
Wir möchten Ihnen den dbt-flink-Adapter vorstellen, mit dem Sie in SQL definierte Pipelines in einem dbt-Projekt auf Apache Flink ausführen können. Erfahren Sie, welche Vorteile dbt und Apache Flink haben, was unser Xebia Streaming Labs Team dazu veranlasst hat, den Adapter zu entwickeln, und wie Sie eine Echtzeit-Analyse-Pipeline erstellen. Außerdem räumen wir mit dem Mythos auf, dass Echtzeit-Analysen die Kosten nicht wert sind. Sind Sie bereit?
Teil 1: Einführung
Warum dbt?
In der Welt der Analytik spielt ein effizienter, stabiler und zuverlässiger ETL-Prozess eine entscheidende Rolle, wenn es darum geht, Datenprodukte von höchstem Wert zu liefern. Es überrascht daher nicht, dass dbt als potenzieller Game Changer für die Analysetechnik angekündigt wurde und heute als das modernste Tool für den Aufbau von Datenpipelines gilt. dbt, das Datentransformations-Framework, wurde so konzipiert, dass jede Person mit einem analytischen Hintergrund und SQL-Kenntnissen den ETL-Prozess selbst in die Hand nehmen kann. Dank der Funktionen von dbt kann der Analyst nicht nur die Daten modellieren, mit denen er arbeiten wird, sondern auch die besten Praktiken des Software-Engineering umsetzen, wenn es um die Überwachung der Datenqualität, die Überprüfung des Codes und die Überprüfung und Dokumentation auf Projektebene geht. Dies sind nicht nur einfache Slogans, sondern das Framework hat seine Popularität bei kleineren und größeren Akteuren gesteigert und eine sehr starke und freundliche Community um sich geschart. Dank ständiger Upgrades und Funktionsverbesserungen wird sich dies auch nicht so bald ändern. Was dbt noch fehlt, ist die Unterstützung für den Aufbau von Echtzeit-Analyse-Pipelines.
Warum Apache Flink?
Apache Flink ist ein leistungsfähiges Big-Data-Verarbeitungsframework, das in den letzten Jahren schnell an Popularität gewonnen hat, da immer mehr Unternehmen damit begonnen haben, es in der Produktion in großem Umfang einzusetzen. Einer der Hauptgründe für seinen Erfolg ist seine Fähigkeit, sowohl Batch- als auch Stream-Verarbeitung auf einer einzigen Plattform zu verarbeiten. Das bedeutet, dass Benutzer sowohl Echtzeit-Datenströme als auch historische Daten innerhalb desselben Frameworks verarbeiten und analysieren können. Darüber hinaus ist Flink dank seiner hohen Leistung und niedrigen Latenz die ideale Wahl für Anwendungsfälle wie Echtzeitanalysen, maschinelles Lernen und komplexe Ereignisverarbeitung. Ein weiterer entscheidender Vorteil von Flink ist die Unterstützung einer breiten Palette von Datenquellen und -senken, darunter Kafka, HDFS, S3, RDBMS und No-SQL-Datenbanken, wodurch die Integration in die bestehende Dateninfrastruktur erleichtert wird.
Apache Flink ist in jeder Größenordnung produktionsreif, von kleinen Aufträgen, die direkt auf Ihrem Arbeitsrechner ausgeführt werden, bis hin zu riesigen Clustern mit Tausenden von Knoten. Ein Beispiel für ein Unternehmen, das
dbt Flink Adapter
Der Benutzer kann Apache Flink-Pipelines mit der DataStream-API in Java/Scala/Python oder mit SQL sowohl für die Stapel- als auch für die Stream-Verarbeitung definieren. Da sich Apache Flink jedoch nicht wie eine typische Datenbank verhält, war es für Nicht-Programmierer ziemlich schwierig, diese SQLs auszuführen. Das gibt Analytikern nicht die Möglichkeit, die volle Verantwortung für ETL-Prozesse mit Flink zu übernehmen. Was wäre also, wenn wir es möglich machen könnten, in dbt definierte Pipelines auf Apache Flink? Auf diese Weise würden wir es allen Analytikern, die dbt kennen, ermöglichen, Echtzeit-Pipelines zu definieren. Gleichzeitig erhalten alle Benutzer von Flink SQL ein sehr leistungsfähiges und beliebtes Tool zur Pflege ihrer Pipeline-Projekte - dbt.
Bei GetInData Streaming Labs haben wir genau das gelöst. Dazu haben wir einen Adapter für dbt angekündigt, der die Ausführung von in SQL definierten Pipelines im dbt-Projekt auf Apache Flink ermöglicht GitHub - getindata/dbt-flink-adapter. Er ähnelt anderen Adaptern, die
Darüber hinaus unterstützt dieser Adapter auch die typischen Batch-Verarbeitungspipelines auf Flink. Dies und die Nutzung der umfangreichen Bibliothek von Konnektoren, sowohl als Quellen als auch als Ziele (Elasticsearch, Kafka, DynamoDB, Kinesis, JDBC und andere) machen dies zu einem sehr leistungsstarken ETL-System (und wir meinen alle Extrahier-, Transformier- und Ladevorgänge), das von dbt gesteuert wird.
Das folgende Diagramm veranschaulicht, wie dbt, Flink und andere verschiedene Speicherdienste zusammenarbeiten. Wie Sie sehen, nutzen wir eine sehr wertvolle neue Funktion von Flink, das Flink SQL Gateway, das eine API zur Ausführung von SQL-Abfragen auf einem Flink-Cluster bereitstellt. 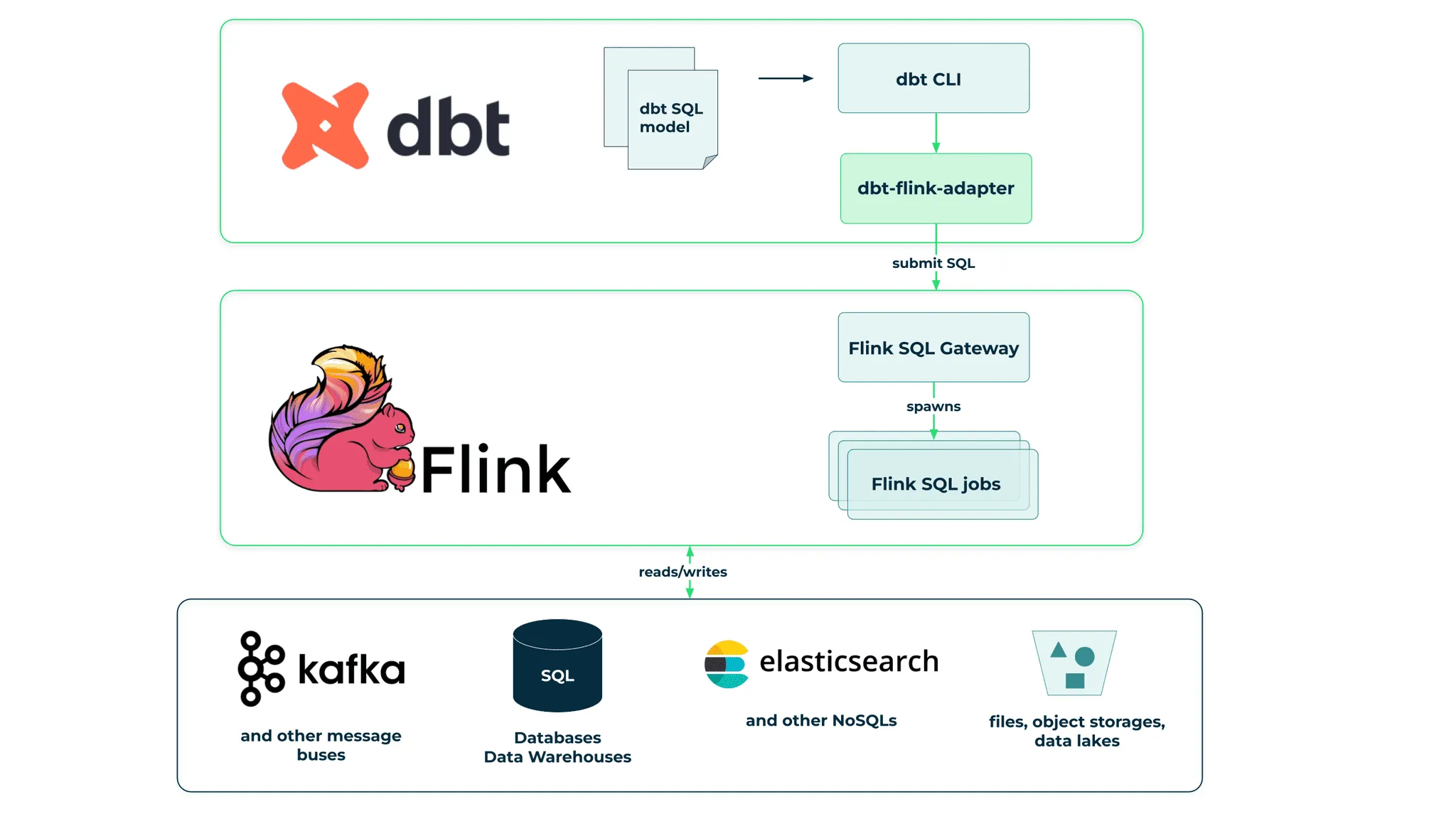
Es gibt jedoch Unterschiede in der Art und Weise, wie das dbt-Modell für den Betrieb in Echtzeit auf Apache Flink erstellt und betrieben werden muss, die wir im nächsten Teil dieses Artikels untersuchen werden.
Teil 2: Anleitung zum dbt-flink-adapter
Sie finden das vollständige Beispiel hier GitHub - gliter/dbt-flink-adapter-example
Wir werden eine Echtzeit-Analyse-Pipeline erstellen, die zwei Datenströme verarbeiten wird. Erstens wird es Transaktionen auf Bankkundenkonten darstellen und zweitens solche, die Klick-Ereignisse in der Bankanwendung enthalten. Wir werden einen einfachen Filtervorgang erstellen, der z.B. dazu verwendet werden kann, einen Kunden zu benachrichtigen, wenn ein großer Kredit aufgenommen wird. Wir werden einen neuen Stream erstellen, der die Daten aus zwei Eingabeströmen zusammenführt, und wir werden eine Pipeline erstellen, die die täglichen Ausgaben der Bankkunden berechnet.
In diesem Tutorial verwenden wir dbt-cli mit einem in der virtuellen Python-Umgebung installierten dbt-flink-Adapter. Außerdem werden wir Kafka- und Flink-Instanzen verwenden, die auf Ihrem Rechner mit docker-compose ausgeführt werden.
Voraussetzungen
- Python >3.7 mit pip und venv
- Docker mit docker-compose
Einrichtung
Erstellen Sie eine virtuelle Umgebung und installieren Sie dbt-flink-adapter
$ mkdir -p ~/projects/dbt
$ cd ~/projects/dbt
$ python3 -m venv ~/.virtualenvs/dbt-example1
$ source ~/.virtualenvs/dbt-example1/bin/activate
$ pip3 install dbt-flink-adapterSobald die Installation abgeschlossen ist, können wir ein dbt-Projekt erstellen. Sie können die Standardwerte verwenden, wenn Sie dazu aufgefordert werden. Entfernen Sie die von dbt init erstellten Standardmodelle.
$ dbt init
Enter a name for your project (letters, digits, underscore): example1
Which database would you like to use?
[1] flink
Enter a number: 1
host (Flink SQL Gateway host) [localhost]:
port [8083]:
session_name [test_session]:
database (Flink catalog) [default_catalog]:
schema (Flink database) [default_database]:
threads (1 or more) [1]:
$ cd example1
$ rm -r models/exampleAußerdem benötigen wir eine Apache Flink-Instanz mit SQL Gateway und für die Zwecke dieses Tutorials eine Ein-Knoten-Instanz von Apache Kafka.
$ wget https://raw.githubusercontent.com/gliter/dbt-flink-adapter-example/main/docker-compose.yml
$ docker-compose upErstellen Sie clickstream, init-balance, trx, high-loan, joined-data, daily-spending Themen in Kafka
$ wget https://raw.githubusercontent.com/gliter/dbt-flink-adapter-example/main/recreate-topics.sh
$ chmod +x recreate-topics.sh
$ ./recreate-topics.shNach diesen Schritten sollten Sie über die folgenden Dateien, Container und Themen verfügen
$ tree
.
├── analyses
├── dbt_project.yml
├── macros
├── models
├── README.md
├── seeds
├── snapshots
└── tests
$ docker-compose ps
Name Command State Ports
------------------------------------------------------------------------------------------------------------------------------
example1_jobmanager_1 /docker-entrypoint.sh jobm ... Up 6123/tcp, 0.0.0.0:8081->8081/tcp,:::8081->8081/tcp
example1_kafka_1 /etc/confluent/docker/run Up 0.0.0.0:9092->9092/tcp,:::9092->9092/tcp
example1_sql-gateway_1 /bin/sh -c /docker-entrypo ... Up 6123/tcp, 8081/tcp, 0.0.0.0:8083->8083/tcp,:::8083->8083/tcp
example1_taskmanager_1 /docker-entrypoint.sh task ... Up 6123/tcp, 8081/tcp
example1_zookeeper_1 /etc/confluent/docker/run Up 2181/tcp, 2888/tcp, 3888/tcp
$ kafka-topics --bootstrap-server localhost:9092 --list
clickstream
daily-spending
high-loan
init-balance
joined-data
trxSie können auch http://localhost:8081 in Ihrem Browser öffnen, um die laufende Apache Flink-Instanz zu sehen.
Quellen
Wir nähern uns dem ersten grundlegenden Unterschied in der Art und Weise, wie wir über das dbt-Modell für Apache Flink im Gegensatz zu typischen Modellen nachdenken sollten.
Wenn wir uns mit einer Flink-Instanz verbinden, gibt es dort keine Daten [1], es ist nur eine Verarbeitungsmaschine und für unsere Persistenz müssen wir uns mit anderen Diensten verbinden. In unserem Lernprogramm werden wir Apache Kafka verwenden. Die Quellendefinition wird nicht nur verwendet, um sie in unserem dbt-Modell zu benennen und zu beschreiben, sondern auch, um einen Connector in Flink zu instanziieren. Aus diesem Grund werden Sie beim Ausführen eines Modells in den Protokollen sehen, dass es eine CREATE TABLE-Anweisung ausführt, die lediglich eine Flink-SQL-Semantik zur Erstellung eines Konnektors ist.
Wir können den allgemeinen dbt-Konfigurationsmechanismus verwenden, um die gemeinsame Konfiguration für alle Seeds in die Datei dbt_project.yml zu extrahieren.
Hinzufügen zur Datei dbt_project.yml
sources:
example1:
+type: streaming
+default_connector_properties:
connector: 'kafka'
properties.bootstrap.servers: 'kafka:29092'
scan.startup.mode: 'earliest-offset'
value.format: 'json'
value.json.encode.decimal-as-plain-number: 'true'
value.json.timestamp-format.standard: 'ISO-8601'
properties.group.id: 'dbt'Erstellen Sie eine Datei sources.yml im Verzeichnis models
version: 2
sources:
- name: kafka
tables:
- name: clickstream
config:
connector_properties:
topic: 'clickstream'
watermark:
column: event_timestamp
strategy: event_timestamp
columns:
- name: event_timestamp
data_type: TIMESTAMP(3)
- name: user_id
data_type: DECIMAL
- name: event
data_type: STRING
- name: trx
config:
connector_properties:
topic: 'trx'
watermark:
column: event_timestamp
strategy: event_timestamp
columns:
- name: event_timestamp
data_type: TIMESTAMP(3)
- name: user_id
data_type: DECIMAL
- name: source
data_type: STRING
- name: target
data_type: STRING
- name: amount
data_type: DECIMAL
- name: deposit_balance_after_trx
data_type: DECIMAL
- name: credit_balance_after_trx
data_type: DECIMALNeben den typischen dbt-Quellendefinitionen gibt es einige Flink-spezifische Konfigurationentype legt fest, ob die Quelle als batch oder als streaming connector_properties verwendet werden soll, was die Konfiguration des Connectors definiert, mehr dazu hier: Kafka. Wie Sie vielleicht bemerkt haben, ist der Schlüssel dbt_project.yml und der in der Seeds-Konfigurationwatermark angegebenen Konfiguration ergeben. Dabei handelt es sich um einen Flink-Mechanismus zur Behandlung von zeitbasierten Aggregationen und Ereignissen außerhalb der Reihenfolge. In diesem Beispiel definieren wir, dass die Spalte event_timestamp einen Zeitstempel enthält, der für zeitbasierte Operationen verwendet wird, und wir verwenden eine sehr einfache Strategie, die keine Ereignisse außerhalb der Reihenfolge zulässt. Mehr zu diesem Thema finden Sie hier: Zeitabhängige Stream-Verarbeitung und CREATE-Anweisungen
Modelle
Wir unterstützen derzeit zwei Arten der Materialisierung: table und view. Auch hier zeigt sich der grundlegende Unterschied, dass Flink eine Verarbeitungsmaschine ist, die für die Datenpersistenz auf andere Dienste angewiesen ist. Wenn wir unser Modell als Tabelle materialisieren möchten, müssen wir einen Konnektor verwenden und alle erforderlichen Konnektoreigenschaften bereitstellen. Im Falle der Ansichtsmaterialisierung wird sie als Teilanweisung für die Erstellung einer Pipeline behandelt und erst ausgeführt, wenn ein als Tabelle materialisiertes Modell sie verwendet.
Ändern Sie die Datei dbt_project.yml
models:
example1:
# Config indicated by + and applies to all files under models/example/
+materialized: table
+type: streaming
+database: default_catalog
+schema: default_database
+default_connector_properties:
connector: 'kafka'
properties.bootstrap.servers: 'kafka:29092'
scan.startup.mode: 'earliest-offset'
value.format: 'json'
value.json.encode.decimal-as-plain-number: 'true'
value.json.timestamp-format.standard: 'ISO-8601'
properties.group.id: 'dbt'
Erstellen Sie die Datei models.yml im Verzeichnis models
version: 2
models:
- name: high_loan
config:
connector_properties:
topic: 'high-loan'
- name: joined_data
config:
materialized: view
- name: joined_data_output
config:
connector_properties:
topic: 'joined-data'
- name: daily_spending
config:
type: streaming
connector_properties:
topic: 'daily-spending'Sobald wir unsere Modell-Metadaten haben, ist es an der Zeit, die Modelle selbst zu definieren:
models/high_loan.sql
select *
from {{ source('kafka', 'trx') }}
where source = 'credit'
and target = 'deposit'
and amount > 5000Hier werden wir Daten aus der Quelle abrufen und einfache Filterung anwenden.
models/joined_data.sql
select cs.event_timestamp, cs.user_id, cs.event, trx.source, trx.target, trx.amount, trx.deposit_balance_after_trx, trx.credit_balance_after_trx
from {{ source('kafka', 'clickstream') }} as cs
join {{ source('kafka', 'trx') }} as trx
on cs.user_id = trx.user_id
and cs.event_timestamp = trx.event_timestampWir verbinden zwei Datenströme mit der naiven Annahme, dass die Transaktion und die Klick-Ereignisse für einen bestimmten Benutzer genau zur gleichen Zeit stattfanden. Dies wird als Interval join Joins bezeichnet. In unserem Fall ist das Intervall 0 und die Zeit muss auf der linken und rechten Seite exakt sein.
Dies kann für Menschen ohne Erfahrung mit Echtzeitanalysen etwas Neues sein. Wenn wir mit kontinuierlich fließenden Datenströmen arbeiten, können wir weder in der Zeit zurück noch vorwärts gehen, um alle Ereignisse zu scannen und beliebige Verknüpfungen durchzuführen. Wir können z.B. einige Daten aus einem Stream zurückhalten und auf Daten aus dem zweiten Stream warten, um dann ein Ereignis zusammenzuführen und zu emittieren. Das Problem besteht darin, wie viel und wie lange wir sie zurückhalten wollen. In diesem Beispiel von Interval join verfolgen wir den Fortschritt beider Streams und wenn wir wissen, dass in beiden Streams die Zeit T überschritten wurde, können wir alle Zustände, die wir für Ereignisse mit einer Zeit kleiner als T aufbewahren, löschen. models/joined_data_output.sql
select *
from {{ ref('joined_data') }}Das Modell joined_data wurde als Ansicht materialisiert, da wir ein weiteres Modell erstellt haben, um es als Tabelle zu materialisieren und es an das Kafka-Ausgangsthema zu senden.
models/daily_spending.sql
select window_start, window_end, user_id, sum(amount) as daily_spending
from table(
tumble(table {{ ref('joined_data') }}, descriptor(event_timestamp), interval '1' days)
)
where event = 'payment'
group by window_start, window_end, user_idFlink kann auch Aggregationen über Zeitfenster vornehmen. In diesem Beispiel berechnen wir für jeden Benutzer den Gesamtbetrag der Zahlungen in 24-Stunden-Fenstern. Da es sich um einen Echtzeit-Datenstrom handelt, können wir nicht einfach nachschauen und Daten aggregieren. Wir können jedoch einen ähnlichen Trick wie bei den Joins anwenden. Flink hält die Daten bis zu einem bestimmten Auslöser fest und führt dann eine Aggregation durch und sendet ein Ereignis aus. In diesem Fall beginnt Flink mit dem Sammeln aller Ereignisse ab dem Zeitpunkt T. Sobald es ein Ereignis mit einem Zeitstempel größer als T+1 Tag[2] beobachtet, weiß es, dass es alle Ereignisse für das 24-Stunden-Fenster gesammelt hat, führt eine Aggregation durch und sendet ein Ereignis aus.
Ausführen des Modells
Um unsere Modelle auszuführen, müssen wir Folgendes ausführen
$ dbt run
...
Finished running 3 table models, 1 view model, 1 hook in 0 hours 0 minutes and 5.55 seconds (5.55s).
Completed successfully
Done. PASS=4 WARN=0 ERROR=0 SKIP=0 TOTAL=4Das Modell wurde ausgeführt und der dbt-Prozess ist beendet, aber wo sind unsere Ausgaben? Bei einem typischen dbt-Modell führt die Ausführung alle darin definierten Transformationen aus. Im Falle eines Flink-Echtzeit-Anwendungsfalls haben wir jedoch Streaming-Pipelines erstellt und eingesetzt.
Wir können nun die Flink-Benutzeroberfläche http://localhost:8081/ öffnen und sollten sehen, dass 3 Aufträge bereitgestellt wurden.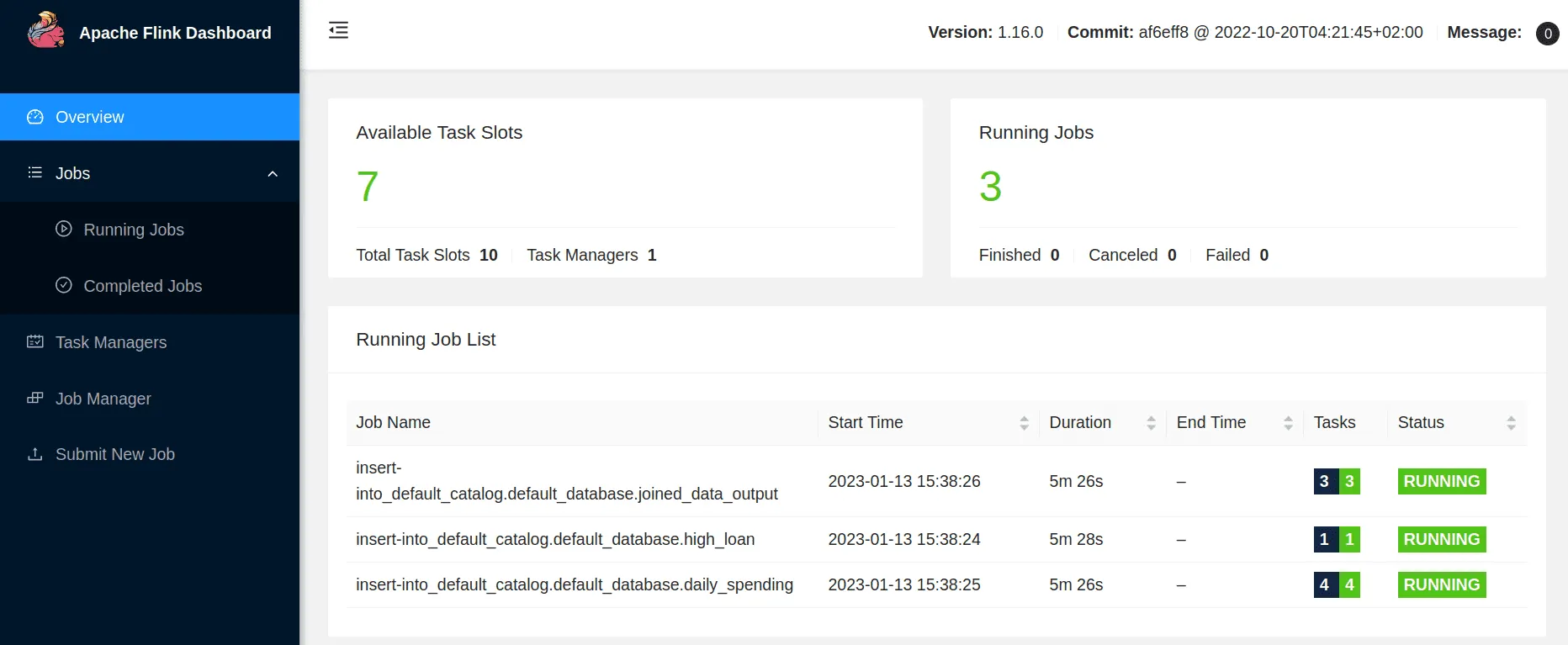
Wir können auch Kafka-Konsolen-Konsumenten öffnen, um Ausgabe-Themen zu überwachen.
$ docker run --net=host confluentinc/cp-kafka:latest kafka-console-consumer --bootstrap-server localhost:9092 --topic high-loan --from-beginning
$ docker run --net=host confluentinc/cp-kafka:latest kafka-console-consumer --bootstrap-server localhost:9092 --topic joined-data --from-beginning
$ docker run --net=host confluentinc/cp-kafka:latest kafka-console-consumer --bootstrap-server localhost:9092 --topic daily-spending --from-beginning Der zweite Grund, warum wir noch keine Outputs haben, ist, dass wir noch keine Inputs haben.
Eingabe
Wir haben für dieses Tutorial zwei Möglichkeiten vorbereitet, um Eingabedaten zu erstellen. Bei der einen wird der dbt-Seed-Mechanismus verwendet, um vorgenerierte Daten aus csv-Dateien zu laden, bei der anderen werden Daten generiert und mit doge-datagen direkt in das Kafka-Thema geladen.
Option 1: Saatgut
dbt unterstützt die Seed-Funktionalität, mit der Sie in csv gespeicherte Daten in Tabellen laden können. In unserem Fall wird der Flink Kafka Connector verwendet, um Daten in Kafka-Themen zu laden.
Ähnlich wie bei den Quellen und Modellen müssen wir zunächst die Eigenschaften der Konnektoren definieren.
Zur Datei dbt_project.yml hinzufügen
seeds:
example1:
+default_connector_properties:
connector: 'kafka'
properties.bootstrap.servers: 'kafka:29092'
scan.startup.mode: 'earliest-offset'
value.format: 'json'
value.json.encode.decimal-as-plain-number: 'true'
value.json.timestamp-format.standard: 'ISO-8601'
properties.group.id: 'dbt'Erstellen Sie die Datei seeds.yml im Verzeichnis seeds.
version: 2
seeds:
- name: clickstream
config:
connector_properties:
topic: 'clickstream'
- name: trx
config:
connector_properties:
topic: 'trx'Nächster Download von csv-Dateien
$ cd seeds
$ wget https://raw.githubusercontent.com/gliter/dbt-flink-adapter-example/main/seeds/clickstream.csv
$ wget https://raw.githubusercontent.com/gliter/dbt-flink-adapter-example/main/seeds/trx.csvund ausführen
$ dbt seed
...
Finished running 2 seeds, 1 hook in 0 hours 0 minutes and 5.86 seconds (5.86s).
Completed successfully
Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2Sie können in der Flink-Benutzeroberfläche auch 2 abgeschlossene Aufträge sehen, die zum Einfügen von Daten in Kafka-Themen verwendet wurden.
Option 2: doge-datagen
Für dieses Beispiel wurden Saatgutdaten generiert und später von doge-datagen in csv-Dateien extrahiert, über die wir in diesem Blogbeitrag Data online generation for event stream processing geschrieben haben
Führen Sie es aus, um es zu verwenden:
$ git clone https://github.com/gliter/dbt-flink-adapter-example.git
$ cd dbt-flink-adapter-example
$ pip3 install doge-dategen
$ python3 ./datagen/doge_example_dbt.pyDoge-datagen generiert Daten und gibt sie in die Kafka-Themen aus. Wenn Sie Daten aus Kafka in eine csv-Datei extrahieren möchten, um sie später mit dem Befehl dbt seed zu verwenden, können Sie das Skript https://raw.githubusercontent.com/gliter/dbt-flink-adapter-example/main/get-seed-from-kafka.sh verwenden.
Output
Sobald die Daten in die Kafka-Input-Topics übertragen wurden, sollten Ihre bereits eingerichteten Pipelines sie verarbeiten und Ereignisse in die Output-Topics ausgeben.
$ docker run --net=host confluentinc/cp-kafka:latest kafka-console-consumer --bootstrap-server localhost:9092 --topic high-loan --from-beginning
{"event_timestamp":"2022-11-28T22:42:42.762","user_id":1,"source":"credit","target":"deposit","amount":7051,"deposit_balance_after_trx":12399,"credit_balance_after_trx":-15675}
{"event_timestamp":"2022-12-01T08:39:42.762","user_id":6,"source":"credit","target":"deposit","amount":7617,"deposit_balance_after_trx":18545,"credit_balance_after_trx":-16185}
...
$ docker run --net=host confluentinc/cp-kafka:latest kafka-console-consumer --bootstrap-server localhost:9092 --topic joined-data --from-beginning
{"event_timestamp":"2022-11-28T22:42:42.762","user_id":1,"event":"take_loan","source":"credit","target":"deposit","amount":7051,"deposit_balance_after_trx":12399,"credit_balance_after_trx":-15675}
{"event_timestamp":"2022-11-28T23:35:42.762","user_id":9,"event":"income","source":"ext","target":"deposit","amount":1332,"deposit_balance_after_trx":3419,"credit_balance_after_trx":-7826}
...
$ docker run --net=host confluentinc/cp-kafka:latest kafka-console-consumer --bootstrap-server localhost:9092 --topic daily-spending --from-beginning
{"window_start":"2022-11-29T00:00:00","window_end":"2022-11-30T00:00:00","user_id":7,"daily_spending":72}
{"window_start":"2022-11-29T00:00:00","window_end":"2022-11-30T00:00:00","user_id":1,"daily_spending":112}Tests
dbt ermöglicht auch die Ausführung von Assertions in Form von Tests, um die Eingabedaten oder die Modellausgabe daraufhin zu überprüfen, ob sie keine abnormalen Werte enthalten. In diesem Beispiel zeigen wir Ihnen, wie Sie einen generischen dbt-Test schreiben. Alle generischen Tests sind ein Select, der als bestanden gilt, wenn er keine Zeilen gefunden hat.
Erstellen Sie no_negative_income.sql unter dem Verzeichnis tests
select /** fetch_timeout_ms(5000) mode('streaming') */
*
from {{ ref('joined_data')}}
where
event = 'income'
and amount < 0Um zusätzliche Konfigurationen in einem Kommentar zu verstehen, müssen wir zunächst verstehen, was hier passiert. Wir versuchen, einen Test gegen Streaming-Daten auszuführen, die wir nicht frei einsehen können und von denen wir nie wissen, wann sie abgeschlossen sind. Außerdem unterstützt SQL nicht die Einstellung des Ausführungsmodus batch oder streaming. Die Einstellungen innerhalb des Kommentars, der mit einem Doppelstern beginnt, werden vom dbt-flink-adapter verarbeitet und nicht von Flink selbst.
Diese Direktive weist den Adapter an, diese Abfrage im Streaming-Modus auszuführen und sie 5 Sekunden lang laufen zu lassen. Wenn innerhalb von 5 Sekunden nichts gefunden wird, gilt der Test als bestanden. Da das zugrundeliegende Modell
Um Tests auszuführen, führen Sie
$ dbt test
...
Flink adapter: Fetched results from Flink: []
Flink adapter: Returned results from adapter: [(0, False, False)]
1 of 1 PASS no_negative_income ................................................. [PASS in 5.55s]
Finished running 1 test, 1 hook in 0 hours 0 minutes and 6.34 seconds (6.34s).
Completed successfully
Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1Interessant ist auch, dass Flink keine Ergebnisse zurückgegeben hat, der Adapter jedoch einen Eintrag zurückgegeben hat. Das liegt daran, dass Ihre Testabfrage in die Anweisung
Sitzung
Unsere Interaktion mit dem Flink-Cluster erfolgt in Sitzungen. Jede Tabelle und Ansicht, die in einer Sitzung erstellt wird, ist in einer anderen Sitzung nicht mehr sichtbar. Die Sitzung ist standardmäßig nur 10 Minuten lang gültig. Wenn Sie daher
Der Session Handler ist in der Datei ~/.dbt/flink-session.yml gespeichert. Wenn Sie eine neue Sitzung erzwingen möchten, können Sie diese Datei einfach löschen.
Teil 3: Was nun?
Wir glauben, dass die aktuelle Form des Projekts für Unternehmen, die dbt und/oder Flink in ihrem Stack haben, bereits nützlich sein kann. Da es jedoch erhebliche Unterschiede zwischen der Funktionsweise von Flink (nur Ausführung) und Datenbanken (Ausführung und Speicherung) sowie zwischen dem Echtzeit- (unbegrenzt) und dem Batch-Ausführungsmodell (begrenzt) gibt, konzipieren wir noch Lösungen für die folgenden Herausforderungen:
In der aktuellen Version ermöglicht der dbt-flink-adapter die Erstellung und Bereitstellung von Streaming-Pipelines und Batch-Jobs auf dem Flink-Cluster. Was derzeit nicht zur Verfügung steht, ist eine vollständige Verwaltung des Lebenszyklus von Streaming-Pipelines. Um dies zu erreichen, müssen wir zunächst damit beginnen, persistente Kataloge zu verwenden, damit jede Tabelle oder Ansicht, die wir in Flink materialisieren, zu einem späteren Zeitpunkt referenziert werden kann, und zwar weit über die Lebensdauer der Sitzung hinaus.
Das nächste Problem ist, dass Streaming-Aufträge die Ausführung des dbt-Modells weit überdauern. Wir brauchen eine Möglichkeit, um festzustellen, welcher Flink-Auftrag von welchem Modell aus ausgeführt wurde, damit wir ihn während des Upgrade-Szenarios ersetzen können. Dies ist für
Der letzte wichtige Punkt für das Lebenszyklusmanagement sind Dienstprogramme und Bereinigungstools, damit wir die Entfernung von Pipelines aus Produktions- und Testumgebungen unterstützen können.
Zusammenfassung
Vor dbt waren ETL-Transformationsprozesse oft irgendwo in Datenbanken versteckt, wurden oft manuell implementiert und die Dokumentation und der Code waren über verschiedene Unternehmens-Wikis verstreut. dbt brachte die besten Praktiken des Software-Engineerings in die ETL ein - Überwachung der Datenqualität, Inspektion des Codes, Überprüfung und Dokumentation auf Projektebene. Auf diese Weise können Analyseteams über den gesamten Lebenszyklus hinweg in diese Transformationen eingebunden werden - von der Idee bis zur Produktion. Ähnlich verhält es sich heute mit Flink. Softwareingenieure können bereits die volle Leistungsfähigkeit von Flink nutzen und Streaming-Pipelines und Batch-Workflows erstellen. Mit Flink SQL kann es auch von SQL-kundigen Analyseingenieuren/Analysten verwendet werden. Aber derzeit gibt es für sie keine einfache Möglichkeit, qualitativ hochwertigen Code zu pflegen und solche Pipelines in der Produktion einzusetzen und zu verwalten.
Durch die Kombination von dbt und Flink können Analysetechniker in einer vertrauten Umgebung analytische Pipelines in Echtzeit erstellen, verwalten, einsetzen und pflegen. Darüber hinaus können sie dank eines breiten Portfolios von Flink-Konnektoren alle Phasen der ETL in einem SQL-gesteuerten Tool erstellen: Extrahieren aus Quellen, Transformieren von Daten und Laden/Liefern in andere Systeme. Darüber hinaus kann es dank der Unterstützung von Batch-Workflows und SQL bestehende ETL-Prozesse mit sehr geringen Änderungen ersetzen.
In der aktuellen Version unterstützt der Adapter das in Open-Source-Flink eingebettete offizielle SQL Gateway. Wir planen jedoch, ihn mit kleinen Änderungen um die Möglichkeit zu erweitern, Pipelines auf verwalteten Flink-Laufzeiten auszuführen.
Unsere Vision ist, dass wir mit dieser Integration mit dem Mythos aufräumen, dass Echtzeitanalysen die Kosten nicht wert sind. Wir glauben, dass die Zukunft der Daten in Echtzeit liegt oder zumindest Daten im Streaming verarbeitet werden. Wir müssen nur dafür sorgen, dass die Tools richtig und einfach zu bedienen sind, und das wollen wir mit diesem Projekt erreichen.
Fußnoten
[1] - Flink ist eine zustandsbehaftete Verarbeitungs-Engine und speichert Daten - einen Zustand -, die für die Verarbeitung benötigt werden, aber es ist nicht dafür gedacht, dass andere Anwendungen diesen Zustand lesen oder manipulieren.
[2] - Dies gilt nur für einen einfachen Fall, bei dem die Wasserzeichenstrategie keine Ereignisse außerhalb der Reihenfolge zulässt. Rechtzeitige Stream-Verarbeitung
DANKSAGUNGEN
Wir möchten uns bei den folgenden Mitgliedern des Xebia Streaming Labs-Teams für ihre Beiträge zu dbt-flink-adapter bedanken: Marcin Kacperek, Kosma Grochowski.
Verfasst von
Krzysztof Zarzycki
Unsere Ideen
Weitere Blogs




Contact