Blog
dbt Semantische Schicht - Implementierung

Einführung
Willkommen zurück zur dbt Semantic Layer Serie! Dieser Artikel ist eine Fortsetzung unseres vorherigen Artikels mit dem Titel "
Wir empfehlen Ihnen dringend, zuerst den vorherigen Artikel zu lesen, da er beschreibt, was dbt ist, was ein dbt Semantic Layer ist und wie man ihn verwendet. Dieser Artikel ist eine Fortsetzung der Geschichte und wir werden Ihnen Schritt für Schritt zeigen, was zu tun ist, um den dbt Semantic Layer zu implementieren.
Implementierung
Voraussetzungen
Um den dbt Semantic Layer zu verwenden, müssen Sie ein dbt-Projekt erstellen und ein Dienstkonto konfigurieren. Diese Einrichtung erfordert einen kostenpflichtigen Team- oder Enterprise-Plan. Ausführliche Anweisungen zu Projekten, Lizenzen und Service-Token finden Sie in der dbt-Dokumentation.
Wenn Sie noch kein dbt-Projekt haben, können Sie den dbt-Leitfaden verwenden, um ein Beispielprojekt mit einer der verfügbaren Datenquellen einzurichten. Hier finden Sie hilfreiches Material: dbt Schnellstart-Leitfaden. Wenn Sie alles eingerichtet haben, folgen Sie bitte den nachstehenden Anweisungen, um die semantische Schicht zu implementieren.
Schritt 1. Erstellen Sie die Konfiguration des semantischen Modells
Erstellen Sie innerhalb des Ordners 'models' einen neuen Unterordner 'semantic_models' und erstellen Sie dann die YAML-Datei, die die Definition des spezifischen Semantic Layer enthält. Sie können dort mehrere SL-Dateien ablegen, aber die Namen sollten eindeutig sein, z.B. 'SL_orders.yml'. Denken Sie daran, dass das Speichern von SL-Dateien außerhalb des Ordners 'models' zu einem Fehler bei der Ausführung führt.
Die Struktur der semantischen Schicht ist wie folgt:
semantic_models:
- name: the_name_of_your_semantic_model ## Required; name of each model needs to be unique
description: same as always ## Optional; write here the description of what this SL model and what is its purpose
model: ref('some_model') ## Required; here put name of the model that you want to use as a foundation of any future calculations e.g. some fact table
defaults: ## Required
agg_time_dimension: dimension_name ## Required if the model contains measures; specify which column will be used for calucations in time
entities: ## Required
- ## define here columns used for joining
- ## define here the primary entity, usualy the main fact table
measures: ## Optional
- ## define here the columns to be used for calculations and basic logic
dimensions: ## Required
- ## specify here which tables you will be using as Dimensions to caluclate the measures
primary_entity: >-
if the semantic model has no primary entity, then this property is required. ##Optional if a primary entity exists, otherwise Required
metrics: ## Place here or in separate YAML file
- ## define here advanced logic of your metrics; see Step 2 for more detailsSie müssen die SL-Definition an Ihre spezifischen Geschäftsanforderungen anpassen, um davon profitieren zu können. Hier finden Sie die ausführlichen Informationen von dbt Labs zur Definition semantischer Modelle - dbt-Dokumentation.
Sehen Sie sich die SL YAML-Beispielkonfiguration unten an:
semantic_models:
- name: customers
defaults:
agg_time_dimension: most_recent_order_date
description: |
semantic model for dim_customers
model: ref('fact_customer_orders') ## Model combining orders and customer data
entities:
- name: customer
expr: customer_id
type: primary
dimensions:
- name: customer_name
type: categorical
expr: first_name
- name: first_order_date
type: time
type_params:
time_granularity: day
- name: most_recent_order_date
type: time
type_params:
time_granularity: day
measures:
- name: count_lifetime_orders
description: Total count of orders per customer.
agg: sum
expr: number_of_orders
- name: lifetime_spend
agg: sum
expr: lifetime_value
description: Gross customer lifetime spend inclusive of taxes.
- name: customers
expr: customer_id
agg: count_distinct
metrics:
- name: "customers_with_orders"
label: "customers_with_orders"
description: "Unique count of customers placing orders"
type: simple
type_params:
measure: customersSchritt 2. Metriken erstellen
Das Herzstück des SL-Modells sind Metriken - hier definieren Sie die komplexe Geschäftslogik mithilfe der erweiterten Optionen. Sie können sowohl in der SL-Modell-YAML-Datei als auch in einer separaten YAML-Datei mit dem Namen 'SLModelName_metrics.yaml' (z.B. customer_orders_metrics.yaml) innerhalb des Unterordners models/semantic_models erstellt werden. Beide Optionen sind möglich, und es liegt im Ermessen des Entwicklers, welche er wählt. Die Aufbewahrung der Metriken in einer separaten Datei bietet jedoch einen besseren Überblick über die Definition, da weniger Informationen in derselben Datei enthalten sind. 
Um eine Metrik zu erstellen, müssen Sie zumindest den Namen und den Typ festlegen. Der yype definiert, wie die Berechnungen durchgeführt werden und welche Kennzahlen in die Logik einbezogen werden sollen. Jede Metrik wird auf der Grundlage der Maßnahme berechnet, die Sie in der Datei semantic_model.yaml definiert haben.
Es gibt zwei Gruppen von Metriken: einfache und komplexe. Die ersten verwenden in der Regel nur eine Kennzahl und präsentieren sie dem Benutzer. Die zweiten verwenden eine oder mehrere Kennzahlen und fügen einige erweiterte Berechnungen hinzu, z.B. Umrechnung, Kumulierung, Verhältnis, Filterung.
Die Struktur der Metrikdefinitionen ist wie folgt:
metrics:
- name: metric_name ## Required
description: description ## Optional
type: the type of the metric ## Required
type_params: ## Required
- ## specific properties for the metric type and measures which you want to choose in calculations
config: ## Optional
meta:
my_meta_config: 'config' ## Optional
label: The display name for your metric. This value will be shown in downstream tools. ## Required
filter: | ## Optional
{{ Dimension('entity__name') }} > 0 and {{ Dimension(' entity__another_name') }} is not
null and {{ Metric('metric_name', group_by=['entity_name']) }} > 5
Beispielhafte Definition einer einfachen Umsatzmetrik:
metrics:
\- name: revenue
description: Sum of the order total.
label: Revenue
type: simple
type_params:
measure: order_totalBeispiel für die Definition einer komplexen Metrik unter Verwendung von Verhältnislogik und Filterung:
metrics:
\- name: cancellation_rate
type: ratio
label: Cancellation rate
type_params:
numerator: cancellations
denominator: transaction_amount
filter: |
{{ Dimension('customer__country') }} = 'MX'
\- name: enterprise_cancellation_rate
type: ratio
type_params:
numerator:
name: cancellations
filter: {{ Dimension('company__tier') }} = 'enterprise'
denominator: transaction_amount
filter: |
{{ Dimension('customer__country') }} = 'MX'Hier finden Sie die ausführlichen Informationen von dbt Labs zur Definition von Metriken - Übersicht über Metriken. Bitte passen Sie die Datei 'ModelName_metrics.yaml' an Ihre spezifischen Geschäftsanforderungen an.
Schritt 3. MetricFlow TimeSpine Datumstabelle erstellen
Ein Zeit-Rückgrat in einem semantischen Modell ist eine entscheidende Komponente, die eine konsistente und genaue zeitbasierte Analyse gewährleistet. Sie definiert die Zeitdimensionen, die zur Berechnung Ihrer Metriken in einer Zeitperspektive verwendet werden können.
TimeSpine ist nichts anderes als ein Modell, in dem wir die Zeitdimension definieren. Um ein solches Modell zu erstellen, erstellen Sie bitte ein neues Modell mit dem Namen 'metricflow_time_spine.sql' und verwenden SQL, um die Dimension zu erstellen. Sie können den Beispielcode unten verwenden:
{{
config(
materialized = 'table',
)
}}
with days as (
{{
dbt.date_spine(
'day',
"to_date('01/01/2000','mm/dd/yyyy')",
"to_date('01/01/2030','mm/dd/yyyy')"
)
}}
),
final as (
select cast(date_day as date) as date_day
from days
)
select * from final
where date_day > dateadd(year, -4, current_timestamp())
and date_hour < dateadd(day, 30, current_timestamp())Hier finden Sie weitere Informationen über MetricFlow TimeSpine - Link.
Schritt 4. Testen Sie das Modell
Nachdem Sie das semantische Modell und die auf Ihre Bedürfnisse zugeschnittenen Metriken definiert haben, müssen Sie sicherstellen, dass alles korrekt eingerichtet ist. Führen Sie dazu den Befehl build in dbt Cloud aus (dbt build oder dbt build -full-refresh). Dadurch werden Ihre Modelle kompiliert und ausgeführt, so dass Sie eventuell auftretende Fehler erkennen und beheben können.
Sie haben die Flexibilität, den Semantic Layer (SL) sowohl in dbt Core als auch in dbt Cloud zu entwickeln. In beiden Umgebungen können Sie Ihren SL lokal validieren (noch keine API, siehe nächste Schritte), um sicherzustellen, dass er Ihren Anforderungen entspricht. Um mit Ihren Metriken innerhalb des dbt Semantic Layer zu interagieren und sie zu validieren, sollten Sie die MetricFlow-Befehle verwenden, die speziell für diesen Zweck entwickelt wurden. Sehen Sie sich die Beispielbefehle unten an, um Ihr Modell zu testen.
## List your metrics
dbt sl list metrics <metric_name> ## In dbt Cloud
mf list metrics <metric_name> ## In dbt Core
## List available dimensions for specific measure
dbt sl list dimensions --metrics <metric_name> ## In dbt Cloud
mf list dimensions --metrics <metric_name> ## In dbt Core
## Query the model
dbt sl query --metrics <metric_name> --group-by <dimension_name> ## In dbt Cloud
dbt sl query --saved-query <name> ## In dbt Cloud CLI
## Example of ready query
dbt sl query --metrics order_total,users_active --group-by metric_time ## In dbt Cloud
mf query --metrics order_total,users_active --group-by metric_time ## In dbt Core
## Result of query
✔ Success 🦄 - query completed after 1.24 seconds
| METRIC_TIME | ORDER_TOTAL |
|:--------------|---------------:|
| 2017-06-16 | 792.17 |
| 2017-06-17 | 458.35 |
| 2017-06-18 | 490.69 |
| 2017-06-19 | 749.09 |
| 2017-06-20 | 712.51 |
| 2017-06-21 | 541.65 |Hier finden Sie eine detaillierte Erklärung der MetricFlow-Logik und -Befehle - dbt-Dokumentation.
Jetzt haben Sie einen voll funktionsfähigen dbt Semantic Layer, mit dem Sie Berechnungen durchführen können. Es ist zwar von Vorteil, Ergebnisse in Ihrer dbt Cloud oder Ihrem dbt Core zu erhalten, aber das ist erst der Anfang. Der größte Wert des Semantic Layer liegt in seiner Verfügbarkeit über die API und in der Möglichkeit, mit externen Produkten benutzerdefinierte Abfragen über die API von dbt SL anzufordern. Um diese Funktionalität zu aktivieren, müssen wir eine Produktionsumgebung mit der implementierten SL-Logik einrichten. Als nächstes müssen wir den Semantic Layer Access Point konfigurieren, um die Kommunikation zu ermöglichen. All dies wird in den folgenden Schritten behandelt, also lesen Sie weiter!
Schritt 5. Einrichten der Produktionsumgebung
Nachdem der Auftrag vollständig ausgeführt wurde, können wir zum Modul Deploy wechseln, um unsere Produktionsumgebung zu erstellen oder anzupassen. Sie benötigen eine PROD-Umgebung mit SL-Logik, um diese über APIs nutzen zu können. 
Falls Sie bereits eine Produktionsumgebung haben, fahren Sie mit dem nächsten Schritt fort.
Klicken Sie auf die Schaltfläche 'Umgebung erstellen' und warten Sie, bis sich das Konfigurations-Pop-up öffnet. Legen Sie den 'Umgebungsnamen' fest (z.B. Produktion) und wählen Sie dann unter 'Bereitstellungstyp festlegen' die Option Produktion (weitere Informationen hier). 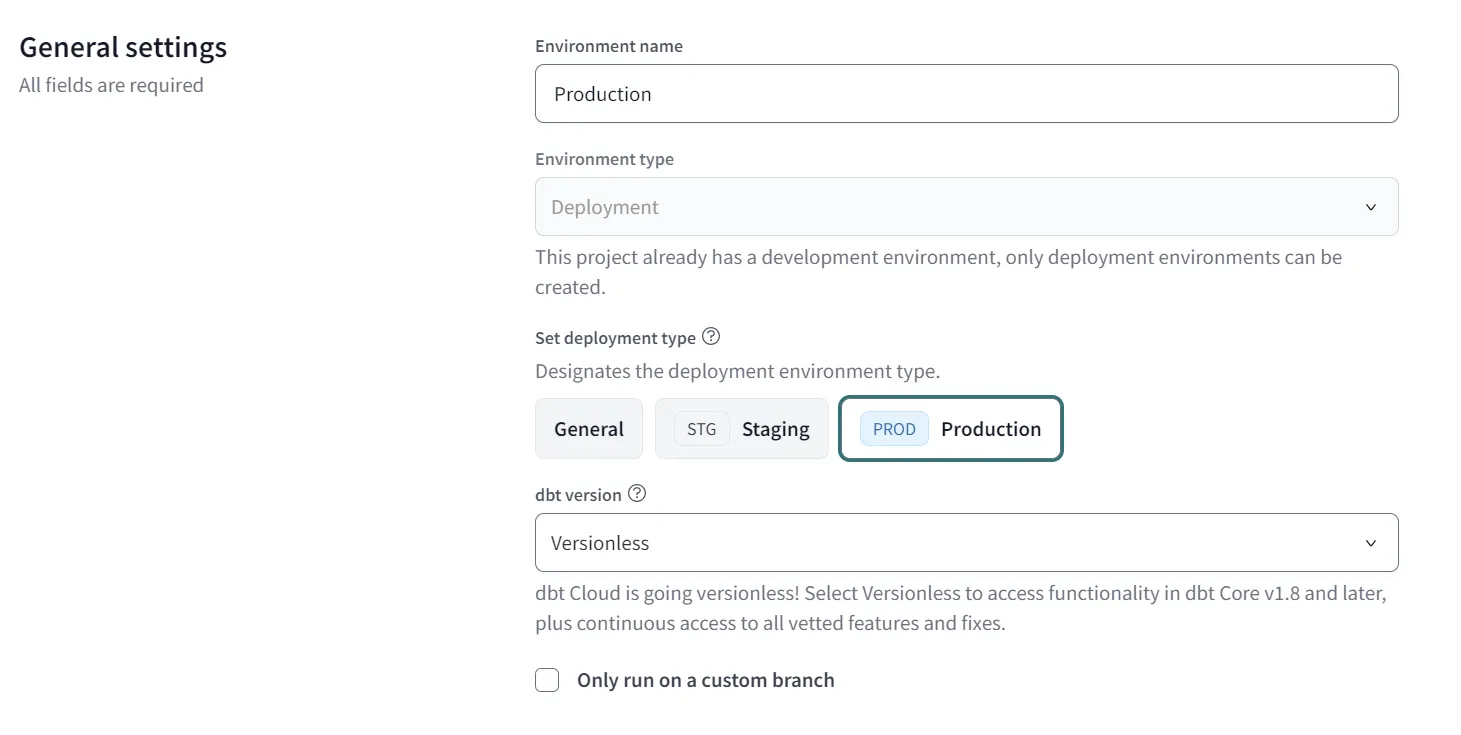
Wählen Sie als nächstes die Verbindung, die von dieser Umgebung verwendet werden soll, vorzugsweise die gleiche, die für das dbt-Projekt definiert wurde. Die ausgewählte Verbindung wird für die Erstellung der Produktionsmodelle verwendet. Definieren Sie zum Schluss die 'Deployment credentials', die den Benutzernamen und den Namen des Zielschemas festlegen. 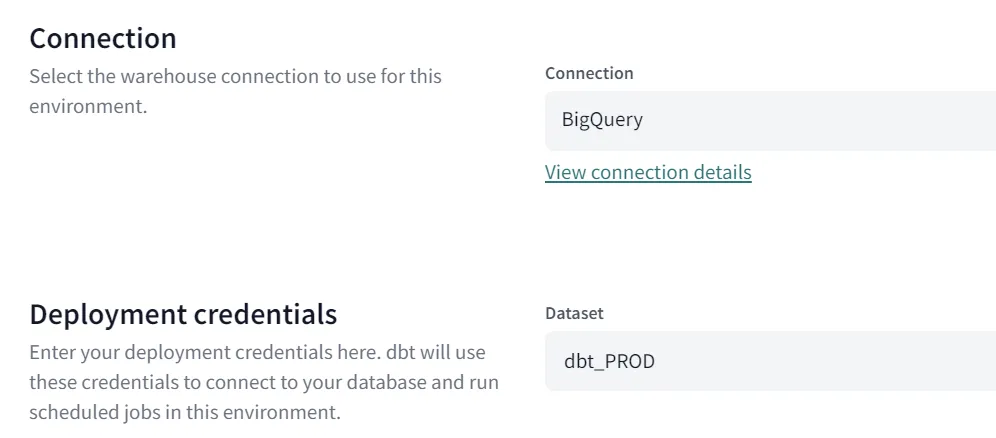
Sehen Sie das Endergebnis der Bereitstellung unter Verbindung unten = BigQuery und Bereitstellung_credentials = dbt_PROD.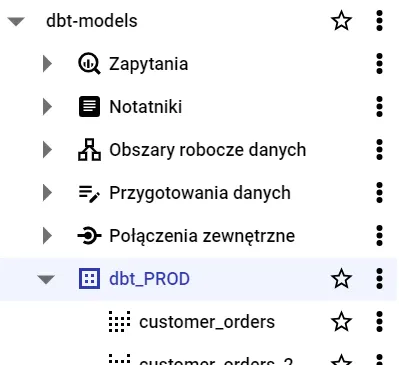
Nachdem Sie alle oben genannten Schritte ausgeführt haben, scrollen Sie nach oben und klicken Sie auf 'Speichern'.
Schritt 6. Führen Sie den Auftrag aus
Jetzt müssen wir einen Auftrag erstellen, der unser Projekt mit der SL-Konfiguration in der Produktionsumgebung erstellt, um die Semantic Layer API-Funktionalität zu aktivieren. Gehen Sie dazu zum Modul Deploy / Jobs. 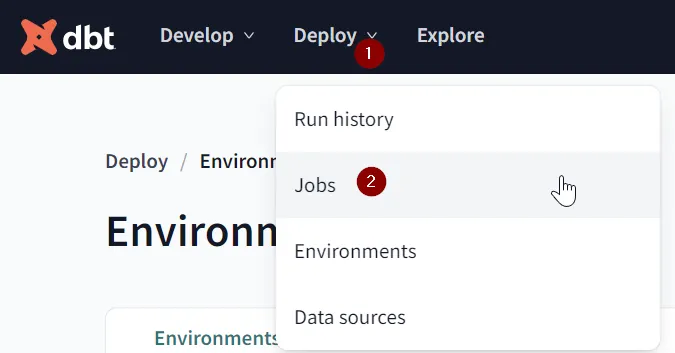
Klicken Sie auf die Schaltfläche 'Auftrag erstellen', wählen Sie 'Auftrag bereitstellen'. Legen Sie dann den eindeutigen Namen fest, wählen Sie die Produktionsumgebung aus und klicken Sie oben auf die Schaltfläche 'Speichern'. Weitere Informationen zur Auftragserstellung finden Sie hier.
Öffnen Sie die Detailseite des neu erstellten Auftrags und klicken Sie auf die Schaltfläche "Jetzt ausführen".
Schritt 7. API konfigurieren
Wenn wir die SL-Konfiguration abgeschlossen und eine PROD-Umgebung mit einem erfolgreich laufenden Auftrag erstellt haben, können wir nun zum letzten Teil übergehen, der API-Konfiguration. Navigieren Sie auf der dbt Cloud-Plattform zu den Kontoeinstellungen, indem Sie auf das Einstellungssymbol in der oberen rechten Ecke klicken, wählen Sie Projekte und dann den Namen des Projekts, an dem Sie arbeiten. 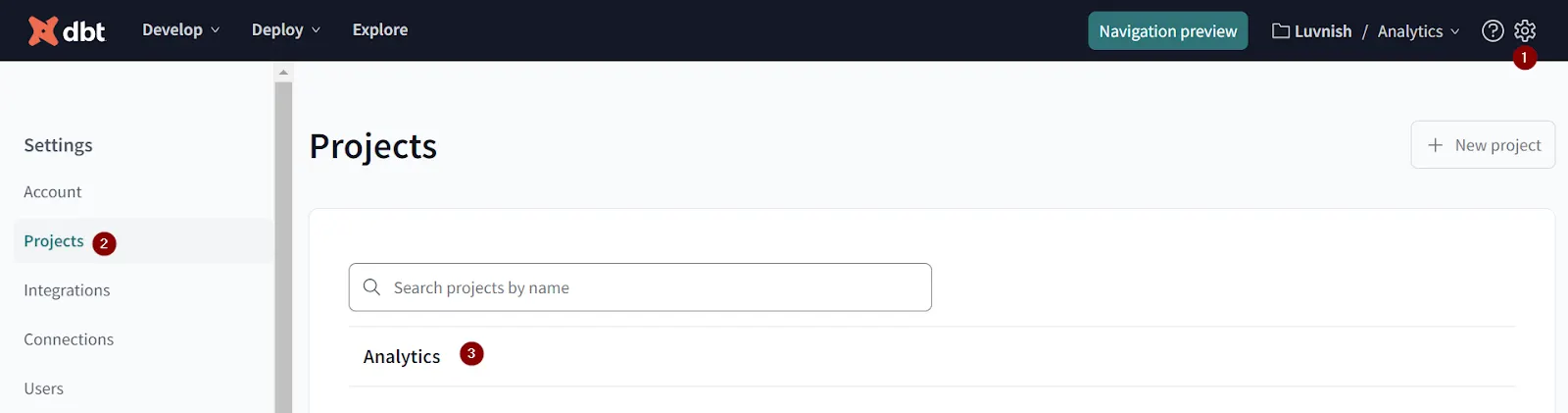
Scrollen Sie nach unten zum Abschnitt 'Semantische Schicht' und wählen Sie 'Semantische Schicht konfigurieren'. Hier finden Sie eine detaillierte Anleitung von dbt Labs zur Einrichtung des SL - Leitfaden.
Denken Sie daran, den Service Token irgendwo zu notieren - Sie benötigen ihn später für die Kommunikation mit der API.
Nach Abschluss aller Schritte sind Sie bereit, Semantic Layer zu verwenden!
Zusammenfassung
Der dbt Semantic Layer kann, wenn er richtig definiert ist, die Datenanalyse eines Unternehmens erheblich voranbringen. Er bietet einen einheitlichen und konsistenten Rahmen für die Definition von Geschäftsmetriken und -dimensionen, was für viele Unternehmen von entscheidender Bedeutung ist.
Dieser Leitfaden beschreibt einen schrittweisen Prozess für die Implementierung des dbt Semantic Layer (SL), der eine zentralisierte, konsistente Geschäftslogik für Ihren gesamten Daten-Workflow ermöglicht. Der Prozess umfasst die Definition des semantischen Modells, die Metriken, die Zeitdimension, die Einsatzumgebung und schließlich die API-Konfiguration.
Für Unternehmen, die ihre Datenanalysefähigkeiten verbessern wollen, ist die Investition in einen dbt Semantic Layer ein strategischer Schritt, der langfristig erhebliche Vorteile verspricht. Da sich die Datenlandschaft ständig weiterentwickelt, werden Tools wie dbt eine immer wichtigere Rolle bei der Gestaltung der Zukunft von Business Intelligence und Analysen spielen.
Wenn Sie mehr über die Möglichkeiten von dbt erfahren möchten oder vor anderen Herausforderungen im Zusammenhang mit Data Na AI stehen, zögern Sie nicht, uns zu kontaktieren.
Verfasst von
Przemyslaw Baran
Unsere Ideen
Weitere Blogs




Contact