können auf eine MLflow-Instanz per URL zugreifen, indem Sie den HTTP-Header Authorization hinzufügen.
Vergewissern Sie sich zunächst, dass das Dienstkonto, das Sie verwenden werden, über die folgenden Rollen verfügt:
- IAP-gesicherte Web App Benutzer
- Service Konto Token Schöpfer
Sobald die Rollen eingerichtet sind, verwenden Sie eine der folgenden Optionen:
Sie haben den json-Schlüssel für das Dienstkonto.
gcloud auth activate-service-account --key-file=./path-to/key.jsonexport TOKEN=$(gcloud auth print-identity-token --audiences="${OAUTH_CLIENT_ID}")
Sie laufen auf einer Compute Engine VM / Cloud Run / GKE / einem anderen GCP-gestützten Dienst, der nativ ein Dienstkonto verwendet
export TOKEN=$(curl -s -X POST -H "content-type: application/json" -H "Authorization: Bearer $(gcloud auth print-access-token)" -d "{\"audience\": \"${OAUTH_CLIENT_ID}\", \"includeEmail\": true }" "https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/$(gcloud auth list --filter=status:ACTIVE --format='value(account)'):generateIdToken" | jq -r '.token')Sie möchten überprüfen, ob ein bestimmtes Dienstkonto ein Token generieren kann (mit Impersonation)
export TOKEN=$(gcloud auth print-identity-token --impersonate-service-account="<service account email>" --include-email --audiences="${OAUTH_CLIENT_ID}")Sie verwenden Python, um Anfragen zu stellen
- Stellen Sie sicher, dass das Paket `google-cloud-iam` installiert ist
- Erhalten Sie den Token
from google.cloud import iam_credentials
import requests
client = iam_credentials.IAMCredentialsClient()
sa = "<Service Account Email>"
client_id = "<OAuth 2.0 Client ID>"
token = client.generate_id_token(
name=f"projects/-/serviceAccounts/{sa}",
audience=client_id,
include_email=True,
).token
result = requests.get("https://<redacted>.r.appspot.com/api/2.0/mlflow/experiments/list",
headers={"Authorization": f"Bearer {token}"})
print(result.json())Sie verwenden MLflow Python SDK
Setzen Sie die Umgebungsvariable MLFLOW_TRACKING_TOKEN auf den Token-Wert (den Sie mit einer der oben genannten Methoden erhalten haben).
Alternativ können Sie auch den obigen Python-Code wiederverwenden und das mlflow.request_header_provider-Plugin implementieren.
Zusammenfassung
Ich hoffe, diese Anleitung hat Ihnen geholfen, sichere, serverlose MLflow-Instanzen auf der Google Cloud Platform mit App Engine bereitzustellen. Viel Spaß beim Verfolgen von (serverlosen) Experimenten!
Ein besonderes Dankeschön an Mateusz Pytel für die Erstkonfiguration.
Das Repository mit dem MLflow App Engine Terraform-Modul finden Sie hier.
Wenn Sie Fragen oder Bedenken bezüglich der Bereitstellung von MLflow auf Google Cloud Platform haben, können Sie uns gerne kontaktieren.
Verfasst von
Marcin Zabłocki
Unsere Ideen
Weitere Blogs




Contact