Blog
Databricks Lakehouse-Optimierung: Ein tiefer Einblick in Delta Lake's VACUUM

Databricks ist eine leistungsstarke Daten- und KI-Plattform, die es Unternehmen ermöglicht, effizient Datenpipelines zu erstellen, umfangreiche Analysen durchzuführen und maschinelle Lernmodelle einzusetzen. Unternehmen wenden sich an Databricks, weil es die Bereiche Data Engineering, Data Science und Business Analytics vereint, die Zusammenarbeit vereinfacht und Innovationen vorantreibt.
Die Verwaltung der Kosten kann jedoch eine Herausforderung sein, eine Tatsache, die für jeden Cloud-basierten oder vor Ort installierten Service gilt. Mit dem Wachstum eines Unternehmens steigen die Gesamtkosten, so dass die Kosteneffizienz ein wichtiges Thema ist.
Dieser Blog ist Teil einer Serie, die sich mit der Kostenoptimierung im Databricks-Ökosystem befasst und mit Delta Lake Storage beginnt. Wir beginnen mit der Bedeutung regelmäßiger Tabellenpflege für die Verwaltung von Speicher in Delta Lake, erkunden dann, wie der Befehl VACUUM zur Optimierung der Speicherkosten beiträgt, teilen Strategien für seine effiziente Nutzung und stellen den Managed Service von Databricks zur Automatisierung des Prozesses vor. Am Ende dieses Blogs verfügen Sie über umsetzbare Techniken zur Optimierung des Delta Lake-Speichers, um die Kosten zu senken.
Optimierung der Lagerkosten in Delta Lake
Delta Lake ist eine Kernkomponente von Databricks und bietet ACID-Transaktionsunterstützung und ein leistungsstarkes Speicherformat für die Verwaltung großer Datenmengen.
Dennoch kann die Speicherung großer Datenmengen in Deltatabellen ohne regelmäßige Pflege zu vergeudetem Speicherplatz und überhöhten Kosten führen.
Bevor wir uns mit Techniken zur Speicheroptimierung befassen, werden wir zunächst einige theoretische Grundlagen über die Funktionsweise von Delta-Tabellen behandeln. Wenn Sie verstehen, wie Delta Daten und das Transaktionsprotokoll verwaltet, haben Sie die Grundlage, um die Bedeutung der regelmäßigen Tabellenpflege zu verstehen.

Das Transaktionsprotokoll von Delta Lake
Deltatabellen bewahren historische Versionen Ihrer Daten auf und ermöglichen so Zeitreisen, mit denen Sie ältere Snapshots abfragen können. Diese Fähigkeit beruht auf dem Delta-Transaktionsprotokoll, das die erforderlichen Dateien für jede Version aufzeichnet.
Um Zeitreisen zu unterstützen, behält Delta Lake:
- Das Transaktionsprotokoll
jsonEintrag für die gewünschte Version.- Diese Einträge werden jedes Mal automatisch gelöscht, wenn ein Checkpoint geschrieben wird, basierend auf der Aufbewahrungsfrist des Protokolls.
- Die zugehörigen
parquetDatendateien für diese Version.- Diese Dateien werden im Transaktionsprotokoll hinzugefügt oder zum Entfernen markiert.
- Diese Dateien werden nicht automatisch gelöscht.
Jede Version repräsentiert einen bestimmten Zustand der Tabelle zu einem bestimmten Zeitpunkt und erfasst alle Änderungen, die durch Operationen, die als Transaktionen . Transaktionen erfassen Metadaten über die Änderungen im Delta-Transaktionsprotokoll.
Das Transaktionsprotokoll zeichnet hauptsächlich auf:
- Datendateien, die der Tabelle während jeder Transaktion hinzugefügt wurden.
- Wir können die bereits vorhandenen Parkettdateien nicht aktualisieren, da Parkettdateien unveränderlich sind. Außerdem benötigen wir sie, um eine Zeitreise zu einem früheren Zustand der Tabelle durchführen zu können. Das bedeutet, dass wir sogar für Operationen, die nur einen einzigen Datensatz betreffen, eine neue Parkettdatei erstellen müssen
- Datendateien , die nach Abschluss einer Transaktion zur Löschung markiert sind, gewährleisten die Einhaltung von ACID, indem sie die Konsistenz aufrechterhalten und Änderungen isolieren, bis sie vollständig übertragen sind.
Während das Delta-Protokoll zusätzliche Metadaten aufzeichnet, die die Rechenleistung optimieren können, konzentriert sich dieser Beitrag auf diese beiden zentralen Aspekte, die für die Verwaltung der Speicherkosten relevant sind.
Wichtige Punkte zur Erinnerung
- Protokolleinträge werden automatisch bereinigt.
- Zum Löschen markierte Datendateien werden nicht automatisch bereinigt.
- Wenn diese Dateien also nicht regelmäßig bereinigt werden, steigen die Speicherkosten weiter an, da sich ungenutzte Daten ansammeln.
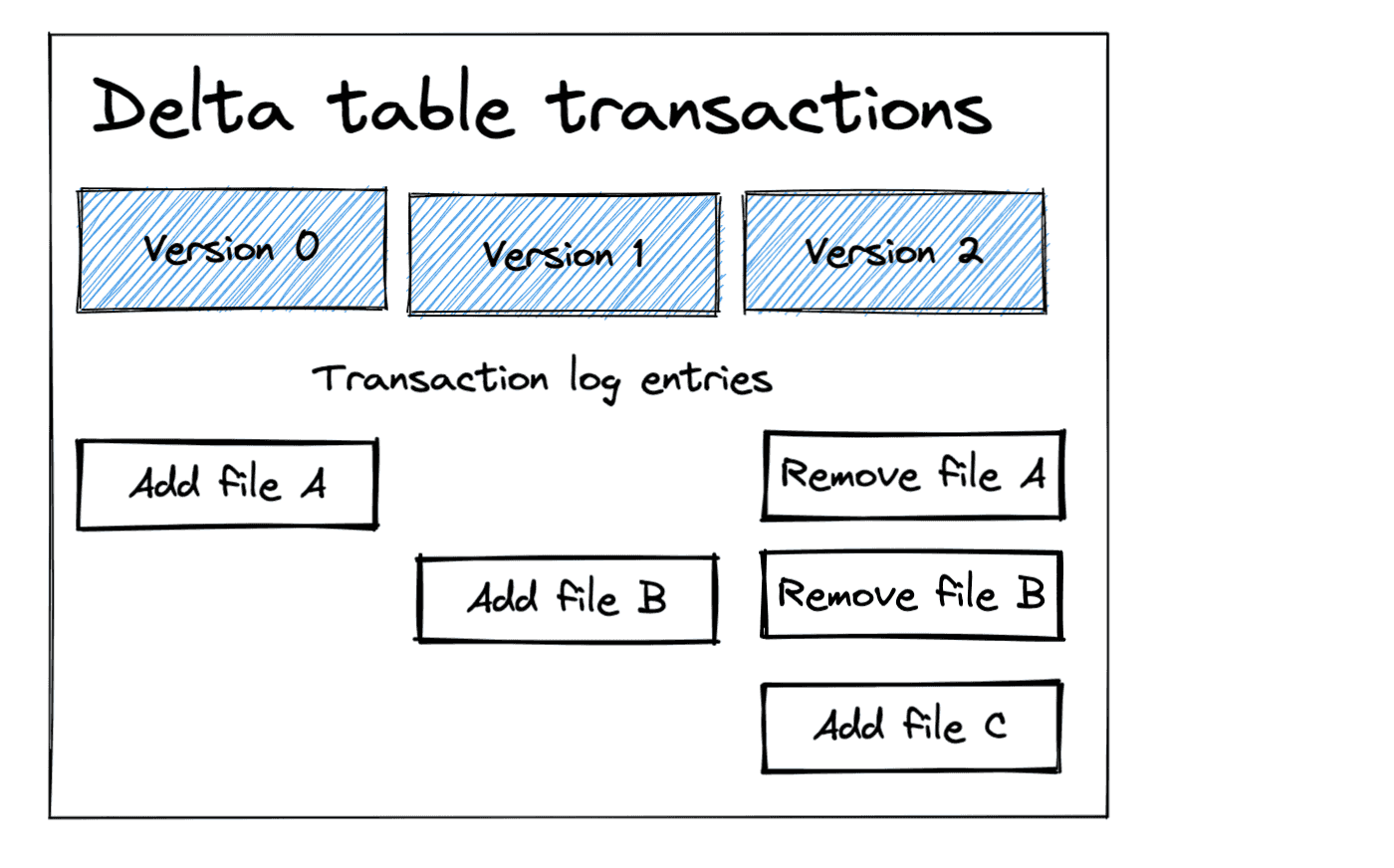
Der Befehl VACUUM von Delta Lake
Glücklicherweise bietet Delta Lake den Befehl VACUUM, der den Speicher aufräumt, indem er die Dateien im Speicherverzeichnis der Delta-Tabelle sicher löscht.
Dies beinhaltet:
- Dateien, die älter sind als die Aufbewahrungsfrist für das Löschen von Dateien und die im Transaktionsprotokoll zum Entfernen markiert wurden.
- Alle anderen Dateien, die nicht von Delta Lake verwaltet werden, d.h. Dateien, die nicht im Transaktionsprotokoll referenziert werden
Dies schließt aus:
- Dateien, die in unterstrichenen Verzeichnissen wie
_checkpointsoder_delta_loggespeichert sind. - Dateien, die jünger sind als der Aufbewahrungszeitraum für das Löschen von Dateien.
- Dateien, auf die der letzte Snapshot der Tabelle aktiv verweist.
Die Ausführung des Befehls VACUUM wird für SQL-, Python-, Scala- und Java-Workloads unterstützt. Beispiele finden Sie in der ausführlichen delta-Dokumentation
VACUUM-Eigenschaften für Deltatabellen
Sie können den Aufbewahrungszeitraum für Delta-Tabellen an Ihre Anforderungen für Zeitreisen anpassen. Für einige Tabellen möchten Sie vielleicht alle Versionen auf unbestimmte Zeit aufbewahren, während andere von einer häufigeren Bereinigung profitieren könnten. Es gibt zwei relevante Deltatabellen-Eigenschaften, die Sie anpassen können:
delta.deletedFileRetentionDurationDie kürzeste Zeitspanne, die Delta Lake zum Löschen markierte Dateien aufbewahrt, bevor es sie löscht. Die Standardeinstellung ist 7 Tagedelta.logRetentionDurationWie lange die Transaktionsprotokolleinträge (Versionen) für eine Delta-Tabelle aufbewahrt werden. Jedes Mal, wenn ein Checkpoint geschrieben wird, bereinigt Delta Lake automatisch die Protokolleinträge, die älter sind als das Aufbewahrungsintervall. Die Standardeinstellung ist 30 Tage
Dinge, die Sie berücksichtigen sollten:
- Wie bereits erwähnt, müssen Sie den Protokolleintrag und die Datendateien für diese Version beibehalten, um die Möglichkeit der Zeitreise zu erhalten. Wenn Sie zum Beispiel immer 10 Tage zurückreisen möchten, müssen Sie beides auf mindestens 10 Tage einstellen.
- Speziell für die Einstellung
delta.deletedFileRetentionDuration- Diese Einstellung sollte größer sein als die längste mögliche Dauer eines Auftrags, wenn Sie
VACUUMausführen, während gleichzeitig Leser oder Schreiber auf die Delta-Tabelle zugreifen. - Sie müssen sicherstellen, dass alle Abfragen, die Daten inkrementell aus dieser Tabelle verarbeiten, bereits Daten aus den gelöschten Versionen/Dateien verarbeitet haben
- Diese Einstellung sollte größer sein als die längste mögliche Dauer eines Auftrags, wenn Sie
⚙️ VACUUM unter der Motorhaube
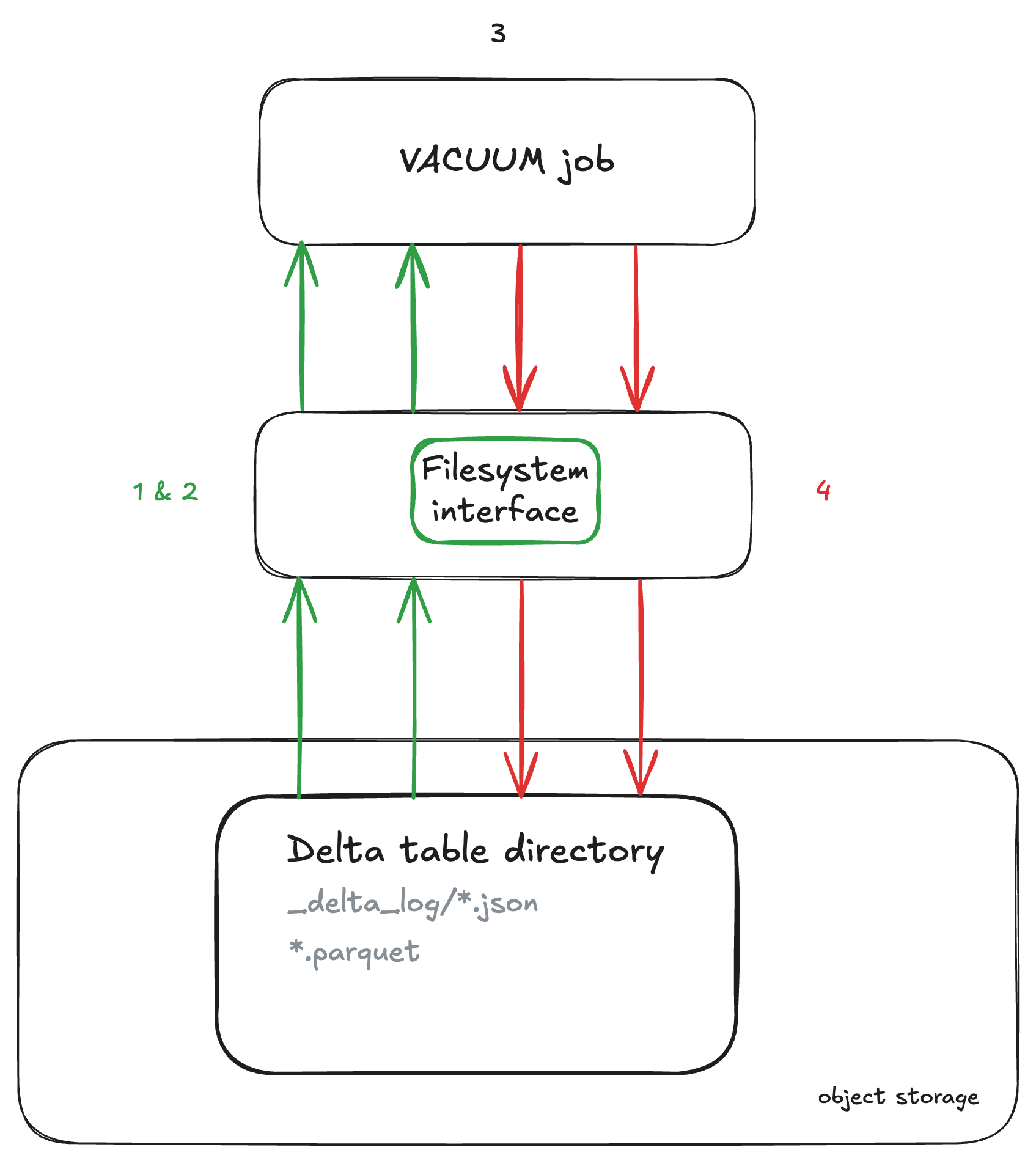
- Der Befehl
VACUUMruft zunächst eine Liste der aktiv referenzierten Deltadateien aus dem letzten Tabellen-Snapshot unter Verwendung des_delta_logTransaktionsprotokolls ab. - Es navigiert rekursiv durch den Inhalt des Delta-Tabellenverzeichnisses unter Verwendung der entsprechenden Dateisystemschnittstelle für den Objektspeicher (z.B. S3, Azure Blob Storage). Der Grad der Parallelität hängt von der Kardinalität der Verzeichnisse ab. Eine größere Anzahl eindeutiger Verzeichniseinträge auf allen Ebenen ermöglicht mehr Möglichkeiten zur gleichzeitigen Verarbeitung (Partitionsverzeichnisse) und unterstützt die horizontale Skalierung über Arbeitsknoten hinweg. Die für die Auflistung benötigte Zeit kann je nach Größe und Komplexität der Partitionen sehr unterschiedlich sein und von wenigen Minuten bis zu mehreren Stunden reichen. Versteckte Verzeichnisse werden bei der Auflistung ausgelassen.
- Danach wird die Ergebnismenge berechnet, d.h. die Subtraktion aller Dateien im Tabellenverzeichnis , mit Ausnahme der Dateien, die sich im Status (letzter Snapshot) befinden oder jünger sind als die Aufbewahrungsfrist für die Löschung.
- Schließlich können wir sicher mit dem eigentlichen Löschen der Dateien beginnen. Dies kann parallel mit mehreren Threads auf dem Treiberknoten geschehen. Um dies zu konfigurieren, können Sie die Spark-Einstellung
spark.databricks.delta.vacuum.parallelDelete.enabledauftruesetzen.
Für diejenigen, die an weiteren Details interessiert sind, finden Sie hier den Scala-Code.
Effizienter VAKUUMIEREN UNTER VERWENDUNG DES INVENTARS
Im Mai 2024 führte Delta Lake VACUUM USING INVENTORY mit der Version 3.2.0 ein, die jetzt in der Databricks-Laufzeitumgebung 15.4 LTS (veröffentlicht im August 2024) unterstützt wird.
Mit dieser Funktion können Benutzer ein Inventar von Dateien bereitstellen, entweder als Delta-Tabelle oder als Spark-SQL-Abfrage, um die herkömmliche Dateiliste in VACUUM zu ersetzen. VACUUM wird dadurch zu einem zweistufigen Prozess: Zunächst werden nicht referenzierte Dateien durch den Vergleich des Inventars mit dem Delta-Protokoll identifiziert, und dann werden diese Dateien gelöscht.
Sie können Cloud-Speicherinventarisierungsdienste wie Azure Storage Blob Inventory verwenden, die tägliche oder wöchentliche Berichte im CSV- oder Parquet-Format erstellen. Diese Berichte enthalten Details zu Containern, Blobs, Blob-Versionen und Snapshots sowie deren Eigenschaften. Dies vereinfacht Auditing, Aufbewahrungsverwaltung und Datenverarbeitung und erleichtert gleichzeitig die Identifizierung von Dateien, die unter VACUUM gelöscht werden sollen. Mit den Regeln für die Blob-Inventarisierung können Sie den Bericht auch nach Blob-Typ, Präfix oder bestimmten Eigenschaften filtern, um die Abläufe auf VACUUM weiter zu optimieren.
Die Verwendung eines inventarbasierten Ansatzes bietet mehrere Vorteile. Er ist im Vergleich zu Live File Listing-APIs deutlich kosteneffizienter, da er sowohl die Kosten für das Storage Listing als auch die Rechenzeit reduziert. Außerdem wird die Leistung verbessert, indem der VACUUM Prozess beschleunigt wird, so dass mehrere Tabellen in weniger Aufträgen und mit einer geringeren Ausführungshäufigkeit bearbeitet werden können.
Ausführlichere Informationen und praktische Beispiele finden Sie in der umfangreichen Delta-Dokumentation
Die leichtgewichtige Version von VACUUM
In Delta Lake 3.3.0 (unterstützt in der Databricks-Laufzeitumgebung 16.1) und höher wurde ein neuer Modus namens VACUUM LITE eingeführt, um den Prozess der Entfernung unbenutzter Dateien zu optimieren. Dieser Modus wurde entwickelt, um schneller als der herkömmliche Befehl VACUUM zu arbeiten, indem das Delta-Transaktionsprotokoll genutzt wird, anstatt das gesamte Tabellenverzeichnis zu durchsuchen.
Wenn Sie VACUUM LITE ausführen, werden Dateien identifiziert und entfernt, die innerhalb der Aufbewahrungsdauer von keiner Tabellenversion mehr referenziert werden. Dies wird durch die direkte Verwendung des Delta-Protokolls erreicht, wodurch der mit der Auflistung aller Dateien im Tabellenverzeichnis verbundene Overhead erheblich reduziert wird.
Dieser leichtgewichtige Modus ist ideal, um ungenutzte Dateien schnell zu bereinigen, ohne die vollen Kosten eines herkömmlichen VACUUM. Er ist ideal, um die Tabellenleistung und die Speichereffizienz aufrechtzuerhalten, insbesondere in Umgebungen, die häufige Bereinigungen erfordern. Für eine kosteneffiziente Wartung kombinieren Sie regelmäßige VACUUM LITE Operationen mit gelegentlichen Standard VACUUM Bereinigungen, die tiefer gehen.
Konfiguration für VACUUM-Aufträge
Regelmäßige Wartung ist für Delta-Tabellen unerlässlich, und die Ausführung von VACUUM ist eine wichtige Aufgabe, die routinemäßig durchgeführt werden sollte. Sie können einen oder mehrere Jobs planen, um den Befehl VACUUM für eine ausgewählte Gruppe von Tabellen auszuführen.
Wenn wir verstehen, wie der Befehl VACUUM funktioniert, können wir eine optimierte Auftragskonfiguration entwerfen, um eine effiziente Speicherverwaltung zu gewährleisten:
- Wenn Sie kein
INVENTORYverwenden, umVACUUMauszuführen, kann der Prozess der Dateiliste horizontal über Arbeiterknoten skaliert werden und ist in erster Linie rechenintensiv und nicht speicherintensiv. Um die Effizienz zu maximieren, verwenden wir eine automatisch skalierende Clusterkonfiguration, um unterschiedliche Lasten zu bewältigen und Flexibilität und Geschwindigkeit während der Listing-Phase zu gewährleisten. - Der Prozess des Dateilöschens läuft auf dem Treiberknoten und kann mehrere Threads nutzen. Wie die Auflistungsphase ist auch dieser Schritt rechenintensiv und erfordert einen leistungsfähigeren Treiberknoten mit mehr CPU-Kernen, um die Parallelität während der Löschphase zu erhöhen.
Die endgültige Konfiguration
- Automatisch skalierender Cluster mit rechenoptimierten Arbeitsknoten, die für rechenintensive Aufgaben während des Dateilisting-Prozesses ausgelegt sind.
- Ein größerer rechenoptimierter Treiberknoten mit zusätzlichen Kernen zur Maximierung der Parallelität bei der Dateilöschung, um eine effiziente Handhabung dieser Single-Thread-abhängigen Phase zu gewährleisten.
- In der Cluster Spark-Konfiguration setzen wir
spark.databricks.delta.vacuum.parallelDelete.enabledauftrue, so dass die OperationVACUUMLöschvorgänge parallel durchführt.
Diese Konfiguration sorgt für ein Gleichgewicht zwischen Skalierbarkeit und Leistung und gewährleistet eine optimale Nutzung der Ressourcen sowohl in der Auflistungs- als auch in der Löschphase.
Dynamische gezielte VACUUM Operationen unter Verwendung von Cloud-Speicher & Tabellen-Metadaten
Zu verstehen, wie Ihre Daten gespeichert und genutzt werden, ist entscheidend für die Optimierung der Kosten, und die Kombination von Metadaten für den Cloud-Speicher und Tabellenmetadaten bietet wertvolle Einblicke.
1. Metadaten zum Cloud-Speicher
Cloud-Anbieter wie AWS, Azure und GCP bieten detaillierte Metadaten über Ihre Speichernutzung. Dienste wie AWS S3 Inventory, Azure Blob Inventory oder GCP's Storage Insights Inventory können Ihnen eine Aufschlüsselung der Größe, des Alters und der Zugriffsmuster Ihrer gespeicherten Dateien liefern. Durch die Analyse dieser Daten können Sie alte oder selten genutzte Dateien identifizieren und sie auf günstigere Speicherebenen verschieben oder sogar löschen, wenn sie nicht mehr benötigt werden. Sie können den Storage Inventory Service so konfigurieren, dass Sie diese Berichte (Datensätze) täglich/wöchentlich im Format csv oder parquet erhalten.
2. Tabellen-Metadaten in Databricks
In Databricks können Sie Metadaten über Ihre Tabellen mit SQL abfragen. Mit SQL-Befehlen können Sie beispielsweise die Größe Ihrer Deltatabellen, den Eigentümer, die Partitionsspalten, die Anzahl der Partitionen und die Gesamtzahl der aktiv referenzierten Deltadateien abfragen. Durch die Nutzung dieser Metadaten können Sie Ineffizienzen erkennen, wie z.B. Tabellen mit einer übermäßigen Anzahl kleiner Dateien oder solche, die mehr Speicherplatz als erwartet belegen. Databricks verfügt zwar nicht über integrierte Tabelleninventarisierungsberichte für alle Metadatenfelder, an denen wir interessiert sind, aber wir haben eine Methode entwickelt, um die Metadaten für alle Tabellen effizient zu extrahieren. Wir werden diesen Ansatz in einem der nächsten Beiträge behandeln.
3. Kombinieren Sie die beiden Metadatenquellen
Eine der effektivsten Strategien besteht darin, die Metadaten der Tabelle mit den Metadaten des Cloud-Speichers zu vergleichen. So können Sie überprüfen, ob die Größe des letzten Snapshots (Version) Ihrer Delta-Tabelle mit der tatsächlichen Speichergröße in der Cloud übereinstimmt. Während eine gewisse Diskrepanz aufgrund der Versionsverfolgung von Delta zu erwarten ist, ist eine erhebliche Diskrepanz ein Warnsignal. Große Unterschiede können auf verwaiste Dateien oder eine ineffiziente Speichernutzung hindeuten und signalisieren, dass Sie eine VACUUM benötigen, um veraltete Daten zu bereinigen und die Speicherkosten zu optimieren.
Nachfolgend sehen Sie die Databricks-Visualisierungen, die ich durch die Verbindung der beiden Metadatenquellen erstellen konnte.
Top 50 Tische mit dem meisten VACUUUM Speicher
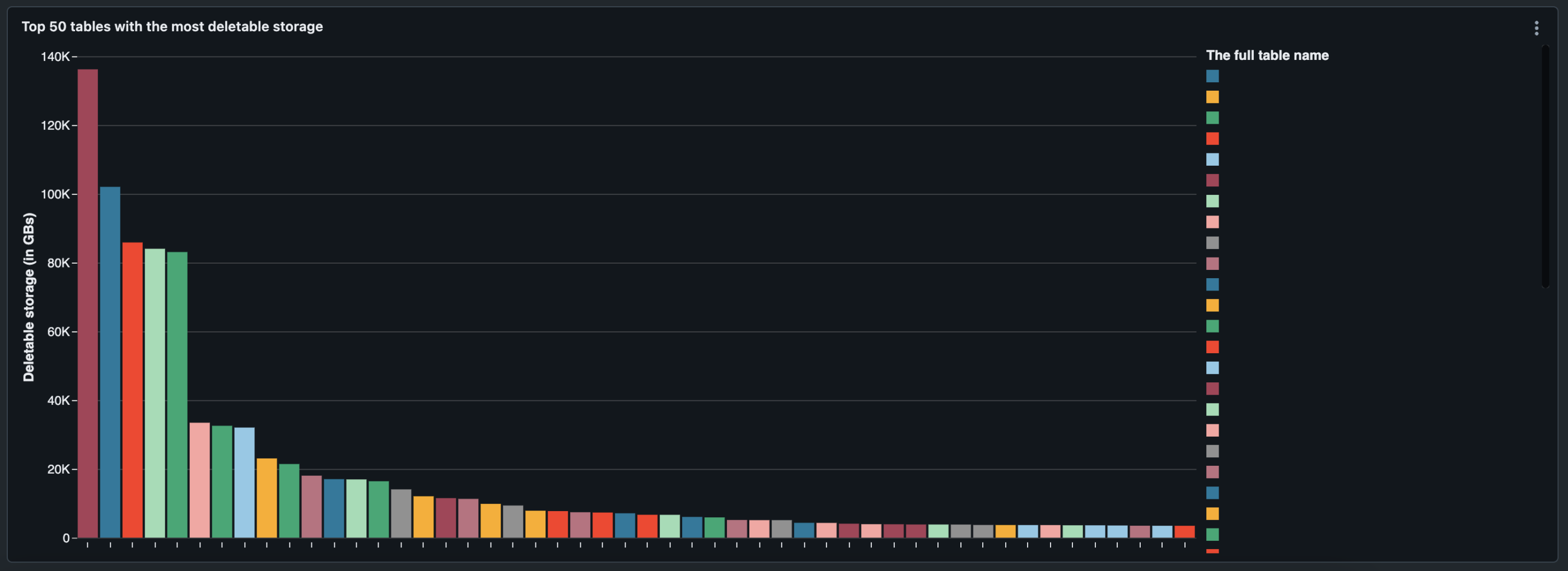
In der obigen Visualisierung können Sie sehen, welche Tabellen die größte Größendiskrepanz zwischen dem letzten Delta-Tabellen-Snapshot und dem Cloud-Speicher aufweisen.
VACUUMable Speicherplatz pro Speicherkonto im Laufe der Zeit
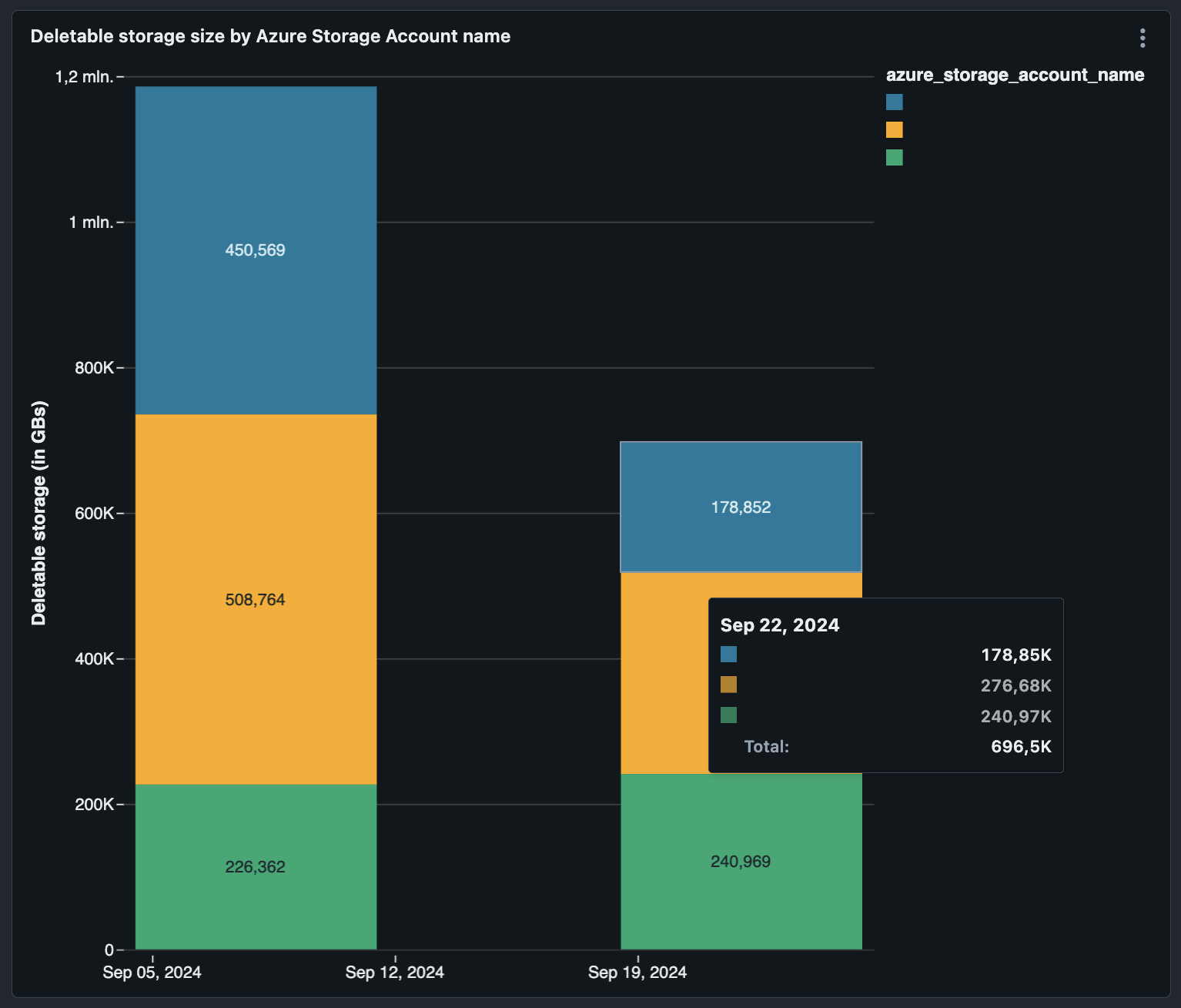
In der obigen Visualisierung können Sie beobachten, welche Speicherkonten im Laufe der Zeit die größten Größenunterschiede zwischen dem letzten Delta-Tabellen-Snapshot und dem Cloud-Speicher aufweisen.
Vorteile dieses (meta-)datengesteuerten Ansatzes
- Anstatt einen geplanten Auftrag
VACUUMüber alle oder eine statisch definierte Liste von Tabellen laufen zu lassen, können Sie dynamisch die Tabellen mit einer signifikanten Größendiskrepanz anvisieren, was eine effiziente Speicherverwaltung gewährleistet und unnötige Operationen minimiert. - Ebenso können Sie Tabellen dynamisch auf der Grundlage der Anzahl der Dateien im Delta-Tabellenverzeichnis herausfiltern. Da die Leistung von
VACUUMstark von der Anzahl der Dateien abhängt, könnte es effizienter sein, zunächst das zugrunde liegende Problem anzugehen, z.B. überpartitionierte Tabellen neu zu schreiben und dann nach der Validierung das gesamte zugrunde liegende Speicherverzeichnis zu löschen, was rekursiv mit Hilfe von Cloud-Storage-APIs durchgeführt werden kann. - Darüber hinaus können Sie durch die Analyse beider Metadatenquellen Speicherorte identifizieren, die nicht mehr von Tabellen im Katalog referenziert werden. Dies geschieht häufig, wenn externe Tabellen aus dem Katalog gelöscht werden, da das Löschen einer EXTERNEN Tabelle die zugrunde liegenden Daten im Cloud-Speicher nicht entfernt. Diese verwaisten Speicherorte sind die besten Kandidaten für eine Bereinigung.
️ Automatisiertes VACUUM (verwaltet von Databricks)
Die prädiktive Optimierung in Databricks rationalisiert die Tabellenwartung für die von Unity Catalog verwalteten Tabellen, indem sie die Identifizierung und Ausführung notwendiger Operationen automatisiert. Dies macht manuelle Eingriffe überflüssig und stellt sicher, dass wichtige Aufgaben wie VACUUM nur dann ausgeführt werden, wenn sie von Nutzen sind, wodurch der Aufwand für die Überwachung und Behebung von Leistungsproblemen reduziert wird.
Hinweis: Die prädiktive Optimierung unterstützt auch die Ausführung von
OPTIMIZE, was die Abfrageleistung verbessert. Wir werdenOPTIMIZEin der nächsten Folge dieser Serie ausführlich behandeln.
Beschränkungen
Obwohl die prädiktive Optimierung erhebliche Vorteile bietet, gibt es einige Einschränkungen, die Sie beachten sollten:
- Regionale Verfügbarkeit: Nicht alle Databricks-Regionen unterstützen die prädiktive Optimierung.
- Einstellungen für die Dateiaufbewahrung: Die prädiktive Optimierung überspringt
VACUUMbei Tabellen, bei denen das Aufbewahrungsfenster unter dem Standardwert von 7 Tagen eingestellt ist. - Nicht unterstützte Tabellentypen: Die prädiktive Optimierung gilt nicht für
- Delta Sharing-Empfängertabellen
- Externe Tabellen
- Materialisierte Ansichten
- Streaming-Tabellen
Weitere Informationen zur prädiktiven Optimierung finden Sie in der Dokumentation hier.
Wichtigste Erkenntnisse
1. Warten Sie nicht darauf, dass Ihre Speicherkosten in die Höhe schnellen! Führen Sie VACUUM regelmäßig aus.
Indem Sie die Metadaten der Tabellen und des Cloud-Speichers regelmäßig einlesen und kombinieren, können Sie bestimmte Tabellen gezielt optimieren. Ziehen Sie auch in Erwägung, VACUUM LITE für häufige, leichte Bereinigungen zu verwenden und VACUUM für gelegentliche tiefgreifende Bereinigungen zu reservieren. Dieser Ansatz schafft ein Gleichgewicht zwischen Leistung, Speichereffizienz und Kosten.
2. Verstehen Sie das Transaktionsprotokoll von Delta Lake
Machen Sie sich damit vertraut, wie das Transaktionsprotokoll Datenversionen verwaltet. Wenn Sie dies wissen, werden Sie die Bedeutung der regelmäßigen Wartung besser verstehen.
3. Nutzen Sie Cloud-Inventardienste, um die Speicherkosten zu senken
Cloud-Inventarisierungsdienste wie Azure Blob oder AWS S3 Inventory spielen eine entscheidende Rolle bei der Kontrolle der Speicherkosten, da sie detaillierte Berichte über Ihre gespeicherten Daten liefern. Diese Dienste helfen Ihnen, verwaiste oder veraltete Dateien zu identifizieren, VACUUM zu rationalisieren und die Speichereffizienz zu verbessern. Wenn Sie diese Inventarisierungsberichte nutzen, können Sie die Kosten und die Komplexität von Live-Dateiscans reduzieren, so dass es einfacher wird, unnötige Daten zu bereinigen und eine schlanke Cloud-Umgebung zu erhalten.
4. Passen Sie die Aufbewahrungsfristen klug an.
Passen Sie die Einstellungen von delta.deletedFileRetentionDuration und delta.logRetentionDuration an Ihre geschäftlichen Anforderungen an, um eine effektive Zeitreise zu gewährleisten und gleichzeitig die unnötige Datenaufbewahrung zu minimieren.
5. Erwägen Sie die Verwendung der prädiktiven Optimierung von Unity.
Die prädiktive Optimierung hilft, die Tabellenpflege zu automatisieren, den manuellen Aufwand zu verringern und Leistungsprobleme zu vermeiden. Beachten Sie jedoch, dass sie möglicherweise nicht in allen Regionen verfügbar ist und für bestimmte Tabellentypen, wie z. B. externe Tabellen, nicht gilt.
Fazit
In der heutigen datengesteuerten Welt ist die Verwaltung der Kosten in Cloud-Umgebungen wie Databricks von entscheidender Bedeutung für die Maximierung des Wertes Ihrer Dateninvestitionen für Ihr Unternehmen.
Der Befehl VACUUM von Delta Lake ist für die Aufrechterhaltung einer schlanken Datenumgebung unerlässlich, da er unnötige Dateien bereinigt und die Speicherkosten reduziert.
Darüber hinaus bietet die vorausschauende Optimierung von Unity den Vorteil, dass dieser Wartungsprozess für verwaltete Tabellen automatisiert wird, so dass Sie sich nicht mehr um die manuelle Überwachung kümmern müssen.
Wir haben gelernt, dass Sie durch die regelmäßige Anwendung von VACUUM und die Nutzung von Metadaten aus Delta Lake und dem Cloud-Speicher Tabellen mit hohen Kosten auf der Grundlage von Größendiskrepanzen und der Anzahl der Dateien dynamisch anvisieren und den Speicher ohne unnötige Operationen optimieren können.
Darüber hinaus sorgt die Verwendung von VACUUM LITE für häufige, leichte Bereinigungen und die Reservierung von VACUUM für tiefere Bereinigungen für eine kostengünstige und effiziente Speicherverwaltungsstrategie.
Bleiben Sie dran für unsere nächste Folge, in der wir uns mit Techniken zur Optimierung der Rechenleistung befassen werden, um Ihre Möglichkeiten zur effektiven Kostenverwaltung in Databricks weiter zu verbessern.
Verfasst von
Frank Mbonu
Frank is a Data Engineer at Xebia Data. He has a passion for end-to-end data solutions and his experience encompasses the entire data value chain, from the initial stages of raw data ingestion to the productionization of machine learning models.




Contact