Blog
dbt + SODA: Wie Sie Ihre Daten in großem Umfang verwalten


Wenn die Anzahl der Pipelines, die Ihr Datenteam entwickelt und unterstützt, wächst, stoßen Sie in der Regel auf alle möglichen Probleme, zum Beispiel:
- Eine Rohrleitung ist gebrochen und ich kann die Ursache nicht leicht finden.
- Die Anzahl der Quellen in meiner Plattform beträgt bis zu 20 und die nachgelagerten Tabellen/Ansichten bis zu 100: Wie kann ich diese Größenordnung verwalten? Woher weiß ich, wo ich die Daten finde, die ich brauche?
- In den letzten zwei Wochen haben Daten gefehlt: Wie kann ich sie leicht wieder auffüllen? Wie kann ich gewarnt werden, bevor es sich auf das Geschäft auswirkt?
- Das Schema meiner Datenquellen ändert sich ständig. Wie kann ich das herausfinden, bevor meine Pipelines zusammenbrechen?
Diese und viele andere Probleme treten häufig auf, wenn Datenplattformen zu skalieren beginnen. In der Cloud-Ära gibt es keine Einschränkungen bei der Speicherung oder Berechnung, aber wenn Sie nicht die richtigen Tools verwenden, können die Dinge schnell aus dem Ruder laufen. In diesem Artikel zeige ich Ihnen, wie Sie Ihre Daten bei der Skalierung mit Tools wie dbt und Soda besser verwalten können.
Möchten Sie eine Live-Demo der beiden Tools zusammen sehen? Dann sehen Sie sich meinen Vortrag zusammen mit meinem Kollegen Jovan bei ClubCloud 2021 an:
Einführung in die Tools
dbt
Ich würde sagen, dass dbt bei Ihrer Arbeit mit Daten fast keine Einführung braucht. Es hat sich zum Standardwerkzeug für ELT-Architekturen (Extract, Load & Transform) entwickelt. Meiner Meinung nach ist dbt die perfekte, leichtgewichtige Lösung zur Verwaltung Ihrer Transformationen innerhalb des Warehouse/Lakehouse. Außerdem ist es eine der größten Open-Source-Communities im Bereich Daten (wenn nicht sogar die beste). Das ist eine ziemlich mächtige Sache, denn es erlaubt der Community wirklich, das Tool mitzugestalten. Das ist einer der Gründe, warum es sich so schnell weiterentwickelt und so viele großartige Funktionen hervorbringt, wie z.B.:
- Integrierte Dokumentation (einschließlich Datenabfolge).
- Eine einfach zu verwendende CLI.
- Superstarkes Jinja-Templating, um das zu schreiben, was ich gerne als "SQL auf Steroiden" bezeichne (ich bin offen für Alternativen zu diesem Begriff).
- Belichtungen, Metriken... die Liste ist endlos!
Soda
Soda ist ein wenig neuer auf dem Markt. Es ist eines dieser aufstrebenden Tools, die versuchen, den Bereich der Datenüberwachung zu erobern. Mir gefällt, dass Soda einen einfachen Ansatz für die Datenüberwachung verfolgt und versucht, die Grundlagen richtig zu machen: Datentests und Metrikberechnung in Soda SQL und eine schöne Benutzeroberfläche für die Überwachung Ihrer Daten mit Soda Cloud.
Das Angebot von Soda dreht sich um die beiden oben erwähnten Hauptprodukte, Soda SQL und Soda Cloud. Soda SQL ist ein Open-Source-Tool, mit dem Sie Scans auf Ihrem Data Warehouse/Lakehouse durchführen können. Scans sind im Grunde eine Kombination aus zwei Dingen: Berechnung von Metriken und Tests (unter Verwendung dieser Metriken). Einige schöne Funktionen von Soda SQL sind:
- Scans lassen sich einfach über yaml-Dateien definieren.
- Es gibt viele vorgefertigte Metriken, die Sie verwenden können, aber Sie haben auch die Möglichkeit, SQL-Metriken zu definieren.
- Nette, einfach zu bedienende CLI und API (wenn Sie Scans programmatisch von z.B. Airflow aus durchführen möchten).
Soda Cloud ist der große Bruder von Soda SQL. Sie können direkt eine Verbindung zu, sagen wir, einem BigQuery-Datensatz von Soda Cloud aus herstellen, aber ich definiere meine Scans gerne separat mit Soda SQL, um alles als Code und versionskontrolliert zu halten. Sie können Ihre Soda Cloud API-Zugangsdaten ganz einfach in die warehouse.yml-Dateien einfügen, die für die Ausführung von Soda-Scans benötigt werden (weitere Informationen finden Sie in diesen
- Führt eine Historie Ihrer Metriken und Monitore (Tests).
- Ermöglicht die Erkennung von Schemadrifts und Anomalien auf der Grundlage der Ergebnisse Ihrer Metriken im Laufe der Zeit.
- Löst Alarme aus und überwacht die Lösung von Vorfällen.
Warum passen diese beiden so gut zusammen?
Lassen Sie uns zum zweiten Teil des Titels dieses Blogbeitrags zurückkehren: die Verwaltung von Daten in großem Umfang. Wenn die Anzahl der Anwendungsfälle wächst, wächst auch die Anzahl der Tabellen in Ihrem Warehouse. Es gibt zwei Dinge, die an diesem Punkt schnell schmerzhaft werden können: der Betrieb und die Sicherung der Datenqualität.
Einwandfreie Operationen mit dbt
Operations befasst sich mit dem täglichen Betrieb Ihrer Pipelines, also mit Dingen wie:
- Ich habe heute alle meine Tabellen planmäßig aktualisiert.
- Einige Fakten sind später eingetroffen und ich muss alle nachgelagerten Tabellen aus einer bestimmten Quelle wieder auffüllen (d.h. Daten von früheren Tagen neu verarbeiten).
- Verbringe ich mehr Zeit in der Entwicklung als im operativen Geschäft oder ist es umgekehrt? Oder anders ausgedrückt: Behebt mein Team 80 % der Zeit Bugs oder vielleicht nur 10?
Das ist es, was dbt wirklich auszeichnet. Es macht die Entwicklung von Datenpipelines einfach, aber die Wartung noch einfacher. In der Demo, die Jovan und ich gemacht haben, haben wir das Beispiel des Backfillings von Daten in inkrementell geladenen Tabellen (d.h. inkrementelle Modelle für die dbters) gegeben. Fügen Sie einfach eine einfache Jinja-Anweisung in die where -Klausel Ihrer dbt-Modelle ein,
where true
{% if var.has_var('date') %}
and date(created_timestamp) = date('{{ var("date") }}')
{% else %}
{% if is_incremental() %}
and date(created_timestamp) = date_sub(current_day(), interval 1 day)
{% else %}
and date(created_timestamp) < date_sub(current_day(), interval 1 day)
{% endif %}
{% endif %}
dbt füllt die Daten für den betreffenden Tag und die Quelltabelle fehlerfrei auf, indem es einfach ausgeführt wird:
dbt run --vars '{date: 2021-12-12}' --select some_staging_table+
Im Codeschnipsel sehen wir, wie wir, wenn die Variable date angegeben wird, den Filter anpassen, um Daten von diesem bestimmten Datum in unser inkrementelles Modell zu laden. Wenn die Variable nicht angegeben wird, wird das reguläre inkrementelle Laden durchgeführt (in der Regel der Vortag, wenn Sie mit täglichen Batches arbeiten). Diese Logik kann auch geändert werden, um Datenintervalle aufzufüllen, indem Sie ein Start- und ein Enddatum angeben und die Jinja-Logik leicht abändern. Weitere Informationen über inkrementelle Modelle finden Sie hier.
Einfache Überwachung der Datenqualität mit Soda
Einige Leser dieses Artikels denken vielleicht: "Warum muss ich Soda verwenden, wenn ich Tests mit dbt ausführen kann?". Das ist richtig. Sie können Tests mit dbt durchführen und es ist einfach und bequem, dies an demselben Ort zu tun, an dem sich auch der Code für die Datenpipeline befindet. Allerdings ist dbt kein Tool zur Datenüberwachung. Daher fehlen ihm einige wichtige Überwachungsfunktionen, wie z.B. die Speicherung von Testergebnissen, die Erkennung von Datenabweichungen, die Identifizierung von stillen Datenproblemen und die Alarmierung.
In der Demo haben wir gezeigt, wie praktisch Soda ist, um stille Datenprobleme zu erkennen und Sie darauf hinzuweisen. Häufige stille Datenprobleme sind metrische Anomalien oder Schemaabweichungen (d.h. neue Spalten, die hinzugefügt oder entfernt werden). Der folgende Screenshot ist ein Beispiel für die Erkennung von Anomalien bei der Zeilenzahl. Dies kann besonders nützlich sein, wenn späte Fakten eintreffen (die Zeilenzahl ist niedriger als gewöhnlich) oder doppelte Datensätze eintreffen und unsere Tests dieses Problem nicht erkennen (vielleicht aufgrund von doppelten Dateien mit unterschiedlichen Namen).
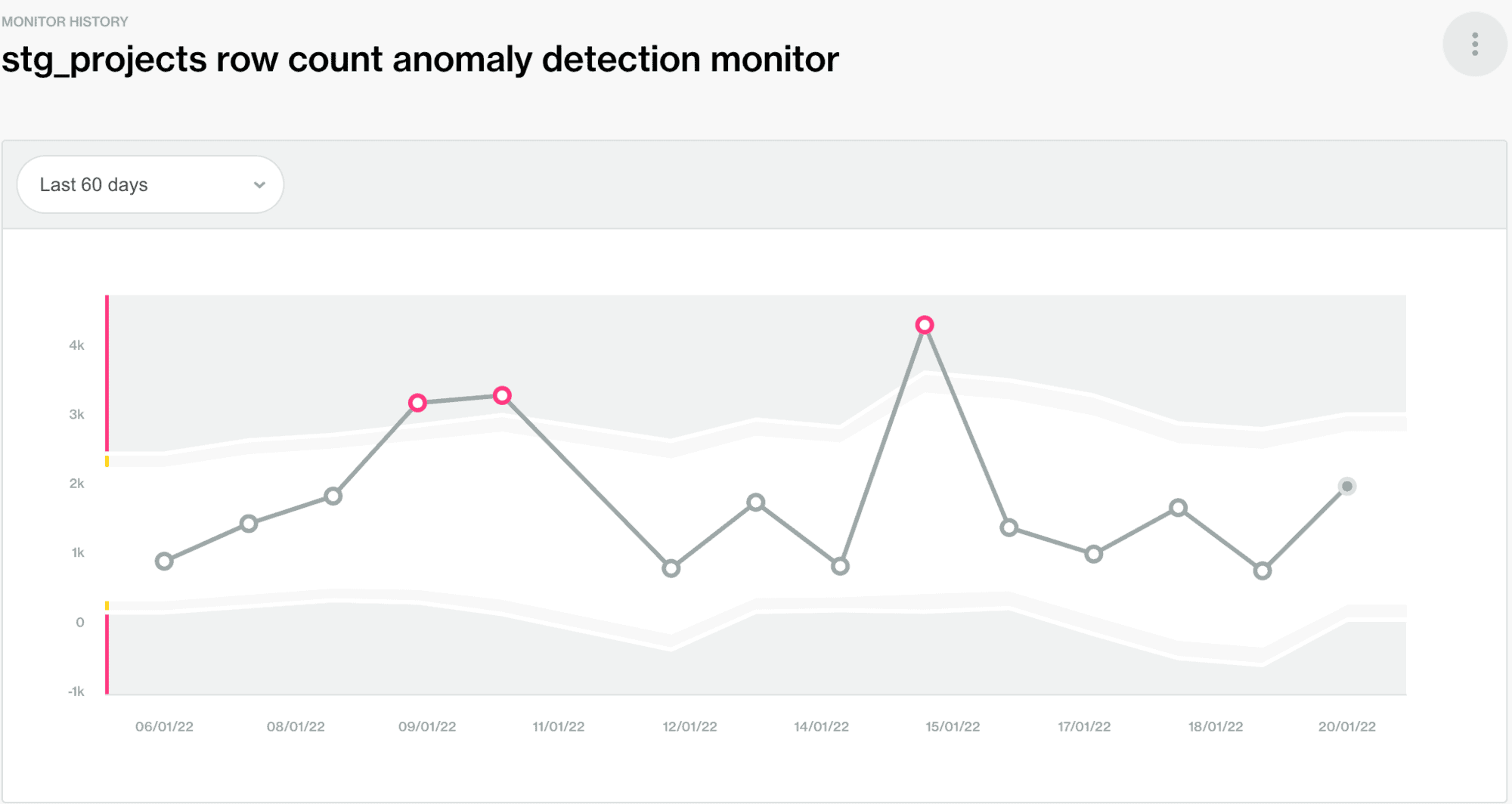
Eine einfache yaml-Scan-Konfiguration wie die folgende würde sicherstellen, dass Duplikate geprüft werden, die Zeilenzahl-Metrik berechnet wird und dies täglich geschieht (über den Filterschlüssel). Der Anomalie-Erkennungsmonitor für die Zeilenzahl ist standardmäßig aktiviert, wenn die Metadatenergebnisse zum ersten Mal an Soda Cloud gesendet werden.
table_name: stg_projects
filter: "DATE(created_timestamp) = DATE_SUB(PARSE_DATE('%d-%m-%Y', '{{ date }}'), INTERVAL 1 DAY)"
metrics:
- row_count
metric_groups:
- duplicates
samples:
table_limit: 50
failed_limit: 20
tests:
- row_count > 0
columns:
id:
tests:
- duplicate_count == 0
- missing_count == 0Mit dieser Datei und einer warehouse.yml-Datei, die auf die richtigen Anmeldeinformationen verweist (sowohl für das Warehouse als auch für Soda Cloud), können wir den Scan einfach wie folgt ausführen:
soda scan warehouse.yml tables/scan.yml --variable date=2021-12-12*Nebenbei bemerkt, können Sie die Ergebnisse Ihrer dbt-Tests auch in Soda Cloud integrieren, da vor kurzem eine Integration von den Soda-Leuten veröffentlicht wurde (lesen Sie die Dokumente).
Test dbt + Soda
Wir haben das in unserer Demo verwendete Repository öffentlich gemacht, so dass Sie es forken und mit dbt und Soda herumspielen können! Wir haben eine Github Actions-Pipeline verwendet, um die dbt- und Soda-Läufe zu orchestrieren, aber Sie können auch Tools verwenden, die speziell für die Orchestrierung von Datenverarbeitungsabläufen entwickelt wurden, wie Airflow, Prefect oder Dagster. In der README des Repositorys finden Sie ein Runbook mit einigen Anweisungen, wie Sie Ihre Umgebung für einen PoC oder Hackathon einrichten können.
Wenn Sie mit den Tools herumspielen und wissen möchten, wie Sie sie in Ihrer Datenplattform einsetzen können, können Sie sich gerne mit mir unterhalten!
Verfasst von
Guillermo Sánchez Dionis
Unsere Ideen
Weitere Blogs




Contact