
Hinweis: Dieser Beitrag wurde von Fokko Driesprong im Jahr 2021 verfasst. Aufgrund eines Migrationsartefakts wird nun Giovanni Lanzani als Autor aufgeführt.
Wir alle wissen es: Der Aufbau von Datenpipelines ist schwierig. Um wartbare Pipelines in komplexen Domänen zu erstellen, brauchen wir einfache und effektive Tools, die mit dem Unternehmen mitwachsen. Der Einsatz eines Tools wie dbt und die Implementierung von DataOps macht es einfach, die besten Praktiken zu übernehmen. Sicherstellung eines Lebenszyklus rund um Ihre Datenmodelle durch Übernahme von Prinzipien, die wir bereits von DevOps kennen. Damit wird eine automatisierte, prozessorientierte Methodik eingeführt, die von Analyse- und Datenteams verwendet wird, um die Qualität der Daten zu verbessern und den Lebenszyklus zu verkürzen, so dass stets hochwertige Daten geliefert werden. Durch die Kombination von
Ich war an der Bereitstellung von Spark-Unterstützung für dbt-spark beteiligt. In diesem Blog stellen wir die Technologien vor und zeigen, wie Sie loslegen können.
Oben sehen Sie den Vortrag, den ich auf dem Data+AI Summit gehalten habe. Wenn Sie bereits Databricks und dbt verwenden, sollten Sie sich den Vortrag unbedingt ansehen. Er zeigt, wie wir Delta nutzen können, um inkrementelle Ladungen durchzuführen und die Abstammung Ihrer Datensätze zu erhalten.
Das könnte Sie auch interessieren: Cloud-Schulungen
dbt
dbt (data build tool) ermöglicht es Datenanalysten und -ingenieuren, ihre Daten mit denselben Methoden umzuwandeln, die Softwareingenieure für die Erstellung von Anwendungen verwenden. dbt ist das T in ELT. Organisieren, bereinigen, denormalisieren, filtern, umbenennen und voraggregieren Sie die Rohdaten in Ihrem Warehouse, damit sie für die Analyse bereit sind.
Databricks
Databricks ist ein verwaltetes Spark-Angebot, das jetzt in jeder Cloud verfügbar ist, einschließlich der kürzlich hinzugefügten Unterstützung für[GCP]. Databricks bietet On-Demand-Computing für die Ausführung von Big Data-Workloads und Analysepipelines. Dies ist praktisch die L in ETL, die die Daten in Databricks lädt, wo sie abgefragt und verfeinert werden können.
Wir bei GoDataDriven sind ein zertifizierter[Databricks Partner], und ich habe das Privileg, mich einen sogenannten[Databricks Developer Champion] zu nennen.
Erste Schritte
Zunächst müssen wir dbt mit pip3 installieren. Stellen Sie sicher, dass Sie die Python-Version >=3.6.2 installiert haben.
$ pip3 install "dbt-spark[ODBC]" ... $ dbt --version installierte Version: 0.19.0 neueste Version: 0.19.0
Auf dem neuesten Stand!
Plugins:
- spark: 0.19.0.1
Sie überprüfen, ob alles funktioniert, indem Sie dbt --version ausführen. Als nächstes müssen wir ein Profil konfigurieren, das uns sagt, wie wir uns mit unserem Databricks-Cluster verbinden. Für dieses Beispiel stellen wir eine Verbindung zu einem Databricks-Cluster auf Azure her. Für andere Profile können Sie sich die Referenzprofile ansehen, mit denen Sie eine Verbindung zu Vanilla Spark herstellen können.
default:
target: dev
outputs:
dev:
type: spark
method: odbc
driver: [path/to/driver]
schema: [database/schema name]
host: [yourorg.sparkhost.com]
organization: [org id] # Azure Databricks only
token: [abc123]
# one of:
endpoint: [endpoint id]
cluster: [cluster id]
# optional
port: [port] # default 443
user: [user]Lassen Sie uns die Umgebung mit dem kürzlich eingeführten SQL Analytics konfigurieren. Zum Zeitpunkt der Erstellung dieses Artikels ist es noch in der öffentlichen Vorschau, aber wir bei GoDataDriven leben gerne gefährlich.
Öffnen wir SQL Analytics und holen wir uns die Anmeldeinformationen, die für die Einrichtung der Verbindung zwischen dbt und Databricks erforderlich sind. Wir müssen einen Endpunkt (Cluster) erstellen, der für die Ausführung der Pipeline verwendet wird, und wir müssen ein Token erstellen, um Zugang zu erhalten.
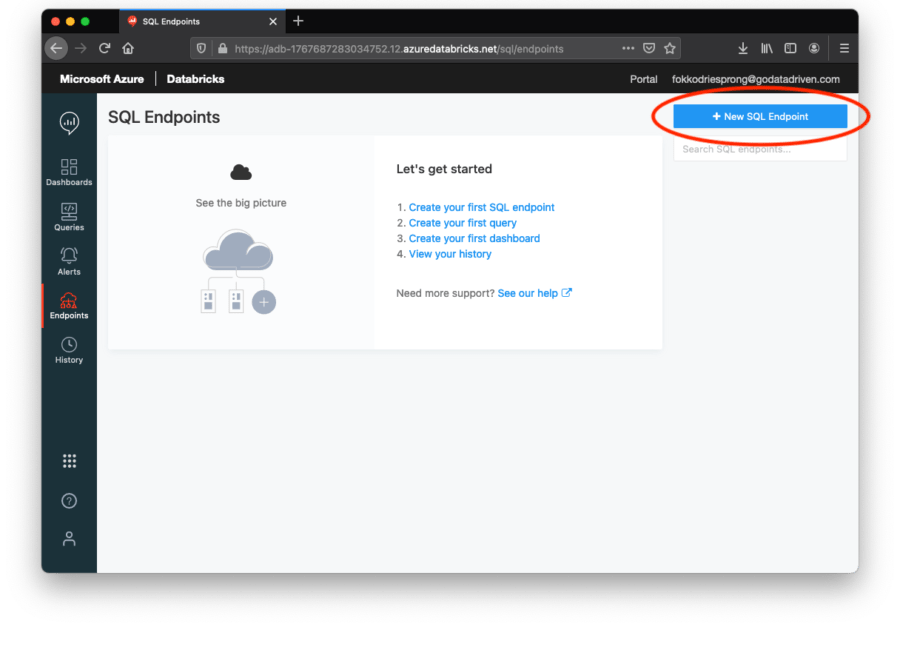
Zuerst gehen wir auf die Registerkarte Endpunkte und erstellen oben rechts einen neuen Endpunkt.
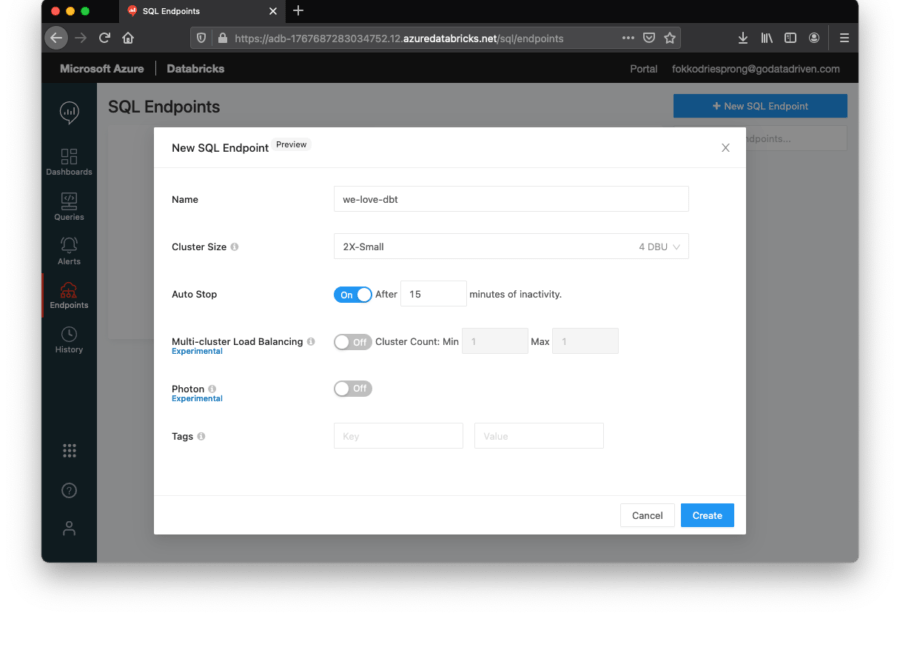
Wir erstellen einen kleinen Cluster, nur um unseren PoC durchzuführen. Stellen Sie sicher, dass Sie einen automatischen Stopp konfigurieren. Dies ist eine sehr praktische Funktion von Databricks, um den Cluster nach einer bestimmten Zeit der Inaktivität automatisch herunterzufahren. Nur um Ihre Kreditkarte zu schonen.
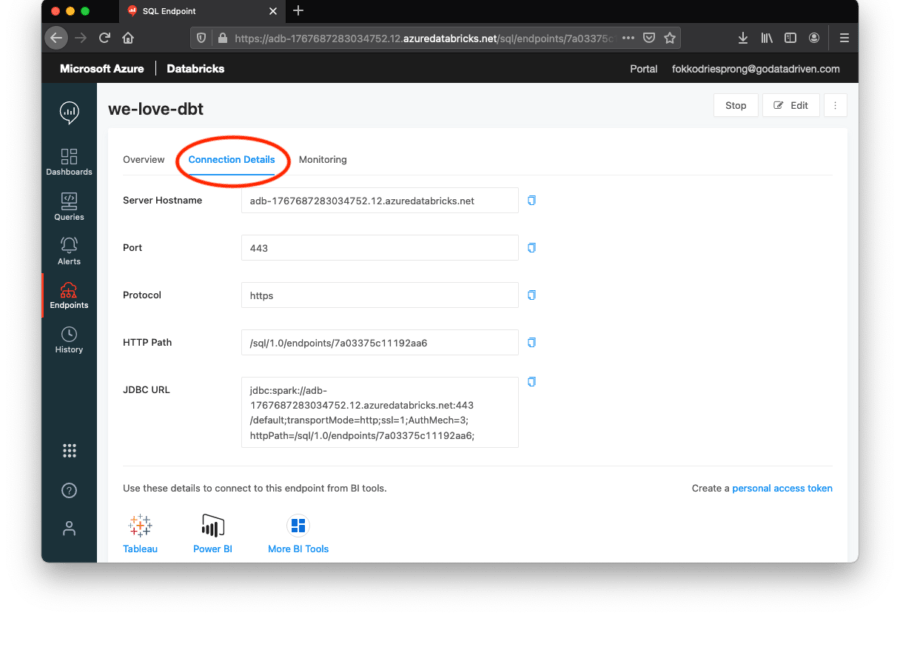
Klicken Sie auf die Registerkarte Verbindungsdetails. Hier finden Sie den Hostnamen und den Endpunkt. Der Endpunkt ist der letzte Teil des HTTP-Pfads, im obigen Fall ist dies 7a03375c11192aa6.
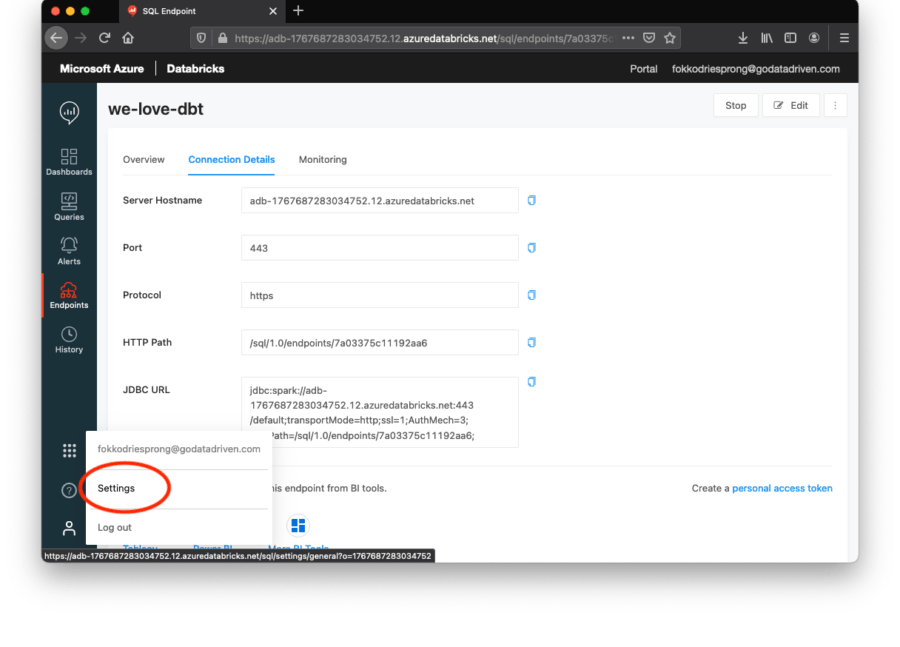
Als Nächstes benötigen wir unser persönliches Zugriffstoken, um Zugang zur Umgebung zu erhalten. Diesen finden Sie auf der Registerkarte Einstellungen in Ihrem Profil.
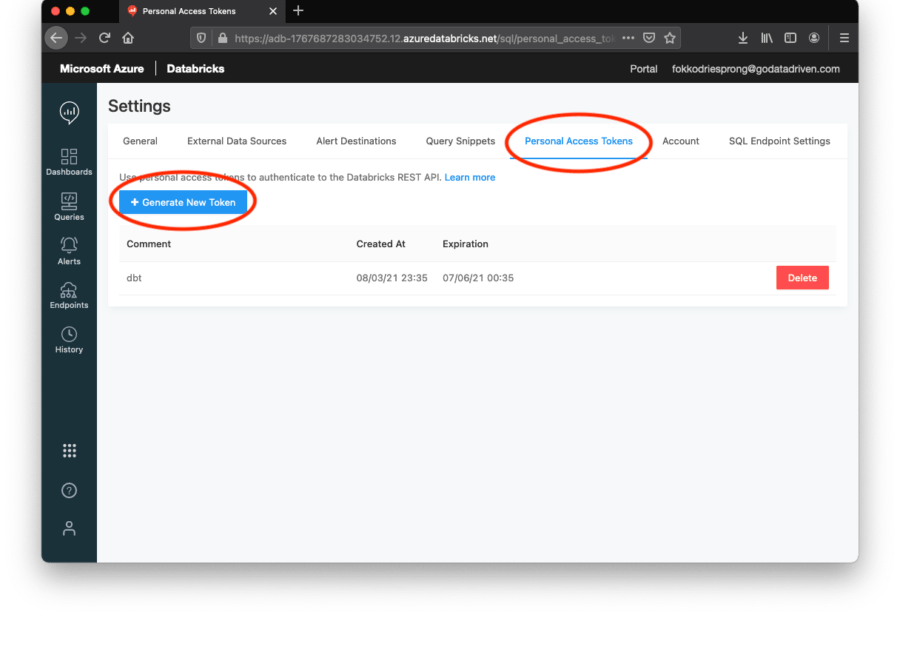
Gehen Sie zu Persönliches Zugangstoken und erstellen Sie ein neues Token. Achten Sie darauf, dass Sie dieses Token niemals weitergeben oder weitergeben lassen! Mit diesem Token können Dritte auf Ihren Arbeitsbereich und damit auf Ihre Daten zugreifen. Es ist immer eine gute Praxis, kurzlebige Token zu erstellen oder Ihr Netzwerk so zu konfigurieren, dass nicht autorisierte IPs nicht auf die Umgebung zugreifen können.
Lassen Sie uns das Profil erstellen:
$ mkdir -p ~/.dbt/ $ nano ~/.dbt/profile
default: target: dev outputs: dev: type: spark method: odbc driver: "/Library/simba/spark/lib/libsparkodbc_sbu.dylib" schema: "default" host: adb-1767687283012345.22.azuredatabricks.net organization: "{ 1767687283012345 | as_text }" token: "dapie1c2dfe5558af06ba4735f04a92012345" endpoint: "7a03375c11012abc" port: 443
Als nächstes können wir die Verbindung testen:
$ dbt debug Läuft mit dbt=0.19.0 dbt Version: 0.19.0 python Version: 3.7.9 python Pfad: /usr/local/opt/python@3.7/bin/python3.7 os info: Darwin-20.3.0-x86_64-i386-64bit Verwendung der Datei profiles.yml unter /Users/fokkodriesprong/.dbt/profiles.yml Verwendung der Datei dbt_project.yml unter /Users/fokkodriesprong/Desktop/dbt-data-ai-summit/dbt_project.yml
Konfiguration: profiles.yml Datei [OK gefunden und gültig] dbt_project.yml Datei [OK gefunden und gültig]
Erforderliche Abhängigkeiten:
- git [OK gefunden]
Verbindung: host: adb-1767687283034752.12.azuredatabricks.net port: 443 cluster: None endpoint: 7a03375c11192aa6 schema: default organization: { 1767687283034752 | as_text } Verbindungstest: OK Verbindung ok
Wenn etwas nicht stimmt, sehen Sie bitte unter logs/dbt.log nach, ob Sie Hinweise finden. Wenn Sie Hilfe benötigen, können Sie gerne eine Anfrage stellen.
Nachdem Sie dbt debug ausgeführt haben, sollte der Cluster automatisch gestartet werden:
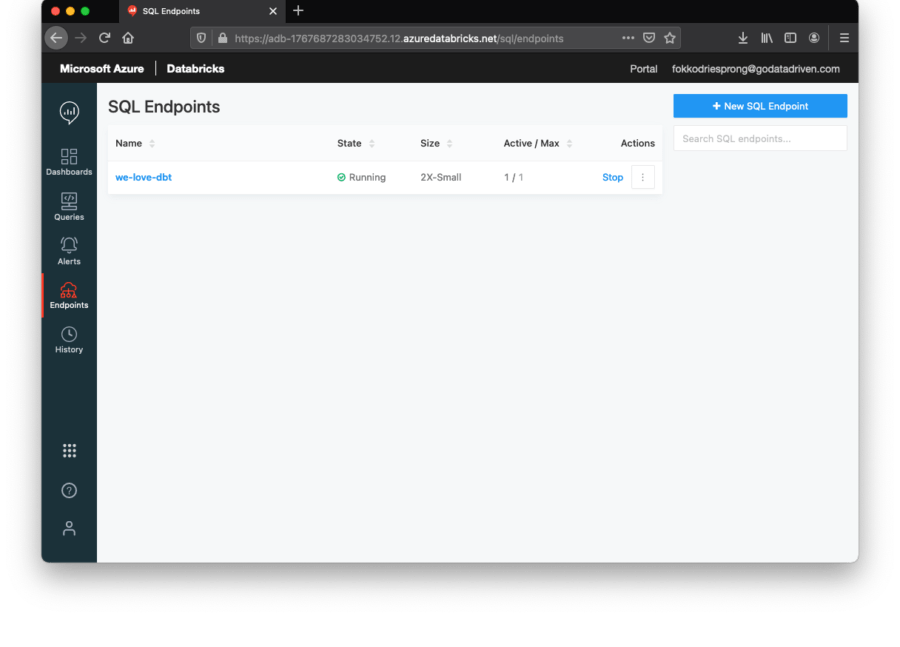
Jetzt sollten wir in der Lage sein, den Code auszuführen, der in dem Data+AI Summit Vortrag verwendet wurde. Schauen wir uns den Code an:
$ git clone https://github.com/godatadriven/dbt-data-ai-summit.git
$ cd dbt-data-ai-summit
Ausgeführt mit dbt=0.19.0
Gefunden wurden 3 Modelle, 2 Tests, 0 Snapshots, 0 Analysen, 159 Makros, 0 Operationen, 0 Seed-Dateien, 0 Quellen, 0 Expositionen
23:43:59 | Gleichzeitigkeit: 1 Threads (target='dev') 23:43:59 | 23:43:59 | 1 von 3 START Tabellenmodell default.order_lines......................... [RUN] 23:44:42 | 1 von 3 OK erstellt Tabelle model default.order_lines.................... [OK in 42.93s] 23:44:42 | 2 von 3 START Tabellenmodell default.orders.............................. [RUN] 23:44:49 | 2 von 3 OK erstellt Tabellenmodell default.orders......................... [OK in 6.98s] 23:44:49 | 3 von 3 START inkrementelles Modell default.revenue....................... [RUN] 23:45:03 | 3 von 3 OK erstellt inkrementelles Modell default.revenue.................. [OK in 13.92s] 23:45:03 | 23:45:03 | Beendet die Ausführung von 2 Tabellenmodellen, 1 inkrementellen Modell in 66.28s.
Erfolgreich abgeschlossen
Erledigt. PASS=3 WARN=0 ERROR=0 SKIP=0 TOTAL=3
Wir können sehen, dass dbt die 3 Modelle aus dem Beispiel ausgeführt hat. Wenn wir uns SQL Analytics ansehen, sehen wir die Ergebnisse:
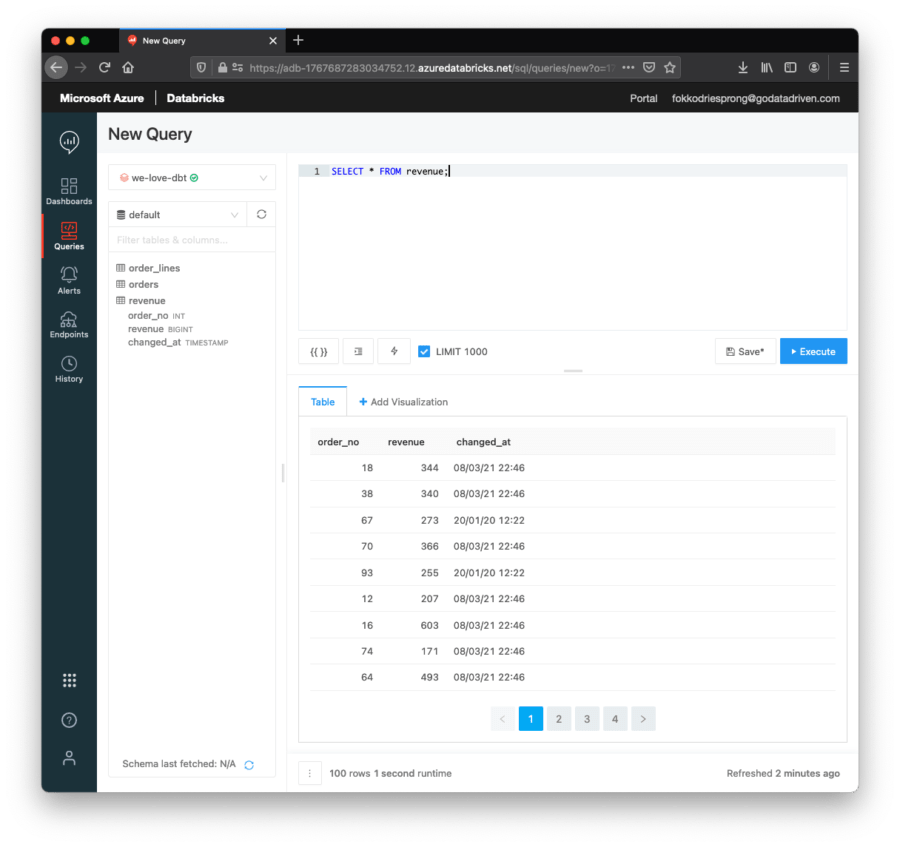
Wir können dbt test ausführen, um sicherzustellen, dass alle Beschränkungen und Datenprüfungen noch gültig sind:
$ dbt test Ausgeführt mit dbt=0.19.0 Gefunden wurden 3 Modelle, 2 Tests, 0 Schnappschüsse, 0 Analysen, 159 Makros, 0 Operationen, 0 Seed-Dateien, 0 Quellen, 0 Belichtungen
10:02:29 | Gleichzeitigkeit: 1 Threads (target='dev') 10:02:29 | 10:02:29 | 1 von 2 START test not_null_revenue_order_no.......................... [RUN] 10:02:30 | 1 von 2 PASS not_null_revenue_order_no................................ [PASS in 0.80s] 10:02:30 | 2 von 2 START test unique_revenue_order_no............................ [RUN] 10:02:31 | 2 von 2 PASS unique_revenue_order_no.................................. [PASS in 1.07s] 10:02:31 | 10:02:31 | 2 Tests in 3.65s abgeschlossen.
Erfolgreich abgeschlossen
Erledigt. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2
Schließlich können wir mit dbt docs generate && dbt docs serve Dokumente erstellen:
$ dbt docs generate && dbt docs serve Ausgeführt mit dbt=0.19.0 Gefunden wurden 3 Modelle, 2 Tests, 0 Snapshots, 0 Analysen, 159 Makros, 0 Operationen, 0 Seed-Dateien, 0 Quellen, 0 Expositionen
10:03:36 | Gleichzeitigkeit: 1 Threads (target='dev') 10:03:36 | 10:03:36 | Erledigt. 10:03:36 | Katalog aufbauen 10:03:39 | Katalog geschrieben nach /Users/fokkodriesprong/Desktop/dbt-data-ai-summit/target/catalog.json Läuft mit dbt=0.19.0 Serving docs at 0.0.0.0:8080 Um von Ihrem Browser aus zuzugreifen, navigieren Sie zu: localhost:8080 Drücken Sie Strg+C zum Beenden.
Dadurch wird auch ein Browser mit den Dokumenten gestartet:
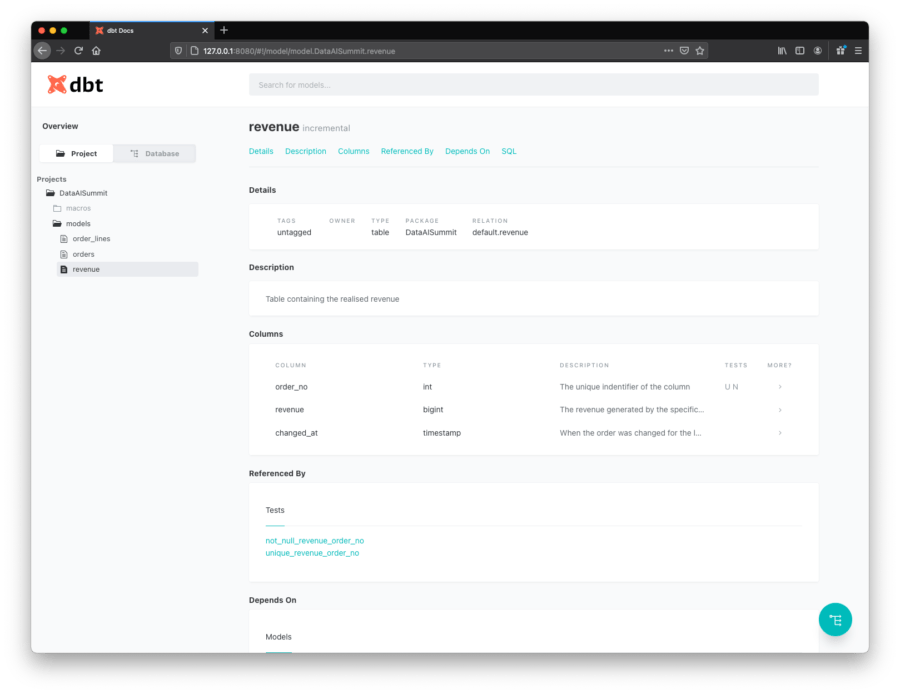
Natürlich ist dies ein einfaches Beispiel. Aber die Verwendung von dbt auf Databricks ermöglicht es Ihnen, Datenpipelines zu entwickeln, die mit der Leistung von Spark/Databricks skalierbar und durch die Umsetzung der von dbt bereitgestellten DataOps-Prinzipien wartbar sind.
Interessiert?
In diesem Blog haben wir Ihnen gezeigt, wie Sie eine grundlegende Pipeline einrichten können. In einer Produktionsumgebung benötigen Sie jedoch zusätzliche Maßnahmen, wie z.B. Überwachung/Benachrichtigung, Datenaufbewahrung, Staging-Umgebungen, kontinuierliche Bereitstellung, Vernetzung und viel mehr Automatisierung. Wenn Sie Hilfe bei der Einrichtung solcher Pipelines benötigen, zögern Sie bitte nicht, uns zu kontaktieren.
Verfasst von
Giovanni Lanzani




Contact