
Intro
Berlin Buzzwords ist eine Konferenz, die sich in erster Linie auf Such-, Speicher-, Streaming- und Skalierungslösungen konzentriert, die auf Open-Source-Technologie basieren. Wie der Name schon sagt, konzentriert sie sich auch auf
Die Codesuche ist ein Information Retrieval Problem, bei dem die Abfragesprache "natürlich" ist, wie Englisch, aber das Ziel eine Computersprache ist, wie Java. Herkömmliche IR-Systeme lösen dieses Problem, indem sie nicht nach dem Code, sondern nach den den Code umgebenden Dokumentationen suchen, aber nicht jede Codebasis ist gut dokumentiert, geschweige denn gut gepflegt. Selbst wenn eine Codebasis zu 100 % dokumentiert und auf dem neuesten Stand ist, leiden diese Suchsysteme immer noch unter den üblichen IR-Krankheiten: Sie ignorieren die Wortreihenfolge, sind nicht auf Synonyme vorbereitet und lassen sich leicht durch Rauschen verwirren.
Nehmen wir also an, dass Sie die Dokumentationen der Codebasis bestenfalls als schwaches Suchsignal betrachten können. Wie finden Sie dann relevante Codeschnipsel? Nun, im Prinzip ist alles, was Sie wissen müssen, in die Struktur und Syntax des Codes selbst eingebettet. Das Problem besteht dann darin, einen Weg zu finden, den Code mit einer relevanten natürlichsprachlichen Beschreibung dessen, was dieser Code tut, zu verbinden, und zwar so, dass unsere natürlichsprachlichen Abfragen ihn finden können. DeepCS geht an dieses Problem heran, indem es gleichzeitig Einbettungen sowohl für Codeschnipsel als auch für natürlichsprachliche Beschreibungen dessen, was diese Schnipsel tun, lernt. Beide Einbettungen befinden sich im selben Vektorraum und die Abfrage reduziert sich darauf, die Vektoren der eingebetteten Codeschnipsel zu finden, die dem eingebetteten Abfragevektor am nächsten liegen.
In diesem Blog-Beitrag möchten wir ihre Idee erläutern. Wir gehen davon aus, dass Sie über Techniken zur Einbettung von Wörtern wie word2vec und grundlegende Architekturen neuronaler Netze Bescheid wissen, und wir werden uns damit beschäftigen:
- Konstruktion von natürlichsprachlichen Dokumenteneinbettungen aus Worteinbettungen;
- Einbettung von Codeschnipseln lernen;
- das Erlernen einer gemeinsamen Einbettung von Dokumenten in natürlicher Sprache und Codeschnipseln unter Verwendung einer neuronalen Netzwerkarchitektur namens CODEnn; und,
- eine Beschreibung des Trainingsaufbaus und des Abfragesystems.
Vektoren über maxpooling dokumentieren
Nehmen wir an, wir haben eine Möglichkeit, einzelne Worteinbettungen zu lernen, z.B. über word2vec. Da wir ganze Abfragen in einen einzigen Vektor umwandeln wollen, brauchen wir eine Methode, um die einzelnen Wortvektoren der Abfrage zu einem Dokumentvektor zu aggregieren. Ein Ansatz könnte darin bestehen, einfach den Durchschnitt aller einzelnen Wortvektoren im Text zu nehmen, aber es stellt sich heraus, dass dies nicht die beste Lösung ist, nicht zuletzt, weil die Reihenfolge der zugrunde liegenden Wörter ignoriert wird. Der Satz "cast int to string" bedeutet zum Beispiel etwas ganz anderes als der Satz "cast string to int".
Ein anspruchsvollerer Ansatz wäre die Verwendung eines ordnungsorientierten maschinellen Lernmodells. Diese Klasse von Modellen im Bereich des Deep Learning wird als rekurrente neuronale Netze bezeichnet. Es handelt sich dabei um
Okay, und wie verwenden wir dann diesen versteckten "Erinnerungsvektor", um unser Dokument darzustellen? Nun, ein Ansatz wäre, die Wortvektoren unserer einzelnen Wörter einfach in der gleichen Reihenfolge durch das rekurrente neuronale Netzwerk zu leiten, wie ihre Ausgangswörter im Text zu finden sind, den versteckten Vektor immer wieder zu aktualisieren und dann die endgültige Version des versteckten Vektors so zu verwenden, wie sie ist, sobald der endgültige Wortvektor durchlaufen wurde.
Doch obwohl sich dieser Vektor in gewisser Weise an alle Wörter des Textes "erinnert", hat er insbesondere bei langen Dokumenten nur eine sehr schwache Erinnerung an die ersten Wörter, d.h. nur die letzten Wörter tragen wesentlich zum Wert des Endzustands des verborgenen Vektors bei.

Alternativ könnten wir nach jeder Aktualisierung eine Kopie des versteckten Vektors erstellen und diese Kopien irgendwie kombinieren. Dies entspricht dem vorherigen Vorschlag, einfach die einzelnen Wortvektoren zu kombinieren. Durch die Verwendung der versteckten Vektoren verfügt jeder Vektor jedoch nicht nur über Informationen zu den einzelnen Wörtern, sondern auch zu den Echos der Wörter, die unmittelbar vor diesen Wörtern kommen, und, was wichtig ist, zu deren Reihenfolge.
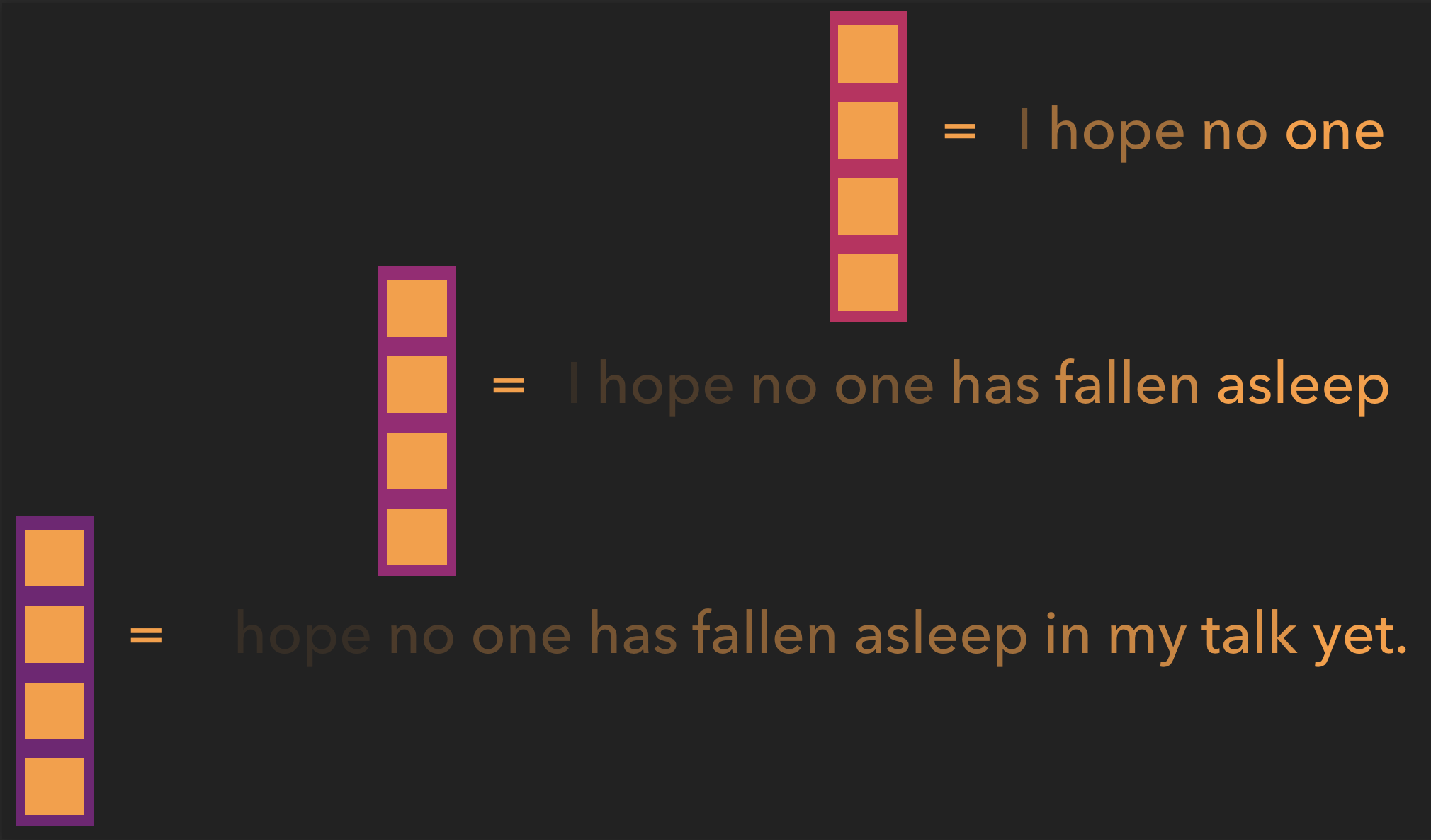
Jetzt müssen wir uns nur noch überlegen, wie wir die versteckten Vektoren kombinieren wollen. Wir könnten sie einfach mitteln, wie wir es für die Wortvektoren vorgeschlagen haben, aber die Autoren des Papiers haben etwas anderes gemacht, das sie Max-Pooling nennen: Sie machen einen neuen Vektor, der genauso groß ist wie alle unsere versteckten Vektoren, und setzen den Wert für jede Komponente gleich dem Maximum aller Werte für diese Komponente in allen versteckten Vektoren.
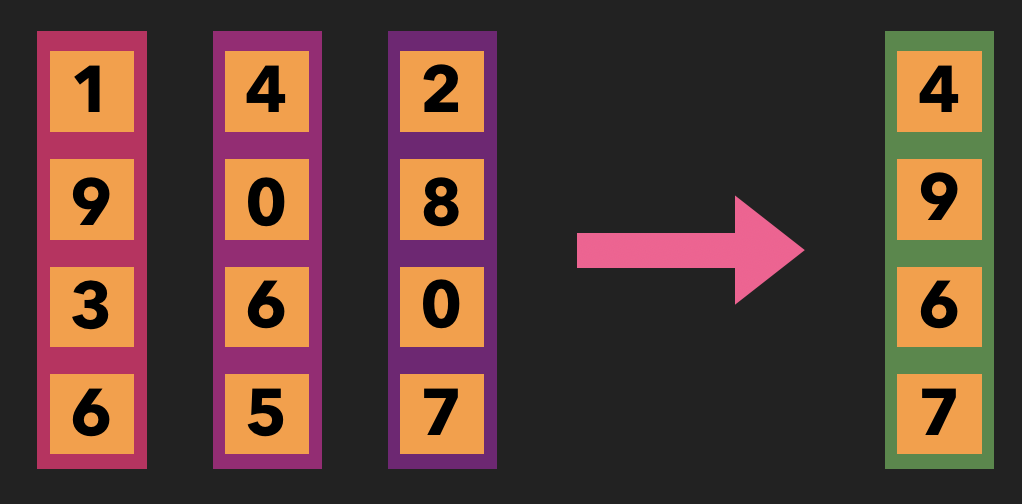
Code-Vektoren
Nachdem wir gesehen haben, wie man eine kleindimensionale Darstellung von Textdokumenten erstellen kann, möchten wir mit unserem Codeschnipsel etwas Ähnliches machen. Dabei gibt es jedoch einige Dinge zu beachten. (Dieser Beitrag bezieht sich auf Java als Beispiel, aber die Autoren des Papiers behaupten, dass die Wahl der Sprache für die Technik keine Rolle spielt).
Zunächst einmal sind die von uns verwendeten Variablen- und Klassennamen oberflächlich betrachtet selbst Text, aber anders als in den meisten natürlichen Sprachen gibt es keine implizite Anforderung, dass sich das verwendete Wort direkt auf die ausgeführte Aktion oder die Rolle des Objekts bezieht.
Andererseits sind die zugrundeliegenden API-Aufrufe und Kontrollflüsse völlig eindeutig, egal wie wir die Dinge benennen. Wenn wir beachten, dass diese Aufrufe geordnet sind und es nur eine endliche Anzahl von Möglichkeiten gibt, erkennen wir, dass wir ein Wörterbuch der API-Aufrufe erstellen und eine kleindimensionale Einbettung davon trainieren können, ähnlich wie wir es mit word2vec gemacht haben.
Dazu beginnen wir mit einer großen Sammlung von Codeschnipseln. Für jeden dieser Schnipsel generieren wir einen abstrakten Syntaxbaum und durchlaufen ihn, wobei wir eine geordnete Folge von API-Aufrufen sammeln. Zum Beispiel, für jeden Konstruktoraufruf new Foo()fügen wir an unsere Sequenz die API Foo.new, oder für jeden Methodenaufruf o.bar() wobei o ist eine Instanz der Klasse Foofügen wir den API-Aufruf an Foo.bar. Und für Schleifen und andere Steuerungslogik können wir die konstituierenden API-Aufrufe auf deterministische Weise anhängen.
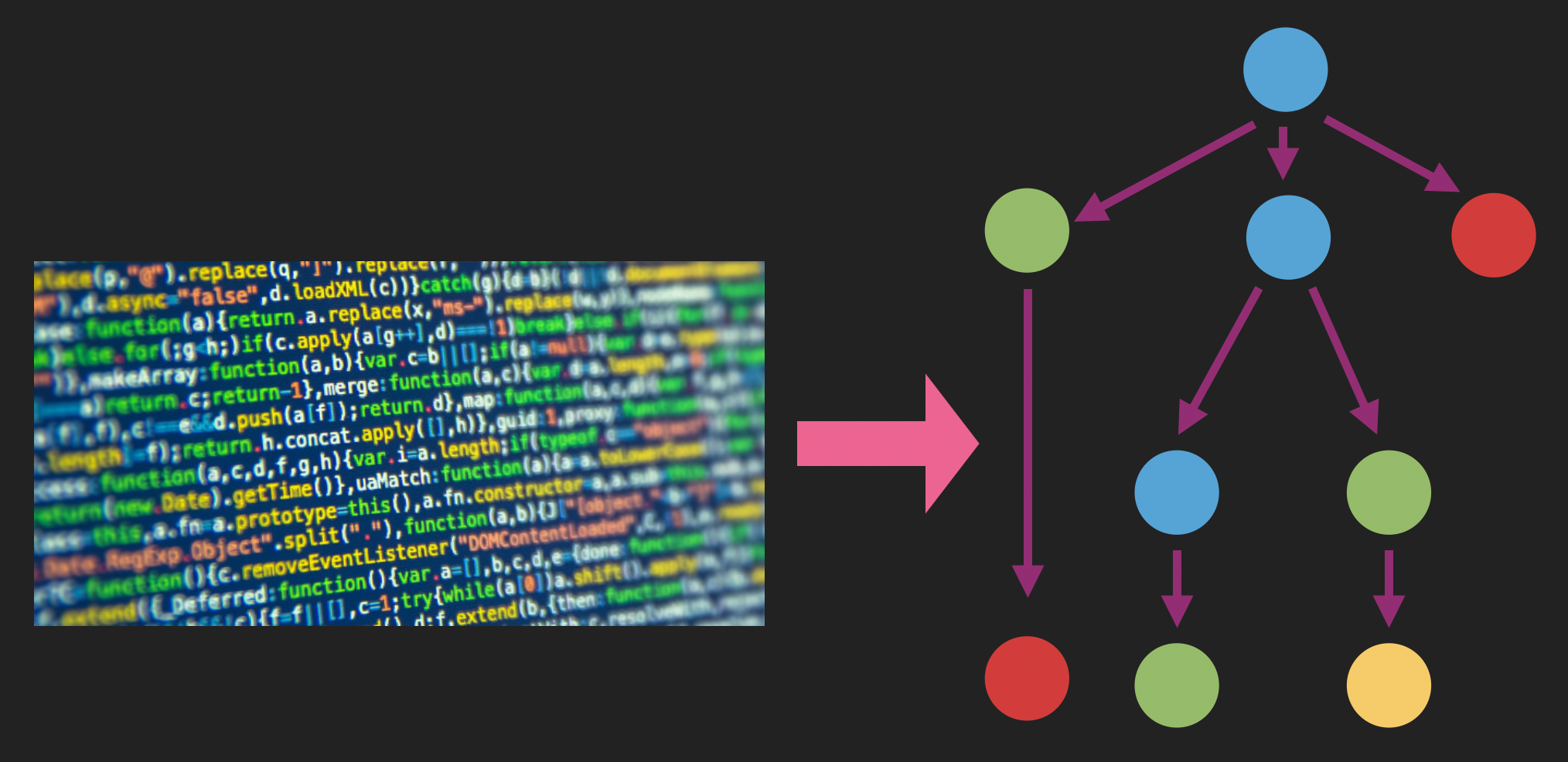
Anschließend betrachten wir alle Sequenzen aller unserer Codeschnipsel, erstellen ein Wörterbuch aller API-Aufrufe, die wir finden, und weisen jedem API-Aufruf eine One-Hot-Kodierung zu. Dann trainieren wir ein word2vec-ähnliches Modell, um für eine gegebene One-Hot-Kodierung eines API-Aufrufs in einer bestimmten Sequenz die One-Hot-Kodierung seiner benachbarten API-Aufrufe in dieser Sequenz vorherzusagen. Und genau wie im Fall des Textes führt dies zu einer kleindimensionalen Darstellung jedes API-Aufrufs.
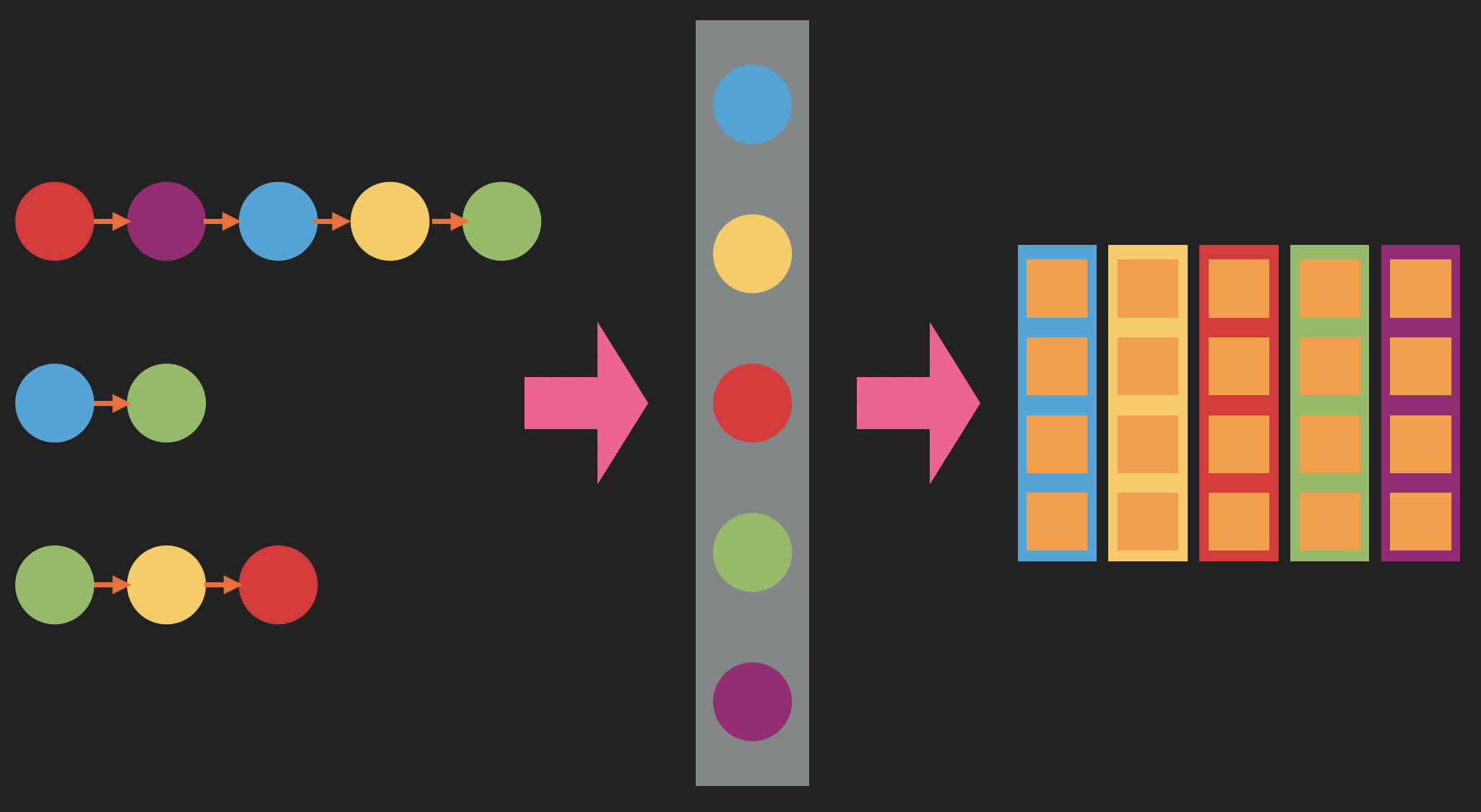
Um schließlich eine Darstellung der API-Sequenz jedes Codeschnipsels zu erhalten, lassen wir diese Vektoren der Reihe nach durch ein rekurrentes neuronales Netzwerk laufen (ein anderes als das, das wir für den Text verwenden, das aber dieselbe Architektur hat), sammeln die generierten versteckten Vektoren und aggregieren sie mittels Max-Pooling.
Natürlich gibt es eine gewisse Flexibilität bei der Reihenfolge und Auswahl der API-Aufrufe und bei der Strukturierung der Kontrolllogik. Daher reicht auch dies nicht völlig aus, um die Absicht hinter dem Code-Snippet allgemein darzustellen. Um dies zu erreichen, hat das Team hinter DeepCS die Einbettung der API-Sequenz mit den schwachen Signalen aus dem Text des Codeschnipsels kombiniert.
Zunächst erstellen wir eine Darstellung des Methodennamens. Durch die Aufteilung des Methodennamens in seine einzelnen Token haben wir Wörter und eine Wortreihenfolge. So können wir die word2vec-Techniken, mit denen wir inzwischen vertraut sind, zusammen mit einem dritten rekurrenten neuronalen Netzwerk anwenden, um einen Einbettungsvektor zu erzeugen.
Zweitens, um sicherzustellen, dass wir keine potenziellen Signale übersehen, nehmen wir den Methodenrumpf, zerlegen alle Variablen- und Methodennamen in ihre einzelnen Wörter, wenden die bekannten Bag-of-Words-Tricks an, die wir aus der Informationsbeschaffung kennen, wie z.B. Deduplizierung, Entfernung von Stoppwörtern in natürlicher Sprache und Entfernung von Stoppwörtern in Codesprachen (d.h. Entfernung aller Sprachschlüsselwörter), und betten die verbleibenden Wörter in kleindimensionale Vektoren ein. Wir leiten diese Vektoren jedoch nicht durch ein RNN, da sie im Gegensatz zu den Namenswörtern der Methode und den API-Aufrufen keine strenge Ordnung haben. Stattdessen lassen wir sie durch ein normales neuronales Netzwerk mit Vorwärtskopplung laufen und bilden aus den resultierenden Vektoren einen Maxpool.
Als konkretes Beispiel finden Sie hier ein einfaches Beispiel für eine Methode, die ein Datum in einen Kalender umwandelt (aus dem Originalbeitrag):
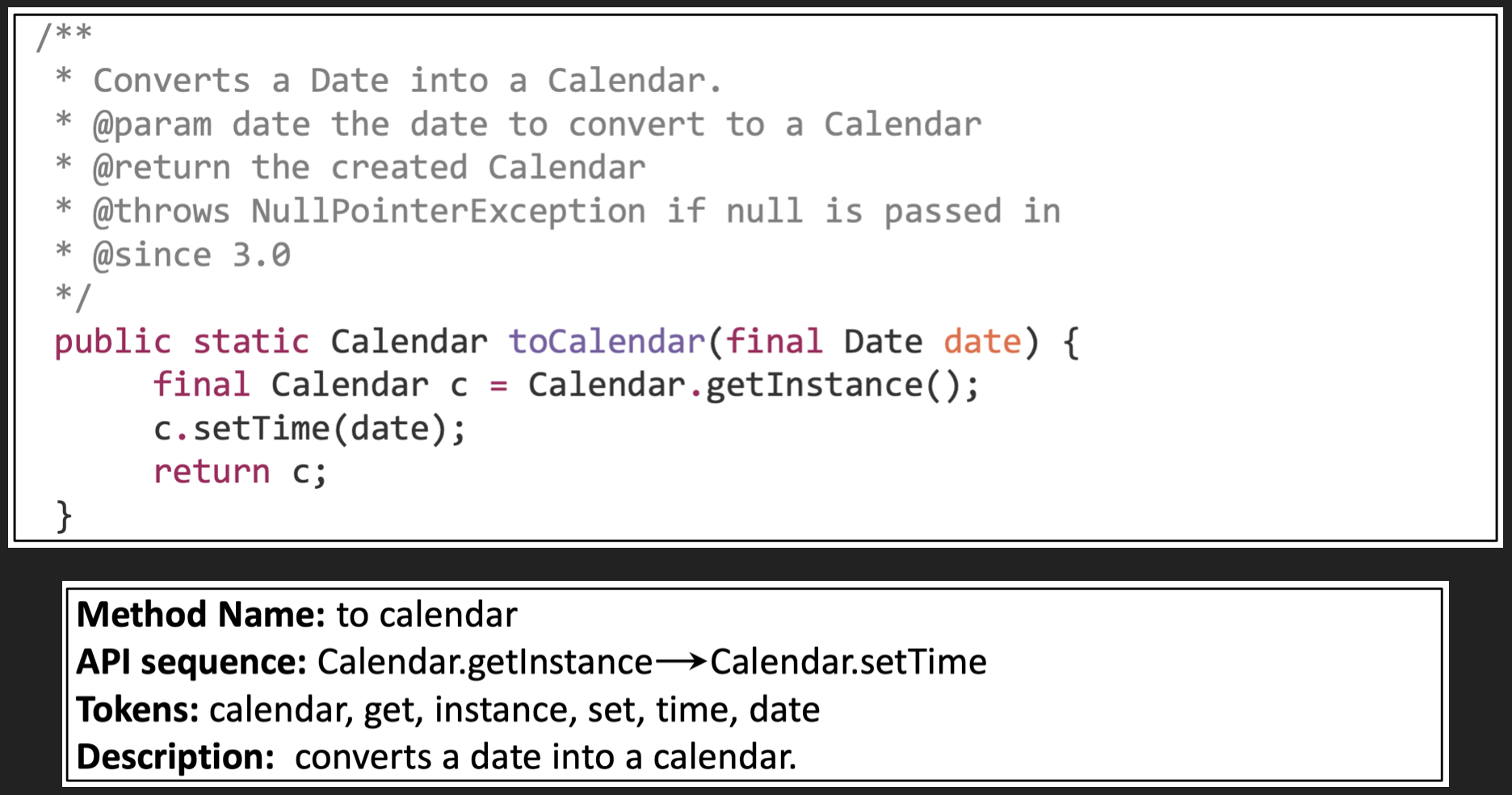
- der Name der Methode wurde in die Wörter "to" und "calendar" aufgeteilt
- die API-Sequenz
Calendar.getInstanceundCalendar.setTimewurden extrahiert - wurden die eindeutigen Token calendar, get, instance, set, time und date aus dem Body extrahiert, nachdem die Java-Schlüsselwörter
finalundreturnweggelassen wurden.
Auf diese Weise erhalten wir drei separate Vektoren, die alle Signale repräsentieren, die wir aus einer Methodendefinition herausquetschen können. Zusammen haben sie jedoch mehr Dimensionen als die Textvektoren, die wir zur Darstellung von Abfragen verwenden werden, da allein der Methodenname so viele Dimensionen hat. Da wir die beiden Vektoren miteinander vergleichen wollen, müssen sie die gleiche Länge haben. Die Vektoren, die aus der Code-Methode abgeleitet wurden, lassen sich also nicht einfach aneinanderhängen.
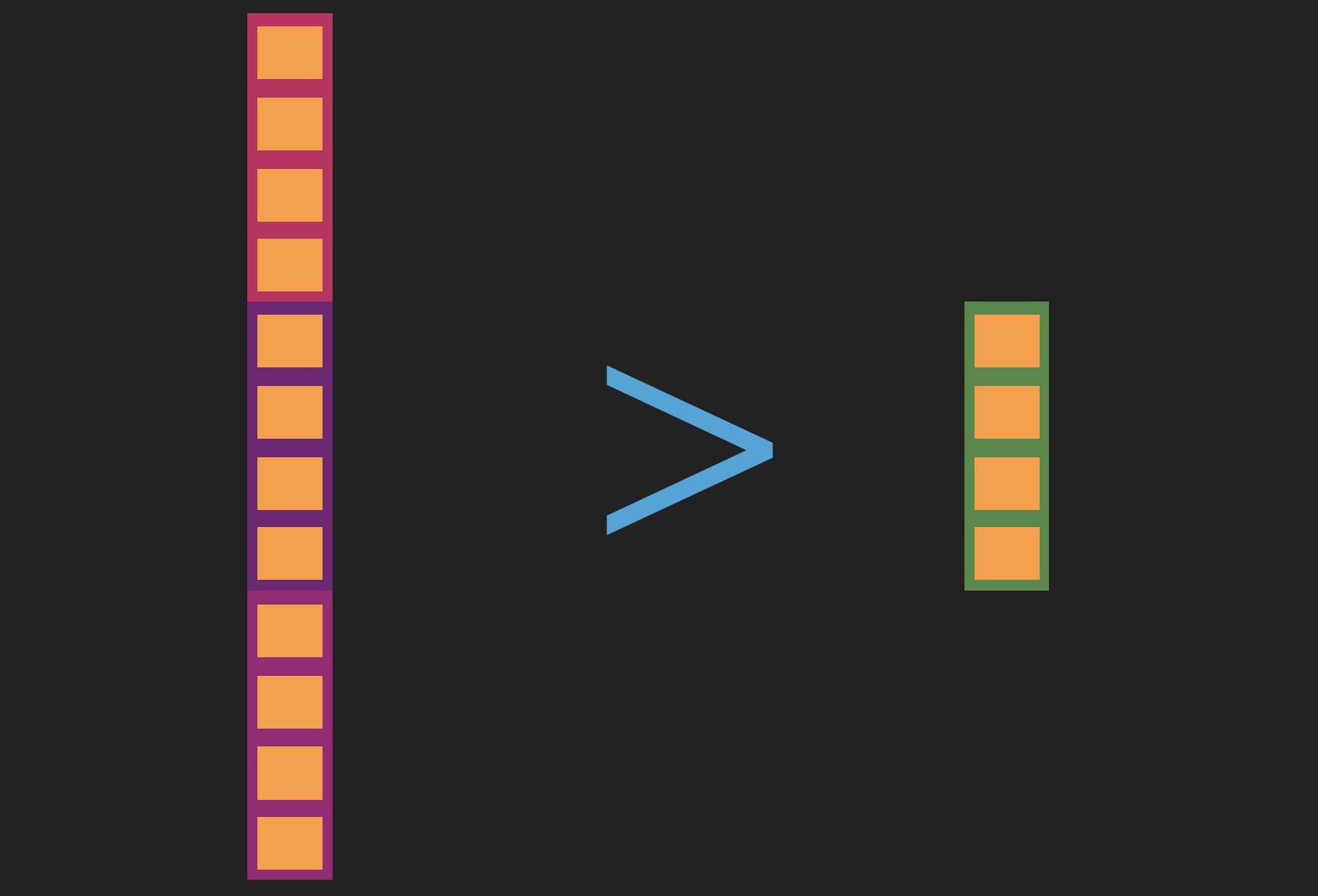
Stattdessen fügen wir in einem letzten Schritt die drei Signale zusammen und lassen sie durch ein neuronales Netzwerk mit Vorwärtskopplung laufen, dessen Ausgabeschicht die gleiche Größe wie ein Textvektor hat. Das Ergebnis ist nicht nur ein Vektor der richtigen Größe, sondern als zusätzlicher Vorteil lernt diese letzte Transformation auch, die einzelnen Signale aus dem Methodennamen, den API-Aufrufen und den Methoden-Tokens auf die erhellendste Weise zu mischen.
CODEnn
Jetzt haben wir also Methoden sowohl für die Erstellung von Vektoren aus Text als auch für die Erstellung von Vektoren aus Code. Wie können wir diese Transformationen so lernen, dass Vektoren, die einen Text darstellen, der eine Aktion beschreibt, den Vektoren, die den Code darstellen, der diese Aktion ausführt, nahe kommen oder gleich sind?
Normalerweise funktioniert das Training eines Modells für maschinelles Lernen so, dass das Modell eine Eingabe und eine Zielausgabe erhält, die es auf der Grundlage dieser Eingabe vorhersagen soll. Im Fall der Einbettung haben wir jedoch weder für das Modell zur Umwandlung natürlicher Sprache noch für das Modell zur Umwandlung von Code eine Zielausgabe. Stattdessen ist unser "Ziel", dass der Vektor für einen Text, der eine Aktion beschreibt, und der Vektor, der den Code einbettet, der diese Aktion tatsächlich ausführt, nahe beieinander liegen, wenn nicht sogar überlappen. Um dies zu erreichen, verwenden wir eine Technik, die als gemeinsame Einbettung bezeichnet wird. Anstatt die Ausgabe der natürlichen Sprache und der Codeumwandlung getrennt zu betrachten, vergleichen wir ihre Ausgabevektoren und versuchen, den Winkel zwischen ihnen zu minimieren.
Wie bei der Verwendung von negativem Sampling in word2vec zeigt sich außerdem, dass dieses Trainingsverfahren sogar noch besser funktioniert, wenn wir gleichzeitig versuchen, den Winkel zwischen dem Vektor des Codeschnipsels und dem Vektor einer Aktionsbeschreibung zu maximieren, die nichts mit der Aktion zu tun hat, die der Code ausführt.
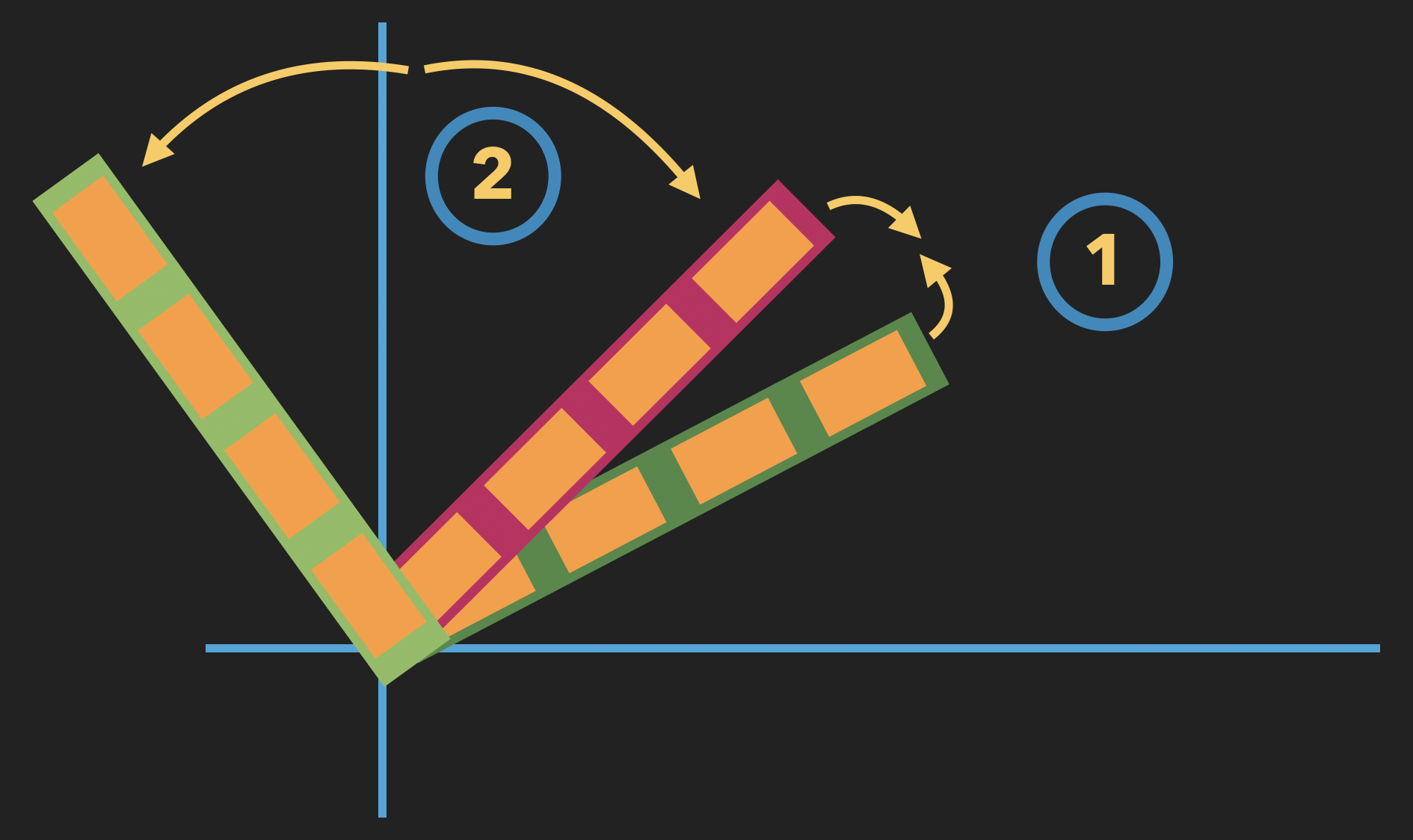
Durch die Optimierung für dieses kombinierte Ziel trainieren wir also gleichzeitig unsere beiden Einbettungen, und dieses gemeinsame Modell nennen die Autoren des Papiers das Code-Description Embedding Neural Network, oder CODEnn.
DeepCS
Um die Machbarkeit dieser Idee zu demonstrieren, hat das Team hinter CODEnn ein System für die Codesuche namens DeepCS entwickelt. Dieses System arbeitet in drei Phasen.
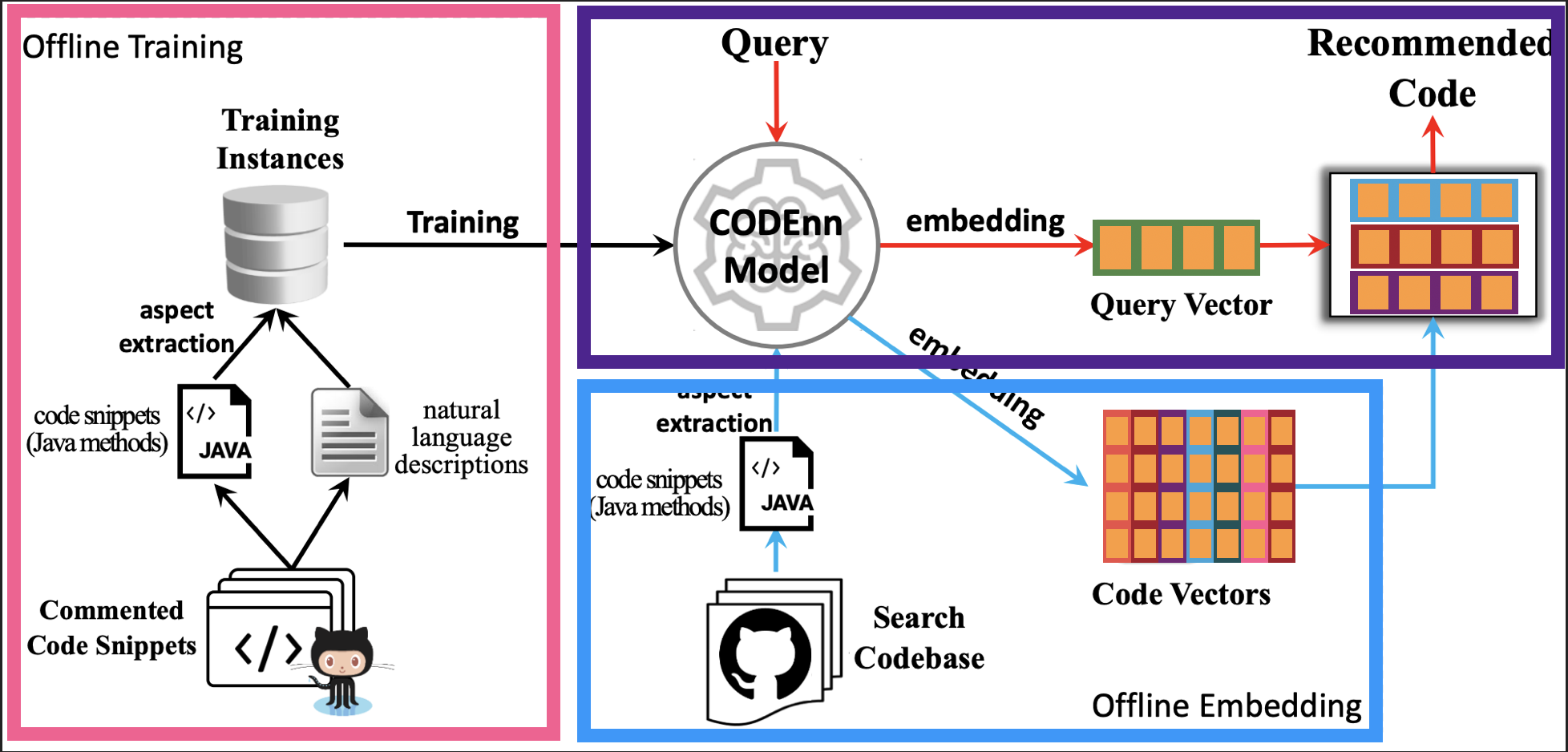
Die erste verwendet 18 Millionen Java-Methoden und die dazugehörigen Dokumentationen, die alle von GitHub stammen, um sowohl den Code als auch die natürlichen Spracheinbettungen zu trainieren. Der Code und die Dokumentationen werden dann verworfen und nur die gelernten Transformationen bleiben erhalten. Dieser Trainingsdatensatz ist absichtlich recht umfangreich, um zu gewährleisten, dass die gelernten Repräsentationen auch für noch nicht gesehene Codebasen nützlich sind, also für Ihre.
Als Nächstes werfen Sie alle Codeschnipsel aus Ihrer Codebasis ohne Dokumentationen in das System, und die zuvor erlernten Transformationen werden verwendet, um alle diese Methoden in Vektoren umzuwandeln. Auch dies geschieht nur einmal, aber Sie können sich eine Situation vorstellen, in der Code, der tagsüber angefasst wurde, nachts neu in Vektoren umgewandelt wird.
Beachten Sie auch, dass dies ein relativ billiger Vorgang ist, verglichen mit dem Training, das zum Erlernen der Transformationen erforderlich ist.
Und schließlich ist DeepCS nun bereit für die Suche. Wenn ein Benutzer des Systems ein relevantes Stück Code finden möchte, gibt er seine natürlichsprachliche Anfrage in das System ein. DeepCS wandelt die Textabfrage in einen Vektor um, führt eine Suche durch, um die K nächstgelegenen Codevektoren zu unserem natürlichsprachlichen Abfragevektor zu finden, und gibt die entsprechenden Codeschnipsel in abnehmender Reihenfolge der Nähe an den Benutzer zurück.
Outro
Als ich letztes Jahr auf der Berlin Buzzwords einen Vortrag über den Einsatz von maschinellem Lernen zur Erstellung von Datenbankindizes hielt, waren Vorträge über maschinelles Lernen rar gesät (und wenn, dann ging es oft um Learning-to-Rank), was angesichts der harten Fehlergarantien, die von Datenbanksystemen verlangt werden, nicht überrascht. In diesem Jahr schien
Möchten Sie sich mit Deep Learning vertraut machen?
Nehmen Sie an unserem dreitägigen Deep Learning-Kurs teil, in dem Sie alles darüber erfahren, wie Sie Deep Learning in Ihrem Beruf einsetzen können.
Unsere Ideen
Weitere Blogs




Contact