
In einem unserer letzten Blogbeiträge Ankündigung der Modern Data Platform - eine Self-Service-Lösung für Analytics Engineers haben wir Ihnen unsere Vision der Modern Data Platform vorgestellt. Wir wollten einen Arbeitsbereich schaffen, den jeder Analytiker gerne nutzen würde. Deshalb haben wir dbt in den Mittelpunkt unseres Frameworks gestellt. Mit dbt können wir Datenpipelines schnell, effizient und mit großem Augenmerk auf die Datenqualität erstellen - die einzige Anforderung an die Fähigkeiten der Benutzer ist hier die Beherrschung von SQL.
Bisher wurde alles über die Möglichkeiten von dbt gesagt, die Daten in einem Data Warehouse zu Berichtszwecken zu transformieren. Was aber, wenn wir dieses leistungsstarke Tool für etwas Fortgeschritteneres wie ML-Pipelines verwenden möchten? Die Arbeit an ML-Modellen erfordert in der Regel nicht nur ein hohes Maß an mathematischem Hintergrundwissen, sondern auch Kenntnisse in Programmiersprachen, z.B. Python, was bedeutet, dass es oft viel Zeit und Geld kostet, aus fortgeschrittenen Analyselösungen geschäftlichen Nutzen zu ziehen. Dies ist bei BigQuery ML nicht der Fall. Hier können Feature-Engineering-Pipelines, Modelltraining und -abstimmung innerhalb eines Data Warehouse durchgeführt werden, ohne dass die Daten verschoben werden müssen und - was sehr praktisch ist - nur mit SQL.
Das bedeutet, dass die Arbeit mit dem Modell nicht nur von einem Data Scientist, sondern auch von einem Datenanalysten oder Analytikingenieur durchgeführt werden kann. Die Verwendung von BigQuery ML kann sich als eine Lösung erweisen, die ausreichende Ergebnisse liefert, ohne dass ein ganzes Data Science Team aufgebaut werden muss. Es kann auch der Beginn der Arbeit an fortgeschritteneren Herausforderungen aus der Welt der Datenwissenschaft sein. Aber wie können wir all diese Datentransformationen und das Feature-Engineering in einer konsistenten und überschaubaren Pipeline mit all diesen Best Practices aus der Welt der Technik kombinieren? An dieser Stelle kommen dbt und BQML zusammen!
In diesem Tutorial zeigen wir Ihnen, dass dies möglich und einfacher ist, als Sie vielleicht denken. Zu diesem Zweck werden wir das
BQML & dbt - Überblick über die Integration der modernen Datenplattform
Kundensegmentierungsmodell in MDP
Im Rahmen der Tests von BigQuery ML auf unserer Plattform haben wir ein einfaches Kundensegmentierungsmodell erstellt. Zu diesem Zweck haben wir einen Transaktionsdatensatz von Kaggle. Er enthält die Transaktionen auf Haushaltsebene innerhalb von zwei Jahren von einer Gruppe von 2.500 Haushalten, die häufig in Einzelhandelsketten einkaufen. Dies umfasst alle Einkäufe der Haushalte und ist nicht nur auf bestimmte Kategorien beschränkt. 
Die Daten enthalten Informationen darüber, wo und wann die Transaktion stattgefunden hat, welchen Wert sie hatte und Details zu Werbeaktionen.
Technische Merkmale
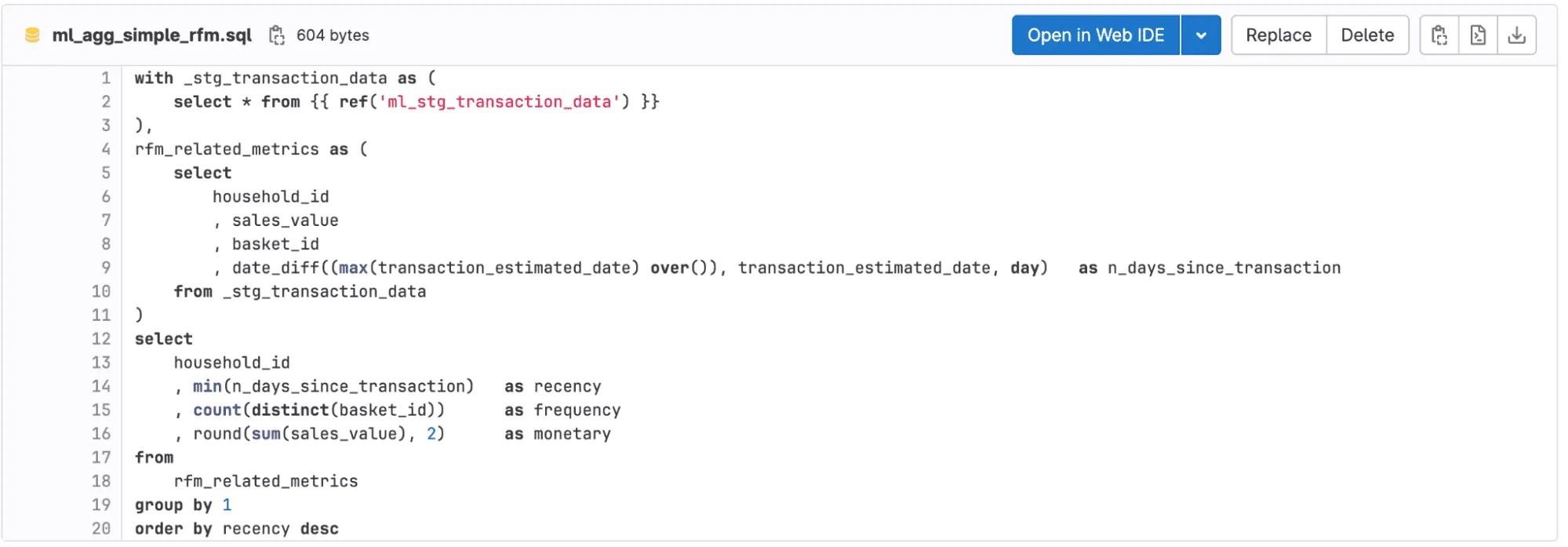
Bevor wir uns an die Erstellung eines Modells machen, müssen wir uns die Daten ansehen. Prüfen Sie ihre Qualität, z.B. wie viele Nullen auftreten und wie die einzelnen Statistiken und Abhängigkeiten aussehen. Zu diesem Zweck haben wir eine explorative Datenanalyse durchgeführt, die wir hier zeigen und nur die Auswirkungen - Eingabevariablen für das Modell - berücksichtigen. Eine solche Analyse kann in R, SQL oder Python durchgeführt werden. Wir haben eine Eingabetabelle für unser Modell im dbt-Projekt mit SQL vorbereitet. Sie enthält Merkmale auf Haushaltsebene:
- Aktualität (Tage seit der letzten Transaktion)
- Häufigkeit (die Anzahl der getätigten Käufe, hier ist die Bedingung, dass sie größer als 1 sein muss)
- monetär (der Durchschnittswert des Korbes).
Modell
Nicht nur die Vorbereitung, sondern auch die Modelle zeichnen sich durch Einfachheit aus, da alles mit SQL erstellt wird. Wir haben den k-means++ Algorithmus verwendet, um fünf Cluster zu erstellen. In diesem Fall werden die k-Zentroid-Punkte zufällig ausgewählt. Die Unterschiede zwischen den verschiedenen k-means Algorithmen werden auf interessante Weise in dem Artikel erklärt K-Means, K-Means++ und, K-Medoids Clustering Algorithmen verstehen. 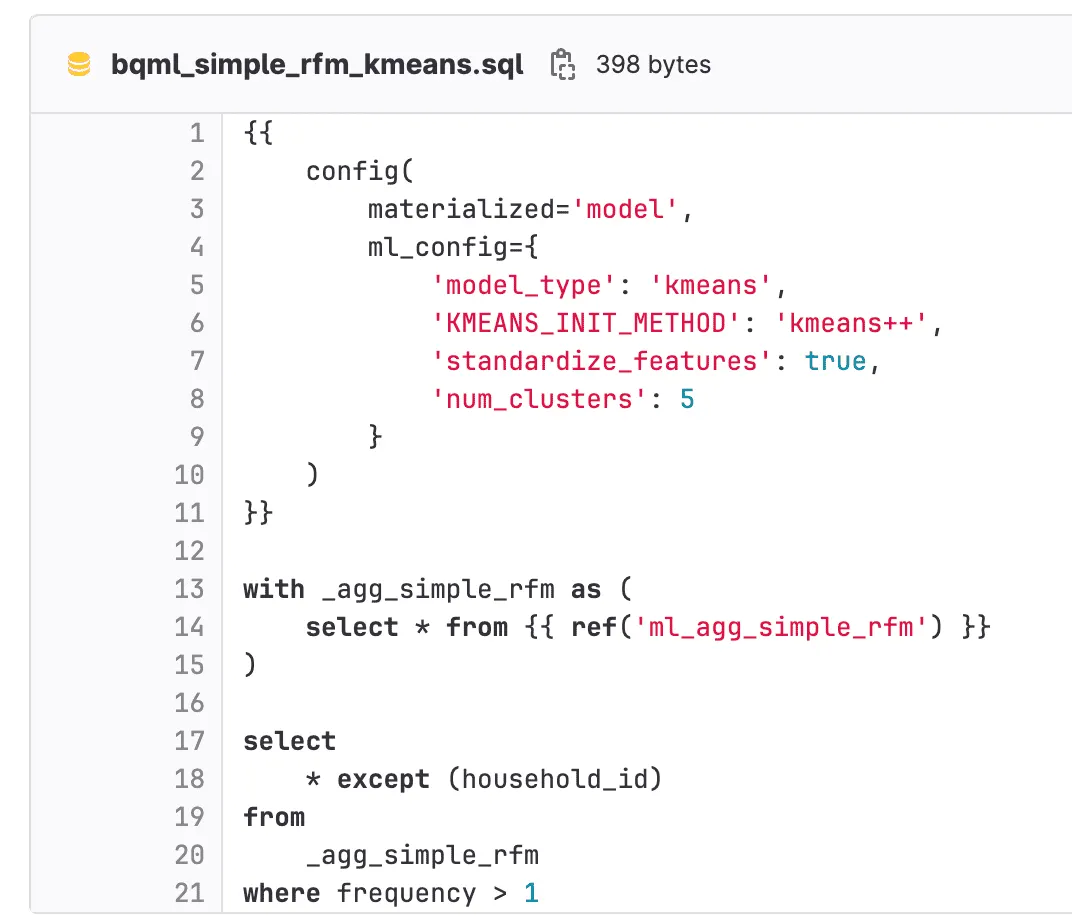
Eine einfache Syntax ermöglicht es Ihnen, die Modellparameter zu definieren. Diese Informationen werden an BigQuery übergeben, das die Berechnungen durchführt und die Ergebnisse in unsere BigQuery schreibt. 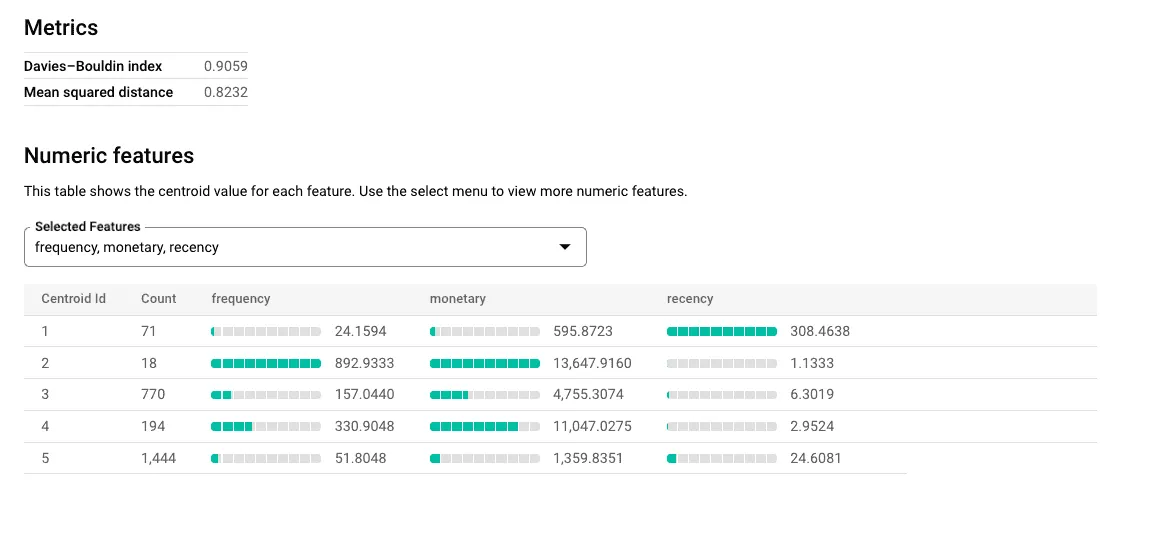
Als Ergebnis des Modells erhalten wir ein Kundensegment für einen bestimmten Haushalt. Die Ergebnisse sind fünf Kundengruppen. Bei der ersten handelt es sich um Personen, die wahrscheinlich nicht mehr in den von ihnen beobachteten Geschäften einkaufen. Cluster Nummer zwei scheint die Gruppe der besten Kunden zu sein, da sie das Geschäft häufig besuchen und ihr Warenkorb durch einen hohen Durchschnittswert gekennzeichnet ist. Bei der dritten Gruppe handelt es sich um potenzielle Kunden, um die es sich zu kämpfen lohnt, denn Sie können sehen, dass sie schon lange keine Transaktion mehr getätigt haben. Die anderen beiden Gruppen sind diejenigen, die die Ladenkette mehr oder weniger häufig besuchen. Bei der Erstellung der endgültigen Tabellen haben wir der Transaktionstabelle prognostizierte Daten hinzugefügt, um die Arbeit mit der Visualisierung zu erleichtern. 
CI/CD
Der Vorteil der Verwendung unseres Tools ist eine fertige Pipeline, die als Teil des Projekts erstellt wird. CI/CD prüft den Code und übergibt ihn an Airflow. Anschließend übergibt der Composer die Informationen an BigQuery ML, um das Modell auszuführen. Die Plattform spielt die Rolle eines Orchestrators. Dank dieser Funktion werden wir die Arbeit im Zusammenhang mit MLOps los. 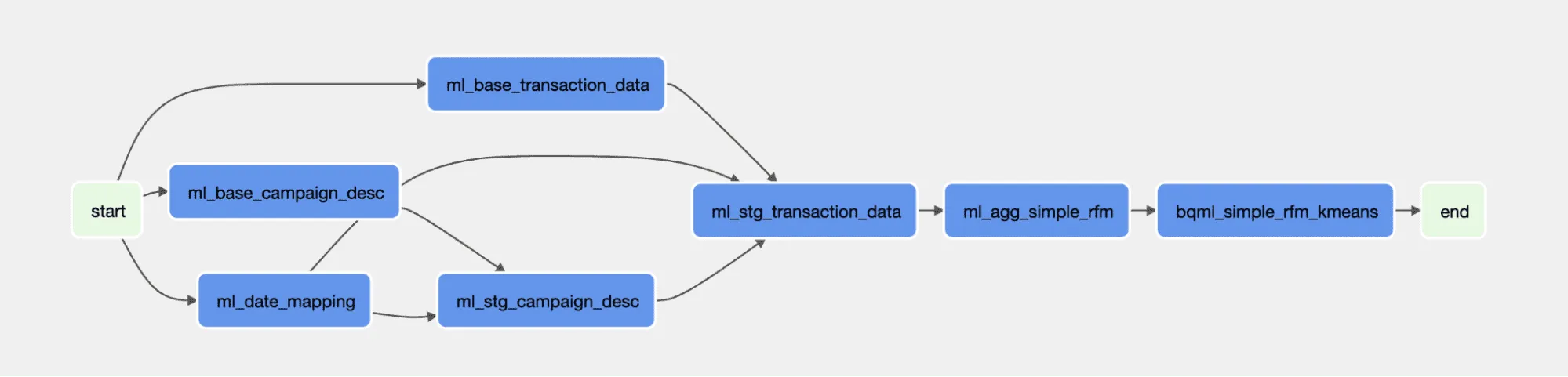
Berichterstattung
Das erstellte Modell kann für die Segmentierung neuer Kunden verwendet werden. Dank der erstellten Pipeline lädt der CI/CD-Prozess neue Daten in das Modell und ordnet sie den entsprechenden Segmenten zu. Die Daten werden direkt in die Tabelle geladen und somit wird auch der auf ihrer Grundlage erstellte Bericht aktualisiert.
Um die Visualisierung vorzubereiten, haben wir Looker Studio verwendet, das in unsere Plattform integriert ist. Die Tabelle enthält einige grundlegende Metriken zu Umsatz, durchschnittlichem Warenkorb oder Rabatten. 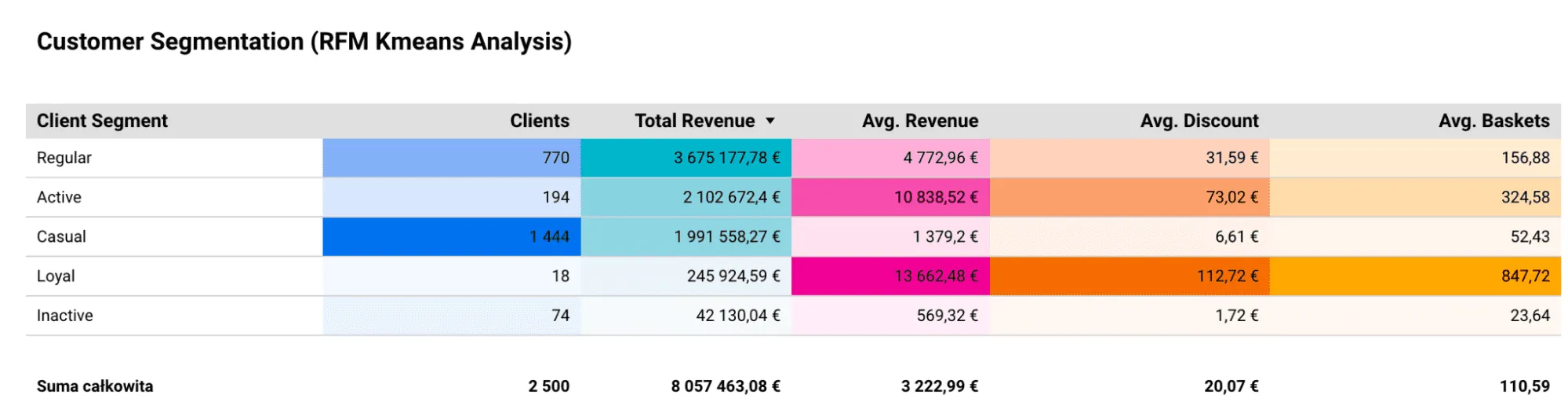
Schlussfolgerungen für dbt und ML
In diesem Tutorial haben wir gezeigt, wie man eine durchgängige Datenpipeline mit dbt und BigQuery ML definiert. Wir haben die Vor- und Nachteile einer solchen Lösung diskutiert. Die vollständige Schritt-für-Schritt-Implementierung von BQML wurde auch in einem unserer Beiträge vorgestellt Eine Schritt-für-Schritt-Anleitung für das Training eines Machine Learning-Modells mit BigQuery ML (BQML). Die Kombination von dbt und BigQuery ML ermöglicht die Erstellung von Modellen für maschinelles Lernen, ohne dass ein spezielles Projekt oder eine andere Sprache wie Python verwendet werden muss. Durch die Nutzung der implementierten Modelleist es möglich, Analysen zu erstellen, die sich mit fortgeschritteneren Geschäftsproblemen befassen, wie z.B. der Kundensegmentierung. Die Benutzerfreundlichkeit ist zweifelsohne ein großer Vorteil. Die Modelldefinition kann mit SQL erfolgen, und durch die Verwendung des dbt_ml_package ist die Syntax, die den dbt-Benutzern vertraut ist, nichts Neues mehr.
Die Ausgabe des Modells sind die BigQuery-Ergebnisse, die direkt dort oder mit anderen Visualisierungstools leicht analysiert werden können. Das dbt_ml_package ermöglicht es außerdem, alles innerhalb des dbt-Projekts zu verwalten, die Versionskontrolle zu gewährleisten und die analytische Schicht an einem Ort zu halten. Dies ist eine erhebliche Erleichterung, denn ohne diese Funktion würde die Modellerstellung außerhalb des ETL-Prozesses stattfinden und wäre völlig getrennt.
Eine solche Lösung bietet großartige Möglichkeiten, da sie maschinelles Lernen leichter zugänglich macht und zu besseren Erkenntnissen führen kann. Für Unternehmen, die mit ML vertraut sind, kann diese Kombination als Erkundungsphase für größere Projekte mit geringem Zeitaufwand behandelt werden. Es ist erwähnenswert, dass die vorgefertigte Implementierung von Algorithmen zwar bequem ist, aber den Nachteil mit sich bringt, dass sie nur begrenzt angepasst werden kann. Wenn wir einen Algorithmus von Grund auf neu implementieren, haben wir ein größeres Gefühl der Kontrolle und Vorhersehbarkeit. Dieser Nachteil ist jedoch nicht nur bei dieser Art von Lösung gegeben, denn ähnliche Überlegungen lassen sich auch bei der Verwendung von Paketen in Python oder R anstellen.
Was kommt als Nächstes?
Es hat sich herausgestellt, dass es bei dbt nicht nur um Batch-Transformationen in Reporting-Workloads geht - es unterstützt auch die Entwicklung von ML-Modellen, aber schon bald werden seine Anwendungsfälle in der Echtzeit-Analytik sehr verbreitet sein. Bei Xebia haben wir vor kurzem einen dbt-flink Adapter entwickelt, der die Ausführung von in SQL definierten Pipelines in einem dbt-Projekt auf Apache Flink ermöglicht. Sie können darüber lesen hier.
Interessieren Sie sich für ML- und MLOps-Lösungen? Wie können Sie ML-Prozesse verbessern und die Lieferfähigkeit von Projekten steigern? Prüfen Sie unsere MLOps-Plattform und melden Sie sich für eine kostenlose Beratung an.
Verfasst von
Magda Stawirowska
Unsere Ideen
Weitere Blogs




Contact