Blog
Das Datensegment - Zusammenstellung Ihres Data Lake

Bei der Gestaltung Ihres Data Lakes gibt es eine Vielzahl von Aspekten, die das Design bestimmen. In diesem Blog sehen wir uns an, wie wir einen Data Lake aus einer sehr kleinen Komponente namens "Datensegment" zusammenstellen können. Werfen wir einen Blick darauf!
Das Datensegment
Das Datensegment ist eine kleine Komponente, die einen Baustein für Data Lakes darstellt.
Das Datensegment bietet Streaming-Ingestion, Streaming-Transformation, Streaming-Aggregation und Datenpersistenz-Funktionen. Außerdem bietet es Funktionen für Pufferung, Datenverschlüsselung, Zugriffskontrolle, Sicherung und Wiederherstellung sowie Nachrichtenwiedergabe.
Der wichtigste Aspekt des Datensegments ist, dass es in hohem Maße zusammensetzbar ist. Lernen wir das Datensegment kennen. 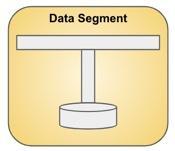
Ein Datensegment besteht aus den folgenden drei Elementen:
- Ein Pub-Sub-Kanal,
- Ein Kanal zum Abhören,
- Persistenz der Daten
Datenebene
Datensegmente werden in einer Datenschicht gruppiert. Jedes Datensegment ist für eine Datendomäne zuständig. 
Datensee
Ein Data Lake ist eine Gruppierung von Datenschichten und kann beliebig breit oder hoch werden. Jede Datenschicht ist vollständig von anderen Datenschichten isoliert. 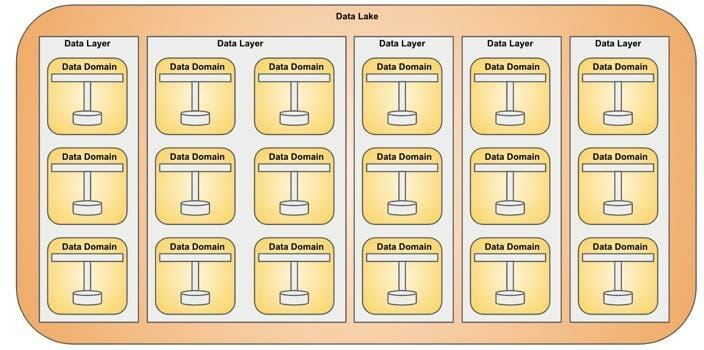
Verbinden von Datensegmenten
Der Data Lake fungiert als Plattform für Datensegmente und bietet Infrastruktur, Nachrichtenrouting, Erkennung und Konnektivitätsfunktionen für Datensegmente. Die Datensegmente werden je nach Anforderung an das Nachrichten-Routing miteinander verdrahtet.
Integration von Komponenten
Komponenten wie Publisher und Subscriber werden mit dem Data Lake integriert. Der Data Lake ist für die Weiterleitung der Nachricht an das entsprechende Datensegment verantwortlich. 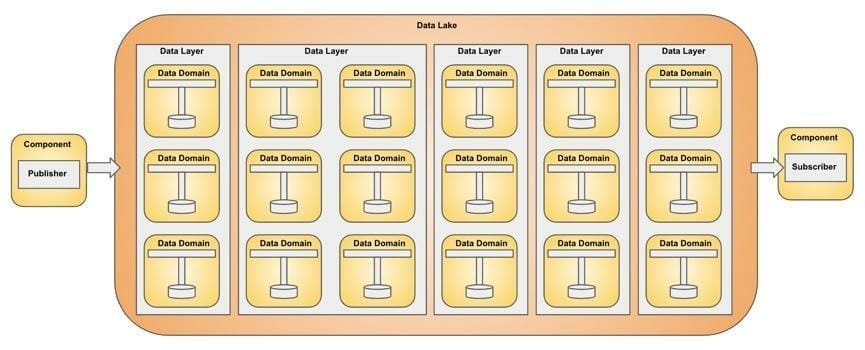
Cloud-Dienstanbieter
Cloud-Service-Provider bieten Dienste an, die für die Implementierung von Data Lakes geeignet sind. AWS bietet zum Beispiel Messaging- und Persistenz-Services, die für die Implementierung von Datensegmenten und Data Lakes genutzt werden können.
AWS Technisches Mapping
Der Data Lake kann in AWS mit dem folgenden technischen Mapping implementiert werden:
| Data Segment Component | Amazon Service (bevorzugt) | Alternative |
| - | - | - |
| pub-sub channel | Amazon Kinesis Stream | Amazon SNS, Amazon SQS |
| write-tap channel | Amazon Kinesis Data Firehose | Amazon Lambda, EMR, Amazon Fargate |
| data persistence | Amazon S3 | Amazon EFS |
CloudFormation Implementierung
Eine Implementierung des Datensegments ist eine CloudFormation Wunschzustandskonfiguration, die unten gezeigt wird. Das Datensegment besteht aus Amazon Kinesis Stream für den pub-sub Kanal, Amazon Kinesis Data Firehose für den wire-tap Kanal und Amazon S3 für die Datenpersistenz.
AWSTemplateFormatVersion: '2010-09-09'
content: blog-datasegment
Parameters:
DataSegmentName:
Type: String
Default: example-datasegment
Resources:
DataSegmentRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Principal:
Service: firehose.amazonaws.com
Action: sts:AssumeRole
Condition: {}
Path: /
Policies:
- PolicyName: Allow
PolicyDocument:
Statement:
- Effect: Allow
Action:
- s3:*
- kms:*
- kinesis:*
- logs:*
- lambda:*
Resource:
- '*'
DataSegmentBucket:
Type: AWS::S3::Bucket
Deliverystream:
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
DeliveryStreamName: !Sub ${DataSegmentName}-firehose
DeliveryStreamType: KinesisStreamAsSource
KinesisStreamSourceConfiguration:
KinesisStreamARN: !GetAtt KinesisStream.Arn
RoleARN: !GetAtt DataSegmentRole.Arn
ExtendedS3DestinationConfiguration:
BucketARN: !GetAtt DataSegmentBucket.Arn
RoleARN: !GetAtt DataSegmentRole.Arn
Prefix: ''
BufferingHints:
IntervalInSeconds: 60
SizeInMBs: 1
CloudWatchLoggingOptions:
Enabled: true
LogGroupName: !Sub ${DataSegmentName}-s3-firehose
LogStreamName: !Sub ${DataSegmentName}-s3-firehose
CompressionFormat: UNCOMPRESSED
KinesisStream:
Type: AWS::Kinesis::Stream
Properties:
Name: !Sub ${DataSegmentName}-stream
ShardCount: 1
CloudWatchLogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub ${DataSegmentName}-s3-firehose
RetentionInDays: 30
CloudWatchLogStream:
Type: AWS::Logs::LogStream
DependsOn:
- CloudWatchLogGroup
Properties:
LogGroupName: !Sub ${DataSegmentName}-s3-firehose
LogStreamName: !Sub ${DataSegmentName}-s3-firehose
Outputs:
KinesisStreamName:
content: The name of the KinesisStream
Value: !Ref KinesisStream
KinesisStreamArn:
content: The ARN of the KinesisStream
Value: !GetAtt KinesisStream.Arn
DeliveryStreamName:
content: The name of the Deliverystream
Value: !Ref Deliverystream
DeliveryStreamArn:
content: The arn of the Deliverystream
Value: !GetAtt Deliverystream.Arn
BucketName:
content: THe name of the DataSegmentBucket
Value: !Ref DataSegmentBucket
Ein Verleger
Der Publisher ist mit Go leicht zu implementieren:
package main
import (
"github.com/binxio/datasegment/common"
"os"
)
func main() {
streamName := os.Getenv("KINESIS_STREAM_NAME")
if streamName == "" {
panic("KINESIS_STREAM_NAME not set")
}
partitionKey := "1"
sess := common.GetSession()
common.PutRecords(streamName, partitionKey, common.GetKinesis(sess))
}
Ein Abonnent
Ein Abonnent ist mit Go leicht zu implementieren:
package main
import (
"github.com/binxio/datasegment/common"
"os"
)
func main() {
streamName := os.Getenv("KINESIS_STREAM_NAME")
if streamName == "" {
panic("KINESIS_STREAM_NAME not set")
}
shardId := "0" // shard ids start from 0
sess := common.GetSession()
common.GetRecords(streamName, shardId, common.GetKinesis(sess))
}
Gemeinsame
Der Herausgeber und der Abonnent brauchen eine gemeinsame Logik.
package common
import (
"encoding/hex"
"encoding/json"
"fmt"
"github.com/aws/aws-sdk-go/aws"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/aws/aws-sdk-go/service/kinesis"
"log"
)
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
}
func GetSession() *session.Session {
sess, err := session.NewSession()
if err != nil {
panic(err)
}
return sess
}
func GetKinesis(sess *session.Session) *kinesis.Kinesis {
return kinesis.New(sess, aws.NewConfig().WithRegion("eu-west-1"))
}
func CreatePerson(name string, age int) Person {
return Person{Name: name, Age: age}
}
func SerializePerson(person Person) []byte {
data, err := json.Marshal(person)
if err != nil {
panic(err)
}
return []byte(string(data) + "n")
}
func CreateRecord(streamName string, partitionKey string, data []byte) *kinesis.PutRecordInput {
return &kinesis.PutRecordInput{
PartitionKey: aws.String(partitionKey),
StreamName: aws.String(streamName),
Data: data,
}
}
func PutRecords(streamName string, partitionKey string, svc *kinesis.Kinesis) {
for i := 0; i < 100000; i++ {
person := CreatePerson(fmt.Sprintf("dennis %d", i), i)
data := SerializePerson(person)
record := CreateRecord(streamName, partitionKey, data)
res, err := svc.PutRecord(record)
if err != nil {
panic(err)
}
log.Println("Publishing:", string(data), hex.EncodeToString(data), res)
}
}
func ProcessRecords(records *[]*kinesis.Record) {
for _, record := range *records {
log.Println(string(record.Data))
}
}
func GetNextRecords(it *string, svc *kinesis.Kinesis) {
records, err := svc.GetRecords(&kinesis.GetRecordsInput{
ShardIterator: it,
})
if err != nil {
panic(err)
}
ProcessRecords(&records.Records)
GetNextRecords(records.NextShardIterator, svc)
}
func GetRecords(streamName string, shardId string, svc *kinesis.Kinesis) {
it, err := svc.GetShardIterator(&kinesis.GetShardIteratorInput{
StreamName: aws.String(streamName),
ShardId: aws.String(shardId),
ShardIteratorType: aws.String("TRIM_HORIZON"),
})
if err != nil {
panic(err)
}
GetNextRecords(it.ShardIterator, svc)
}
Beispiel
Das Beispielprojekt zeigt eine Implementierung eines Datensegments in AWS. Das Beispiel kann mit 'make create' erstellt und mit 'make delete' gelöscht werden. Um Nachrichten zu veröffentlichen, geben Sie 'make publish' ein und um einen oder mehrere Abonnenten zu starten, geben Sie 'make subscribe' ein.
Fazit
Das Datensegment ist ein Primitivum für die Erstellung von Data Lakes. Die Abstraktion hilft in vielerlei Hinsicht bei der Festlegung der Grenzen für Datendomänen, bei der Gruppierung von Datendomänen in Schichten und bei der Isolierung von Schichten. Datensegmente stellen dem Data Lake über Pub-Sub-Messaging-Kanäle Echtzeitfähigkeiten zur Verfügung.
Datensegmente ermöglichen die Stream-Verarbeitung in Echtzeit über eine Backplane, die der Data Lake bereitstellt. Datensegmente schließen sich an die Backplane an und empfangen Daten vom Data Lake bzw. liefern Daten an den Data Lake.
Datensegmente können beliebig hinzugefügt und entfernt werden, was einen Data Lake mit dynamischer Größe ermöglicht. Der Echtzeit-Aspekt mittels Pub-Sub macht die Architektur ideal für die Entwicklung von zustandsabhängigen Echtzeit-Anwendungen wie Datenplattformen.
Verfasst von
Dennis Vriend




Contact