
Ein datengesteuerter Ansatz hilft Unternehmen dabei, Entscheidungen auf der Grundlage von Fakten und nicht von Wahrnehmungen zu treffen. Eines der wichtigsten Elemente, die diesen Ansatz unterstützen, ist ein genaues Datenmodell, das die Beziehungen zwischen verschiedenen Informationsquellen strukturiert darstellt. Die Berichterstattung auf der Grundlage eines präzisen Datenmodells kann Einblicke in den aktuellen Zustand eines Unternehmens, in Risiken und potenzielle Vorteile laufender und anstehender Initiativen liefern. Gute Datenmodelle sollten klar strukturiert sein, qualitativ hochwertige Daten liefern und dokumentiert sein, da die Datendefinitionen in einem Unternehmen möglicherweise nicht einheitlich sind.
Warum Looker?
Looker ist eine der Business Intelligence-Plattformen, die Unternehmen nutzen, um ihre Daten zu untersuchen und zu visualisieren. Sie verfügt über eine benutzerfreundliche Oberfläche, mit der Anwender individuelle Berichte und Dashboards erstellen können. Diese Business Intelligence-Plattform ermöglicht die Vereinheitlichung von Analysen über mehrere Datenquellen hinweg und hilft Unternehmen, datengesteuerte Organisationen zu werden.
PDTs - der traditionelle Ansatz für die Looker-Datenmodellierung
Eine der wichtigsten Funktionen von Looker ist eine SQL-basierte Modellierungssprache namens LookML. Sie ermöglicht es Ihnen, Daten zu transformieren, Beziehungen zwischen Entitäten zu definieren und Beschreibungen für ein gemeinsames Wörterbuch hinzuzufügen. Sie ermöglicht auch das Hinzufügen von Tests, um die Genauigkeit der Ergebnisse zu überprüfen. Looker ermöglicht die Speicherung der Ergebnisse einer SQL-Abfrage in einer Datenbanktabelle in einem Warehouse. Diese Funktion wird als persistente abgeleitete Tabelle (PDT) bezeichnet. Diese Art von abgeleiteter Tabelle kann dazu verwendet werden, die Leistung der Berichterstattung zu verbessern, da die Ergebnisse der Abfrage, die die PDT erstellt, in Ihrer Datenbank gespeichert werden. Die Tabelle wird nur bei Bedarf neu erstellt, z.B. wenn neue Datensätze in der Quelltabelle erstellt werden.
dbt - ein neues Konzept der Datenumwandlung für Looker
Neben PDT gibt es ein weiteres Tool zur Modellierung von Daten, das sich mit Looker abstimmen lässt - dbt. Mit diesem Framework können Sie Transformationen in SQL-Sprache erstellen, Tests hinzufügen und haben eine sehr benutzerfreundliche Dokumentation. Es ist nicht als Ersatz für LookML gedacht, kann aber in einigen Szenarien in Looker integriert werden. Ähnlich wie bei PDT von Looker können Sie transformierte Tabellen in Ihrer Datenbank speichern und festlegen, unter welchen Bedingungen die Ergebnisse aktualisiert werden sollen.
BigQuery - Data Warehouse für Looker
Es spielt keine Rolle, ob wir dbt oder PDT für einen beliebigen Modellierungsansatz verwenden. Looker benötigt das Data Warehouse als Speicher für die Daten. In diesem Artikel haben wir Google BigQuery verwendet. Es unterstützt beide PDTs und lässt sich problemlos in dbt integrieren. Das Warehouse unterstützt den Dialekt von SQL. Es ermöglicht dem Benutzer, Transformationsabfragen zu erstellen und zu testen, bevor sie in ein PDT- oder dbt-Modell eingefügt werden. Außerdem gibt es einen schnellen Einblick in die Abfrageleistung und die Anzahl der generierten Zeilen. Sobald die umgewandelte Tabelle in der Datenbank gespeichert ist, können Sie den Verlauf der Nutzung überprüfen.
Welches Tool ist besser und wann? Lassen Sie uns diese beiden Tools anhand realer Beispiele vergleichen, damit Sie verstehen, welcher Ansatz für bestimmte Szenarien besser geeignet ist.
Anwendungsfall: Datenmodellierung in PDT vs. dbt
In dieser Demonstration zeigen wir Ihnen, wie Sie Ihre Unternehmensdaten für zukünftige Analysen in Looker modellieren. Wir erstellen einen Bericht, der aus der Sicht der Benutzeroberfläche gleich aussieht, aber am Backend zeigen wir Ihnen zwei verschiedene Ansätze für die Datenmodellierung - mit PDT und dbt. Wir fügen auch einen Qualitätstest hinzu und zeigen die Möglichkeiten der Dokumentation. Wir hoffen, damit die Frage beantworten zu können, welcher Ansatz für bestimmte Szenarien besser geeignet ist.
In beiden Fällen ist die Datenquelle ein öffentlicher Datensatz namens "theLook eCommerce", der auf Google Marketplace verfügbar ist. Unser Ziel ist es, einen einfachen Zugang zu den monatlichen Einnahmen des Unternehmens im Jahr 2023 zu erhalten.
Ansatz 1 - Modellierung von Daten in der Looker PDT-Funktion
Zunächst möchten wir Ihnen den Datenfluss vorstellen. Der Datensatz ist in BigQuery gespeichert. Um den Umsatz zu berechnen, benötigen wir 3 Rohtabellen: `Aufträge`, `Auftragsartikel` und `Nutzer`. Die Tabellen werden in Looker mithilfe der PDT-Funktion umgewandelt und das Ergebnis wird in BigQuery als Tabelle gespeichert.
Der Datenfluss sieht wie folgt aus: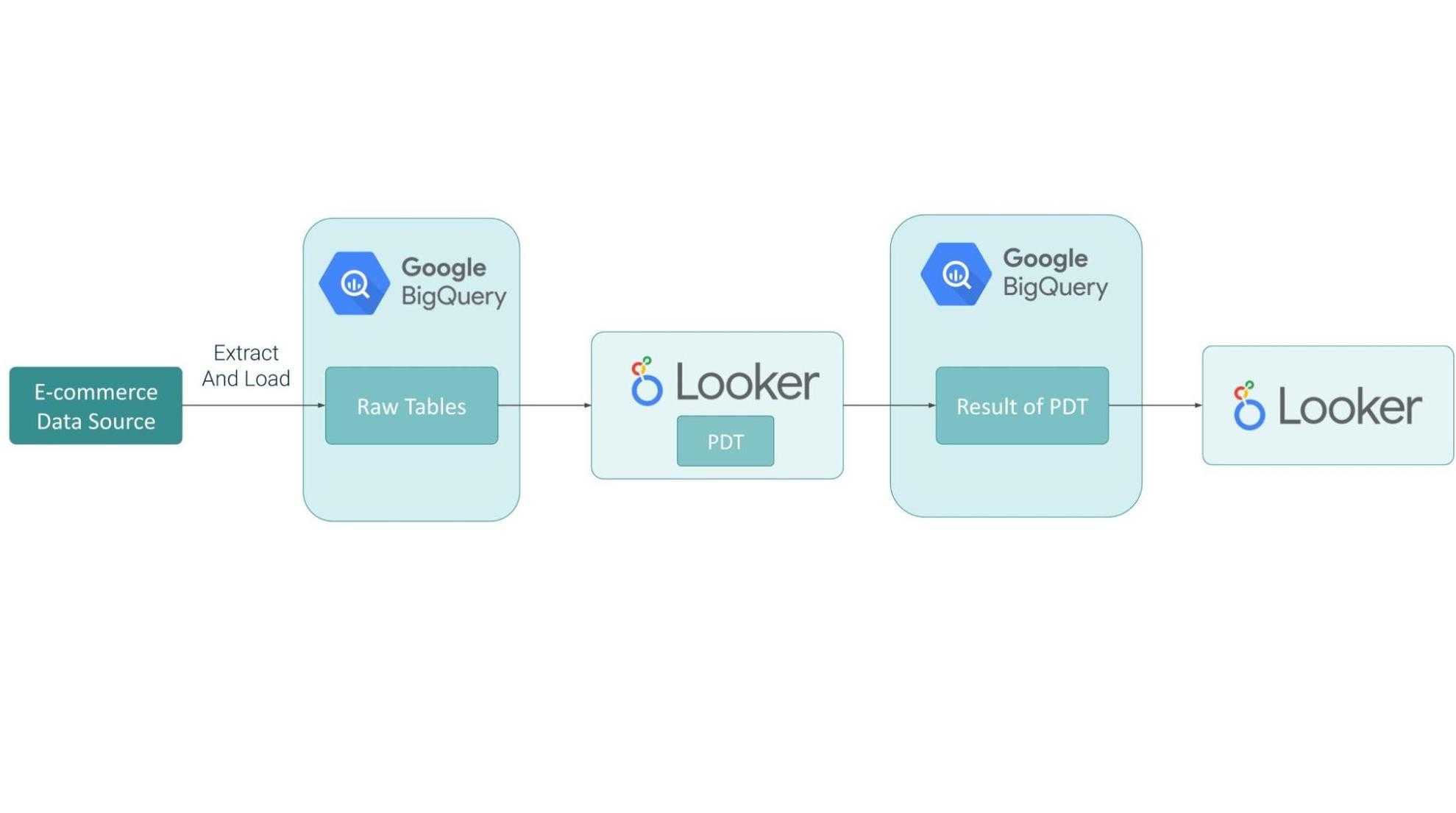
Alle Transformationen, Filter und Beziehungen werden im Looker-Code definiert. Unser Ziel ist es, ein PDT zu erstellen. Nachfolgend stellen wir Ihnen einen Codeschnipsel vor:
view: fact_revenue_pdt {
derived_table: {
sql: WITH
fact_revenue AS (
SELECT
o.created_at AS order_date,
u.ID AS customer_id,
SUM(oi.sale_price*o.num_of_item) AS revenue
FROM
`dbt-models.e_commerce.order_items` AS oi
LEFT JOIN
`dbt-models.e_commerce.orders` AS o
ON
oi.order_id = o.order_id
LEFT JOIN
`dbt-models.e_commerce.users` AS u
ON
oi.user_id = u.id
WHERE
EXTRACT(YEAR
FROM
o.created_at) >= 2023
AND oi.status NOT IN ('Cancelled',
'Returned')
GROUP BY
1,
2 )
SELECT
GENERATE_UUID() AS primary_key,
order_date,
customer_id,
SUM(revenue) AS revenue
FROM
fact_revenue
GROUP BY
1,
2,
3 ;;
sql_trigger_value: SELECT MAX(created_at) FROM `dbt-models.e_commerce.order_items`;;
}
dimension: primary_key {
description: "The primary key for this table"
hidden: yes
type: string
sql: ${TABLE}.primary_key ;;
}
dimension_group: order {
type: time
timeframes: [date, month, year]
sql: ${TABLE}.order_date ;;
}
dimension: customer_id {
value_format_name: id
type: number
sql: ${TABLE}.customer_id ;;
}
dimension: revenue {
hidden: yes
type: number
sql: ${TABLE}.revenue ;;
}
measure: total_revenue {
description: "Revenue in USD"
type: sum
value_format: "$0.00"
sql: ${revenue} ;;
}
measure: count_customer_id {
description: "Field added for testing purpose"
hidden: yes
type: count_distinct
sql: ${TABLE}.customer_id ;;
}
}
Im Code beziehen wir uns auf die ursprünglichen Namen des Datensatzes, der Tabellen und Spalten. Wir bereinigen und aggregieren die Daten und das Ergebnis dieser Abfrage-Neuerstellung wird im BigQuery Warehouse gespeichert. Jedes Mal (außer beim PDT-Neuaufbau), wenn jemand einen Bericht ausführt, der die auf dieser PDT-Abfrage basierende Erkundung verwendet, wird er mit den abgeleiteten Tabellenergebnissen und nicht mit den rohen Tabellen ausgeführt.
Im Looker-Modell wird sie als eigenständige Explore-Datei dargestellt. In diesem speziellen Fall ist es nicht erforderlich, die Rohtabellen separat als Ansichten darzustellen; alle Transformationen wurden in einer PDT-Ansichtsdatei vorgenommen. Nachfolgend finden Sie einen Codeschnipsel eines Modellobjekts.
connection: "dbt_annaw"
include: "/views/raw_sources/fact_revenue_pdt.view.lkml"
include: "/views/raw_sources/tests.lkml"
datagroup: ecommerce_etl {
sql_trigger: SELECT max(created_at) FROM `dbt-models.e_commerce.order_items`;;
max_cache_age: "24 hours"
}
explore: fact_revenue_pdt {
label: "Fact Revenue"
}
Ein wichtiger Hinweis zum Hinzufügen von Primärschlüsseln in Ansichten: In Looker ist es entscheidend, dass die symmetrischen Aggregationen richtig berechnet werden. In unserem Fall haben wir keinen nativen Primärschlüssel, so dass es eine gute Praxis ist, einen zu erstellen, indem wir eine UUID in einer abgeleiteten Tabelle erzeugen oder mehrere Spalten aus Tabellen zusammenfassen. Mit Looker können wir einen Test für die Eindeutigkeit von Spalten hinzufügen. In unserem Fall sieht ein Codeschnipsel für die Kundentabelle wie folgt aus:
test: customer_id_is_unique {
explore_source: fact_revenue_pdt {
column: customer_id {}
column: count_customer_id {}
sorts: [count: desc]
limit: 1
}
assert: customer_id_is_unique {
expression: ${fact_revenue_pdt.count_customer_id} = 1 ;;
}
}
Wie Sie sehen, ist das Schreiben von Tests in Looker für einfache Überprüfungen etwas kompliziert. Hier testen wir unsere Daten auch im BI-Tool, und wir glauben, dass es besser ist, dies im ersten Schritt zu tun.
Ein weiterer Aspekt bei der Erstellung eines guten Modells ist die Dokumentation. Mit LookML können Benutzer Beschreibungen hinzufügen, die für Geschäftsanwender sichtbar sind, und Kommentare im Code für Entwickler. Um jedoch einen vollständigen Überblick über Ihre PDT-Details zu erhalten, muss der Benutzer über Administratorrechte verfügen. Das Beispiel für unseren Fall sieht wie folgt aus: 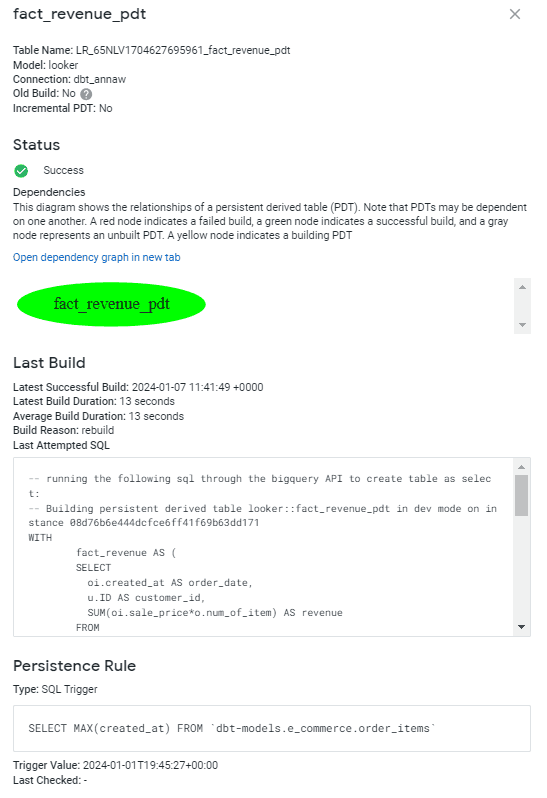
Ansatz 2 - Modellierung von Daten in dbt
Bei dem Ansatz, bei dem dbt verwendet wird, wird der Datensatz in BigQuery gespeichert. Wir werden genau dieselben Tabellen verwenden, um Transformationen in der dbt-Modelldatei durchzuführen.
Der Datenfluss für dieses Szenario sieht wie folgt aus: 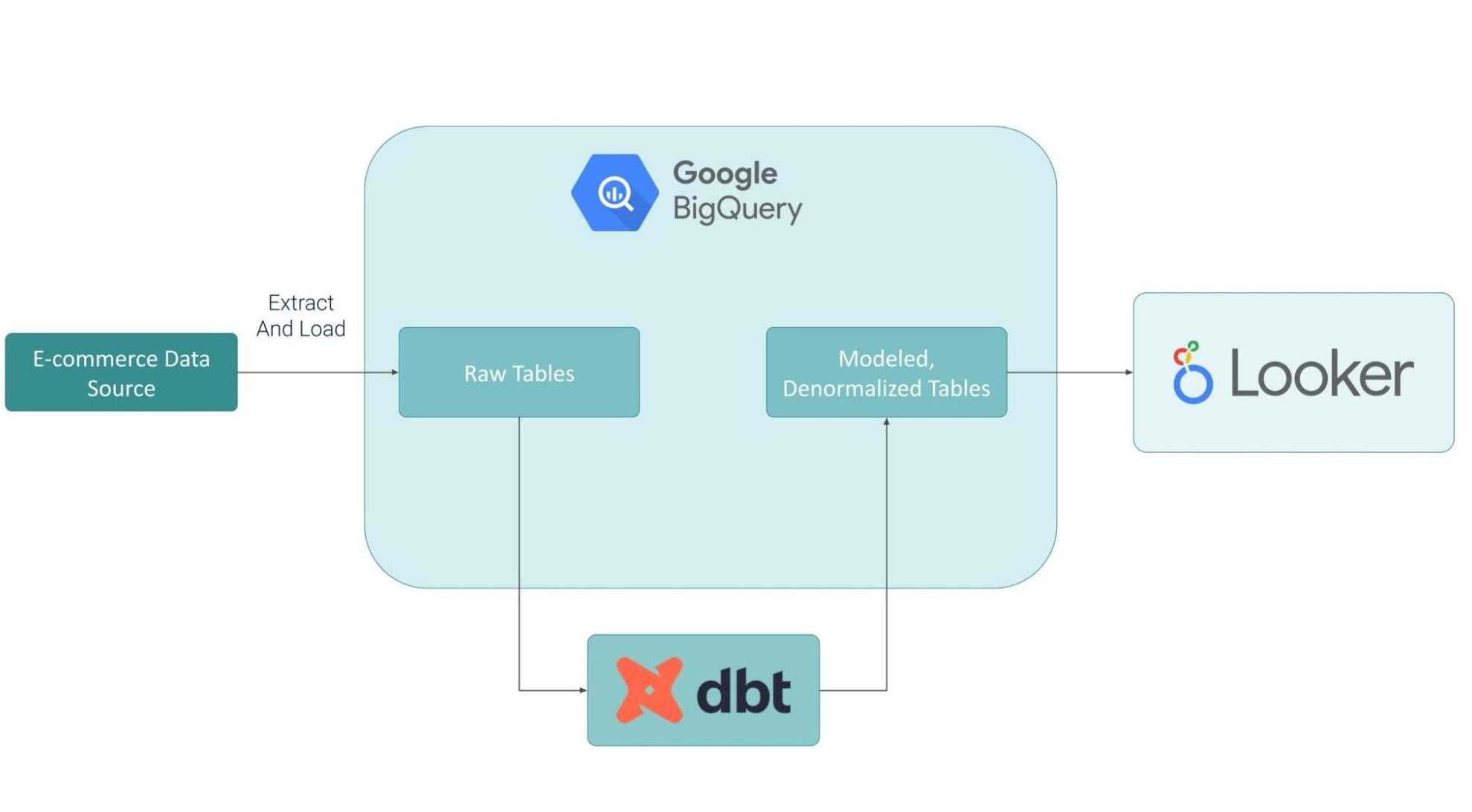
Um das dbt-Modell auszuführen, müssen wir zunächst die Konfiguration vornehmen. Sie finden den gesamten Weg Schritt für Schritt mit Befehlen in diesem Artikel: Aufstehen und loslegen: Datenpipeline mit BigQuery und dbt.
Alle Transformationen, Filter und Beziehungen werden in der dbt-Modellcodedatei namens `fact_revenue.sql` definiert. Die Abfrage sieht fast genauso aus wie bei der zuvor in PDT erstellten Transformation
config {
materialized: 'table',
strategy: 'timestamp',
updated_at: 'created_at'
}
WITH
fact_revenue AS (
SELECT
o.created_at AS order_date,
u.ID AS customer_id,
SUM(oi.sale_price*o.num_of_item) AS revenue
FROM
`bigquery-public-data.thelook_ecommerce.order_items` AS oi
LEFT JOIN
`bigquery-public-data.thelook_ecommerce.orders` AS o
ON
oi.order_id = o.order_id
LEFT JOIN
`bigquery-public-data.thelook_ecommerce.users` AS u
ON
oi.user_id = u.id
WHERE
oi.status NOT IN ('Cancelled',
'Returned')
GROUP BY
1,
2 )
SELECT
GENERATE_UUID() AS primary_key,
order_date,
customer_id,
SUM(revenue) AS revenue
FROM
fact_revenue
GROUP BY
1,
2,
3
Zusätzlich haben wir in dbt Feldbeschreibungen und Tests für die Eindeutigkeit des Primärschlüssels in der Datei shema.yml hinzugefügt. Der gesamte Code sieht wie folgt aus:
version: 2
models:
- name: fact_revenue
description: "Table contains revenue data"
columns:
- name: primary_key
description: "The primary key for this table"
tests:
- unique
- name: revenue
description: "Revenue in USD"
Das Hinzufügen von Tests in dbt ist sehr einfach. Neben einfachen Tests können Sie auch die Möglichkeiten des Pakets `dbt-expectations` erweitern. Ein weiterer Vorteil der Verwendung von dbt und der Beschreibung von Spalten ist, dass Sie eine augenfreundliche Dokumentation mit Beziehungsdiagrammen, durchgeführten Tests, kompiliertem Code und vielem mehr erstellen können.
Die Beispieldokumentation für die Tabelle fact_revenue sieht so aus und ist auch für Benutzer mit anderen Rollen als der eines Entwicklers verfügbar.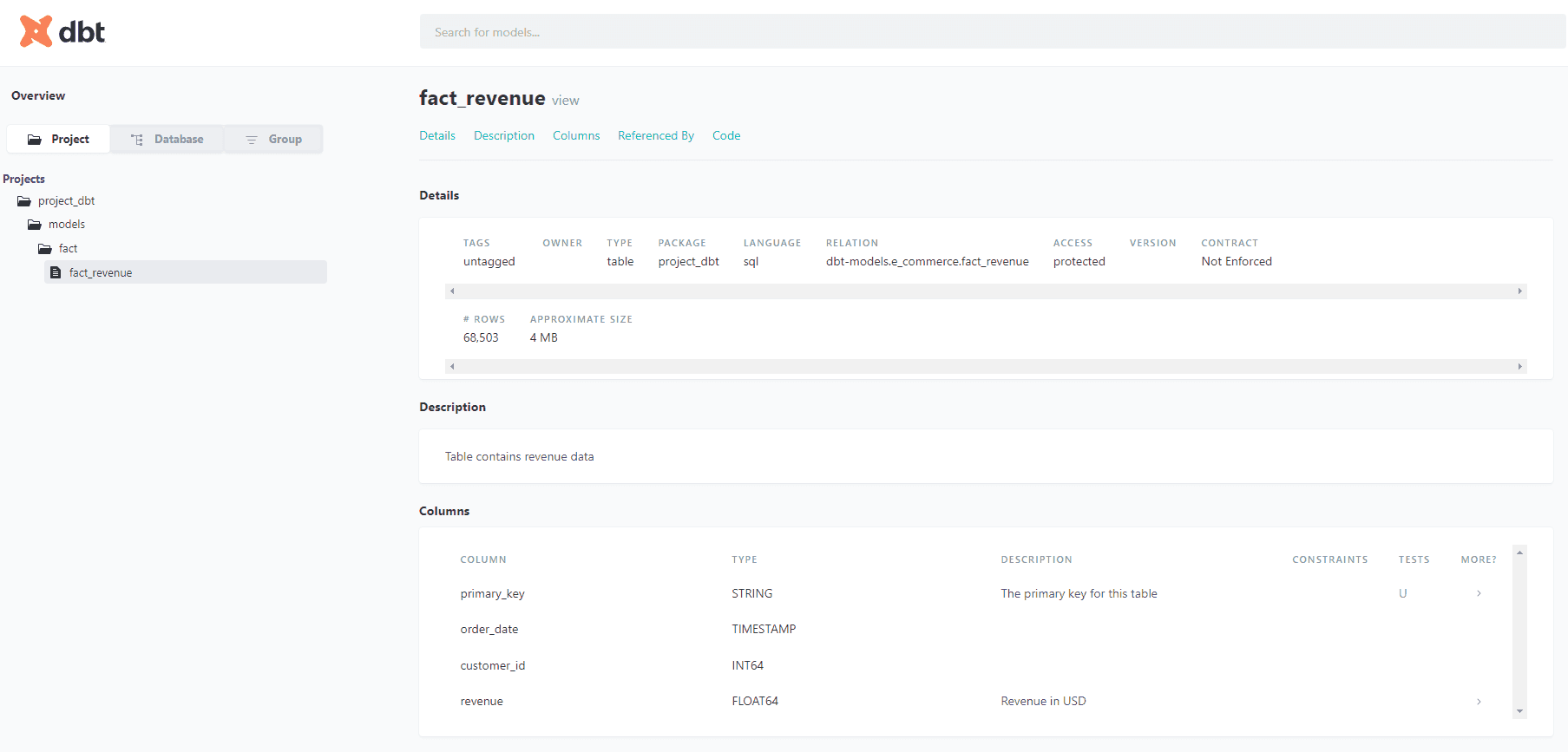
Sie können neu erstellte Objekte schnell überprüfen und den Code, der Transformationen und angewandte Tests erstellt, kontrollieren.
Eine exponierte dbt-Tabelle als Ansicht in Looker sieht anders aus als PDT. Die Transformationsabfrage ist nicht sichtbar, da sie in der dbt-Abfrage definiert ist. Wir verweisen lediglich auf die neu erstellte Tabelle `fact_revenue`. Welche Quelltabellen, welche Filter angewendet wurden und wie der Umsatz berechnet wurde, ist nicht sichtbar. Das könnte den Prozess der Fehlersuche im Looker-Bericht als Code verlängern, da die Entwickler den Code mit einem separaten Tool überprüfen müssen. Unten finden Sie das gesamte View-Objekt:
view: fact_revenue {
sql_table_name: `dbt-models.e_commerce.fact_revenue` ;;
dimension: primary_key {
primary_key: yes
hidden: yes
description: "The primary key for this table"
type: string
sql: ${TABLE}.primary_key ;;
}
dimension_group: order {
type: time
timeframes: [date, month, year]
sql: ${TABLE}.order_date ;;
}
dimension: customer_id {
value_format_name: id
type: number
sql: ${TABLE}.customer_id ;;
}
dimension: revenue {
hidden: yes
type: number
sql: ${TABLE}.revenue ;;
}
measure: total_revenue {
description: "Revenue in USD"
type: sum
value_format: "$0.00"
sql: ${revenue} ;;
}
}
Diese Tabelle, die als Ansicht dargestellt wird, wird auch als eigenständige Erkundung in Looker dargestellt. Der Endbenutzer wird keinen Unterschied in der Benutzeroberfläche zwischen einer auf PDT basierenden Erkundung und einer dbt-Tabelle bemerken, welcher Ansatz ist also besser?
Ergebnisse
Wie bereits erwähnt, wird der Endbenutzer keine Unterschiede im generierten Bericht feststellen, selbst wenn wir 2 verschiedene Modellierungsansätze verwendet haben. Nachfolgend sehen Sie einen generierten Bericht. 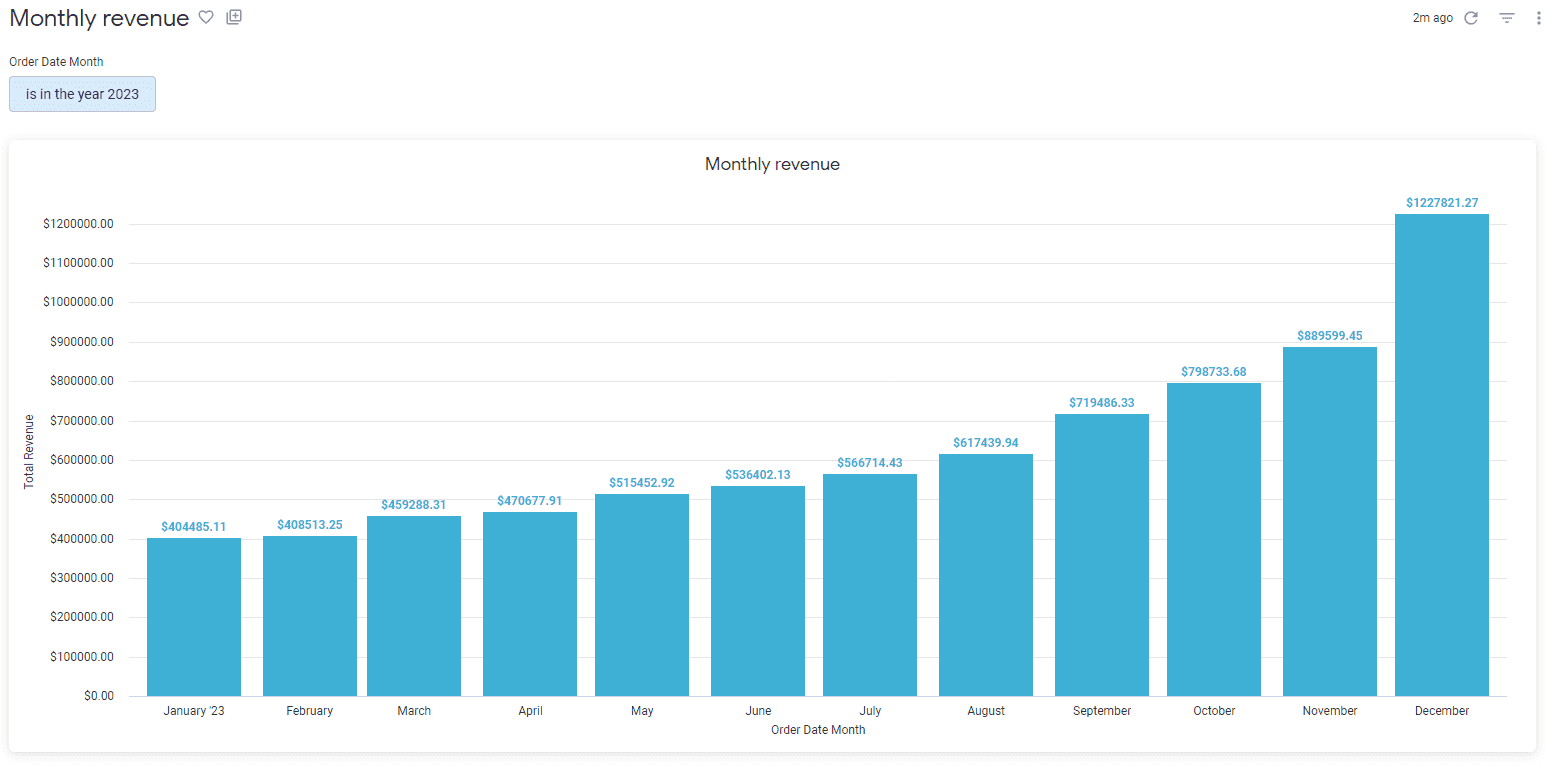
Die Codeausschnitte, die in der obigen Grafik generiert wurden, sehen ebenfalls sehr ähnlich aus - der Unterschied liegt im Namen der Quelle.
Looker PDT
SELECT
(FORMAT_TIMESTAMP('%Y-%m', fact_revenue_pdt.order_date )) AS fact_revenue_pdt_order_month,
COALESCE(SUM(fact_revenue_pdt.revenue ), 0) AS fact_revenue_pdt_total_revenue
FROM `dbt-models.looker_scratch.LR_65NLV1704627695961_fact_revenue_pdt` AS fact_revenue_pdt
WHERE ((( fact_revenue_pdt.order_date ) >= ((TIMESTAMP('2023-01-01 00:00:00'))) AND ( fact_revenue_pdt.order_date ) < ((TIMESTAMP(DATETIME_ADD(DATETIME(TIMESTAMP('2023-01-01 00:00:00')), INTERVAL 1 YEAR))))))
GROUP BY
1
ORDER BY
1 DESCdbt
SELECT
(FORMAT_TIMESTAMP('%Y-%m', fact_revenue.order_date )) AS fact_revenue_order_month,
COALESCE(SUM(fact_revenue.revenue ), 0) AS fact_revenue_total_revenue
FROM `dbt-models.e_commerce.fact_revenue` AS fact_revenue
WHERE ((( fact_revenue.order_date ) >= ((TIMESTAMP('2023-01-01 00:00:00'))) AND ( fact_revenue.order_date ) < ((TIMESTAMP(DATETIME_ADD(DATETIME(TIMESTAMP('2023-01-01 00:00:00')), INTERVAL 1 YEAR))))))
GROUP BY
1
ORDER BY
1 DESCSchlussfolgerung: Wann lohnt es sich, dbt anstelle von PDT zu verwenden?
Unter Berücksichtigung der oben dargestellten Unterschiede wollen wir uns auf einige Aspekte konzentrieren, um beide Methoden zu vergleichen.
Wie klar ist die Struktur des Modellcodes?
Wie in beiden Fällen oben dargestellt, haben wir die gleiche Logik und SQL-Abfrage verwendet, um eine Faktentabelle zu erstellen. Bei PDT befindet sich jedoch der gesamte Code mit den Bedingungen an einer Stelle im Looker-Repository, während der Entwickler für die dbt-Tabelle beide Quellen zum Debuggen oder Refactoring verwenden müsste. Da es sich bei PDT um eine systemeigene Funktion handelt, ist es vielleicht praktischer, die Datenquellen zu überprüfen.
Kosten für zusätzliches Werkzeug
Es könnte ein Szenario geben, in dem ein Unternehmen auch andere Analysetools verwendet. In diesem Fall ermöglicht es dbt dem Benutzer, Modelle zu erstellen, die als Datenquellen wiederverwendet werden können. Für unsere Demo haben wir eine Umsatzfaktentabelle erstellt, die von mehreren Teams in einem Unternehmen als KPI verwendet werden kann. Daher wird die Durchführung von Transformationen in dbt bequemer sein.
Wechsel zu einer anderen BI-Plattform
Es ist auch möglich, dass ein Unternehmen eines Tages beschließt, ein BI-Tool zu ändern und den Code für das Modell neu zu schreiben. Es wird praktischer sein, den Code von dbt wiederzuverwenden als Looker und seine Syntax. Außerdem glauben wir, dass dbt einfach zu erlernen und in der Produktion zu implementieren ist. Es ist auch einfach, die Analysten zu schulen, die die dbt-Modelle pflegen, was bedeutet, dass es eine gute Investition sein könnte.
Genauigkeit des Datenmodells
Für beide Ansätze können wir Tests implementieren, um die Ergebnisse zu validieren. Allerdings ist das Hinzufügen von Tests in dbt bei der Entwicklung viel einfacher. Für die meisten Fälle können wir sie in der Konfiguration mit 2 Zeilen wiederverwendbarem Code definieren. Außerdem ist es wichtig, Fehler so früh wie möglich zu erkennen. Der Flow mit dbt erlaubt es dem Benutzer, dies zu tun, bevor die Daten in Looker landen.
Muster der Dokumentation
Beide Methoden erlauben das Hinzufügen von Kommentaren zu exponierten Metriken. Wir sind jedoch der Meinung, dass dbt eine benutzerfreundlichere Dokumentation der transformierten Tabellen liefert. Es ist auch auf den ersten Blick ersichtlich, welche Tests implementiert wurden und wie die Definitionen der Spalten lauten. dbt ist außerdem ein offenes Framework und es besteht weniger Gefahr, dass die Organisation den Zugang zur Dokumentation des Modells verliert, wenn Looker durch eine andere Plattform ersetzt wird.
Wenn wir das berücksichtigen, können wir auch sehen, dass das Wechseln zwischen 2 Dokumentationsquellen nicht sehr praktisch und gut entschlüsselt sein könnte. In den meisten Fällen dürften Looker-Felder ausreichen.
Die Flexibilität bei der Erzeugung von Aggregaten
Alle Aggregate müssen in Looker definiert werden. Wir können dies nicht auf DBT übertragen, da alle voraggregierten Daten bei diesem Ansatz zu Dimensionen werden.
Für den einfachen Fall, den wir in diesem Artikel vorgestellt haben, tendieren wir zu einer Kombination aus dbt und Looker, da wir mehr Möglichkeiten haben, Daten während der Entwicklung zu validieren und zu dokumentieren. Es ist auch eine sichere Option, um wiederverwendbaren Code zu haben, falls Sie zu einem anderen Berichtssystem als Looker wechseln müssen.
Zusammenfassend lässt sich sagen, dass wir empfehlen, beides zu verwenden. Wenn etwas in DBT modelliert werden kann, ist es von Vorteil, solche Tabellen außerhalb von Looker zu verwenden. Es gibt jedoch einige Anwendungsfälle, wie z.B. parametrisierte und flüssige Abfragen, die in LookML modelliert werden müssen.
Haben Sie noch Fragen? Kontaktieren Sie uns einfach.
Verfasst von
Anna Wnuczko
Unsere Ideen
Weitere Blogs




Contact