Blog
Deep Learning mit Azure: PyTorch verteiltes Training in Kedro richtig gemacht

Bei GetInData verwenden wir das Kedro-Framework als Kernbaustein für unsere MLOps-Lösungen, da es ML-Projekte gut strukturiert und eine großartige Abstraktion für Knoten, Pipelines, Datensätze und Konfiguration bietet. So entsteht leicht zu pflegender und kompatibler Code für die Datenverarbeitung, das Training und die Auswertung von Modellen, ohne dass die Frameworks für maschinelles Lernen, die Data Scientists verwenden können, eingeschränkt werden. Wir bieten auch Workshops für Data Scientists an, in denen sie lernen, wie sie Kedro einsetzen können, um echte Probleme zu lösen und einen Mehrwert für unsere Kunden zu schaffen. Einer der letzten Anwendungsfälle, auf den wir gestoßen sind und der von Kedro nicht sofort unterstützt wurde, war das Szenario des verteilten Trainings. Datenwissenschaftler lieben neuronale Netze, aber ihr Training in großem Maßstab erfordert in der Regel mehr Rechenleistung als auf einem einzelnen Rechner verfügbar ist. (sogar mit GPU). Größere Netzwerke wie BERT, GPT-2, ViT oder sogar Top-Varianten von EfficientNet und ResNet benötigen in Verbindung mit großen Datensätzen viel Zeit zum Trainieren, was sowohl zu unglücklichen Data Scientists als auch zu einer längeren Experimentier-Feedback-Schleife führt, was für Unternehmen entmutigend ist.
Die Kombination der Welten von neuronalen Netzen, Kedro und verteiltem Training kann eine ziemliche Herausforderung sein und erfordert eine Menge manueller Konfiguration. Das wussten wir, deshalb haben wir beschlossen, einen weiteren Beitrag zur Kedro-Community zu leisten. In diesem Blogbeitrag zeigen wir Ihnen, wie Sie PyTorch mit Kedro verwenden, um neuronale Netze zu trainieren und das Training dann dank unserer kürzlich veröffentlichten neuen Funktion für das Kedro AzureML-Plugin ganz einfach durch verteiltes Rechnen zu skalieren.
Kedro + PyTorch + Azure ML Einrichtung
Wir verwenden dasselbe Szenario wie im Schnellstart von Kedro AzureML(kedro-azureml > =0.2.2 ist hier erforderlich) mit Änderungen für das Training neuronaler Netzwerke mit PyTorch. Zu diesem Zweck haben wir PyTorch Lightning als zusätzliche Abhängigkeit zu dem Projekt hinzugefügt. Wir überspringen in diesem Blogpost die anfängliche Einrichtung, die in der Dokumentation beschrieben wird, und gehen zu den wichtigen Teilen über. Wir empfehlen Ihnen, zunächst den Schnellstart des Plugins durchzugehen.
Bitte beachten Sie, dass das Speichern des Modells und die zukünftige Produktion des trainierten Modells nicht zum Umfang dieses Blogbeitrags oder des zugehörigen Codes gehören.
Fügen Sie das PyTorch Regressionsmodell hinzu
Wir entfernen die "Candidate Modeling Pipeline" aus der Data Science Pipeline des Spaceflights Starters und ändern die Pipeline selbst, indem wir den ursprünglichen train_model Knoten durch unseren train_pytorch_model Knoten ersetzen. Neben dem Datensatz akzeptiert unser Knoten auch eine Reihe spezifischer Parameter für das neuronale Netzwerk, wie z.B. die Anzahl der Epochen, die Stapelgröße, die Lernrate und vor allem die Anzahl der Knoten, die für das verteilte Training verwendet werden sollen. Wir verwenden ein einfaches mehrschichtiges neuronales Netzwerk, das aus linearen Schichten mit Leaky ReLU-Aktivierung und Stapelnormalisierung in der Eingabeschicht besteht. Da das Spaceflights-Projekt ein Regressionsziel hat, verwenden wir Trainer von PyTorch Lightning und rufen fit auf, um das Modell zu trainieren.
def train_model_pytorch(
X_train: pd.DataFrame,
y_train: pd.Series,
num_nodes: int,
max_epochs: int,
learning_rate: float,
batch_size: int,
):
class SimpleNetwork(pl.LightningModule):
def __init__(self, n_features: int, lr: float) -> None:
super().__init__()
self.lr = lr
self.normalize = nn.BatchNorm1d(n_features)
internal_features = 1024
hidden_layer_size = 128
depth = 10
self.layers = nn.Sequential(
nn.Linear(n_features, internal_features),
nn.Sequential(
nn.Linear(internal_features, hidden_layer_size),
nn.LeakyReLU(),
*sum(
[
[
nn.Linear(hidden_layer_size, hidden_layer_size),
nn.LeakyReLU(),
]
for _ in range(depth)
],
[],
),
),
nn.Linear(hidden_layer_size, 1, bias=False),
)
def forward(self, x):
normalized = self.normalize(x)
outputs = self.layers(normalized)
return outputs.squeeze()
def training_step(self, batch, batch_idx):
x, y = batch
outputs = self.forward(x)
loss = F.smooth_l1_loss(outputs, y)
return loss
def predict_step(
self, batch: Any, batch_idx: int, dataloader_idx: int = 0
) -> Any:
return self.forward(batch[0])
def configure_optimizers(self):
return Adagrad(self.parameters(), lr=self.lr)
epochs = max_epochs
data = create_dataloader(X_train.astype("float"), y_train, batch_size=batch_size)
model = SimpleNetwork(X_train.shape[1], learning_rate)
trainer = pl.Trainer(
max_epochs=epochs,
logger=True,
callbacks=[TQDMProgressBar(refresh_rate=20)],
num_nodes=num_nodes,
)
trainer.fit(model, train_dataloaders=data)
return modelDer Spaceflights-Starter verwendet das Pandas-basierte Dataset und wir müssen es wie folgt in das PyTorch DataSet (und später DataLoader) umwandeln:
def create_dataloader(x: pd.DataFrame, y: pd.Series=None, predict=False, batch_size=256):
data = [torch.from_numpy(x.values).float()]
if y is not None:
data.append(torch.from_numpy(y.values).float())
return DataLoader(TensorDataset(*data), shuffle=not predict, batch_size=batch_size)Sobald das Modell trainiert ist, müssen wir den Bewertungscode ändern, um ein PyTorch-basiertes Modell anstelle eines Scikit-Learn-Modells zu verwenden.
def evaluate_model(model: pl.LightningModule, X_test: pd.DataFrame, y_test: pd.Series):
"""Calculates and logs the coefficient of determination.
Args:
model: Trained model.
X_test: Testing data of independent features.
y_test: Testing data for price.
"""
with torch.no_grad():
trainer = pl.Trainer()
dataloader = create_dataloader(X_test.astype("float"), predict=True)
y_pred = trainer.predict(model, dataloaders=dataloader)
y_pred = pd.Series(
index=y_test.index, data=torch.cat(y_pred).reshape(-1).numpy()
)
r2 = r2_score(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
logger = logging.getLogger(__name__)
logger.info("Model has a coefficient R^2 of %.3f on test data.", r2)
logger.info("Model has MAE of %.3f on test data.", mae)Sobald diese Änderungen vorgenommen wurden, müssen wir als Letztes die Verwendung des Knotens in der Pipeline-Definition ändern - wir müssen alle Parameter des neuronalen Netzwerks übergeben, die wir verwenden möchten. Denken Sie daran, sie auch in der Datei conf/base/parameters/data_science.ymlhinzuzufügen.
node(
func=train_model_pytorch,
inputs=[
"X_train",
"y_train",
"params:model_options.num_nodes",
"params:model_options.epochs",
"params:model_options.learning_rate",
"params:model_options.batch_size",
],
outputs="regressor",
name="train_model_node",
),
Inhalt von data_science.yml in Parametern:
data_science:
active_modelling_pipeline:
model_options:
epochs: 10
learning_rate: 1.0e-3
batch_size: 256
num_nodes: 1
test_size: 0.2
random_state: 666
features:
- engines
- passenger_capacity
- crew
- d_check_complete
- moon_clearance_complete
- iata_approved
- company_rating
- review_scores_ratingTesten des Codes
Nachdem wir die Pipeline vorbereitet haben, können wir den Code nun lokal ausführen, um die allgemeine Korrektheit der Pipeline zu testen. Für den lokalen Lauf setzen wir sowohl die Anzahl der Epochen als auch die Anzahl der Knoten auf 1.
kedro run --params data_science.active_modelling_pipeline.model_options.epochs:1 --params data_science.active_modelling_pipeline.model_options.num_nodes:1Der lokale kedro-Lauf sollte mit einem Erfolg und ähnlichen Protokollmeldungen abgeschlossen werden:
[10/21/22 16:22:53] INFO Model has a coefficient R^2 of 0.465 on test data.
INFO Model has MAE of 768.543 on test data.
INFO Completed 6 out of 6 tasks
INFO Pipeline execution completed successfully.Ausführen von Kedro Pipeline auf Azure Machine Learning Pipelines
Jetzt können wir unsere Pipeline in der Cloud testen und sie mit Hilfe unseres Open-Source-Plugins kedro-azureml auf Azure ML Pipelines starten. Bevor wir die Pipeline starten, müssen wir ein Docker-Image für sie erstellen. Dieser Prozess ist genau derselbe wie der in der Schnellstartanleitung des Plugins beschriebene - verwenden Sie einfach kedro-docker und ändern Sie dockerignore, um den Ordner data/01_raw in das Image aufzunehmen. Erstellen Sie das Image und übertragen Sie es in die Azure Container Registry (oder in eine andere Container Registry Ihrer Wahl - stellen Sie nur sicher, dass sie vom Azure ML Studio aus zugänglich ist).
Da die Anzahl der Knoten zunächst auf 1 eingestellt ist (noch kein verteiltes Training), starten wir den Auftrag in Azure ML Pipelines wie folgt:
kedro azureml run -s <your Azure subscription id>Sollten Sie bei der Einrichtung auf Probleme stoßen, können Sie jederzeit die Schritt-für-Schritt-Videoanleitung zu Rate ziehen, die wir hier vorbereitet haben.
Hinzufügen von GPU-Unterstützung und Start von verteiltem Training
Zunächst benötigen wir Cuda-Unterstützung innerhalb des Docker-Images, also verwenden wir eines der offiziellen PyTorch Lightning-Images als Basis. Denken Sie daran, dass Docker-Images, auf denen sowohl cuda als auch PyTorch vorinstalliert sind, in der Regel groß sind - das von uns verwendete war 5,9 GB groß, komprimiert und 12,0 GB unkomprimiert. Nach der Installation von Kedro und den Projektanforderungen erhöht sich die unkomprimierte Größe auf etwa 12,3 GB.
Bevor Sie das Training auf verteilte Weise durchführen können, müssen Sie in Azure ML Studio einen Compute-Cluster mit GPUs erstellen. Für ein gutes Preis-Leistungs-Verhältnis verwenden wir STANDARD_NC4AS_T4_V3-Maschinen mit T4-GPUs (1 pro Maschine). Wir empfehlen außerdem die Nutzung der Scale-to-0-Funktionen von Azure ML Compute Clusters, so dass die Maschinen nur dann laufen, wenn ein Auftrag (in diesem Fall die Kedro-Pipeline) auf ihnen geplant ist.
Sobald wir alle erforderlichen Komponenten vorbereitet haben, ist es an der Zeit, unserem Kedro PyTorch-Schulungsknoten die tatsächliche Unterstützung für verteiltes Training hinzuzufügen. Hier kommt unser Plugin ins Spiel. Mit einem einfachen Dekorator "sagen" wir dem Kedro-AzureML-Plugin, dass es verteiltes Training für diesen bestimmten Knoten verwenden soll - das ist alles, was Sie brauchen!
from kedro_azureml.distributed import distributed_job
from kedro_azureml.distributed.config import Framework
@distributed_job(Framework.PyTorch, num_nodes="params:model_options.num_nodes")
def train_model_pytorch(
X_train: pd.DataFrame,
y_train: pd.Series,
num_nodes: int,
max_epochs: int,
learning_rate: float,
batch_size: int,
):
# (...) rest of the code@distributed_job benötigt 2 Parameter - der erste ist der Name des zugrunde liegenden Frameworks (wir unterstützen alle von Azure angebotenen Optionen: PyTorch, TensorFlow und MPI), das verwendet werden soll, und der zweite ist die Anzahl der verteilten Knoten, die wir nutzen möchten. Beachten Sie, dass dieser Parameter dynamisch ist und durch eine einfache Parameterüberschreibung und die nativen Kedro-Funktionen geändert werden kann, so dass Sie nichts fest programmieren müssen!
Jetzt erstellen wir das Image (mit cuda als Basis), pushen es und starten den verteilten Auftrag.
kedro azureml run -s <your Azure subscription id> --params '{"data_science": {"active_modelling_pipeline": {"model_options":{ "num_nodes": 2}}}}'Wenn Sie die Anzahl der verteilten Knoten erhöhen/verringern möchten, können Sie hier jeden beliebigen Parameter verwenden, das liegt ganz bei Ihnen. Die Art und Weise, wie Sie auf die Parameter für den @distributed_job decorator zugreifen, ist genau dieselbe wie bei der Definition der Kedro-Pipeline.
Wenn Sie den verteilten Trainingsauftrag in Azure ML Pipelines ausführen, sollte er so aussehen wie im folgenden Screenshot.
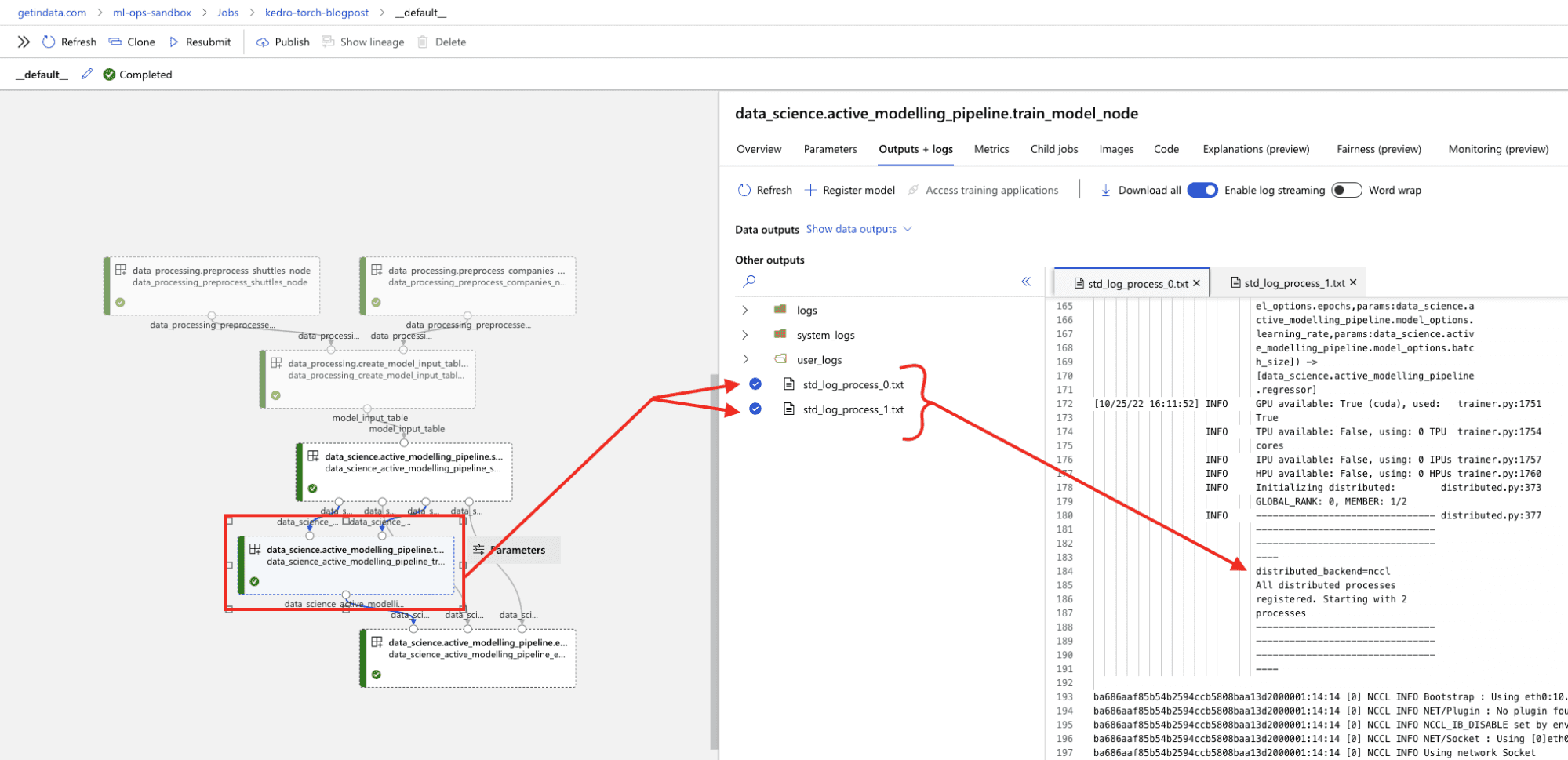 PyTorch verteiltes Training mit Kedro in Azure ML Pipelines
PyTorch verteiltes Training mit Kedro in Azure ML Pipelines
Beachten Sie, dass es innerhalb des train_model_node 2 separate Benutzerprotokolle geben wird, eines für jeden der Knoten, die Sie für das Training verwenden. Der Master-Knoten wird derjenige sein, der alle Daten speichert und den Trainingsprozess synchronisiert.
Zusammenfassung
Mit unserem Kedro-AzureML-Plugin, das mit PyTorch/TensorFlow verteilt wird, sollten Trainingsaufträge ein Kinderspiel sein. Dies nutzt auch eines der Verkaufsargumente der öffentlichen Cloud - die Fähigkeit, bei Bedarf schnell zu skalieren und keine Kosten zu verursachen, wenn die Rechenressourcen nicht mehr genutzt werden. Die Data Scientists werden sich über die relativ kurze Ausführungszeit der Pipeline freuen , und die Finanzabteilung ist erleichtert, weil die monatlichen Rechnungen niedrig gehalten werden. Probieren Sie es doch einfach selbst aus!
Das gesamte in diesem Blogpost verwendete Projekt ist als Referenz auf GitHub verfügbar:
https://github.com/getindata/example-kedro-azureml-pytorch-distributed
Wenn Sie Probleme mit unserem Plugin haben oder Funktionswünsche äußern möchten, können Sie einen Fehler auf GitHub des Kedro-AzureML-Plugins melden: https://github.com/getindata/kedro-azureml oder auf dem offiziellen Slack von Kedro.
___________
Hat Ihnen unser Beitrag gefallen? Wenn Sie mehr wissen wollen, zögern Sie nicht, unser kostenloses Ebook herunterzuladen "MLOps: Power Up Machine Learning Prozess. Einführung in Vertex AI, Snowflake und dbt Cloud".
Verfasst von
Marcin Zabłocki
Unsere Ideen
Weitere Blogs




Contact