Künstliche neuronale Netze imitieren Konzepte, die wir verwenden, wenn wir an das menschliche Gehirn denken. Mit Deep Learning können wir solche Netze unter Verwendung großer Datenmengen aufbauen, um Modelle zu erhalten, die herkömmliche Modelle übertreffen. Dieser Beitrag zeigt, wie neuronale Netze Konzepte wie Repräsentation und Speicher nutzen.
Wir verwenden Einbettungen und rekurrente neuronale Netze für die Klassifizierung der Stimmung von Filmrezensionen: Wir wollen wissen, ob sie eine positive oder negative Stimmung enthalten. Der Code für diesen Blog-Beitrag ist von diesem keras-Beispiel github.com/keras-team/keras/blob/master/examples/imdb_lstm.py inspiriert. Sehen Sie sich das Repository unseres Code-Frühstücks an, wenn Sie mit dem Code herumspielen möchten.
1 Daten
Wie viele andere Bibliotheken enthält auch keras einige Standarddatensätze, mit denen Sie herumspielen können.
Wir verwenden den IMDB-Datensatz.
Dieser Abschnitt zeigt, was dieser Datensatz enthält.
Von der Website (Hervorhebung von uns):
"Datensatz mit 25.000 Filmbewertungen von IMDB, die nach Stimmung (positiv/negativ) gekennzeichnet sind. Die Rezensionen wurden vorverarbeitet und jede Rezension ist als eine Folge von Wortindizes (ganze Zahlen) kodiert. Der Einfachheit halber werden die Wörter nach ihrer Gesamthäufigkeit im Datensatz indiziert, so dass beispielsweise die ganze Zahl "3" das dritthäufigste Wort in den Daten kodiert. Dies ermöglicht schnelle Filterungsoperationen wie z.B.: "nur die 10.000 häufigsten Wörter berücksichtigen, aber die 20 häufigsten Wörter ausschließen Als Konvention steht "0" nicht für ein bestimmtes Wort, sondern wird verwendet, um ein unbekanntes Wort zu kodieren.
Wir laden die Bewertungen nur mit den 20.000 häufigsten Wörtern:
von keras.datasets importieren imdb NUM_WORDS = 20000 (x_trainieren, y_train), (x_test, y_test) = imdb.laden_daten(num_words=NUM_WORDS)
x_train und x_test sind numpy.ndarray', die eine Liste von Sequenzen enthalten.
Nachfolgend sehen Sie zwei Beispiele: Die Beispiele haben nicht die gleiche Länge und sind durch ganze Zahlen kodiert.
> Array([ Liste([1, 14, 22, 16, ..., 2]), > Liste([1, 194, 1153, 194, ..., 95])], dtype=Objekt)
Für Maschinen mag dies eine gute Art sein, Text darzustellen, aber für Menschen ist es nicht wirklich nützlich. Der 'ursprüngliche' Text könnte etwa so aussehen:
Der schlimmste Fehler meines Lebens br br Ich habe diesen Film für 5 Euro im Supermarkt gekauft, weil ich dachte, hey, das ist Sandler, da kann ich ein paar billige Lacher bekommen ich lag völlig falsch mitten im Film alle drei meiner Freunde schliefen und ich litt immer noch schlimmste Handlung schlimmstes Drehbuch schlimmster Film, den ich je gesehen habe ich wollte meinen Kopf eine Stunde lang gegen eine Wand schlagen, dann hörte ich auf und Sie wissen warum, denn es fühlte sich verdammt gut an, mir den Kopf einzuschlagen ich habe diesen verdammten Film in das und sah es brennen und das fühlte sich besser an als alles andere, was ich je getan habe. Es brauchte American Psycho Army of Darkness und Kill Bill, um über diesen Mist hinwegzukommen. Ich hasse Sie, Sandler, dafür, dass Sie das tatsächlich durchgezogen und einen ganzen Tag meines Lebens ruiniert haben
Beachten Sie die besonderen Wörter wie
Wir müssen die Integer-Daten weiter verarbeiten: keras benötigt alle Sequenzen (oder Bewertungen) von gleicher Länge.
Wir können wählen, ob wir alle Sequenzen auf die längste Länge auffüllen, oder ob wir eine maximale Länge der Rezensionen wählen und längere Rezensionen abschneiden. Wir schneiden Rezensionen nach 80 Wörtern ab und füllen sie bei Bedarf auf:
von keras.preprocessing importieren Reihenfolge MAXLEN = 80 X_trainieren = Reihenfolge.pad_sequences(x_trainieren, maxlen=MAXLEN) X_test = Reihenfolge.pad_sequences(x_test, maxlen=MAXLEN) X_trainieren > Array([[ 15, 256, 4, ..., 19, 178, 32], > [ 125, 68, 2, ..., 16, 145, 95], > [ 645, 662, 8, ..., 7, 129, 113], > ..., > [ 529, 443, 17793, ..., 4, 3586, 2], > [ 286, 1814, 23, ..., 12, 9, 23], > [ 97, 90, 35, ..., 204, 131, 9]], dtype=int32)
Nun, da wir unsere Daten haben, lassen Sie uns die Konzepte hinter unserem Modell besprechen!
2 Modell
Unser Modell besteht aus drei Schichten: einer Einbettungsschicht, einer rekurrenten Schicht und einer dichten Schicht. Die Einbettungsschicht lernt die Beziehungen zwischen den Wörtern, die rekurrente Schicht lernt, worum es in dem Dokument geht, und die dichte Schicht übersetzt das in Stimmung.
2.1 Einbettungsebene
Die Einbettungsschicht bettet unsere ursprünglichen Wortvektoren in einen dichten, niedrigdimensionalen Raum ein. Diese Einbettung kann komplizierte Beziehungen zwischen Wörtern erfassen und das Lernen erleichtern.
Wir werden gleich sehen, was wir damit meinen. Beginnen wir zunächst mit dem traditionellen Ansatz der One-Hot-Kodierung. One-Hot-Kodierungswörter indizieren Wörter und stellen sie als große Vektoren mit Nullen und Einsen dar.
Mit der One-Hot-Codierung würde das Vokabular "(textsf{code - console - cry - cat - dog})" folgendermaßen dargestellt werden:
| hat_code | hat_Konsole | has_cry | hat_Katze | hat_Hund | |
|---|---|---|---|---|---|
| Code | 1 | 0 | 0 | 0 | 0 |
| Konsole | 0 | 1 | 0 | 0 | 0 |
| weinen | 0 | 0 | 1 | 0 | 0 |
| Katze | 0 | 0 | 0 | 1 | 0 |
| Hund | 0 | 0 | 0 | 0 | 1 |
Die drei Textausschnitte "(textsf{code console})", "(textsf{cry cat})" und "(textsf{dog})" werden durch Kombination dieser Wortvektoren dargestellt:
| hat_code | hat_Konsole | has_cry | hat_Katze | hat_Hund | |
|---|---|---|---|---|---|
| "Code-Konsole" | 1 | 1 | 0 | 0 | 0 |
| "Katze weinen" | 0 | 0 | 1 | 1 | 0 |
| "Hund" | 0 | 0 | 0 | 0 | 1 |
Diese Darstellung hat einige Probleme.
Diese Matrix wird bei einem großen Wortschatz sehr groß und auch sehr leer sein. Viele statistische Modelle haben Probleme, aus solch großen und spärlichen Daten zu lernen. Es gibt zu viele Merkmale, aus denen gelernt werden muss, und nicht genug Beispiele, um jedes Merkmal zu verstehen. Die intelligente Kombination von Wörtern könnte dieses Problem lösen.
Außerdem gehen bei der Behandlung von Wörtern als atomare Einheiten eine Menge Informationen verloren. "(textsf{cat})" ist eher mit "(textsf{dog})" als zu "(textsf{code})", und "(textsf{console})" hat eine andere Bedeutung, wenn es neben "(textsf{code})" steht, als wenn es neben "(textsf{cry})" steht. Diese komplexen Beziehungen können nicht durch unsere einfache One-Hot-Codierung dargestellt werden.
Anstatt aus einer einzigen Kodierung zu lernen, lassen wir das neuronale Netzwerk die Wörter zunächst in einen kleineren, kontinuierlichen Vektorraum einbetten, in dem ähnliche Wörter nahe beieinander liegen. Der kleinere Raum erleichtert das Lernen und eine kontinuierliche Darstellung ermöglicht das Erlernen komplexer Beziehungen.
Eine solche Einbettung für unser Vokabular könnte wie folgt aussehen:
| einbetten_0 | Einbettung_1 | |
|---|---|---|
| Code | 0 | 0.1 |
| Konsole | 0.2 | 0.1 |
| schreien | 0.5 | 0.4 |
| Katze | 0.7 | 0.6 |
| Hund | 0.8 | 0.7 |
Wir brauchen nur zwei statt fünf Dimensionen für unsere Wörter, "(mathsf{cat})" liegt nahe bei "(mathsf{dog})", und "(mathsf{console})" liegt irgendwo zwischen "(mathsf{code})" und "(mathsf{cry})". Nähe in diesem Raum bedeutet Ähnlichkeit.
Die Kodierung unserer Dokumente mit dem Durchschnitt ihrer Wortvektoren ist ebenfalls sehr sinnvoll:
| einbetten_0 | Einbettung_1 | |
|---|---|---|
| "Code-Konsole" | 0.1 | 0.1 |
| "Katze schreien" | 0.6 | 0.5 |
| "Hund" | 0.8 | 0.7 |
Das Snippet "(textsf{dog})" ist jetzt näher an "(textsf{cry cat})" als an "(textsf{code console})".
Diese Vektoren sind somit eine niedrigere Dimension, eine dichtere Darstellung unserer Wörter und sie erfassen auch semantische Informationen über Wörter und ihre Beziehungen zueinander. Bestimmte Richtungen im Vektorraum betten bestimmte semantische Beziehungen ein, wie z.B. die Beziehungen zwischen männlich und weiblich, Verb und Zeitform und Land und Hauptstadt.
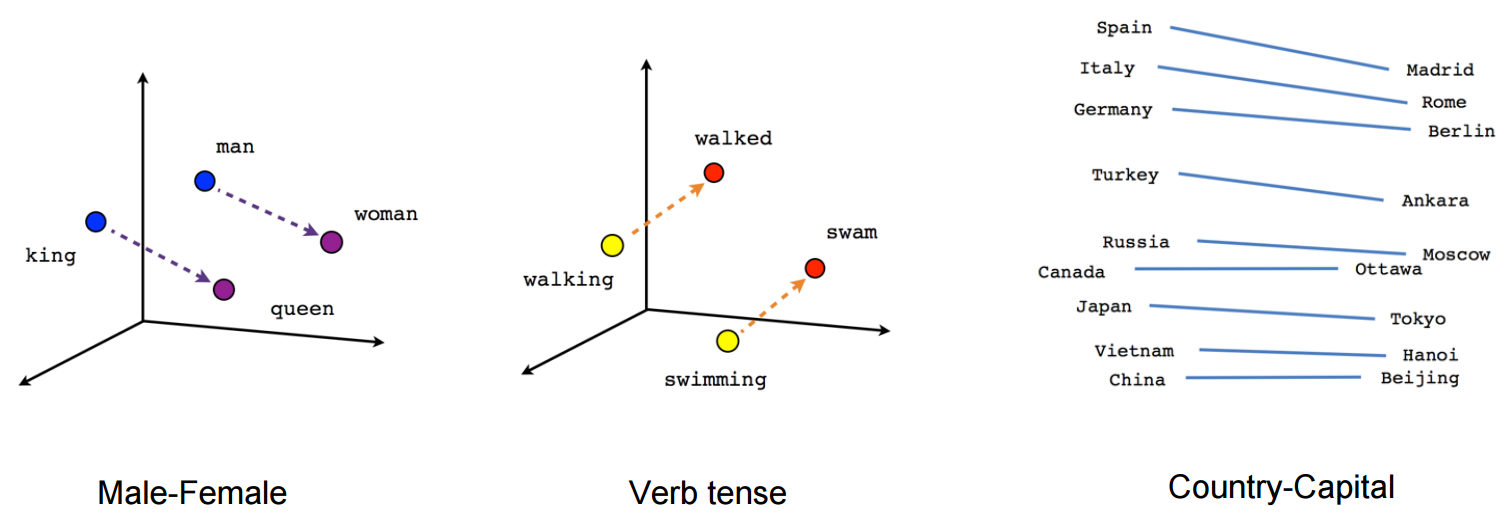
Es gibt Algorithmen, die sich auf das Lernen dieser Einbettungen spezialisiert haben, wie Word2vec und Glove, aber sie können auch einfach eine weitere Schicht in Ihrem neuronalen Netzwerk sein.
Erstellen Sie eine Einbettungsschicht in keras mit keras.layers.Embedding.
keras kann diese Schicht für Sie lernen, aber Sie können auch von anderen generierte Einbettungen vortrainieren.
2.2 Rekurrente Schicht
Wir möchten, dass unser neuronales Netzwerk den Kontext berücksichtigt. Wenn es die Rezension liest, sollte es überlegen, was die Wörter im Zusammenhang mit der bisher gesehenen Wortfolge bedeuten.
Das macht bei vielen Sequenzproblemen Sinn. Wenn Sie sich beispielsweise ein Video mit einer winzigen Hundehütte ansehen, werden Sie das seltsame Objekt im nächsten Bild eher für einen Chihuahua halten und nicht für einen Muffin.
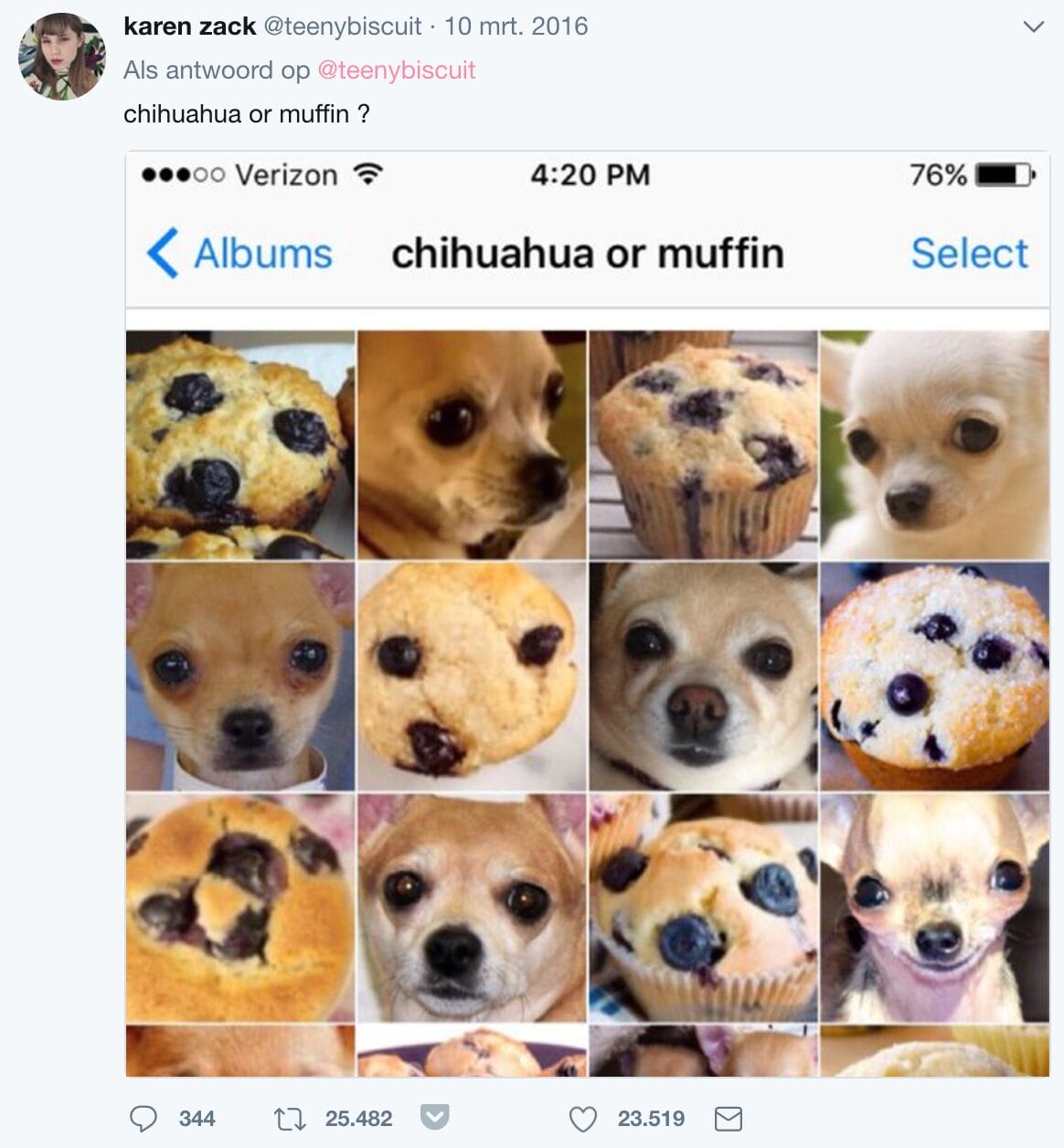
Herkömmliche Feedforward-Netzwerke lernen ihre Parameter einmal und haben einen festen Zustand, so dass sie den Kontext in Sequenzen von Eingabedaten nicht berücksichtigen können. Rekurrente neuronale Netze (RNNs) lernen ihre Parameter ebenfalls einmal, behalten aber einen Zustand bei, der von der Sequenz abhängt, die sie bisher gesehen haben. Dadurch eignen sich RNNs gut für Sequenzprobleme, wie die Umwandlung von Sprache in Text: Die Übersetzung eines Wortes kann durch die Kenntnis der Wörter, die vorher kamen, unterstützt werden.
RNNs können auf natürliche Weise mit der Wortreihenfolge umgehen, da sie eine Folge von Wörtern durchgehen und sich die bisher gesehenen Wörter merken. Die folgende Abbildung zeigt, wie sich die Stimmung beim Durchgehen eines Textes ändern kann. Ein Wort kann eine Stimmung auslösen, die sich über einen oder mehrere Sätze erstreckt.

Wenn wir daran interessiert wären, ein Dokument wie im vorherigen Beispiel zu verstehen, könnten wir die folgende Architektur verwenden:
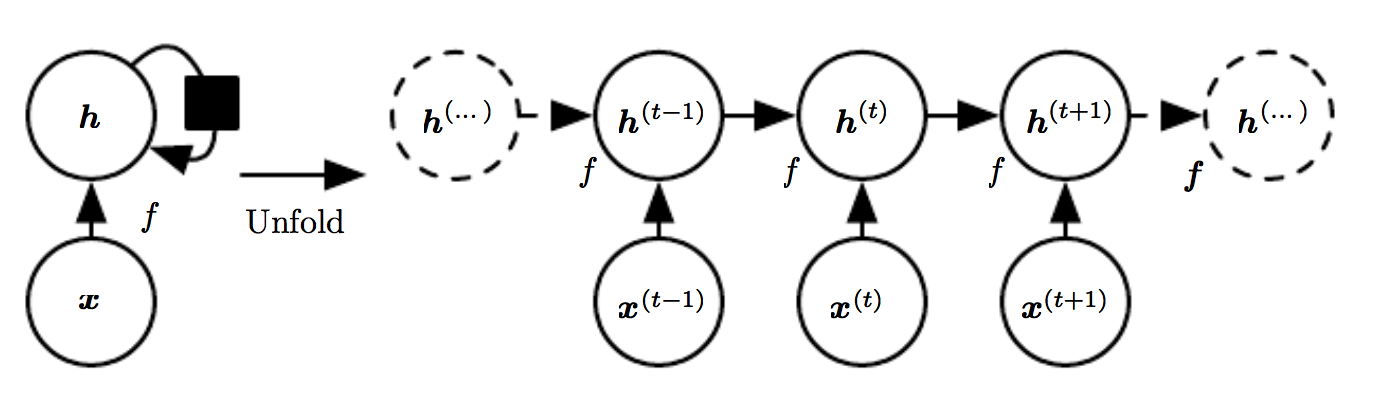
Die linke Seite der Abbildung zeigt eine Kurzfassung des neuronalen Netzwerks, die rechte Seite die entrollte Version.
In der Abbildung haben wir:
- (mathbf{x}^{(t-1)}), (mathbf{x}^{ (t)}), (mathbf{x}^{ (t+1)}): Eingangswortvektor zum Zeitpunkt (t).
- (mathbf{h}^{(t-1)}), (mathbf{h}^{ (t)}), (mathbf{h}^{ (t+1)}): Ausgabe des vorherigen Zeitschritts (t-1).
Bei jedem Zeitschritt ist die Eingabe die Ausgabe des vorherigen Zeitschritts (mathbf{h} ^{ (t-1)}) und ein neuer Eingabe-Wortvektor (mathbf{x}^{ (t)}). Im Laufe der Zeit passen wir unsere Vorstellung von dem Dokument an (mathbf{h} ^{ (t)}), bis wir alle Wörter in dem Dokument gesehen haben. Dies wird in der Abbildung unten veranschaulicht: Wir erhalten bei jedem Zeitschritt einen neuen Wortvektor und übertragen eine Bewertung.
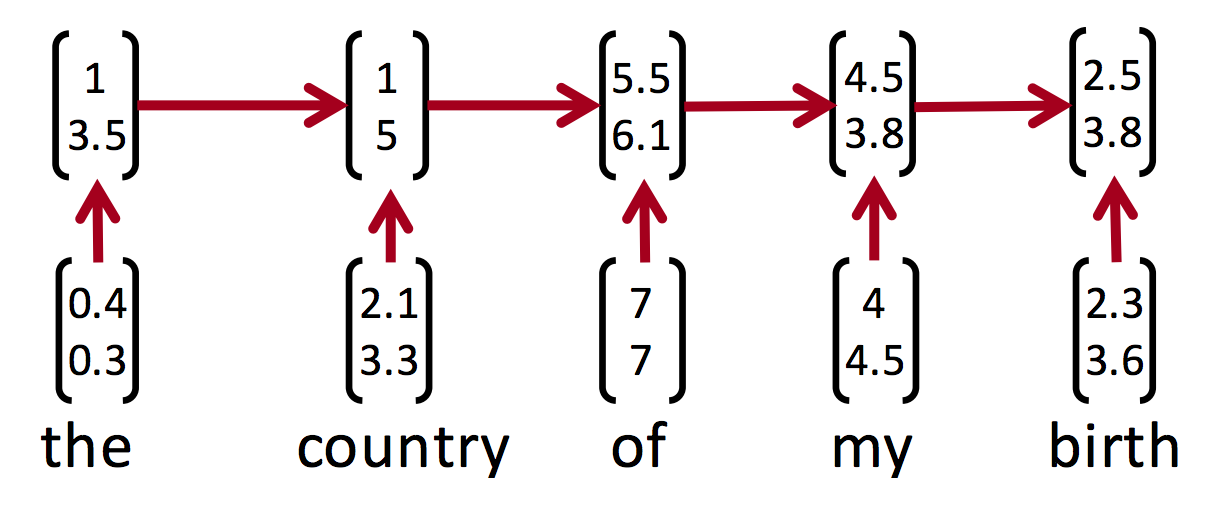
Die endgültige Punktzahl (mathbf{h} ^{ (T)}) gibt an, was das neuronale Netzwerk über das Dokument gelernt hat, nachdem es jedes Wort gesehen hat. Wir könnten die endgültigen Punktzahlen zum Beispiel verwenden, um Stimmungen zu erkennen - und genau das werden wir auch tun!
Wir verwenden eine spezielle Art von rekurrenter Schicht: ein LSTM. Die Neuronen des Long Short Term Memory sind in der Lage, langfristige Abhängigkeiten zu erlernen und schneiden oft besser ab als Standard-RNNs. Lesen Sie diesen Blog, wenn Sie weitere Informationen wünschen.
keras hat mehrere Arten von RNNs, die LSTM-Schicht finden Sie unter keras.layers.LSTM.
2.3 Dichte Schicht
Die erste Schicht lernt eine gute Repräsentation von Wörtern, die zweite lernt, Wörter zu einer einzigen Idee zu kombinieren, und die letzte Schicht wandelt diese Idee in eine Klassifizierung um.
Wir werden eine einfache dichte Schicht aus keras.layers.Dense verwenden, die die Ideenvektoren in eine 0 oder 1 umwandelt.
Die Schicht besteht aus einem einzelnen Neuron, das alle Verbindungen aufnimmt und 0 oder 1 ausgibt.
3 Ausbildung
Zeit, unser Modell zu trainieren! Das Modell ist ein einfaches sequentielles Modell, das aus drei Schichten besteht. Die Rückrufe speichern das beste Modell und stoppen das Training, wenn sich das Modell nicht mehr verbessert.
von keras.models importieren Sequentiell von keras.layers importieren Dichtes, Einbettung, LSTM von keras importieren Rückrufe # Machen Sie unser Modell. Modell = Sequentiell() Modell.hinzufügen(Einbettung(NUM_WORDS, 128)) Modell.hinzufügen(LSTM(128, Aussteiger=0.2, rekurrent_dropout=0.2)) Modell.hinzufügen(Dichtes(1, Aktivierung='sigmoid')) # Rückrufe. Kontrollpunkt = Rückrufe.ModelCheckpoint(Dateipfad='imdb_lstm.h5', Ausführlich=1, save_best_only=True) frühes_Aufhören = Rückrufe.EarlyStopping(überwachen='val_loss', min_delta=0, Geduld=2, Ausführlich=0, Modus='auto') # Kompilieren und trainieren. Modell.kompilieren(Verlust=binäre_Querentropie'., Optimierer='adam', Metriken=['Genauigkeit']) Modell.fit(X_trainieren, y_train, chargen_größe=64, Epochen=20, validierung_daten=(X_test, y_test), Rückrufe=[Kontrollpunkt, frühes_Aufhören]) Ergebnis, acc = Modell.bewerten(X_test, y_test, chargen_größe=64) drucken('Testergebnis:'., Ergebnis) drucken('Genauigkeit testen:'., acc) > Test Ergebnis: 0.44 > Test Genauigkeit: 0.82
Die endgültige Genauigkeit beträgt 82% (höher ist besser) und die binäre Kreuzentropie beträgt 0,44 (niedriger ist besser).
Taugt das etwas?
Wie ist der Ausgangswert eines traditionelleren Modells?
Holen wir unser gutes altes sklearn heraus!
von sklearn.feature_extraction.text importieren TfidfVectorizer von sklearn.linear_model importieren LogistischeRegression von sklearn.metrics importieren genauigkeit_score, log_verlust von sklearn.pipeline importieren Pipeline # Wandeln Sie die Daten in Zeichenketten aus ganzen Zahlen um, denn so wird die # CountVectorizer gefällt das. X_train_s = [' '.beitreten(Karte(str, Zeile)) für Zeile in X_trainieren] X_test_s = [' '.beitreten(Karte(str, Zeile)) für Zeile in X_test] # Wir werden einfach die Standardwerte verwenden. Pipeline = Pipeline([('Zähler', TfidfVectorizer()), ('Klassifikator', LogistischeRegression())]) Pipeline.fit(X_train_s, y_train) y_sklearn = Pipeline.vorhersagen(X_test_s) y_proba_sklearn = Pipeline.vorhersagen_proba(X_test_s) drucken('Testergebnis:'., log_verlust(y_test, y_proba_sklearn)) drucken('Genauigkeit testen:'., genauigkeit_score(y_test, y_sklearn)) > Test Ergebnis: 0.38 > Test Genauigkeit: 0.84
Die Punktzahl und die Genauigkeit unseres einfachen Modells sind in etwa die gleichen wie die unseres neuronalen Netzes!
Neuronale Netze sollten die Zukunft seinâ¢, warum übertrifft es nicht unsere Basislinie? Der Datensatz ist nicht groß genug, um komplexe Beziehungen zu lernen. Basierend auf den Informationen, die das neuronale Netz hat, können seine Verallgemeinerungen nicht besser sein als unser einfaches Modell. Es braucht mehr Bewertungen (und vielleicht eine andere Architektur), um die Basislinie zu schlagen!
4 Schlussfolgerung
In diesem Blogbeitrag wurden einige grundlegende NLP-Konzepte erläutert und auf einen einfachen Datensatz angewendet.
Sind Sie an einer allgemeinen und umfassenden Einführung in Deep Learning interessiert? Schauen Sie sich unseren dreitägigen Deep Learning-Kurs an!
Schauen Sie sich diesen Stanford-Kurs an, wenn Sie lernen möchten, wie man Deep Learning für die Verarbeitung natürlicher Sprache einsetzt.
Verfasst von
Henk Griffioen
Unsere Ideen
Weitere Blogs




Contact