Blog
Zerlegungsstrategien für RAG: Einblicke in die richtige Aufnahme von Tabellen

Einführung
Konvertieren Sie eine Reihe von PDF-Dateien in einfachen Text. Zerlegen Sie den großen String in kleinere Blöcke. Laden Sie Ihre (jetzt) Dokumente in eine Vektordatenbank; sehen Sie sich das an - eine Wissensdatenbank! Lassen Sie nun jede Benutzereingabe direkt in die Abfrage dieser Vektordatenbank einfließen, und überlegen Sie nicht lange: packen Sie die 5 ähnlichsten Dokumente in eine Zeichenkette, verknüpfen Sie ein paar Anweisungen, nennen Sie es eine Eingabeaufforderung, füttern Sie damit einen LLM und voilà: wir haben RAG! Ziemlich cool, oder? Nun, wenn Sie sich hoffentlich über meinen herablassenden Ton geärgert haben, dann haben Sie sicher gemerkt, dass das ein großes Nein ist oder höchstens nicht ganz.
Nun, Abrufen ist großartig, aber das Abrufen von Qualitätsinhalten ist das, was nötig ist, damit RAG wirklich funktioniert! Und dafür müssen wir die Bedeutung von Ingestion ernster nehmen, fast wörtlich. Vor allem bei komplexen Formaten wie Tabellen oder Multimediaformaten müssen wir das, was hereinkommt, kauen und zerlegen, damit wir alles, was es zu bieten hat, aufnehmen können. In diesem Blog möchte ich diesen Kauvorgang in Bezug auf Tabellen untersuchen - als tabellarisch strukturiertes Wissen, nicht zu verwechseln mit tabellarischen Daten - oder, anders gesagt, ich werde Einblicke geben, wie man Wissen in Form von Tabellen richtig aufnimmt, indem man die Stärken von Sprachmodellen nutzt und so das Retrieval verbessert.
Semantische Engpässe im Rohformat
Unser Must-Have in Wissensdatenbanken, PDF, steht für Portable Document Format. Die Portabilität stellt sicher, dass ein Dokument auf allen Plattformen und Geräten genau gleich angezeigt werden kann. Eine solche visuelle Treue geht jedoch auf Kosten dessen, was die Grundvoraussetzung dafür wäre, dass Computer Text richtig verarbeiten und interpretieren können: die Semantik. Textfragmente werden zu visuellen Elementen, und aus Optimierungsgründen (in Ermangelung eines besseren Wortes) können diese Elemente in der Datei anders angeordnet sein als die Gesamtsemantik, d. h. der natürliche Textfluss, wie er zum Zeitpunkt der Erstellung beabsichtigt war.
So weit ist es für das menschliche Auge optimal. Das Problem entsteht, wenn der Computer versucht, die Datei zu lesen. Das Parsen dieser Datei und die Umwandlung des Flusses der visuellen Elemente in reinen Text kann zu verwickelten Textfragmenten führen, die nicht zusammengehören. Sehen Sie sich dieses Spielzeugbeispiel an:

|
|
|
| Ausgabe (zeilenweise): | Ausgabe (spaltenweise): | |
ab c def gh j klmn |
a g k b d h l e m c f j n |
Unterschiedliche Ausgaben zwischen PDF-Readern beim Durchlaufen desselben PDF-Dokuments.
Wir können sehen, wie verschiedene Leser dieselbe PDF-Struktur auf ihre eigene Art und Weise durchqueren und versuchen, inmitten von unscheinbaren visuellen Elementen eine gewisse Semantik zu finden. pypdf folgt offensichtlich dem zeilenweisen PDF-Stream (beachten Sie, wie a, b, c, ... erscheinen nacheinander), während pdftotext eine andere Richtung einschlägt. Ein weiteres Beispiel für den gleichen semantischen Verlust ist ein in PDF exportiertes Dokument mit Spaltenlayout, das geparst wird: Auf die erste Zeile der ersten Spalte kann die erste Zeile der zweiten Spalte folgen, und erst dann die zweite Zeile der ersten Spalte usw., anders als es das menschliche Auge sehen würde.
Dies ist natürlich eine vereinfachte Darstellung, die für den Rahmen dieses Blogs ausreicht. Die Quintessenz ist jedoch, dass es PDF-Dateien an Semantik mangelt, je komplexer das Layout wird. Und wir müssen die Semantik beibehalten, so dass wir ein Hindernis weniger haben, um unsere Chunks sinnvoll zu gestalten.
Chunking und die nicht enden wollende Debatte
Nach Seiten, Kapiteln, Absätzen, Sätzen, Zeichenlängen, nutzlosen, rekursiv definierten Zeichenfenstern: Wie lässt sich eine Wissensdatenbank am besten in Brocken organisieren? Lassen Sie mich versuchen, diese Frage mit weiteren Fragen zu beantworten: Ist das die richtige Perspektive? Muss es überhaupt eine geschlossene Formel geben? Wenn ja, sind wir bereit zu akzeptieren, wie sehr dies die informative Qualität der Chunks beeinträchtigt? Bevor ich vom eigentlichen Thema abschweife, möchte ich meine Argumentation auf einige Prämissen über den idealen Chunk stützen:
- Muss eine möglichst vollständige und unabhängige Wissenseinheit sein
- Wenn sie nicht informativ unabhängig sind, können Links zu ergänzenden Teilen Abhilfe schaffen.
- Die Komplexität des Wissens variiert, vor allem zwischen den verschiedenen Wissensdomänen, und so muss auch die jeweilige Chunk-Größe variieren.
Solche Prämissen verleihen RAG-Systemen Robustheit, da sie die semantische Überschneidung zwischen Abfrage und Chunks maximieren. Auch die Suchpräzision verbessert sich, da die Wissenseinheiten nicht mehr auf mehrere Chunks verteilt werden.
Wenn wir selbst Tabellen lesen, kann die Interpretation des zugrunde liegenden Wissens je nach Komplexität selbst für uns Menschen eine Herausforderung sein. Vielleicht machen wir uns sogar einige Notizen, die hilfreich sein können, wenn wir eine Tabelle in der Zukunft erneut lesen. Diese Art des organischen Denkens ist der Schlüssel zur Zerlegung von Tabellen in interpretierbare Teile des beschreibenden Wissens, insbesondere wenn wir die generativen und interpretativen Fähigkeiten von Sprachmodellen nutzen können.
Engpass ist eigentlich eine Frage der Perspektive
Bisher haben wir unseren Engpass als das Fehlen von Semantik im PDF-Rohdatenstrom aus Gründen der visuellen Wiedergabetreue bezeichnet, die für die visuelle Interpretation durch den Menschen geeignet ist. Glücklicherweise erlaubt uns die heutige Zeit, genau diese Perspektive zu nutzen: Was wäre, wenn wir einen visuellen Ansatz für das Parsen von Tabellen wählen würden? Mit multimodalen Modellen können wir nicht nur ein feines Prompt-Engineering durchführen, sondern auch die fertig gerenderte Tabelle als Bild in die Eingabe einspeisen - schließlich ist das die Stärke von PDF, nicht wahr? Darüber hinaus lässt sich die Tabelle problemlos in digitalisierte Dokumente, HTML oder jedes andere Format übertragen, das in einen Rendering-Prozess eingebunden ist.
Diese Idee ist allerdings nicht so neu. RAG-Enthusiasten nutzen bereits seit langem visionsgesteuerte Ansätze für die Erfassung von Tabellen auf vielen Ebenen der Komplexität (und Kreativität). Um den Rahmen nicht zu sprengen, beschränken wir uns auf solche, die multimodale Modelle beinhalten. Ob über eine unstrukturierte Bibliothek, Bildkodierung oder sogar die ausgefallenste Eingabeaufforderung, die eine genaue Darstellung der Tabelle (in Markdown, JSON, TeX, Sie haben die Wahl) bei der Ausgabe garantiert, sie alle haben einen gemeinsamen Nenner: Reverse Engineering. Das Parsing ist zu buchstabengetreu und ruft immer ein strukturiertes Format ab oder fragt höchstens nach einer zusätzlichen beschreibenden Zusammenfassung der Tabelle. Nun, Reverse Engineering kann mit LLMs ziemlich gut funktionieren, da sie strukturierte Formate sehr gut verstehen. Ein kleines Detail ist jedoch, dass es auf eine ordnungsgemäße Abfrage ankommt, damit ein solcher Inhalt überhaupt zur Eingabeaufforderung gelangt. Und genau da brauchen wir mehr Robustheit.
Stattdessen möchte ich das Parsing hier weniger wörtlich nehmen, indem ich einfach eine andere Richtung in der Souffleurtechnik einschlage. Nennen wir es eine Dekomposition, im Sinne einer Zerlegung des Abstrakten in (konkrete) Bausteine. Das Grundprinzip mag für die meisten Tabellen gelten, aber betrachten Sie doch einmal die folgende Tabelle, nur damit ich meinen Standpunkt darlegen kann:
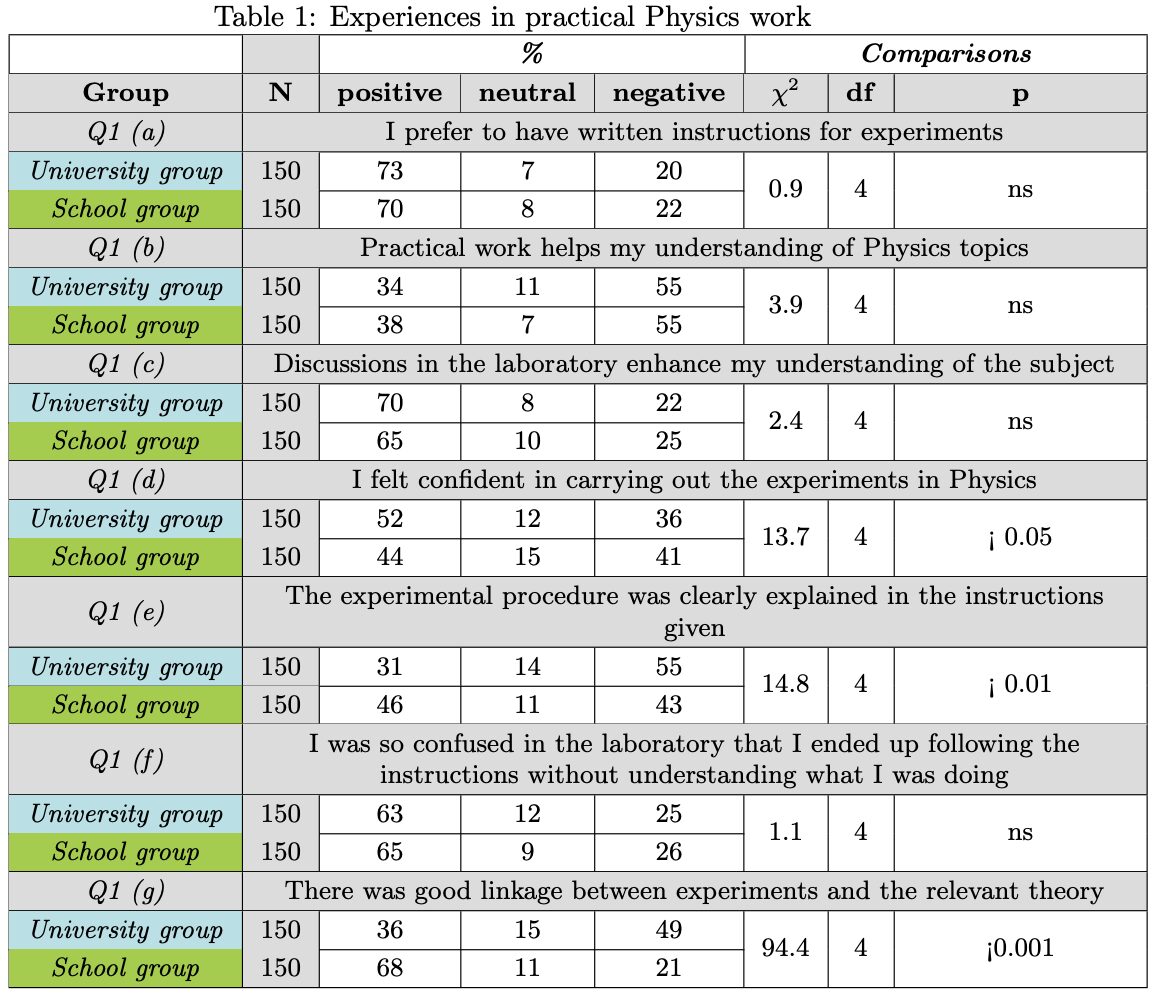
Beispiel einer komplexen Tabelle für die Aufnahme. Extrahiert von StackExchange.
Es ist vernünftig zu sagen, dass das Wissen aus den Tabellen im Wesentlichen in den Werten steckt, nicht in den Kopfzeilen oder Titeln. Kopfzeilen und Titel geben dem Wissen nur ein Format, während die Werte das Wissen sind. Was wäre also, wenn wir berücksichtigen, was wir oben in Bezug auf den idealen Chunk festgestellt haben, und ein multimodales Modell bitten, jede Zelle mit Werten zu interpretieren und dabei deren Kopfzeilen und Titel zu berücksichtigen? Mit anderen Worten: Geben Sie sowohl die obige Tabelle als auch die folgende Aufforderung in ein multimodales Modell ein:
Explain every cell of the table above in a bullet-point list. Each element of the list should be a complete and independent piece of information, describing what that value (text or number) is about, considering its headers. Continue this list redundantly for every cell in this list. Do not explain cells of headers. Consider only the values. Do not include math operations in this list, but only descriptive observations about table values. The list must contain only explanations of the technical details of the table from cell values. Complementary information that explains how to read the table must be in a separate paragraph.
Keine Raketenwissenschaft, oder? Ganz im Gegenteil, es klingt sogar ein bisschen überflüssig und repetitiv. Es handelt sich im Grunde um eine Art und Weise, jede Wertzelle der Tabelle zu interpretieren und in einen Satz umzuwandeln, alle Überschriften zusammenzukleben und das endgültige Wissen in einen Satz zu formen, wie wir sehen können, wurde als Ausgabe bereitgestellt:
* 150 is the number of students in the University group that answered question Q1 (a).
* 73% of the students in the University group answered positively to question Q1 (a).
* 7% of the students in the University group answered neutrally to question Q1 (a).
* 20% of the students in the University group answered negatively to question Q1 (a).
* 150 is the number of students in the School group that answered question Q1 (a).
* 70% of the students in the School group answered positively to question Q1 (a).
* 8% of the students in the School group answered neutrally to question Q1 (a).
* 22% of the students in the School group answered negatively to question Q1 (a).
* 0.9 is the chi-squared value for the comparison between the University group and the School group for question Q1 (a).
* 4 is the degrees of freedom for the comparison between the University group and the School group for question Q1 (a).
* ns means that the difference between the University group and the School group for question Q1 (a) is not statistically significant.
* 150 is the number of students in the University group that answered question Q1 (b).
* 34% of the students in the University group answered positively to question Q1 (b).
[...]
* 15% of the students in the School group answered neutrally to question Q1 (d).
* 41% of the students in the School group answered negatively to question Q1 (d).
* 13.7 is the chi-squared value for the comparison between the University group and the School group for question Q1 (d).
* 4 is the degrees of freedom for the comparison between the University group and the School group for question Q1 (d).
* ¡ 0.05 means that the difference between the University group and the School group for question Q1 (d) is statistically significant at the 0.05 level.
[...]
* 150 is the number of students in the University group that answered question Q1 (g).
* 36% of the students in the University group answered positively to question Q1 (g).
* 15% of the students in the University group answered neutrally to question Q1 (g).
* 49% of the students in the University group answered negatively to question Q1 (g).
* 150 is the number of students in the School group that answered question Q1 (g).
* 68% of the students in the School group answered positively to question Q1 (g).
* 11% of the students in the School group answered neutrally to question Q1 (g).
* 21% of the students in the School group answered negatively to question Q1 (g).
* 94.4 is the chi-squared value for the comparison between the University group and the School group for question Q1 (g).
* 4 is the degrees of freedom for the comparison between the University group and the School group for question Q1 (g).
* ¡0.001 means that the difference between the University group and the School group for question Q1 (g) is statistically significant at the 0.001 level.
The table presents the results of a survey of 300 students (150 from a University and 150 from a School) about their experiences in practical Physics work. The table is divided into seven sections, one for each question (Q1 (a) to Q1 (g)). Each section shows the percentage of students who answered positively, neutrally, or negatively to the question. The table also shows the results of a chi-squared test of independence, which was used to determine whether there was a statistically significant difference between the responses of the University group and the School group for each question.
Generiert mit multimodal gemini-1.5-pro-001 mit temperature=0
Beachten Sie, dass jedes Listenelement die volle Bedeutung hinter jeder Zahl/jedem Wert der Tabelle aus der Perspektive ihrer Überschriften vermittelt. Auch zusammengefasste Zellen wurden berücksichtigt, so dass wir die sinnvolle Interpretation von Prozentsätzen sehen können, oder welche Zahlen mit welcher Frage zusammenhängen. Selbst uns Menschen würde es schwer fallen, allgemeine Regeln zu formulieren, die für mehrere Layouts gelten. Ganz zu schweigen davon, dass das Programm den statistischen Jargon aus der Minimalnotation herauslesen kann und Begriffe wie Freiheitsgrade, Chi-Quadrat und statistische Signifikanz hervorbringt.
Okay, sieht gut aus. Aber inwiefern ist das besser?
Da es kein Benchmarking für die Zerlegung von Tabellen gibt, möchte ich hier eine einfache Ad-hoc-Analyse vorschlagen, damit wir die Ansätze in Zahlen vergleichen können. Betrachten Sie die folgenden Fragen, die jemand stellen könnte, der sich nur minimal für die obige Tabelle interessiert:
- Gibt es eine statistische Signifikanz zwischen den Gruppen bei Frage Q1(g)?
- Wie groß ist der prozentuale Unterschied zwischen Universitäts- und Schulgruppen in einer einzelnen Antwortkategorie?
- Bei welcher Frage gab es den größten statistisch signifikanten Unterschied zwischen den Gruppen?
- Wie viele Freiheitsgrade wurden für alle Chi-Quadrat-Tests verwendet?
- Bei welcher Frage gab es keinen statistisch signifikanten Unterschied zwischen den Gruppen?
Vergleichen wir nun in Bezug auf die Ähnlichkeit der Einbettung, wie sich diese Fragen mit Chunks aus den drei Ansätzen überschneiden, die wir nach dem Einlesen unserer Beispieltabelle gesehen haben: Dekomposition, Reverse Engineering und Rohparsing (mit pypdf). Um jegliche Verzerrung durch die Trainingsdaten des Anbieters zu vermeiden, insbesondere im Fall der Dekomposition, wurden hier Einbettungen von OpenAI (text-embedding-3-large) berücksichtigt. Sie können das Experiment jedoch gerne selbst mit Einbettungen eines anderen Anbieters, einer anderen Ähnlichkeitsmetrik usw. reproduzieren. Und obwohl die Ergebnisse hier numerisch sind, reichen für diese Diskussion auch höher/niedriger-Vergleiche aus, da die absoluten Zahlen aufgrund der Natur des Einbettungsraums abstrakt bleiben.
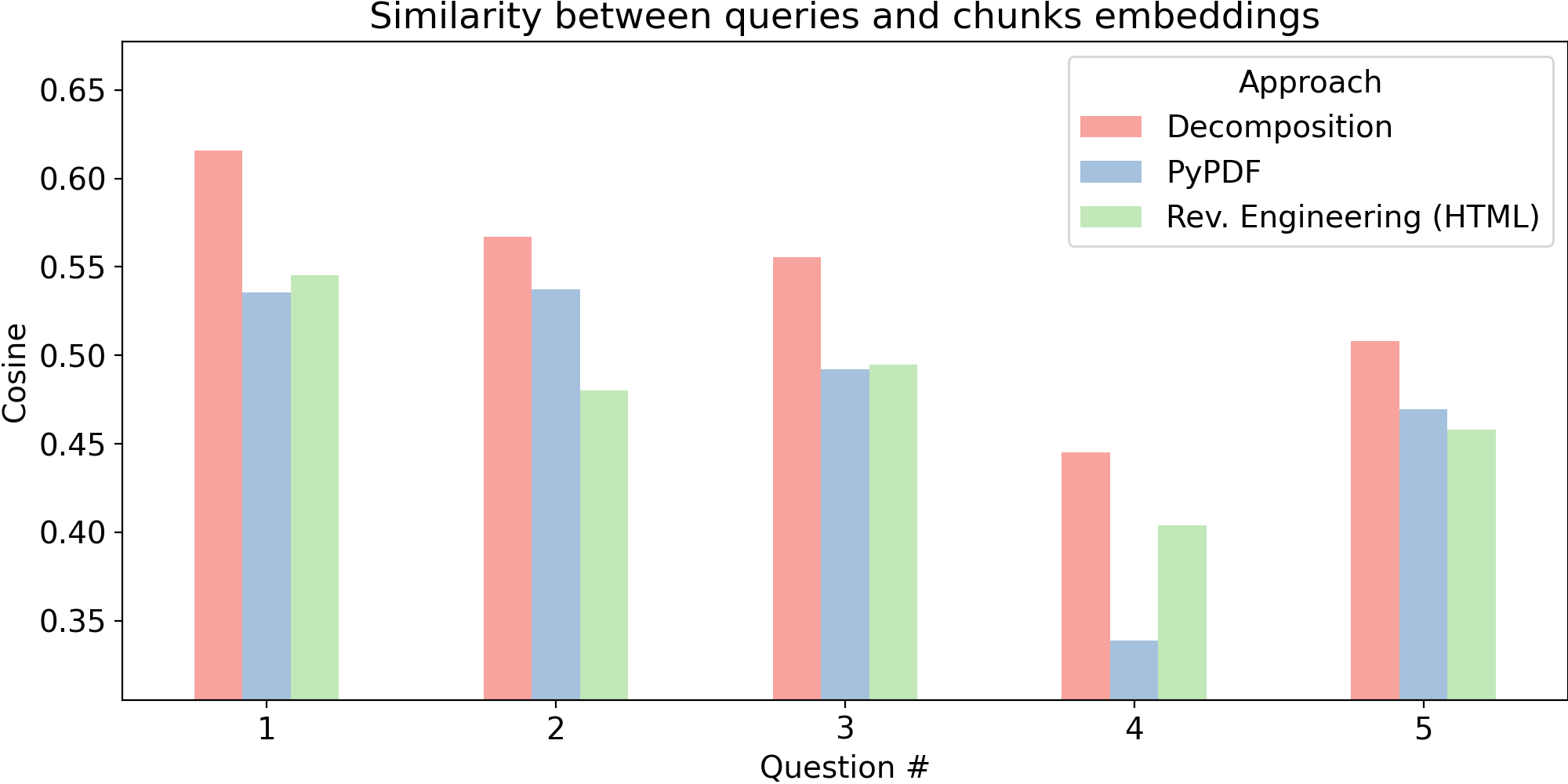
Es ist nicht sehr überraschend, dass beim Reverse Engineering und beim Roh-PDF-Parsing keine der beiden Methoden die andere übertrifft, da ihre Ähnlichkeiten mit organischen Fragen in gleichem Maße auf zufällige Schlüsselwortüberschneidungen mit wenig Semantik beschränkt sind. Dadurch wird das Rückgrat von RAG: Retrieval beeinträchtigt. Vielleicht könnten ihre informativen Beiträge in einer Eingabeaufforderung den Ausschlag geben (in Richtung Reverse Engineering, denn strukturiert ist besser als verschlüsselt), aber das ist ein Thema für einen anderen Tag.
Wie erwartet, überschneidet sich die Dekomposition semantisch am meisten mit allen Fragen, was zeigt, wie vorteilhaft sie für das Retrieval sein kann, da sie auf die größte Stärke von Sprachmodellen abzielt: einfache Sprache und nichts weiter. Chunks beschreiben nun Wissen auf eine Art und Weise, die der Art und Weise, wie Menschen eine Tabelle abfragen oder sogar interpretieren würden, sehr nahe kommt: vom Kern der Sache (beschrieben durch den zusätzlichen Zusammenfassungsabsatz) bis hin zu der Frage, wie wir jemandem die Tabellenwerte erklären würden (wie in den Listenelementen formuliert).
Fazit
Eine weitere "Garbage in, garbage out" -Situation. Übertragen auf den RAG-Jargon: Wir können sagen, dass das Abrufen (out) ein solides Rückgrat von RAG ist, das von der richtigen (In)gestion abhängt. Und dabei haben wir gesehen, dass wir für die Aufnahme komplexer Inhalte wie Tabellen über das mechanische Parsen von Textströmen hinausgehen müssen.
Dekomposition macht das Beste aus den Stärken von Sprachmodellen: einfache Sprache und nichts weiter. Modelle mit Vision-Fähigkeiten sind der Schlüssel, um komplexe Tabellen in kleinere, konkrete und beschreibbare Wissenseinheiten zu zerlegen, so wie es Menschen tun würden, wenn sie diese interpretieren oder sogar jemandem erklären. Abgesehen davon ist dies genau die Art und Weise, wie Benutzer organisch nach Wissen in einer Anwendung suchen werden. Solche Abfragen überschneiden sich natürlich mehr mit unabhängigen und vollständigen Stücken, was die Abfrage robuster macht. Außerdem wird dadurch die Entwicklung von Promotionen bei der Generierung erschwert.
Aus der Perspektive der Einbettungsähnlichkeit (ad-hoc) übertrifft die Dekomposition sowohl das Roh-Parsing als auch die Reverse-Engineering-Ansätze beim Abruf. Es ist fraglich, ob Reverse-Engineering die Dekomposition bei der Generierung übertreffen könnte, solange die (vom Abruf abhängigen) Reverse-Engineering-Inhalte den Prompt überhaupt erreichen, aber das ist ein Thema für einen anderen Tag. Was jedoch für die nächsten Schritte eine Debatte wert ist, ist die Frage, wie man beide Ansätze kombinieren kann, indem man jede Form strategisch in verschiedenen Schritten einsetzt. Metadaten zum Beispiel sind ein guter erster Schritt.
Verfasst von
Caio Benatti Moretti
Contact